
Hari ini, akhirnya, program utama konferensi telah dimulai. Tingkat penerimaan tahun ini hanya 8%, mis. harus menjadi yang terbaik dari yang terbaik dari yang terbaik. Terapan dan aliran penelitian dipisahkan dengan jelas, ditambah ada beberapa kegiatan terkait yang terpisah. Aliran terapan terlihat lebih menarik, ada laporan terutama dari jurusan (Google, Amazon, Alibaba, dll.). Saya akan memberi tahu Anda tentang pertunjukan yang berhasil saya hadiri.
Data untuk selamanya
Hari dimulai dengan presentasi yang cukup panjang sehingga data harus bermanfaat dan digunakan untuk kebaikan. Seorang
profesor di Universitas California
berbicara (perlu dicatat bahwa ada banyak wanita di KDD, baik di kalangan mahasiswa maupun di antara pembicara). Semua ini dinyatakan dalam FATES singkatan:
- Keadilan - tidak ada bias dalam perkiraan model, semuanya netral gender dan toleran.
- Acountability - harus ada seseorang atau sesuatu yang bertanggung jawab atas keputusan yang dibuat oleh mesin.
- Transparansi - transparansi dan keterjelasan keputusan.
- Etika - ketika bekerja dengan data, penekanan khusus harus pada etika dan privasi.
- Keselamatan dan keamanan - sistem harus aman (tidak berbahaya) dan dilindungi (tahan terhadap pengaruh manipulatif dari luar)
Manifesto ini, sayangnya, lebih mengekspresikan keinginan dan berkorelasi lemah dengan kenyataan. Model akan benar secara politis hanya jika semua tanda dihapus darinya; tanggung jawab untuk mentransfer ke seseorang yang spesifik selalu sangat sulit; semakin jauh DS berkembang, semakin sulit untuk menafsirkan apa yang terjadi di dalam model; pada etika dan privasi, ada beberapa contoh bagus pada hari pertama, tetapi sebaliknya, data sering diperlakukan dengan cukup bebas.
Ya, kita tidak bisa tidak mengakui bahwa model-model modern sering kali tidak aman (autopilot dapat membuang mobil dengan sopir) dan tidak terlindungi (Anda dapat mengambil contoh yang merusak pekerjaan jaringan saraf tanpa mengetahui bagaimana jaringan bekerja). Sebuah karya terbaru yang menarik oleh
DeepExplore : sistem untuk mencari kerentanan di jaringan saraf menghasilkan, antara lain, gambar yang membuat autopilot mengarahkan dengan cara yang salah.

Berikut ini adalah definisi lain dari Ilmu Data sebagai "DS adalah studi penggalian data formulir nilai". Secara prinsip, cukup bagus. Pada awal pidato, pembicara secara khusus menyebutkan bahwa DS sering melihat data hanya dari saat analisis, sementara siklus hidup penuh jauh lebih luas, dan ini, antara lain, tercermin dalam definisi.
Nah, ada beberapa contoh pekerjaan laboratorium.
Sekali lagi kita akan menganalisis tugas menilai pengaruh banyak faktor pada hasil, tetapi tidak dari posisi iklan, tetapi secara umum. Ada
artikel yang belum diterbitkan. Pertimbangkan, misalnya, pertanyaan aktor mana yang akan dipilih untuk film agar dapat mengumpulkan box office yang baik. Kami menganalisis daftar akting dari film terlaris tertinggi dan mencoba memprediksi kontribusi masing-masing aktor. Tapi! Ada yang disebut
perancu yang mempengaruhi seberapa efektif seorang aktor (misalnya, Stallone akan berjalan dengan baik dalam film thrash action, tetapi tidak dalam komedi romantis). Untuk memilih yang tepat, Anda perlu menemukan semua perancu dan mengevaluasinya, tetapi kami tidak akan pernah yakin bahwa kami telah menemukan semua orang. Sebenarnya, artikel ini mengusulkan pendekatan baru - deconfounder. Alih-alih menyoroti perancu, kami secara eksplisit memperkenalkan variabel laten dan mengevaluasinya dalam mode tanpa pengawasan, dan kemudian kami mempelajari model berdasarkan pada mereka. Semuanya kedengarannya cukup aneh, karena sepertinya varian sederhana dari embeddings, apa yang baru tidak jelas.
Beberapa gambar indah diperlihatkan, contoh-contoh bagaimana di universitas AI mereka, dll. Bergerak maju.
E-commerce dan Profiling
Pergi ke bagian aplikasi pada perdagangan. Pada awalnya ada beberapa laporan yang sangat menarik, pada akhirnya ada sejumlah bubur, tetapi yang pertama adalah yang pertama.
Pemodelan Pengguna Baru dan prediksi Churn
Pekerjaan menarik Snapchat dalam memprediksi arus keluar. Orang-orang menggunakan ide, yang kami juga berhasil berlari sekitar 4 tahun yang lalu: sebelum memprediksi arus keluar, pengguna perlu dibagi menjadi beberapa kelompok sesuai dengan jenis perilaku. Pada saat yang sama, ruang vektor berdasarkan jenis tindakan mereka ternyata sangat buruk, hanya dari beberapa jenis interaksi (kami, pada waktunya, harus membuat pilihan tanda untuk bergerak dari tiga ratus menjadi satu setengah), tetapi mereka memperkaya ruang dengan statistik tambahan dan menganggapnya sebagai rangkaian waktu , sebagai hasilnya, klaster diperoleh bukan tentang apa yang dilakukan pengguna, tetapi tentang
seberapa sering mereka melakukannya.
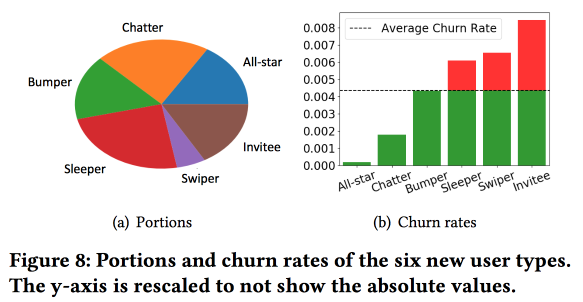
Pengamatan penting: jaringan memiliki "inti" dari pengguna yang paling terhubung dan aktif dengan ukuran 1,7 juta orang. Pada saat yang sama, perilaku dan retensi pengguna sangat bergantung pada apakah ia dapat berkomunikasi dengan seseorang dari "inti".
Lalu kami mulai membangun model. Mari kita ambil pendatang baru dalam dua minggu (511 ribu), fitur sederhana dan ego-networking (ukuran dan kepadatan), dan lihat apakah mereka terkait dengan "inti", dll. Kami memberi makan perilaku pengguna dengan LSTM dan mendapatkan akurasi perkiraan arus keluar sedikit lebih tinggi dari logreg (sebesar 7-8%). Tapi kemudian kesenangan dimulai. Untuk mempertimbangkan spesifikasi masing-masing kelompok, kami akan melatih beberapa LSTM secara paralel, dan kami akan melampirkan lapisan perhatian di atas. Akibatnya, skema semacam itu mulai bekerja baik pada pengelompokan (mana dari LSTM yang mendapat perhatian) dan pada perkiraan arus keluar. Ini memberi peningkatan + 5-7% lagi dalam kualitas, dan logreg sudah terlihat pucat. Tapi! Sebenarnya, akan lebih adil untuk membandingkannya dengan logreg tersegmentasi yang dilatih secara terpisah untuk cluster (yang dapat diperoleh dengan cara yang lebih sederhana).
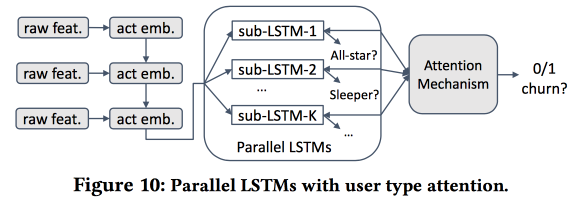
Saya bertanya tentang interpretabilitas: setelah semua, arus keluar sering diprediksi bukan untuk mendapatkan perkiraan, tetapi untuk memahami faktor apa yang mempengaruhinya. Pembicara jelas siap untuk pertanyaan ini: untuk ini, kluster khusus digunakan dan dianalisis, daripada yang di mana perkiraan aliran lebih tinggi dibedakan dari yang lain.
Representasi pengguna universal
Orang-orang Alibaba
berbicara tentang cara membangun asosiasi pengguna. Ternyata memiliki banyak pengiriman pengguna adalah buruk: banyak yang tidak diselesaikan, kekuatan terbuang sia-sia. Mereka berhasil membuat presentasi universal dan menunjukkan bahwa itu berfungsi lebih baik. Secara alami pada jaringan saraf. Arsitekturnya cukup standar, sudah dalam satu bentuk atau yang lain telah berulang kali dijelaskan di konferensi. Fakta dari perilaku pengguna dimasukkan ke dalam input, kami membangun di atasnya, memberikan semuanya kepada LSTM, menggantung lapisan perhatian di atas, dan di sebelahnya ada kisi tambahan untuk fitur statis, dimahkotai dengan multitask (sebenarnya, beberapa kisi kecil untuk tugas tertentu) . Kami melatih semua ini bersama-sama, output dengan perhatian adalah embedding pengguna.
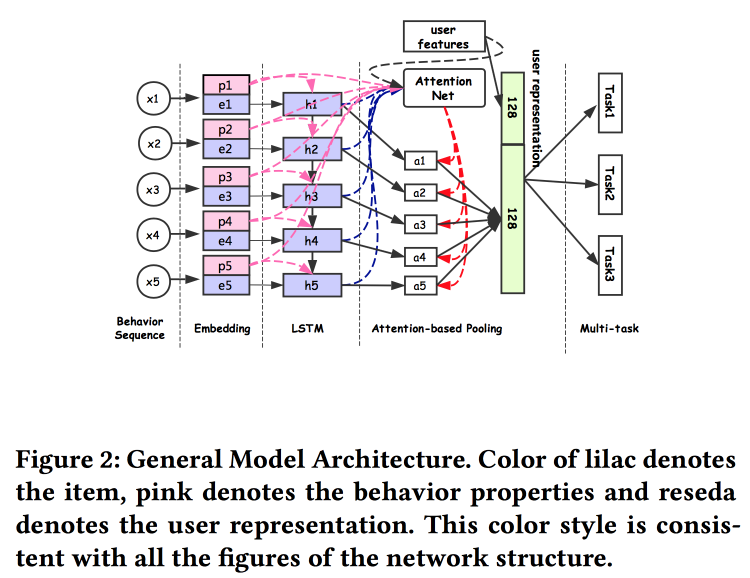
Ada beberapa tambahan yang lebih kompleks: selain perhatian sederhana, mereka menambahkan jaring perhatian "mendalam", dan juga menggunakan versi LSTM yang dimodifikasi - properti yang terjaga keamanannya LSTM
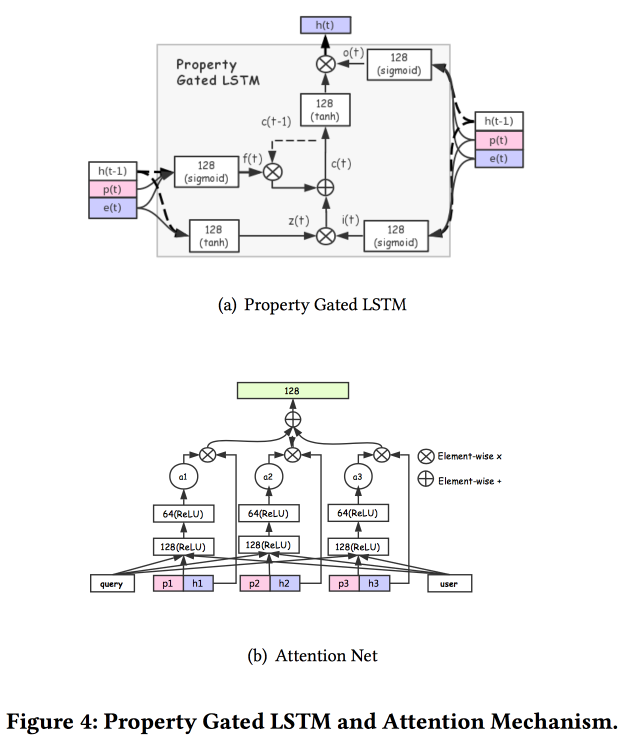
Tugas di mana semua ini dijalankan: prediksi RKPT, prediksi preferensi harga, pembelajaran menentukan peringkat, prediksi mode mengikuti, prediksi preferensi toko. Dataset selama 10 hari termasuk 6 * 10
9 contoh untuk pelatihan.
