Musim semi ini, Kontes Retro OpenAI diadakan, yang didedikasikan untuk pembelajaran penguatan, pembelajaran meta, dan, tentu saja, Sonic. Tim kami mengambil tempat ke-4 dari 900+ tim. Bidang pelatihan dengan penguatan sedikit berbeda dari pembelajaran mesin standar, dan kontes ini berbeda dari kompetisi RL biasa. Saya meminta detail di bawah kucing.
TL; DR
Garis dasar yang benar tidak perlu trik tambahan ... secara praktis.
Intro dalam pelatihan penguatan
Reinforced learning adalah area yang menggabungkan teori kontrol optimal, teori permainan, psikologi dan neurobiologi. Dalam praktiknya, pembelajaran penguatan digunakan untuk menyelesaikan masalah pengambilan keputusan dan mencari strategi perilaku yang optimal, atau kebijakan yang terlalu rumit untuk pemrograman "langsung". Dalam hal ini, agen dilatih tentang sejarah interaksi dengan lingkungan. Lingkungan, pada gilirannya, mengevaluasi tindakan agen, memberinya hadiah (skalar) - semakin baik perilaku agen, semakin besar hadiahnya. Akibatnya, kebijakan terbaik dipelajari dari agen yang telah belajar untuk memaksimalkan total hadiah untuk seluruh waktu interaksi dengan lingkungan.
Sebagai contoh sederhana, Anda dapat memainkan BreakOut. Dalam permainan tua yang baik dari seri Atari ini, seseorang / agen perlu mengontrol platform horizontal yang lebih rendah, mengenai bola dan secara bertahap memecah semua blok atas dengannya. Semakin merobohkan - semakin besar hadiahnya. Oleh karena itu, apa yang dilihat seseorang / agen adalah gambar layar dan perlu untuk membuat keputusan ke arah mana untuk memindahkan platform yang lebih rendah.
Jika Anda tertarik dengan topik pelatihan penguatan, saya menyarankan Anda tentang kursus pengantar yang keren dari HSE , serta rekannya sumber terbuka yang lebih rinci. Jika Anda menginginkan sesuatu yang dapat Anda baca, tetapi dengan contoh - buku yang terinspirasi oleh dua kursus ini. Saya meninjau / menyelesaikan / membantu menciptakan semua kursus ini, dan karena itu saya tahu dari pengalaman saya sendiri bahwa mereka memberikan dasar yang sangat baik.
Tentang tugas
Tujuan utama dari kompetisi ini adalah untuk mendapatkan agen yang bisa bermain dengan baik di seri game SEGA - Sonic The Hedgehog. OpenAI baru saja mulai mengimpor game dari SEGA ke platformnya untuk melatih agen RL, dan dengan demikian memutuskan untuk mempromosikan momen ini sedikit. Bahkan artikel tersebut dirilis dengan perangkat segalanya dan penjelasan rinci tentang metode dasar.
Ketiga game Sonic didukung, masing-masing dengan 9 level, di mana, dengan menjentikkan air mata, Anda bahkan bisa bermain, mengingat masa kecil Anda (setelah membelinya di Steam terlebih dahulu).
Keadaan lingkungan (apa yang dilihat agen) adalah gambar dari simulator - gambar RGB, dan sebagai tindakan agen diminta untuk memilih tombol mana pada joystick virtual untuk menekan - lompat / kiri / kanan dan seterusnya. Agen tersebut menerima poin hadiah serta dalam game aslinya, mis. untuk mengumpulkan cincin, serta untuk kecepatan melewati level. Sebenarnya, kami memiliki sonik asli di depan kami, hanya saja perlu untuk melewatinya dengan bantuan agen kami.
Kompetisi diadakan dari 5 April hingga 5 Juni, yaitu hanya 2 bulan, yang tampaknya cukup kecil. Tim kami dapat berkumpul dan memasuki kompetisi hanya pada bulan Mei, yang membuat kami belajar banyak saat bepergian.
Baseline
Sebagai garis dasar, panduan pelatihan lengkap untuk pelatihan Pelangi (pendekatan DQN) dan PPO (pendekatan Gradien Kebijakan) di salah satu level yang memungkinkan di Sonic dan penyerahan agen yang dihasilkan diberikan.
Versi Rainbow didasarkan pada proyek anyrl yang sedikit diketahui, tetapi PPO menggunakan garis dasar lama yang bagus dari OpenAI dan bagi kami jauh lebih disukai.
Garis dasar yang diterbitkan berbeda dari pendekatan yang dijelaskan dalam artikel oleh kesederhanaan yang lebih besar dan set kecil "peretasan" untuk mempercepat pembelajaran. Dengan demikian, penyelenggara melemparkan ide dan menetapkan arah, tetapi keputusan tentang penggunaan dan implementasi ide-ide ini diserahkan kepada peserta dalam kompetisi.
Mengenai ide, saya ingin mengucapkan terima kasih kepada OpenAI atas keterbukaan, dan secara pribadi John Schulman atas saran, ide, dan saran yang dia ucapkan di awal kompetisi ini. Kami, seperti banyak peserta (dan bahkan pendatang baru di dunia RL), ini memungkinkan kami untuk lebih fokus pada tujuan utama kompetisi - pembelajaran meta dan peningkatan generalisasi agen, yang akan kita bicarakan sekarang.
Fitur evaluasi keputusan
Hal yang paling menarik dimulai pada saat mengevaluasi agen. Dalam kompetisi / benchmark RL tipikal, algoritma diuji dalam lingkungan yang sama di mana mereka dilatih, yang berkontribusi pada algoritma yang baik dalam mengingat dan memiliki banyak hiperparameter. Dalam kontes yang sama, pengujian algoritma dilakukan di tingkat Sonic baru (yang tidak pernah ditunjukkan kepada siapa pun), yang dikembangkan oleh tim OpenAI khusus untuk kontes ini. Ceri pada kue adalah fakta bahwa dalam proses pengujian, agen juga diberi hadiah selama berlalunya tingkat, yang memungkinkan untuk berlatih kembali secara langsung dalam proses pengujian. Namun, dalam hal ini perlu diingat bahwa pengujian terbatas baik dalam waktu - 24 jam dan kutu game - 1 juta. Pada saat yang sama, OpenAI sangat mendukung penciptaan agen yang dapat dengan cepat berlatih kembali ke level baru. Seperti yang telah disebutkan, mendapatkan dan mempelajari solusi semacam itu adalah tujuan utama OpenAI selama kompetisi ini.
Dalam lingkungan akademik, arah mempelajari kebijakan yang dapat dengan cepat beradaptasi dengan kondisi baru disebut meta learning, dan dalam beberapa tahun terakhir telah aktif dikembangkan.
Selain itu, berbeda dengan kompetisi kaggle yang biasa, di mana seluruh pengajuan datang untuk mengirim file jawaban Anda, dalam kompetisi ini (dan memang dalam kompetisi RL) tim diharuskan untuk membungkus solusi mereka dalam wadah buruh pelabuhan dengan API yang diberikan, kumpulkan dan kirimkan gambar buruh pelabuhan. Ini meningkatkan ambang untuk memasuki kompetisi, tetapi membuat proses pengambilan keputusan jauh lebih jujur - sumber daya dan waktu untuk gambar buruh pelabuhan terbatas, masing-masing, algoritma yang terlalu berat dan / atau lambat sama sekali tidak lolos seleksi. Tampaknya bagi saya bahwa pendekatan untuk mengevaluasi ini jauh lebih disukai, karena memungkinkan peneliti tanpa "cluster rumah DGX dan AWS" untuk bersaing setara dengan pecinta model 50.000 kaca. Harapan untuk melihat lebih banyak kompetisi seperti ini di masa depan.
Tim
Kolesnikov Sergey ( scitator )
Penggemar RL. Pada saat kompetisi, seorang siswa di Institut Fisika dan Teknologi Moskow, MIPT, menulis dan mempertahankan ijazah dari NIPS tahun lalu: Kompetisi Learning to Run (sebuah artikel yang juga harus ditulis).
Senior Data Scientist @ Dbrain - Kami membawa kontes siap produksi dengan buruh pelabuhan dan sumber daya terbatas ke dunia nyata.
Pavlov Mikhail ( fgvbrt )
Pengembang Riset Senior DiphakLab . Berulang kali berpartisipasi dan memenangkan hadiah dalam hackathons dan memperkuat kompetisi pelatihan.
Sergeev Ilya ( sergeevii123 )
Penggemar RL. Saya menekan salah satu hackathons RL Deephack dan semuanya dimulai. Data Scientist @ Avito.ru - visi komputer untuk berbagai proyek internal.
Sorokin Ivan ( 1ytic )
Terlibat dalam pengenalan ucapan di speechpro.ru .
Pendekatan dan Solusi
Setelah pengujian cepat terhadap baseline yang diusulkan, pilihan kami jatuh pada pendekatan OpenAI - PPO, sebagai opsi yang lebih terbentuk dan menarik untuk mengembangkan solusi kami. Selain itu, dilihat dari artikel mereka untuk kompetisi ini, agen PPO mengatasi tugas sedikit lebih baik. Dari artikel yang sama, perbaikan pertama yang kami gunakan dalam solusi kami lahir, tetapi hal pertama yang pertama:
Pelatihan PPO kolaboratif di semua tingkatan yang tersedia
Garis dasar yang ditata hanya dilatih di salah satu dari 27 level Sonic yang tersedia. Namun, dengan bantuan modifikasi kecil, dimungkinkan untuk memparalelkan pelatihan sekaligus ke 27 level. Karena keragaman yang lebih besar dalam pelatihan, agen yang dihasilkan memiliki generalisasi yang jauh lebih besar dan pemahaman yang lebih baik tentang perangkat dunia Sonic, dan karenanya mengatasi urutan besarnya lebih baik.
Pelatihan tambahan selama pengujian
Kembali ke ide utama kompetisi, meta learning, perlu untuk menemukan pendekatan yang akan memiliki generalisasi maksimum dan dapat dengan mudah beradaptasi dengan lingkungan baru. Dan untuk adaptasi, perlu untuk melatih kembali agen yang ada untuk lingkungan pengujian, yang, pada kenyataannya, dilakukan (pada setiap tingkat tes, agen mengambil 1 juta langkah, yang cukup untuk beradaptasi ke tingkat tertentu). Pada akhir setiap permainan uji, agen mengevaluasi penghargaan yang diterima dan mengoptimalkan kebijakannya menggunakan cerita yang baru saja diterima. Penting untuk dicatat di sini bahwa dengan pendekatan ini penting untuk tidak melupakan semua pengalaman Anda sebelumnya dan tidak menurunkan dalam kondisi tertentu, yang, pada dasarnya, adalah kepentingan utama pembelajaran meta, karena agen tersebut segera kehilangan semua kemampuan yang ada untuk menggeneralisasi.
Bonus eksplorasi
Masuk jauh ke dalam kondisi remunerasi untuk level, agen diberi hadiah untuk bergerak maju sepanjang koordinat x, masing-masing, dia bisa terjebak di beberapa level, ketika Anda pertama kali harus maju dan kemudian kembali. Diputuskan untuk membuat tambahan untuk hadiah untuk agen, yang disebut penjelajahan berdasarkan hitungan , ketika agen itu diberikan hadiah kecil jika dia dalam keadaan dia belum masuk. Dua jenis bonus eksplorasi diterapkan: berdasarkan gambar dan berdasarkan koordinat x agen. Hadiah berdasarkan gambar dihitung sebagai berikut: untuk setiap lokasi piksel dalam gambar, dihitung berapa kali setiap nilai terjadi untuk suatu episode, hadiah itu berbanding terbalik dengan produk di semua lokasi piksel berapa kali nilai di lokasi ini bertemu untuk suatu episode. Hadiah berdasarkan koordinat x dianggap dengan cara yang sama: untuk setiap koordinat x (dengan akurasi tertentu) dihitung berapa kali agen dalam koordinat ini untuk episode, hadiah berbanding terbalik dengan jumlah ini untuk koordinat x saat ini.
