 Agar pemantauan bermanfaat, kami harus menyusun berbagai skenario masalah yang mungkin terjadi dan merancang dasbor dan pemicu sedemikian rupa sehingga mereka segera memahami penyebab insiden tersebut.
Agar pemantauan bermanfaat, kami harus menyusun berbagai skenario masalah yang mungkin terjadi dan merancang dasbor dan pemicu sedemikian rupa sehingga mereka segera memahami penyebab insiden tersebut.
Dalam beberapa kasus, kami sangat memahami bagaimana komponen infrastruktur ini atau itu berfungsi, dan kemudian diketahui sebelumnya metrik mana yang akan berguna. Dan terkadang kami menghapus hampir semua metrik yang mungkin dengan detail maksimal dan kemudian melihat bagaimana masalah tertentu terlihat pada mereka.
Hari ini kita akan melihat bagaimana dan mengapa postgres Write-Ahead Log (WAL) dapat membengkak. Seperti biasa - contoh dari kehidupan nyata dalam gambar.
Sedikit teori WAL di postgresql
Setiap perubahan dalam database pertama kali dicatat dalam WAL, dan hanya setelah itu data di halaman dalam cache buffer diubah dan ditandai sebagai kotor - yang perlu disimpan ke disk. Selain itu, proses CHECKPOINT secara berkala dimulai, yang menyimpan semua halaman yang kotor ke disk dan menyimpan nomor segmen WAL, hingga semua halaman yang diubah sudah ditulis ke disk.
Jika tiba-tiba postgresql karena suatu alasan crash dan mulai lagi, semua segmen WAL dari pos pemeriksaan terakhir akan diputar selama proses pemulihan.
Segmen WAL sebelum pos pemeriksaan tidak lagi berguna bagi kami untuk pemulihan basis data pasca-kecelakaan, tetapi dalam postgres WAL juga berpartisipasi dalam proses replikasi, dan cadangan semua segmen untuk Pemulihan Waktu Titik - PITR juga dapat dikonfigurasi.
Seorang insinyur yang berpengalaman mungkin sudah mengerti segalanya, bagaimana itu rusak dalam kehidupan nyata :)
Mari kita lihat grafiknya!
WAL pembengkakan # 1
Agen pemantau kami untuk setiap instance postgres yang ditemukan menghitung jalur pada disk ke direktori dengan wal dan menghapus ukuran total dan jumlah file (segmen):
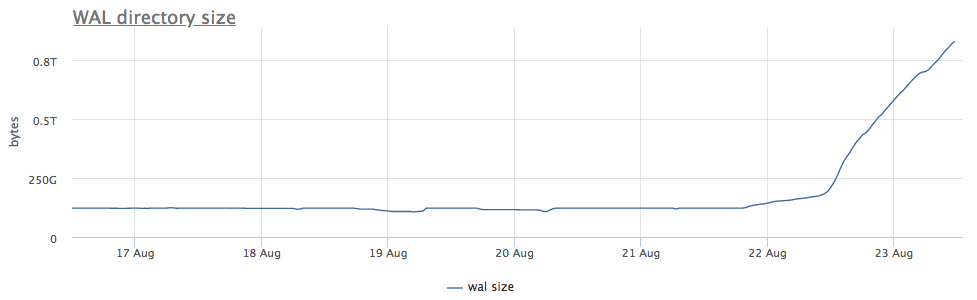
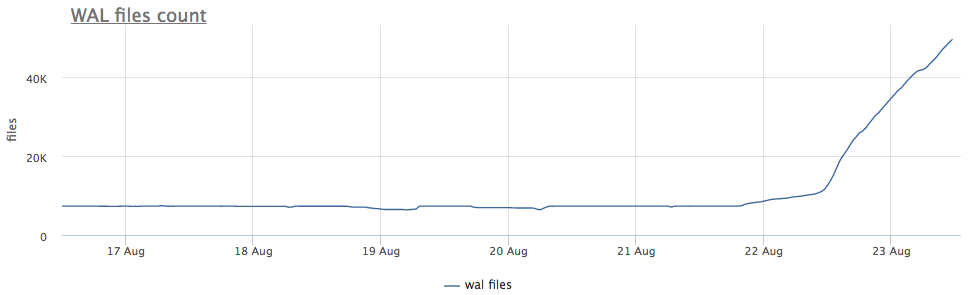
Pertama-tama, kita melihat berapa lama kita menjalankan CHECKPOINT.