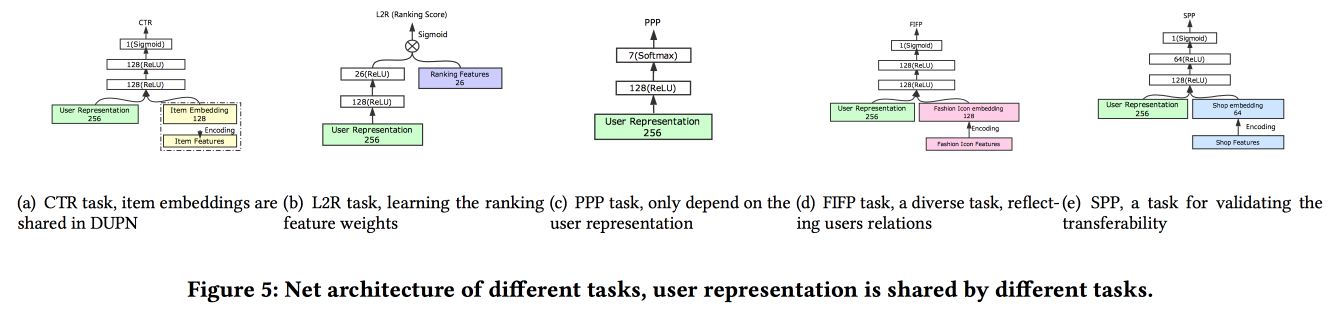
Lalu ada orang yang tidak terduga: mereka melatih semua ini di TensorFlow, pada kluster CPU yang terdiri dari 2000 mesin dengan masing-masing 15 core, dibutuhkan 4 hari untuk menyelesaikan data selama 10 hari. Oleh karena itu, mereka terus berlatih ulang hari demi hari (10 jam di kluster ini). Tentang GPU / FPGA tidak punya waktu untuk bertanya :(. Menambahkan tugas baru dilakukan baik melalui pelatihan ulang secara keseluruhan, atau melalui pelatihan ulang grid dangkal (fine tuning netwrok). Dalam runtime untuk inferensi, mereka menyimpan representasi (output dengan perhatian untuk pengguna tertentu) dan hanya kepala grid yang dihitung untuk tugas-tugas khusus Tes A / B menunjukkan peningkatan 2-3% untuk berbagai indikator.
Prediksi pengembalian produk E-tail
Mereka memprediksi pengembalian barang oleh pengguna setelah pembelian,
karya disajikan oleh IBM. Sayangnya, sejauh ini tidak ada teks dalam akses terbuka. Mengembalikan barang adalah masalah serius senilai $ 200 miliar setahun. Untuk membangun perkiraan pengembalian, ia menggunakan model hypergraph yang menghubungkan produk dan keranjang, menggunakan keranjang ini mereka mencoba menemukan yang terdekat dengan hypergraph, setelah itu mereka memperkirakan probabilitas pengembalian. Untuk mencegah pengembalian, toko online memiliki banyak kemungkinan, misalnya, menawarkan diskon untuk mengeluarkan produk tertentu dari keranjang.
Kami segera mencatat bahwa ada perbedaan yang signifikan antara keranjang dengan duplikat (misalnya, dua t-shirt identik dengan ukuran yang berbeda) dan tanpa, oleh karena itu, kami harus segera membangun model yang berbeda untuk kedua kasus ini.
Algoritma umum disebut HyperGo:
- Kami sedang membangun hypergraph untuk mewakili pembelian dan pengembalian dengan informasi dari pengguna, produk, keranjang.
- Selanjutnya, kami menggunakan potongan grafik lokal berdasarkan random walk untuk mendapatkan informasi lokal untuk perkiraan.
- Kami secara terpisah mempertimbangkan keranjang dengan take dan tanpa take.
- Kami menggunakan metode Bayesian untuk menilai dampak dari masing-masing produk dalam keranjang.
Bandingkan kualitas perkiraan pengembalian dengan KNN untuk keranjang, ditimbang menurut Jacquard KNN, penjatahan dengan jumlah duplikat, kami memperoleh peningkatan hasilnya. Tautan ke GitHub berkedip di slide, tetapi mereka tidak dapat menemukan sumbernya, dan tidak ada tautan di artikel tersebut.
