
Saya bisa mengumpulkan workstation saya sebagai mahasiswa. Secara logis, saya lebih suka solusi komputasi AMD. karena itu murah menguntungkan dari segi harga / kualitas. Saya mengambil komponen untuk waktu yang lama, pada akhirnya saya berhasil dengan 40k dengan satu set FX-8320 dan RX-460 2GB. Awalnya kit ini tampak sempurna! Teman sekamar saya dan saya menambang Monero sedikit dan set saya menunjukkan 650h / s versus 550h / s pada satu set i5-85xx dan Nvidia 1050Ti. Benar, dari set saya di ruangan itu agak panas di malam hari, tetapi ini diputuskan ketika saya membeli pendingin menara untuk CPU.
Kisah itu sudah berakhir
Semuanya seperti dalam dongeng sampai saya tertarik pada pembelajaran mesin di bidang visi komputer. Bahkan lebih tepatnya - sampai saya harus bekerja dengan input gambar dengan resolusi lebih dari 100x100px (sampai saat ini, FX 8-core saya diatasi dengan cepat). Kesulitan pertama adalah tugas menentukan emosi. 4 Lapisan ResNet, masukkan gambar 100x100 dan 3000 gambar dalam set pelatihan. Dan sekarang - 9 jam pelatihan 150 era pada CPU.
Tentu saja, karena keterlambatan ini, proses pengembangan iteratif menderita. Di tempat kerja, kami memiliki Nvidia 1060 6GB dan pelatihan untuk struktur yang sama (meskipun regresi dilatih di sana untuk melokalisasi objek), ia terbang dalam 15-20 menit - 8 detik untuk era gambar 3.5k. Ketika Anda memiliki kontras di bawah hidung Anda, pernapasan menjadi lebih sulit.
Nah, tebak langkah pertama saya setelah semua ini? Ya, saya pergi untuk menawar 1050Ti dengan tetangga saya. Dengan argumen tentang kegunaan CUDA untuknya, dengan tawaran untuk menukar kartu saya dengan biaya tambahan. Namun semuanya sia-sia. Dan sekarang saya memposting RX 460 saya di Avito dan meninjau 1050Ti yang berharga di situs Citylink dan TechnoPoint. Bahkan dalam hal penjualan kartu yang berhasil, saya harus menemukan 10rb lagi (saya seorang siswa, meskipun masih bekerja).
Google
Baiklah Saya akan google cara menggunakan Radeon di bawah Tensorflow. Mengetahui bahwa ini adalah tugas yang eksotis, saya tidak terlalu berharap untuk menemukan sesuatu yang masuk akal. Kumpulkan di bawah Ubuntu, apakah itu dimulai atau tidak, dapatkan frasa batu bata yang diambil dari forum.
Dan jadi saya pergi ke arah lain - saya tidak google Tensorflow AMD Radeon, tetapi Keras AMD Radeon. Ini langsung melemparkan saya ke halaman PlaidML . Saya memulainya dalam 15 menit (meskipun saya harus downgrade Keras ke 2.0.5) dan mengatur jaringan untuk belajar. Pengamatan pertama - era adalah 35 detik, bukan 200.
Naik untuk menjelajah
Penulis PlaidML adalah vertex.ai , yang merupakan bagian dari grup proyek Intel (!). Tujuan pengembangan adalah lintas-platform maksimum. Tentu saja, ini menambah kepercayaan pada produk. Artikel mereka mengatakan bahwa PlaidML kompetitif dengan Tensorflow 1.3 + cuDNN 6 karena "optimasi menyeluruh".
Namun, kami melanjutkan. Artikel berikut sampai batas tertentu mengungkapkan kepada kita struktur internal perpustakaan. Perbedaan utama dari semua kerangka kerja lainnya adalah pembuatan kernel perhitungan otomatis (dalam notasi Tensorflow, "inti" adalah proses lengkap untuk melakukan operasi tertentu dalam grafik). Untuk pembuatan kernel otomatis dalam PlaidML, dimensi yang pasti dari semua tensor, konstanta, langkah, ukuran konvolusi, dan nilai batas yang harus Anda gunakan nanti sangat penting. Misalnya, dikemukakan bahwa pembuatan kernel efektif lebih lanjut berbeda untuk 1 dan 32 batch atau untuk konvolusi ukuran 3x3 dan 7x7. Memiliki data ini, kerangka itu sendiri akan menghasilkan cara yang paling efisien untuk memparalelkan dan menjalankan semua operasi untuk perangkat tertentu dengan karakteristik tertentu. Jika Anda melihat Tensorflow, saat membuat operasi baru, kami juga perlu mengimplementasikan kernel - dan implementasinya sangat berbeda untuk kernel single-threaded, multi-threaded atau CUDA-compatible. Yaitu PlaidML jelas lebih fleksibel.
Kami melangkah lebih jauh. Implementasi ditulis dalam Tile bahasa yang ditulis sendiri. Bahasa ini memiliki keuntungan utama sebagai berikut - kedekatan sintaksis dengan notasi matematika (tapi gila!):
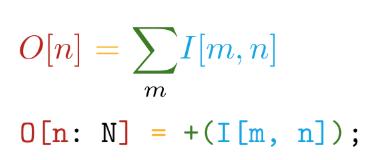
Dan diferensiasi otomatis dari semua operasi yang dinyatakan. Misalnya, di TensorFlow, saat membuat operasi kustom baru, Anda sangat disarankan untuk menulis fungsi untuk menghitung gradien. Jadi, ketika membuat operasi kami sendiri dalam bahasa Tile, kita hanya perlu mengatakan APA yang ingin kita hitung tanpa memikirkan BAGAIMANA CARA mempertimbangkan hal ini dalam kaitannya dengan perangkat perangkat keras.
