
Kami memiliki dua pendekatan untuk Disaster Recovery: cluster "stretched" (instalasi aktif-aktif) dan platform dengan mesin virtual (replika) dimatikan. Mereka memiliki beberapa poin untuk menyimpan foto.
Ada permintaan untuk toleransi bencana, dan banyak klien kami sangat membutuhkannya. Oleh karena itu, kami mulai mengerjakan kedua skema tersebut sebagai bagian dari produksi kami.
Metode memiliki pro dan kontra, sekarang saya akan memberi tahu Anda tentang mereka.
Cluster Peregangan
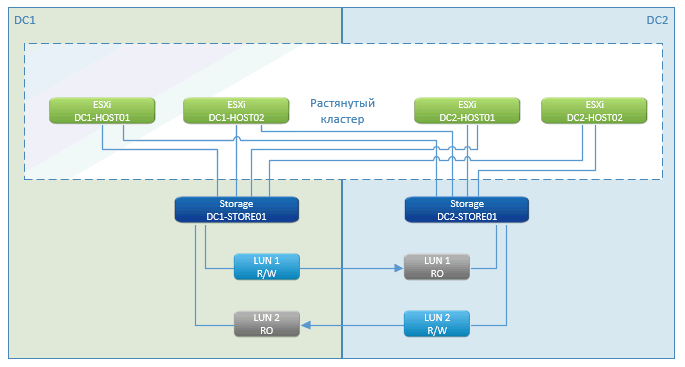
Seperti yang Anda lihat, ini adalah kisah standar metro cluster. Dalam pro - downtime hampir nol, berhenti hanya pada saat memulai mesin virtual. Fitur ini berfungsi - VMware High Availability (HA). Dia melihat bahwa host hilang, dan segera restart VM di situs jarak jauh.
Peluncuran dilakukan segera dari penyimpanan, yang terletak di cluster.
Penyimpanan dengan cluster yang didistribusikan secara geografis adalah fitur pemasaran NetApp. Pabrikan lain memiliki sesuatu dengan nama yang mirip. Intinya, ini adalah replikasi asinkron yang dipikirkan dari satu sisi ke sisi lain. Kami menulis ke satu node di jaringan lokal dan menyinkronkan melalui saluran komunikasi khusus dengan yang lain.
Dalam hal terjadi kegagalan dari salah satu sistem penyimpanan, sisanya (di situs lain) menyajikan jalur ke disk ke host yang tersisa. VM yang telah mati dihidupkan ulang pada mereka. Semuanya terjadi secara otomatis - pusat data macet, semuanya reboot, penyimpanan berfungsi, VMware berfungsi. Klien melihat bahwa semuanya berkedip dan mulai lagi.
Satu-satunya cache dari RAM VM bisa hilang. Tetapi jika database membuangnya, maka kerugiannya adalah nol dalam waktu.
Jika kami kehilangan komunikasi antara situs, maka semuanya terus berfungsi di tempatnya dan, segera setelah koneksi dipulihkan, ia mulai menyinkronkan.
Kelemahannya adalah harga tinggi. Karena Anda benar-benar membutuhkan SHD ganda (terlebih lagi, serupa dalam jenis, kecepatan dan volume disk SHD pertama di situs utama), yang tidak dapat digunakan entah bagaimana, kecuali sebagai cadangan. Ditambah lagi mengikat penyimpanan untuk cluster metro, ini adalah jembatan FC, jaringan FC dan banyak lagi.
Kami memiliki dua DPC, di antaranya bundel FC sepanjang dua balok (empat garis optik gelap dan DWDM). Ini adalah dua potong besi, masing-masing menyediakan bandwidth 200 Gbps untuk FC dan Ethernet.
Alternatif dengan DR

Ada perangkat lunak dengan nama yang mudah diingat - VMware vCloud Availability untuk Cloud-to-Cloud DR.
Ini adalah sistem untuk membuat VM identik di situs jarak jauh satu kali, secara relatif, dalam 15 menit. Sebuah sistem untuk menyajikan semua ini dengan cara yang tepat ke mekanisme kontrol cloud melekat padanya pada pita listrik.
Artinya, teknologi Replikasi VMware ada di backend. Jika terjadi kegagalan, kami meluncurkan paket DR di situs kedua secara manual, secara otomatis berhenti mencoba mereplikasi, kemudian mendaftarkan VM di vCloud Director, menyesuaikan alamat IP (sehingga tidak harus diubah ke VM) dan memulai VM dalam urutan yang diperlukan. Dalam solusi kami, tidak perlu mengubah pengalamatan, kami merentangkan jaringan ke kedua pusat data.
