Catatan perev. : Penulis artikel asli, Nicolas Leiva, adalah arsitek solusi Cisco yang memutuskan untuk berbagi dengan rekan-rekannya, insinyur jaringan, bagaimana jaringan Kubernetes bekerja dari dalam. Untuk melakukan ini, ia mengeksplorasi konfigurasi paling sederhana di cluster, aktif menggunakan akal sehat, pengetahuan tentang jaringan dan utilitas Linux / Kubernetes standar. Ternyata dengan lantang, tapi sangat jelas.
Selain fakta bahwa
panduan The Hard Way Kubernetes dari Kelsey Hightower hanya berfungsi (
bahkan pada AWS! ), Saya suka bahwa jaringannya tetap bersih dan sederhana; dan ini adalah peluang bagus untuk memahami peran, misalnya, Container Network Interface (
CNI ). Karena itu, saya akan menambahkan bahwa jaringan Kubernetes tidak terlalu intuitif, terutama untuk pemula ... dan juga jangan lupa bahwa "tidak
ada yang namanya jaringan kontainer".
Meskipun sudah ada bahan yang bagus tentang topik ini (lihat tautan di
sini ), saya tidak dapat menemukan contoh sedemikian rupa sehingga saya akan menggabungkan semua yang diperlukan dengan kesimpulan dari tim yang disukai dan dibenci oleh teknisi jaringan, yang menunjukkan apa yang sebenarnya terjadi di balik layar. Karena itu, saya memutuskan untuk mengumpulkan informasi dari banyak sumber - Saya harap ini membantu dan Anda lebih memahami bagaimana semuanya terhubung satu sama lain. Pengetahuan ini penting tidak hanya untuk menguji diri Anda sendiri, tetapi juga untuk menyederhanakan proses mendiagnosis masalah. Anda dapat mengikuti contoh di kluster Anda dari
Kubernetes The Hard Way : semua alamat IP dan pengaturan diambil dari sana (per komit untuk Mei 2018, sebelum menggunakan
wadah Nabla ).
Dan kita akan mulai dari akhir, ketika kita memiliki tiga pengendali dan tiga simpul kerja:
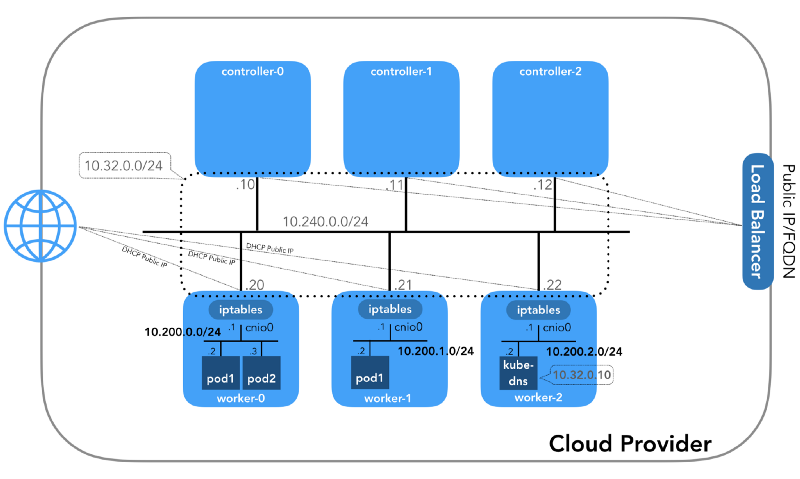
Anda mungkin memperhatikan bahwa ada juga setidaknya tiga subnet pribadi di sini! Sedikit kesabaran, dan mereka semua akan dipertimbangkan. Ingatlah bahwa meskipun kami merujuk pada awalan IP yang sangat spesifik, mereka hanya diambil dari
Kubernetes The Hard Way , sehingga mereka hanya memiliki signifikansi lokal, dan Anda bebas memilih blok alamat lain untuk lingkungan Anda sesuai dengan
RFC 1918 . Untuk kasus IPv6, akan ada artikel blog terpisah.
Jaringan Host (10.240.0.0/24)
Ini adalah jaringan internal di mana semua node merupakan bagian. Didefinisikan oleh flag
--private-network-ip di
GCP atau opsi
--private-ip-address di
AWS ketika mengalokasikan sumber daya komputasi.
Menginisialisasi node pengontrol di GCP
for i in 0 1 2; do gcloud compute instances create controller-${i} \
(
controllers_gcp.sh )
Inisialisasi Node Controller di AWS
for i in 0 1 2; do declare controller_id${i}=`aws ec2 run-instances \
(
controllers_aws.sh )
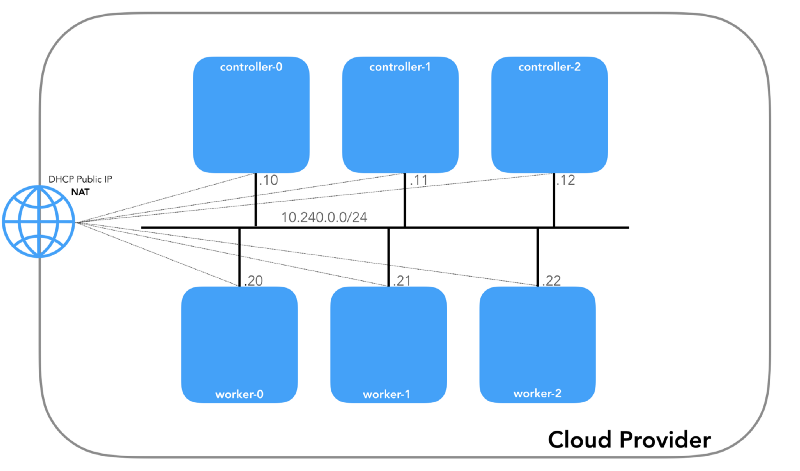
Setiap instance akan memiliki dua alamat IP: privat dari jaringan host (controller -
10.240.0.1${i}/24 , pekerja -
10.240.0.2${i}/24 ) dan yang publik, yang ditunjuk oleh penyedia cloud, yang akan kita bicarakan nanti bagaimana menuju ke
NodePorts .
Gcp
$ gcloud compute instances list NAME ZONE MACHINE_TYPE PREEMPTIBLE INTERNAL_IP EXTERNAL_IP STATUS controller-0 us-west1-c n1-standard-1 10.240.0.10 35.231.XXX.XXX RUNNING worker-1 us-west1-c n1-standard-1 10.240.0.21 35.231.XX.XXX RUNNING ...
Aws
$ aws ec2 describe-instances --query 'Reservations[].Instances[].[Tags[?Key==`Name`].Value[],PrivateIpAddress,PublicIpAddress]' --output text | sed '$!N;s/\n/ /' 10.240.0.10 34.228.XX.XXX controller-0 10.240.0.21 34.173.XXX.XX worker-1 ...
Semua node harus dapat melakukan ping satu sama lain jika
kebijakan keamanannya benar (dan jika
ping diinstal pada host).
Jaringan perapian (10.200.0.0/16)
Ini adalah jaringan tempat pod hidup. Setiap simpul kerja menggunakan subnet dari jaringan ini. Dalam kasus kami,
POD_CIDR=10.200.${i}.0/24 untuk
worker-${i} .
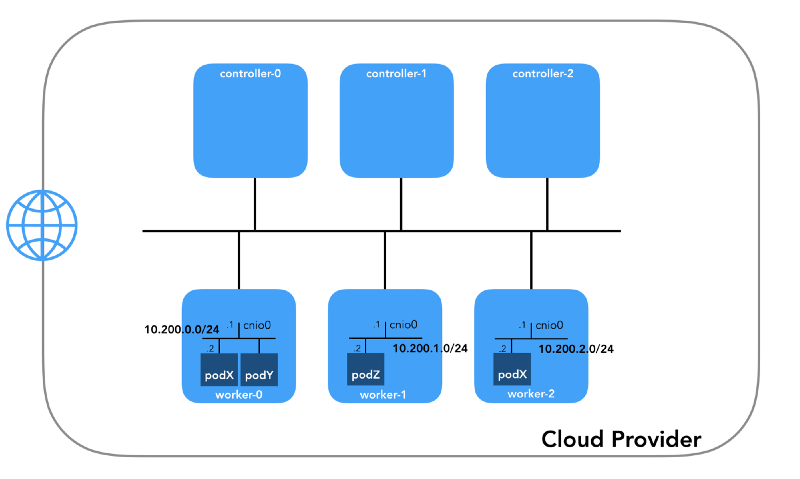
Untuk memahami bagaimana semuanya dikonfigurasi, mundur selangkah dan lihat
model jaringan Kubernetes , yang membutuhkan hal-hal berikut:
- Semua wadah dapat berkomunikasi dengan wadah lain tanpa menggunakan NAT.
- Semua node dapat berkomunikasi dengan semua kontainer (dan sebaliknya) tanpa menggunakan NAT.
- IP yang dilihat wadah harus sama dengan yang dilihat orang lain.
Semua ini dapat diimplementasikan dengan banyak cara, dan Kubernetes melewati pengaturan jaringan ke
plugin CNI .
“Plugin CNI bertanggung jawab untuk menambahkan antarmuka jaringan ke namespace jaringan wadah (misalnya, satu ujung pasangan veth ) dan membuat perubahan yang diperlukan pada host (misalnya, menghubungkan ujung kedua veth ke jembatan). Kemudian dia harus menetapkan antarmuka IP dan mengkonfigurasi rute sesuai dengan bagian Manajemen Alamat IP dengan memanggil plugin IPAM yang diinginkan. " (dari Spesifikasi Antarmuka Jaringan Kontainer )
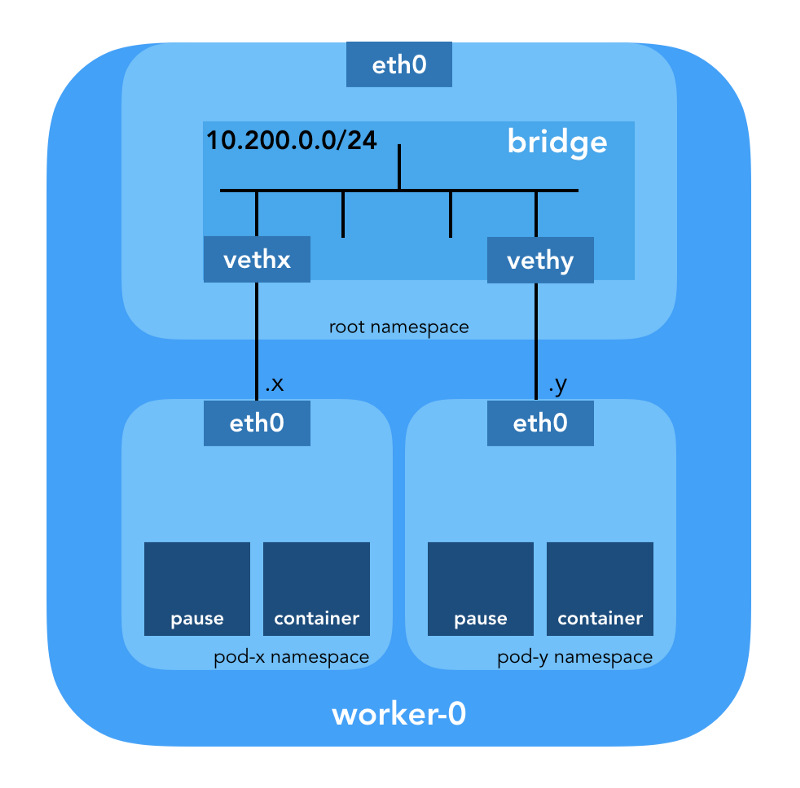
Namespace jaringan
“Namespace membungkus sumber daya sistem global menjadi sebuah abstraksi yang dapat dilihat oleh proses-proses dalam namespace ini sedemikian rupa sehingga mereka memiliki turunan tersendiri dari sumber daya global. Perubahan sumber daya global terlihat oleh proses lain yang termasuk dalam namespace ini, tetapi tidak terlihat oleh proses lain. " ( dari halaman manual namespaces )
Linux menyediakan tujuh ruang nama yang berbeda (
Cgroup ,
IPC ,
Network ,
Mount ,
PID ,
User ,
UTS ). Ruang nama jaringan (
CLONE_NEWNET ) mendefinisikan sumber daya jaringan yang tersedia untuk proses: "Setiap ruang nama jaringan memiliki perangkat jaringan, alamat IP, tabel perutean IP, direktori
/proc/net , nomor port dan sebagainya"
( dari artikel " Ruang nama dalam operasi ") .
Perangkat Ethernet Virtual (Veth)
"Pasangan jaringan virtual (veth) menawarkan abstraksi dalam bentuk" pipa ", yang dapat digunakan untuk membuat terowongan di antara ruang nama jaringan atau untuk membuat jembatan ke perangkat jaringan fisik di ruang jaringan lain. Ketika namespace dibebaskan, semua perangkat di dalamnya dihancurkan. " (dari halaman manual ruang nama jaringan )
Turun ke tanah dan lihat bagaimana semua ini berhubungan dengan cluster. Pertama,
plugin jaringan di Kubernetes beragam, dan plugin CNI adalah salah satunya (
mengapa tidak CNM? ).
Kubelet pada setiap node memberi tahu
runtime kontainer yang digunakan
plug-in jaringan . Container Network Interface (
CNI ) adalah antara runtime wadah dan implementasi jaringan. Dan sudah plugin CNI mengatur jaringan.
“Plugin CNI dipilih dengan meneruskan --network-plugin=cni baris perintah --network-plugin=cni ke Kubelet. Kubelet membaca file dari --cni-conf-dir (defaultnya adalah /etc/cni/net.d ) dan menggunakan konfigurasi CNI dari file ini untuk mengkonfigurasi jaringan untuk setiap file. " (dari Persyaratan Plugin Jaringan )
Binari nyata dari plugin CNI ada di
-- cni-bin-dir (defaultnya adalah
/opt/cni/bin ).
Harap perhatikan bahwa
kubelet.service panggilan
--network-plugin=cni termasuk
--network-plugin=cni :
[Service] ExecStart=/usr/local/bin/kubelet \\ --config=/var/lib/kubelet/kubelet-config.yaml \\ --network-plugin=cni \\ ...
Pertama-tama, Kubernetes menciptakan namespace jaringan untuk perapian, bahkan sebelum memanggil plugin apa pun. Ini diimplementasikan menggunakan wadah
pause khusus, yang "berfungsi sebagai" wadah induk "untuk semua wadah perapian"
(dari artikel " Wadah Jeda Yang Maha Kuasa ") . Kubernetes kemudian menjalankan plugin CNI untuk melampirkan wadah
pause ke jaringan. Semua wadah pod menggunakan
netns wadah
pause ini.
{ "cniVersion": "0.3.1", "name": "bridge", "type": "bridge", "bridge": "cnio0", "isGateway": true, "ipMasq": true, "ipam": { "type": "host-local", "ranges": [ [{"subnet": "${POD_CIDR}"}] ], "routes": [{"dst": "0.0.0.0/0"}] } }
Konfigurasi CNI yang digunakan menunjukkan penggunaan plugin
bridge untuk mengkonfigurasi jembatan perangkat lunak Linux (L2) di ruang nama root yang disebut
cnio0 (
nama defaultnya adalah
cni0 ), yang bertindak sebagai gateway (
"isGateway": true ).

Pasangan veth juga akan dikonfigurasi untuk menghubungkan perapian ke jembatan yang baru dibuat:
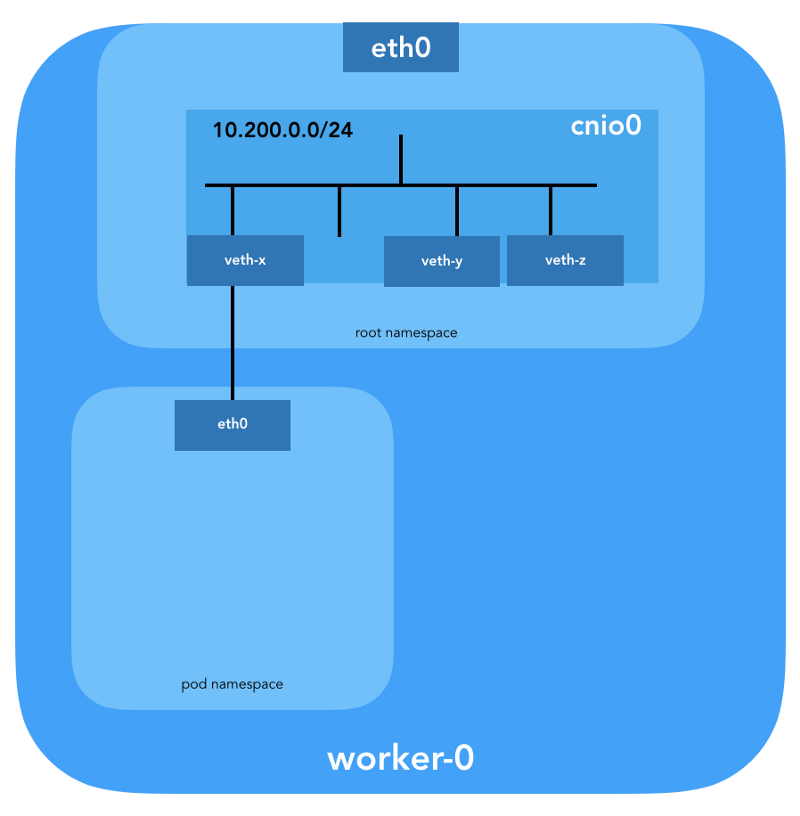
Untuk menetapkan informasi L3, seperti alamat IP,
plugin IPAM (
ipam ) dipanggil. Dalam hal ini, tipe
host-local digunakan, "yang menyimpan keadaan secara lokal pada sistem file host, yang memastikan keunikan alamat IP pada satu host"
(dari host-local ) . Plugin IPAM mengembalikan informasi ini ke plugin sebelumnya (
bridge ), sehingga semua rute yang ditentukan dalam konfigurasi dapat dikonfigurasi (
"routes": [{"dst": "0.0.0.0/0"}] ). Jika
gw tidak ditentukan,
ini diambil dari subnet . Rute default juga dikonfigurasi di namespace jaringan perapian, menunjuk ke jembatan (yang dikonfigurasi sebagai subnet IP pertama dari perapian).
Dan detail penting terakhir: kami meminta penyamaran (
"ipMasq": true ) untuk lalu lintas yang berasal dari jaringan perapian. Kami tidak benar-benar membutuhkan NAT di sini, tetapi ini adalah konfigurasi di
Kubernetes The Hard Way . Oleh karena itu, untuk kelengkapan, saya harus menyebutkan bahwa entri di
iptables plugin
bridge dikonfigurasi untuk contoh khusus ini. Semua paket dari perapian, penerima yang tidak dalam kisaran
224.0.0.0/4 ,
akan berada di belakang NAT , yang tidak cukup memenuhi persyaratan "semua wadah dapat berkomunikasi dengan wadah lain tanpa menggunakan NAT." Baiklah, kami akan membuktikan mengapa NAT tidak diperlukan ...

Perutean perapian
Sekarang kami siap untuk menyesuaikan polong. Mari kita lihat semua ruang jaringan dari nama-nama salah satu simpul kerja dan menganalisis salah satunya setelah membuat penyebaran
nginx dari sini . Kami akan menggunakan
lsns dengan opsi
-t untuk memilih jenis namespace yang diinginkan (mis.
net ):
ubuntu@worker-0:~$ sudo lsns -t net NS TYPE NPROCS PID USER COMMAND 4026532089 net 113 1 root /sbin/init 4026532280 net 2 8046 root /pause 4026532352 net 4 16455 root /pause 4026532426 net 3 27255 root /pause
Menggunakan opsi
-i ke
ls kita dapat menemukan nomor inode mereka:
ubuntu@worker-0:~$ ls -1i /var/run/netns 4026532352 cni-1d85bb0c-7c61-fd9f-2adc-f6e98f7a58af 4026532280 cni-7cec0838-f50c-416a-3b45-628a4237c55c 4026532426 cni-912bcc63-712d-1c84-89a7-9e10510808a0
Anda juga dapat membuat daftar semua ruang nama jaringan menggunakan
ip netns :
ubuntu@worker-0:~$ ip netns cni-912bcc63-712d-1c84-89a7-9e10510808a0 (id: 2) cni-1d85bb0c-7c61-fd9f-2adc-f6e98f7a58af (id: 1) cni-7cec0838-f50c-416a-3b45-628a4237c55c (id: 0)
Untuk melihat semua proses yang berjalan di ruang jaringan
cni-912bcc63–712d-1c84–89a7–9e10510808a0 (
4026532426 ), Anda dapat menjalankan, misalnya, perintah berikut:
ubuntu@worker-0:~$ sudo ls -l /proc/[1-9]*/ns/net | grep 4026532426 | cut -f3 -d"/" | xargs ps -p PID TTY STAT TIME COMMAND 27255 ? Ss 0:00 /pause 27331 ? Ss 0:00 nginx: master process nginx -g daemon off; 27355 ? S 0:00 nginx: worker process
Dapat dilihat bahwa selain
pause di pod ini, kami meluncurkan
nginx . Wadah
pause berbagi ruang nama
net dan
ipc dengan semua wadah pod lainnya. Ingat PID dari
pause - 27255; kami akan kembali ke sana.
Sekarang mari kita lihat apa yang
kubectl tentang pod ini:
$ kubectl get pods -o wide | grep nginx nginx-65899c769f-wxdx6 1/1 Running 0 5d 10.200.0.4 worker-0
Lebih detail:
$ kubectl describe pods nginx-65899c769f-wxdx6
Name: nginx-65899c769f-wxdx6 Namespace: default Node: worker-0/10.240.0.20 Start Time: Thu, 05 Jul 2018 14:20:06 -0400 Labels: pod-template-hash=2145573259 run=nginx Annotations: <none> Status: Running IP: 10.200.0.4 Controlled By: ReplicaSet/nginx-65899c769f Containers: nginx: Container ID: containerd://4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 Image: nginx ...
Kami melihat nama pod -
nginx-65899c769f-wxdx6 - dan ID salah satu kontainernya (
nginx ), tetapi tidak ada yang dikatakan tentang
pause . Gali simpul kerja yang lebih dalam untuk mencocokkan semua data. Ingat bahwa
Kubernetes The Hard Way tidak menggunakan
Docker , oleh karena itu untuk perincian tentang wadah kita merujuk ke utilitas konsol yang
mengandungerd - ctr
(lihat juga artikel " Integrasi contenterd dengan Kubernetes, menggantikan Docker, siap untuk produksi " - kira - kira Transfer ) :
ubuntu@worker-0:~$ sudo ctr namespaces ls NAME LABELS k8s.io
Mengetahui
k8s.io containerd (
k8s.io ), Anda bisa mendapatkan ID kontainer
nginx :
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers ls | grep nginx 4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 docker.io/library/nginx:latest io.containerd.runtime.v1.linux
... dan
pause juga:
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers ls | grep pause 0866803b612f2f55e7b6b83836bde09bd6530246239b7bde1e49c04c7038e43a k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux 21640aea0210b320fd637c22ff93b7e21473178de0073b05de83f3b116fc8834 k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 k8s.gcr.io/pause:3.1 io.containerd.runtime.v1.linux
ID kontainer
nginx berakhir dengan
…983c7 cocok dengan yang kami dapatkan dari
kubectl . Mari kita lihat apakah kita dapat menentukan wadah
pause mana yang termasuk dalam
nginx pod:
ubuntu@worker-0:~$ sudo ctr -n k8s.io task ls TASK PID STATUS ... d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 27255 RUNNING 4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 27331 RUNNING
Ingat bahwa proses dengan PID 27331 dan 27355 sedang berjalan di
cni-912bcc63–712d-1c84–89a7–9e10510808a0 namespace jaringan?
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers info d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 { "ID": "d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6", "Labels": { "io.cri-containerd.kind": "sandbox", "io.kubernetes.pod.name": "nginx-65899c769f-wxdx6", "io.kubernetes.pod.namespace": "default", "io.kubernetes.pod.uid": "0b35e956-8080-11e8-8aa9-0a12b8818382", "pod-template-hash": "2145573259", "run": "nginx" }, "Image": "k8s.gcr.io/pause:3.1", ...
... dan:
ubuntu@worker-0:~$ sudo ctr -n k8s.io containers info 4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 { "ID": "4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7", "Labels": { "io.cri-containerd.kind": "container", "io.kubernetes.container.name": "nginx", "io.kubernetes.pod.name": "nginx-65899c769f-wxdx6", "io.kubernetes.pod.namespace": "default", "io.kubernetes.pod.uid": "0b35e956-8080-11e8-8aa9-0a12b8818382" }, "Image": "docker.io/library/nginx:latest", ...
Sekarang kita tahu pasti wadah mana yang berjalan di pod ini (
nginx-65899c769f-wxdx6 ) dan namespace jaringan (
cni-912bcc63–712d-1c84–89a7–9e10510808a0 ):
- nginx (ID:
4c0bd2e2e5c0b17c637af83376879c38f2fb11852921b12413c54ba49d6983c7 ); - jeda (ID:
d19b1b1c92f7cc90764d4f385e8935d121bca66ba8982bae65baff1bc2841da6 ).

Bagaimana ini di bawah (
nginx-65899c769f-wxdx6 ) terhubung ke jaringan? Kami menggunakan PID 27255 yang sebelumnya diterima dari
pause untuk menjalankan perintah di namespace jaringannya (
cni-912bcc63–712d-1c84–89a7–9e10510808a0 ):
ubuntu@worker-0:~$ sudo ip netns identify 27255 cni-912bcc63-712d-1c84-89a7-9e10510808a0
Untuk keperluan ini, kita akan menggunakan
nsenter dengan opsi
-t yang mendefinisikan PID target, dan
-n tanpa menentukan file untuk masuk ke namespace jaringan dari proses target (27255). Inilah yang akan
ip link show :
ubuntu@worker-0:~$ sudo nsenter -t 27255 -n ip link show 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 3: eth0@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default link/ether 0a:58:0a:c8:00:04 brd ff:ff:ff:ff:ff:ff link-netnsid 0
... dan
ifconfig eth0 :
ubuntu@worker-0:~$ sudo nsenter -t 27255 -n ifconfig eth0 eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 10.200.0.4 netmask 255.255.255.0 broadcast 0.0.0.0 inet6 fe80::2097:51ff:fe39:ec21 prefixlen 64 scopeid 0x20<link> ether 0a:58:0a:c8:00:04 txqueuelen 0 (Ethernet) RX packets 540 bytes 42247 (42.2 KB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 177 bytes 16530 (16.5 KB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
Ini mengkonfirmasi bahwa alamat IP yang diperoleh sebelumnya melalui
kubectl get pod dikonfigurasikan pada antarmuka
eth0 . Antarmuka ini adalah bagian dari
pasangan veth , satu ujungnya ada di perapian, dan yang lainnya di root namespace. Untuk mengetahui antarmuka ujung kedua, kami menggunakan
ethtool :
ubuntu@worker-0:~$ sudo ip netns exec cni-912bcc63-712d-1c84-89a7-9e10510808a0 ethtool -S eth0 NIC statistics: peer_ifindex: 7
Kita melihat bahwa
ifindex pesta adalah 7. Periksa bahwa itu ada di root namespace. Ini dapat dilakukan dengan menggunakan
ip link :
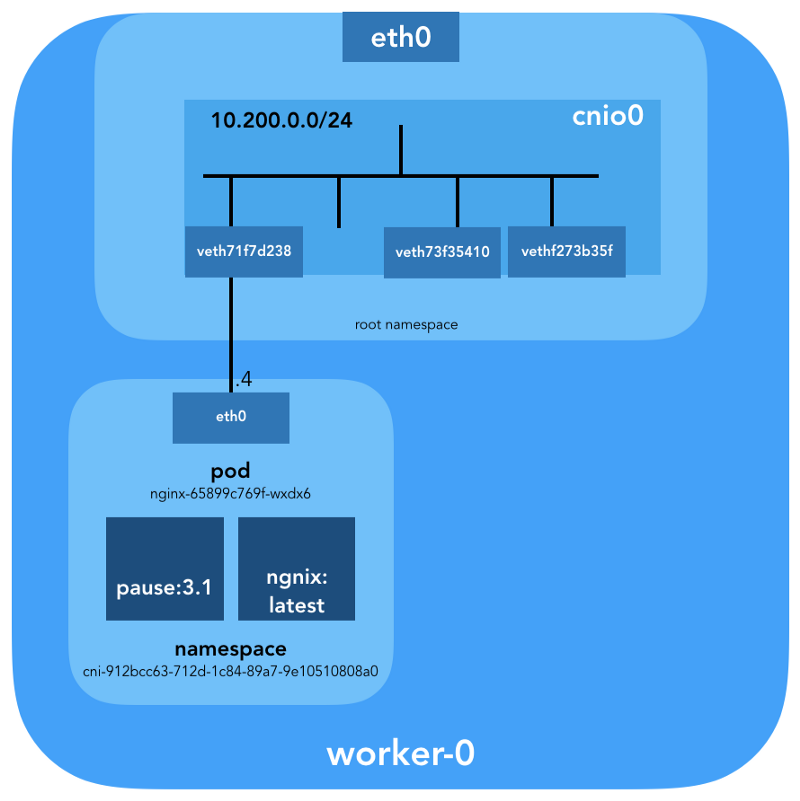
ubuntu@worker-0:~$ ip link | grep '^7:' 7: veth71f7d238@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master cnio0 state UP mode DEFAULT group default
Untuk memastikan ini pada akhirnya, mari kita lihat:
ubuntu@worker-0:~$ sudo cat /sys/class/net/veth71f7d238/ifindex 7
Hebat, sekarang semuanya jelas dengan tautan virtual. Menggunakan
brctl mari kita lihat siapa lagi yang terhubung ke jembatan Linux:
ubuntu@worker-0:~$ brctl show cnio0 bridge name bridge id STP enabled interfaces cnio0 8000.0a580ac80001 no veth71f7d238 veth73f35410 vethf273b35f
Jadi, gambarnya adalah sebagai berikut:
Pemeriksaan perutean
Bagaimana sebenarnya kami meneruskan lalu lintas? Mari kita lihat tabel routing di pod namespace jaringan:
ubuntu@worker-0:~$ sudo ip netns exec cni-912bcc63-712d-1c84-89a7-9e10510808a0 ip route show default via 10.200.0.1 dev eth0 10.200.0.0/24 dev eth0 proto kernel scope link src 10.200.0.4
Setidaknya kita tahu cara menuju ke root namespace (
default via 10.200.0.1 ). Sekarang mari kita lihat tabel routing host:
ubuntu@worker-0:~$ ip route list default via 10.240.0.1 dev eth0 proto dhcp src 10.240.0.20 metric 100 10.200.0.0/24 dev cnio0 proto kernel scope link src 10.200.0.1 10.240.0.0/24 dev eth0 proto kernel scope link src 10.240.0.20 10.240.0.1 dev eth0 proto dhcp scope link src 10.240.0.20 metric 100
Kita tahu bagaimana meneruskan paket ke Router VPC (VPC
memiliki router “implisit”, yang
biasanya memiliki alamat kedua dari ruang alamat IP utama dari subnet). Sekarang: Apakah Router VPC tahu cara menuju jaringan setiap perapian? Tidak, dia tidak, oleh karena itu diasumsikan bahwa rute akan dikonfigurasikan oleh plugin CNI atau
secara manual (seperti dalam manual). Rupanya,
AWS CNI-plugin tidak hanya untuk kita di AWS. Ingat bahwa ada
banyak plugin CNI , dan kami sedang mempertimbangkan contoh
konfigurasi jaringan sederhana :
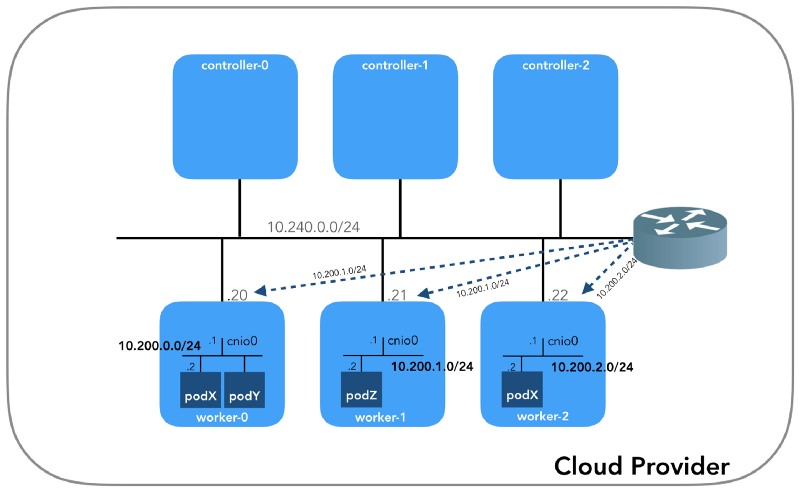
Perendaman mendalam di NAT
kubectl create -f busybox.yaml buat dua wadah
busybox identik dengan Pengontrol Replikasi:
apiVersion: v1 kind: ReplicationController metadata: name: busybox0 labels: app: busybox0 spec: replicas: 2 selector: app: busybox0 template: metadata: name: busybox0 labels: app: busybox0 spec: containers: - image: busybox command: - sleep - "3600" imagePullPolicy: IfNotPresent name: busybox restartPolicy: Always
(
busybox.yaml )
Kami mendapatkan:
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE busybox0-g6pww 1/1 Running 0 4s 10.200.1.15 worker-1 busybox0-rw89s 1/1 Running 0 4s 10.200.0.21 worker-0 ...