OpenTag: Buka Ekstraksi Nilai Atribut dari Profil Produk
Pekerjaan yang cukup menarik dari Amazon. Tantangan: menambang berbagai fakta untuk Alexa untuk menjawab pertanyaan dengan lebih baik. Mereka mengatakan betapa rumitnya segalanya, sistem lama tidak tahu cara bekerja dengan kata-kata baru, sering membutuhkan sejumlah besar aturan tulisan tangan dan heuristik, hasilnya begitu-begitu. Tentu saja, jaringan saraf dengan arsitektur embednig-LSTM yang sudah dikenal akan membantu menyelesaikan semua masalah, tetapi kami akan membuat LSTM berlipat ganda, dan kami juga akan menggulirkan
Bidang Acak Bersyarat di bagian atas.

Kami akan memecahkan masalah penandaan urutan kata-kata. Tag akan menunjukkan di mana kita memulai dan mengakhiri urutan atribut tertentu (misalnya, rasa dan komposisi makanan anjing), dan LSTM akan mencoba untuk memprediksi mereka. Sebagai roti dan curtsy menuju Mechanical Turk, pelatihan model aktif digunakan. Untuk memilih contoh yang perlu dikirim untuk markup lebih lanjut, gunakan heuristik "untuk mengambil contoh di mana tag paling sering bertukar antar era".
Mempelajari dan Mentransfer Representasi ID dalam E-commerce
Dalam
pekerjaan mereka
, kolega dari Alibaba kembali kembali ke masalah membangun embeddings, kali ini melihat tidak hanya pada pengguna, tetapi pada ID pada prinsipnya: untuk produk, merek, kategori, pengguna, dll. Sesi interaksi digunakan sebagai sumber data, dan atribut tambahan juga diperhitungkan. Skipgram digunakan sebagai algoritma utama.
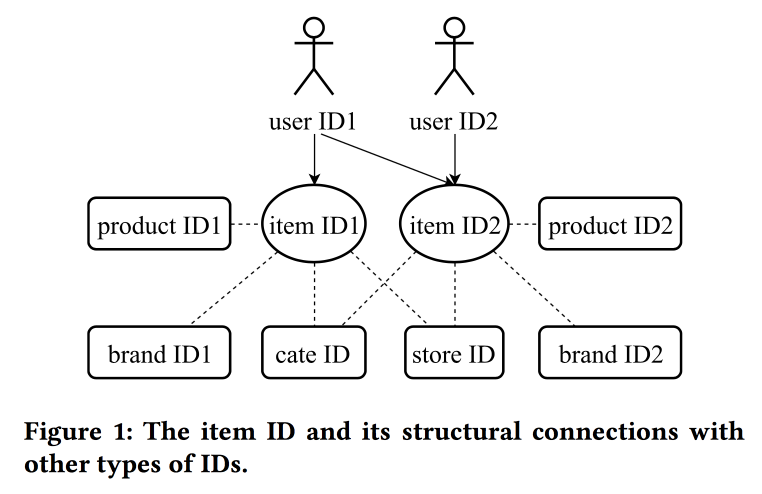
Pembicara memiliki pengucapan yang sangat berat dengan aksen Cina yang kuat, untuk memahami apa yang terjadi hampir tidak mungkin. Salah satu "trik" dari pekerjaan adalah mekanisme mentransfer representasi dengan informasi yang kurang, misalnya, dari item ke pengguna melalui rata-rata (dengan cepat, Anda tidak perlu mempelajari keseluruhan model). Dari item lama, Anda dapat menginisialisasi yang baru (tampaknya berdasarkan kesamaan konten), serta mentransfer tampilan pengguna dari satu domain (elektronik) ke domain lain (pakaian).
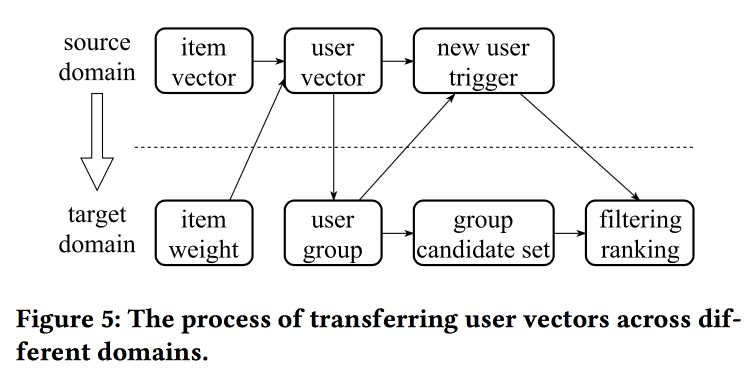
Secara keseluruhan, tidak sepenuhnya jelas di mana kebaruan di sini, rupanya, detail perlu digali; selain itu, tidak jelas bagaimana ini membandingkan dengan cerita sebelumnya tentang representasi pengguna yang disatukan.
Seleksi Parameter Online untuk Masalah Peringkat Berbasis Web
Pekerjaan yang sangat menarik dari teman-teman di LinkedIn. Inti dari pekerjaan ini adalah untuk memilih parameter optimal dari operasi algoritma online, dengan mempertimbangkan beberapa tujuan yang bersaing. Sebagai ruang lingkup, pertimbangkan rekaman itu dan cobalah untuk menambah jumlah sesi dari jenis-jenis tertentu:
- Sesi dengan aksi virus (VA).
- Resume Submission Session (JA).
- Interaksi Konten dalam sesi Umpan (EFS).
