
Saat-saat ketika salah satu tugas paling mendesak dari visi komputer adalah kemampuan untuk membedakan foto-foto anjing dari foto-foto kucing, sudah ada di masa lalu. Saat ini, jaringan saraf dapat melakukan tugas yang jauh lebih kompleks dan menarik untuk pemrosesan gambar. Secara khusus, jaringan dengan arsitektur Mask R-CNN memungkinkan Anda untuk memilih kontur ("topeng") dari berbagai objek dalam foto, bahkan jika ada beberapa objek seperti itu, mereka memiliki ukuran yang berbeda dan sebagian tumpang tindih. Jaringan ini juga mampu mengenali pose orang-orang dalam gambar.
Pada awal tahun ini, saya memiliki kesempatan untuk berpartisipasi dalam kompetisi Data Science Bowl 2018 di Kaggle untuk tujuan pendidikan. Untuk tujuan pendidikan, saya menggunakan salah satu model yang beberapa peserta menempati posisi tinggi dengan murah hati. Itu adalah jaringan saraf Masker R-CNN yang baru-baru ini dikembangkan oleh Facebook Research. (Perlu dicatat bahwa tim pemenang masih menggunakan arsitektur yang berbeda - U-Net. Rupanya, itu lebih cocok untuk tugas-tugas biomedis, yang termasuk Data Science Bowl 2018).
Karena tujuannya adalah untuk membiasakan diri dengan tugas-tugas Belajar Dalam, dan tidak menempati tempat yang tinggi, setelah akhir kompetisi ada keinginan yang kuat untuk memahami bagaimana jaringan saraf yang digunakan "di bawah tenda" bekerja. Artikel ini adalah kompilasi informasi yang diperoleh dari dokumen asli dari arXiv.org dan beberapa artikel di Medium. Materi ini murni teoretis (walaupun pada akhirnya ada tautan tentang penerapan praktis), dan tidak mengandung lebih dari yang ada di sumber yang ditunjukkan. Tetapi ada sedikit informasi tentang topik dalam bahasa Rusia, jadi mungkin artikel itu akan bermanfaat bagi seseorang.
Semua ilustrasi diambil dari sumber orang lain dan milik pemiliknya yang sah.
Jenis Tugas Visi Komputer
Biasanya, tugas modern penglihatan komputer dibagi menjadi empat jenis (tidak perlu memenuhi terjemahan nama mereka bahkan dalam sumber berbahasa Rusia, oleh karena itu dalam bahasa Inggris, agar tidak membuat kebingungan):
- Klasifikasi - klasifikasi gambar berdasarkan jenis objek yang dikandungnya;
- Segmentasi semantik - definisi semua piksel objek dari kelas atau latar belakang tertentu dalam gambar. Jika beberapa objek dari kelas yang sama tumpang tindih, pikselnya tidak dapat dipisahkan satu sama lain;
- Deteksi objek - deteksi semua objek dari kelas yang ditentukan dan penentuan kerangka kerja yang melampirkan masing-masing;
- Segmentasi Instance - definisi piksel yang dimiliki oleh setiap objek dari setiap kelas secara terpisah;
Menggunakan contoh gambar dengan balon dari
[9], ini dapat diilustrasikan sebagai berikut:
Perkembangan evolusi Masker R-CNN
Konsep yang mendasari Mask R-CNN mengalami pengembangan bertahap melalui arsitektur beberapa jaringan saraf menengah yang menyelesaikan tugas yang berbeda dari daftar di atas. Mungkin cara termudah untuk memahami prinsip-prinsip berfungsinya jaringan ini adalah dengan mempertimbangkan secara berurutan semua tahapan ini.
Tanpa memikirkan hal-hal dasar seperti backpropagation, fungsi aktivasi non-linear, dan apa yang dimaksud dengan jaringan saraf multilayer secara umum, penjelasan singkat tentang bagaimana lapisan Konvolusi Neural Networks bekerja mungkin masih sepadan (R-CNN).
Konvolusi dan MaxPooling
Lapisan convolutional memungkinkan Anda untuk menggabungkan nilai-nilai piksel yang berdekatan dan menyorot fitur gambar yang lebih umum. Untuk melakukan ini, gambar secara berurutan meluncur dengan jendela persegi ukuran kecil (3x3, 5x5, 7x7 piksel, dll.) Yang disebut kernel (kernel). Setiap elemen inti memiliki koefisien bobotnya sendiri dikalikan dengan nilai piksel gambar di mana elemen inti saat ini ditumpangkan. Kemudian angka-angka yang diperoleh untuk seluruh jendela ditambahkan, dan jumlah terbobot ini memberikan nilai dari tanda berikutnya.
Untuk mendapatkan matriks ("peta") atribut dari seluruh gambar, inti secara berurutan bergeser secara horizontal dan vertikal. Pada lapisan berikut, operasi konvolusi sudah diterapkan ke peta karakteristik yang diperoleh dari lapisan sebelumnya. Secara grafis, prosesnya dapat digambarkan sebagai berikut:
Gambar atau kartu fitur dalam satu lapisan dapat dipindai bukan oleh satu tetapi oleh beberapa filter independen, sehingga tidak memberikan satu kartu, tetapi beberapa (mereka juga disebut "saluran"). Menyesuaikan bobot setiap filter terjadi menggunakan prosedur backpropagation yang sama.
Jelas, jika inti filter selama pemindaian tidak melampaui gambar, dimensi peta fitur akan kurang dari gambar asli. Jika Anda ingin menjaga ukuran yang sama, terapkan apa yang disebut paddings - nilai yang melengkapi gambar di tepinya dan yang kemudian ditangkap oleh filter bersama dengan piksel nyata dari gambar.
Selain paddings, perubahan dimensi juga dipengaruhi oleh langkah - nilai dari langkah dimana jendela bergerak di sekitar gambar / peta.
Konvolusi bukan satu-satunya cara untuk mendapatkan karakteristik umum dari sekelompok piksel. Cara termudah untuk melakukan ini adalah memilih satu piksel sesuai dengan aturan yang diberikan, misalnya maksimum. Inilah yang dilakukan oleh layer MaxPooling.
Tidak seperti konvolusi, maxpooling biasanya diterapkan untuk memisahkan kelompok piksel.
R-CNN
Arsitektur jaringan R-CNN (Daerah Dengan CNN) dikembangkan oleh tim dari UC Berkley untuk menerapkan Convolution Neural Networks ke tugas deteksi objek. Pendekatan untuk memecahkan masalah yang ada pada saat itu mendekati kemampuan maksimal mereka dan kinerja mereka tidak meningkat secara signifikan.
CNN tampil baik dalam klasifikasi gambar, dan pada jaringan yang diberikan mereka pada dasarnya diterapkan untuk hal yang sama. Untuk melakukan ini, tidak seluruh gambar diumpankan ke input CNN, tetapi daerah yang sebelumnya dialokasikan dengan cara yang berbeda, di mana beberapa objek seharusnya. Pada waktu itu, ada beberapa pendekatan seperti itu, penulis memilih
Pencarian Selektif , meskipun mereka menunjukkan bahwa tidak ada alasan khusus untuk preferensi.
Arsitektur yang sudah jadi juga digunakan sebagai jaringan CNN -
CaffeNet (AlexNet). Jaringan saraf seperti itu, seperti yang lain untuk rangkaian gambar ImageNet, mengklasifikasikan ke dalam 1000 kelas. R-CNN dirancang untuk mendeteksi objek dari sejumlah kelas yang lebih kecil (N = 20 atau 200), sehingga lapisan klasifikasi terakhir CaffeNet digantikan oleh lapisan dengan keluaran N + 1 (dengan kelas tambahan untuk latar belakang).
Pencarian Selektif mengembalikan sekitar 2.000 wilayah dengan ukuran dan rasio aspek yang berbeda, tetapi CaffeNet menerima gambar dengan ukuran tetap 227x227 piksel sebagai input, jadi Anda harus memodifikasinya sebelum mengirimkan wilayah sebelum memasukkan wilayah ke input jaringan. Untuk ini, gambar dari wilayah itu terlampir di dalam spanning square terkecil. Di sepanjang sisi (lebih kecil) di mana bidang terbentuk, beberapa piksel "kontekstual" (mengelilingi wilayah) gambar ditambahkan, sisa bidang tidak diisi dengan apa pun. Kotak yang dihasilkan diskalakan ke ukuran 227x227 dan diumpankan ke input CaffeNet.

Terlepas dari kenyataan bahwa CNN dilatih untuk mengenali kelas N + 1, pada akhirnya itu hanya digunakan untuk mengekstraksi vektor fitur 4096-dimensi tetap. SVM linear N terlibat dalam penentuan langsung objek dalam gambar, yang masing-masing melakukan klasifikasi biner sesuai dengan jenis objeknya, menentukan apakah ada hal seperti itu di wilayah yang ditransfer atau tidak. Dalam dokumen asli, seluruh prosedur diilustrasikan oleh skema berikut:
Para penulis berpendapat bahwa proses klasifikasi dalam SVM sangat produktif, pada dasarnya hanya operasi matriks. Vektor fitur yang diperoleh dari CNN digabungkan di semua wilayah menjadi matriks 2000x4096, yang kemudian dikalikan dengan matriks 4096xN dengan bobot SVM.
Perlu dicatat bahwa wilayah yang diperoleh menggunakan Pencarian Selektif hanya
dapat berisi beberapa objek, dan bukan fakta bahwa mereka mengandungnya secara keseluruhan. Apakah atau tidak mempertimbangkan suatu wilayah yang mengandung suatu objek ditentukan oleh
metrik titik -
temu atas Union (IoU) . Metrik ini adalah rasio luas persimpangan dari daerah kandidat persegi panjang dengan persegi panjang yang benar-benar mencakup objek ke area persatuan persegi panjang ini. Jika rasio melebihi nilai ambang batas yang telah ditentukan, wilayah kandidat dianggap mengandung objek yang diinginkan.
IoU juga digunakan untuk menyaring sejumlah besar wilayah yang mengandung objek tertentu (penindasan non-maksimum). Jika IoU suatu wilayah dengan wilayah yang menerima hasil maksimum untuk objek yang sama berada di atas ambang batas, wilayah pertama dibuang begitu saja.
Selama prosedur analisis kesalahan, penulis juga mengembangkan metode yang memungkinkan untuk mengurangi kesalahan dalam memilih objek yang menyertakan bingkai - regresi kotak-terikat. Setelah mengklasifikasikan konten wilayah kandidat, empat parameter ditentukan menggunakan regresi linier berdasarkan atribut dari CNN - (dx, dy, dw, dh). Mereka menggambarkan berapa banyak bagian tengah bingkai wilayah harus digeser oleh x dan y, dan berapa banyak untuk mengubah lebar dan tingginya agar lebih akurat menutupi objek yang dikenali.
Dengan demikian, prosedur untuk mendeteksi objek oleh jaringan R-CNN dapat dibagi menjadi langkah-langkah berikut:
- Sorot daerah kandidat menggunakan Pencarian Selektif.
- Mengonversi suatu wilayah ke ukuran yang diterima oleh CNN CaffeNet.
- Memperoleh fitur vektor fitur CNN 4096-dimensi.
- Melakukan klasifikasi biner N dari setiap vektor fitur menggunakan N linear SVMs.
- Regresi linear parameter bingkai wilayah untuk cakupan objek yang lebih akurat
Para penulis mencatat bahwa arsitektur yang mereka kembangkan juga berkinerja baik dalam masalah segmentasi semantik.
Cepat r-cnn
Meskipun hasilnya bagus, kinerja R-CNN masih rendah, terutama untuk jaringan yang lebih dalam dari CaffeNet (seperti VGG16). Selain itu, pelatihan untuk kotak pembatas berlari dan SVM diperlukan untuk menyimpan sejumlah besar atribut ke disk, jadi itu mahal dalam hal ukuran penyimpanan.
Para penulis Fast R-CNN mengusulkan untuk mempercepat proses karena beberapa modifikasi:
- Untuk melewati CNN tidak masing-masing dari 2.000 kandidat daerah secara terpisah, tetapi seluruh gambar. Daerah yang diusulkan kemudian ditumpangkan pada peta fitur umum yang dihasilkan;
- Alih-alih pelatihan independen dari tiga model (CNN, SVM, bbox regressor) menggabungkan semua prosedur pelatihan menjadi satu.
Konversi tanda-tanda yang jatuh ke berbagai daerah ke ukuran tetap dilakukan menggunakan prosedur
RoIPooling . Jendela wilayah dengan lebar w dan tinggi h dibagi menjadi kisi-kisi yang memiliki sel H × W dengan ukuran h / H × w / W. (Penulis dokumen menggunakan W = H = 7). Untuk setiap sel tersebut, Max Pooling dilakukan untuk memilih hanya satu nilai, sehingga memberikan matriks fitur H × W yang dihasilkan.
SVM biner tidak digunakan, sebagai gantinya, fitur yang dipilih dipindahkan ke lapisan yang sepenuhnya terhubung, dan kemudian ke dua lapisan paralel: softmax dengan output K + 1 (satu untuk setiap kelas + 1 untuk latar belakang) dan kotak pembalikan yang mundur.
Arsitektur jaringan umum terlihat seperti ini:
Untuk pelatihan bersama classifier softmax dan regresi bbox, fungsi kerugian gabungan digunakan:
L(p,u,tu,v)=Lcls(p,u)+ lambda[u ge1]Lloc(tu,v)
Di sini:
u - kelas objek yang sebenarnya digambarkan di wilayah kandidat;
Lcls(p,u)=− log(pu) - Kehilangan log untuk kelas u;
v=(vx,vy,vw,vh) - perubahan nyata dalam kerangka wilayah untuk cakupan objek yang lebih akurat;
tu=(tux,tuy,tuw,tuh) - perubahan yang diperkirakan dalam kerangka wilayah;
Lloc - fungsi kerugian antara perubahan bingkai yang diprediksi dan yang nyata;
[u ge1] - fungsi indikator sama dengan 1 saat
u ge1 , dan 0 saat sebaliknya. Kelas
u=0 latar belakang ditunjukkan (mis. tidak adanya objek di wilayah).
lambda - Koefisien yang dirancang untuk menyeimbangkan kontribusi dari kedua fungsi yang hilang pada hasil keseluruhan. Namun, dalam semua percobaan penulis dokumen, sama dengan 1.
Para penulis juga menyebutkan bahwa mereka menggunakan dekomposisi SVD terpotong dari matriks bobot untuk mempercepat perhitungan dalam lapisan yang sepenuhnya terhubung.
Lebih cepat r-cnn
Setelah perbaikan yang dilakukan di Fast R-CNN, hambatan jaringan saraf ternyata menjadi mekanisme untuk menghasilkan daerah kandidat. Pada 2015, sebuah tim dari Microsoft Research mampu membuat langkah ini secara signifikan lebih cepat. Mereka menyarankan menghitung daerah bukan dari gambar asli, tetapi lagi dari peta fitur yang diperoleh dari CNN. Untuk ini, modul yang disebut Jaringan Proposal Wilayah (RPN) ditambahkan. Seluruh arsitektur adalah sebagai berikut:
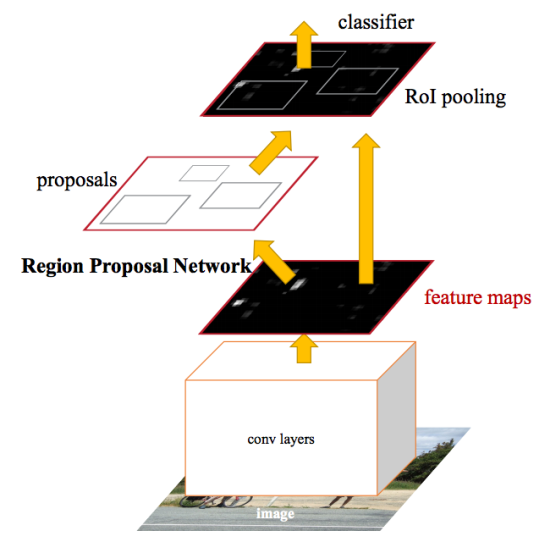
Dalam kerangka kerja RPN, menurut CNN diekstraksi, mereka meluncur ke "jaringan mini-saraf" dengan jendela kecil (3x3). Nilai-nilai yang diperoleh dengan bantuannya ditransfer ke dua lapisan paralel yang sepenuhnya terhubung: lapisan regresi kotak (reg) dan lapisan klasifikasi kotak (cls). Output dari lapisan-lapisan ini didasarkan pada apa yang disebut jangkar: k frame untuk setiap posisi jendela geser, yang memiliki ukuran dan rasio aspek yang berbeda. Reg-layer untuk setiap jangkar tersebut menghasilkan 4 koordinat, mengoreksi posisi bingkai penutup; Cls-layer menghasilkan dua angka masing-masing - probabilitas bahwa frame mengandung setidaknya beberapa objek atau tidak. Dalam dokumen, ini diilustrasikan oleh skema berikut:
Proses pembelajaran menggabungkan dan menggabungkan lapisan; mereka memiliki fungsi kerugian yang sama, yang merupakan jumlah dari fungsi kerugian masing-masing, dengan koefisien penyeimbang.
Kedua layer RPN hanya menyediakan penawaran untuk wilayah kandidat. Mereka yang sangat mungkin berisi objek diteruskan ke modul deteksi dan penyempurnaan objek, yang masih diimplementasikan sebagai Fast R-CNN.
Untuk berbagi fitur yang diperoleh di CNN antara RPN dan modul deteksi, proses pelatihan seluruh jaringan dibangun secara iteratif menggunakan beberapa langkah:
- Bagian RPN diinisialisasi dan dilatih untuk mengidentifikasi daerah kandidat.
- Menggunakan wilayah RPN yang diusulkan, bagian Fast R-CNN dilatih ulang.
- Jaringan deteksi terlatih digunakan untuk menginisialisasi bobot untuk RPN. Lapisan konvolusi umum, bagaimanapun, adalah tetap dan hanya lapisan spesifik untuk RPN yang dikembalikan.
- Dengan lapisan konvolusi tetap, Fast R-CNN akhirnya disetel.
Skema yang diusulkan bukan satu-satunya, dan bahkan dalam bentuk saat ini dapat dilanjutkan dengan langkah-langkah berulang selanjutnya, tetapi penulis studi asli melakukan eksperimen tepat setelah pelatihan tersebut.
Topeng r-cnn
Mask R-CNN mengembangkan arsitektur R-CNN yang lebih cepat dengan menambahkan cabang lain yang memprediksi posisi topeng yang menutupi objek yang ditemukan, dan dengan demikian memecahkan masalah segmentasi instance. Topeng hanyalah matriks persegi panjang, di mana 1 pada beberapa posisi berarti bahwa pixel yang sesuai milik objek kelas tertentu, 0 - bahwa pixel bukan milik objek.

Visualisasi topeng multi-warna pada gambar sumber dapat memberikan gambar berwarna:

Para penulis dokumen secara kondisional membagi arsitektur yang dikembangkan menjadi jaringan CNN untuk menghitung fitur gambar, yang disebut tulang punggung, dan kepala - penyatuan bagian-bagian yang bertanggung jawab untuk memprediksi bingkai pembungkus, mengklasifikasikan objek dan menentukan topengnya. Fungsi kerugian umum untuk mereka dan mencakup tiga komponen:
L=Lcls+Lbox+Lmask
Ekstraksi topeng terjadi dalam gaya kelas-agnostik: topeng diprediksi secara terpisah untuk setiap kelas, tanpa pengetahuan sebelumnya tentang apa yang digambarkan di wilayah tersebut, dan kemudian topeng kelas yang memenangkan pengelompokan independen hanya dipilih. Dikatakan bahwa pendekatan semacam itu lebih efektif daripada mengandalkan pengetahuan apriori di kelas.
Salah satu modifikasi utama yang timbul dari kebutuhan untuk memprediksi topeng adalah perubahan dalam prosedur
RoIPool (yang menghitung matriks fitur untuk wilayah kandidat) ke apa yang disebut
RoIAlign . Faktanya adalah bahwa peta fitur yang diperoleh dari CNN memiliki ukuran lebih kecil dari gambar asli, dan wilayah yang mencakup jumlah bilangan bulat piksel dalam gambar tidak dapat ditampilkan di wilayah proporsional peta dengan jumlah fitur bilangan bulat:
Di RoIPool, masalahnya diselesaikan hanya dengan membulatkan nilai fraksional menjadi bilangan bulat. Pendekatan ini berfungsi dengan baik ketika memilih bingkai penutup, tetapi topeng yang dihitung berdasarkan data tersebut terlalu tidak akurat.
Sebaliknya, RoIAlign tidak menggunakan pembulatan, semua angka tetap valid, dan interpolasi bilinear selama empat titik integer terdekat digunakan untuk menghitung nilai atribut.