Selain itu, optimalisasi kerja dengan DRAM dan analog dari cache L1 dalam GPU dilakukan. Ingat perangkat skematik:
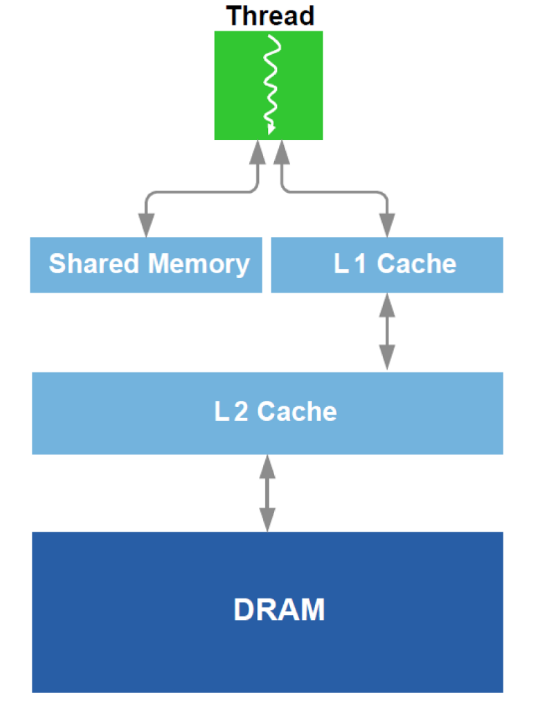
Untuk optimasi, semua data yang tersedia tentang peralatan digunakan - ukuran cache, lebar garis cache, bandwidth DRAM, dll. Metode utama adalah menyediakan pembacaan simultan dari blok yang cukup besar dari DRAM (upaya untuk menghindari pengalamatan ke area yang berbeda) dan mencapai bahwa data yang dimuat ke dalam cache digunakan beberapa kali (upaya untuk menghindari memuat ulang data yang sama beberapa kali).
Semua optimisasi terjadi selama era pertama pelatihan, sementara itu sangat meningkatkan waktu lari pertama:
Selain itu, perlu dicatat bahwa kerangka kerja ini terkait dengan OpenCL . Keuntungan utama OpenCL adalah bahwa itu adalah standar untuk sistem heterogen dan tidak ada yang mencegah Anda menjalankan kernel pada CPU . Ya, di sinilah salah satu rahasia utama cross-platform PlaidML berada.
Kesimpulan
Tentu saja, pelatihan pada RX 460 masih 5-6 kali lebih lambat daripada pada 1060, tetapi Anda dapat membandingkan kategori harga kartu video! Lalu saya mendapat RX 580 8gb (mereka meminjamkan saya!) Dan waktu yang dibutuhkan untuk menjalankan era berkurang menjadi 20 detik, yang hampir sebanding.
Blog vertex.ai memiliki grafik yang jujur (lebih banyak lebih baik):
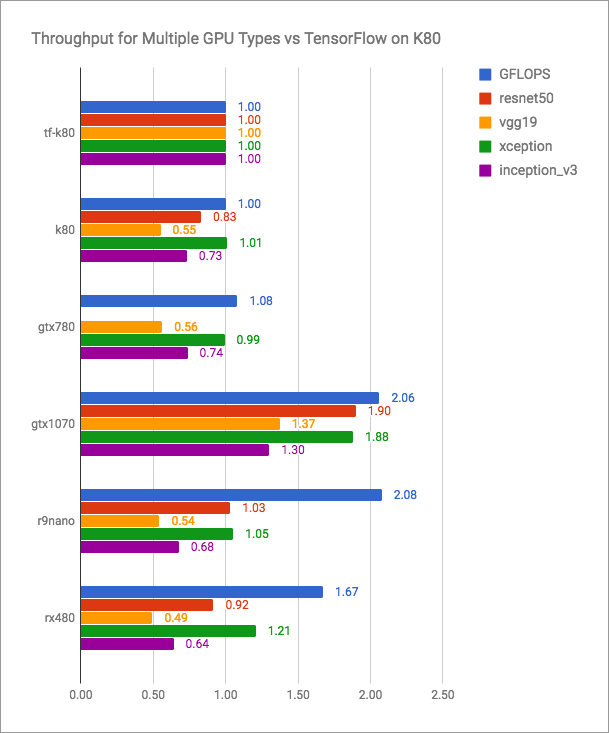
Dapat dilihat bahwa PlaidML bersaing dengan Tensorflow + CUDA, tetapi tentu saja tidak lebih cepat untuk versi saat ini. Tetapi pengembang PlaidML mungkin tidak berencana untuk memasuki pertempuran terbuka semacam itu. Tujuan mereka adalah universalitas, lintas platform.
Saya akan meninggalkan di sini tabel yang tidak cukup komparatif dengan pengukuran kinerja saya:
| Perangkat komputer | Jalankan waktu era (batch - 16), s |
|---|
| AMD FX-8320 tf | 200 |
| RX 460 2GB kotak-kotak | 35 |
| RX 580 8 GB kotak-kotak | 20 |
| 1060 6GB TF | 8 |
| 1060 6GB kotak-kotak | 10 |
| Intel i7-2600 tf | 185 |
| Intel i7-2600 kotak-kotak | 240 |
| GT 640 kotak-kotak | 46 |
Posting blog vertex.ai terbaru dan suntingan terbaru ke repositori tertanggal Mei 2018. Tampaknya jika pengembang alat ini tidak berhenti merilis versi baru dan semakin banyak orang yang tersinggung oleh Nvidia yang akrab dengan PlaidML, maka mereka akan berbicara tentang vertex.sebuah jauh lebih sering.
Temukan radeon Anda!