
Jadi hari kelima, hari terakhir KDD berakhir. Saya berhasil mendengar beberapa laporan menarik dari Facebook dan Google AI, mengingat taktik sepakbola dan menghasilkan beberapa bahan kimia. Tentang ini dan tidak hanya - di bawah luka. Sampai jumpa setahun di Anchorage, ibu kota Alaska!
Tentang Data Besar Belajar untuk Masalah Data Kecil
Laporan pagi dari
profesor Cina itu sulit. Pembicara dengan jelas memuat selama persiapan, sering tersesat, mulai melewatkan slide, dan bukannya berbicara seumur hidup, mencoba memuat otak yang mengantuk dengan matematika.
Garis besar umum dari cerita ini berkisar pada gagasan bahwa selalu ada banyak data. Misalnya, ada ekor panjang di mana ada banyak contoh yang beragam. Ada kumpulan data dengan sejumlah besar kelas, yang, meskipun besar dalam dirinya sendiri, hanya memiliki beberapa catatan untuk setiap kelas. Sebagai contoh dataset seperti itu, ia mengutip
Omniglot - karakter tulisan tangan dari 50 huruf, kelas 1623 dan 20 gambar per kelas rata-rata. Namun pada kenyataannya, dalam perspektif ini, Anda juga dapat mempertimbangkan kumpulan tugas rekomendasi, ketika kami memiliki banyak pengguna dan tidak begitu banyak peringkat untuk masing-masing dari mereka secara individual.
Apa yang bisa dilakukan untuk membuat hidup lebih mudah bagi ML dalam situasi seperti itu? Pertama-tama cobalah untuk membawa pengetahuan dari bidang subjek ke dalamnya. Ini dapat dilakukan dalam berbagai bentuk: ini adalah rekayasa fitur, dan regularisasi khusus, dan penyempurnaan arsitektur jaringan. Solusi umum lainnya adalah transfer learning, saya pikir hampir semua orang yang bekerja dengan gambar memulai dengan meningkatkan beberapa ImageNet dari data mereka. Dalam kasus Omniglot, donor alami untuk transfer adalah
MNIST .
Salah satu bentuk transfer dapat berupa
pembelajaran multi-tugas , yang sudah beberapa kali dibicarakan oleh KDD. Pengembangan MTL dapat dianggap sebagai pendekatan
meta learning - dengan melatih algoritma pada sampel dari berbagai tugas, kita dapat BELAJAR tidak hanya parameter, tetapi juga hiperparameter (tentu saja, hanya jika prosedur kami dapat dibedakan).
Melanjutkan topik multi-tugas, kita bisa sampai pada konsep pembelajaran berkelanjutan seumur hidup, yang dapat paling jelas ditunjukkan oleh contoh robotika. Robot harus dapat menyelesaikan masalah yang berbeda, dan ketika mempelajari tugas baru untuk menggunakan pengalaman sebelumnya. Tetapi Anda dapat mempertimbangkan pendekatan ini dengan contoh Omniglot: setelah mempelajari salah satu karakter, Anda dapat melanjutkan untuk belajar berikutnya, menggunakan akumulasi pengalaman. Benar, masalah
lupa bencana yang berbahaya menanti kita di sepanjang jalan ini, ketika algoritme mulai melupakan apa yang telah dipelajarinya sebelumnya (untuk mengatasi ini, disarankan untuk mengatur
EWC ).
Selain itu, pembicara berbicara tentang beberapa karyanya dalam arah ini.
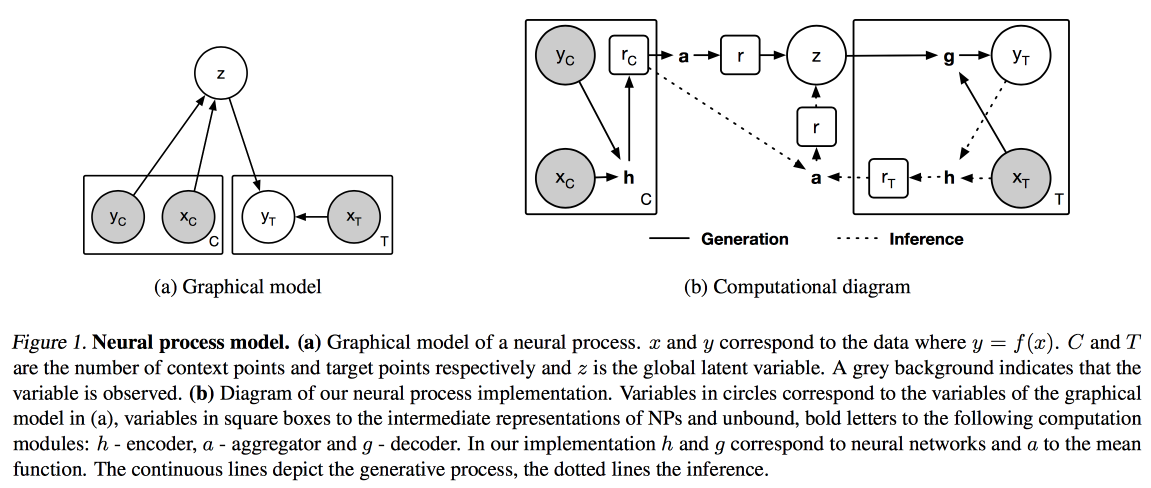
Neural Processes (analogi proses Gaussian untuk jaringan saraf) dan
Distil and Transfer Learning (optimasi pembelajaran transfer untuk kasus ketika kita tidak mengambil model yang sebelumnya dilatih sebagai dasar, tetapi melatih kita dalam mode multi-tugas).
Gambar Dan Teks
Hari ini saya memutuskan untuk berjalan menggunakan laporan terapan, di pagi hari tentang bekerja dengan teks, gambar, dan video.
Layanan konversi Corpus
Frekuensi publikasi berkembang sangat cepat, sulit untuk bekerja dengan ini, terutama mengingat kenyataan bahwa hampir seluruh pencarian dilakukan dalam teks. IBM
menawarkan layanannya untuk menandai lampiran pengetahuan Ilmiah 3.0. Alur kerja utama terlihat seperti ini:
- Parsim PDF, kenali teks dalam gambar.
- Kami memeriksa apakah ada model untuk bentuk teks ini, jika demikian, kami membuat ekstrak semantik dengannya.
- Jika tidak ada model, kami mengirim anotasi dan melatih.
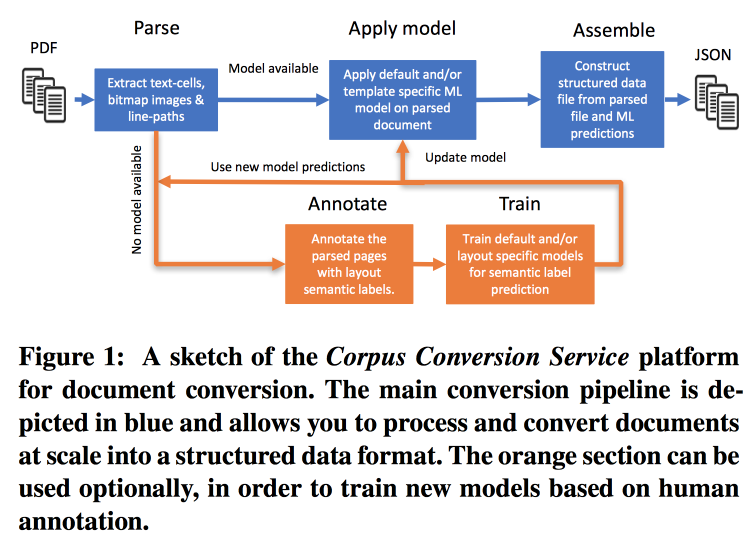
Untuk melatih model, kita mulai dengan pengelompokan berdasarkan struktur. Dalam sebuah cluster menggunakan crowdsourcing, kami tata letak beberapa halaman. Ternyata mencapai akurasi> 98% saat pelatihan penandaan 200-300 dokumen. Ada ketidakseimbangan kelas yang kuat dalam markup (hampir semuanya ditandai sebagai teks), jadi Anda perlu melihat keakuratan semua kelas dan matriks kebingungan.
Model memiliki struktur hierarkis. Misalnya, satu model mengenali suatu tabel, dan yang lainnya memotong baris / kolom / header (dan ya, sebuah tabel dapat disarangkan dalam sebuah tabel). Sebagai model, jaringan konvolusional digunakan.
Untuk semua ini, mereka mengumpulkan conveyor di Docker dengan Kubernetes dan siap untuk mengunduh corpus teks Anda dengan biaya yang masuk akal. Mereka dapat bekerja tidak hanya dengan teks PDF, tetapi juga dengan pemindaian, mereka mendukung bahasa oriental. Selain hanya mengeluarkan teks, mereka bekerja untuk mengekstraksi grafik pengetahuan, mereka berjanji untuk memberi tahu rincian tentang KDD berikutnya.
Ekspansi Kueri Langka Melalui Jaringan Adversarial Generatif dalam Iklan Penelusuran
Mesin pencari menghasilkan uang paling banyak dari iklan, dan iklan ditampilkan tergantung pada apa yang dicari pengguna. Tetapi perbandingannya tidak selalu jelas. Misalnya, atas permintaan tiket pesawat, menampilkan iklan tiket bus murah tidak terlalu benar, tetapi expedia akan melakukannya dengan baik, tetapi Anda tidak dapat memahaminya dengan kata kunci. Model pembelajaran mesin mungkin membantu, tetapi mereka tidak bekerja dengan baik dengan permintaan yang jarang.
Untuk mengatasi masalah ini, untuk memperluas kueri penelusuran,
kami akan melatih GAN Bersyarat sesuai dengan model urutan-ke-urutan. Kami menggunakan jaringan berulang (2-layer GRU) sebagai arsitektur. Kami memodifikasi min-max dari GAN, mencoba mengarahkannya untuk menambahkan kata kunci yang ada klik pada iklan.
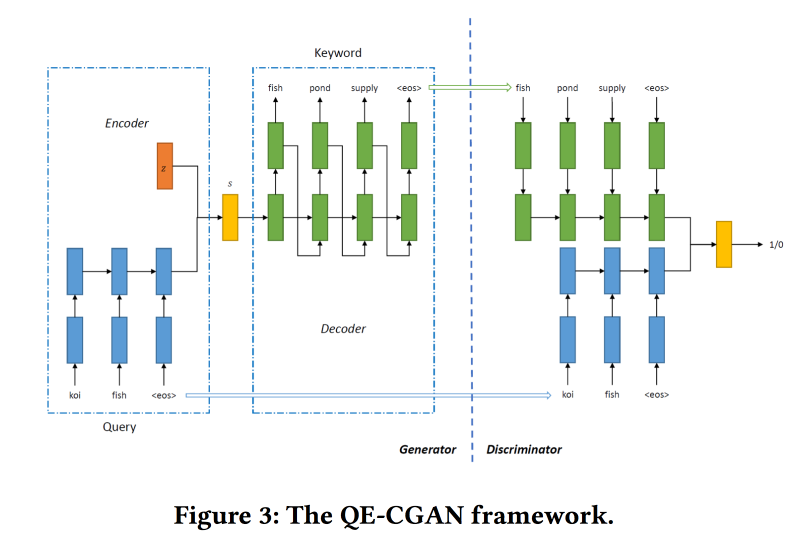
Dataset untuk pelatihan tentang 14 juta kueri dan 4 juta kata kunci iklan. Model yang diusulkan bekerja lebih baik pada bagian panjang permintaan, yang dilakukan. Namun di kepala, kinerjanya tidak lebih tinggi.
Pembelajaran Metrik Jauh Kolaboratif untuk Pemahaman Video
Pekerjaan ini disajikan oleh orang-orang dari Google AI. Mereka ingin membuat embeddings video yang bagus dan kemudian menggunakannya dalam video, rekomendasi, anotasi otomatis yang serupa, dll. Ia bekerja sebagai berikut:
- Dari video, kami mencicipi bingkai - gambar dan sepotong trek audio.
- Kami mengekstrak fitur dari gambar yang dipelajari sebelumnya oleh Inception.
- Kami melakukan hal yang sama dengan fragmen audio (arsitektur jaringan spesifik tidak ditampilkan). Pada tanda-tanda yang diperoleh, kami menggantung jerat yang terhubung penuh dengan menarik oleh bingkai. Kami dinormalkan dengan L2.
- Selanjutnya, poin yang menarik - kami berusaha untuk memastikan bahwa video serupa dekat dalam hal kesamaan kolaboratif. Untuk melakukan ini, kami menggunakan triplet loss dalam pelatihan (kami mengambil objek, sampel itu mirip dan berbeda, kami memastikan bahwa embeddings dari yang berbeda lebih jauh dari yang asli daripada yang serupa). Jangan lupa bahwa Anda perlu menggunakan penambangan negatif.

Mereka digunakan untuk awal yang dingin dalam video yang serupa, tetapi ada beberapa masalah: dengan kesamaan visual, mereka dapat menemukan video dalam bahasa lain atau video pada topik yang berbeda (terutama relevan untuk format video "board and lecturer"). Sarankan Anda untuk menggunakan meta-informasi tambahan tentang video.
Ada masalah dengan rekomendasinya: Anda harus mencocokkan riwayat penjelajahan dan 5 miliar video dari Youtube. Untuk mempercepat pekerjaan, kami menghitung bagi pengguna vektor rata-rata penyematan video yang ditonton. Diperiksa di
movielens , dipompa trailer dari Youtube untuk dianalisis. Mereka menunjukkan bahwa bagi pengguna dengan sejumlah kecil peringkat itu berfungsi lebih baik.
Dalam masalah anotasi video,
campuran pendekatan
ahli digunakan: mereka melatih pada logreg untuk menanamkan untuk setiap anotasi yang mungkin. Diperiksa di
Youtube-8 dan menunjukkan hasil yang sangat bagus.
Nama Disambiguasi di AMiner: Clustering, Maintenance, dan Human in the Loop
AMiner - grafik untuk akademi, menyediakan berbagai layanan untuk bekerja dengan literatur. Salah satu masalah: tabrakan nama penulis dan entitas. Algoritma otomatis dengan beberapa bentuk pembelajaran aktif
ditawarkan sebagai solusi.
Prosesnya terdiri dari tiga tahap: menggunakan pencarian teks, kami mengumpulkan kandidat (dokumen dengan nama penulis yang serupa), klaster (dengan penentuan otomatis jumlah cluster) dan membangun profil.

Untuk mempertimbangkan kesamaan dalam pengelompokan, Anda memerlukan beberapa jenis presentasi (pemunculan). Ini dapat diperoleh dengan menggunakan model global (seluruh grafik) atau lokal (untuk kandidat yang dijadikan sampel). Pola tangkapan global yang dapat ditransfer ke dokumen baru, dan lokal membantu untuk mempertimbangkan karakteristik individu - kami akan menggabungkan. Untuk mendapatkan penanaman global, mereka juga menggunakan jaringan Siam yang terlatih dalam kehilangan triplet, dan untuk yang lokal - grafik auto-encoder (saya meninggalkan gambar di artikel demi menghemat ruang).
Pertanyaan yang paling menyakitkan adalah berapa banyak cluster yang saya miliki? Pendekatan
X-means tidak skala ke sejumlah besar cluster, RNN digunakan untuk memprediksi jumlah mereka: K cluster diambil dari set yang ditandai, kemudian N contoh dari cluster ini. Mereka melatih jaringan untuk mengungkapkan jumlah awal cluster.

Data tiba cukup cepat, 500 ribu sebulan, tetapi butuh berminggu-minggu untuk menjalankan seluruh model. Untuk inisialisasi cepat, mereka menggunakan pilihan kandidat untuk pencarian teks dan IPN untuk pernikahan global. Poin penting: orang-orang yang menandai apa yang seharusnya dan tidak seharusnya berada dalam kelompok dimasukkan dalam proses pembelajaran. Pada data ini, model dilatih ulang.
