Sebelumnya kami
berbicara tentang superkomputer Jepang paling kuat untuk penelitian dalam fisika nuklir. Superkomputer Post-K exaflops sedang dibuat di Jepang - Jepang akan menjadi yang pertama meluncurkan mesin dengan kekuatan komputasi seperti itu.
Komisioning dijadwalkan untuk 2021.
Pekan lalu, Fujitsu berbicara tentang karakteristik teknis dari chip A64FX, yang akan membentuk dasar "mesin" baru. Kami akan memberi tahu Anda lebih banyak tentang chip dan kapabilitasnya.
 / foto Toshihiro Matsui CC / komputer superkomputer Jepang
/ foto Toshihiro Matsui CC / komputer superkomputer JepangSpesifikasi A64FX
Diharapkan bahwa kemampuan komputasi Post-K akan hampir sepuluh kali
lebih tinggi daripada kinerja yang paling kuat dari superkomputer
IBM Summit yang ada (
pada Juni 2018 ).
Superkomputer ini memiliki kinerja yang mirip dengan chip berbasis lengan A64FX. Chip ini
terdiri dari 48 core untuk operasi komputasi dan empat core untuk mengendalikannya. Semuanya dibagi secara merata menjadi empat grup - Core Memory Groups (CMG).
Setiap grup memiliki 8 MB cache L2. Terhubung ke pengontrol memori dan antarmuka NoC ("
jaringan pada chip "). NoC menghubungkan berbagai CMG dengan pengontrol PCIe dan Tofu. Yang terakhir bertanggung jawab untuk komunikasi antara prosesor dan seluruh sistem. Pengontrol Tofu memiliki sepuluh port dengan throughput 12,5 GB / s.
Tata letak chip adalah sebagai berikut:
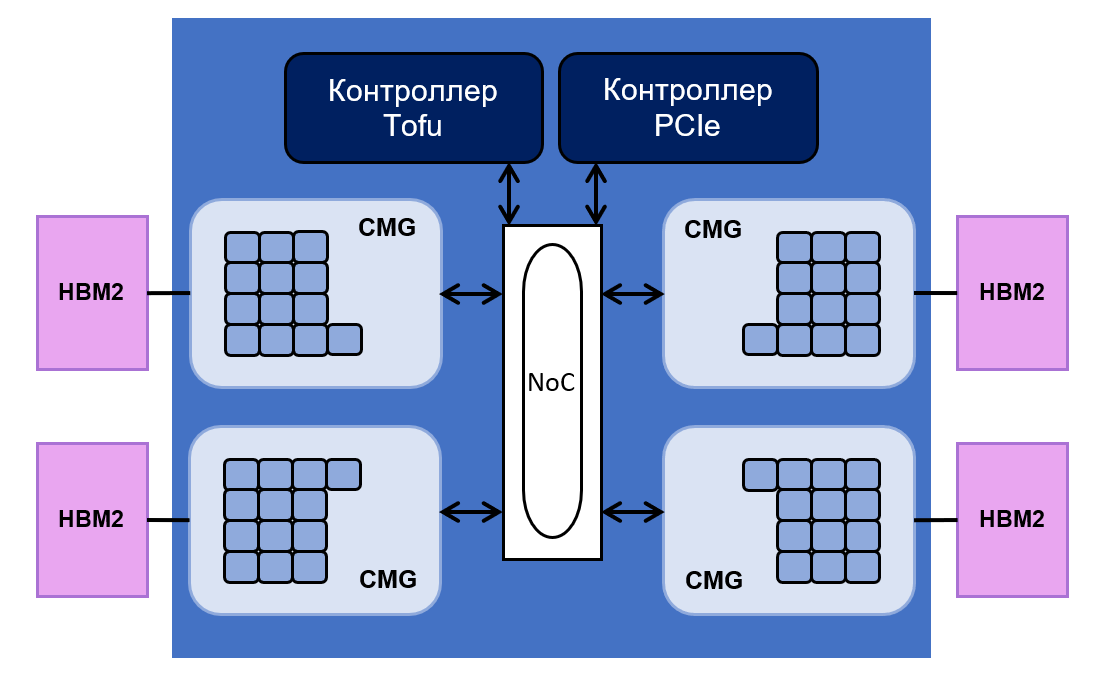
Total memori
HBM2 prosesor adalah 32 gigabyte, dan throughputnya sama dengan 1024 GB / s. Fujitsu mengatakan bahwa kinerja prosesor pada operasi floating point mencapai 2,7 teraflops untuk operasi 64-bit, 5,4 teraflops untuk 32-bit dan 10,8 teraflops untuk 16-bit.
Penciptaan Post-K dipantau oleh editor sumber daya Top500, yang menyusun daftar sistem komputasi yang paling kuat. Menurut mereka, untuk mencapai kinerja dalam satu exaflops, superkomputer menggunakan lebih dari 370 ribu prosesor A64FX.
Perangkat pertama akan menggunakan teknologi ekstensi vektor yang disebut Scalable Vector Extension (SVE). Ini berbeda dari
arsitektur SIMD lain karena tidak
membatasi panjang register vektor, tetapi menetapkan rentang yang valid untuknya. SVE mendukung vektor dengan panjang 128 hingga 2048 bit. Jadi setiap program dapat dijalankan pada prosesor lain yang mendukung SVE, tanpa perlu kompilasi ulang.
Menggunakan SVE (karena ini adalah fungsi SIMD), prosesor dapat secara bersamaan melakukan perhitungan dengan beberapa array data. Berikut ini adalah contoh dari salah satu instruksi ini untuk fungsi NEON, yang digunakan untuk komputasi vektor dalam arsitektur prosesor Arm lainnya:
vadd.i32 q1, q2, q3
Ia menambahkan empat bilangan bulat 32-bit dari register 128-bit q2 dengan angka yang sesuai dalam register 128-bit q3 dan menulis array yang dihasilkan ke q1. Setara dengan operasi ini di C terlihat seperti ini:
for(i = 0; i < 4; i++) a[i] = b[i] + c[i];
Selain itu, SVE mendukung auto-vektorisasi. Vektorizer otomatis menganalisis siklus dalam kode dan, jika mungkin, menggunakan register vektor untuk menjalankannya. Ini meningkatkan kinerja kode.
Misalnya, fungsi dalam C:
void vectorize_this(unsigned int *a, unsigned int *b, unsigned int *c) { unsigned int i; for(i = 0; i < SIZE; i++) { a[i] = b[i] + c[i]; } }
Ini akan dikompilasi sebagai berikut (untuk prosesor Arm 32-bit):
104cc: ldr.w r3, [r4, #4]! 104d0: ldr.w r1, [r2, #4]! 104d4: cmp r4, r5 104d6: add r3, r1 104d8: str.w r3, [r0, #4]! 104dc: bne.n 104cc <vectorize_this+0xc>
Jika Anda menggunakan auto-vektorisasi, maka akan terlihat seperti ini:
10780: vld1.64 {d18-d19}, [r5 :64] 10784: adds r6, #1 10786: cmp r6, r7 10788: add.w r5, r5, #16 1078c: vld1.32 {d16-d17}, [r4] 10790: vadd.i32 q8, q8, q9 10794: add.w r4, r4, #16 10798: vst1.32 {d16-d17}, [r3] 1079c: add.w r3, r3, #16 107a0: bcc.n 10780 <vectorize_this+0x70>
Di sini, register SIMD q8 dan q9 dimuat dengan data dari array yang ditunjukkan oleh r5 dan r4. Setelah itu, instruksi vadd menambahkan empat nilai integer 32-bit sekaligus. Ini meningkatkan jumlah kode, tetapi lebih banyak data diproses untuk setiap iterasi dari loop.
Siapa lagi yang menciptakan superkomputer exaflops
Superkomputer Exaflops tidak hanya dibuat di Jepang. Misalnya, pekerjaan juga sedang berlangsung di Cina dan Amerika Serikat.
Di Cina, buat Tianhe-3 (Tianhe-3). Prototipnya sudah
diuji di Pusat Supercomputing Nasional di Tianjin. Versi final dari komputer ini rencananya akan selesai pada tahun 2020.
 / foto O01326 CC / Tianhe-2 Supercomputer - pendahulu Tianhe-3
/ foto O01326 CC / Tianhe-2 Supercomputer - pendahulu Tianhe-3Di jantung Tianhe-3
adalah prosesor Phytium Cina. Perangkat ini berisi 64 core,
memiliki kinerja 512 gigaflops dan bandwidth memori 204,8 GB / s.
Prototipe yang berfungsi juga dibuat untuk mesin dari seri
Sunway . Ini sedang diuji di Pusat Superkomputer Nasional di Jinan. Menurut pengembang, sekitar 35 aplikasi saat ini beroperasi di komputer - ini adalah simulator biomedis, aplikasi untuk memproses data besar, dan program untuk mempelajari perubahan iklim. Diharapkan bahwa pekerjaan pada komputer akan selesai pada paruh pertama 2021.
Adapun Amerika Serikat, Amerika
berencana untuk membuat komputer exaflops mereka pada tahun 2021. Proyek ini bernama Aurora A21, dan
Laboratorium Nasional Argonne dari Departemen Energi AS , serta Intel dan Cray sedang mengerjakannya.
Tahun ini, para peneliti telah
memilih sepuluh proyek untuk Program Ilmu Pengetahuan Awal Aurora, yang pesertanya akan menjadi yang pertama menggunakan sistem kinerja tinggi yang baru. Diantaranya adalah program untuk membuat
peta neuron otak, mempelajari materi gelap dan mengembangkan simulator akselerator partikel.
Komputer Exaflops akan memungkinkan untuk membangun model yang kompleks untuk penelitian, sehingga banyak proyek ilmiah menunggu pembuatan mesin tersebut. Salah satu yang paling ambisius adalah Proyek Otak Manusia (HBP), yang tujuannya adalah untuk membuat model otak manusia yang lengkap dan mempelajari perhitungan neuromorfik. Menurut para ilmuwan dari HBP, penggunaan sistem exaflops baru dapat ditemukan sejak hari pertama keberadaannya.
Apa yang kami lakukan di IT-GRAD: • IaaS • PCI DSS hosting • Cloud -152
Konten dari Blog Perusahaan IaaS kami: