Dalam film Mission Impossible 3, proses pembuatan topeng mata-mata terkenal ditampilkan, berkat beberapa karakter yang tidak dapat dibedakan dari yang lain. Menurut plot, pada awalnya itu diperlukan untuk memotret orang yang ingin menjadi pahlawan dari beberapa sudut. Pada tahun 2018, model wajah 3D yang sederhana bahkan mungkin tidak dicetak, tetapi setidaknya dibuat dalam bentuk digital - dan didasarkan hanya pada satu foto. Seorang peneliti VisionLabs menjelaskan secara terperinci proses di acara Yandex "
Dunia melalui mata robot " dari seri Data & Sains, dengan perincian tentang metode dan formula spesifik.
- Selamat sore. Nama saya Nikolai, saya bekerja untuk VisionLabs, sebuah perusahaan visi komputer. Profil utama kami adalah pengenalan wajah, tetapi kami juga memiliki teknologi yang dapat diterapkan dalam augmented reality dan virtual. Secara khusus, kami memiliki teknologi untuk membangun wajah 3D dari satu foto, dan hari ini saya akan membicarakannya.

Mari kita mulai dengan cerita tentang apa itu. Pada slide Anda melihat foto asli Jack Ma dan model 3D yang dibangun dari foto ini dalam dua variasi: dengan dan tanpa tekstur, hanya geometri. Ini adalah tugas yang sedang kami selesaikan.

Kami juga ingin dapat menghidupkan model ini, mengubah arah pandangan kami, ekspresi wajah, menambahkan ekspresi wajah, dll.
Aplikasi ini berada di area yang berbeda. Yang paling jelas adalah game, termasuk VR. Anda juga dapat melakukan ruang pas virtual - coba kacamata, jenggot dan gaya rambut. Anda dapat melakukan pencetakan 3D, karena beberapa orang tertarik pada aksesori yang dipersonalisasi untuk wajah mereka. Dan Anda dapat membuat wajah untuk robot: cetak dan tampilkan pada beberapa tampilan pada robot.

Saya akan mulai dengan memberi tahu Anda cara membuat wajah 3D secara umum, dan kemudian kita akan beralih ke tugas rekonstruksi 3D sebagai tugas membuat generasi terbalik. Setelah itu, kami akan fokus pada animasi dan beralih ke tantangan yang muncul di area ini.

Apa tugas menghasilkan wajah? Kami ingin memiliki beberapa cara untuk menghasilkan wajah tiga dimensi yang berbeda dalam bentuk dan ekspresi. Berikut adalah dua baris dengan contoh. Baris pertama menunjukkan wajah dengan bentuk yang berbeda, milik seolah-olah orang yang berbeda. Dan di bawah ini adalah wajah yang sama dengan ekspresi berbeda.

Salah satu cara untuk menyelesaikan masalah pembangkitan adalah model yang dapat dideformasi. Wajah paling kiri pada slide adalah jenis model rata-rata yang kita dapat menerapkan deformasi dengan menyesuaikan slider. Inilah tiga slider. Di baris atas ada wajah ke arah peningkatan intensitas slider, di baris bawah - ke arah penurunan. Dengan demikian, kita akan memiliki beberapa parameter yang dapat disesuaikan. Dengan menginstalnya, Anda dapat memberi orang bentuk yang berbeda.

Contoh dari model yang dapat dideformasi adalah Basel Face Model yang terkenal, dibangun dari pemindaian wajah. Untuk membuat model yang cacat, pertama-tama Anda perlu membawa beberapa orang, membawanya ke laboratorium khusus dan memotret wajah mereka dengan peralatan khusus, menerjemahkannya menjadi 3D. Kemudian, berdasarkan ini, Anda dapat membuat wajah baru.

Bagaimana cara mengaturnya secara matematis? Kita dapat membayangkan model wajah tiga dimensi sebagai vektor dalam ruang 3n dimensi. Di sini n adalah jumlah simpul dalam model, masing-masing simpul sesuai dengan tiga koordinat dalam 3D, dan dengan demikian kita mendapatkan koordinat 3n.

