Setiap hari, pengguna melakukan jutaan aktivitas online. Proyek FACETz DMP perlu menyusun data ini dan mengelompokkannya untuk mengidentifikasi preferensi pengguna. Dalam artikel tersebut, kita akan berbicara tentang bagaimana tim melakukan segmentasi audiensi 600 juta orang, memproses 5 miliar acara setiap hari dan bekerja dengan statistik menggunakan Kafka dan HBase.
Materi tersebut didasarkan pada transkrip
laporan oleh Artyom Marinov , spesialis data besar di Directual, dari konferensi SmartData 2017.
Nama saya Artyom Marinov, saya ingin berbicara tentang bagaimana kami mendesain ulang arsitektur proyek DMP FACETz ketika saya bekerja di Data Centric Alliance. Mengapa kami melakukannya, apa yang menyebabkannya, ke mana kami pergi dan masalah apa yang kami temui.
DMP (Platform Manajemen Data) adalah platform untuk mengumpulkan, memproses, dan mengagregasi data pengguna. Data banyak hal yang berbeda. Platform ini memiliki sekitar 600 juta pengguna. Ini adalah jutaan cookie yang ada di Internet dan membuat berbagai acara. Secara umum, satu hari rata-rata terlihat seperti ini: kita melihat sekitar 5,5 miliar peristiwa per hari, mereka entah bagaimana tersebar pada hari, dan pada puncaknya mencapai sekitar 100 ribu peristiwa per detik.

Acara adalah berbagai sinyal pengguna. Misalnya, kunjungan ke situs: kami melihat dari mana browser pengguna berasal, agen penggunanya, dan semua yang dapat kami ekstrak. Terkadang kita melihat bagaimana dan untuk pertanyaan pencarian apa dia datang ke situs tersebut. Ini juga bisa berupa berbagai data dari dunia offline, misalnya, apa yang dibayarnya dengan kupon diskon dan sebagainya.
Kita perlu menyimpan data ini dan menandai pengguna ke dalam apa yang disebut kelompok segmen audiens. Misalnya, segmennya mungkin seorang "wanita" yang "mencintai kucing" dan mencari "layanan mobil", ia "memiliki mobil yang lebih tua dari tiga tahun."
Mengapa mengelompokkan pengguna? Ada banyak aplikasi untuk ini, misalnya, iklan. Berbagai jaringan iklan dapat mengoptimalkan algoritma penayangan iklan. Jika Anda mengiklankan layanan mobil Anda, Anda dapat mengatur kampanye sedemikian rupa sehingga hanya orang yang memiliki informasi acara mobil lama, tidak termasuk pemilik yang baru. Anda dapat secara dinamis mengubah konten situs, Anda dapat menggunakan data untuk penilaian - ada banyak aplikasi.
Data diperoleh dari banyak tempat yang sangat berbeda. Ini bisa berupa pengaturan piksel langsung - ini adalah jika klien ingin menganalisis audiensnya, ia meletakkan piksel di situs, gambar tak terlihat yang diunduh dari server kami. Intinya adalah kita melihat kunjungan pengguna ke situs ini: Anda dapat menyimpannya, mulai menganalisis dan memahami potret pengguna, semua informasi ini tersedia untuk klien kami.

Data dapat diperoleh dari berbagai mitra yang melihat banyak data dan ingin memonetisasi mereka dengan berbagai cara. Mitra dapat menyediakan data baik secara waktu nyata maupun melakukan unggahan berkala dalam bentuk file.
Persyaratan utama:
- Skalabilitas horisontal;
- Estimasi volume audiens;
- Kenyamanan pemantauan dan pengembangan;
- Laju reaksi yang baik untuk berbagai peristiwa.
Salah satu persyaratan utama sistem adalah skalabilitas horizontal. Ada saat dimana ketika Anda mengembangkan portal atau toko online, Anda dapat memperkirakan jumlah pengguna Anda (bagaimana itu akan tumbuh, bagaimana itu akan berubah) dan secara kasar memahami berapa banyak sumber daya yang dibutuhkan, dan bagaimana toko itu akan hidup dan berkembang dari waktu ke waktu.
Ketika Anda mengembangkan platform yang mirip dengan DMP, Anda harus siap dengan kenyataan bahwa setiap situs besar - Amazon bersyarat - dapat menempatkan piksel Anda di dalamnya, dan Anda harus bekerja dengan lalu lintas seluruh situs ini, sementara Anda tidak boleh jatuh, dan indikatornya entah bagaimana sistem seharusnya tidak berubah dari ini.
Penting juga untuk dapat memahami volume audiens tertentu sehingga pengiklan potensial atau orang lain dapat menyusun rencana media. Misalnya, seseorang mendatangi Anda dan meminta Anda untuk mencari tahu berapa banyak wanita hamil dari Novosibirsk mencari hipotek untuk menilai apakah masuk akal untuk menargetkan mereka atau tidak.
Dari sudut pandang pengembangan, Anda harus dapat dengan dingin memonitor semua yang terjadi di sistem Anda, men-debug beberapa bagian dari lalu lintas nyata, dan sebagainya.
Salah satu persyaratan sistem yang paling penting adalah laju reaksi yang baik terhadap kejadian. Semakin cepat sistem merespons peristiwa, semakin baik, ini jelas. Jika Anda mencari tiket teater, maka jika Anda melihat semacam penawaran diskon setelah sehari, dua hari atau bahkan satu jam - ini mungkin tidak relevan, karena Anda sudah bisa membeli tiket atau pergi ke pertunjukan. Ketika Anda mencari bor - Anda mencarinya, temukan, beli, gantung rak, dan setelah beberapa hari pengeboman dimulai: "Beli bor!".
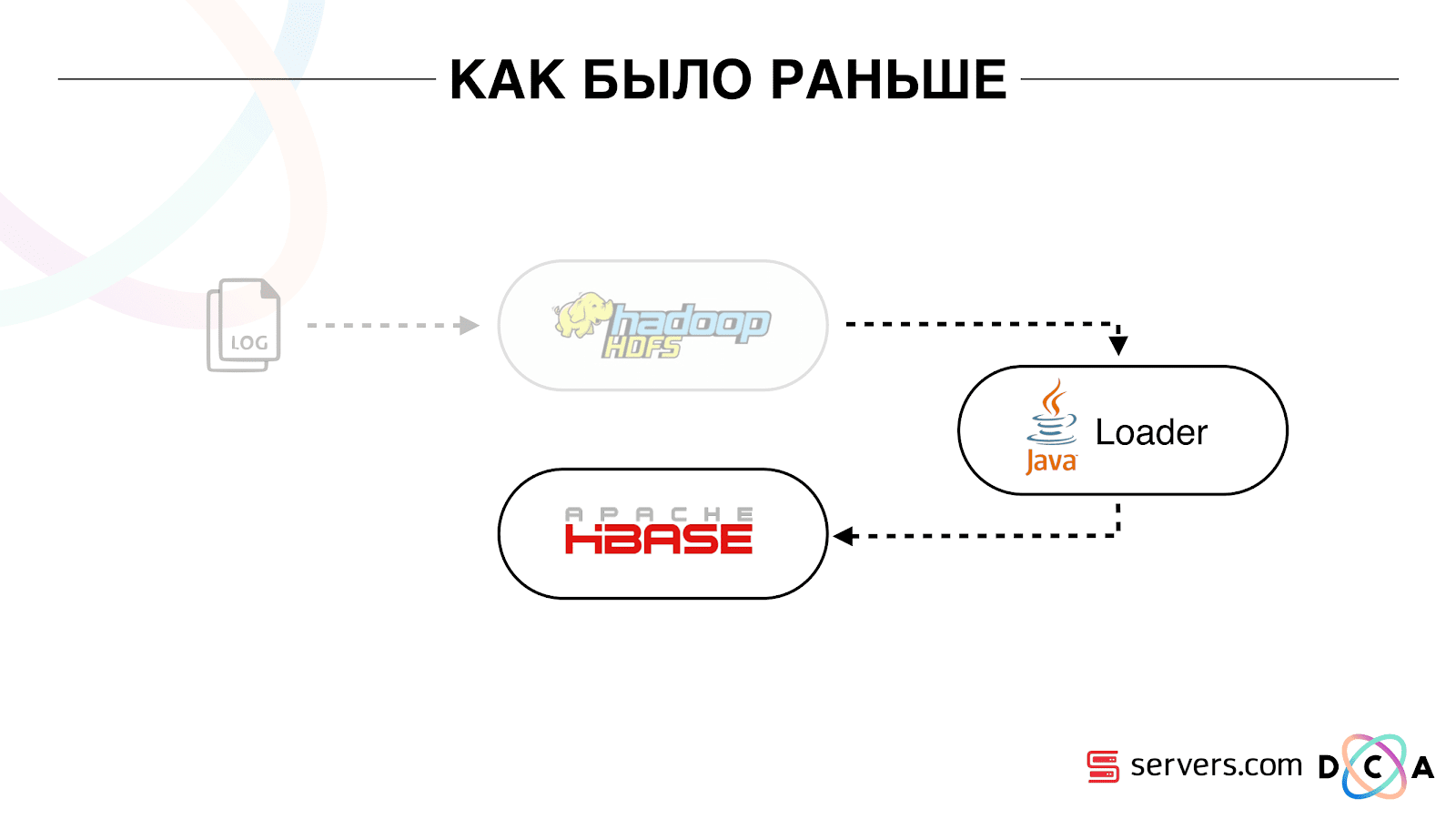
Seperti sebelumnya
Artikel secara keseluruhan adalah tentang arsitektur daur ulang. Saya ingin memberi tahu Anda apa titik awal kami, bagaimana semuanya bekerja sebelum perubahan.
Semua data yang kami miliki, apakah itu aliran data langsung atau log, disimpan pada penyimpanan file yang didistribusikan HDFS. Kemudian ada proses tertentu yang dimulai secara berkala, mengambil semua file yang tidak diproses dari HDFS dan mengubahnya menjadi permintaan pengayaan data dalam HBase ("permintaan PUT").
Bagaimana kami menyimpan data dalam HBase
Ini adalah basis data Time Series berbentuk kolom. Dia memiliki konsep Kunci Baris - ini adalah kunci di mana Anda menyimpan data Anda. Kami menggunakan ID pengguna sebagai kunci, id pengguna, yang kami hasilkan saat kami melihat pengguna untuk pertama kalinya. Di dalam setiap kunci, data dibagi menjadi Keluarga Kolom - entitas di mana Anda dapat mengelola meta-informasi data Anda. Misalnya, Anda dapat menyimpan seribu versi catatan untuk "data" Keluarga Kolom dan menyimpannya selama dua bulan, dan untuk Keluarga Kolom "mentah" - setahun, sebagai opsi.
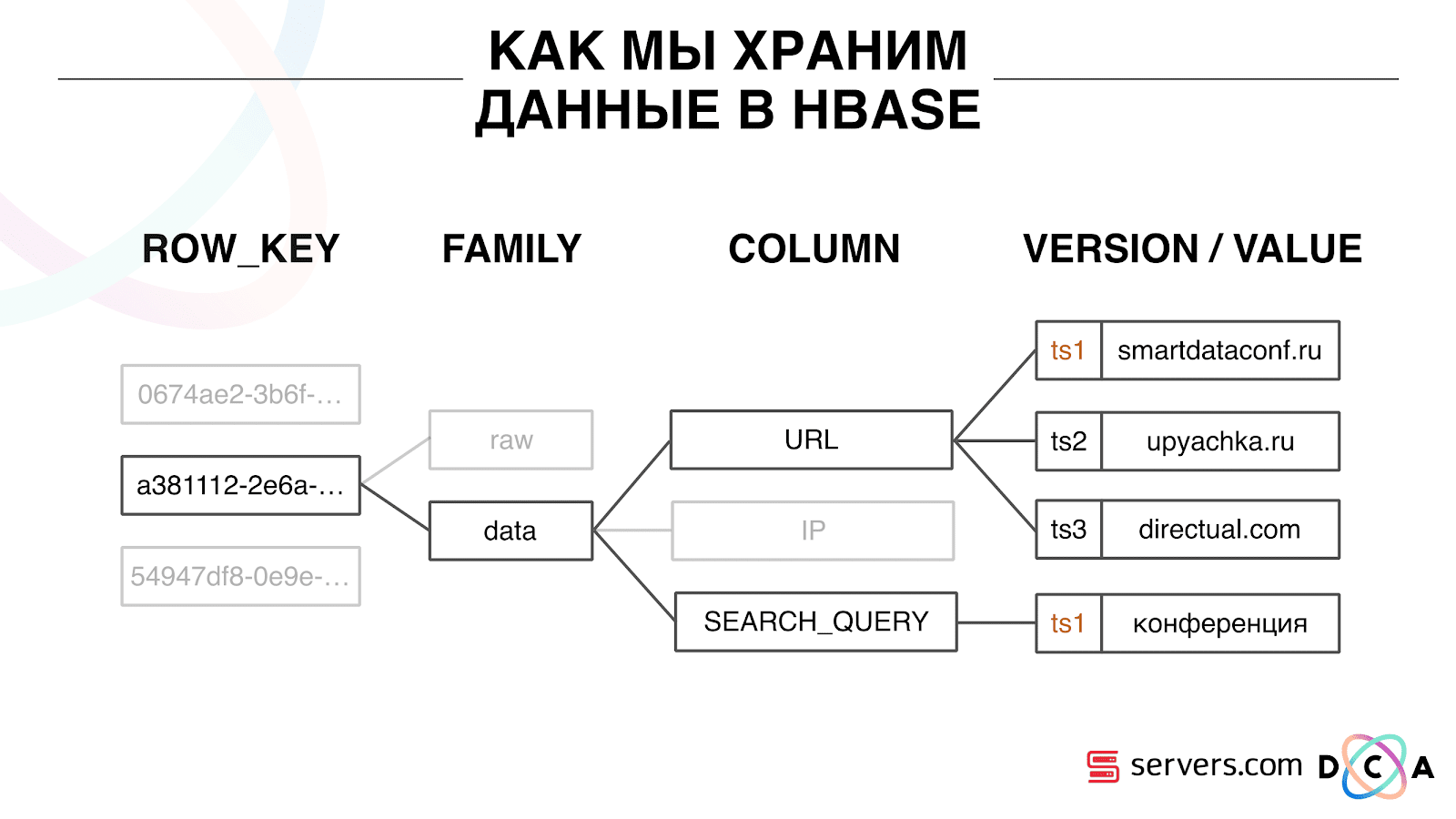
Di dalam Keluarga Kolom, ada banyak Kualifikasi Kolom (kolom selanjutnya). Kami menggunakan berbagai atribut pengguna sebagai kolom. Itu bisa berupa URL yang dia kunjungi, alamat IP, permintaan pencarian. Dan yang paling penting, banyak informasi disimpan di dalam setiap kolom. Di dalam URL kolom itu dapat diindikasikan bahwa pengguna pergi ke smartdataconf.ru, kemudian ke beberapa situs lain. Dan cap waktu digunakan sebagai versi - Anda melihat riwayat kunjungan pengguna yang terurut. Dalam kasus kami, kami dapat menentukan bahwa pengguna datang ke situs web smartdataconf dengan kata kunci "konferensi", karena mereka memiliki stempel waktu yang sama.
Bekerja dengan HBase
Ada beberapa opsi untuk bekerja dengan HBase. Itu bisa permintaan PUT (permintaan untuk perubahan data), MENDAPATKAN permintaan ("berikan saya semua data pada pengguna Vasya" dan sebagainya). Anda dapat menjalankan permintaan SCAN - pemindaian sekuensial multi-utas dari semua data dalam HBase. Kami menggunakan ini sebelumnya untuk menandai di segmen pemirsa.
Ada tugas yang disebut Mesin Analytics, itu dijalankan sekali sehari dan memindai HBase di banyak utas. Untuk setiap pengguna, ia mengangkat keseluruhan cerita dari HBase dan menjalankannya melalui serangkaian skrip analitik.

Apa itu skrip analitik? Ini adalah semacam kotak hitam (kelas java), yang menerima semua data pengguna sebagai input dan memberikan seperangkat segmen yang dianggap cocok sebagai output. Kami memberikan segalanya untuk skrip yang kami lihat - IP, kunjungan, UserAgent, dll., Dan pada output skrip yang diberikan: "ini adalah wanita, suka kucing, tidak suka anjing".
Data ini diberikan kepada mitra, statistik dipertimbangkan. Penting bagi kita untuk memahami berapa banyak wanita pada umumnya, berapa banyak pria, berapa banyak orang menyukai kucing, berapa banyak yang punya atau tidak punya mobil, dan sebagainya.
Kami menyimpan statistik dalam MongoDB dan menulis dengan menambahkan penghitung segmen tertentu untuk setiap hari. Kami memiliki grafik volume masing-masing segmen untuk setiap hari.
Sistem ini bagus untuk waktunya. Itu memungkinkan untuk skala secara horizontal, tumbuh, diizinkan untuk memperkirakan volume audiens, tetapi ia memiliki sejumlah kelemahan.
Tidak selalu mungkin untuk memahami apa yang terjadi dalam sistem, untuk melihat log. Sementara kami berada di hoster sebelumnya, tugas cukup sering jatuh karena berbagai alasan. Ada sekelompok Hadoop 20 + server, sekali sehari salah satu server secara stabil jatuh. Hal ini menyebabkan fakta bahwa sebagian tugas bisa jatuh dan tidak menghitung data. Diperlukan waktu untuk menyalakannya kembali, dan, mengingat itu berfungsi selama beberapa jam, ada sejumlah nuansa tertentu.
Hal paling mendasar yang tidak dipenuhi oleh arsitektur yang ada adalah bahwa waktu reaksi terhadap peristiwa itu terlalu lama. Bahkan ada cerita tentang hal ini. Ada perusahaan yang mengeluarkan pinjaman mikro kepada penduduk di daerah, dan kami bermitra dengan mereka. Klien mereka datang ke situs, mengisi aplikasi kredit mikro, perusahaan perlu memberikan jawaban dalam 15 menit: apakah mereka siap memberikan pinjaman atau tidak. Jika Anda siap, mereka segera mentransfer uang ke kartu.
Semuanya bekerja dengan baik. Klien memutuskan untuk memeriksa bagaimana umumnya terjadi: mereka mengambil laptop terpisah, memasang sistem yang bersih, mengunjungi banyak halaman di Internet dan pergi ke situs mereka. Mereka melihat bahwa ada permintaan, dan sebagai tanggapan kami mengatakan bahwa belum ada data. Klien bertanya: "Mengapa tidak ada data?"
Kami menjelaskan: ada jeda tertentu sebelum pengguna mengambil tindakan. Data dikirim ke HBase, diproses, dan hanya kemudian klien menerima hasilnya. Tampaknya jika pengguna tidak melihat iklan - semuanya beres, tidak ada hal buruk yang akan terjadi. Tetapi dalam situasi ini, pengguna mungkin tidak diberi pinjaman karena lag.
Ini bukan kasus yang terisolasi, dan itu perlu untuk beralih ke sistem waktu nyata. Apa yang kita inginkan darinya?

Kami ingin menulis data ke HBase segera setelah kami melihatnya. Kami melihat kunjungan, memperkaya semua yang kami tahu, dan mengirimkannya ke Storage. Segera setelah data di Storage berubah, Anda harus segera menjalankan seluruh rangkaian skrip analitik yang kami miliki. Kami ingin kemudahan pemantauan dan pengembangan, kemampuan untuk menulis skrip baru, men-debug mereka ke potongan-potongan lalu lintas nyata. Kami ingin memahami sistem apa yang sedang sibuk saat ini.
Hal pertama yang kami mulai adalah menyelesaikan masalah kedua: segmen pengguna segera setelah mengubah data tentang dia di HBase. Awalnya, kami memiliki node pekerja (tugas pengurangan peta diluncurkan pada mereka) yang terletak di tempat yang sama dengan HBase. Dalam beberapa kasus, itu sangat bagus - perhitungan dilakukan di sebelah data, tugas bekerja cukup cepat, lalu lintas sedikit melewati jaringan. Jelas bahwa tugas tersebut menghabiskan beberapa sumber daya, karena menjalankan skrip analitis yang kompleks.
Ketika kami mulai bekerja dalam waktu nyata, sifat beban pada HBase berubah. Kami beralih ke bacaan acak bukan yang berurutan. Penting bahwa beban pada HBase diharapkan - kami tidak dapat mengizinkan seseorang untuk menjalankan tugas pada cluster Hadoop dan merusak kinerja HBase.
Hal pertama yang kami lakukan adalah memindahkan HBase ke server yang terpisah. Juga men-tweak BlockCache dan BloomFilter. Kemudian kami melakukan pekerjaan dengan baik tentang cara menyimpan data dalam HBase. Mereka cukup banyak memperbaiki sistem yang saya bicarakan di awal, dan menuai data itu sendiri.

Dari yang sudah jelas: kami menyimpan IP sebagai string, dan menjadi panjang jumlahnya. Beberapa data diklasifikasikan, dilakukan hal-hal kosa kata, dan sebagainya. Intinya adalah bahwa karena ini, kami dapat mengguncang HBase sekitar dua kali - dari 10 TB menjadi 5 TB. HBase memiliki mekanisme yang mirip dengan pemicu dalam database biasa. Ini adalah mekanisme coprocessor. Kami menulis coprocessor bahwa, ketika pengguna berubah ke HBase, mengirimkan ID pengguna ke Kafka.
ID pengguna ada di Kafka. Selanjutnya ada "segmentator" layanan tertentu. Itu membaca aliran pengidentifikasi pengguna dan berjalan pada mereka semua skrip yang sama yang sebelumnya, meminta data dari HBase. Proses diluncurkan pada 10% dari lalu lintas, kami melihat cara kerjanya. Semuanya cukup baik.

Selanjutnya, kami mulai menambah beban dan melihat sejumlah masalah. Hal pertama yang kami lihat adalah layanan bekerja, segmen, dan kemudian jatuh Kafka, menghubungkan dan mulai bekerja lagi. Beberapa layanan - mereka saling membantu. Kemudian yang berikutnya jatuh, yang lain dan seterusnya dalam lingkaran. Pada saat yang sama, jajaran pengguna untuk segmentasi hampir tidak disapu.
Ini karena kekhasan mekanisme detak jantung di Kafka, maka itu masih versi 0.8. Detak jantung adalah ketika konsumen memberi tahu broker apakah mereka hidup atau tidak, dalam kasus kami, segmentator melaporkan. Berikut ini terjadi: kami menerima paket data yang agak besar, mengirimkannya untuk diproses. Untuk sementara ini berhasil, sementara itu bekerja - tidak ada detak jantung yang dikirim. Broker percaya bahwa konsumen sudah mati, dan mematikannya.
Konsumen bekerja sampai akhir, membuang-buang CPU yang berharga, mencoba mengatakan bahwa paket data berhasil dan yang berikutnya dapat diambil, tetapi ia ditolak karena yang lain mengambil apa yang ia kerjakan. Kami memperbaikinya dengan membuat latar belakang kami menjadi panas, kemudian kebenaran muncul versi Kafka yang lebih baru di mana kami memperbaiki masalah ini.
Kemudian muncul pertanyaan: hardware apa yang harus dipasang oleh segmentator kami. Segmentasi adalah proses sumber daya intensif (terikat CPU). Penting bahwa layanan tidak hanya mengkonsumsi banyak CPU, tetapi juga memuat jaringan. Sekarang traffic mencapai 5 Gbit / detik. Pertanyaannya adalah: di mana harus meletakkan layanan, pada banyak server kecil atau sedikit besar.
Saat itu, kami sudah pindah ke
server.com menggunakan logam kosong. Kami berbicara dengan orang-orang dari server, mereka membantu kami, memungkinkan untuk menguji kerja solusi kami baik pada sejumlah kecil server mahal, dan pada banyak yang murah dengan CPU yang kuat. Kami memilih opsi yang sesuai, menghitung biaya unit untuk memproses satu peristiwa per detik. By the way, pilihan jatuh pada Dell R230 yang cukup kuat dan pada saat yang sama sangat terjangkau, mereka meluncurkannya - semuanya bekerja.
Adalah penting bahwa setelah segmentator menandai pengguna ke dalam segmen, hasil analisisnya kembali ke Kafka, dalam topik tertentu Hasil Segmentasi.
Lebih lanjut, kami dapat terhubung secara independen ke data ini oleh konsumen yang berbeda yang tidak akan saling mengganggu. Ini memungkinkan kami untuk memberikan data secara independen ke setiap mitra, baik itu mitra eksternal, DSP internal, Google, statistik.
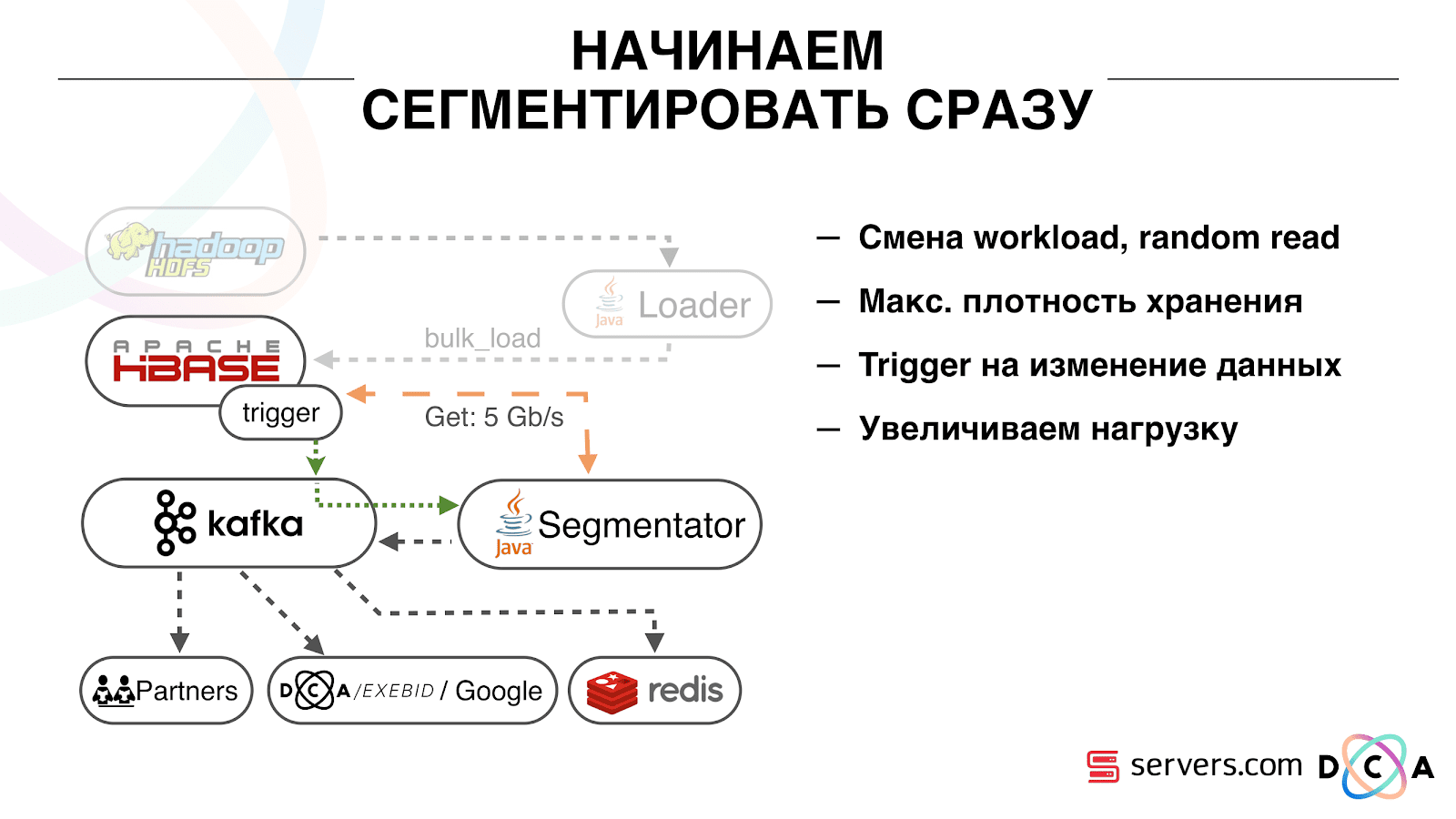
Dengan statistik, ada juga hal yang menarik: sebelumnya kita bisa meningkatkan nilai penghitung di MongoDB, berapa banyak pengguna di segmen tertentu untuk hari tertentu. Sekarang, ini tidak dapat dilakukan karena kami sekarang menganalisis setiap pengguna setelah dia menyelesaikan suatu peristiwa, yaitu beberapa kali sehari.
Karena itu, kami harus menyelesaikan masalah penghitungan jumlah unik pengguna di aliran. Untuk melakukan ini, kami menggunakan struktur data HyperLogLog dan implementasinya di Redis. Struktur data probabilistik. Ini berarti bahwa Anda dapat menambahkan pengidentifikasi pengguna di sana, pengidentifikasi itu sendiri tidak akan disimpan, sehingga Anda dapat menyimpan jutaan pengidentifikasi unik di HyperLogLog yang sangat ringkas, dan ini akan memakan waktu hingga 12 kilobyte per kunci.
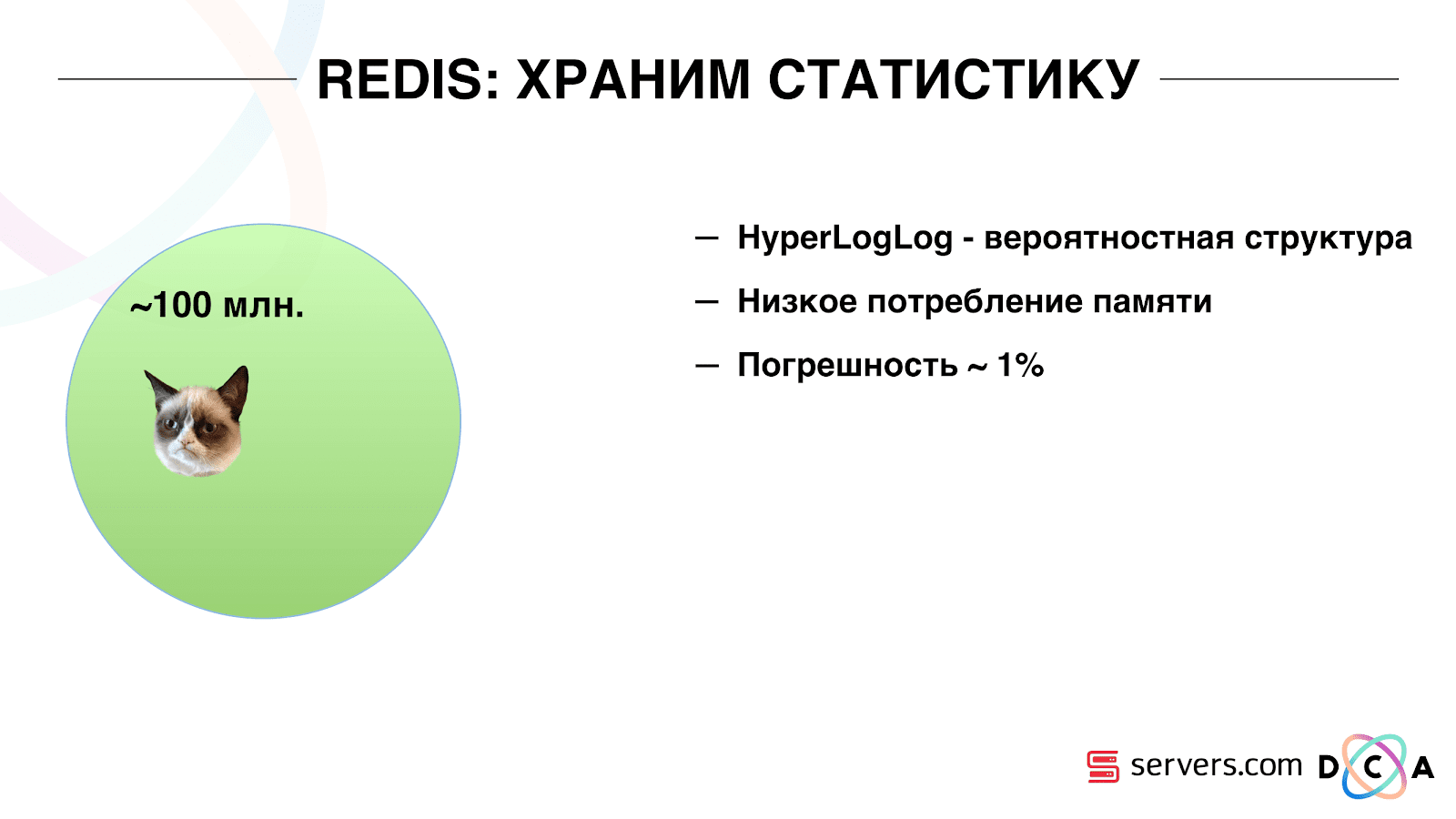
Anda tidak bisa mendapatkan pengidentifikasi sendiri, tetapi Anda bisa mengetahui ukuran set ini. Karena struktur data probabilistik, ada beberapa kesalahan. Misalnya, jika Anda memiliki segmen "suka kucing," membuat permintaan untuk ukuran segmen ini untuk hari tertentu, Anda akan menerima 99,2 juta dan ini berarti sekitar "dari 99 juta hingga 100 juta".
Juga di HyperLogLog Anda bisa mendapatkan ukuran gabungan dari beberapa set. Katakanlah Anda memiliki dua segmen: "anjing laut cinta" dan "anjing cinta". Katakanlah 100 juta pertama, 1 juta kedua. Seseorang mungkin bertanya: "Berapa banyak binatang yang mereka sukai?" dan dapatkan jawaban "sekitar 101 juta" dengan kesalahan 1%. Akan menarik untuk menghitung seberapa banyak kucing dan anjing dicintai pada saat yang sama, tetapi untuk melakukan ini cukup sulit.

Di satu sisi, Anda dapat mengetahui ukuran setiap set, mencari tahu ukuran serikat, menambah, mengurangi satu dari yang lain dan mendapatkan persimpangan. Tetapi karena kenyataan bahwa ukuran kesalahan bisa lebih besar dari ukuran persimpangan akhir, hasil akhir bisa berupa "dari -50 hingga 50 ribu."

Kami telah bekerja sedikit tentang cara meningkatkan kinerja saat menulis data ke Redis. Awalnya, kami mencapai 200 ribu operasi per detik. Tetapi ketika setiap pengguna memiliki lebih dari 50 segmen - merekam informasi tentang setiap pengguna - 50 operasi. Ternyata bandwidth kami sangat terbatas dan, dalam contoh ini, tidak dapat menulis informasi tentang lebih dari 4 ribu pengguna per detik, ini beberapa kali lebih sedikit dari yang kami butuhkan.
Kami membuat "prosedur tersimpan" yang terpisah di Redis via Lua, memuatnya di sana dan mulai meneruskan string ke sana dengan seluruh daftar segmen satu pengguna. Prosedur di dalam akan memotong string yang lewat menjadi pembaruan HyperLogLog yang diperlukan dan menyimpan data, jadi kami mencapai sekitar 1 juta pembaruan per detik.
Sedikit hardcore: Redis adalah single-threaded, Anda dapat menyematkannya ke satu inti prosesor, dan kartu jaringan ke yang lain dan mencapai kinerja 15% lainnya, menghemat pada pengalihan konteks. Selain itu, poin penting adalah bahwa Anda tidak bisa hanya mengelompokkan struktur data, karena operasi untuk mendapatkan kekuatan serikat set tidak dikelompokkan
Kafka adalah alat yang hebat
Anda melihat bahwa Kafka adalah alat transportasi utama kami dalam sistem.
Ini memiliki esensi "topik". Di sinilah Anda menulis data, tetapi pada dasarnya - antrian. Dalam kasus kami, ada beberapa antrian. Salah satunya adalah pengidentifikasi pengguna yang perlu disegmentasi. Yang kedua adalah hasil segmentasi.
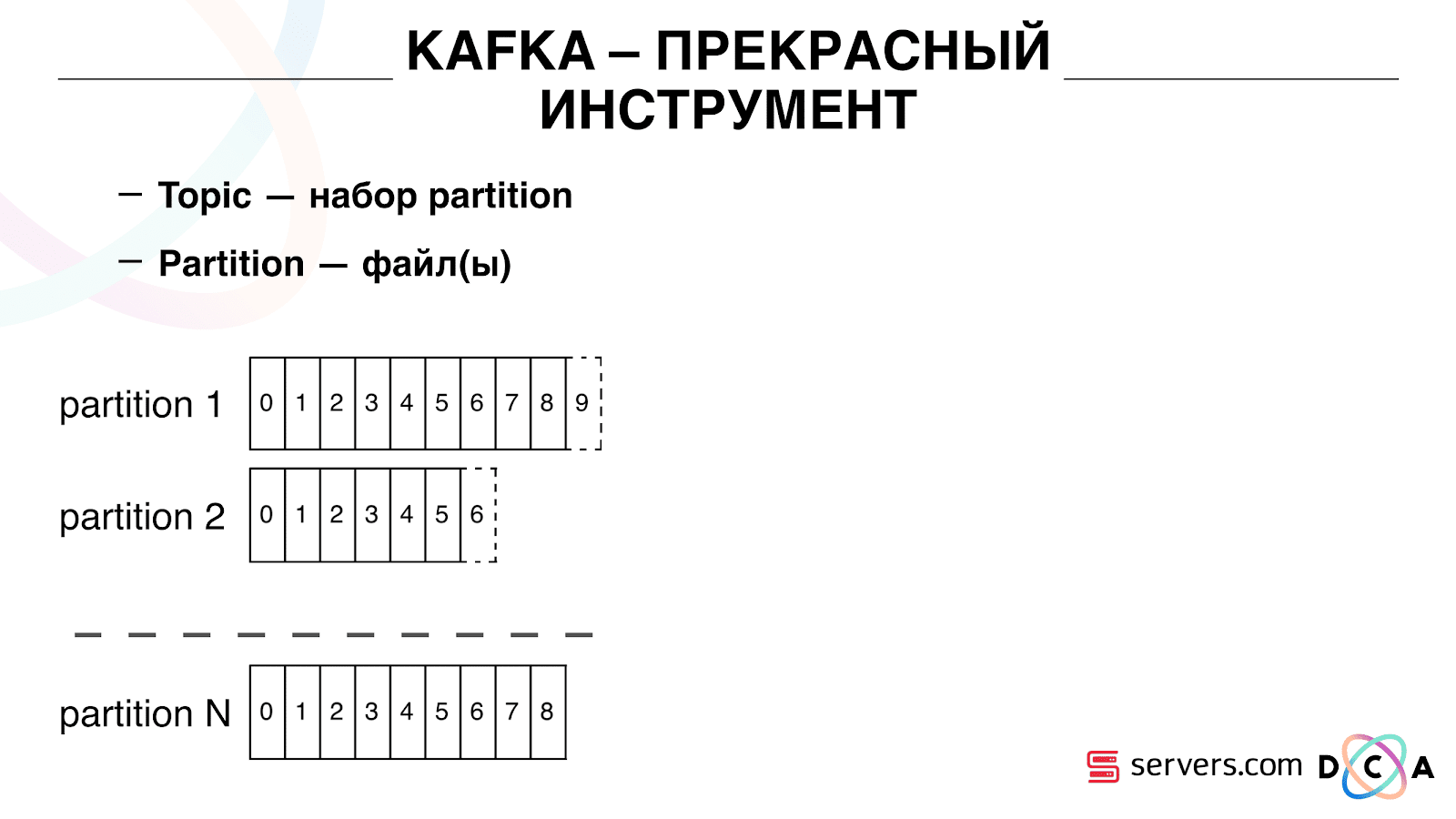
Topik adalah sekumpulan partisi. Itu dibagi menjadi beberapa bagian. Setiap partisi adalah file di hard drive. Ketika produsen Anda menulis data, mereka menulis potongan-potongan teks ke bagian akhir partisi. Ketika konsumen Anda membaca data, mereka hanya membaca dari partisi ini.
Yang penting adalah bahwa Anda dapat secara independen menghubungkan beberapa kelompok konsumen, mereka akan mengkonsumsi data tanpa mengganggu satu sama lain. Ini ditentukan oleh nama kelompok konsumen dan dicapai sebagai berikut.
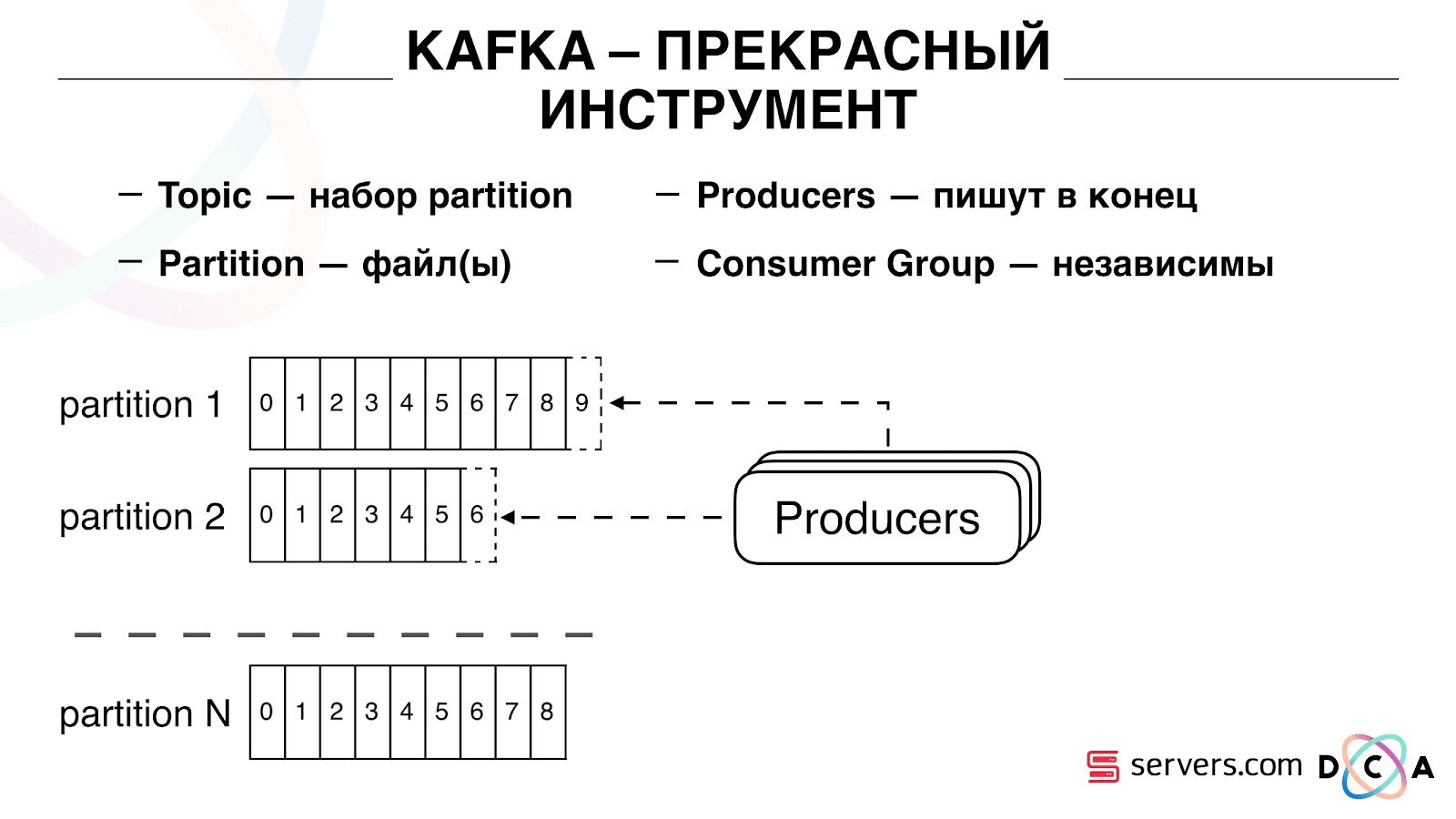
Ada yang namanya offset, posisi di mana grup konsumen sekarang berada di setiap partisi. Misalnya, grup A mengkonsumsi pesan ketujuh dari partisi1, dan yang kelima dari partisi2. Grup B, independen A, memiliki offset lain.
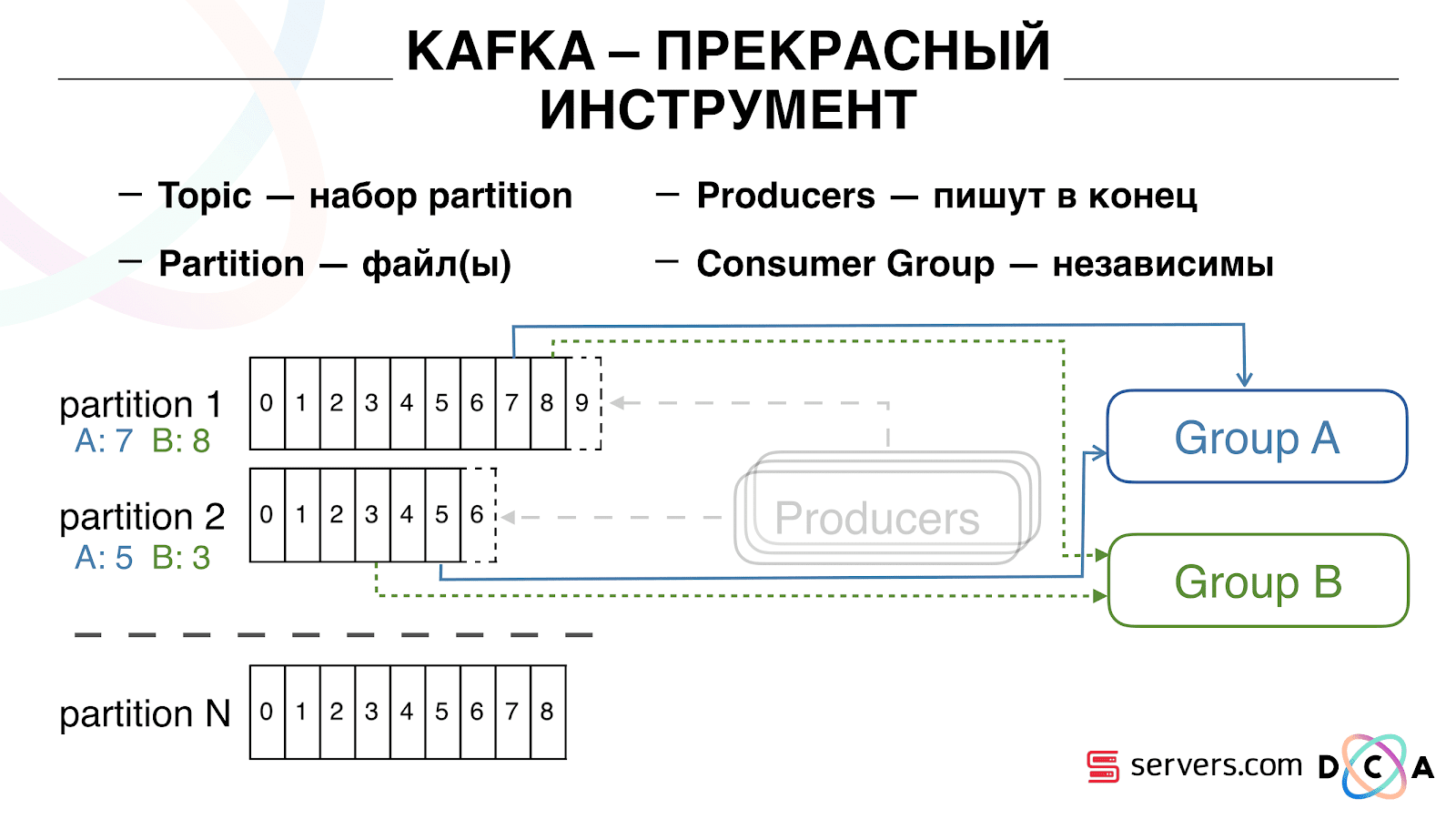 Anda dapat mengatur skala grup konsumen Anda secara horizontal, menambahkan proses atau server lain. Ini akan terjadi penggantian partisi (pialang Kafka akan memberi setiap konsumen daftar partisi untuk konsumsi) Ini berarti bahwa grup konsumen pertama akan mulai mengkonsumsi hanya partisi 1, dan yang kedua hanya mengkonsumsi partisi 2. Jika beberapa konsumen meninggal (misalnya, hearthbeat tidak datang), pengalihan tugas baru terjadi , setiap konsumen menerima daftar partisi terbaru untuk diproses.
Anda dapat mengatur skala grup konsumen Anda secara horizontal, menambahkan proses atau server lain. Ini akan terjadi penggantian partisi (pialang Kafka akan memberi setiap konsumen daftar partisi untuk konsumsi) Ini berarti bahwa grup konsumen pertama akan mulai mengkonsumsi hanya partisi 1, dan yang kedua hanya mengkonsumsi partisi 2. Jika beberapa konsumen meninggal (misalnya, hearthbeat tidak datang), pengalihan tugas baru terjadi , setiap konsumen menerima daftar partisi terbaru untuk diproses. Cukup nyaman. Pertama, Anda dapat memanipulasi offset untuk setiap grup konsumen. Bayangkan ada mitra yang Anda kirimi data dari topik ini dengan hasil segmentasi. Dia menulis bahwa dia secara tidak sengaja kehilangan data hari terakhir sebagai akibat dari bug. Dan Anda, untuk kelompok konsumen dari klien ini, mundur saja sehari dan tuangkan seluruh hari data ke sana. Kami juga dapat memiliki grup konsumen kami sendiri, terhubung ke lalu lintas produksi, menonton apa yang terjadi, dan men-debug data nyata.Jadi, kami telah mencapai bahwa kami mulai mensegmentasi pengguna ketika berubah, kami dapat secara mandiri menghubungkan konsumen baru, kami menulis statistik dan kami dapat menontonnya. Sekarang Anda perlu mendapatkan data yang ditulis ke HBase segera setelah itu datang kepada kami.
Cukup nyaman. Pertama, Anda dapat memanipulasi offset untuk setiap grup konsumen. Bayangkan ada mitra yang Anda kirimi data dari topik ini dengan hasil segmentasi. Dia menulis bahwa dia secara tidak sengaja kehilangan data hari terakhir sebagai akibat dari bug. Dan Anda, untuk kelompok konsumen dari klien ini, mundur saja sehari dan tuangkan seluruh hari data ke sana. Kami juga dapat memiliki grup konsumen kami sendiri, terhubung ke lalu lintas produksi, menonton apa yang terjadi, dan men-debug data nyata.Jadi, kami telah mencapai bahwa kami mulai mensegmentasi pengguna ketika berubah, kami dapat secara mandiri menghubungkan konsumen baru, kami menulis statistik dan kami dapat menontonnya. Sekarang Anda perlu mendapatkan data yang ditulis ke HBase segera setelah itu datang kepada kami.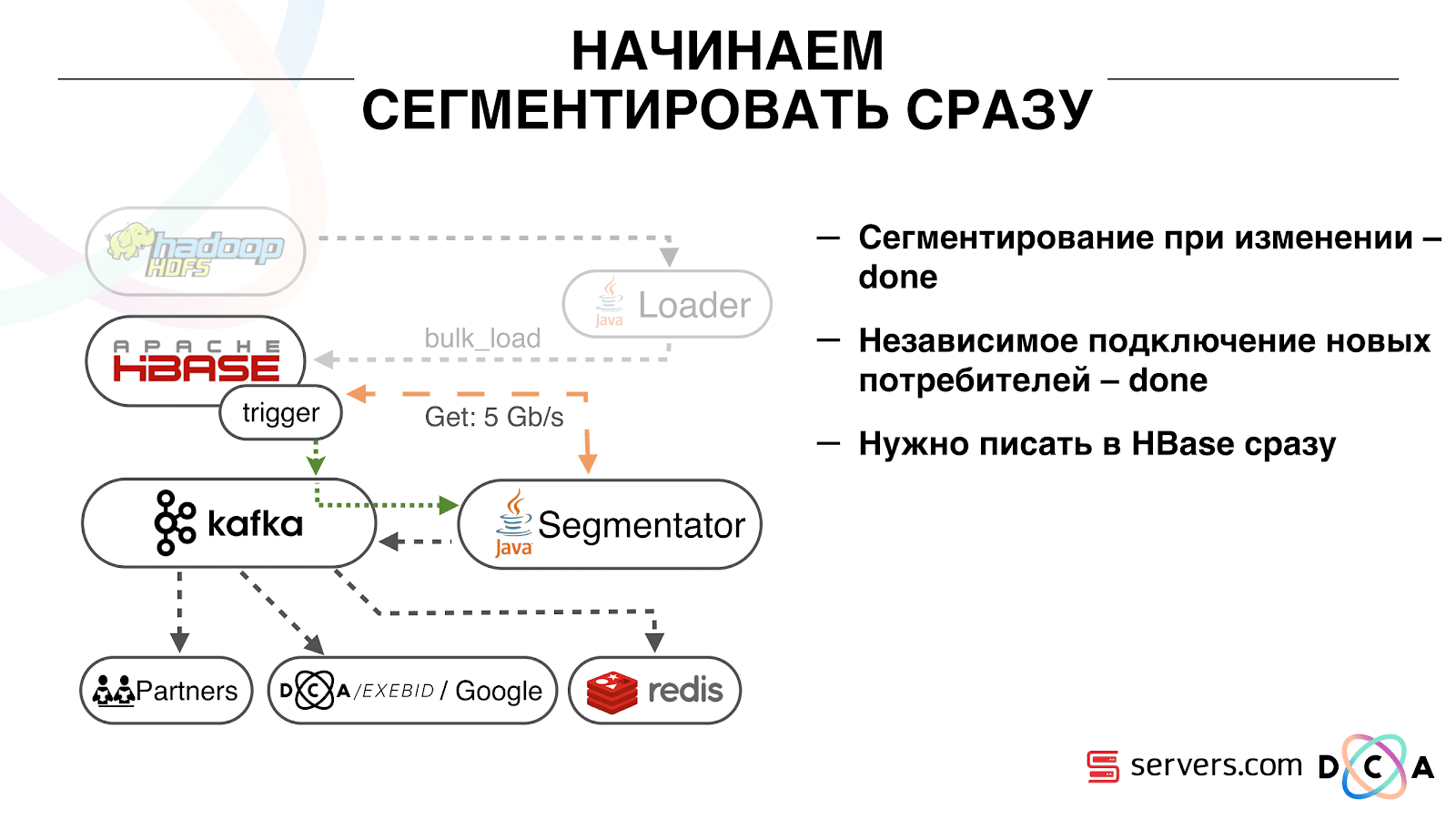 Bagaimana kami melakukannya. Dulu ada pemuatan data batch. Ada Batch Loader, itu memproses file log aktivitas pengguna: jika pengguna melakukan 10 kunjungan, batch datang untuk 10 peristiwa, itu dicatat dalam HBase dalam satu operasi. Hanya ada satu acara per segmentasi. Sekarang kami ingin menulis setiap acara terpisah di penyimpanan. Kami akan sangat meningkatkan aliran tulis dan aliran baca. Jumlah acara per segmentasi juga akan meningkat.
Bagaimana kami melakukannya. Dulu ada pemuatan data batch. Ada Batch Loader, itu memproses file log aktivitas pengguna: jika pengguna melakukan 10 kunjungan, batch datang untuk 10 peristiwa, itu dicatat dalam HBase dalam satu operasi. Hanya ada satu acara per segmentasi. Sekarang kami ingin menulis setiap acara terpisah di penyimpanan. Kami akan sangat meningkatkan aliran tulis dan aliran baca. Jumlah acara per segmentasi juga akan meningkat. Hal pertama yang kami lakukan adalah port HBase ke SSD. Dengan cara standar, ini tidak dilakukan secara khusus. Ini dilakukan dengan menggunakan HDFS. Anda dapat mengatakan bahwa direktori khusus pada HDFS harus berada pada kelompok disk seperti itu. Ada masalah keren dengan fakta bahwa ketika kami membawa HBase ke SSD dan menyebutnya, semua snapshot juga ada di sana, dan SSD kami berakhir dengan sangat cepat.Ini juga diselesaikan, kami mulai mengekspor snapshots ke file secara berkala, menulis ke direktori HDFS lain dan menghapus semua meta-informasi tentang snapshot. Jika Anda perlu memulihkan - ambil file yang disimpan, impor dan pulihkan. Untungnya, operasi ini sangat jarang.Juga pada SSD mereka mengeluarkan Write Ahead Log, Twisted MemStore, menyalakan blok cache pada opsi tulis. Ini memungkinkan Anda untuk segera memasukkannya ke dalam cache blok saat merekam data. Ini sangat nyaman karena dalam kasus kami, jika kami merekam data, maka sangat mungkin untuk segera dibaca. Ini juga memberi beberapa keuntungan.Selanjutnya, kami mengalihkan semua sumber data kami untuk menulis data ke Kafka. Sudah dari Kafka kami mencatat data dalam HDFS untuk menjaga kompatibilitas, termasuk agar analis kami dapat bekerja dengan data, menjalankan tugas MapReduce dan menganalisis hasilnya.Kami menghubungkan grup konsumen terpisah yang menulis data ke HBase. Ini, pada kenyataannya, pembungkus yang bertuliskan dari Kafka dan membentuk PUT di HBase.
Hal pertama yang kami lakukan adalah port HBase ke SSD. Dengan cara standar, ini tidak dilakukan secara khusus. Ini dilakukan dengan menggunakan HDFS. Anda dapat mengatakan bahwa direktori khusus pada HDFS harus berada pada kelompok disk seperti itu. Ada masalah keren dengan fakta bahwa ketika kami membawa HBase ke SSD dan menyebutnya, semua snapshot juga ada di sana, dan SSD kami berakhir dengan sangat cepat.Ini juga diselesaikan, kami mulai mengekspor snapshots ke file secara berkala, menulis ke direktori HDFS lain dan menghapus semua meta-informasi tentang snapshot. Jika Anda perlu memulihkan - ambil file yang disimpan, impor dan pulihkan. Untungnya, operasi ini sangat jarang.Juga pada SSD mereka mengeluarkan Write Ahead Log, Twisted MemStore, menyalakan blok cache pada opsi tulis. Ini memungkinkan Anda untuk segera memasukkannya ke dalam cache blok saat merekam data. Ini sangat nyaman karena dalam kasus kami, jika kami merekam data, maka sangat mungkin untuk segera dibaca. Ini juga memberi beberapa keuntungan.Selanjutnya, kami mengalihkan semua sumber data kami untuk menulis data ke Kafka. Sudah dari Kafka kami mencatat data dalam HDFS untuk menjaga kompatibilitas, termasuk agar analis kami dapat bekerja dengan data, menjalankan tugas MapReduce dan menganalisis hasilnya.Kami menghubungkan grup konsumen terpisah yang menulis data ke HBase. Ini, pada kenyataannya, pembungkus yang bertuliskan dari Kafka dan membentuk PUT di HBase.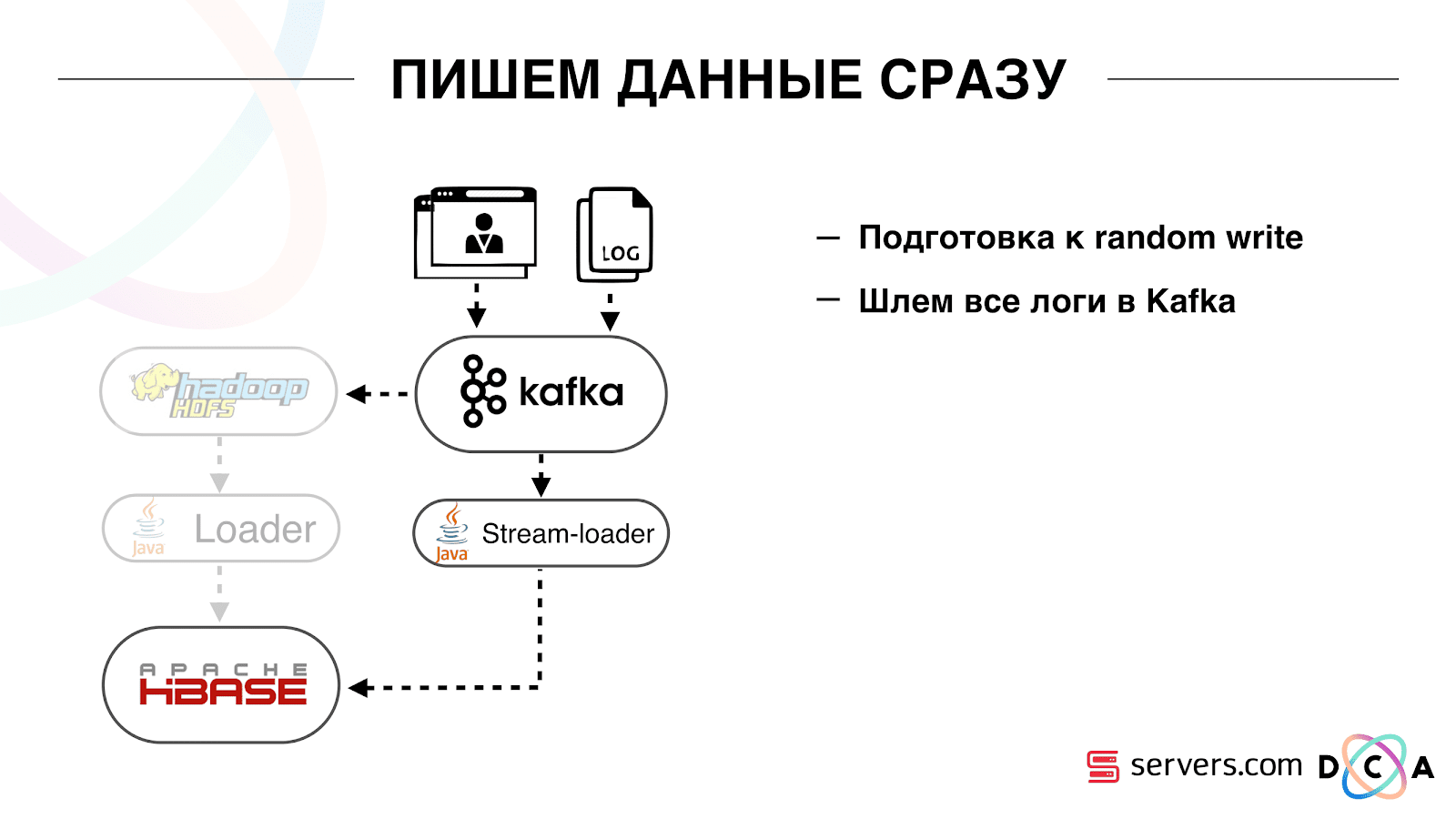 Kami meluncurkan dua sirkuit secara paralel agar tidak merusak kompatibilitas ke belakang dan tidak menurunkan kinerja sistem. Skema baru diluncurkan hanya pada persentase lalu lintas tertentu. Pada 10%, semuanya sangat keren. Tetapi pada beban yang lebih besar, segmenter tidak dapat mengatasi aliran segmentasi.
Kami meluncurkan dua sirkuit secara paralel agar tidak merusak kompatibilitas ke belakang dan tidak menurunkan kinerja sistem. Skema baru diluncurkan hanya pada persentase lalu lintas tertentu. Pada 10%, semuanya sangat keren. Tetapi pada beban yang lebih besar, segmenter tidak dapat mengatasi aliran segmentasi. Kami mengumpulkan metrik "berapa banyak pesan yang terdapat di Kafka sebelum dibaca dari sana." Ini metrik yang bagus. Awalnya, kami mengumpulkan metrik "berapa banyak pesan mentah sekarang", tetapi tidak mengatakan sesuatu yang istimewa. Anda melihat: "Saya punya sejuta pesan mentah," jadi apa? Untuk mengartikan juta ini, Anda perlu tahu seberapa cepat segmentator (konsumen) bekerja, yang tidak selalu jelas.Dengan metrik ini, Anda segera melihat bahwa data sedang ditulis ke antrian, diambil darinya, dan Anda melihat seberapa banyak yang mereka harapkan akan diproses. Kami melihat bahwa kami tidak punya waktu untuk melakukan segmentasi, dan pesannya ada di antrian beberapa jam sebelum membacanya.Anda bisa saja menambah kapasitas, tetapi itu akan terlalu
Kami mengumpulkan metrik "berapa banyak pesan yang terdapat di Kafka sebelum dibaca dari sana." Ini metrik yang bagus. Awalnya, kami mengumpulkan metrik "berapa banyak pesan mentah sekarang", tetapi tidak mengatakan sesuatu yang istimewa. Anda melihat: "Saya punya sejuta pesan mentah," jadi apa? Untuk mengartikan juta ini, Anda perlu tahu seberapa cepat segmentator (konsumen) bekerja, yang tidak selalu jelas.Dengan metrik ini, Anda segera melihat bahwa data sedang ditulis ke antrian, diambil darinya, dan Anda melihat seberapa banyak yang mereka harapkan akan diproses. Kami melihat bahwa kami tidak punya waktu untuk melakukan segmentasi, dan pesannya ada di antrian beberapa jam sebelum membacanya.Anda bisa saja menambah kapasitas, tetapi itu akan terlalu mahal saja. Karena itu, kami berusaha mengoptimalkan.Skala diri
Kami memiliki HBase. Pengguna berubah, pengenalnya terbang di Kafka. Topik dibagi menjadi partisi, partisi target dipilih oleh ID pengguna. Ini berarti bahwa ketika Anda melihat pengguna "Vasya" - ia pergi ke partisi 1. Ketika Anda melihat "Petya" - ke partisi 2. Ini nyaman - Anda dapat mencapai bahwa Anda akan melihat satu konsumen pada satu contoh layanan Anda, dan yang kedua - di sisi lain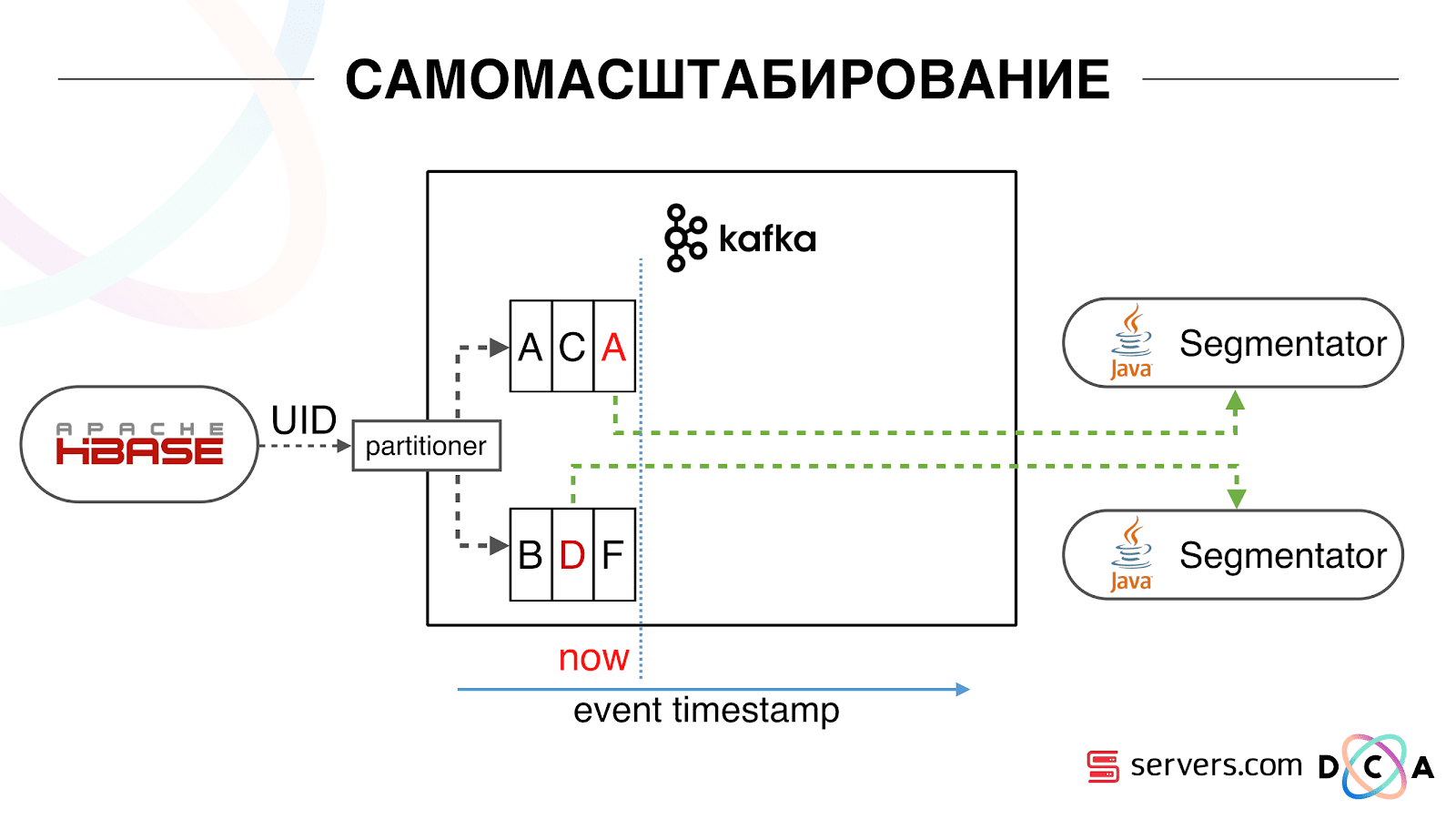 Kami mulai menonton apa yang terjadi. Satu perilaku khas pengguna di Internet adalah pergi ke beberapa situs web dan membuka beberapa tab latar belakang. Yang kedua adalah pergi ke situs dan membuat beberapa klik untuk sampai ke halaman arahan.Kami melihat antrian segmentasi dan melihat yang berikut: Pengguna A mengunjungi halaman tersebut. 5 acara lagi berasal dari pengguna ini - masing-masing menandakan pembukaan halaman. Kami memproses setiap peristiwa dari pengguna. Namun pada kenyataannya, data dalam HBase berisi semua 5 kunjungan. Kami memproses semua 5 kunjungan untuk pertama kalinya, kedua kalinya, dan seterusnya - kami menghabiskan sumber daya CPU.
Kami mulai menonton apa yang terjadi. Satu perilaku khas pengguna di Internet adalah pergi ke beberapa situs web dan membuka beberapa tab latar belakang. Yang kedua adalah pergi ke situs dan membuat beberapa klik untuk sampai ke halaman arahan.Kami melihat antrian segmentasi dan melihat yang berikut: Pengguna A mengunjungi halaman tersebut. 5 acara lagi berasal dari pengguna ini - masing-masing menandakan pembukaan halaman. Kami memproses setiap peristiwa dari pengguna. Namun pada kenyataannya, data dalam HBase berisi semua 5 kunjungan. Kami memproses semua 5 kunjungan untuk pertama kalinya, kedua kalinya, dan seterusnya - kami menghabiskan sumber daya CPU.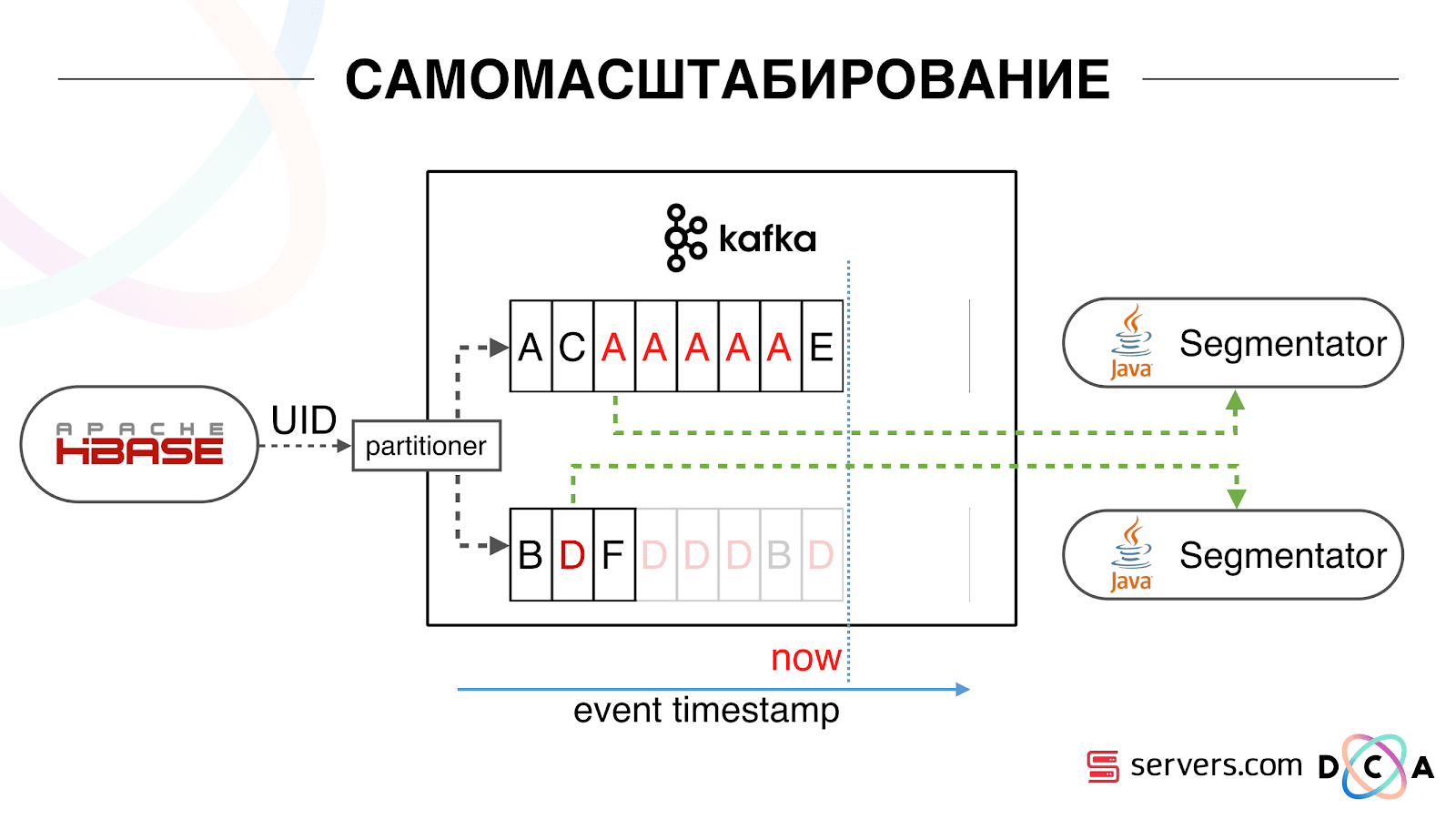 Karenanya, kami mulai menyimpan cache lokal tertentu pada setiap segmenter dengan tanggal saat kami terakhir menganalisis pengguna ini. Artinya, kami memprosesnya, menulis userid dan cap waktu ke cache. Setiap pesan kafka juga memiliki stempel waktu - kami hanya membandingkannya: jika stempel waktu dalam antrian kurang dari tanggal segmentasi terakhir - kami telah menganalisis pengguna untuk data ini, dan Anda dapat melewati acara ini.Peristiwa pengguna (Merah A) dapat berbeda, dan mereka rusak. Pengguna dapat membuka beberapa tab latar belakang, membuka beberapa tautan secara berurutan, mungkin situs tersebut memiliki beberapa mitra sekaligus, yang masing-masing mengirimkan data ini.Pixel kami dapat melihat kunjungan pengguna, dan kemudian beberapa tindakan lainnya - kami akan mengirimkan helmnya ke diri kami sendiri. Lima peristiwa tiba, kami sedang memproses merah pertama A. Jika acara telah tiba, maka sudah dalam HBase. Kami melihat acara, dijalankan melalui serangkaian skrip. Kami melihat acara berikut, dan ada semua peristiwa yang sama, karena sudah direkam. Kami menjalankannya lagi dan menyimpan cache dengan tanggal, membandingkannya dengan cap waktu acara.
Karenanya, kami mulai menyimpan cache lokal tertentu pada setiap segmenter dengan tanggal saat kami terakhir menganalisis pengguna ini. Artinya, kami memprosesnya, menulis userid dan cap waktu ke cache. Setiap pesan kafka juga memiliki stempel waktu - kami hanya membandingkannya: jika stempel waktu dalam antrian kurang dari tanggal segmentasi terakhir - kami telah menganalisis pengguna untuk data ini, dan Anda dapat melewati acara ini.Peristiwa pengguna (Merah A) dapat berbeda, dan mereka rusak. Pengguna dapat membuka beberapa tab latar belakang, membuka beberapa tautan secara berurutan, mungkin situs tersebut memiliki beberapa mitra sekaligus, yang masing-masing mengirimkan data ini.Pixel kami dapat melihat kunjungan pengguna, dan kemudian beberapa tindakan lainnya - kami akan mengirimkan helmnya ke diri kami sendiri. Lima peristiwa tiba, kami sedang memproses merah pertama A. Jika acara telah tiba, maka sudah dalam HBase. Kami melihat acara, dijalankan melalui serangkaian skrip. Kami melihat acara berikut, dan ada semua peristiwa yang sama, karena sudah direkam. Kami menjalankannya lagi dan menyimpan cache dengan tanggal, membandingkannya dengan cap waktu acara. Berkat ini, sistem memperoleh properti skalabilitas diri. Sumbu y adalah persentase dari apa yang kami lakukan dengan ID pengguna ketika mereka datang kepada kami. Hijau - pekerjaan yang kami lakukan, meluncurkan skrip segmentasi. Kuning - kami tidak melakukan ini, karena Sudah tersegmentasi persis data ini.
Berkat ini, sistem memperoleh properti skalabilitas diri. Sumbu y adalah persentase dari apa yang kami lakukan dengan ID pengguna ketika mereka datang kepada kami. Hijau - pekerjaan yang kami lakukan, meluncurkan skrip segmentasi. Kuning - kami tidak melakukan ini, karena Sudah tersegmentasi persis data ini.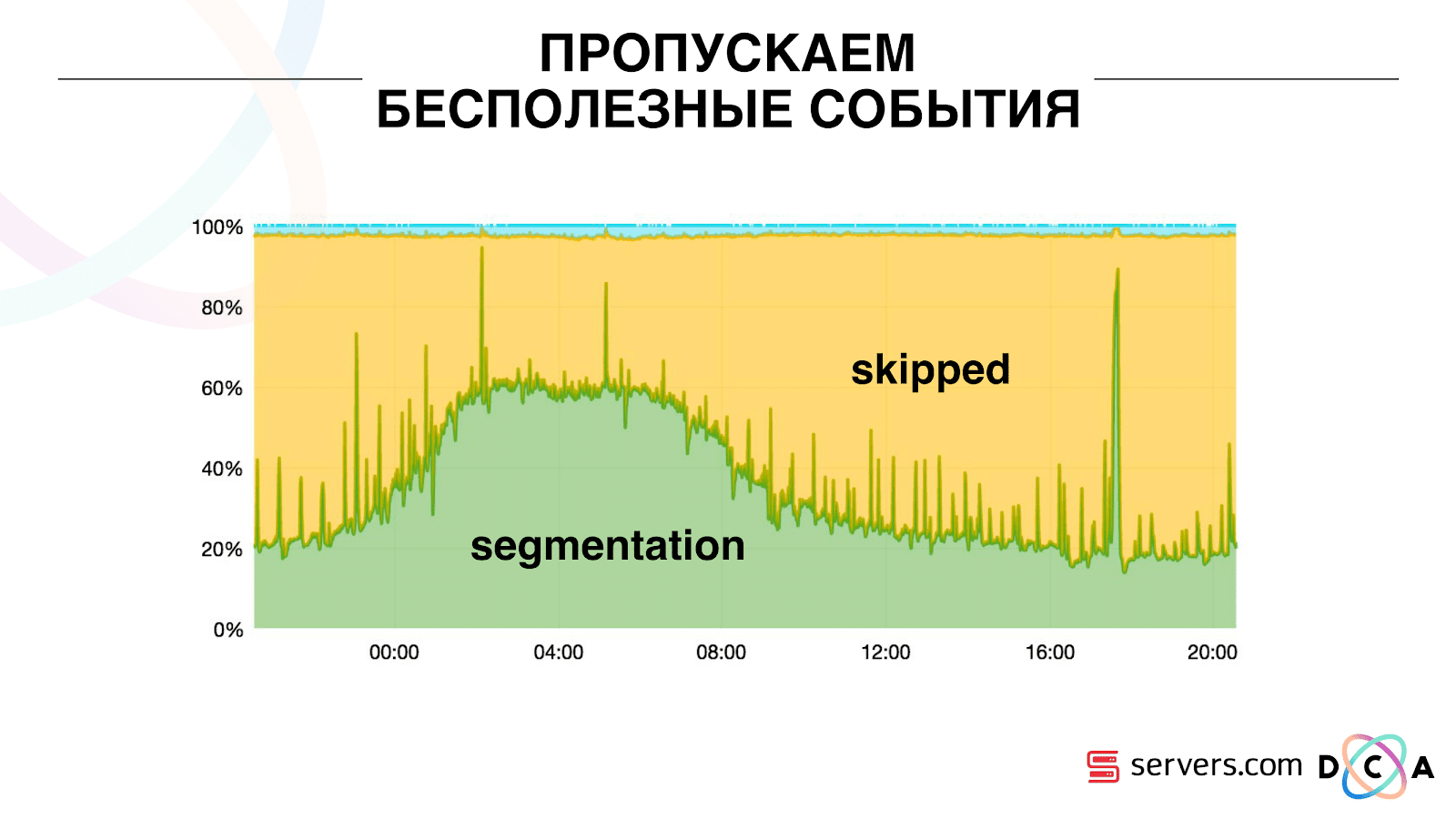 Dapat dilihat bahwa ada sumber daya di malam hari, aliran data lebih sedikit, dan Anda dapat mengelompokkan setiap peristiwa kedua. Hari sumber daya yang lebih kecil, dan kami hanya mengelompokkan 20% dari acara. Lompatan pada akhir hari - mitra mengunggah file data yang belum pernah kita lihat sebelumnya, dan mereka harus "tersegmentasi" tersegmentasi.Sistem itu sendiri beradaptasi dengan memuat pertumbuhan. Jika kami memiliki mitra yang sangat besar, kami memproses data yang sama tetapi sedikit lebih jarang. Dalam hal ini, karakteristik sistem akan memburuk pada malam hari, segmentasi akan tertunda bukan selama 2-3 detik, tetapi selama satu menit. Di pagi hari, tambahkan server dan kembali ke hasil yang diinginkan.Jadi, kami menyimpan sekitar 5 kali di server. Sekarang kami bekerja pada 10 server, dan itu akan memakan waktu 50-60.Hal biru kecil di atas adalah bot. Ini adalah bagian tersulit dari segmentasi. Mereka memiliki sejumlah besar kunjungan, mereka membuat beban yang sangat besar pada setrika. Kami melihat setiap bot di server terpisah. Kami dapat mengumpulkan di dalamnya cache lokal dengan daftar hitam bot. Memperkenalkan antifraud sederhana: jika pengguna melakukan terlalu banyak kunjungan untuk waktu tertentu, maka ada sesuatu yang salah dengannya, kami menambahkan ke daftar hitam untuk sementara waktu. Ini adalah garis biru kecil, sekitar 5%. Mereka memberi kami 30% penghematan pada CPU.Dengan demikian, kami telah mencapai apa yang kami lihat seluruh pipa pemrosesan data pada setiap tahap. Kami melihat metrik tentang seberapa banyak pesan di Kafka. Di malam hari, sesuatu tumpul di suatu tempat, waktu pemrosesan meningkat menjadi satu menit, kemudian dilepaskan dan kembali normal.
Dapat dilihat bahwa ada sumber daya di malam hari, aliran data lebih sedikit, dan Anda dapat mengelompokkan setiap peristiwa kedua. Hari sumber daya yang lebih kecil, dan kami hanya mengelompokkan 20% dari acara. Lompatan pada akhir hari - mitra mengunggah file data yang belum pernah kita lihat sebelumnya, dan mereka harus "tersegmentasi" tersegmentasi.Sistem itu sendiri beradaptasi dengan memuat pertumbuhan. Jika kami memiliki mitra yang sangat besar, kami memproses data yang sama tetapi sedikit lebih jarang. Dalam hal ini, karakteristik sistem akan memburuk pada malam hari, segmentasi akan tertunda bukan selama 2-3 detik, tetapi selama satu menit. Di pagi hari, tambahkan server dan kembali ke hasil yang diinginkan.Jadi, kami menyimpan sekitar 5 kali di server. Sekarang kami bekerja pada 10 server, dan itu akan memakan waktu 50-60.Hal biru kecil di atas adalah bot. Ini adalah bagian tersulit dari segmentasi. Mereka memiliki sejumlah besar kunjungan, mereka membuat beban yang sangat besar pada setrika. Kami melihat setiap bot di server terpisah. Kami dapat mengumpulkan di dalamnya cache lokal dengan daftar hitam bot. Memperkenalkan antifraud sederhana: jika pengguna melakukan terlalu banyak kunjungan untuk waktu tertentu, maka ada sesuatu yang salah dengannya, kami menambahkan ke daftar hitam untuk sementara waktu. Ini adalah garis biru kecil, sekitar 5%. Mereka memberi kami 30% penghematan pada CPU.Dengan demikian, kami telah mencapai apa yang kami lihat seluruh pipa pemrosesan data pada setiap tahap. Kami melihat metrik tentang seberapa banyak pesan di Kafka. Di malam hari, sesuatu tumpul di suatu tempat, waktu pemrosesan meningkat menjadi satu menit, kemudian dilepaskan dan kembali normal. Kita dapat memantau bagaimana tindakan kita dengan sistem memengaruhi throughputnya, kita dapat melihat seberapa banyak script berjalan, di mana perlu untuk mengoptimalkan, dan berapa banyak yang bisa disimpan. Kita dapat melihat ukuran segmen, dinamika ukuran segmen, mengevaluasi asosiasi dan persimpangannya. Ini dapat dilakukan untuk ukuran segmen yang kurang lebih sama.
Kita dapat memantau bagaimana tindakan kita dengan sistem memengaruhi throughputnya, kita dapat melihat seberapa banyak script berjalan, di mana perlu untuk mengoptimalkan, dan berapa banyak yang bisa disimpan. Kita dapat melihat ukuran segmen, dinamika ukuran segmen, mengevaluasi asosiasi dan persimpangannya. Ini dapat dilakukan untuk ukuran segmen yang kurang lebih sama.Apa yang ingin Anda saring?
Kami memiliki cluster Hadoop dengan beberapa sumber daya komputasi. Dia sibuk - analis mengerjakannya di siang hari, tetapi pada malam hari dia praktis bebas. Secara umum, kami dapat membuat wadah dan menjalankan segmenter sebagai proses terpisah di dalam kluster kami. Kami ingin menyimpan statistik dengan lebih akurat untuk menghitung volume persimpangan dengan lebih akurat. Kami juga perlu optimisasi pada CPU. Ini secara langsung mempengaruhi biaya keputusan.Untuk meringkas: Kafka baik, tetapi, seperti halnya teknologi lainnya, Anda perlu memahami cara kerjanya di dalam dan apa yang terjadi padanya. Misalnya, jaminan prioritas pesan hanya berfungsi di dalam partisi. Jika Anda mengirim pesan yang masuk ke partisi yang berbeda, tidak jelas dalam urutan apa mereka akan diproses.Data nyata sangat penting. Jika kami tidak menguji lalu lintas nyata, maka kemungkinan besar kami tidak akan melihat masalah dengan bot, dengan sesi pengguna. Akan mengembangkan sesuatu dalam ruang hampa, lari dan berbaring. Penting untuk memantau apa yang Anda anggap perlu untuk dipantau, dan bukan untuk memantau apa yang tidak Anda pikirkan.Menit periklanan. Jika Anda menyukai laporan ini dari konferensi SmartData, harap perhatikan bahwa SmartData 2018 akan diadakan di St. Petersburg pada 15 Oktober, sebuah konferensi untuk mereka yang tenggelam dalam dunia pembelajaran mesin, analisis, dan pemrosesan data. Program ini akan memiliki banyak hal menarik, situs ini sudah memiliki pembicara dan laporan pertama.