
Pada 18-19 Agustus, Tele2 menyelenggarakan Hackathon Ilmu Data. Hackathon ini berfokus pada analisis dialog dukungan teknis di jejaring sosial, mempercepat dan menyederhanakan interaksi pelanggan.
Tugas tidak memiliki metrik khusus yang perlu dioptimalkan, tugas itu bisa diciptakan untuk Anda sendiri. Yang utama adalah meningkatkan layanan. Juri kompetisi adalah direktur dari berbagai bidang Tele2, serta komunitas grandmaster Kaggle yang terkenal di bidang Ilmu Data Pavel Pleskov.
Di bawah potongan, kisah tim yang menempati posisi pertama.
Ketika seorang rekan mengundang saya untuk berpartisipasi dalam hackathon ini, saya setuju dengan cepat.
Saya tertarik pada topik NLP, dan juga ada beberapa perkembangan jaringan saraf yang ingin saya uji dalam praktik.
Penyelenggara Hackathon mengirim fragmen kecil data terlebih dahulu yang memberikan gambaran tentang data seperti apa yang akan tersedia di acara tersebut.
Data ternyata agak kotor, troll asing masuk ke dialog, tidak selalu jelas apa jenis pertanyaan yang dijawab operator.
Menjadi jelas bahwa tidak akan mudah untuk mengimplementasikan ide dalam 24 jam yang dialokasikan, jadi saya mengambil 1 hari libur dari pekerjaan dan menghabiskannya untuk mempersiapkan jaringan saraf yang ingin saya coba. Ini memungkinkan kami untuk tidak membuang waktu hackathon mencari bug, tetapi untuk fokus pada aplikasi dan kasus bisnis.
Kantor Tele2 terletak di wilayah Moskow Baru di taman bisnis Rumyantsevo. Bagi saya, pergi ke sana untuk beberapa waktu, tetapi taman bisnis membuat kesan yang baik (dengan pengecualian kabel listrik).
 Saluran listrik dengan latar belakang pusat bisnis
Saluran listrik dengan latar belakang pusat bisnisTepat di stasiun metro, panitia menemui kami, menunjukkan kepada kami bagaimana menuju ke kantor. Bangunan pusat bisnis itu sendiri ditempati oleh banyak perusahaan, kantor Tele2 terletak di lantai 5. Peserta Hackathon ditugaskan area khusus di dalam kantor, ada dapur, area relaksasi dengan PlayStation dan sandaran. Terutama senang dengan kecepatan wi-fi, tidak ada masalah yang melekat dalam peristiwa massa yang diamati.
 Sarapan
SarapanDataset nyata yang disediakan oleh Tele2 terdiri dari 3 file CSV besar dengan dialog dukungan teknis: dialog di jejaring sosial, telegram dan email. Secara total, lebih dari 4 juta hit adalah apa yang Anda butuhkan untuk melatih jaringan saraf.
Apa itu jaringan saraf?
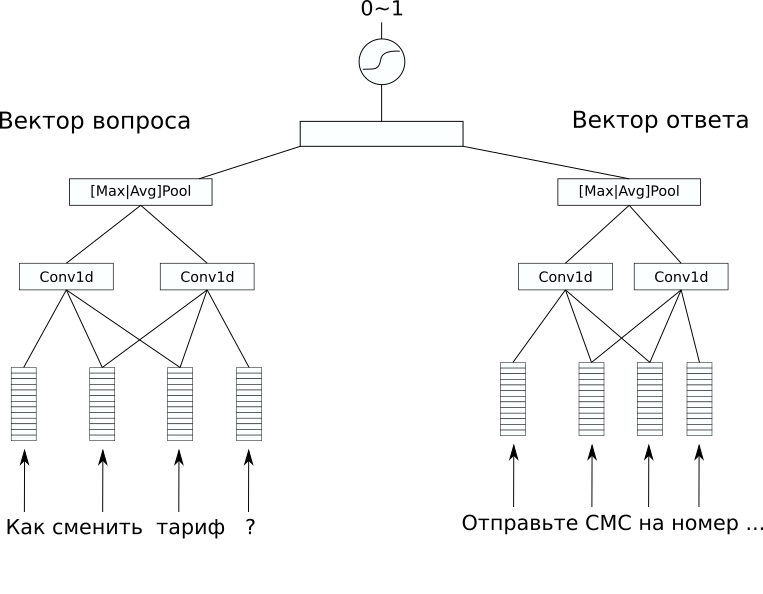 Arsitektur jaringan
Arsitektur jaringanDalam dataset tidak ada markup tambahan yang akan menarik untuk diprediksi, tapi saya ingin menyelesaikan masalah yang diawasi. Oleh karena itu, kami memutuskan untuk mencoba memprediksi jawaban atas pertanyaan, jadi setidaknya bot obrolan sederhana dari model seperti itu dapat dibuat. Untuk ini, kami memilih arsitektur CDSSM (Convolution Deep Semantic Similarity Model). Ini adalah salah satu model jaringan saraf sederhana untuk membandingkan teks dengan makna, yang pada awalnya diusulkan oleh Microsoft untuk menentukan peringkat hasil pencarian Bing.
Esensinya adalah sebagai berikut: pertama, setiap teks dikonversi menjadi vektor menggunakan urutan lapisan konvolusi dan penyatuan.
Kemudian vektor yang dihasilkan dibandingkan dalam beberapa cara. Dalam masalah kami, lapisan linier tambahan yang menggabungkan kedua vektor dengan sigmoid sebagai fungsi aktivasi memberikan hasil yang baik. Bobot kalimat pengodean jaringan ke dalam vektor bisa sama untuk sepasang teks (jaringan semacam itu disebut siam), dan bisa berbeda.
Dalam kasus kami, varian dengan bobot yang berbeda memberikan hasil terbaik, karena teks pertanyaan dan jawaban sangat berbeda.
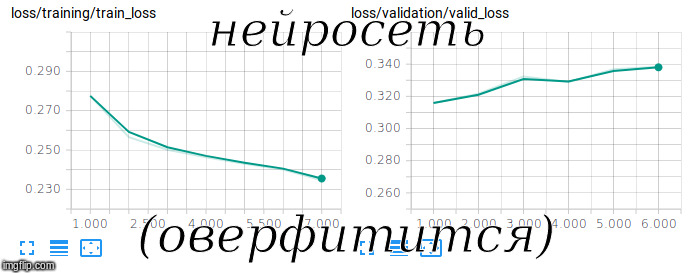 Mencoba melatih jaringan Siam
Mencoba melatih jaringan SiamFastText dengan RusVectōr digunakan sebagai
embeddings pra-pelatihan, ini tahan terhadap kesalahan ketik, yang sering ditemukan dalam pertanyaan pengguna.
Untuk melatih model seperti itu, perlu dilatih tidak hanya pada contoh positif, tetapi juga pada contoh negatif. Untuk melakukan ini, kami menambahkan pasangan pertanyaan dan jawaban acak dalam rasio 1 banding 10 ke set pelatihan.
Untuk mengevaluasi kualitas pada sampel yang tidak seimbang tersebut, metrik ROC-AUC digunakan. Setelah 3 jam pelatihan tentang GPU, kami berhasil mencapai nilai 0,92 dalam metrik ini.
Menggunakan model ini, adalah mungkin untuk menyelesaikan tidak hanya masalah langsung - untuk memilih jawaban yang tepat untuk pertanyaan, tetapi juga sebaliknya - untuk menemukan kesalahan operator, kualitas rendah dan jawaban aneh untuk pertanyaan pengguna.
Kami berhasil menemukan beberapa jawaban ini tepat di hackathon dan memasukkannya dalam presentasi akhir. Bagi saya, ini mengesankan bagi juri.
Aplikasi yang menarik juga dapat ditemukan dalam representasi vektor teks yang dihasilkan jaringan dalam proses kerjanya.
Dengan menggunakannya, Anda dapat mencari anomali dalam pertanyaan dan jawaban dengan
berbagai metode tanpa pengawasan .
Sebagai hasilnya, keputusan kami dibuat dengan baik dari sudut pandang teknis dan dari sudut pandang bisnis. Sisa tim, pada dasarnya, mencoba menyelesaikan masalah analisis kunci dan pemodelan tematik, sehingga solusi kami berbeda. Akibatnya, kami mengambil tempat 1, berpisah puas dan lelah.
 Dalam foto (dari kiri ke kanan): Alexander Abramov, Konstanin Ivanov, Andrey Vasnetsov (penulis) dan Shvetsov Egor
Dalam foto (dari kiri ke kanan): Alexander Abramov, Konstanin Ivanov, Andrey Vasnetsov (penulis) dan Shvetsov EgorApa lagi yang harus dibaca: