
Hari kedua program KDD utama. Di bawah potongan lagi, banyak hal menarik: dari pembelajaran mesin di Pinterest ke berbagai cara untuk menggali pipa air. Termasuk pidato peraih Nobel di bidang ekonomi - sebuah cerita tentang bagaimana NASA bekerja dengan telemetri, dan banyak embedding grafik :)
Desain pasar dan pasar terkomputerisasi
Performa bagus oleh
pemenang Nobel yang bekerja dengan Shapley di pasar. Pasar adalah hal artifisial yang perangkat orangnya buat. Ada yang disebut pasar komoditas, ketika Anda membeli produk tertentu dan Anda tidak peduli siapa, itu penting hanya pada harga berapa (misalnya, pasar saham). Dan ada pasar yang cocok ketika harga bukan satu-satunya faktor (dan kadang-kadang tidak sama sekali).
Misalnya, distribusi anak di sekolah. Sebelumnya, di AS, skema ini bekerja seperti ini: orang tua menuliskan daftar sekolah berdasarkan prioritas (1, 2, 3, dll.), Sekolah pertama-tama mempertimbangkan mereka yang telah mengindikasikannya sebagai nomor 1, mengurutkannya sesuai dengan kriteria sekolah mereka dan mengambil sebanyak yang mereka bisa ambil . Bagi mereka yang tidak menabrak, kami mengambil sekolah kedua dan mengulangi prosedur. Dari sudut pandang teori permainan, skema ini sangat buruk: orang tua harus bersikap "strategis", tidak praktis untuk mengatakan preferensi mereka secara jujur - jika Anda tidak masuk sekolah 1, pada putaran kedua, sekolah 2 mungkin sudah penuh dan Anda tidak akan masuk ke dalamnya, bahkan jika karakteristik Anda lebih tinggi daripada mereka yang diterima di babak pertama. Dalam praktiknya, tidak menghormati teori permainan diterjemahkan menjadi korupsi dan perjanjian internal antara orang tua dan sekolah. Matematikawan telah mengusulkan algoritma lain - "penerimaan ditangguhkan". Gagasan utamanya adalah bahwa sekolah tidak segera memberikan persetujuan, tetapi hanya menyimpan daftar peringkat kandidat "dalam ingatan", dan jika seseorang melampaui batas, maka ia segera mendapat penolakan. Dalam hal ini, ada strategi yang dominan untuk orang tua: pertama kita pergi ke sekolah 1, jika suatu saat kita mendapat penolakan, maka kita pergi ke sekolah 2 dan tidak takut kehilangan apa pun - peluang untuk sampai ke sekolah 2 sama seperti jika kita pergi ke sekolah 2 segera. Namun, skema ini diimplementasikan "dalam produksi". Hasil tes A / B tidak dilaporkan.
Contoh lain adalah transplantasi ginjal. Tidak seperti banyak organ lain, Anda dapat hidup dengan satu ginjal, sehingga suatu situasi sering muncul bahwa seseorang siap untuk memberikan ginjal kepada orang lain, tetapi bukan yang abstrak, tetapi yang spesifik (karena hubungan pribadi). Namun, kemungkinan donor dan penerima kompatibel sangat kecil, dan Anda harus menunggu organ lain. Ada alternatif - pertukaran ginjal. Jika dua pasangan adalah donor dan penerima dan tidak kompatibel di dalam, tetapi kompatibel di antara pasangan, maka Anda dapat bertukar: 4 operasi ekstraksi / implantasi secara simultan. Sistem sudah bekerja untuk ini. Dan jika ada organ "bebas" yang tidak terikat pada pasangan tertentu, maka dapat menimbulkan seluruh rantai pertukaran (dalam praktiknya ada rantai hingga 30 transplantasi).
Ada banyak pasar pencocokan serupa sekarang: dari Uber ke pasar iklan online, dan semuanya berubah sangat cepat karena komputerisasi. Antara lain, "privasi" banyak berubah: sebagai contoh, pembicara mengutip penelitian oleh seorang siswa yang menunjukkan bahwa di AS setelah pemilihan, jumlah perjalanan untuk mengunjungi Thanksgiving berkurang karena perjalanan antara negara-negara dengan pandangan politik yang berbeda. Penelitian ini dilakukan pada dataset anonim koordinat telepon, tetapi penulis cukup mudah mengidentifikasi "rumah" pemilik telepon, yaitu dataset deanonymized.
Secara terpisah, pembicara berbicara tentang pengangguran teknologi. Ya, mobil tak berawak akan menghilangkan banyak dari mereka (6% dari pekerjaan di AS berisiko), tetapi mereka akan menciptakan pekerjaan baru (untuk mekanik otomatis). Tentu saja, pengemudi tua tidak akan lagi dapat berlatih kembali dan baginya itu akan menjadi pukulan yang kuat. Pada saat-saat seperti itu, Anda perlu berkonsentrasi bukan pada bagaimana mencegah perubahan (itu tidak akan berhasil), tetapi pada bagaimana membantu orang melewati mereka tanpa rasa sakit mungkin. Di pertengahan abad terakhir, selama mekanisasi pertanian, banyak orang kehilangan pekerjaan, tetapi kami senang bahwa sekarang separuh penduduk tidak harus pergi bekerja di ladang? Sayangnya, ini hanya pembicaraan tentang opsi mitigasi yang diterapkan bagi mereka yang menghadapi pengangguran teknologi, pembicara tidak menyarankan ...
Dan ya, lagi tentang keadilan. Tidak mungkin membuat distribusi model ramalan sama di semua kelompok, model akan kehilangan artinya. Apa yang bisa dilakukan, secara teori, sehingga distribusi KESALAHAN jenis pertama dan kedua sama untuk semua kelompok? Itu sudah terlihat jauh lebih masuk akal, tetapi bagaimana mencapai ini dalam praktiknya tidak jelas. Dia memberikan tautan ke artikel menarik tentang praktik hukum - di AS, seorang hakim memutuskan apakah akan dibebaskan dengan jaminan
berdasarkan perkiraan ML .
Rekomendasi I
Saya bingung dalam jadwal dan sampai pada pidato yang salah, tetapi masih dalam topik - blok pertama pada sistem rekomendasi.
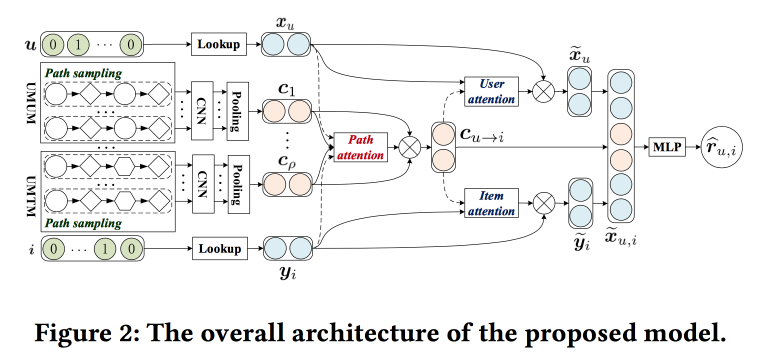
Memanfaatkan Konteks Meta-path berdasarkan rekomendasi N Top dengan mekanisme Co-attention
Orang-orang berusaha untuk meningkatkan rekomendasi dengan menganalisis jalur di grafik. Idenya cukup sederhana. Ada rekomendasi jaringan saraf "klasik" dengan embeddings untuk objek dan pengguna dan bagian yang sepenuhnya terhubung di atas. Ada rekomendasi pada grafik, termasuk yang memiliki markup jaringan saraf. Mari kita coba menggabungkan semua ini dalam satu mekanisme. Mari kita mulai dengan membangun "meta-grafik" yang menyatukan pengguna, film dan atribut (aktor / sutradara / genre, dll.), Pada grafik walk-om acak kami mencicipi sejumlah jalur, mengumpankannya ke jaringan konvolusi, menambahkan embeddings pengguna di samping dan objek, dan lebih dari itu kami menaruh perhatian (di sini sedikit rumit, dengan karakteristiknya sendiri untuk cabang yang berbeda). Untuk mendapatkan jawaban akhir, letakkan perceptron dengan dua lapisan tersembunyi di atasnya.
Aplikasi Internet Konsumen
Di sela-sela laporan, saya pindah ke presentasi di mana saya awalnya ingin: pembicara tamu dari LinkedIn, Pinterest dan Amazon berbicara di sini. Semua gadis dan semua kepala departemen DS.
Recommentations Kontekstual Neraline untuk Komunitas Aktif LinkedIn
Intinya adalah untuk merangsang pengembangan dan aktivasi komunitas di LinkedIn. Saya melewatkan setengah tentang pengembangan, rekomendasi terakhir: untuk mengeksploitasi pola lokal. Sebagai contoh, di India, siswa sering setelah lulus mencoba untuk menghubungi lulusan dari universitas yang sama dari kursus masa lalu dengan karier yang mapan. LinkedIn memperhitungkan hal ini saat membangun dan saat membuat rekomendasi.
Tetapi hanya menciptakan komunitas saja tidak cukup, perlu ada kegiatan: pengguna mempublikasikan konten, menerima dan memberikan umpan balik. Tunjukkan korelasi umpan balik yang diterima dengan jumlah publikasi di masa mendatang. Tunjukkan bagaimana informasi tersebut mengalir di seluruh grafik. Tetapi bagaimana jika sebuah simpul tidak terlibat dalam kaskade? Kirim pemberitahuan!
Lalu ada banyak percakapan dengan cerita kemarin tentang bekerja dengan notifikasi dan rekaman itu. Di sini mereka juga menggunakan pendekatan optimasi multi-tujuan "memaksimalkan salah satu metrik sambil menjaga yang lain dalam batas-batas tertentu." Untuk mengontrol beban, kami memperkenalkan sistem Kontrol Lalu Lintas Udara kami, yang membatasi beban pada notifikasi per pengguna (mereka mampu mengurangi berhenti berlangganan dan keluhan hingga 20%, tanpa kehilangan keterlibatan). ATC memutuskan apakah push dapat dikirim ke pengguna atau tidak, dan push ini disiapkan oleh sistem lain yang disebut Concourse, yang berfungsi dalam mode streaming (seperti milik kami, di
Samza !). Tentang dirinya itulah yang banyak diberitahukan kemarin. Concourse juga memiliki mitra offline dengan nama Beehive, tetapi lambat laun itu semakin mengalir.
Tercatat beberapa poin lagi:
- Dedupilasi itu penting, dan berkualitas tinggi, mengingat keberadaan banyak saluran dan konten.
- Penting untuk memiliki platform. Dan mereka memiliki tim platform khusus, dan programmer bekerja di sana.
Pendekatan Pinterest untuk Pembelajaran mesin
Seorang
juru bicara Pinterest sekarang berbicara dan berbicara tentang dua tugas besar yang menggunakan umpan-ML (homefeed) dan pencarian. Pembicara segera mengatakan bahwa produk akhir adalah hasil kerja tidak hanya dari para ilmuwan data, tetapi juga para insinyur dan programmer ML - orang telah dialokasikan untuk mereka semua.
Rekaman (situasi ketika tidak ada niat pengguna) dibangun sesuai dengan model berikut:
- Kami memahami pengguna - kami menggunakan informasi dari profil, grafik, interaksi dengan pin (yang saya lihat saya tendang), kami membangun embedings sesuai dengan perilaku dan atribut.
- Kami memahami konten - kami melihatnya dalam semua aspek: visual, tekstual, siapa penulis, dewan mana yang terlibat, siapa yang bereaksi. Sangat penting untuk diingat bahwa orang-orang dalam satu gambar sering melihat hal-hal yang berbeda: seseorang memiliki aksen biru dalam desain, seseorang memiliki perapian, dan seseorang memiliki dapur.
- Menyatukan semuanya - prosedur tiga langkah: kami menghasilkan kandidat (rekomendasi + langganan), mempersonalisasi (menggunakan model peringkat), dan berbaur sesuai dengan kebijakan dan aturan bisnis.
Untuk rekomendasi, mereka menggunakan jalan acak di bawah grafik papan-pengguna, mereka memperkenalkan PinSage, tentang apa yang mereka bicarakan
kemarin . Personalisasi telah berkembang dari penyortiran waktu, melalui model linear dan GBDT ke jaringan saraf (sejak 2017). Saat mengumpulkan daftar akhir, penting untuk tidak melupakan aturan bisnis: kesegaran, variasi, filter tambahan. Kami mulai dengan heuristik, sekarang kami bergerak ke arah model optimasi konteks secara keseluruhan sehubungan dengan tujuan.
Dalam situasi pencarian (ketika ada niat) mereka bergerak sedikit berbeda: mereka mencoba untuk lebih memahami niat. Untuk melakukan ini, gunakan pemahaman kueri dan teknik perluasan kueri, dan ekstensi dibuat tidak hanya dengan pelengkapan otomatis, tetapi melalui navigasi visual yang indah. Mereka menggunakan teknik berbeda untuk bekerja dengan gambar dan teks. Kami mulai pada tahun 2014 tanpa pembelajaran dalam, meluncurkan Pencarian Visual dengan pembelajaran dalam pada tahun 2015, pada tahun 2016 menambahkan deteksi objek dengan analisis dan pencarian semantik, baru-baru ini meluncurkan layanan Lens - Anda mengarahkan kamera smartphone pada subjek dan mendapatkan pin. Dalam pembelajaran yang mendalam, mereka secara aktif menggunakan multi-tugas: ada blok umum yang membangun penyematan gambar. dan jaringan lain di atas untuk menyelesaikan masalah yang berbeda.
Selain tugas-tugas ini, ML lebih banyak digunakan di mana: pemberitahuan / iklan / spam / perkiraan, dll.
Sedikit tentang pelajaran yang dipetik:
- Kita harus ingat tentang bias, salah satu "kaya semakin kaya" (kecenderungan pembelajaran mesin untuk mentransfer lalu lintas ke objek yang sudah populer).
- Adalah wajib untuk menguji dan memantau: implementasi grid pada awalnya sangat meruntuhkan semua indikator, kemudian ternyata karena bug, distribusi fitur telah lama melayang dan void muncul online.
- Infrastruktur dan platform sangat penting, dengan penekanan khusus pada kenyamanan dan paralelisasi eksperimen, tetapi Anda harus dapat memotong eksperimen secara offline.
- Metrik dan pemahaman: offline tidak menjamin online, tetapi untuk interpretasi model, kami membuat alat.
- Membangun ekosistem yang berkelanjutan: tentang filter sampah dan clickbait, pastikan untuk menambahkan umpan balik negatif ke UI dan model.
- Ingatlah untuk memiliki lapisan untuk menyematkan aturan bisnis.
Grafik Pengetahuan Luas oleh Amazon
Sekarang seorang
gadis dari Amazon sedang bermain.
Ada grafik pengetahuan - node entitas, tepi atribut, dll. - yang dibangun secara otomatis, misalnya, di Wikipedia. Mereka membantu menyelesaikan banyak masalah. Kami ingin mendapatkan hal serupa untuk produk, tetapi ada banyak masalah dengan ini: tidak ada input data terstruktur, produk dinamis, ada banyak aspek yang tidak sesuai dengan model grafik pengetahuan (itu bisa diperdebatkan, menurut saya, lebih tepatnya “jangan berbohong tanpa komplikasi serius dari struktur "), Banyak vertikal dan" entitas yang tidak disebutkan namanya. " Ketika konsep itu "dijual" kepada manajemen dan menerima lampu hijau, para pengembang mengatakan bahwa itu adalah "proyek selama seratus tahun", dan sebagai hasilnya mereka berhasil dalam 15 bulan kerja.
Kami mulai dengan mengekstraksi entitas dari direktori Amazon: ada beberapa jenis struktur di sini, meskipun bersumber dari crowdsourced dan kotor. Selanjutnya, mereka menghubungkan OpenTag (dijelaskan lebih rinci kemarin) untuk pemrosesan kata. Dan komponen ketiga adalah Ceres - alat untuk parsing dari web, dengan mempertimbangkan pohon DOM. Idenya adalah dengan memberi anotasi pada salah satu halaman situs, Anda dapat dengan mudah menguraikan sisanya - setelah semua, semua dihasilkan oleh templat (tetapi ada banyak nuansa). Untuk melakukan ini, kami menggunakan sistem markup Vertex (dibeli oleh Amazon pada 2011) - mereka membuat markup di dalamnya, berdasarkan itu seperangkat xpath dibuat untuk mengisolasi atribut, dan regresi logistik menentukan yang berlaku di halaman tertentu. Untuk menggabungkan informasi dari situs yang berbeda, gunakan hutan acak. Mereka juga menggunakan pelatihan aktif, halaman kompleks dikirim untuk menandai ulang secara manual. Pada akhirnya, mereka melakukan pembersihan pengetahuan yang diawasi - penggolong sederhana, misalnya, merek / bukan merek.
Selanjutnya, sedikit seumur hidup. Mereka membedakan dua jenis tujuan. Roofshots adalah tujuan jangka pendek yang kami capai dengan memindahkan produk, dan Moonshots adalah tujuan yang kami mendorong batas-batas dan kepemimpinan global.
Pernikahan dan perwakilan
Setelah makan siang saya pergi ke bagian tentang cara membuat embed, terutama untuk grafik.
Menemukan Latihan Serupa dengan Representasi Semantik Bersatu
Orang-orang
memecahkan masalah menemukan tugas serupa di beberapa sistem pembelajaran online Cina. Tugas dijelaskan oleh teks, gambar, dan satu set kontsetov terkait. Kontribusi pengembang adalah untuk menyatukan informasi dari sumber-sumber ini. Konvolusi dibuat untuk gambar, embedment dilatih untuk konsep, dan juga untuk kata-kata. Word embeddings diteruskan ke LSTM berbasis Attention bersama dengan informasi tentang konsep dan gambar. Dapatkan representasi pekerjaan.

Blok yang dijelaskan di atas diubah menjadi jaringan Siam, di mana perhatian juga ditambahkan dan pada output skor kesamaan.
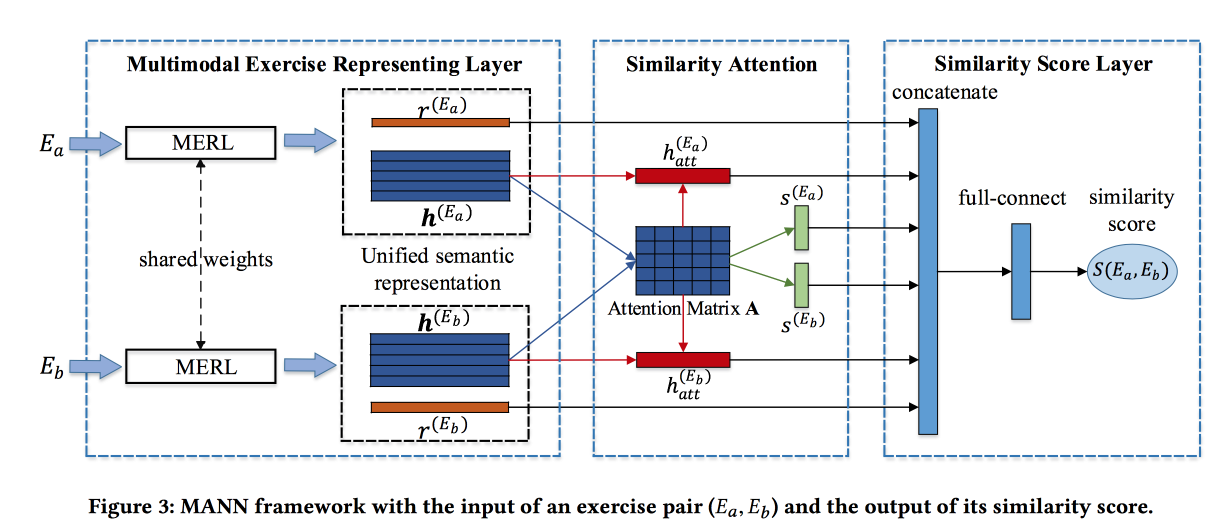
Mereka mengajar pada dataset yang ditandai dari 100 ribu latihan dan 400 ribu pasangan (total 1,5 juta latihan). Tambahkan hard negative dengan latihan pengambilan sampel dengan konsep yang sama. Matriks perhatian kemudian dapat digunakan untuk menafsirkan kesamaan.
Embedded Kedekatan Orde Jaringan Embedded
Para pria
sedang membangun varian embedding yang sangat menarik untuk grafik. Pertama, metode berdasarkan jalan dan berdasarkan tetangga dikritik karena berfokus pada "kedekatan" tingkat tertentu (sesuai dengan panjang jalan). Mereka menawarkan metode yang memperhitungkan kedekatan pesanan yang diinginkan, dan dengan bobot yang terkontrol.
Idenya sangat sederhana. Mari kita mengambil fungsi polinomial dan menerapkannya pada matriks adjacency dari grafik, dan kami memfaktorkan hasilnya dengan SVD. Dalam hal ini, tingkat anggota tertentu dari polinomial adalah tingkat kedekatan, dan bobot anggota ini adalah pengaruh tingkat ini pada hasilnya. Secara alami, ide liar ini tidak layak: setelah menaikkan matriks adjacency ke suatu daya, itu menjadi lebih padat, tidak muat ke dalam memori dan Anda memfaktorkan ara seperti itu.
Tanpa matematika, itu adalah sampah, karena jika Anda menerapkan fungsi polinomial ke hasil SETELAH ekspansi, maka kami mendapatkan hal yang persis sama seperti jika ekspansi diterapkan ke matriks besar. Sebenarnya tidak juga. Kami mempertimbangkan SVD kira-kira dan hanya menyisakan nilai eigen paling atas, tetapi setelah menerapkan polinomial, urutan nilai eigen dapat berubah, jadi Anda perlu mengambil angka dengan margin.

Algoritma menawan dengan kesederhanaannya dan menunjukkan hasil yang menakjubkan dalam tugas prediksi tautan.

NetWalk: Pendekatan Penyisipan Jauh yang Fleksibel untuk Deteksi Anomali di Jaringan Dinamis
Seperti namanya,
kita akan membangun embed grafik berdasarkan walks. Tapi bukan hanya, tetapi dalam mode streaming, karena kami memecahkan masalah mencari anomali di jaringan dinamis (ada pekerjaan pada topik ini kemarin). Untuk membaca dan memperbarui embedment dengan cepat, mereka menggunakan konsep "
reservoir ", di mana terdapat sampel grafik dan diperbarui secara stokastik ketika perubahan diterima.
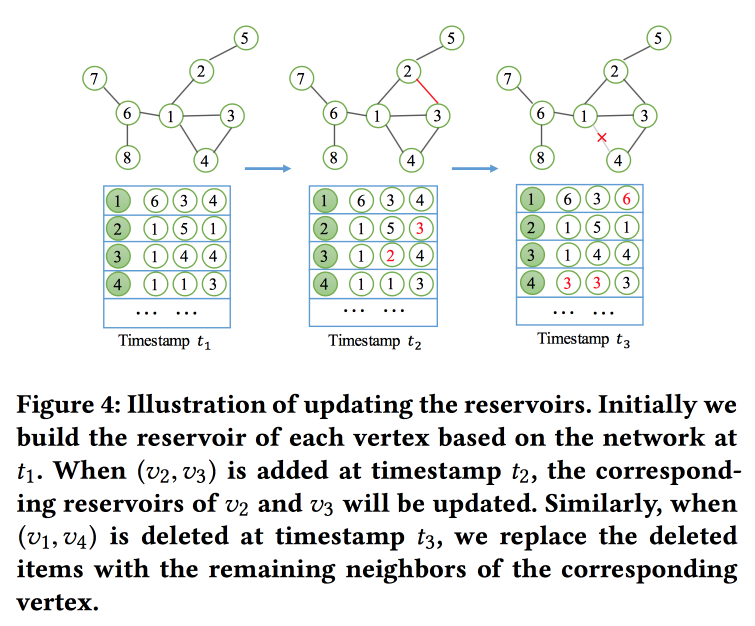
Untuk pelatihan, mereka merumuskan tugas yang agak rumit dengan beberapa tujuan, yang utama adalah kedekatan embed untuk node dalam satu jalur dan kesalahan minimum ketika memulihkan jaringan dengan auto-encoder.
