Beberapa waktu yang lalu, saya mengaktifkan uji coba gratis di Google untuk cloud mereka, saya tidak menyelesaikan masalah saya, ternyata Google memberikan $ 300 selama 12 bulan di bawah uji coba, tetapi bertentangan dengan harapan saya, batasan lain dikenakan selain batas anggaran. Sebagai contoh, saya tidak mengizinkan penggunaan mesin virtual dengan lebih dari 8 vcpu di satu wilayah. Setelah setengah tahun, saya memutuskan untuk menggunakan anggaran percobaan untuk berkenalan dengan dataproc, sebuah cluster hadup yang sudah diinstal dari Google. Tugasnya adalah mencoba mengevaluasi seberapa mudah bagi saya untuk meluncurkan proyek pada akses Google, apakah masuk akal atau lebih baik untuk segera fokus pada perangkat keras saya dan memikirkan administrasi. Saya memiliki perasaan yang samar-samar bahwa perangkat keras modern dan tumpukan bigdata harus dengan mudah beradaptasi dengan database kecil puluhan atau ratusan GB, memuat secara brutal, jika tidak seluruh dataset, maka sebagian besar ke dalam memori cluster. Beberapa subdata terpisah untuk data mart mungkin tidak lagi diperlukan.
Singkatnya, dataproc terkesan dengan kemudahan peluncuran dan pengaturan, dibandingkan dengan Oracle dan Cloudera. Pada tahap pertama, saya bermain dengan satu node cluster pada 8 vCpu, yang maksimum memungkinkan percobaan gratis. Jika Anda melihat kesederhanaan, maka teknologi mereka sudah memungkinkan seorang Hindu untuk memulai sebuah cluster dalam 15 menit, memuat data sampel dan menyiapkan laporan menggunakan alat BI biasa, tanpa sub-jendela perantara. Pengetahuan mendalam tentang Hadoup tidak lagi diperlukan sama sekali.
Pada prinsipnya, saya melihat bahwa hal itu bagus untuk memulai cepat dan untuk uang waras Anda dapat menjalankan prototipe, mengevaluasi jenis perangkat keras apa yang Anda butuhkan untuk suatu tugas. Namun, sebuah cluster yang lebih besar, dalam lusinan node, jelas akan makan lebih dari sekedar sewa + beberapa administrator yang melihat cluster tersebut. Jauh dari kenyataan bahwa cloud akan terlihat layak secara ekonomi. Langkah pertama saya mencoba untuk mengevaluasi opsi sepenuhnya mikro dengan satu node cluster 8 vCpu dan 0,5 TB data mentah. Pada prinsipnya, tes percikan + hadoop pada kelompok yang lebih besar sudah penuh di Internet, tetapi saya berencana untuk menguji opsi sedikit lebih besar nanti.
Hanya dalam satu jam, saya googled script untuk membuat cadangan cluster, mengkonfigurasi firewall dan mengkonfigurasi server hemat, yang memungkinkan jdbc untuk terhubung ke memicu sql dari Windows rumah. Saya menghabiskan dua atau tiga jam lagi mengoptimalkan pengaturan percikan default dan memuat beberapa meja kecil berukuran sekitar 10 GB (ukuran file data di Oracle). Saya mendorong seluruh tabel ke dalam memori (mengubah cache tabel;) dan memungkinkan untuk bekerja dengan mereka dari mesin Windows saya dari Dbeaver dan Tableau (melalui konektor sql spark).
Secara default, spark menggunakan hanya 1 eksekutor pada 4 vCpu, saya mengedit spark-defaults.conf, menginstal 3 eksekutor, masing-masing 2 vCpu dan untuk waktu yang lama saya tidak mengerti mengapa saya benar-benar hanya memiliki 1 eksekutor dalam pekerjaan saya. Ternyata saya tidak mengedit memori, dua benang lainnya tidak bisa mengalokasikan memori. Saya menetapkan 6,5 GB pada komputer, setelah itu ketiganya mulai naik seperti yang diharapkan.
Selanjutnya, saya memutuskan untuk bermain dengan volume yang sedikit lebih serius dan tugas yang lebih dekat ke DWH dari tes TPC-DS. Sebagai permulaan, saya secara resmi membuat tabel dengan faktor skala 500 dari alat resmi. Saya mendapat sekitar 480 GB data mentah (teks dibatasi). Tes TPC-DS adalah DWH khas, dengan fakta dan dimensi. Saya tidak mengerti bagaimana cara menghasilkan data langsung di penyimpanan google, saya harus menghasilkan mesin virtual pada disk dan kemudian menyalinnya ke penyimpanan google. Google, seperti yang saya mengerti, percaya bahwa tudung berfungsi sempurna dengan penyimpanan google dan kecepatan di sana menjanjikan sedikit lebih baik daripada jika data berada di dalam cluster pada HDFS. Dalam hal ini, sebagian beban beralih dari HDFS ke penyimpanan google.
Setelah terhubung melalui Dbeaver, saya mengkonversi file teks ke tablet berbasis parket dengan kemasan tajam menggunakan perintah SQL. 480 GB data teks dikemas ke dalam 187 parket file. Prosesnya memakan waktu sekitar dua jam, meja terbesar dalam teks ini menempati 188 GB, 3 pelaksana percikan mengubahnya menjadi parket dalam 74 menit, ukuran SUV adalah 66,8 GB. Di desktop saya dengan kira-kira 8 vCpu (i7-3770k) yang sama, saya pikir "masukkan ke tabel pilih * ..." ke dalam tabel Oracle dengan blok 8k akan memakan waktu sehari, dan berapa banyak file data yang akan diambil bahkan menakutkan untuk dibayangkan.
Selanjutnya, saya memeriksa kinerja alat BI pada konfigurasi seperti itu, membuat laporan sederhana di Tableua
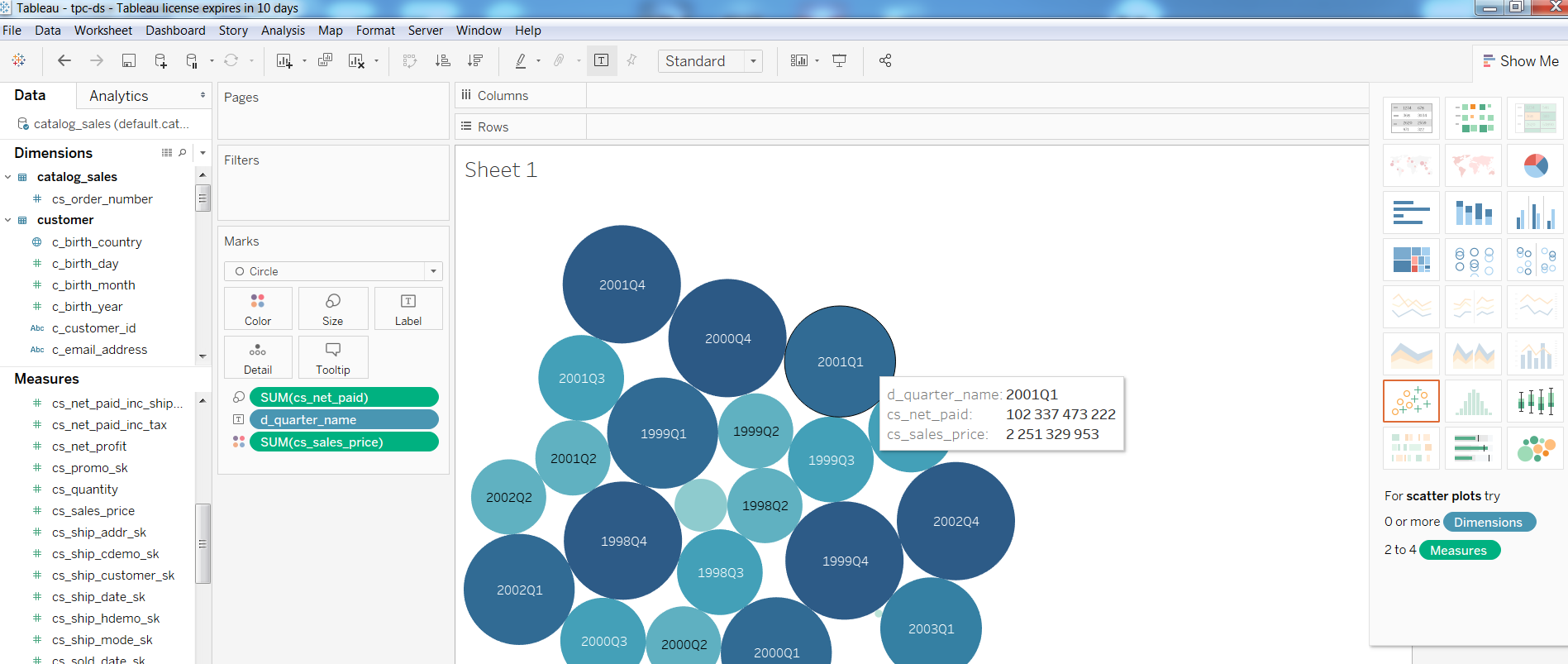
Adapun kueri, Query1 dari tes TPC-DS
Pertanyaan1WITH customer_total_return AS (SELECT sr_customer_sk AS ctr_customer_sk, sr_store_sk AS ctr_store_sk, Sum(sr_return_amt) AS ctr_total_return FROM store_returns, date_dim WHERE sr_returned_date_sk = d_date_sk AND d_year = 2001 GROUP BY sr_customer_sk, sr_store_sk) SELECT c_customer_id FROM customer_total_return ctr1, store, customer WHERE ctr1.ctr_total_return > (SELECT Avg(ctr_total_return) * 1.2 FROM customer_total_return ctr2 WHERE ctr1.ctr_store_sk = ctr2.ctr_store_sk) AND s_store_sk = ctr1.ctr_store_sk AND s_state = 'TN' AND ctr1.ctr_customer_sk = c_customer_sk ORDER BY c_customer_id LIMIT 100;
selesai pada 1:08, Query2 dengan partisipasi tabel terbesar (catalog_sales, web_sales)
Pertanyaan2 WITH wscs AS (SELECT sold_date_sk, sales_price FROM (SELECT ws_sold_date_sk sold_date_sk, ws_ext_sales_price sales_price FROM web_sales) UNION ALL (SELECT cs_sold_date_sk sold_date_sk, cs_ext_sales_price sales_price FROM catalog_sales)), wswscs AS (SELECT d_week_seq, Sum(CASE WHEN ( d_day_name = 'Sunday' ) THEN sales_price ELSE NULL END) sun_sales, Sum(CASE WHEN ( d_day_name = 'Monday' ) THEN sales_price ELSE NULL END) mon_sales, Sum(CASE WHEN ( d_day_name = 'Tuesday' ) THEN sales_price ELSE NULL END) tue_sales, Sum(CASE WHEN ( d_day_name = 'Wednesday' ) THEN sales_price ELSE NULL END) wed_sales, Sum(CASE WHEN ( d_day_name = 'Thursday' ) THEN sales_price ELSE NULL END) thu_sales, Sum(CASE WHEN ( d_day_name = 'Friday' ) THEN sales_price ELSE NULL END) fri_sales, Sum(CASE WHEN ( d_day_name = 'Saturday' ) THEN sales_price ELSE NULL END) sat_sales FROM wscs, date_dim WHERE d_date_sk = sold_date_sk GROUP BY d_week_seq) SELECT d_week_seq1, Round(sun_sales1 / sun_sales2, 2), Round(mon_sales1 / mon_sales2, 2), Round(tue_sales1 / tue_sales2, 2), Round(wed_sales1 / wed_sales2, 2), Round(thu_sales1 / thu_sales2, 2), Round(fri_sales1 / fri_sales2, 2), Round(sat_sales1 / sat_sales2, 2) FROM (SELECT wswscs.d_week_seq d_week_seq1, sun_sales sun_sales1, mon_sales mon_sales1, tue_sales tue_sales1, wed_sales wed_sales1, thu_sales thu_sales1, fri_sales fri_sales1, sat_sales sat_sales1 FROM wswscs, date_dim WHERE date_dim.d_week_seq = wswscs.d_week_seq AND d_year = 1998) y, (SELECT wswscs.d_week_seq d_week_seq2, sun_sales sun_sales2, mon_sales mon_sales2, tue_sales tue_sales2, wed_sales wed_sales2, thu_sales thu_sales2, fri_sales fri_sales2, sat_sales sat_sales2 FROM wswscs, date_dim WHERE date_dim.d_week_seq = wswscs.d_week_seq AND d_year = 1998 + 1) z WHERE d_week_seq1 = d_week_seq2 - 53 ORDER BY d_week_seq1;
selesai dalam 4:33 menit, Kueri3 dalam 3,6, Kueri4 dalam 32 menit.
Jika seseorang tertarik pada pengaturan, di bawah cut note saya tentang membuat cluster. Pada prinsipnya, hanya ada beberapa perintah gcloud dan pengaturan HIVE_SERVER2_THRIFT_PORT.
Catatanopsi satu simpul cluster:
gcloud dataproc --region europe-north1 cluster membuat test1 \
--subnet default \
--bucket tape1 \
--zone europe-north1-a \
--single-node \
--master-machine-type n1-highmem-8 \
--master-boot-disk-ukuran 500 \
--gambar-versi 1.3 \
--inisiasi-tindakan gs: //dataproc-initialization-actions/hue/hue.sh \
--inisiasi-tindakan gs: //dataproc-initialization-actions/zeppelin/zeppelin.sh \
--inisiasi-tindakan gs: //dataproc-initialization-actions/hive-hcatalog/hive-hcatalog.sh \
--proyek 123
opsi untuk 3 node:
gcloud dataproc --region europe-north1 cluster \
buat cluster-test1 --bucket tape1 \
--subnet default --zone eropa-north1-a \
--master-machine-type n1-standard-1 \
--master-boot-disk-size 10 --num-worker 2 \
- pekerja-mesin-tipe n1-standar-1 - pekerja-boot-disk-ukuran 10 \
--inisiasi-tindakan gs: //dataproc-initialization-actions/hue/hue.sh \
--inisiasi-tindakan gs: //dataproc-initialization-actions/zeppelin/zeppelin.sh \
--inisiasi-tindakan gs: //dataproc-initialization-actions/hive-hcatalog/hive-hcatalog.sh \
--proyek 123
hitung gcloud --project = 123 \
aturan firewall membuat allow-dataproc \
--direction = INGRESS --priority = 1000 --network = default \
--action = ALLOW --rules = tcp: 8088, tcp: 50070, tcp: 8080, tcp: 10010, tcp: 10000 \
--source-rentang = xxx.xxx.xxx.xxx / 32 --target-tags = dataproc
di master node:
sudo su - vi / usr/lib/spark/conf/spark-env.sh
ubah: ekspor HIVE_SERVER2_THRIFT_PORT = 10010
sudo -u spark / usr/lib/spark/sbin/start-thriftserver.sh
Dilanjutkan ...