Ping dari satu wadah ke wadah lain harus berhasil:
$ kubectl exec -it busybox0-rw89s -- ping -c 2 10.200.1.15 PING 10.200.1.15 (10.200.1.15): 56 data bytes 64 bytes from 10.200.1.15: seq=0 ttl=62 time=0.528 ms 64 bytes from 10.200.1.15: seq=1 ttl=62 time=0.440 ms --- 10.200.1.15 ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max = 0.440/0.484/0.528 ms
Untuk memahami pergerakan lalu lintas, Anda dapat melihat paket menggunakan
tcpdump atau
conntrack :
ubuntu@worker-0:~$ sudo conntrack -L | grep 10.200.1.15 icmp 1 29 src=10.200.0.21 dst=10.200.1.15 type=8 code=0 id=1280 src=10.200.1.15 dst=10.240.0.20 type=0 code=0 id=1280 mark=0 use=1
IP sumber dari pod 10.200.0.21 diterjemahkan ke dalam alamat IP host 10.240.0.20.
ubuntu@worker-1:~$ sudo conntrack -L | grep 10.200.1.15 icmp 1 28 src=10.240.0.20 dst=10.200.1.15 type=8 code=0 id=1280 src=10.200.1.15 dst=10.240.0.20 type=0 code=0 id=1280 mark=0 use=1
Di iptables, Anda dapat melihat bahwa jumlah bertambah:
ubuntu@worker-0:~$ sudo iptables -t nat -Z POSTROUTING -L -v Chain POSTROUTING (policy ACCEPT 0 packets, 0 bytes) pkts bytes target prot opt in out source destination ... 5 324 CNI-be726a77f15ea47ff32947a3 all -- any any 10.200.0.0/24 anywhere /* name: "bridge" id: "631cab5de5565cc432a3beca0e2aece0cef9285482b11f3eb0b46c134e457854" */ Zeroing chain `POSTROUTING'
Di sisi lain, jika Anda menghapus
"ipMasq": true dari konfigurasi plugin CNI, Anda dapat melihat yang berikut ini (operasi ini dilakukan secara eksklusif untuk tujuan pendidikan - kami tidak menyarankan mengubah konfigurasi pada gugus yang berfungsi!):
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE busybox0-2btxn 1/1 Running 0 16s 10.200.0.15 worker-0 busybox0-dhpx8 1/1 Running 0 16s 10.200.1.13 worker-1 ...
Ping masih harus lulus:
$ kubectl exec -it busybox0-2btxn -- ping -c 2 10.200.1.13 PING 10.200.1.6 (10.200.1.6): 56 data bytes 64 bytes from 10.200.1.6: seq=0 ttl=62 time=0.515 ms 64 bytes from 10.200.1.6: seq=1 ttl=62 time=0.427 ms --- 10.200.1.6 ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max = 0.427/0.471/0.515 ms
Dan dalam hal ini - tanpa menggunakan NAT:
ubuntu@worker-0:~$ sudo conntrack -L | grep 10.200.1.13 icmp 1 29 src=10.200.0.15 dst=10.200.1.13 type=8 code=0 id=1792 src=10.200.1.13 dst=10.200.0.15 type=0 code=0 id=1792 mark=0 use=1
Jadi, kami memeriksa bahwa "semua wadah dapat berkomunikasi dengan wadah lain tanpa menggunakan NAT."
ubuntu@worker-1:~$ sudo conntrack -L | grep 10.200.1.13 icmp 1 27 src=10.200.0.15 dst=10.200.1.13 type=8 code=0 id=1792 src=10.200.1.13 dst=10.200.0.15 type=0 code=0 id=1792 mark=0 use=1
Jaringan Cluster (10.32.0.0/24)
Anda mungkin telah memperhatikan dalam contoh
busybox bahwa alamat IP yang ditugaskan untuk
busybox berbeda dalam setiap kasus. Bagaimana jika kita ingin membuat wadah ini tersedia untuk komunikasi dari perapian lain? Orang bisa mengambil alamat IP saat ini dari pod, tetapi mereka akan berubah. Untuk alasan ini, Anda perlu mengonfigurasi sumber daya
Service , yang akan mem-proxy permintaan ke banyak perapian yang berumur pendek.
“Layanan di Kubernetes adalah abstraksi yang mendefinisikan rangkaian logis perapian dan kebijakan yang dengannya mereka dapat diakses.” (dari dokumentasi Layanan Kubernetes )
Ada berbagai cara untuk menerbitkan layanan; tipe default adalah
ClusterIP , yang menetapkan alamat IP dari blok CIDR dari cluster (mis., hanya dapat diakses dari cluster). Salah satu contohnya adalah Add-on DNS Cluster yang dikonfigurasi di Kubernetes The Hard Way.
# ... apiVersion: v1 kind: Service metadata: name: kube-dns namespace: kube-system labels: k8s-app: kube-dns kubernetes.io/cluster-service: "true" addonmanager.kubernetes.io/mode: Reconcile kubernetes.io/name: "KubeDNS" spec: selector: k8s-app: kube-dns clusterIP: 10.32.0.10 ports: - name: dns port: 53 protocol: UDP - name: dns-tcp port: 53 protocol: TCP # ...
