Setahun yang lalu, kami menambahkan kumpulan metrik dari atribut disk SMART ke server klien. Pada saat itu, kami tidak menambahkannya ke antarmuka dan menunjukkannya kepada pelanggan. Faktanya adalah, kami tidak mengambil metrik melalui smartctl, tetapi kami menarik ioctl langsung dari kode sehingga fungsi ini berfungsi tanpa menginstal smartmontools di server klien.
Agen tidak menghapus semua atribut yang tersedia, tetapi hanya yang paling signifikan menurut kami dan yang paling tidak spesifik vendor (jika tidak, ia harus mendukung basis disk yang mirip dengan smartmontools).
Sekarang, tangan akhirnya mencapai titik untuk memeriksa apa yang kami syuting di sana. Dan diputuskan untuk memulai dengan atribut "indikator keausan media", yang menunjukkan persentase sumber daya perekaman SSD yang tersisa. Di bawah potongan beberapa cerita dalam gambar tentang bagaimana sumber daya ini dihabiskan dalam kehidupan nyata di server.
Apakah ada SSD yang terbunuh?
Dipercaya bahwa SSD baru yang lebih produktif dilepaskan lebih sering daripada yang lama berhasil terbunuh. Oleh karena itu, hal pertama yang menarik adalah melihat yang paling terbunuh dalam hal merekam disk sumber daya. Nilai minimum untuk semua ssd dari semua klien adalah 1%.
Kami segera menulis kepada klien tentang ini, ternyata Dedik di hetzner. Dukungan hosting segera diganti SSD:

Akan sangat menarik untuk melihat bagaimana situasi terlihat dari sudut pandang sistem operasi ketika ssd berhenti melayani catatan (kami sekarang mencari peluang untuk sengaja mengejek ssd untuk melihat metrik skenario ini :)
Seberapa cepat SSD terbunuh?
Karena kami mulai mengumpulkan metrik setahun yang lalu, dan kami tidak menghapus metrik, dimungkinkan untuk melihat metrik ini tepat waktu. Sayangnya, server dengan laju aliran tertinggi terhubung ke okmeter hanya 2 bulan yang lalu.

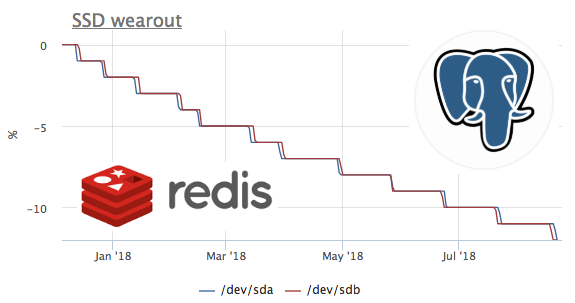
Dalam grafik ini, kita melihat bagaimana dalam 2 bulan mereka membakar 8% dari sumber rekaman. Artinya, dengan profil rekaman yang sama, SSD ini akan cukup untuk 100 / (8/2) = 25 bulan. Saya tidak tahu banyak atau sedikit, tetapi mari kita lihat jenis muatan apa yang ada?

Kami melihat bahwa hanya ceph yang bekerja dengan disk, tetapi kami memahami bahwa ceph hanya lapisan. Dalam hal ini, klien ceph bertindak sebagai repositori untuk kluster kubernet pada beberapa node, mari kita lihat apa di dalam k8 yang menghasilkan disk paling banyak:

Nilai absolut tidak cocok kemungkinan besar karena fakta bahwa ceph bekerja di cluster dan catatan dari redis meningkat karena replikasi data. Tetapi profil memuat memungkinkan Anda untuk dengan yakin mengatakan bahwa catatan memulai persis redis. Mari kita lihat apa yang terjadi pada lobak:

di sini Anda dapat melihat bahwa rata-rata kurang dari 100 permintaan per detik dieksekusi, yang dapat mengubah data. Ingatlah bahwa redis memiliki 2 cara untuk menulis data ke disk :
- RDB - snapshot berkala dari seluruh basis data ke disk, saat memulai redis, kita membaca dump terakhir ke memori, dan kita kehilangan data antara dump
- AOF - kami menulis log dari semua perubahan, saat mulai redis kehilangan log ini dan semua data muncul di memori, kami hanya kehilangan data antara fsync dari log ini
Karena semua orang mungkin sudah menebak dalam kasus ini, RDB digunakan dengan frekuensi dump 1 menit:

SSD + RAID
Menurut pengamatan kami, ada tiga konfigurasi utama subsistem disk server dengan kehadiran SSD:
- di server 2 SSD dikumpulkan dalam raid-1 dan semuanya tinggal di sana
- server memiliki HDD + raid-10 dari ssd, biasanya digunakan untuk RDBMSs klasik (sistem, WAL dan bagian dari data pada HDD, dan pada SSD data terpanas dalam hal membaca)
- server memiliki SSD yang berdiri sendiri (JBOD), biasanya digunakan untuk cassandra jenis nosql
Jika ssd dikumpulkan dalam raid-1, rekaman masuk ke kedua disk, jadi keausan berjalan pada kecepatan yang sama:
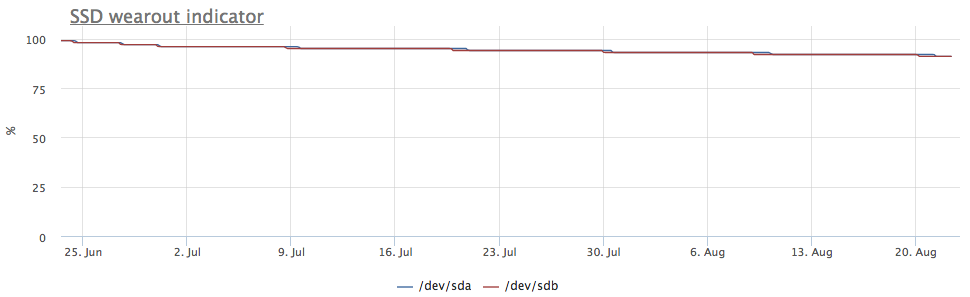
Tetapi server menarik perhatian saya, di mana gambarnya berbeda:

Dalam kasus ini, hanya partisi mdraid yang dipasang (semua array raid-1):

Metrik rekaman juga menunjukkan bahwa ada lebih banyak entri di / dev / sda:

Ternyata salah satu partisi di / dev / sda digunakan sebagai swap, dan swap i / o di server ini cukup terlihat:

Depresiasi SSD dan PostgreSQL
Sebenarnya, saya ingin melihat tingkat keausan SSD pada berbagai beban tulis di Postgres, tetapi sebagai aturan, mereka digunakan dengan sangat hati-hati pada basis data SSD yang dimuat dan perekaman besar-besaran ke HDD. Saat mencari case yang cocok, saya menemukan satu server yang sangat menarik:

Pemakaian dua ssd dalam serangan-1 selama 3 bulan adalah 4%, tetapi jika dilihat dari kecepatan perekaman WAL, postgres ini menulis kurang dari 100 Kb / s:
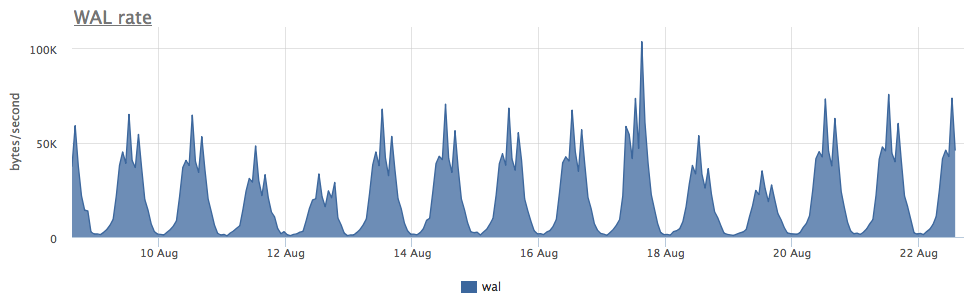
Ternyata postgres aktif menggunakan file-file sementara, bekerja dengan yang menciptakan aliran penulisan ke disk:

Karena postgresql dengan diagnostik cukup bagus, kami dapat, hingga permintaan, mencari tahu apa yang sebenarnya perlu kami perbaiki:

Seperti yang Anda lihat di sini, SELECT khusus ini menghasilkan banyak file sementara. Secara umum, dalam postgres SELECT, kadang-kadang mereka menghasilkan catatan tanpa file sementara - di sini kita sudah membicarakan hal ini.
Total
- Jumlah penulisan ke disk yang dibuat oleh Redis + RDB tidak tergantung pada jumlah modifikasi dalam database, tetapi pada ukuran database + interval pembuangan (dan secara umum, ini adalah tingkat tertinggi dari amplifikasi tulis di penyimpanan data yang saya tahu)
- Swap yang digunakan secara aktif pada ssd buruk, tetapi jika Anda perlu menambahkan jitter ke ssd wear (untuk reliabilitas raid-1), maka itu mungkin menjadi pilihan :)
- Selain WAL dan datafile, basis data masih dapat menulis semua jenis data sementara ke disk.
Kami di okmeter.io percaya bahwa untuk sampai ke dasar penyebab masalah, insinyur membutuhkan banyak metrik tentang semua lapisan infrastruktur. Kami melakukan yang terbaik untuk membantu :)