
Banyak orang yang mempelajari pembelajaran mesin akrab dengan proyek OpenAI, salah satu pendiri di antaranya adalah Elon Musk, dan menggunakan platform
OpenAI Gym sebagai media untuk melatih model jaringan saraf mereka.
Gym berisi serangkaian besar lingkungan, beberapa di antaranya adalah berbagai jenis simulasi fisik: gerakan hewan, manusia,
robot . Simulasi ini didasarkan pada mesin fisika
MuJoCo , yang gratis untuk tujuan pendidikan dan ilmiah.
Pada artikel ini, kita akan membuat simulasi fisik yang sangat sederhana mirip dengan lingkungan OpenAI Gym, tetapi didasarkan pada Bullet engine fisika gratis (
PyBullet ). Dan juga membuat agen untuk bekerja dengan lingkungan ini.
PyBullet adalah modul python untuk menciptakan lingkungan simulasi fisik berdasarkan pada mesin fisika
Fisika Bullet . Itu, seperti MuJoCo, sering digunakan sebagai stimulasi berbagai robot, yang tertarik pada habr ada
artikel dengan contoh nyata.
Ada
QuickStartGuide yang cukup bagus untuk PyBullet yang berisi tautan ke contoh di halaman sumber di
GitHub .
PyBullet memungkinkan Anda memuat model yang sudah dibuat dalam format URDF, SDF atau MJCF. Dalam sumber ada perpustakaan
model dalam format ini, serta lingkungan simulator
robot asli yang benar-benar siap pakai
.Dalam kasus kami, kami sendiri akan menciptakan lingkungan menggunakan PyBullet. Antarmuka lingkungan akan
mirip dengan antarmuka OpenAI Gym. Dengan cara ini kami dapat melatih agen kami baik di lingkungan kami maupun di lingkungan Gym.
Semua kode (iPython), serta pengoperasian program dapat dilihat di
Google Colaboratory .
Lingkungan
Lingkungan kita akan terdiri dari bola yang dapat bergerak di sepanjang sumbu vertikal dalam rentang ketinggian tertentu. Bola memiliki massa, dan gravitasi bekerja di atasnya, dan agen harus, mengendalikan gaya vertikal yang diterapkan pada bola, membawanya ke target. Ketinggian target berubah dengan setiap restart pengalaman.

Simulasi sangat sederhana, dan sebenarnya dapat dianggap sebagai simulasi dari beberapa penggerak dasar.
Untuk bekerja dengan lingkungan, 3 metode digunakan:
reset (memulai kembali eksperimen dan membuat semua objek lingkungan),
langkah (menerapkan tindakan yang dipilih dan memperoleh keadaan lingkungan yang dihasilkan),
render (tampilan visual lingkungan).
Saat menginisialisasi lingkungan, kita perlu menghubungkan objek kita ke simulasi fisik. Ada 2 opsi koneksi: dengan antarmuka grafis (GUI) dan tanpa (LANGSUNG) .Dalam kasus kami, itu LANGSUNG.
pb.connect(pb.DIRECT)
atur ulang
Dengan setiap percobaan baru, kami mereset simulasi
pb.resetSimulation () dan membuat semua objek lingkungan lagi.
Dalam PyBullet, objek memiliki 2 bentuk: bentuk tabrakan, dan
bentuk visual . Yang pertama digunakan oleh mesin fisik untuk menghitung tumbukan benda dan, untuk mempercepat perhitungan fisika, biasanya memiliki bentuk yang lebih sederhana daripada benda nyata. Yang kedua adalah opsional, dan hanya digunakan saat membentuk gambar objek.
Bentuk dikumpulkan dalam satu objek (tubuh) -
MultiBody . Tubuh dapat terdiri dari satu bentuk (pasangan
CollisionShape / Bentuk Visual ), seperti dalam kasus kami, atau beberapa.