(
kube-dns.yaml )
kubectl menunjukkan bahwa
Service mengingat titik akhir dan menerjemahkannya:
$ kubectl -n kube-system describe services ... Selector: k8s-app=kube-dns Type: ClusterIP IP: 10.32.0.10 Port: dns 53/UDP TargetPort: 53/UDP Endpoints: 10.200.0.27:53 Port: dns-tcp 53/TCP TargetPort: 53/TCP Endpoints: 10.200.0.27:53 ...
Bagaimana tepatnya? ..
iptables lagi. Mari kita telusuri aturan yang dibuat untuk contoh ini. Daftar lengkapnya dapat dilihat dengan perintah
iptables-save .
Segera setelah paket dibuat oleh proses (
OUTPUT ) atau tiba di antarmuka jaringan (
PREROUTING ), mereka melewati rantai
iptables berikut:
-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES -A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
Target berikut ini sesuai dengan paket TCP yang dikirim ke port 53 pada 10.32.0.10, dan ditransmisikan ke penerima 10.200.0.27 dengan port 53:
-A KUBE-SERVICES -d 10.32.0.10/32 -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp cluster IP" -m tcp --dport 53 -j KUBE-SVC-ERIFXISQEP7F7OF4 -A KUBE-SVC-ERIFXISQEP7F7OF4 -m comment --comment "kube-system/kube-dns:dns-tcp" -j KUBE-SEP-32LPCMGYG6ODGN3H -A KUBE-SEP-32LPCMGYG6ODGN3H -p tcp -m comment --comment "kube-system/kube-dns:dns-tcp" -m tcp -j DNAT --to-destination 10.200.0.27:53
Hal yang sama untuk paket UDP (penerima 10.32.0.10:53 → 10.200.0.27:53):
-A KUBE-SERVICES -d 10.32.0.10/32 -p udp -m comment --comment "kube-system/kube-dns:dns cluster IP" -m udp --dport 53 -j KUBE-SVC-TCOU7JCQXEZGVUNU -A KUBE-SVC-TCOU7JCQXEZGVUNU -m comment --comment "kube-system/kube-dns:dns" -j KUBE-SEP-LRUTK6XRXU43VLIG -A KUBE-SEP-LRUTK6XRXU43VLIG -p udp -m comment --comment "kube-system/kube-dns:dns" -m udp -j DNAT --to-destination 10.200.0.27:53
Ada jenis
Services di Kubernetes. Secara khusus, Kubernetes The Hard Way
NodePort tentang
NodePort - lihat
Uji Asap: Layanan .
kubectl expose deployment nginx --port 80 --type NodePort
NodePort menerbitkan layanan pada alamat IP dari setiap node, menempatkannya di port statis (disebut
NodePort ).
NodePort dapat diakses dari luar cluster. Anda dapat memeriksa port khusus (dalam hal ini -
kubectl ) menggunakan
kubectl :
$ kubectl describe services nginx ... Type: NodePort IP: 10.32.0.53 Port: <unset> 80/TCP TargetPort: 80/TCP NodePort: <unset> 31088/TCP Endpoints: 10.200.1.18:80 ...
Di bawah sekarang tersedia dari Internet sebagai
http://${EXTERNAL_IP}:31088/ . Di sini
EXTERNAL_IP adalah alamat IP publik dari
instance yang berfungsi . Dalam contoh ini, saya menggunakan alamat IP publik
pekerja-0 . Permintaan diterima oleh host dengan alamat IP internal 10.240.0.20 (penyedia cloud terlibat dalam NAT publik), namun, layanan ini sebenarnya dimulai pada host lain (
pekerja-1 , yang dapat dilihat oleh alamat IP titik akhir - 10.200.1.18):
ubuntu@worker-0:~$ sudo conntrack -L | grep 31088 tcp 6 86397 ESTABLISHED src=173.38.XXX.XXX dst=10.240.0.20 sport=30303 dport=31088 src=10.200.1.18 dst=10.240.0.20 sport=80 dport=30303 [ASSURED] mark=0 use=1
Paket dikirim dari
pekerja-0 ke
pekerja-1 , di mana ia menemukan penerima:
ubuntu@worker-1:~$ sudo conntrack -L | grep 80 tcp 6 86392 ESTABLISHED src=10.240.0.20 dst=10.200.1.18 sport=14802 dport=80 src=10.200.1.18 dst=10.240.0.20 sport=80 dport=14802 [ASSURED] mark=0 use=1
Apakah sirkuit seperti itu ideal? Mungkin tidak, tetapi berhasil. Dalam hal ini, aturan
iptables diprogram adalah sebagai berikut:
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/nginx:" -m tcp --dport 31088 -j KUBE-SVC-4N57TFCL4MD7ZTDA -A KUBE-SVC-4N57TFCL4MD7ZTDA -m comment --comment "default/nginx:" -j KUBE-SEP-UGTFMET44DQG7H7H -A KUBE-SEP-UGTFMET44DQG7H7H -p tcp -m comment --comment "default/nginx:" -m tcp -j DNAT --to-destination 10.200.1.18:80
Dengan kata lain, alamat untuk penerima paket dengan port 31088 disiarkan pada 10.200.1.18. Port ini juga siaran, dari 31088 hingga 80.
Kami tidak menyentuh jenis layanan lain -
LoadBalancer - yang membuat layanan tersedia untuk umum menggunakan penyeimbang beban penyedia cloud, tetapi artikel tersebut ternyata berukuran besar.
Kesimpulan
Tampaknya ada banyak informasi, tetapi kami hanya menyentuh ujung gunung es. Di masa depan saya akan berbicara tentang IPv6, IPVS, eBPF dan beberapa plugin CNI saat ini yang menarik.
PS dari penerjemah
Baca juga di blog kami: