Halo kolega.
Kami baru saja menerjemahkan buku yang menarik dari Brendan Burns, yang berbicara tentang pola desain untuk sistem terdistribusi

Selain itu, terjemahan buku "
Mastering Kubernetes " (edisi ke-2) sudah berjalan lancar dan buku penulis tentang Docker akan diterbitkan pada bulan September, dan akan ada posting terpisah tentang hal itu.
Kami percaya bahwa perhentian berikutnya di jalan ini adalah sebuah buku tentang Prometheus, jadi hari ini kami membawa kepada Anda terjemahan dari sebuah artikel pendek oleh Björn Wenzel tentang interaksi erat antara Prometheus dan Kubernetes. Harap ingat untuk berpartisipasi dalam survei ini.
Memantau cluster Kubernetes adalah bisnis yang sangat penting. Cluster berisi banyak informasi yang memungkinkan Anda untuk menjawab pertanyaan dari kategori: berapa banyak memori dan ruang disk yang tersedia sekarang, seberapa aktif cpu digunakan? Wadah mana yang menghabiskan berapa banyak sumber daya? Ini juga mencakup pertanyaan tentang status aplikasi yang berjalan di cluster.
Salah satu alat yang dimiliki untuk pekerjaan semacam itu disebut Prometheus. Didukung oleh Cloud Native Computing Foundation, awalnya Prometheus dikembangkan oleh SoundCloud. Secara konseptual, Prometheus sangat sederhana:
Arsitektur
Server Prometheus dapat berfungsi, misalnya, di kluster Kubernetes dan menerima konfigurasi melalui file khusus. Konfigurasi ini, khususnya, berisi informasi tentang di mana terminal berada untuk mengumpulkan data setelah interval yang ditentukan. Kemudian, server Prometheus meminta metrik dari terminal-terminal ini dalam format khusus (biasanya tersedia di
/metrics ) dan menyimpannya dalam basis data deret waktu. Berikut ini adalah contoh singkat: file konfigurasi kecil yang meminta metrik dari modul
node_exporter digunakan sebagai agen di setiap node:
scrape_configs: - job_name: "node_exporter" scrape_interval: "15s" target_groups: - targets: ['<ip>:9100']
Pertama kita mendefinisikan nama pekerjaan
job_name , kemudian nama ini dapat digunakan untuk meminta metrik di Prometheus, kemudian
scrape_interval data
scrape_interval dan sekelompok server yang menjalankan
node_exporter . Sekarang Prometheus akan setiap 15 detik meminta server untuk
path /metrics ke metrik saat ini. Itu terlihat seperti ini:
Pertama, nama metrik diberikan, lalu tanda tangan (informasi dalam kurung kurawal) dan, akhirnya, nilai metrik. Yang paling menarik adalah fungsi pencarian untuk metrik ini. Prometheus memiliki
bahasa permintaan yang sangat kuat untuk tujuan ini.
Gagasan utama Prometheus, yang sudah dijelaskan di atas, adalah ini: Prometheus pada jeda waktu yang ditentukan memeriksa port untuk metrik dan menyimpannya dalam basis data deret waktu. Jika Prometheus tidak dapat menghapus metrik itu sendiri, maka ada fungsi lain yang disebut pushgateway. Gerbang pushg menerima metrik yang dikirim oleh pekerjaan eksternal, dan Prometheus mengumpulkan informasi dari gateway ini pada interval tertentu.
Komponen opsional lain dari arsitektur Prometheus adalah
alertmanager . Komponen
alertmanager memungkinkan
alertmanager untuk menetapkan batas, dan jika melebihi batasnya, mengirim pemberitahuan melalui email, kendur, atau opsgenie.
Selain itu, server Prometheus berisi banyak
fitur terintegrasi , misalnya, ia dapat meminta instance EC2 di API Amazon atau meminta pod, node, dan layanan dari Kubernetes. Ini juga memiliki banyak
eksportir , misalnya,
node_exporter tersebut. Eksportir tersebut dapat bekerja, misalnya, pada simpul di mana aplikasi seperti MySQL diinstal dan pada interval tertentu untuk polling aplikasi untuk metrik dan menyediakannya di terminal / metrik, dan server Prometheus dapat mengumpulkan metrik ini dari sana.
Selain itu, tidak sulit untuk menulis eksportir Anda sendiri - misalnya, untuk aplikasi yang menyediakan metrik seperti informasi jvm. Misalnya, ada
perpustakaan yang dikembangkan oleh Prometheus untuk mengekspor metrik tersebut. Pustaka ini dapat digunakan bersama dengan Spring, dan juga memungkinkan Anda untuk mendefinisikan metrik Anda sendiri. Ini adalah contoh dari halaman
client_java :
@Controller public class MyController { @RequestMapping("/") @PrometheusTimeMethod(name = "my_controller_path_duration_seconds", help = "Some helpful info here") public Object handleMain() {
Ini adalah metrik yang menjelaskan durasi metode, dan metrik lainnya sekarang dapat diberikan melalui terminal atau didorong melalui pushgateway.
Penggunaan di Cluster Kubernetes
Seperti yang saya sebutkan, untuk menggunakan Prometheus di cluster Kubernetes ada kemampuan terintegrasi untuk menghapus informasi dari perapian, simpul dan layanan. Yang paling menarik, Kubernetes dirancang khusus untuk bekerja dengan Prometheus. Misalnya,
kubelet dan
kube-apiserver memberikan metrik yang
kube-apiserver di Prometheus, jadi pemantauannya sangat sederhana.
Dalam contoh ini, sebagai permulaan, saya menggunakan grafik helm resmi.
Bagi saya sendiri, saya sedikit mengubah konfigurasi grafik helm default. Pertama, saya perlu mengaktifkan
rbac di instalasi Prometheus, jika tidak Prometheus tidak dapat mengumpulkan informasi dari
kube-apiserver . Oleh karena itu, saya menulis file values.yaml saya sendiri, yang menjelaskan bagaimana grafik helm harus ditampilkan.
Saya membuat perubahan paling sederhana:
alertmanager.enabled: false , yaitu, membatalkan penyebaran alertmanager di cluster (saya tidak akan menggunakan alertmanager, saya pikir lebih mudah untuk mengkonfigurasi peringatan dengan Grafana)kubeStateMetrics.enabled: false Saya pikir metrik ini mengembalikan hanya beberapa informasi tentang jumlah maksimum perapian. Ketika Anda pertama kali memulai sistem, informasi ini tidak penting bagi sayaserver.persistentVolume.enabled: false sampai saya memiliki volume persisten yang dikonfigurasi secara default- Saya mengubah konfigurasi pengumpulan informasi di Prometheus, seperti yang dilakukan pada permintaan tarik di github . Faktanya adalah bahwa dalam Kubernetes v1.7, metrik cAdvisor bekerja pada port yang berbeda.
Setelah itu, Anda dapat memulai Prometheus menggunakan helm:
helm install stable/prometheus --name prometheus-monitoring -f prometheus-values.yamlJadi kami menginstal server Prometheus, dan pada setiap node - instal di bawah node_exporter. Sekarang Anda dapat pergi ke GUI web Prometheus dan melihat beberapa informasi:
kubectl port-forward <prometheus-server-pod> 9090Tangkapan layar berikut menunjukkan untuk tujuan apa Prometheus mengumpulkan informasi (Status / target), dan ketika informasi diambil beberapa kali di yang terakhir:
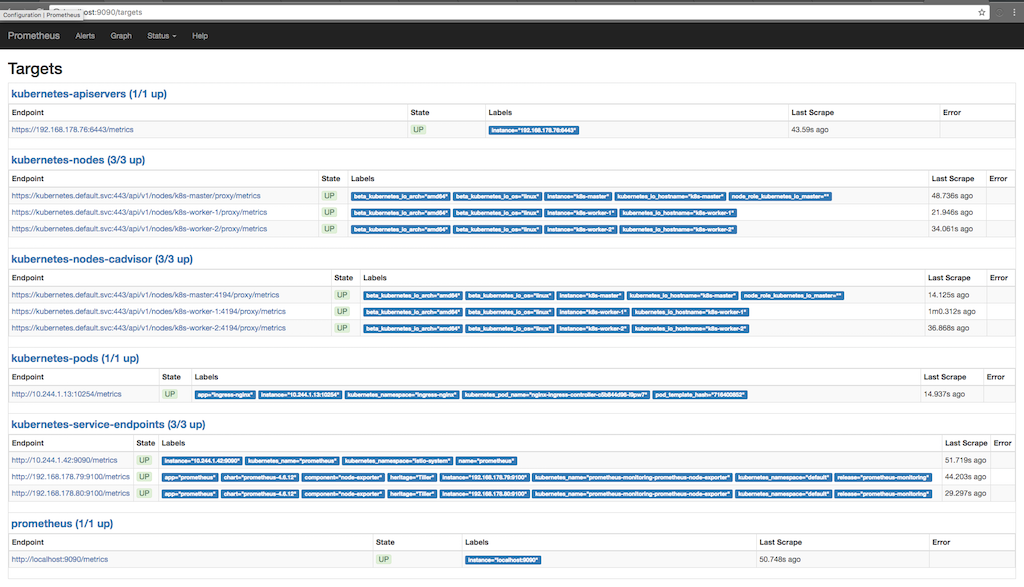
Di sini Anda dapat melihat bagaimana Prometheus meminta metrik dari apiserver, node, cadvisor yang berjalan pada node dan titik akhir layanan kubernet. Anda dapat melihat metrik secara detail dengan membuka Grafik dan menulis kueri untuk melihat informasi yang kami minati:

Di sini, misalnya, kita melihat penyimpanan gratis di titik mount “/”. Di bagian bawah diagram, tanda tangan ditambahkan yang ditambahkan oleh Prometheus atau sudah tersedia di node_exporter. Kami menggunakan tanda tangan ini untuk meminta hanya titik mount “/”.
Metrik khusus dengan anotasi
Seperti yang telah diperlihatkan dalam tangkapan layar pertama, di mana tujuan yang diminta metrik dari Demetheus diperoleh, ada juga metrik untuk perapian yang bekerja di kluster. Salah satu fitur bagus Prometheus adalah kemampuan untuk mengambil informasi dari seluruh perapian. Jika wadah di perapian menyediakan metrik Prometheus, maka kami dapat mengumpulkan metrik ini menggunakan Prometheus secara otomatis. Satu-satunya hal yang perlu kita perhatikan adalah menyediakan instalasi dengan dua anotasi; dalam kasus saya
nginx-ingress-controller melakukan ini di luar kotak:
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: nginx-ingress-controller namespace: ingress-nginx spec: replicas: 1 selector: matchLabels: app: ingress-nginx template: metadata: labels: app: ingress-nginx annotations: prometheus.io/port: '10254' prometheus.io/scrape: 'true' ...
Di sini kita melihat bahwa templat penyebaran dilengkapi dengan dua anotasi Prometheus. Yang pertama menjelaskan port yang melaluinya Prometheus harus meminta metrik, dan yang kedua mengaktifkan fungsi pengumpulan data. Sekarang, Prometheus meminta
Kubernetes Api-Server pod yang dianotasi untuk mengumpulkan informasi dan mencoba mengumpulkan informasi dari terminal / metrik.
Pekerjaan federasi
Kami memiliki proyek di mana Prometheus digunakan dalam mode gabungan. Idenya adalah ini: kami hanya mengumpulkan informasi yang hanya dapat diakses dari dalam cluster (atau lebih mudah untuk mengumpulkan informasi ini dari dalam cluster), mengaktifkan mode gabungan dan mendapatkan informasi ini menggunakan Prometheus kedua yang dipasang di luar cluster. Dengan demikian, dimungkinkan untuk mengumpulkan informasi dari beberapa cluster Kubernetes sekaligus, juga menangkap komponen lain yang tidak dapat diakses dari dalam cluster ini atau tidak terkait dengan cluster ini. Selain itu, maka tidak perlu untuk menyimpan data yang dikumpulkan dalam cluster untuk waktu yang lama, dan jika ada yang salah dengan cluster, kami dapat mengumpulkan beberapa informasi, misalnya, node_exporter, dari luar cluster.