
Sekarang semua orang berbicara banyak tentang kecerdasan buatan dan penerapannya di semua bidang perusahaan. Namun, ada beberapa daerah di mana, sejak zaman kuno, satu jenis model telah mendominasi, yang disebut "kotak putih" - regresi logistik. Salah satu bidang tersebut adalah penilaian kredit bank.
Ada beberapa alasan untuk ini:
- Koefisien regresi dapat dengan mudah dijelaskan, tidak seperti kotak hitam seperti meningkatkan, yang dapat mencakup lebih dari 500 variabel
- Pembelajaran mesin masih belum dipercaya oleh manajemen karena kesulitan dalam menafsirkan model
- Ada persyaratan tidak tertulis dari regulator untuk interpretabilitas model: kapan saja, misalnya, Bank Sentral dapat meminta penjelasan - mengapa pinjaman kepada peminjam ditolak
- Perusahaan menggunakan program penambangan data eksternal (misalnya, penambang cepat, SAS Enterprise Miner, STATISTICA atau paket lainnya) yang memungkinkan Anda mempelajari cara membuat model dengan cepat, bahkan tanpa keterampilan pemrograman
Alasan-alasan ini membuat hampir tidak mungkin untuk menggunakan model pembelajaran mesin yang kompleks di beberapa bidang, jadi penting untuk dapat "memeras maksimal" dari regresi logistik sederhana, yang mudah dijelaskan dan ditafsirkan.
Dalam posting ini, kita akan berbicara tentang bagaimana, ketika membangun skor, kita meninggalkan paket penambangan data eksternal yang mendukung solusi open source dalam bentuk Python, meningkatkan kecepatan pengembangan beberapa kali, dan juga meningkatkan kualitas semua model.
Proses penilaian
Proses klasik membangun model penilaian pada regresi terlihat seperti ini:
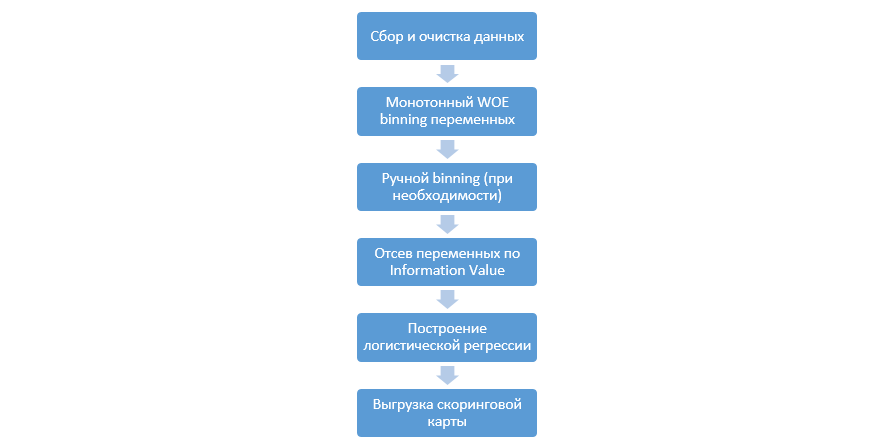
Ini dapat bervariasi dari perusahaan ke perusahaan, tetapi tahap utama tetap konstan. Kita selalu perlu melakukan binning variabel (berbeda dengan paradigma pembelajaran mesin, di mana dalam kebanyakan kasus hanya pengkodean kategoris diperlukan), penyaringan mereka dengan Nilai Informasi (IV), dan unggahan manual semua koefisien dan nampan untuk integrasi selanjutnya ke dalam DSL.
Pendekatan untuk membangun kartu penilaian ini bekerja dengan baik di tahun 90-an, tetapi teknologi paket penambangan data klasik sudah sangat ketinggalan zaman dan tidak memungkinkan penggunaan teknik baru, seperti, misalnya, regularisasi L2 dalam regresi, yang secara signifikan dapat meningkatkan kualitas model.
Pada satu titik, sebagai studi, kami memutuskan untuk mereproduksi semua langkah yang dilakukan analis ketika membangun penilaian, melengkapi mereka dengan pengetahuan Data Scientists, dan mengotomatiskan seluruh proses sebanyak mungkin.
Peningkatan python
Sebagai alat pengembangan, kami memilih Python karena kesederhanaan dan perpustakaan yang bagus, dan mulai memainkan semua langkah secara berurutan.
Langkah pertama adalah mengumpulkan data dan menghasilkan variabel - tahap ini adalah bagian penting dari pekerjaan analis.
Dengan Python, Anda bisa memuat data yang dikumpulkan dari database menggunakan pymysql.
Kode untuk diunduh dari databasedef con(): conn = pymysql.connect( host='10.100.10.100', port=3306, user='******* ', password='*****', db='mysql') return conn; df = pd.read_sql(''' SELECT * FROM idf_ru.data_for_scoring ''', con=con())
Selanjutnya, kami mengganti nilai langka dan hilang dengan kategori terpisah untuk mencegah ovefitting, pilih target, hapus kolom tambahan, dan bagi dengan kereta dan uji.
Persiapan data def filling(df): cat_vars = df.select_dtypes(include=[object]).columns num_vars = df.select_dtypes(include=[np.number]).columns df[cat_vars] = df[cat_vars].fillna('_MISSING_') df[num_vars] = df[num_vars].fillna(np.nan) return df def replace_not_frequent(df, cols, perc_min=5, value_to_replace = "_ELSE_"): else_df = pd.DataFrame(columns=['var', 'list']) for i in cols: if i != 'date_requested' and i != 'credit_id': t = df[i].value_counts(normalize=True) q = list(t[t.values < perc_min/100].index) if q: else_df = else_df.append(pd.DataFrame([[i, q]], columns=['var', 'list'])) df.loc[df[i].value_counts(normalize=True)[df[i]].values < perc_min/100, i] =value_to_replace else_df = else_df.set_index('var') return df, else_df cat_vars = df.select_dtypes(include=[object]).columns df = filling(df) df, else_df = replace_not_frequent_2(df, cat_vars) df.drop(['credit_id', 'target_value', 'bor_credit_id', 'bchg_credit_id', 'last_credit_id', 'bcacr_credit_id', 'bor_bonuses_got' ], axis=1, inplace=True) df_train, df_test, y_train, y_test = train_test_split(df, y, test_size=0.33, stratify=df.y, random_state=42)
Sekarang mulailah tahap yang paling penting dalam penilaian untuk regresi - Anda perlu menulis biner WOE untuk variabel numerik dan kategori. Dalam domain publik, kami tidak menemukan opsi yang baik dan cocok untuk kami dan memutuskan untuk menulis sendiri. Artikel 2017 ini diambil sebagai dasar binning numerik, dan juga kategoris ini, mereka sendiri menulis dari awal. Hasilnya mengesankan (Gini pada tes naik 3-5 dibandingkan dengan algoritma binning dari program penambangan data eksternal).
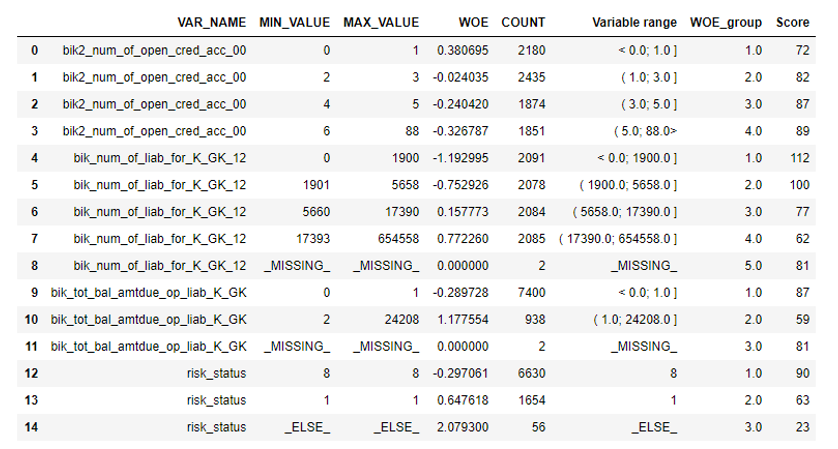
Setelah itu, Anda dapat melihat grafik atau tabel (yang kemudian kami tulis dalam excel) bagaimana variabel dibagi menjadi kelompok-kelompok dan memeriksa monotonnya:
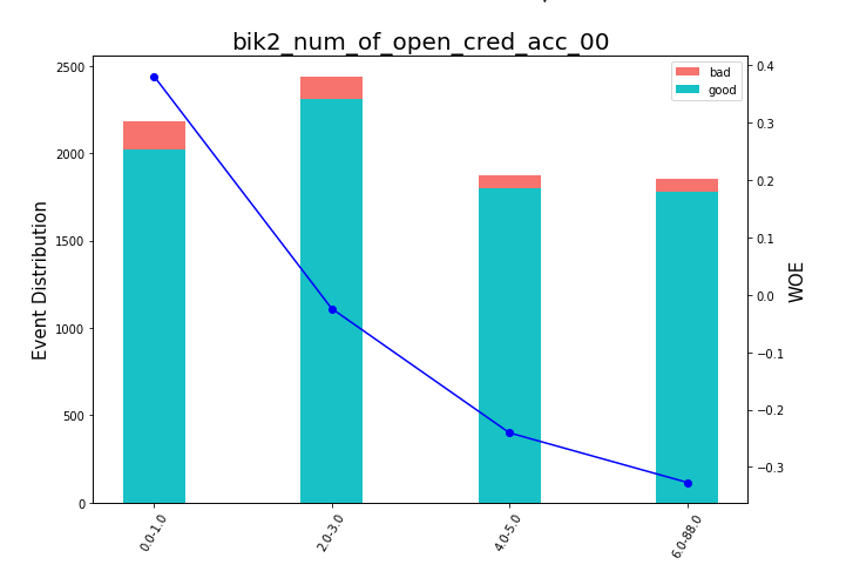
Bagan Rendering Bean def plot_bin(ev, for_excel=False): ind = np.arange(len(ev.index)) width = 0.35 fig, ax1 = plt.subplots(figsize=(10, 7)) ax2 = ax1.twinx() p1 = ax1.bar(ind, ev['NONEVENT'], width, color=(24/254, 192/254, 196/254)) p2 = ax1.bar(ind, ev['EVENT'], width, bottom=ev['NONEVENT'], color=(246/254, 115/254, 109/254)) ax1.set_ylabel('Event Distribution', fontsize=15) ax2.set_ylabel('WOE', fontsize=15) plt.title(list(ev.VAR_NAME)[0], fontsize=20) ax2.plot(ind, ev['WOE'], marker='o', color='blue')
Fungsi untuk binning manual ditulis secara terpisah, yang berguna, misalnya, dalam kasus variabel "versi OS", di mana semua ponsel Android dan iOS dikelompokkan secara manual.
Fungsi binning manual def adjust_binning(df, bins_dict): for i in range(len(bins_dict)): key = list(bins_dict.keys())[i] if type(list(bins_dict.values())[i])==dict: df[key] = df[key].map(list(bins_dict.values())[i]) else:
Langkah selanjutnya adalah pemilihan variabel berdasarkan Nilai Informasi. Nilai defaultnya terputus 0,1 (semua variabel di bawah ini tidak memiliki daya prediksi yang baik).
Setelah itu, pemeriksaan korelasi dilakukan. Dari dua variabel yang berkorelasi, Anda perlu menghapus satu dengan kurang IV. Penghapusan penghapusan diambil 0,75.
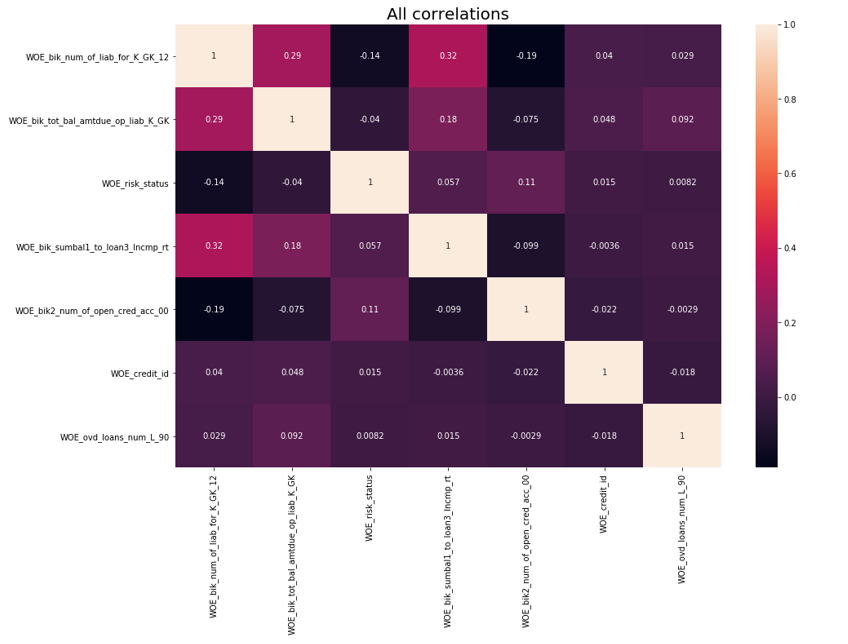
Penghapusan Korelasi def delete_correlated_features(df, cut_off=0.75, exclude = []):
Selain seleksi oleh IV, kami menambahkan pencarian rekursif untuk jumlah variabel optimal dengan metode
RFE dari sklearn.
Seperti yang kita lihat dalam grafik, setelah 13 variabel kualitasnya tidak berubah, yang berarti bahwa yang ekstra dapat dihapus. Untuk regresi, lebih dari 15 variabel dalam penilaian dianggap sebagai bentuk buruk, yang dalam kebanyakan kasus dikoreksi menggunakan RFE.
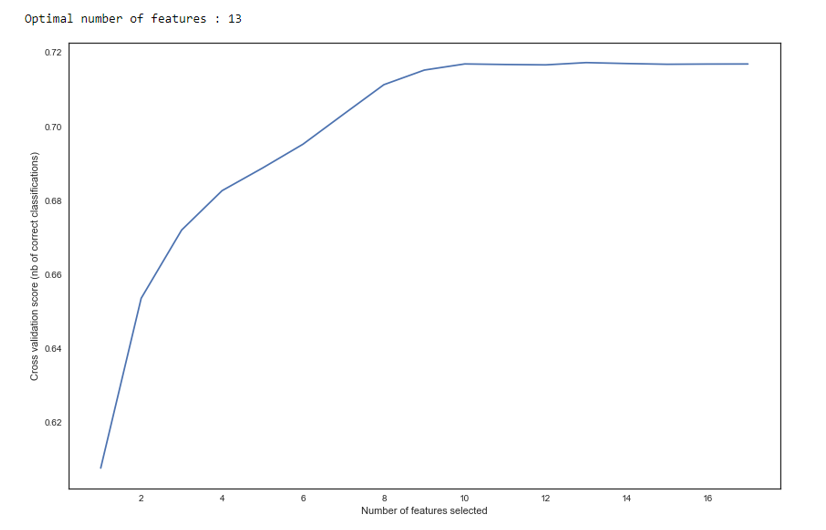
RFE def RFE_feature_selection(clf_lr, X, y): rfecv = RFECV(estimator=clf_lr, step=1, cv=StratifiedKFold(5), verbose=0, scoring='roc_auc') rfecv.fit(X, y) print("Optimal number of features : %d" % rfecv.n_features_)
Selanjutnya, regresi dibangun dan metriknya dievaluasi pada cross-validation dan uji sampel. Biasanya semua orang melihat koefisien Gini (artikel bagus tentangnya di
sini ).
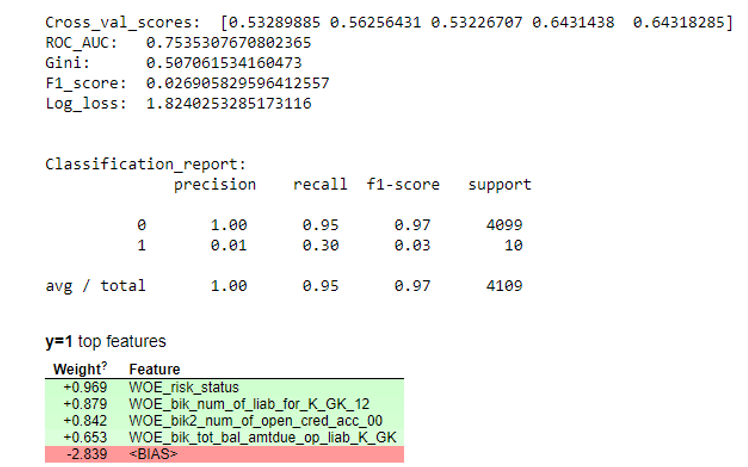
Hasil simulasi def plot_score(clf, X_test, y_test, feat_to_show=30, is_normalize=False, cut_off=0.5):
Ketika kami memastikan bahwa kualitas model sesuai dengan kami, maka perlu untuk menulis semua hasil (koefisien regresi, grup bin, grafik dan variabel stabilitas Gini, dll.) Dalam excel. Untuk ini, mudah untuk menggunakan xlsxwriter, yang dapat bekerja dengan data dan gambar.
Contoh lembar excel:
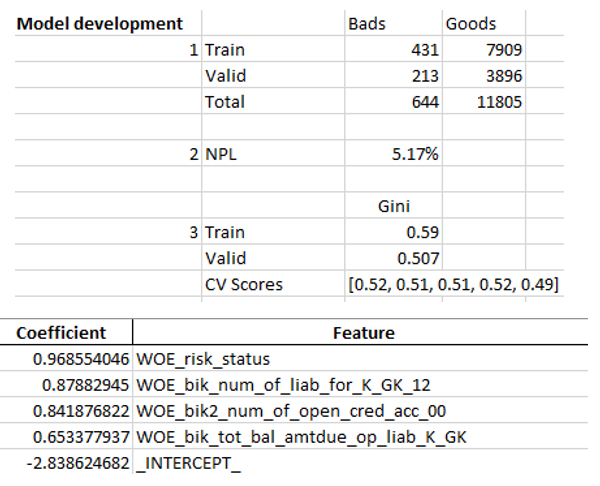
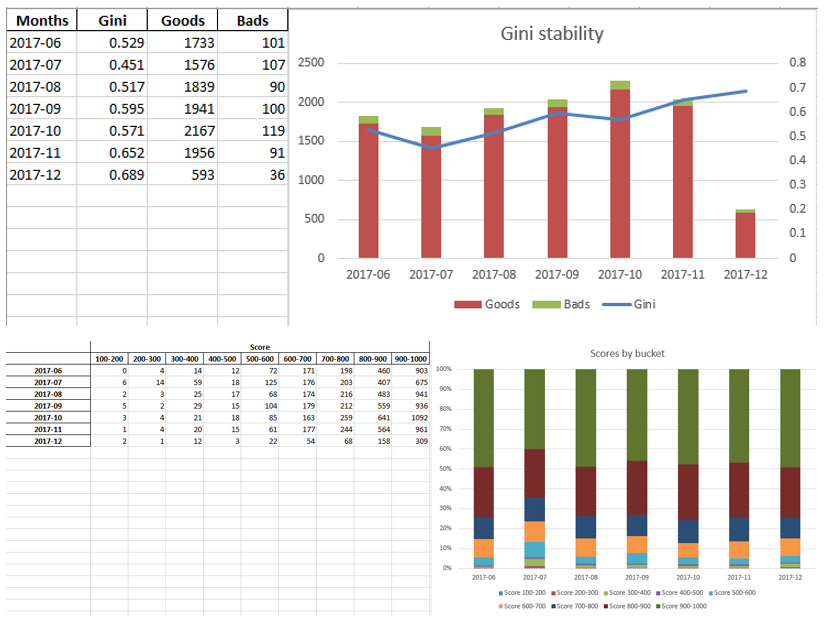
Pada akhirnya, excel terakhir terlihat lagi oleh manajemen, setelah itu diberikan kepada IT untuk menanamkan model dalam produksi.
Ringkasan
Seperti yang kita lihat, hampir semua tahapan penilaian dapat diotomatiskan sehingga analis tidak memerlukan keterampilan pemrograman untuk membangun model. Dalam kasus kami, setelah membuat kerangka kerja ini, analis hanya perlu mengumpulkan data dan menentukan beberapa parameter (menunjukkan variabel target, kolom mana yang akan dihapus, jumlah minimum tempat sampah, koefisien cutoff untuk korelasi variabel, dll.), Setelah itu Anda dapat menjalankan skrip dengan python, yang mana akan membangun model dan menghasilkan excel dengan hasil yang diinginkan.
Tentu saja, kadang-kadang perlu untuk memperbaiki kode untuk kebutuhan proyek tertentu, dan Anda tidak dapat melakukannya dengan satu tombol untuk menjalankan skrip selama pemodelan, tetapi bahkan sekarang kita melihat kualitas yang lebih baik daripada paket data mining yang digunakan di pasar berkat teknik seperti binning optimal dan monoton, pengecekan korelasi , RFE, versi regresi yang diatur, dll.
Dengan demikian, berkat penggunaan Python, kami secara signifikan mengurangi waktu pengembangan kartu penilaian, serta mengurangi biaya tenaga kerja analis.