Mesin terus-menerus direplikasi, tetapi bukan seluruh pusat data, tetapi hanya yang terpilih yang merupakan proses kritis. Ini direplikasi sesekali, interval minimum adalah 15 menit (ini adalah kasus yang ideal ketika semuanya terbang dan ada server replikasi khusus dan minimum perubahan ke VM). Dalam praktiknya, Anda memiliki salinan setengah jam atau satu jam yang lalu. Jika ada yang salah, maka data yang jatuh ke interval hilang. 15 menit adalah pertanyaan agen yang mengumpulkan replikasi baru. Veeam mengatakan bahwa mereka bisa memakan waktu kurang dari 15 menit, tetapi pada kenyataannya itu juga lebih lama dalam praktik jika mereka tidak menggunakan fitur penyimpanan. Saya tidak melihat pada mesin industri (bukan pada tes) bahwa itu akan menjadi sebaliknya.
Untuk waktu yang lama, NetApp, seperti banyak produsen sistem penyimpanan lainnya, memiliki teknologi SnapMirror, yang memungkinkan Anda mengubah pekerjaan replikasi dari hypervisor ke sistem penyimpanan, dan Replikasi VMware dapat menggunakannya.
Saat layanan replikasi berjalan, kereta berjalan jauh. Tapi itu murah.
Mengapa masih murah - karena Anda dapat menggunakan penyimpanan apa pun di sisi mana pun (dari produsen yang berbeda, kelas yang berbeda), Anda tidak perlu mengalokasikan sejumlah besar disk sebelumnya.
Tidak perlu mengalokasikan grup disk besar, di dalamnya bulan dipotong. Ini hanya terjadi pada penyimpanan lokal dan diterapkan pada kenyataan ketersediaan catatan dari mesin virtual. Karena ini, tempat pada sistem penyimpanan ditempati secara optimal, jika digunakan untuk tugas-tugas lain. Dan itu digunakan, karena kami tidak memberikan layanan seperti itu kepada semua pelanggan.
Minus - Anda perlu mengkonfigurasi replikasi di tingkat VM, yaitu, kontrol bahwa semuanya sudah dikonfigurasi dengan benar, bahwa ini adalah mesin, pastikan replikasi melewati, bahwa tidak ada kesalahan. Buat rencana DR untuk setiap klien, lakukan tes mereka.
Dalam kasus pertama, penyimpanan diambil, secara kondisional, infrastruktur, hampir berdasarkan sektor (lebih tepatnya, oleh objek). Dan di sini satu mesin dapat jatuh karena tugas jatuh karena beberapa alasan perangkat lunak terkait dengan bug di tingkat tinggi, atau karena masalah aksesibilitas. Ini terjadi sedikit lebih sering daripada jika Anda hanya mengambil level rendah.
Dalam plus - DR menyimpan beberapa poin. Anda dapat memutar kembali beberapa foto.
Di luar OS tamu, Anda memerlukan perangkat lunak tambahan.
Untuk mendapatkan semua jaringan yang diperlukan ke Vcloud Director, kami membutuhkan pekerjaan administrator kami. Secara umum, semua konektivitas jaringan dalam versi ini tetap dengan administrator kami. Untuk klien cloud, ini berarti aplikasi, yang juga membutuhkan waktu.
Replikasi juga dikonfigurasi melalui aplikasi. VM yang ditambahkan - Anda harus mengirim permintaan yang perlu Anda tiru. Itu tidak termasuk dalam tugas replikasi secara otomatis. Perlu memperhatikan administrator.
Perbedaannya
Akibatnya, harga mungkin berbeda lebih dari dua kali. Replikasi akan menggandakan biaya ruang disk dengan dua atau lebih (dua salinan lengkap + riwayat perubahan), ditambah sesuatu untuk layanan dan reservasi sumber daya komputasi. Dalam kasus cluster metro, biaya ruang akan dikalikan dua, tetapi ruang itu sendiri akan lebih mahal secara signifikan, ditambah Anda perlu secara ketat memesan node di situs terpencil. Artinya, sumber daya komputasi harus dikalikan dua, kita tidak bisa menggunakannya untuk hal lain.
Dalam kasus metro cluster, kita hanya bisa menggunakan disk yang sama sehingga ada mirror penuh. Jika pada pusat data utama beberapa drive cepat, beberapa lambat pada 10 ribu putaran per menit, maka konfigurasi yang sama diperlukan. Dalam kasus replika, disk yang lebih lambat di situs cadangan dimungkinkan, yang lebih murah karena penyimpanan. Tetapi ketika beralih ke cadangan, itu akan berubah menjadi kurang dalam kinerja. Yaitu, jika ia menyimpan sesuatu pada SSD di cluster utama, dan direplikasi ke disk biasa, maka penyimpanan akan jauh lebih murah dengan biaya memperlambat infrastruktur cadangan.
Saat ini kami sedang memilih apa yang akan dimasukkan dalam rilis sebelumnya, jadi kami ingin berkonsultasi: dapatkah Anda memberi tahu kami secara singkat bagaimana Anda mengatur situs DR Anda dan apa yang ingin Anda lakukan secara umum?