Kami mengambil metrik dari pg_stat_bgwriter:
- checkpoints_timed - counter peluncuran pos pemeriksaan yang terjadi dengan syarat bahwa waktu dari pos pemeriksaan terakhir dilampaui oleh lebih dari pg_settings.checkpoint_timeout
- checkpoints_req - penghitung mulai dari pos pemeriksaan dengan ketentuan bahwa ukuran wal terlampaui dari pos pemeriksaan terakhir
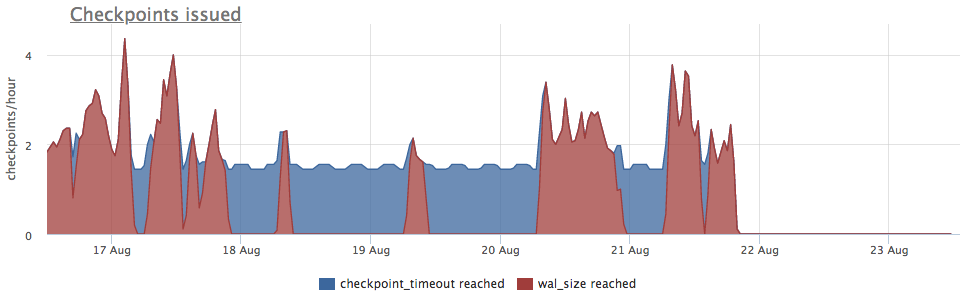
Kami melihat bahwa pos pemeriksaan belum diluncurkan untuk waktu yang lama. Dalam hal ini, tidak mungkin untuk secara langsung memahami alasan untuk TIDAK memulai proses ini (tetapi tentu saja akan keren), tetapi kita tahu bahwa dalam postgres banyak masalah muncul karena transaksi yang lama!
Kami memeriksa:

Lebih lanjut jelas apa yang harus dilakukan:
- bunuh transaksi
- berurusan dengan alasan mengapa itu panjang
- tunggu, tetapi periksa apakah ada cukup ruang
Poin penting lainnya: pada replika yang terhubung ke server ini, wal juga bengkak !
Pengarsip WAL
Saya mengingatkan Anda sesekali: replikasi bukan cadangan!
Cadangan yang baik harus memungkinkan Anda memulihkan pada waktu tertentu. Misalnya, jika seseorang "tidak sengaja" melakukan
DELETE FROM very_important_tbl;
Maka kita harus dapat mengembalikan database ke keadaan tepat sebelum transaksi ini. Ini disebut PITR (pemulihan point-in-time) dan diimplementasikan dalam postgresql dengan backup penuh berkala dari database + menyimpan semua segmen WAL setelah dump.
Pengaturan archive_command bertanggung jawab untuk membuat cadangan wal, postgres hanya memulai perintah yang Anda tentukan, dan jika selesai tanpa kesalahan, segmen dianggap berhasil disalin. Jika kesalahan terjadi, ia akan mencoba sampai kemenangan, segmen akan terletak pada disk.
Nah, dan sebagai ilustrasi - gambar dari pengarsipan yang rusak wal:
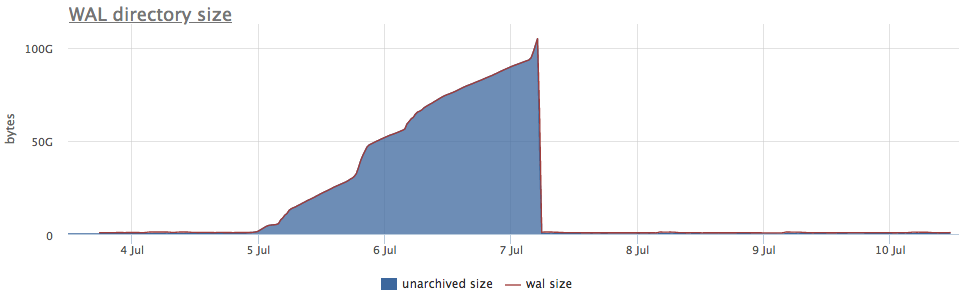
Di sini, selain ukuran semua segmen wal, ada ukuran yang belum diarsipkan - ini adalah ukuran segmen yang belum dianggap berhasil disimpan.
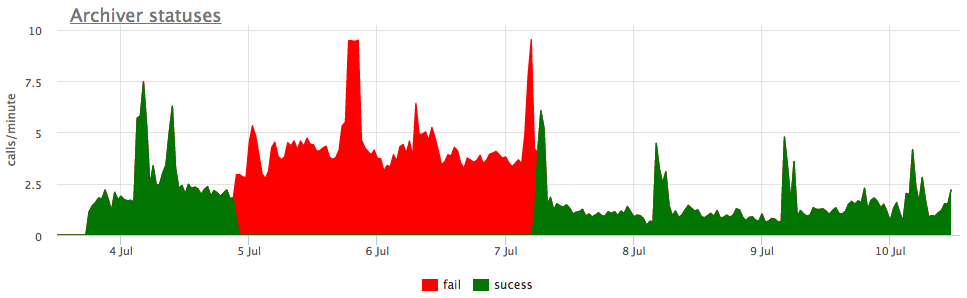
Kami mempertimbangkan status sesuai dengan penghitung dari pg_stat_archiver. Untuk jumlah file, kami membuat pemicu otomatis untuk semua klien, karena sering rusak, terutama ketika beberapa penyimpanan cloud digunakan sebagai tujuan (S3, misalnya).
Tertunda replikasi
Streaming replikasi yang sedang berjalan bekerja melalui transfer dan bermain dengan replika. Jika karena alasan tertentu replika ada di belakang dan belum kehilangan sejumlah segmen, wizard akan menyimpan segmen pg_settings.wal_keep_segments untuknya. Jika replika jatuh pada jumlah segmen yang lebih besar, itu tidak akan lagi dapat terhubung ke master (itu harus dituangkan kembali).
Untuk menjamin pelestarian sejumlah segmen yang diinginkan, fungsi slot replikasi muncul di 9.4, yang akan dibahas nanti.
Slot replikasi
Jika replikasi dikonfigurasikan menggunakan slot replikasi dan setidaknya ada satu koneksi replika yang berhasil ke slot, maka jika replika menghilang, postgres akan menyimpan semua segmen wal baru sampai tempat habis.
Artinya, slot replikasi yang terlupakan dapat menyebabkan pembengkakan. Namun untungnya, kita dapat memantau status slot melalui pg_replication_slots.
Inilah yang terlihat dalam contoh langsung:
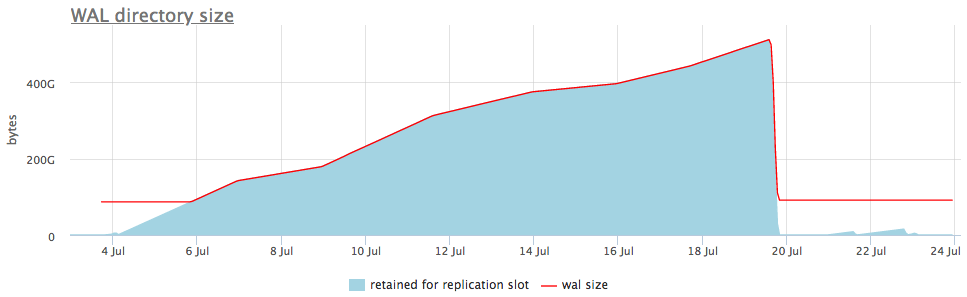

Pada grafik atas, di sebelah ukuran wal, kami selalu menampilkan slot dengan jumlah maksimum segmen terakumulasi, tetapi ada juga grafik terperinci yang akan menunjukkan slot mana yang bengkak.
Setelah kami memahami slot apa yang mengumpulkan data, kami dapat memperbaiki replika yang terkait dengannya, atau cukup menghapusnya.
Saya mengutip kasus pembengkakan wal yang paling umum, tetapi saya yakin ada kasus lain (bug di postgres juga kadang-kadang ditemukan). Oleh karena itu, penting untuk memantau ukuran wal dan menanggapi masalah sebelum ruang disk habis dan database akan berhenti melayani permintaan.
Layanan pemantauan kami sudah tahu cara mengumpulkan semua ini, memvisualisasikan dan mengingatkan dengan benar. Dan kami juga memiliki opsi pengiriman di tempat bagi mereka yang tidak cocok dengan cloud.