Rosetta: Sistem skala besar untuk deteksi dan pengenalan teks dalam gambar
Orang-orang dari FB
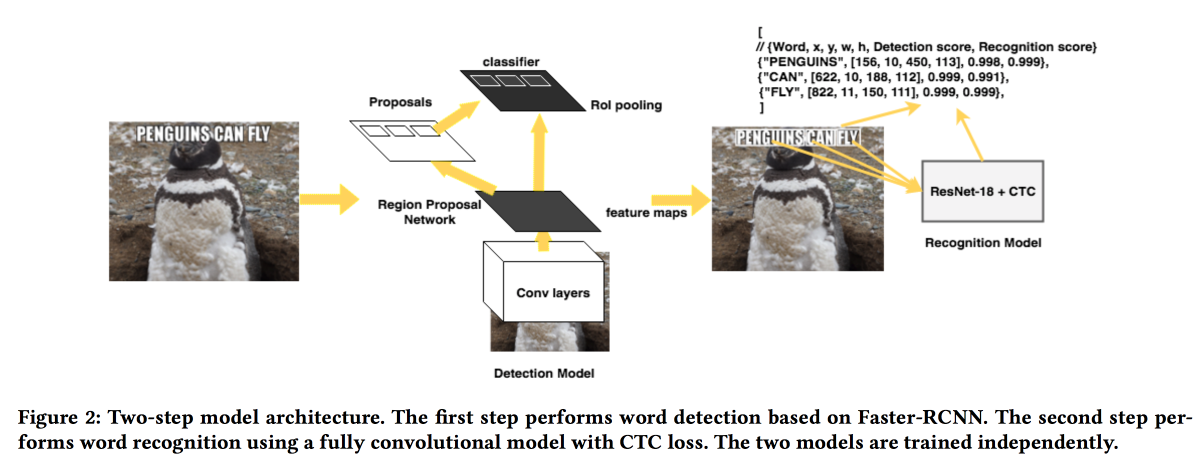
akan menyajikan solusi mereka untuk mengekstraksi teks dari gambar. Model ini bekerja dalam dua tahap: jaringan pertama menentukan teks, yang kedua mengenalinya.
Faster-RCNN digunakan sebagai detektor dengan penggantian ResNet dengan
SuffleNet untuk mempercepat pekerjaan. Untuk pengakuan, mereka menggunakan ResNet18 dan dilatih menggunakan
CTC loss .
Untuk meningkatkan konvergensi, kami menggunakan beberapa trik:
- Selama pelatihan, suara kecil dimasukkan ke dalam hasil detektor.
- Teks-teks itu direntangkan secara horizontal sebesar 20%.
- Pembelajaran kurikulum yang digunakan - contoh-contoh yang rumit secara bertahap (berdasarkan jumlah karakter).
Ilmu alam
Bagian konten terakhir di konferensi dikhususkan untuk "ilmu alam". Sedikit chemistry, sepakbola, dan lainnya.
Tingkat Penemuan Salah Dikendalikan Deteksi Efek Perawatan heterogen untuk Eksperimen Terkontrol Online
Pekerjaan yang sangat menarik pada analisis tes A / B. Masalah dengan sebagian besar sistem analisis adalah mereka melihat efek rata-rata, sementara pada kenyataannya, sebagian besar pengguna bereaksi terhadap perubahan secara positif dan beberapa negatif, dan lebih banyak yang dapat dicapai jika Anda memahami ke mana fitur tersebut pergi dan siapa tidak

Anda dapat membagi pengguna ke dalam kohort terlebih dahulu dan mengevaluasi efeknya, tetapi dengan peningkatan jumlah kohort, jumlah positif palsu meningkat (Anda dapat mencoba menguranginya menggunakan metode
Bonferoni , tetapi terlalu konservatif). Selain itu, Anda harus mengetahui kohort sebelumnya. Orang-orang menyarankan menggunakan kombinasi beberapa pendekatan: menggabungkan mekanisme deteksi efek heterogen (HTE) dengan metode penyaringan positif palsu.
Untuk mendeteksi efek heterogen, sebuah matriks dengan
x=0/1 0/1 (dalam grup atau tidak) dan efeknya ditransformasikan menjadi matriks di mana bukannya
0/1 terletak angka
(x — p)/p(1-p) , di mana
p adalah probabilitas inklusi dalam tes. Selanjutnya, model untuk memprediksi efek
x (regresi linier atau laso) diajarkan. Para pengguna yang hasilnya berbeda secara signifikan dari perkiraan adalah kandidat untuk pemisahan menjadi efek "heterogen".
Selanjutnya, kami mencoba dua metode untuk filter positif palsu:
Benjamini-Hochberg dan
Knockoffs . Yang pertama jauh lebih mudah diimplementasikan, tetapi yang kedua lebih fleksibel dan menunjukkan hasil yang lebih menarik.
Kutukan Pemenang: Estimasi Bias untuk Efek Total Fitur dalam Eksperimen Terkendali Online
Orang-orang dari AirBnB berbicara sedikit tentang bagaimana mereka meningkatkan sistem analisis eksperimen. Masalah utama adalah bahwa ketika bereksperimen dengan banyak bias, kami mempertimbangkan bias seleksi dalam pekerjaan ini - kami memilih eksperimen dengan hasil terbaik yang
diamati , tetapi ini berarti bahwa kita akan lebih sering memilih eksperimen di mana hasil yang diamati terlalu tinggi relatif terhadap yang asli.
Akibatnya, saat menggabungkan eksperimen, efek akhir kurang dari jumlah efek eksperimen. Tetapi mengetahui bias ini, Anda dapat mencoba untuk mengevaluasi dan mengurangi dengan menggunakan perangkat statistik (dengan asumsi bahwa perbedaan antara efek nyata dan yang diamati didistribusikan secara normal) Singkatnya, sesuatu seperti ini:

Dan jika Anda menambahkan
bootstrap , Anda bahkan dapat membangun interval kepercayaan untuk perkiraan efek yang tidak bias.
Penemuan Taktik Otomatis dalam Data Pertandingan Sepak Bola Spatio-Temporal
Pekerjaan yang menarik pada pengungkapan taktik tim sepak bola. Data pertandingan tersedia dalam bentuk urutan tindakan (lulus / sentuh / tekan, dll.), Sekitar 2.000 tindakan per pertandingan. Gabungkan atribut kontinu (koordinat / waktu) dan diskrit (pemain). Penting untuk memperluas data menggunakan pengetahuan tentang area subjek (tambahkan peran pemain dan jenis operan, misalnya), tetapi itu tidak selalu berhasil. Selain itu, berbagai jenis pengguna tertarik pada berbagai jenis pola: pelatih - sukses, striker - defensif, jurnalis - unik.
Metode yang diusulkan adalah sebagai berikut:
- Bagilah aliran menjadi fase-fase untuk transisi bola antar tim.
- Fase klaster menggunakan pembengkokan waktu dinamis sebagai jarak. Cara menentukan jumlah cluster, tidak diceritakan.
- Kami membuat peringkat kelompok berdasarkan tujuan (untuk siapa kami mencari taktik).
- Kami meminimalkan pola di dalam cluster (penambangan pola sekuensial CM-SPADE ), kami meninggalkan koordinat sesuai dengan segmen lapangan (sayap kiri / kanan, tengah, penalti).
- Beri peringkat pola lagi.
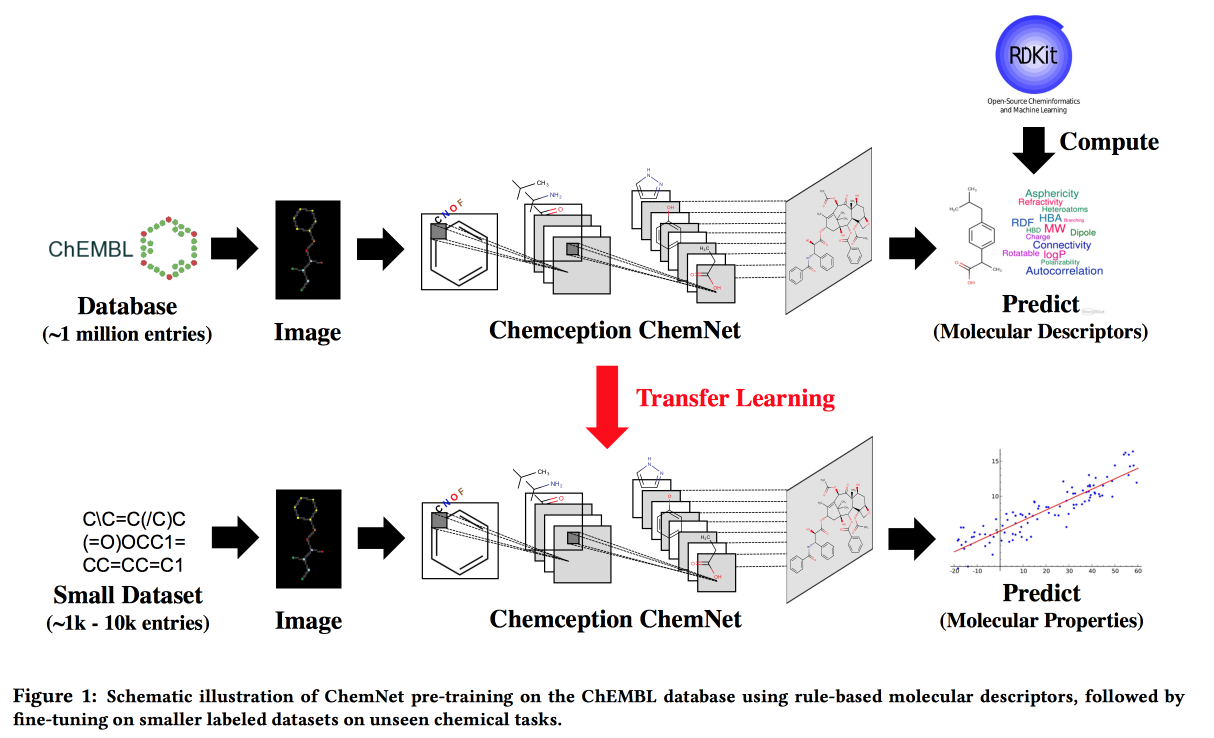
Menggunakan Label Berbasis Aturan untuk Pembelajaran yang Lemah yang Dibimbing: ChemNet untuk Properti Kimia yang Dapat Ditransfer P
Bekerja untuk situasi ketika tidak ada data besar, tetapi ada model teoritis dengan aturan hierarkis. Menggunakan teori, kami membangun jaringan saraf "ahli". Berlaku untuk tugas mengembangkan senyawa kimia dengan sifat yang diinginkan.
Saya ingin, dengan analogi dengan gambar, untuk mendapatkan jaringan di mana lapisan akan sesuai dengan berbagai tingkat abstraksi: atom / kelompok fungsional / fragmen / molekul. Di masa lalu, ada pendekatan untuk kumpulan data berlabel besar, misalnya, SMILE2Vect: gunakan
SMILE untuk menerjemahkan rumus ke dalam teks, dan kemudian menerapkan teknik untuk membuat embedding untuk teks.
Tetapi bagaimana jika tidak ada dataset bertanda besar? Kami mengajarkan ChemNet menggunakan
RDKit untuk tujuan yang dapat diprediksi, dan kemudian kami melakukan transfer pembelajaran untuk memecahkan masalah. Kami menunjukkan bahwa kami dapat bersaing dengan model yang dilatih tentang data berlabel. Anda dapat belajar berlapis-lapis, yang berarti mencapai tujuan - untuk memecah lapisan-lapisan berdasarkan tingkat abstraksi.
PrePeP - Alat untuk Identifikasi dan Karakterisasi Senyawa Gangguan Pan Assay
Kami mengembangkan obat-obatan , menggunakan ilmu data untuk memilih kandidat. Ada molekul yang bereaksi dengan banyak zat. Mereka tidak dapat digunakan sebagai obat, tetapi sering muncul pada tahap awal tes. Ini adalah molekul
PAIN yang akan kita saring.
Ada kesulitan: data habis dan sombong (107 ribu), kelas tidak seimbang (positif 0,5%), dan ahli kimia ingin mendapatkan model yang ditafsirkan. Gabungkan data dari struktur grafik (
gSpan ) dari sidik jari molekul dan kimia. Mereka berjuang dengan keseimbangan dengan mengantongi undersampling negatif, mengajar pohon, ramalan yang dikumpulkan dengan suara terbanyak.