Fungsi peringkat dalam algoritma adalah rata-rata tertimbang dari perkiraan konversi untuk ketiga tujuan ini. Sebenarnya, bobot adalah parameter yang akan kami coba optimalkan secara online. Awalnya, mereka merumuskan tugas bisnis sebagai "memaksimalkan jumlah sesi virus sambil mempertahankan dua jenis lainnya setidaknya pada tingkat tertentu", tetapi kemudian mereka mengubahnya sedikit untuk kemudahan optimasi.
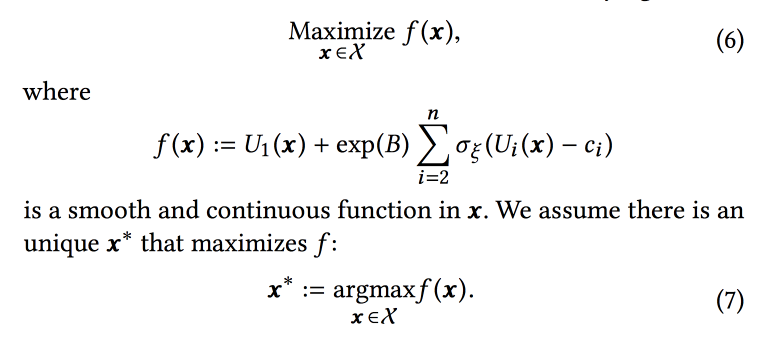
Kami mensimulasikan data dengan satu set distribusi binomial (pengguna akan mengkonversi ke tujuan yang diinginkan atau tidak, setelah melihat rekaman dengan parameter tertentu), di mana probabilitas keberhasilan dengan parameter yang diberikan adalah
proses Gaussian (sendiri untuk setiap jenis konversi). Selanjutnya, kami menggunakan
sampler Thompson dengan bandit "tak terhingga
kasar " untuk memilih parameter optimal (tidak online, tetapi offline pada data historis, jadi untuk waktu yang lama). Mereka memberikan beberapa tips: gunakan titik tebal untuk membangun grid awal dan pastikan untuk menambahkan sampel
epsilon-serakah (dengan kemungkinan epsilon mencoba titik acak di luar angkasa), jika tidak, Anda dapat mengabaikan global maksimum.
Mereka mensimulasikan pengambilan sampel secara offline satu jam sekali (Anda perlu banyak sampel), hasilnya adalah distribusi parameter optimal tertentu. Lebih lanjut, ketika seorang pengguna masuk dari distribusi ini, mereka mengambil parameter khusus untuk membangun rekaman (penting untuk melakukan ini secara konsisten dengan seed dari ID pengguna untuk inisialisasi sehingga rekaman pengguna tidak berubah secara radikal).
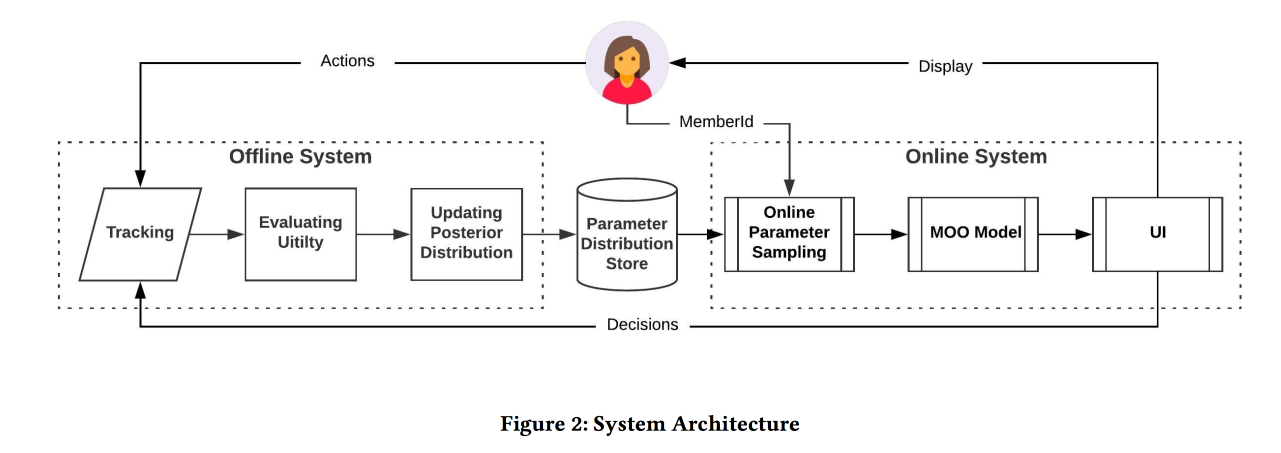
Menurut hasil percobaan A / B, mereka menerima peningkatan pengiriman resume sebesar 12% dan suka oleh 3%. Bagikan beberapa pengamatan:
- Lebih mudah mengambil sampel lebih banyak daripada mencoba menambahkan lebih banyak informasi ke model (misalnya, hari dalam seminggu / jam).
- Kami menganggap independensi tujuan dalam pendekatan ini, tetapi tidak jelas apakah itu (lebih tepatnya, tidak). Namun, pendekatan tersebut berhasil.
- Bisnis harus menetapkan sasaran dan ambang batas.
- Penting untuk mengeluarkan seseorang dari proses dan membiarkannya melakukan sesuatu yang bermanfaat.