Jika kita memiliki satu set pemindaian, maka setiap pemindaian diwakili oleh vektor seperti itu, dan kita memiliki satu set n vektor seperti itu.
Selanjutnya, kita dapat membangun wajah baru sebagai kombinasi linear dari vektor dari basis data kita. Pada saat yang sama, kami ingin koefisien menjadi bermakna. Jelas, mereka tidak bisa sepenuhnya sewenang-wenang, dan saya akan segera menunjukkan alasannya. Salah satu batasan dapat diatur sehingga semua koefisien berada dalam kisaran dari 0 hingga 1. Ini harus dilakukan, karena jika koefisien sepenuhnya arbitrer, maka wajah akan berubah menjadi tidak masuk akal.

Di sini saya ingin memberikan parameter beberapa arti probabilistik. Artinya, kami ingin melihat serangkaian parameter dan memahami apakah seseorang akan berubah atau tidak. Dengan ini kami ingin distorsi rendah sesuai dengan wajah yang terdistorsi.

Begini cara melakukannya. Kita dapat menerapkan metode komponen utama ke satu set pemindaian. Pada output, kita mendapatkan rata-rata wajah S0, mendapatkan matriks V, satu set komponen utama, dan juga mendapatkan variasi data sepanjang komponen utama. Kemudian kita bisa melihat segar pada generasi wajah, kita akan mewakili wajah-wajah sebagai beberapa wajah rata-rata, ditambah matriks komponen utama, dikalikan dengan vektor parameter.
Nilai parameter adalah intensitas slider yang saya bicarakan di salah satu slide sebelumnya. Dan juga kita dapat menetapkan beberapa nilai probabilistik ke vektor parameter. Secara khusus, kami dapat setuju bahwa vektor ini adalah Gaussian.

Dengan demikian, kami mendapatkan metode yang memungkinkan Anda untuk menghasilkan wajah 3D, dan generasi ini dikendalikan oleh parameter berikut. Seperti pada slide sebelumnya, kami memiliki dua set parameter, dua vektor α id dan α exp, mereka sama seperti pada slide sebelumnya, tetapi α id bertanggung jawab atas bentuk wajah, dan α exp akan bertanggung jawab untuk emosi.
T vektor baru juga muncul - vektor tekstur. Ini memiliki dimensi yang sama dengan vektor bentuk, dan setiap simpul dalam vektor ini memiliki tiga nilai RGB. Demikian pula, vektor tekstur dihasilkan menggunakan vektor parameter β. Di sini parameter tidak diformalkan yang akan bertanggung jawab untuk pencahayaan wajah dan posisinya, tetapi mereka juga ada.

Berikut adalah contoh wajah yang dapat dihasilkan menggunakan model cacat. Harap dicatat bahwa mereka berbeda dalam bentuk, warna kulit, dan juga digambar dalam kondisi pencahayaan yang berbeda.
Sekarang kita dapat beralih ke rekonstruksi 3D. Ini disebut masalah terbalik, karena kami ingin memilih parameter seperti itu untuk model yang dapat dideformasi sehingga wajah yang kita gambar darinya akan sebanyak mungkin mirip dengan aslinya. Slide ini berbeda dari yang pertama di sini, di sebelah kanan, wajah sepenuhnya sintetis. Jika pada slide pertama tekstur kita diambil dari foto, maka di sini tekstur diambil dari model yang dapat dideformasi.
Pada output, kita akan memiliki semua parameter, pada slide α id dan α exp disajikan, dan kita juga akan memiliki pencahayaan, parameter tekstur, dll.

Kami mengatakan bahwa kami ingin memastikan bahwa model yang dihasilkan terlihat seperti foto. Kesamaan ini ditentukan dengan menggunakan fungsi energi. Di sini kita hanya mengambil perbedaan piksel-demi-piksel dari gambar dalam piksel tersebut di mana kami pikir wajahnya terlihat. Misalnya, jika wajah diputar, maka tumpang tindih akan terjadi. Misalnya, bagian tulang pipi akan tertutup hidung. Dan matriks visibilitas M harus menampilkan tumpang tindih seperti itu.
Intinya, rekonstruksi 3D adalah untuk meminimalkan fungsi energi ini. Tetapi untuk mengatasi masalah minimisasi ini, alangkah baiknya memiliki inisialisasi dan regularisasi. Regularisasi diperlukan untuk alasan yang jelas, seperti yang kami katakan bahwa jika kami tidak mengatur parameter dan membuatnya benar-benar sewenang-wenang, kami bisa mendapatkan wajah yang terdistorsi. Inisialisasi diperlukan karena tugas secara keseluruhan kompleks, memiliki minimum lokal, dan Anda tidak ingin berurusan dengan mereka.

