Halo, Habr! Hari ini saya ingin berbicara tentang bagaimana pembelajaran yang mendalam membantu kita lebih memahami seni. Artikel ini dibagi menjadi beberapa bagian sesuai dengan tugas yang kami selesaikan:
- mencari gambar dalam database dari foto yang diambil oleh ponsel;
- penentuan gaya dan genre gambar yang tidak ada dalam database.
Semua ini menjadi bagian dari layanan database Arthive dan aplikasi mobile-nya.
Tugas mengidentifikasi lukisan adalah untuk menemukan gambar yang sesuai dari gambar yang berasal dari aplikasi mobile dalam database, menghabiskan kurang dari satu detik untuk ini. Pemrosesan seluruhnya dalam perangkat seluler dikeluarkan pada tahap studi pra-desain. Selain itu, ternyata mustahil untuk melakukan pemisahan gambar dari latar belakang di latar belakang dalam kondisi pemotretan nyata. Karena itu, kami memutuskan bahwa layanan kami akan menerima seluruh foto dari ponsel sebagai input, dengan semua distorsi, kebisingan, dan kemungkinan tumpang tindih sebagian.

Akankah kami membantu Dasha menemukan lukisan-lukisan ini dalam database lebih dari 200.000 gambar?
Basis seni Arthive mencakup hampir 250.000 gambar, bersama dengan berbagai metadata. Pangkalan ini terus diperbarui - dari puluhan hingga ratusan gambar per hari. Bahkan dipompa dengan resolusi terbatas (tidak lebih dari 1400 piksel di sebagian besar sisi), gambar menempati lebih dari 80 gigabyte. Sayangnya, basis datanya “kotor”: ada file yang rusak atau terlalu kecil, gambar yang tidak selaras dan tidak diproses, gambar duplikat. Namun, secara keseluruhan ini adalah data yang bagus.
Perbandingan lukisan
Mari kita lihat bagaimana gambar dalam database terlihat:
Pada dasarnya, gambar-gambar dalam basisdata disejajarkan, dipotong ke tepi kanvas, warnanya dipertahankan.
Dan inilah tampilan permintaan dari perangkat seluler:

Warna hampir selalu terdistorsi - pencahayaan kompleks ditemukan, silau hadir, bahkan refleksi dari lukisan lain dalam kaca ditemukan. Gambar-gambar itu sendiri terdistorsi perspektif, dapat dipotong sebagian, atau sebaliknya, menempati kurang dari setengah gambar, dapat ditutup sebagian, misalnya oleh orang-orang.
Untuk mengidentifikasi gambar, Anda harus dapat membandingkan gambar dari permintaan dengan gambar dalam database.
Untuk membandingkan gambar yang rentan terhadap distorsi perspektif dan distorsi warna, kami menggunakan pencocokan titik kunci. Untuk melakukan ini, kami menemukan titik kunci dengan deskriptor pada gambar, menemukan korespondensi mereka, dan kemudian secara homografis menampilkan titik yang sesuai menggunakan metode RANSAC. Ini umumnya dilakukan dengan cara yang sama seperti yang dijelaskan dalam contoh OpenCV . Jika jumlah titik "awal" yang ditemukan oleh RANSAC cukup besar, dan transformasi homografik yang ditemukan terlihat masuk akal (tidak memiliki penskalaan atau rotasi yang kuat), maka kita dapat mengasumsikan bahwa gambar yang diinginkan adalah satu dan gambar yang sama tunduk pada distorsi perspektif .
Contoh pemetaan poin-poin utama:

Contoh Pencocokan Negatif Perbandingan lukisan dari contoh di atas Tentu saja, mencari poin-poin penting biasanya merupakan proses yang agak lambat, tetapi untuk mencari basis data Anda dapat menemukan poin-poin utama dari semua gambar di muka dan menyimpannya. Dalam eksperimen kami, kami sampai pada kesimpulan bahwa kurang dari 1000 poin cukup untuk pencarian lukisan yang andal. Saat menggunakan 64 byte per titik (koordinat + deskriptor AKAZE) untuk menyimpan 1024 poin, 64 kbytes per gambar atau sekitar 15 GB per basis sudah cukup.
Membandingkan gambar dengan poin-poin utama dalam kasus kami membutuhkan waktu sekitar 15 ms, yaitu, untuk penghitungan lengkap dari database 250.000 gambar, dibutuhkan sekitar 1 jam. Ini banyak sekali.
Di sisi lain, jika kita belajar untuk dengan cepat memilih dari seluruh database beberapa (misalkan, 100) dari kandidat yang paling mungkin, kita akan memenuhi target waktu 1 detik per permintaan.
Peringkat kesamaan
Jaringan konvolusi yang mendalam telah membuktikan diri sebagai cara yang baik untuk mencari gambar yang serupa. Jaringan digunakan untuk mengekstraksi fitur dan menghitung berdasarkan deskriptor yang memiliki properti bahwa jarak (Euclidean, cosinus atau lainnya) antara deskriptor gambar yang sama akan lebih kecil daripada untuk gambar yang berbeda.
Anda dapat melatih jaringan sedemikian rupa sehingga untuk gambar gambar dari pangkalan dan gambar yang terdistorsi dari foto, itu menghasilkan deskriptor dekat, dan untuk gambar yang berbeda - yang lebih jauh. Lebih jauh, jaringan seperti itu digunakan untuk menghitung deskriptor semua gambar dalam database dan deskriptor foto dalam permintaan. Anda dapat dengan cepat memilih gambar terdekat dan mengaturnya sesuai dengan jarak antara deskriptor.
Cara dasar untuk melatih jaringan untuk menghitung deskriptor adalah dengan menggunakan jaringan Siam.
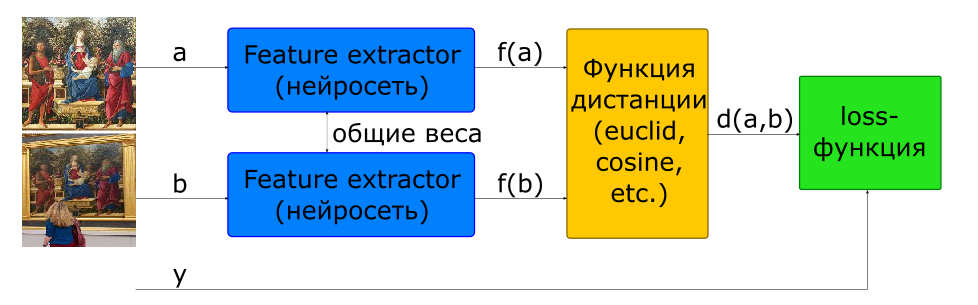
- input gambar
jika dan - satu kelas jika berbeda
- deskriptor gambar
- jarak antara sepasang vektor fitur
- fungsi obyektif
Untuk membangun arsitektur seperti itu, jaringan yang menghitung deskriptor (Feature Extractor) digunakan dalam model 2 kali dengan bobot umum. Beberapa gambar diumpankan ke input jaringan. Jaringan Feature Extractor menghitung deskriptor gambar, kemudian jaringan menghitung jarak menurut metrik yang ditentukan (biasanya jarak Euclidean atau kosinus digunakan). Fungsi target dari pelatihan jaringan dibangun sedemikian rupa sehingga untuk pasangan positif (gambar dari satu gambar) jarak menurun, dan untuk negatif (gambar dari gambar yang berbeda) meningkat. Untuk mengurangi pengaruh pasangan negatif, jarak di antara mereka dibatasi oleh nilai margin.
Dengan demikian, kita dapat mengatakan bahwa dalam proses pembelajaran, jaringan berusaha untuk menghitung deskriptor dari gambar yang sama di dalam hypersphere dengan jari-jari margin, dan deskriptor dari yang berbeda - untuk mendorong keluar dari bidang ini.
Misalnya, ini mungkin terlihat seperti melatih deskriptor dua dimensi menggunakan jaringan Siam pada dataset MNIST.
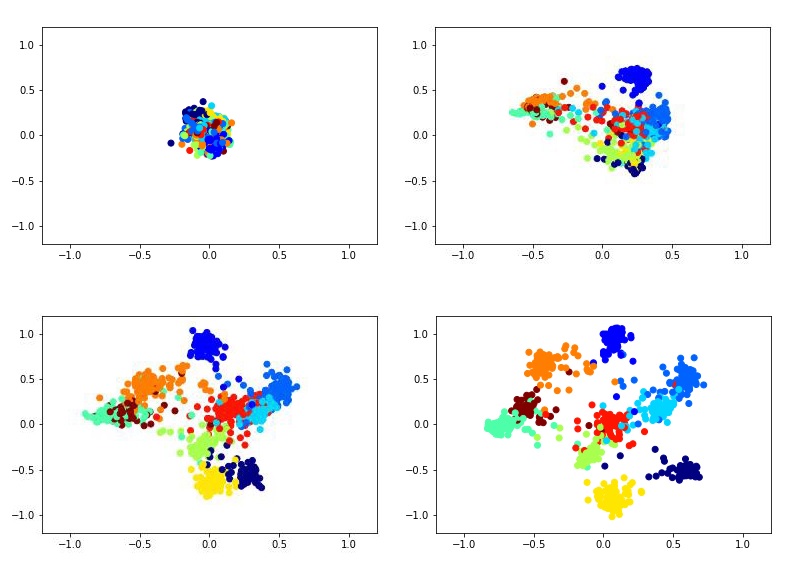
Untuk melatih jaringan siam, Anda perlu memasukkan pasangan gambar dan label yang sama dengan 1 jika gambar tersebut berasal dari kelas yang sama, atau 0 jika berbeda. Ada masalah dalam memilih proporsi pasangan positif dan negatif. Idealnya, tentu saja, akan diperlukan untuk tunduk pada pelatihan jaringan semua kemungkinan kombinasi pasangan dari set pelatihan, tetapi ini secara teknis tidak mungkin. Dan jumlah pasangan negatif dalam hal ini secara signifikan melebihi jumlah yang positif, yang juga tidak akan memiliki efek yang sangat baik pada proses pembelajaran.
Bagian dari masalah dengan memilih proporsi pasangan untuk pelatihan diselesaikan dengan menggunakan arsitektur triplet.
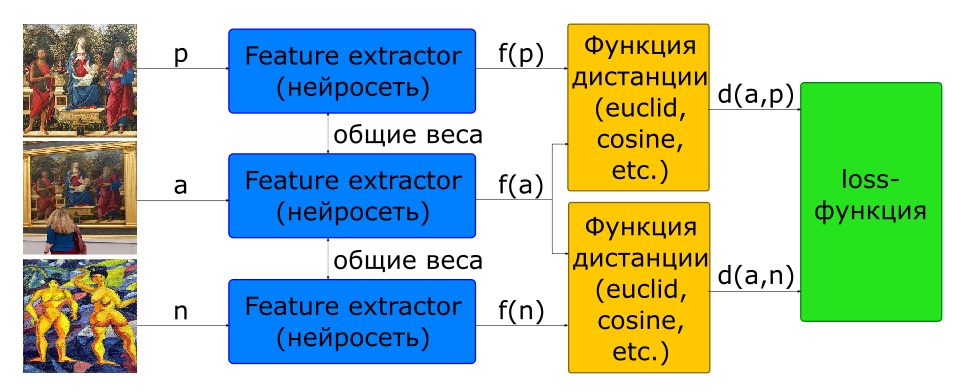
- input gambar: - satu gambar, - yang lain
- fungsi obyektif
Pada input dari jaringan seperti itu, 3 gambar segera dibentuk, membentuk pasangan positif dan negatif.
Selain itu, hampir semua peneliti setuju bahwa pilihan pasangan negatif sangat penting untuk pembelajaran jaringan. Fungsi objektif untuk banyak sampel (pasangan untuk siam, tiga kali lipat untuk triplet) ternyata 0 jika mereka tidak melanggar batas margin, oleh karena itu, sampel tersebut tidak berpartisipasi dalam pelatihan jaringan. Seiring waktu, proses pembelajaran melambat bahkan lebih, karena semakin sedikit sampel dengan nilai bukan nol dari fungsi tujuan. Untuk mengatasi masalah ini, pasangan negatif dipilih bukan secara kebetulan, tetapi dengan mencari penambangan hard case. Dalam praktiknya, beberapa kandidat negatif dipilih untuk ini, untuk masing-masing deskriptor dihitung menggunakan versi terbaru dari bobot jaringan (dari era sebelumnya atau bahkan dari yang sekarang). Memiliki deskriptor, Anda dapat memilih negatif di masing-masing tiga sehingga menghasilkan kerugian yang tidak diketahui nol.
Untuk mencari gambar yang serupa, Feature Extractor dipisahkan dari jaringan dan digunakan untuk menghitung deskriptor. Untuk gambar dalam database, deskriptor dihitung terlebih dahulu saat ditambahkan. Dengan demikian, tugas menemukan gambar yang serupa adalah menghitung deskriptor gambar dalam kueri dan mencari deskriptor yang paling dekat dengan metrik yang diberikan dalam database.
Extractor Fitur Jaringan kami didasarkan pada arsitektur Inception v3. Salah satu lapisan antara dipilih secara eksperimental, berdasarkan pada keluaran di mana deskriptor dari 512 bilangan real dihitung.
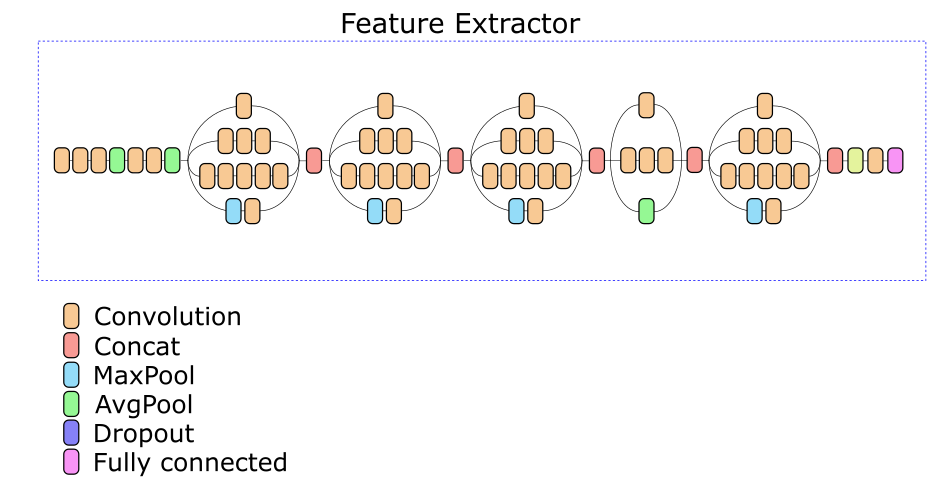
Augmentasi Data
Alangkah baiknya jika kita dapat menempatkan setiap gambar dalam bingkai yang berbeda, di dinding yang berbeda dan mengambil gambar setiap kali dari sudut yang berbeda pada ponsel yang berbeda. Dalam praktiknya, ini, tentu saja, tidak mungkin. Oleh karena itu, perlu untuk menghasilkan data pelatihan.
Untuk menghasilkan data, sekitar 500 foto berbagai lukisan dengan latar belakang berbeda di bawah kondisi pencahayaan yang berbeda dikumpulkan. Untuk setiap foto, 4 titik dipilih sesuai dengan sudut kanvas gambar. Untuk empat poin, kita dapat secara sewenang-wenang memasukkan gambar apa pun ke dalam bingkai, dengan demikian mengganti gambar dan mendapatkan distorsi perspektif yang hampir acak dari gambar dari database. Melengkapi proses ini dengan crop acak, noise dan distorsi warna, kami mendapatkan kesempatan untuk menghasilkan gambar yang benar-benar cocok yang meniru foto-foto lukisan.

Pemisahan gambar dari latar belakang
Kualitas pekerjaan dan model untuk mengidentifikasi lukisan, dan model untuk mengklasifikasikan genre / gaya, sangat tergantung pada seberapa baik gambar dipisahkan dari latar belakang. Idealnya, sebelum Anda memasukkan gambar ke dalam model, Anda harus menemukan 4 sudut kanvas dan perspektif tampilan dalam kotak. Dalam praktiknya, ternyata sangat sulit untuk mengimplementasikan algoritma yang akan menjamin ini. Di satu sisi, ada beragam latar belakang, bingkai, dan objek yang dapat jatuh ke dalam bingkai di dekat gambar. Di sisi lain, ada lukisan di dalamnya yang memiliki garis besar bentuk persegi panjang (jendela, fasad bangunan, gambar-dalam-gambar). Akibatnya, seringkali sangat sulit untuk mengatakan di mana gambar berakhir dan lingkungannya dimulai.
Pada akhirnya, kami menetapkan implementasi sederhana berdasarkan metode klasik dari visi komputer (deteksi perbatasan + pemfilteran morfologis + analisis komponen yang terhubung), yang memungkinkan Anda dengan percaya diri memotong latar belakang monofonik, tetapi tidak kehilangan sebagian gambar.
Kecepatan kerja
Algoritma pemrosesan kueri terdiri dari langkah-langkah utama berikut:
- persiapan - pada kenyataannya, detektor sederhana dari gambar diimplementasikan, yang berfungsi dengan baik jika gambar berisi latar belakang polos;
- menghitung deskriptor gambar menggunakan jaringan dalam;
- peringkat gambar berdasarkan jarak ke deskriptor dalam database;
- mencari poin-poin penting dalam gambar;
- memeriksa kandidat dalam urutan peringkat.
Kami menguji kecepatan jaringan pada 200 permintaan, waktu pemrosesan berikut untuk masing-masing tahap diperoleh (waktu dalam detik):
| panggung | min | maks | rata-rata |
|---|
| Persiapan (pencarian gambar) | 0,008 | 0,011 | 0,016 |
| Perhitungan Deskriptor (GPU) | 0,082 | 0,092 | 0,088 |
| KNN (k <500, CPU, brute force) | 0,199 | 0,820 | 0,394 |
| Pencarian Titik Kunci | 0,031 | 0,432 | 0,156 |
| Periksa Poin Kunci | 0,007 | 9,844 | 2.585 |
| Total waktu permintaan | 0,358 | 10.386 | 3.239 |
Karena verifikasi kandidat berhenti segera, karena gambar ditemukan dengan keyakinan yang cukup, kita dapat mengasumsikan bahwa waktu pemrosesan minimum dari permintaan sesuai dengan gambar yang ditemukan di antara kandidat pertama. Waktu permintaan maksimum diperoleh untuk lukisan yang tidak ditemukan sama sekali - cek berhenti setelah 500 kandidat.
Dapat dilihat bahwa sebagian besar waktu dihabiskan untuk pemilihan kandidat dan verifikasi mereka. Perlu dicatat bahwa implementasi langkah-langkah ini telah dibuat sangat tidak optimal dan memiliki potensi besar untuk akselerasi.
Pencarian Gandakan
Setelah membangun indeks penuh dari dasar lukisan, kami menggunakannya untuk mencari duplikat dalam database. Setelah sekitar 3 jam melihat database, ditemukan bahwa setidaknya 13657 gambar diulang dalam database dua kali (dan sekitar tiga).
Selain itu, ditemukan kasus yang sangat menarik yang bukan duplikat.
 Satu dua
Satu dua . Tampaknya ini adalah dua tahap dari pekerjaan yang sama.
 Satu
Satu ,
Dua ,
Tiga . Jangan memperhatikan namanya - ketiga gambar berbeda.
Serta contoh identifikasi positif palsu oleh poin-poin penting.
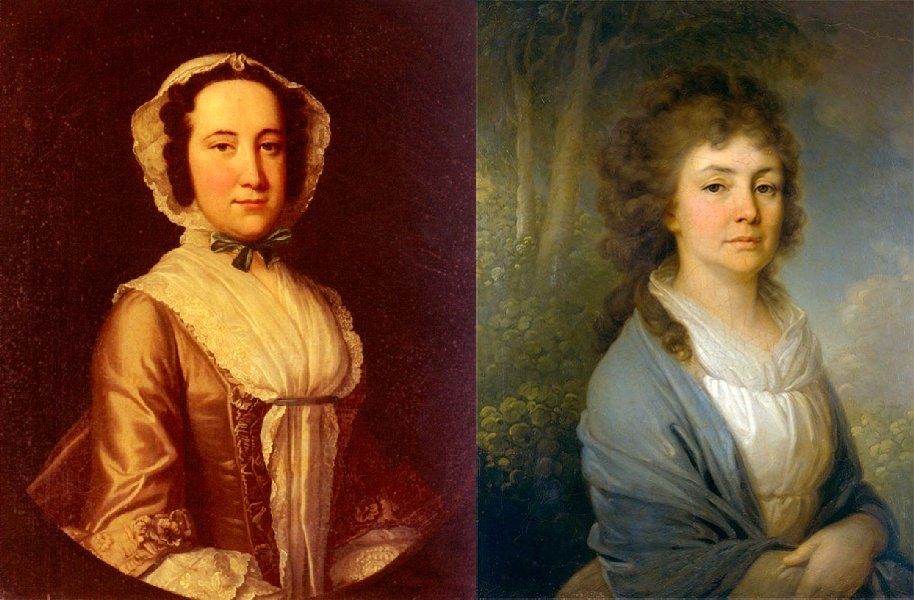 Satu dua
Satu dua .
Alih-alih sebuah kesimpulan
Secara umum, kami puas dengan hasil layanan.
Pada set tes, akurasi identifikasi lebih dari 80% tercapai. Dalam praktiknya, sering kali ternyata bahwa jika gambar tidak ditemukan pertama kali, maka cukup untuk memotretnya dari sudut yang berbeda, dan letaknya. Kesalahan ketika gambar yang salah ditemukan, hampir tidak pernah terjadi.
Secara keseluruhan, solusinya dibungkus dalam wadah buruh pelabuhan dan diberikan kepada pelanggan. Sekarang identifikasi lukisan dengan foto tersedia dalam aplikasi menggunakan layanan Arthive, misalnya, Pushkin Museum, tersedia di Play Market (namun, lukisan itu terlepas dari latar belakang, membutuhkan latar belakang cahaya, yang terkadang membuat fotografi sulit).