Pemberitahuan Realisasi Berbasis Aktivitas Dekat Dekat Waktu
Karya lain dari LinkedIn, kali ini tentang mengelola notifikasi. Kami memiliki orang, acara, saluran pengiriman, dan tujuan jangka panjang untuk meningkatkan keterlibatan pengguna tanpa negatif signifikan dalam bentuk keluhan dan berhenti berlangganan dari dorongan. Tugas ini penting dan sulit, dan Anda harus melakukan segalanya dengan benar: kepada orang yang tepat pada waktu yang tepat untuk mengirim konten yang tepat di saluran yang tepat dan dalam jumlah yang tepat.
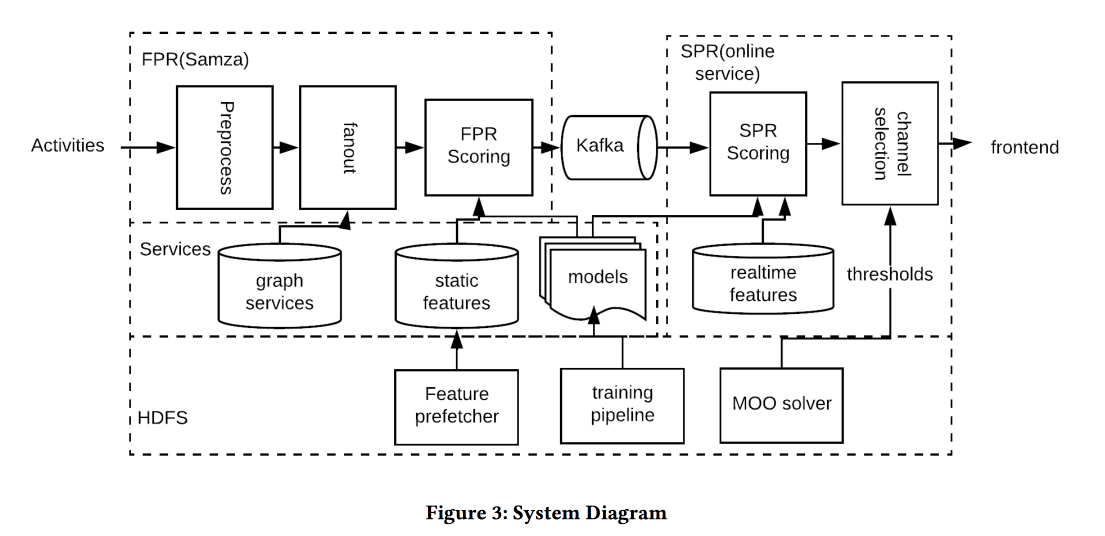
Arsitektur sistem pada gambar di atas, inti dari apa yang terjadi kira-kira sebagai berikut:
- Kami memfilter setiap spam pada input.
- Orang yang tepat: helm untuk semua orang yang sangat terhubung dengan penulis / konten, menyeimbangkan ambang pada kekuatan komunikasi, mengelola cakupan dan relevansi.
- Waktu yang tepat: segera kirim konten, yang waktunya penting (acara teman), sisanya dapat disimpan untuk saluran yang kurang dinamis.
- Konten yang tepat: gunakan logreg! Model perkiraan klik pada tumpukan tanda dibangun, secara terpisah untuk kasus ketika seseorang ada dalam aplikasi dan ketika tidak.
- Saluran yang benar: kami menetapkan ambang batas yang berbeda untuk relevansi, yang paling ketat untuk mendorong, lebih rendah - jika pengguna sekarang ada dalam aplikasi, bahkan lebih rendah - untuk surat (ini berisi semua jenis intisari / iklan).
- Volume yang benar: model sunat berdasarkan volume ada di keluaran, juga terlihat relevan, direkomendasikan untuk melakukannya secara individual (heuristik ambang batas yang baik adalah skor minimum objek yang dikirim selama beberapa hari terakhir)
Pada tes A / B menerima peningkatan beberapa persen dalam jumlah sesi.
Personalisasi Real-time menggunakan Embeddings for Search Ranking di Airbnb
Dan itu adalah
kertas aplikasi terbaik dari AirBnB. Tujuan: untuk mengoptimalkan penerbitan penempatan dan hasil pencarian yang serupa. Kami memutuskan melalui konstruksi embedding penempatan dan pengguna dalam satu ruang untuk mengevaluasi lebih lanjut kesamaannya. Penting untuk diingat bahwa ada riwayat jangka panjang (preferensi pengguna) dan jangka pendek (tujuan pengguna / sesi saat ini).
Tanpa basa-basi lagi, kami menggunakan untuk membangun penempatan word2vec pada urutan klik dalam sesi pencarian (satu sesi - satu dokumen). Tapi kami masih melakukan beberapa modifikasi (lagipula KDD):
- Kami mengambil sesi di mana ada reservasi.
- Apa yang akhirnya dilindungi undang-undang, kami pegang sebagai konteks global untuk semua elemen sesi selama pembaruan w2v.
- Negatif dalam pelatihan disampel di kota yang sama.

Efektivitas model semacam itu diperiksa dalam tiga cara standar:
- Periksa offline: seberapa cepat kita dapat menaikkan hotel yang tepat di sesi pencarian.
- Pengujian oleh penilai: membuat alat khusus untuk memvisualisasikan yang serupa.
- Tes A / B: spoiler, CTR telah tumbuh secara signifikan, pemesanan belum meningkat, tetapi sekarang terjadi lebih awal
Kami mencoba untuk menentukan peringkat hasil pencarian tidak hanya sebelumnya, tetapi juga untuk mengatur ulang (karena itu real-time) setelah menerima tanggapan - klik pada satu kalimat dan abaikan yang lain. Pendekatannya adalah mengumpulkan tempat-tempat yang diklik dan diabaikan dalam dua kelompok, menemukan penanaman di setiap centroid (ada rumus khusus), dan kemudian di peringkat kita menaikkan seperti klik, lebih rendah seperti melompat seperti.
Tes A / B menerima peningkatan pemesanan, pendekatan bertahan dalam ujian waktu: itu ditemukan satu setengah tahun yang lalu dan masih berputar dalam produksi.
Dan jika Anda perlu mencari di kota lain? Anda tidak akan dapat memprioritaskan dengan klik, tidak ada informasi tentang sikap pengguna terhadap tempat di penyelesaian ini. Untuk menghindari masalah ini, kami memperkenalkan "embeddings konten". Pertama, kita akan membuat ruang tanda tanda sederhana (murah / mahal, di pusat / di pinggiran, dll) dengan ukuran sekitar 500 ribu jenis (untuk tempat dan orang). Selanjutnya, kami membuat hiasan berdasarkan jenis. Ketika belajar jangan lupa untuk menambahkan negatif yang jelas pada penolakan (ketika pemilik tempat belum mengkonfirmasi reservasi).
Grafik Jaringan Syaraf Konvolusional untuk Sistem Rekomendasi Web-Scale
Bekerja dari Pinterest berdasarkan rekomendasi pin. Kami mempertimbangkan pin pengguna grafik bipartit dan menambahkan fitur jaringan ke rekomendasi. Grafiknya sangat besar - 3 miliar pin, 16 miliar interaksi, sematan grafik klasik tidak dapat dibuat. ,
GraphSAGE , ( , message passing),
PinSAGE . , , .
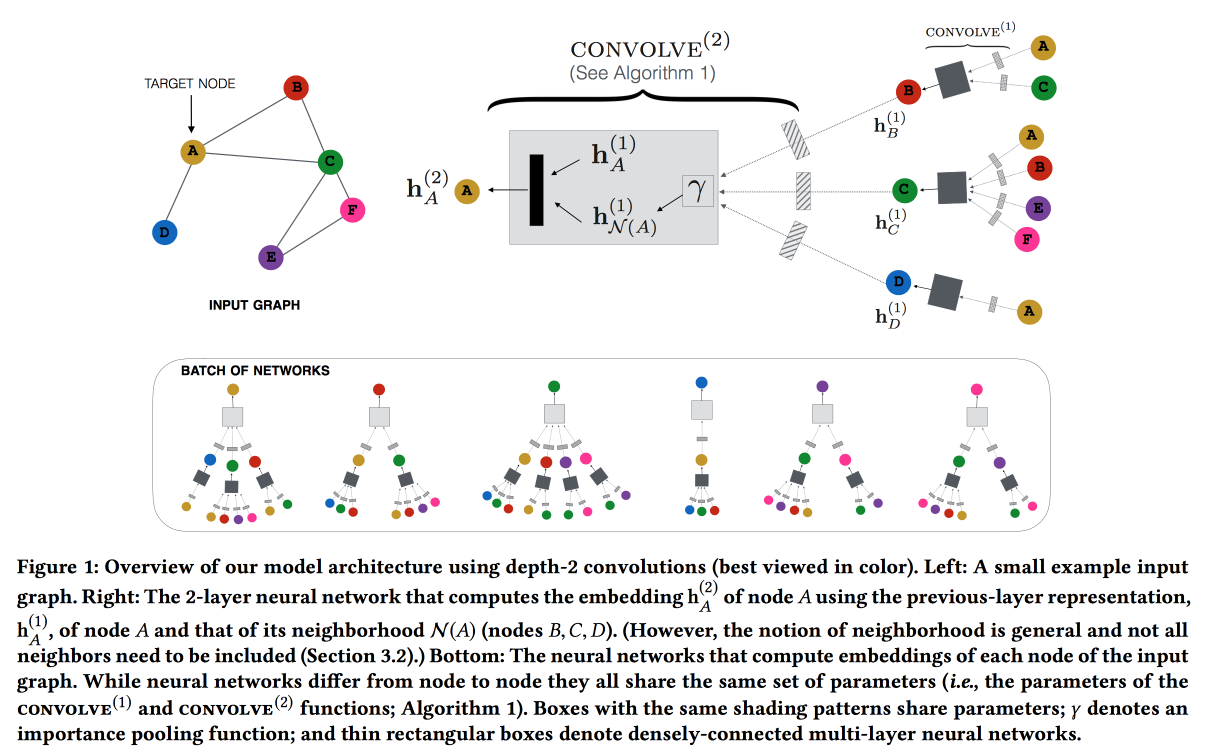
« »:
- max margin loss.
- CPU/GPU: CPU ( GPU ) GPU. , .
- , random walk-.
- Curriculum Learning: hard negative-. .
- Map reduce, .
, , . , /-.
Q&R: A Two-Stage Approach Toward Interactive Recommendation
« , , ?» — YouTube
. : « ?». «» (, , YouTube , ).
YouTube Video-RNN, ID . , ID , (post fusion). (- -
GRU , LSTM LSTM).

7 , 8-, . , 8 % , --. /-
interleaving- +0,7 % , +1,23 % .
: 18 % , +4 % .
Graph and social nets
, , , .
Graph Classification using Structural Attention
, « ». , , .
, , .
, LSTM , attention-, , . . , , , .
: , , . attention, , LSTM self-attention, ( ). «», , .
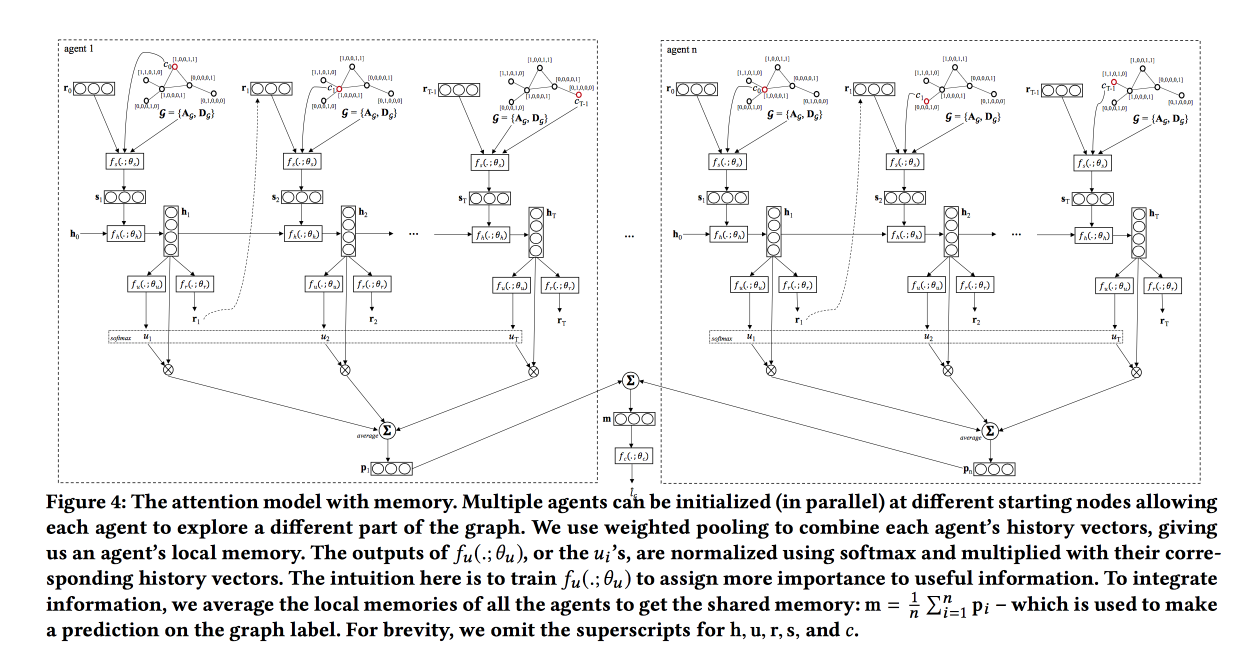
, baseline — . ,
TreeLSTM .
SpotLight: Detecting Anomalies in Streaming Graphs
, , -, , . « ». , , .
«» . - - , .
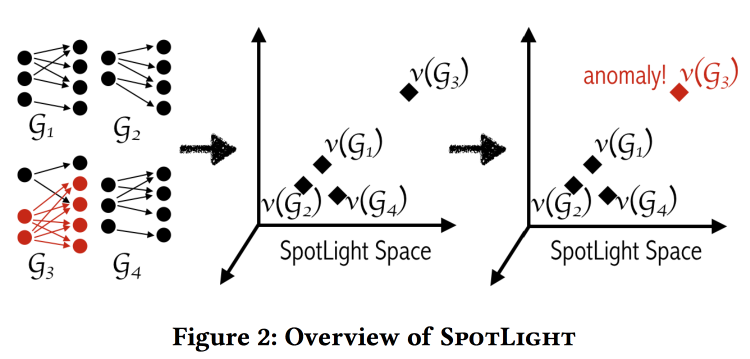
: , . . . , / .
, .
labeled DARPA dataset . , baseline- (.. ).
Adversarial Attacks on Graph Networks
. Adversary , , ..: / . , — ( — )? .
, :
- «» .
- «» .
- «» .
- , (poisoning).
. , , , — . . .
, unnoticeability: , ?
Multi-Round Influence maximization
. , , .
, ( , ).
-- :
- : , .
- : , .
- - : inffluencer- . , .
Reverse-Reachable sets: inffluencer-, , .
EvoGraph: An Effective and Efficient Graph Upscaling Method for Preserving Graph Properties
. ,
, .
, , power law. , , «» , : «» .

, , .
.
data science . Sebenarnya. , . .
All models are wrong, but some are useful — data science, , , . «» ( , , adversarial ..)
www.embo.org/news/articles/2015/the-numbers-speak-for-themselves — (overfitting, selection bias, , ..)
1762
The Equitable Life Assurance Society , .
Sekarang perusahaan asuransi mengalami kesulitan: pada tahun 2011 diskriminasi jenis kelamin akhirnya dilarang, sekarang gender tidak dapat diperhitungkan dalam asuransi (yang sangat sulit - bahkan jika Anda secara eksplisit menyembunyikan fitur "gender", model ini cenderung memperkirakannya karena alasan lain). Ini menyebabkan efek yang menarik di Inggris:- Wanita mengemudi lebih akurat dan kecil kemungkinannya untuk mengalami kecelakaan, sehingga asuransi lebih murah bagi mereka.
- Setelah naik level, biaya asuransi untuk wanita naik, dan untuk pria turun.
- Pasar bekerja: akibatnya, ada lebih banyak pria dan wanita di jalan.
- Karena "akurasi" rata-rata pengemudi di jalan menurun, ada lebih banyak kecelakaan.
- Setelah itu, asuransi, tentu saja, mulai naik harga.
- Asuransi perjalanan mulai mencuci pengemudi yang rapi dengan lebih keras.
Akibatnya, mereka mendapat "spiral kematian".
Tema ini menggemakan kinerja pembukaan hari itu. F - Keadilan, ini adalah beberapa puri awan yang tidak dapat dijangkau. Model ML belajar memisahkan contoh (termasuk orang) dalam ruang atribut, oleh karena itu mereka tidak bisa "adil" menurut definisi.