Penyisipan Jaringan Sadar Taksonomi Hierarkis
Pilihan lain
untuk membuat embed untuk grafik, kali ini berdasarkan pada model pembangkit probabilistik. Kualitas embeddings ditingkatkan dengan menggunakan informasi dari taksonomi hirarkis (misalnya, domain pengetahuan untuk jaringan kutipan atau kategori produk untuk produk dalam e-tail). Proses pembuatan dibangun di atas beberapa "topik", beberapa di antaranya terkait dengan simpul dalam taksonomi, dan beberapa ke simpul tertentu.
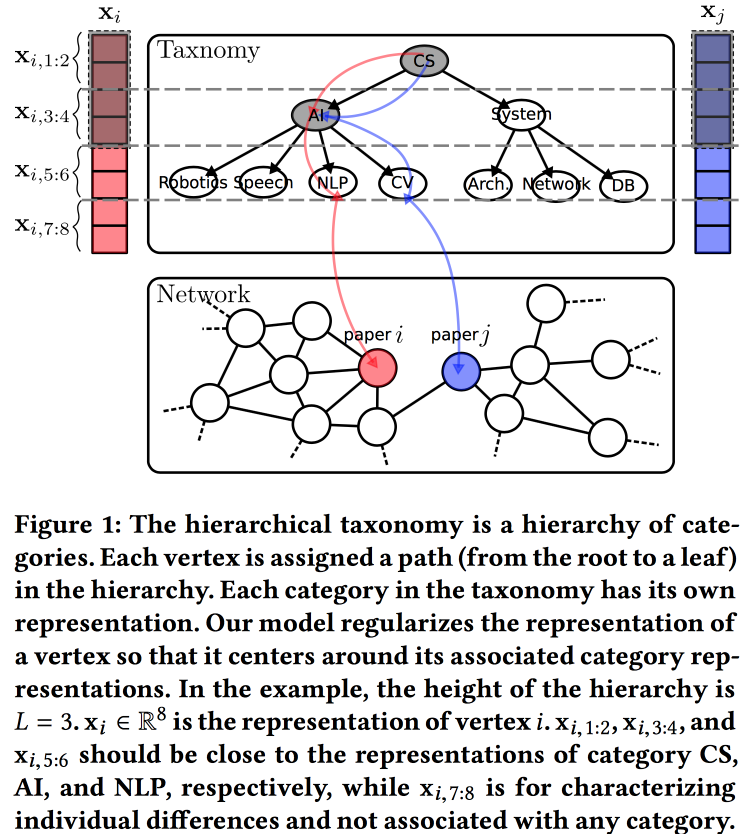
Kami mengasosiasikan distribusi normal a priori dengan rata-rata nol dengan parameter taksonomi, parameter verteks tertentu dalam taksonomi - distribusi normal dengan rata-rata sama dengan parameter taksonomi, dan distribusi normal dengan dispersi nol rata-rata dan tak terbatas untuk parameter bebas dari simpul. Kami menghasilkan lingkungan vertex menggunakan distribusi Bernoulli, di mana probabilitas keberhasilan sebanding dengan kedekatan parameter node. Kami mengoptimalkan seluruh raksasa ini dengan
algoritma-EM .
Penyisipan Jaringan Rekursif Dalam dengan Kesetaraan Reguler
Teknik penyematan umum tidak berfungsi untuk semua tugas. Misalnya, pertimbangkan peran tugas simpul. Untuk menentukan peran, bukan tetangga spesifik (yang biasanya dilihat) yang penting, tetapi struktur grafik di sekitar titik dan beberapa pola di dalamnya. Pada saat yang sama, sangat sulit untuk secara algoritmik mencari pola-pola ini (kesetaraan reguler) secara langsung, tetapi untuk grafik besar itu tidak realistis.
Karena itu, kita akan pergi ke
arah lain . Untuk setiap node, kami menghitung parameter yang terkait dengan grafiknya: derajat, kepadatan, berbagai pusat, dll. Embedding tidak dapat dibangun di atasnya saja, tetapi rekursi dapat digunakan, karena keberadaan pola yang sama menyiratkan bahwa atribut tetangga dari dua node dengan peran yang sama harus serupa. Yang berarti Anda dapat menumpuk lebih banyak lapisan.
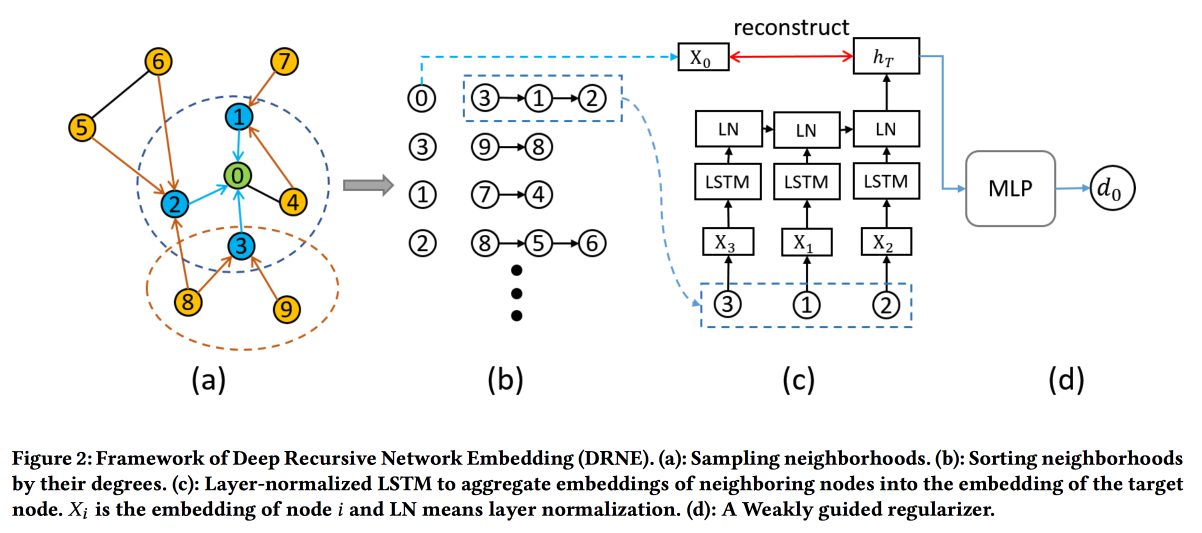
Validasi menunjukkan bahwa mereka mem-bypass garis dasar standar DeepWalk dan node2wek pada banyak tugas.
Menanamkan Jaringan Temporal melalui Formasi Lingkungan
Pekerjaan penyematan grafik terbaru untuk hari ini. Kali ini kita akan melihat dinamika: kita akan mengevaluasi momen koneksi dan semua fakta interaksi dalam waktu. Ambil jaringan kutipan sebagai contoh, di mana interaksi adalah publikasi bersama.
Kami menggunakan Proses Hawkes untuk memodelkan bagaimana interaksi vertex masa lalu mempengaruhi interaksi masa depan mereka. HP . attention . log likelihood . .
Safety
. , . , ML , , .
Using Machine Learning to Assess the Risk of and Prevent Water Main Breaks
: , , — . , . , ( - , ), 1-2 % . ,
.
data miner-
Data Science for Social Good . , , :

, . : , GBDT. -1 % .
base line-: « » , , « , » . ML, , .
27 32- , , , ( , — ). , $1,2 .
, , , 1940-, , ( ) .
Detecting Spacecraft Anomalies Using LSTMs and Nonparametric Dynamic Thresholding
NASA
( ). — . , . , .
ML . LSTM , . ( , ). , , . , . , .
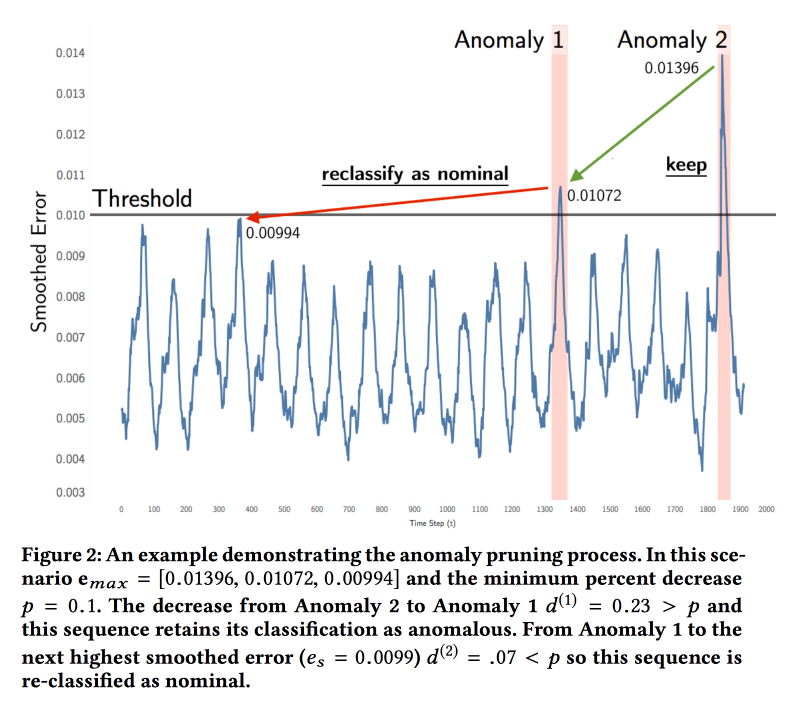
:
soil moisture active passive Curiosity c Mars Science Laboratory. 122 , 80 %. , , . , , .
Explaining Aviation Safety Incidents Using Deep Temporal Multiple Instance Learning
, , . Safety Incidents, , . , . .
, - , . «», .. , . , , . , , .
GRU ,
Multiple Instances Learning . , «» — , . « , , — » ( = ). max pooling .

cross entropy loss . base line
MI-SVM ADOPT.
ActiveRemediation: The Search for Lead Pipes in Flint, Michigan
, ,
.
. 120 . , 2013 , : . , 2014-. 2015- — . , . , …
— , . , . .
. «», . : , , , . , , — , …
6 . , 20 %. data scientist-.
, 19 , , , . , « ». , , XGBoost - . ( 7 % , ).
, -, , , — . « » .

, , 16 % 3 %. , , — Excel .
A Dynamic Pipeline for Spatio-Temporal Fire Risk Prediction
Sebagai kesimpulan, titik sakit lainnya adalah inspeksi api. Tentang apa yang terjadi jika tidak dilakukan, kami pelajari pada Maret 2018. Di AS, kasus seperti itu juga tidak jarang. Pada saat yang sama, sumber daya untuk memeriksa petugas pemadam kebakaran terbatas, mereka harus diarahkan ke tempat-tempat dengan risiko terbesar.
Ada model terbuka untuk menilai risiko kebakaran, tetapi mereka dirancang untuk kebakaran hutan dan tidak cocok untuk kota. Ada semacam sistem di New York, tetapi ditutup. Jadi, Anda perlu mencoba
membuatnya sendiri .
Bekerja sama dengan petugas pemadam kebakaran Pittsburgh, mereka mengumpulkan data tentang kebakaran selama beberapa tahun, menambahkan informasi tentang demografi, pendapatan, bentuk bisnis, dll., Serta panggilan lain ke departemen pemadam kebakaran yang tidak terkait dengan kebakaran. Dan mereka mencoba menilai risiko kebakaran berdasarkan data ini.
Dua model XGBoost berbeda diajarkan: untuk rumah tangga dan real estat komersial. Kualitas pekerjaan dievaluasi, pertama-tama, menurut
Kappa mengingat ketidakseimbangan kelas yang kuat.
Menambahkan faktor dinamis (panggilan ke pemadam kebakaran, memicu detektor / alarm) ke model secara signifikan meningkatkan kualitas, tetapi untuk menggunakannya, model harus dihitung ulang setiap minggu. Berdasarkan perkiraan, model membuat moncong web yang menyenangkan untuk inspektur kebakaran yang menunjukkan di mana objek dengan risiko terbesar berada.
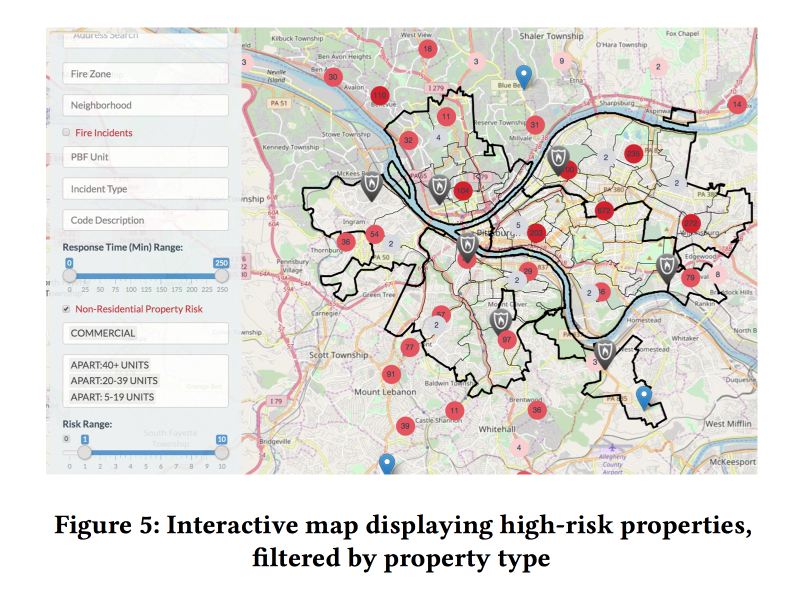
Pentingnya gejala dianalisis. Di antara fitur-fitur penting untuk perdagangan terkait dengan alarm palsu (rupanya, penutupan lebih lanjut). Tetapi untuk rumah tangga - jumlah pajak yang dibayarkan (Hai Fairness, inspeksi kebakaran di daerah miskin akan lebih sering dilakukan).