Selain bentuk-bentuk yang membentuk tubuh, perlu untuk menentukan massa, posisi dan orientasinya di ruang angkasa.
Beberapa kata tentang badan multi-objek.Sebagai aturan, dalam kasus nyata, untuk mensimulasikan berbagai mekanisme, badan yang terdiri dari banyak bentuk digunakan. Saat membuat tubuh, selain bentuk dasar tabrakan dan visualisasi, tubuh ditransfer rantai bentuk benda anak (
Tautan ), posisi dan orientasinya relatif terhadap objek sebelumnya, serta jenis koneksi (sambungan) benda di antara mereka sendiri (Sambungan). Jenis koneksi dapat diperbaiki, prismatik (meluncur pada poros yang sama) atau rotasi (berputar pada satu poros). 2 jenis koneksi terakhir memungkinkan Anda untuk mengatur parameter dari jenis motor yang sesuai (
JointMotor ), seperti gaya akting, kecepatan atau torsi, sehingga mensimulasikan motor dari "sambungan" robot. Lebih detail dalam
dokumentasi .
Kami akan membuat 3 tubuh: Bola, Pesawat (Bumi) dan Pointer Target. Objek terakhir hanya akan memiliki bentuk visualisasi dan nol massa, karena itu ia tidak akan berpartisipasi dalam interaksi fisik antara tubuh:
Tentukan gravitasi dan waktu langkah simulasi.
pb.setGravity(0,0,-10) pb.setTimeStep(1./60)
Untuk mencegah bola jatuh segera setelah memulai simulasi, kami menyeimbangkan gravitasi.
pb_force = 10 * PB_BallMass pb.applyExternalForce(pb_ballId, -1, [0,0,pb_force], [0,0,0], pb.LINK_FRAME)
langkah
Agen memilih tindakan berdasarkan kondisi lingkungan saat ini, setelah itu memanggil metode
langkah dan menerima keadaan baru.
2 jenis aksi didefinisikan: menambah dan mengurangi gaya yang bekerja pada bola. Batas kekuatan terbatas.
Setelah mengubah gaya yang bekerja pada bola, langkah baru simulasi fisik
pb.stepSimulation () diluncurkan , dan parameter berikut dikembalikan ke agen:
observasi - pengamatan (keadaan lingkungan)
hadiah - hadiah untuk tindakan sempurna
dilakukan - bendera akhir dari pengalaman
info - informasi tambahan
Sebagai keadaan lingkungan, 3 nilai dikembalikan: jarak ke target, gaya saat ini diterapkan pada bola, dan kecepatan bola. Nilai-nilai dikembalikan normal (0..1), karena parameter lingkungan yang menentukan nilai-nilai ini dapat bervariasi tergantung pada keinginan kita.
Hadiah untuk tindakan sempurna adalah 1 jika bola dekat dengan target (tinggi target plus / minus nilai bergulir yang dapat diterima
TARGET_DELTA ) dan 0 dalam kasus lain.
Eksperimen selesai jika bola keluar zona (jatuh ke tanah atau terbang tinggi). Jika bola mencapai tujuan, percobaan juga berakhir, tetapi hanya setelah waktu tertentu (
STEPS_AFTER_TARGET langkah-langkah percobaan). Dengan demikian, agen kami dilatih tidak hanya untuk bergerak menuju tujuan, tetapi juga untuk berhenti dan dekat dengannya. Mengingat bahwa hadiah saat Anda hampir mencapai tujuan adalah 1, pengalaman yang sepenuhnya berhasil harus memiliki total hadiah yang setara dengan
STEPS_AFTER_TARGET .
Sebagai informasi tambahan untuk menampilkan statistik, jumlah langkah yang dilakukan dalam percobaan, serta jumlah langkah yang dilakukan per detik, dikembalikan.
membuat
PyBullet memiliki 2 opsi rendering gambar - rendering GPU berbasis OpenGL dan CPU berbasis TinyRenderer. Dalam kasus kami, hanya implementasi CPU yang dimungkinkan.