Percobaan mixup
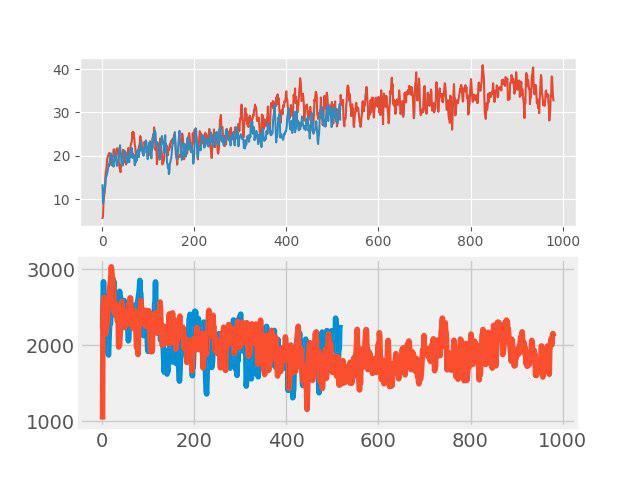
Dalam "mengajar dengan guru" baru-baru ini metode augmentasi data yang sederhana namun efektif, yang disebut mixup. Idenya sangat sederhana: penambahan dua gambar input sewenang-wenang dilakukan dan jumlah tertimbang dari label yang sesuai ditugaskan untuk gambar baru ini (misalnya, 0,7 anjing + 0,3 kucing). Dalam tugas-tugas seperti klasifikasi gambar dan pengenalan suara, mixup menunjukkan hasil yang baik. Oleh karena itu, menarik untuk menguji metode ini untuk RL. Augmentasi dilakukan di setiap kelompok besar, terdiri dari beberapa episode. Gambar input dicampur dalam piksel, tetapi dengan tag semuanya tidak begitu sederhana. Pengembalian nilai, nilai, dan neglogpac dicampur dengan jumlah tertimbang, tetapi tindakan (tindakan) dipilih dari contoh dengan koefisien maksimum. Solusi semacam itu tidak menunjukkan peningkatan nyata (meskipun, tampaknya, seharusnya ada peningkatan generalisasi), tetapi tidak memperburuk baseline. Grafik di bawah ini membandingkan algoritma PPO dengan mixup (merah) dan tanpa mixup (biru): di bagian atas adalah hadiah selama pelatihan, di bagian bawah adalah panjang episode.
Pemilihan kebijakan awal terbaik
Peningkatan ini adalah salah satu yang terakhir dan memberikan kontribusi yang sangat signifikan terhadap hasil akhir. Di tingkat pelatihan, beberapa kebijakan yang berbeda dengan berbagai hiperparameter dilatih. Pada tingkat tes, untuk beberapa episode pertama, masing-masing diuji, dan untuk pelatihan lebih lanjut, kebijakan yang memberikan hadiah tes maksimum untuk episode dipilih.
Bloopers
Dan sekarang pada pertanyaan tentang apa yang dicoba, tetapi "tidak terbang." Bagaimanapun, ini bukan artikel SOTA baru untuk menyembunyikan sesuatu.
- Perubahan arsitektur jaringan: Aktivasi SELU , perhatian diri, blok SE
- Neuroevolution
- Membuat level Sonic Anda sendiri - semuanya disiapkan, tetapi tidak ada cukup waktu
- Pelatihan meta melalui MAML dan REPTILE
- Ensemble dari beberapa model dan pelatihan lebih lanjut selama pengujian masing-masing model menggunakan sampling penting
Ringkasan
Setelah 3 minggu dari akhir kompetisi, OpenAI memposting hasilnya . Di 11 level tambahan yang diciptakan, tim kami menerima tempat ke-4 yang terhormat, setelah melompat dari posisi ke-8 dalam ujian publik, dan menyusul garis pangkal yang tidak jelas dari OpenAI.
Poin pembeda utama yang “terbang” di 3ki pertama:
- Sistem tindakan yang lebih baik (muncul dengan tombol mereka sendiri, yang ekstra dihapus);
- Investigasi negara melalui hash dari gambar input;
- Lebih banyak level pelatihan;
Selain itu, saya ingin mencatat bahwa dalam kontes ini, selain menang, uraian keputusan mereka, serta materi yang membantu peserta lain didorong secara aktif - ada juga nominasi terpisah untuk ini. Yang, sekali lagi, meningkatkan kontes lampu.
Kata penutup
Secara pribadi, saya sangat menyukai kompetisi ini, serta tema meta learning. Selama berpartisipasi, saya berkenalan dengan sejumlah besar artikel (saya bahkan tidak melupakan beberapa di antaranya) dan mempelajari sejumlah besar pendekatan berbeda yang saya harap dapat diterapkan di masa depan.
Dalam tradisi terbaik untuk berpartisipasi dalam kompetisi, semua kode tersedia dan diposting di github .