Dalam dokumen asli, perbedaannya dijelaskan sebagai berikut:
Di sini, peta yang ditetaskan menunjukkan peta fitur, dan kontinu - tampilan pada peta fitur wilayah kandidat dari foto aslinya. Seharusnya ada 4 grup di wilayah ini untuk max pooling dengan 4 atribut yang ditunjukkan oleh titik-titik pada gambar. Berbeda dengan prosedur RoIPool, yang karena pembulatan hanya akan menyelaraskan wilayah dengan koordinat bilangan bulat, RoIAlign meninggalkan titik di tempat mereka saat ini, tetapi menghitung nilai masing-masing menggunakan interpolasi bilinear sesuai dengan empat tanda terdekat.
Interpolasi bilinearInterpolasi bilinear dari fungsi dua variabel dilakukan dengan menerapkan interpolasi linier, pertama ke arah salah satu koordinat, kemudian di yang lain.
Biarkan perlu untuk menginterpolasi nilai fungsi
f(x,y) pada titik P dengan nilai fungsi yang diketahui pada titik-titik sekitarnya
Q11=(x1,y1),Q12=(x1,y2),Q21=(x2,y1),Q22=(x2,y2) (lihat gambar di bawah). Untuk melakukan ini, pertama nilai titik bantu R1 dan R2 diinterpolasi, dan kemudian nilai pada titik P diinterpolasi berdasarkan mereka.
R1=(x,y1)
R2=(x,y2)
f(R1)≈ frac(x2−x)(x2−x1)f(Q11)+ frac(x−x1)(x2−x1)f(Q21)
f(R2)≈ frac(x2−x)(x2−x1)f(Q12)+ frac(x−x1)(x2−x1)f(Q22)
f(P)≈(y2−y)(y2−y1)f(R1)+(y−y1)(y2−y1)f(R2)
( — ,
)
instance segmentation object detection, Mask R-CNN (human pose estimation). — (keypoints), , , .., :

, , ( ) 1, — 0 (one-hot mask). , K , .
Feature Pyramid Networks
Mask R-CNN, CNN ResNet-50/101 backbone, Feature Pyramid Network (FPN). , FPN backbone Mask R-CNN , . , , .
Feature Pyramids, image pyramids, — .
Dalam Feature Pyramid Network, fitur peta yang diekstraksi oleh lapisan CNN berturut-turut dengan dimensi yang menurun dianggap sebagai semacam "piramida" hierarkis yang disebut jalur bottom-up. Selain itu, peta tanda-tanda baik tingkat bawah maupun atas piramida memiliki kelebihan dan kekurangannya: yang pertama memiliki resolusi tinggi, tetapi semantic rendah, kemampuan generalisasi; yang kedua - sebaliknya:Arsitektur FPN memungkinkan Anda untuk menggabungkan keunggulan lapisan atas dan bawah dengan menambahkan jalur top-down dan koneksi lateral. Untuk ini, peta setiap lapisan atasnya diperbesar dengan ukuran yang mendasarinya dan isinya ditambahkan elemen demi elemen. Dalam prediksi akhir, kartu yang dihasilkan dari semua level digunakan.Secara skematis, ini dapat direpresentasikan sebagai berikut:Meningkatkan ukuran peta tingkat atas (upsampling) dilakukan dengan metode paling sederhana - tetangga terdekat, yaitu kira-kira seperti ini:Tautan yang bermanfaat
arXiv.org:
1. R-CNN:
https://arxiv.org/abs/1311.25242. Fast R-CNN:
https://arxiv.org/abs/1504.080833. Faster R-CNN:
https://arxiv.org/abs/1506.014974. Mask R-CNN:
https://arxiv.org/abs/1703.068705. Feature Pyramid Network:
https://arxiv.org/abs/1612.03144medium.com Mask R-CNN , . , :
6.
Simple Understanding of Mask RCNN — .
7.
A Brief History of CNNs in Image Segmentation: From R-CNN to Mask R-CNN- Sejarah perkembangan jaringan dalam urutan kronologis yang sama seperti pada artikel ini.8. Dari R-CNN ke Mask R-CNN adalah pertimbangan lain dari tahapan pengembangan.9.
Splash of Color: Instance Segmentation with Mask R-CNN and TensorFlow — Opensource- Matterport.
Mask R-CNN : - .
, , Data Science Bowl 2018 kaggle ( , ; Kernels Discussions ):
10.
Mask R-CNN in PyTorch by Heng CherKeng . , . PyTorch 0.4.0, GPU-, NVIDIA CUDA. ,
Deep Learning AMI Amazon ( , , , , — p2.xlarge).
, , Matterport (, ). , :
11.
ConvNets. Mask R-CNN