Untuk mendapatkan kerangka simulasi saat ini, perlu untuk menentukan
matriks spesies dan
matriks proyeksi , dan kemudian mendapatkan gambar
rgb dari ukuran yang diberikan dari kamera.
camTargetPos = [0,0,5]
Di akhir setiap percobaan, video dihasilkan berdasarkan gambar yang dikumpulkan.
ani = animation.ArtistAnimation(plt.gcf(), render_imgs, interval=10, blit=True,repeat_delay=1000) display(HTML(ani.to_html5_video()))
Agen
Kode pengguna
jaara GitHub diambil sebagai dasar untuk Agen, sebagai contoh sederhana dan dapat dipahami untuk menerapkan pelatihan penguatan untuk lingkungan Gym.
Agen berisi 2 objek:
Memori - penyimpanan untuk pembentukan contoh pelatihan dan
Otak sendiri adalah jaringan saraf yang ia latih.
Jaringan saraf terlatih dibuat di TensorFlow menggunakan perpustakaan Keras, yang baru-baru ini sepenuhnya
dimasukkan dalam TensorFlow.
Jaringan saraf memiliki struktur sederhana - 3 lapisan, yaitu Hanya 1 lapisan tersembunyi.
Lapisan pertama berisi 512 neuron dan memiliki jumlah input yang sama dengan jumlah parameter keadaan medium (3 parameter: jarak ke target, kekuatan dan kecepatan bola). Lapisan tersembunyi memiliki dimensi yang sama dengan lapisan pertama - 512 neuron, pada keluaran itu terhubung ke lapisan keluaran. Jumlah neuron dari lapisan output sesuai dengan jumlah tindakan yang dilakukan oleh Agen (2 tindakan: mengurangi dan meningkatkan kekuatan akting).
Dengan demikian, keadaan sistem dipasok ke input jaringan, dan pada output kami memiliki manfaat untuk setiap tindakan.
Untuk dua lapisan pertama,
ReLU (unit linear yang diperbaiki) digunakan sebagai fungsi aktivasi, untuk yang terakhir -
fungsi linier (jumlah nilai input sederhana).
Sebagai fungsi kesalahan,
MSE (standard error), sebagai algoritma pengoptimalan -
RMSprop (Root Mean Square Propagation).
model = Sequential() model.add(Dense(units=512, activation='relu', input_dim=3)) model.add(Dense(units=512, activation='relu')) model.add(Dense(units=2, activation='linear')) opt = RMSprop(lr=0.00025) model.compile(loss='mse', optimizer=opt)
Setelah setiap langkah simulasi, Agen menyimpan hasil langkah ini dalam bentuk daftar
(s, a, r, s_) :
s - pengamatan sebelumnya (keadaan lingkungan)
a - tindakan yang selesai
r - hadiah yang diterima untuk tindakan yang dilakukan
s_ - pengamatan akhir setelah aksi
Setelah itu, Agen menerima dari memori serangkaian contoh acak untuk periode sebelumnya dan membentuk paket pelatihan (
batch ).
Keadaan awal
s dari langkah-langkah acak yang dipilih dari memori diambil sebagai nilai input (
X ) dari paket.
Nilai aktual dari output pembelajaran (
Y ' ) dihitung sebagai berikut: Pada output (
Y ) dari jaringan saraf untuk s akan ada nilai-nilai
fungsi-Q untuk setiap tindakan
Q (s) . Dari set ini, agen memilih tindakan dengan nilai
Q (s, a) = MAX (Q (s)) tertinggi , menyelesaikannya dan menerima penghargaan
r . Nilai
Q baru untuk tindakan yang dipilih
a adalah
Q (s, a) = Q (s, a) + DF * r , di mana
DF adalah faktor diskon. Nilai output yang tersisa akan tetap sama.
STATE_CNT = 3 ACTION_CNT = 2 batchLen = 32
Pelatihan jaringan terjadi pada paket yang dibentuk
self.model.fit(x, y, batch_size=32, epochs=1, verbose=0)
Setelah percobaan selesai, video dihasilkan
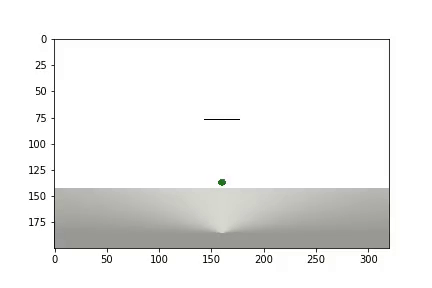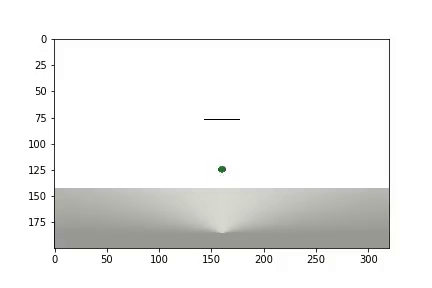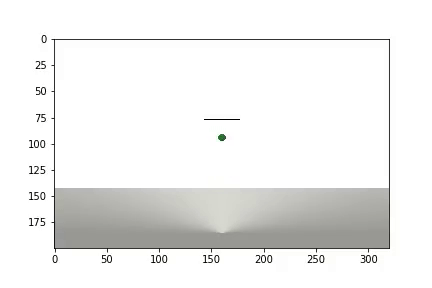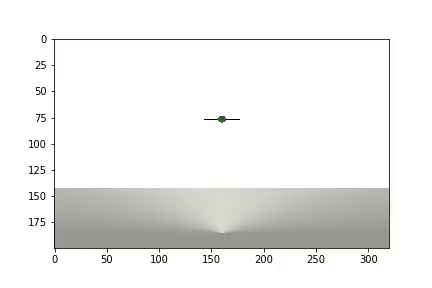
dan statistik ditampilkan
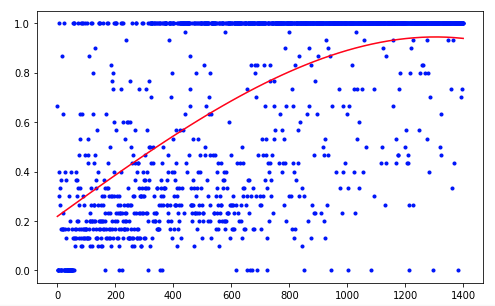
Agen tersebut membutuhkan 1.200 percobaan untuk mencapai hasil sekitar 95 persen (jumlah langkah sukses). Dan dengan percobaan ke-50, Agen telah belajar untuk memindahkan bola ke target (percobaan yang gagal hilang).
Untuk meningkatkan hasil, Anda dapat mencoba mengubah ukuran lapisan jaringan (LAYER_SIZE), parameter faktor diskon (GAMMA) atau tingkat penurunan dalam probabilitas memilih tindakan acak (LAMBDA).
Agen kami memiliki arsitektur paling sederhana - DQN (Deep Q-Network). Pada tugas sederhana seperti itu, cukup untuk mendapatkan hasil yang dapat diterima.
Menggunakan, misalnya, arsitektur DDQN (Double DQN) harus memberikan pelatihan yang lebih halus dan lebih akurat. Dan jaringan RDQN (DQN Berulang) akan dapat melacak pola perubahan lingkungan dari waktu ke waktu, yang akan memungkinkan untuk menyingkirkan parameter kecepatan bola, mengurangi jumlah parameter input jaringan.
Anda juga dapat memperluas simulasi kami dengan menambahkan massa bola variabel atau sudut kemiringan gerakannya.
Tapi ini waktu berikutnya.