Bagaimana inisialisasi dapat dilakukan? Untuk ini, Anda dapat menggunakan 68 poin kunci wajah. Sejak 2013-2014, banyak algoritma telah muncul yang memungkinkan 68 poin terdeteksi dengan akurasi yang cukup baik, dan sekarang mereka mendekati saturasi keakuratannya. Karena itu, kami memiliki cara untuk mendeteksi 68 titik wajah dengan andal.
Kita dapat menambahkan istilah baru pada fungsi energi kita, yang akan mengatakan bahwa kita ingin proyeksi 68 poin model yang sama bertepatan dengan titik-titik kunci wajah. Kami menandai titik-titik ini pada model, lalu kami entah bagaimana mengubah bentuk model, memelintirnya, memproyeksikan poin, dan memastikan bahwa posisi titik-titik tersebut bertepatan. Di foto kiri ada titik-titik dua warna, ungu dan kuning. Beberapa titik terdeteksi oleh algoritma, sementara yang lain diproyeksikan dari model. Menandai titik pada model di sebelah kanan, tetapi untuk titik di sepanjang tepi wajah, tidak ada satu titik yang ditandai, tetapi seluruh garis. Ini dilakukan karena ketika wajah diputar, tanda titik-titik ini harus berubah, dan titik dipilih dengan garis.

Berikut adalah istilah yang saya bicarakan, itu adalah perbedaan koordinat-bijaksana dari dua vektor yang menggambarkan poin-poin kunci dari wajah dan poin-poin utama yang diproyeksikan dari model.

Mari kita kembali ke regularisasi dan mempertimbangkan seluruh masalah dari perspektif kesimpulan Bayesian. Probabilitas bahwa vektor α sama dengan sesuatu yang diberikan dalam gambar yang diketahui sebanding dengan produk dari probabilitas mengamati gambar untuk α yang diberikan, dikalikan dengan probabilitas α. Jika kita mengambil logaritma negatif dari ungkapan ini, yang harus kita kurangi, kita akan melihat bahwa istilah yang bertanggung jawab untuk regularisasi akan memiliki bentuk khusus di sini. Secara khusus, ini adalah istilah kedua. Mengingat bahwa kita sebelumnya membuat asumsi bahwa vektor α adalah Gaussian, kita melihat bahwa istilah yang bertanggung jawab untuk regularisasi adalah jumlah kuadrat dari parameter yang direduksi menjadi variasi di sepanjang komponen utama.

Jadi, kita bisa menuliskan fungsi energi penuh, yang berisi tiga istilah. Istilah pertama bertanggung jawab untuk tekstur, untuk perbedaan piksel antara gambar yang dihasilkan dan gambar target. Istilah kedua bertanggung jawab untuk poin-poin utama, dan yang ketiga bertanggung jawab untuk regularisasi.
Koefisien persyaratan dalam proses minimalisasi tidak dioptimalkan, mereka hanya ditetapkan.
Di sini, fungsi energi direpresentasikan sebagai fungsi dari semua parameter. α parameter bentuk wajah id, parameter ekspresi ekspresi, parameter tekstur β, parameter lain yang kita bicarakan tetapi tidak diformalkan, ini adalah parameter posisi dan pencahayaan.
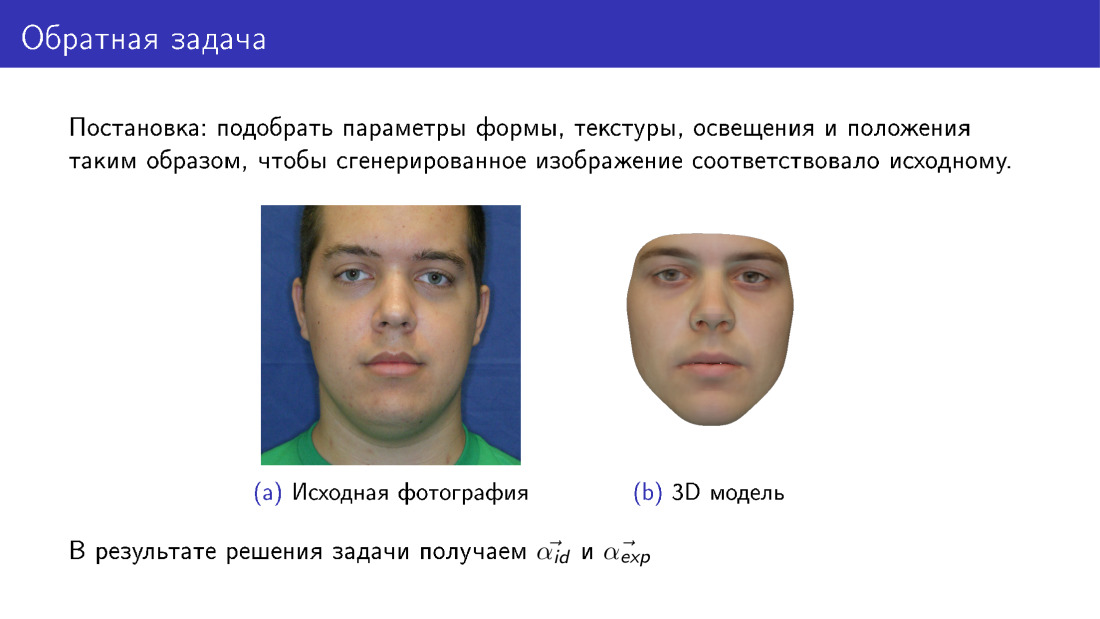
Marilah kita memikirkan komentar ini. Fungsi energi ini dapat disederhanakan. Dari situ, Anda dapat membuang istilah yang bertanggung jawab untuk tekstur, dan hanya menggunakan informasi yang dikirim oleh 68 poin. Dan ini akan memungkinkan Anda untuk membangun semacam model 3D. Namun, perhatikan profil model. Di sebelah kiri adalah model yang dibangun hanya pada titik-titik kunci. Di sebelah kanan adalah model yang menggunakan tekstur saat membangun. Perhatikan bahwa profil di sebelah kanan lebih konsisten dengan foto pusat, yang mewakili tampilan depan wajah.

Animasi dengan algoritma yang ada untuk membangun model wajah 3D bekerja cukup sederhana. Ingatlah bahwa ketika membangun model 3D, kita mendapatkan dua vektor parameter, satu bertanggung jawab untuk bentuk, yang lain untuk ekspresi. Vektor parameter ini untuk pengguna dan avatar akan selalu memiliki sendiri. Pengguna memiliki satu vektor parameter formulir, avatar memiliki yang berbeda. Namun, kita dapat membuat vektor yang bertanggung jawab atas ekspresi menjadi sama untuk mereka. Kami akan mengambil parameter yang bertanggung jawab untuk ekspresi wajah pengguna, dan cukup menggantinya ke dalam model avatar. Dengan demikian kami akan mentransfer ekspresi wajah pengguna ke avatar.
Mari kita bicara tentang dua tantangan di bidang ini: kecepatan kerja dan model cacat yang terbatas.

Kecepatan benar-benar masalah. Meminimalkan fungsi energi total adalah tugas yang sangat intensif secara komputasi. Secara khusus, dapat berlangsung dari 20 hingga 40, rata-rata 30 detik. Ini sudah cukup lama. Jika kita membangun model tiga dimensi hanya pada titik-titik kunci, itu akan menjadi jauh lebih cepat, tetapi kualitas akan menderita karenanya.

Bagaimana cara mengatasi masalah ini? Anda dapat menggunakan lebih banyak sumber daya, beberapa orang menyelesaikan masalah ini pada GPU. Hanya poin-poin kunci yang dapat digunakan, tetapi kualitas akan menurun. Dan Anda dapat menggunakan metode pembelajaran mesin.

Mari kita lihat secara berurutan. Ini adalah karya tahun 2016, di mana ekspresi wajah pengguna ditransfer ke video tertentu, Anda dapat mengontrol video menggunakan wajah Anda. Di sini, konstruksi model 3D dilakukan secara real time menggunakan GPU.

Berikut adalah metode yang menggunakan pembelajaran mesin. Idenya adalah kita pertama-tama dapat mengambil basis wajah yang besar, untuk setiap wajah menggunakan algoritma yang panjang namun akurat untuk membangun model 3D, menampilkan setiap model sebagai satu set parameter, dan kemudian melatih grid untuk memprediksi parameter ini. Secara khusus, dalam karya ini tahun 2016, ResNet digunakan, yang mengambil gambar ke input, dan memberikan parameter model ke output.

Model tiga dimensi dapat direpresentasikan dengan cara lain. Dalam karya 2017 ini, model 3D disajikan bukan sebagai satu set parameter, tetapi sebagai satu set voxel. Jaringan memprediksi voxel, mengubah gambar menjadi representasi tiga dimensi. Perlu dicatat bahwa opsi pelatihan jaringan dimungkinkan untuk mana model 3D tidak diperlukan sama sekali.

Ini berfungsi sebagai berikut. Di sini bagian yang paling penting adalah layer, yang dapat mengambil parameter model yang dapat dideformasi sebagai input dan membuat gambar. Ini memiliki properti yang luar biasa sehingga Anda dapat melakukan propagasi kesalahan kembali. Jaringan menerima gambar sebagai input, memprediksi parameter, mengumpankan parameter ini ke lapisan yang membuat gambar, membandingkan gambar ini dengan input, menerima kesalahan, menyebarkan kembali kesalahan dan terus belajar. Dengan demikian, jaringan belajar untuk memprediksi parameter model tiga dimensi, hanya memiliki gambar sebagai data pelatihan. Dan itu sangat menarik.

Kami berbicara banyak tentang akurasi - khususnya, bahwa itu menderita jika kita membuang beberapa istilah dari fungsi energi. Mari memformalkan apa artinya ini, bagaimana Anda dapat mengevaluasi akurasi rekonstruksi wajah 3D. Untuk melakukan ini, kita membutuhkan pindaian kebenaran kebenaran yang diperoleh dengan menggunakan peralatan khusus, menggunakan metode sehubungan dengan yang ada beberapa jaminan keakuratan. Jika pangkalan seperti itu ada, maka kita dapat membandingkan model yang direkonstruksi dengan kebenaran dasar. Ini dilakukan dengan sederhana: kami menghitung jarak rata-rata dari simpul model kami, yang kami bangun, ke simpul-simpul dalam kebenaran dasar, dan menormalkan kembali ukuran pemindaian. Ini harus dilakukan karena wajah berbeda, ada yang lebih besar, ada yang lebih kecil, dan kesalahan pada wajah kecil akan lebih kecil, hanya karena wajah itu sendiri lebih kecil. Oleh karena itu, diperlukan normalisasi.

Saya ingin berbicara tentang pekerjaan kami, itu akan ada di bengkel, ada ECCV. Kami melakukan hal serupa, kami mengajarkan MobileNet untuk memprediksi parameter model yang dapat dideformasi. Sebagai data pelatihan, kami menggunakan model 3D yang dibuat untuk foto-foto dari dataset 300W. Mengevaluasi akurasi berdasarkan pemindaian BU4DFE.
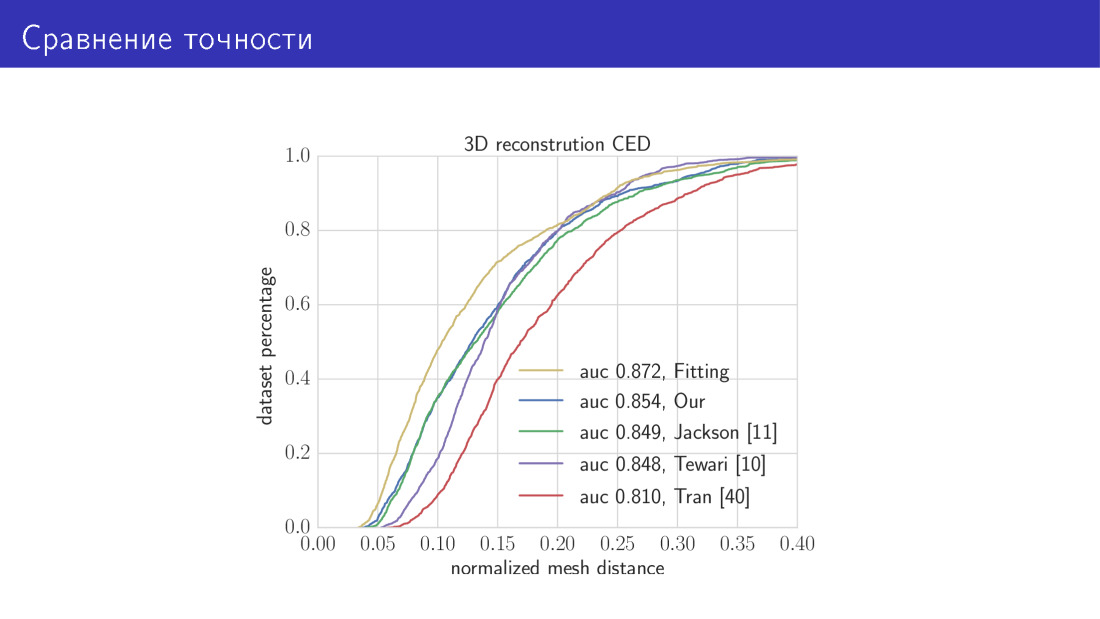
Inilah hasilnya. Kami membandingkan dua algoritma kami dengan yang paling canggih. Kurva kuning pada grafik ini adalah algoritma yang membutuhkan waktu 30 detik dan terdiri dari meminimalkan fungsi energi total. Di sini sepanjang sumbu X adalah kesalahan yang baru saja kita bicarakan, jarak rata-rata antara simpul. Sumbu Y adalah sebagian kecil dari gambar di mana kesalahan ini lebih kecil dari pada sumbu X. Dalam grafik ini, semakin tinggi kurva, semakin baik. Kurva berikutnya adalah jaringan berbasis MobileNet kami. Selanjutnya, tiga karya yang kami bicarakan. Parameter jaringan prediksi dan jaringan prediksi voxel.
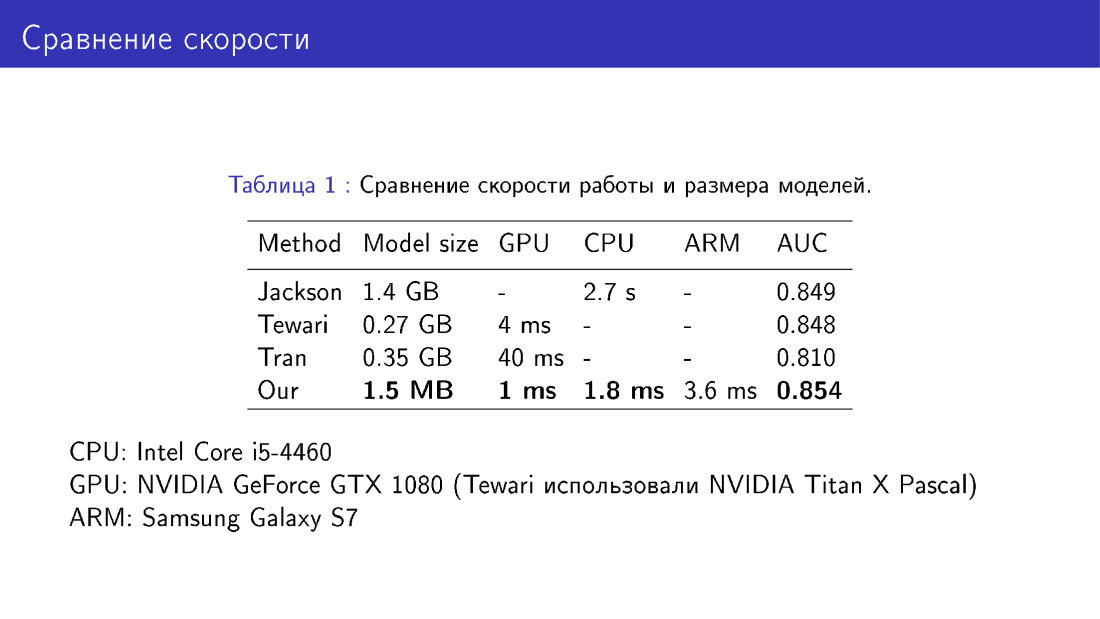
Kami juga membandingkan jaringan kami dengan rekan-rekan dalam hal ukuran dan kecepatan model. Ini adalah kemenangan karena kami menggunakan MobileNet, yang cukup mudah.
Tantangan kedua adalah keterbatasan model yang dapat dideformasi.

Perhatikan wajah kiri, lihat sayap hidung. Ada bayangan di sayap hidung. Batas-batas bayangan tidak sesuai dengan batas hidung pada foto, sehingga diperoleh cacat. Alasan untuk ini adalah bahwa model yang dapat dideformasi, pada prinsipnya, tidak dapat membangun hidung dari bentuk yang diperlukan, karena model yang dapat dideformasi ini diperoleh dari pemindaian hanya 200 wajah. Kami ingin hidungnya benar, seperti pada foto yang tepat. Dengan demikian, kita perlu entah bagaimana melampaui kerangka model yang dapat dideformasi.

Ini dapat dilakukan dengan menggunakan deformasi mesh nonparametrik. Berikut adalah tiga tugas yang ingin kami selesaikan: memodifikasi bagian lokal wajah, seperti hidung, lalu mengintegrasikannya ke dalam model asli wajah, dan meskipun begitu segala sesuatu yang lain tetap tidak berubah.

Ini bisa dilakukan sebagai berikut. Mari kita kembali ke penunjukan mesh sebagai vektor dalam ruang 3n-dimensi dan melihat operator rata-rata. Ini adalah operator yang di S dengan header menggantikan setiap titik dengan rata-rata tetangganya. Tetangga puncak adalah mereka yang terhubung ke tepi.
Kami akan mendefinisikan fungsi energi tertentu yang menggambarkan posisi simpul relatif terhadap tetangganya. Kami ingin posisi puncak relatif terhadap tetangganya tetap tidak berubah, atau setidaknya tidak banyak berubah. Tetapi pada saat yang sama, kita akan entah bagaimana memodifikasi S. Fungsi energi ini disebut internal, karena juga akan ada beberapa istilah eksternal, yang akan mengatakan bahwa, misalnya, hidung harus mengambil bentuk tertentu.
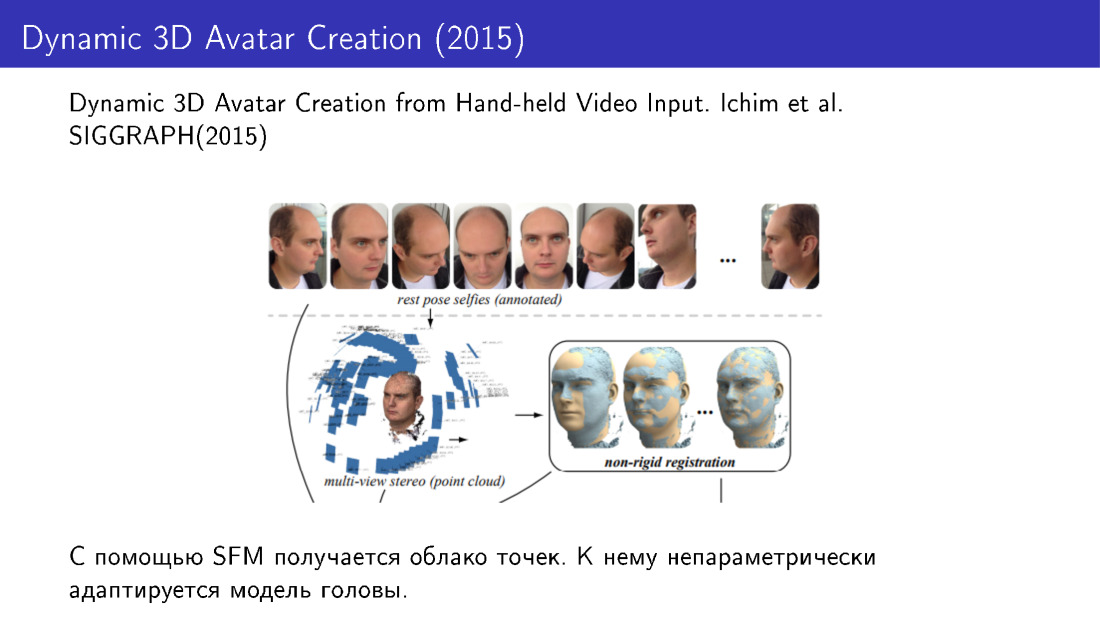
Teknik-teknik tersebut digunakan, misalnya, dalam karya 2015. Mereka melakukan rekonstruksi wajah 3D dari beberapa foto. Kami mengambil beberapa foto dari telepon, menerima point cloud, dan kemudian mengadaptasi model wajah ke cloud ini menggunakan modifikasi non-parametrik.
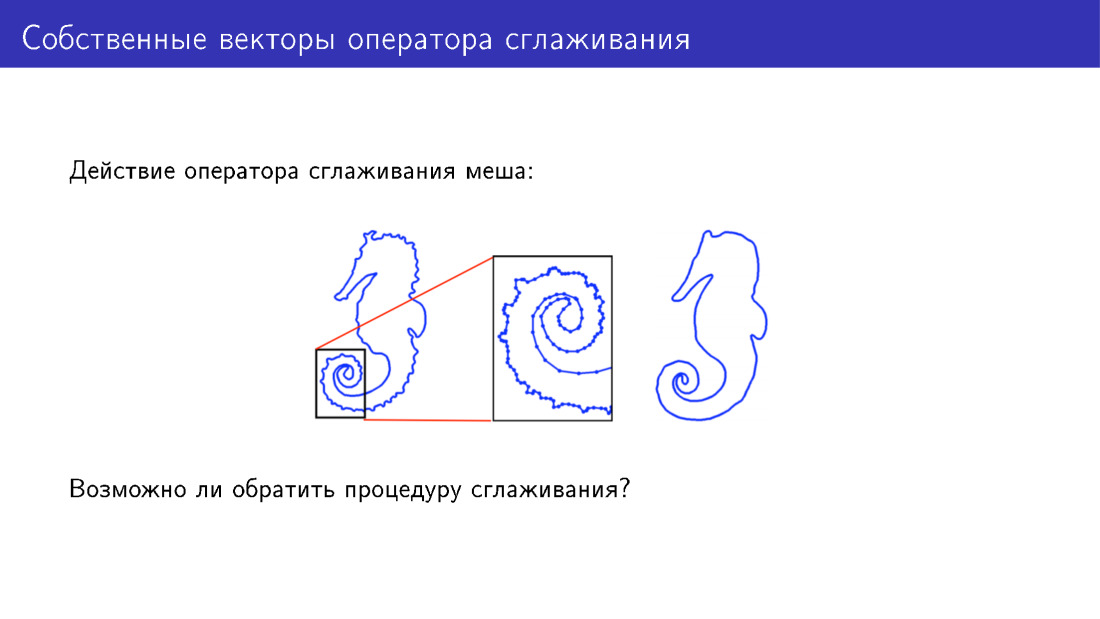
Anda dapat melampaui model terdeformasi dengan cara lain. Mari kita memikirkan tindakan operator smoothing. Di sini, untuk kesederhanaan, mesh dua dimensi disajikan dimana operator ini telah diterapkan. Ada banyak detail pada model di sebelah kiri, pada model di sebelah kanan, detail ini telah dihaluskan. Tetapi bisakah kita melakukan sesuatu untuk menambahkan detail daripada menghapusnya?

. .
? -: - . . , 2016 . , .