
Dalam
artikel sebelumnya tentang topik manajemen risiko negara, kami membahas dasar-dasarnya: mengapa otoritas negara harus mengelola risiko, ke mana harus mencari risiko, dan apa pendekatan untuk menilai. Hari ini kita akan berbicara tentang proses analisis risiko: bagaimana mengidentifikasi penyebab terjadinya mereka dan mengidentifikasi pelanggar.
Penilaian risiko
Untuk menilai risiko - bahkan dalam kerangka pendekatan statis, meskipun dinamis - Anda perlu menemukan penyebabnya, kondisi terjadinya, dan menentukan karakteristik utama: probabilitas dan potensi kerusakan dari implementasi.
Ambil, misalnya, bea cukai: ketika mengimpor produk apa pun ke negara itu, kecuali untuk berbagai informasi yang berbeda (biaya, berat, kemasan, pengirim, penerima, dll.), Deklarasi harus dibuat dalam deklarasi sesuai dengan klasifikasi khusus - nomenklatur komoditas kegiatan ekonomi asing (FEA). Kode untuk barang ini kemudian menentukan bea masuk sesuai dengan tarif bea cukai (tarif TN FEA +).
Tarif bea cukai adalah penggolong kompleks: sekilas, beberapa barang dapat dikaitkan dengan kode yang berbeda dengan tarif bea yang berbeda. Misalnya, Anda dapat menangani peralatan penambangan yang kompleks hanya dengan mempelajari gambar-gambarnya. Oleh karena itu godaan importir untuk menyatakan kode yang salah (tetapi mirip dengan kebenaran) untuk membayar lebih sedikit uang ke anggaran.
Jadi kami
mengidentifikasi risiko - pernyataan kode produk yang tidak dapat diandalkan dalam deklarasi untuk mengecilkan pembayaran bea cukai. Alasannya adalah kehadiran di classifier posisi "batas" dengan tingkat tugas yang berbeda.
Lebih sulit untuk mendeteksi kondisi untuk terjadinya risiko seperti itu - kapan dan dengan barang apa yang terjadi dalam praktiknya. Untuk melakukan ini, Anda perlu melakukan
analisis risiko : untuk mempelajari sejarah pengamatan objek kontrol, untuk mengetahui kapan dan siapa yang menyatakan kode produk yang salah, dan untuk mengidentifikasi beberapa karakteristik umum dari kasus ini. Ini akan memungkinkan untuk merumuskan
aturan untuk manajemen risiko di masa depan: objek mana yang akan kita kaitkan dengan risiko dan audit apa yang harus dikenakan.
Cara termudah untuk mendapatkan aturan ini adalah memercayai penilaian ahli dari karyawan Anda.
Aturan Pakar
Aturan tersebut untuk mengidentifikasi risiko adalah spesialis masalah pokok. Mereka dibimbing oleh pengalaman kerja mereka atau merangkum pendapat rekan-rekan yang setiap hari menemui pelanggar. Hasilnya adalah penilaian sederhana dari bentuk "jika ... maka ...".
Probabilitas terjadinya risiko dan potensi kerusakan dari ancaman dalam kasus ini ditentukan "oleh mata" atau oleh perkiraan kasar.
Keuntungan dari aturan ahli adalah kemudahan kompilasi dan interpretasi oleh manusia. Kerugiannya adalah bahwa sejumlah besar orang, baik pelanggar dan subyek kegiatan ekonomi yang terhormat, secara bersamaan dapat jatuh di bawah aturan. Karena itu, efektivitas kontrol akan rendah. Pada saat yang sama, beberapa pelanggar akan lewat, di mana ahli tidak dapat mendeteksi dan memperhitungkan pola akun.
Misalnya, aturan ahli untuk kontrol bea cukai memberi tahu kami bahwa semua kumpulan apel dengan nilai di bawah ambang tertentu terkait dengan pengiriman risiko:

Ketika kami melakukan kontrol, kami akan menemukan kedua barang dengan penyimpangan (merah) dan pengiriman cukup normal (hijau), biaya rendah yang dijelaskan oleh diskon individu, perjuangan pengirim dengan terlalu banyak menimbun atau model perusahaan ekonomi.
Apa pun di atas ambang batas nilai bersyarat ini (garis merah) akan di luar kendali (lingkaran abu-abu). Tetapi jika kita memeriksanya juga, kita akan menemukan pengiriman dan pengiriman yang benar-benar sah yang nilainya sebenarnya bahkan lebih tinggi dari apa yang dinyatakan dalam deklarasi (lingkaran abu-abu dengan garis putus-putus merah) dan pembayaran cukai tidak dibayar penuh.
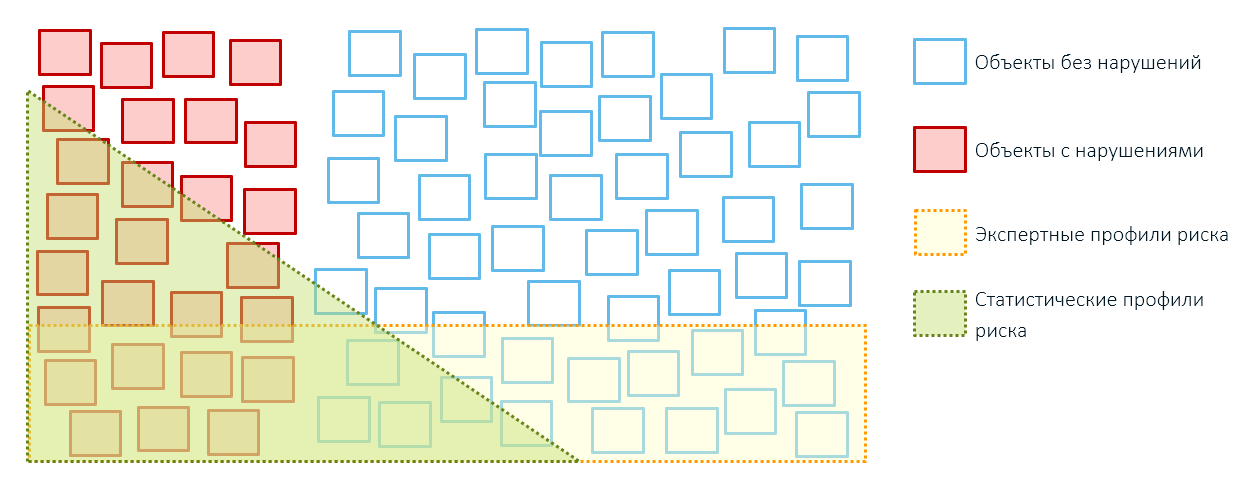
Oleh karena itu, penerapan aturan pakar biasanya mengarah pada cakupan objek kontrol yang berlebihan dan kinerja rendah (ingat, kotak kami dari artikel pertama?):
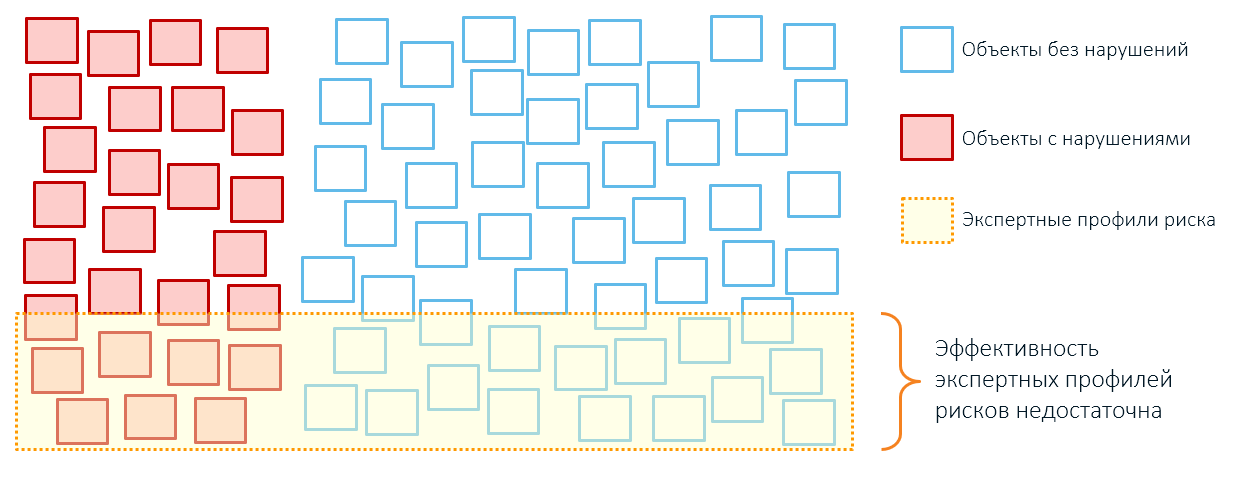
Para ahli tidak boleh disalahkan: kesadaran manusia terbatas pada objek yang dapat dioperasikannya (artikel yang ingin tahu dipublikasikan di Habr sekali, penulisnya menyarankan bahwa jumlah mereka dibatasi hingga tujuh). Karenanya pukulan besar bukannya detail yang tepat: katakanlah, risiko kebakaran ditentukan hanya pada tahun bangunan itu dibangun, luas lokasi, dan kategori penduduk. Semua karakteristik ini pernah "dimainkan": kebakaran terjadi di sebuah rumah tua, sebuah ruangan terbakar di area yang tidak berfungsi. Oleh karena itu, para ahli mengharapkan ancaman di masa depan justru dari objek jenis ini.
Tetapi tidak semua bangunan "berbahaya" ini benar-benar akan terbakar, bahkan jika mereka jatuh di bawah kekuasaan ahli: banyak rumah tua dan kayu berdiri seolah-olah tidak ada yang terjadi. Beberapa rumah yang rusak telah berdiri tanpa api selama bertahun-tahun. Hanya saja ahli tidak dapat memperhitungkan beberapa karakteristik halus individu dari benda berbahaya.
Di sinilah pembelajaran mesin ikut bermain yang membantu membuat
profil risiko statistik . Mereka terbentuk ketika kita menerapkan teknologi analisis data untuk sejarah pelanggaran dan informasi tentang objek yang dikendalikan.
Profil Risiko Statistik
Dalam hal ini, kami memecahkan masalah klasifikasi biner: algoritma analitik khusus menentukan dengan sendirinya karakteristik objek yang memungkinkan untuk menghubungkannya dengan "buruk" atau "baik". Jika semuanya dilakukan dengan benar, pada akhirnya kita akan mendapatkan penilaian risiko yang cukup akurat: kondisi terperinci dan probabilitas yang dihitung secara otomatis ditambah potensi kerusakan (yang, dengan pendekatan ahli, juga ditentukan entah bagaimana "ahli"). Karakteristik ini mendefinisikan "profil risiko" - apa, di mana, kapan, dan bagaimana menakutkan.
Profil risiko statistik dibuat dengan berbagai cara. Ini mungkin didasarkan pada pohon keputusan atau hutan acak. Anda dapat menerapkan jaringan saraf rumit dengan sejumlah besar lapisan tersembunyi.
Tetapi kami di SAS percaya bahwa untuk tujuan kontrol negara, lebih baik membuat profil risiko statistik berdasarkan algoritma yang ditafsirkan, misalnya,
regresi atau
pohon keputusan . Praktek telah menunjukkan bahwa sulit bagi badan negara untuk mengarahkan dirinya sendiri meskipun itu adalah perkiraan yang akurat tetapi tidak dapat dipahami dari sebuah mesin, jika itu tidak menjelaskan mengapa orang yang dihormati ini ditandai sebagai penjahat.
Lembaga negara perlu memahami dengan tepat faktor-faktor mana yang mengindikasikan ancaman dan mana dari para pelanggar yang memiliki karakteristik yang sama, karena ada prosedur untuk menyetujui keputusan manajerial (kasus tertentu yang merupakan profil risiko). Pejabat tersebut harus memahami apa yang sebenarnya ia luncurkan "ke dalam pertempuran", karena ia bertanggung jawab atas hasil dari profil risiko.
Setiap verifikasi harus dibenarkan dan pembenaran ini harus diungkapkan dengan kata-kata. Jika tidak, maka Anda harus memerah di depan jaksa penuntut dan menjelaskan bagaimana ternyata agen negara “mencubit” bisnis domestik berdasarkan instruksi misterius deus ex machina.
Oleh karena itu, profil risiko statistik juga terlihat seperti aturan yang dapat dibaca dan dipahami. Hanya daftar karakteristik yang menggambarkan kemungkinan pelanggar yang lebih besar dan lebih kompleks daripada profil ahli:
 * Nilai parameter profil diubah dan tidak sesuai dengan yang asli
* Nilai parameter profil diubah dan tidak sesuai dengan yang asliSeperangkat
indikator risiko (kondisi) mungkin tampak sedikit aneh. Tapi ini bukan "sihir yang hebat" - hanya dengan bantuan teknologi pembelajaran mesin dan informasi terbatas yang kami miliki, kami menggambarkan beberapa pola tersembunyi dari perilaku manusia yang mengarah pada gangguan.
Hal yang sama juga ada dalam kontrol pajak - pelanggar dapat membedakan dari jumlah total pembayar pajak kisaran tertentu dari transaksi tertentu, tenggat waktu untuk pengajuan deklarasi, jumlah karyawan di staf perusahaan, jumlah akun dan 30 parameter berbeda yang secara kolektif menggambarkan wirausahawan yang tidak jujur yang mengingkari PPN.
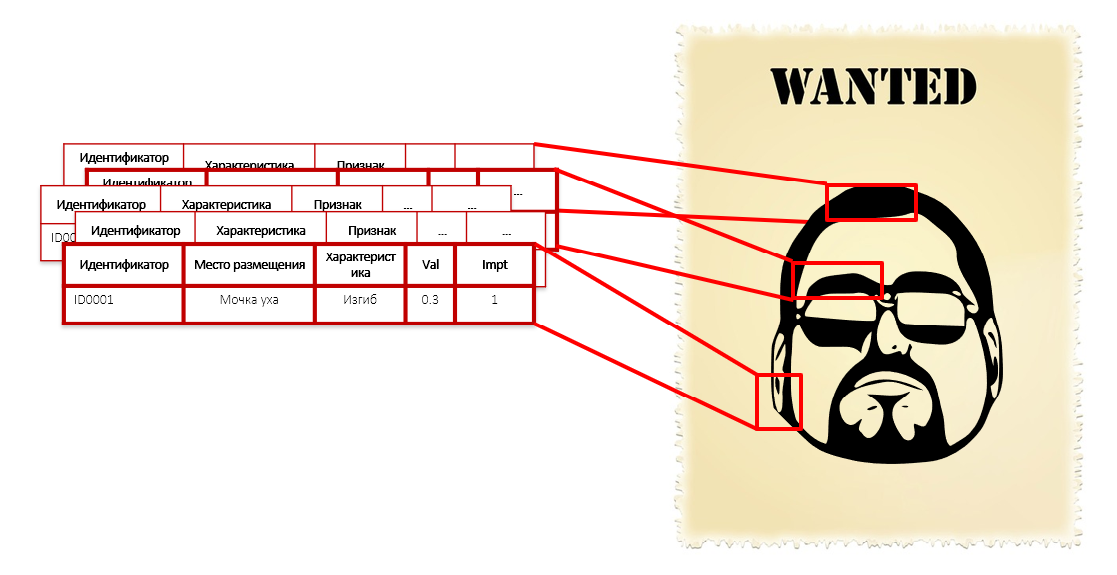
Seseorang tidak akan dapat membandingkan semua karakteristik ini, ia akan mengelola dengan tiga atau lima, yang lebih mudah dimengerti. Dan programnya bisa. Sedetail yang diperlukan. Ketika membangun sebuah model, algoritme secara otomatis beralih pada massa data dan menemukan kesamaan apa yang dimiliki para pelaku - bahkan jika itu adalah cinta akan ikatan merah di jaring kuning.
Ini mirip dengan deskripsi penjahat dalam ciri-ciri individualnya: bentuk hidung, telinga, lengkungan alis, warna baju dan panjang kaki. Kita tidak tahu wajahnya, tinggi dan berat, tetapi kita memiliki ribuan karakteristiknya, termasuk panjang rambut di jari-jari jari kelingking kiri. Masing-masing parameter ini secara individual tidak memberikan niat kriminal - Anda tidak perlu memborgol seseorang hanya untuk jari-jari kelengkungan daun telinga. Tetapi seluruh rangkaian karakteristik ini bersama-sama membentuk potret yang cukup akurat dari penyusup:
Ketika kami beralih dari menerapkan aturan pakar ke profil statistik berdasarkan analisis pola tersembunyi, kami membuang pemeriksaan yang tidak efektif. Bidang besar kontrol terus-menerus menyempit ke titik dampak pada objek yang termasuk dalam
pola perilaku tidak adil yang diungkapkan.
Ingat apel dari contoh bea cukai di atas. Dengan mengirimkan sejarah cek ke pintu masuk model statistik, kami mendapatkan profil risiko yang memperhitungkan karakteristik perilaku pelanggar importir, terlepas dari harga di mana mereka menyatakan barang:
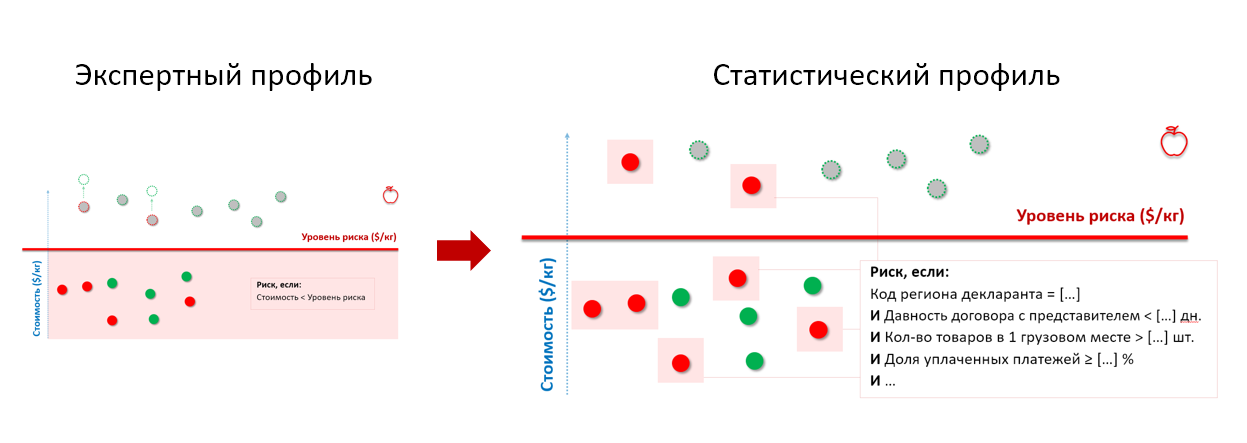 * set parameter profil risiko telah diubah dan tidak sesuai dengan yang asli
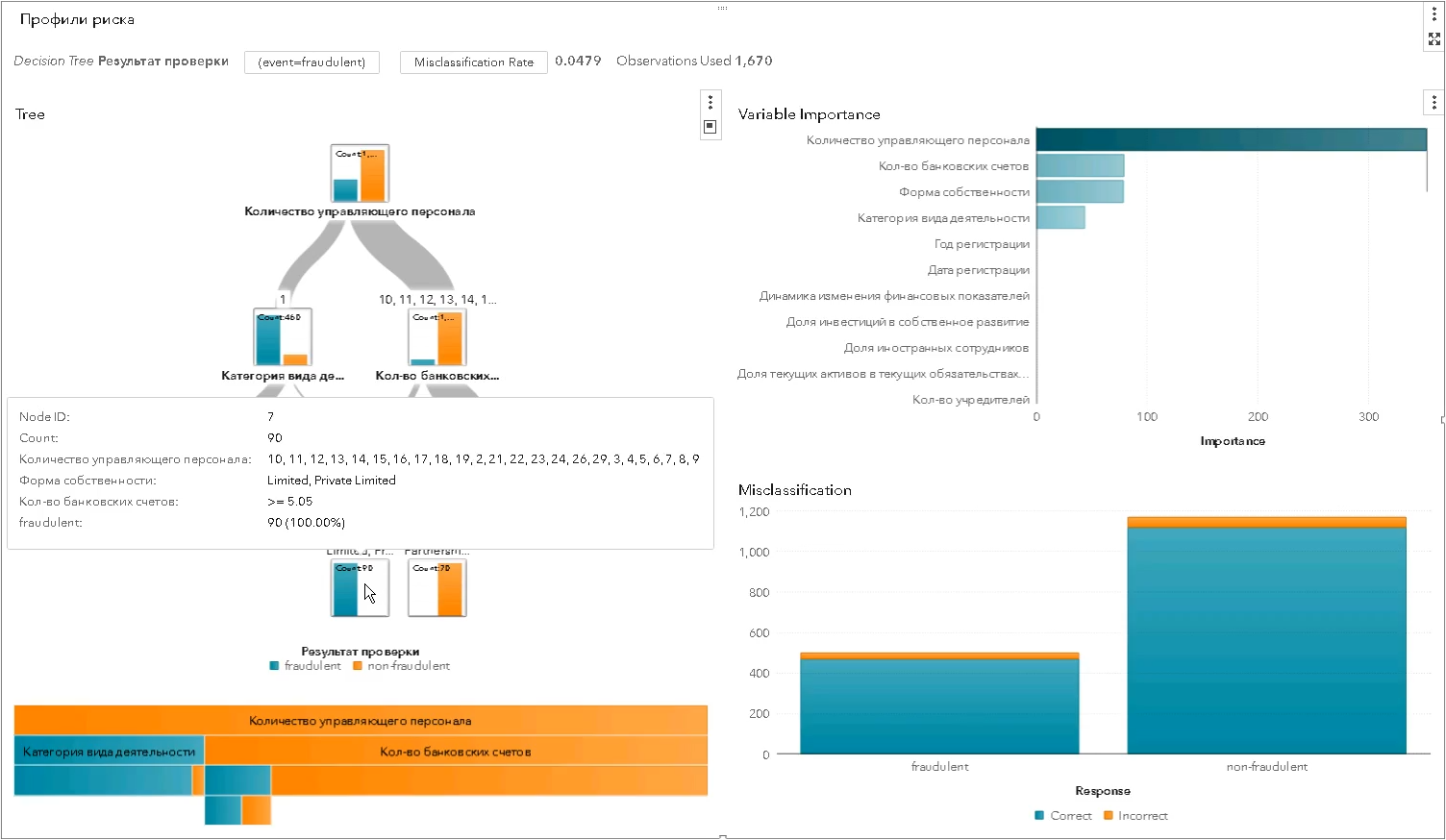
* set parameter profil risiko telah diubah dan tidak sesuai dengan yang asliIni adalah bagaimana profil risiko statistik dibangun menggunakan algoritma dari kelas "pohon keputusan" - setiap levelnya semakin memisahkan himpunan entitas yang diuji menjadi "baik" dan "buruk" dan menunjukkan karakteristik pemisahan mana yang paling signifikan (dalam tangkapan layar SAS Visual Statistics):
Profil statistik lebih baik daripada yang ahli - lebih tepatnya, lebih selektif, tidak memihak. Mereka membantu meningkatkan efektivitas inspeksi dengan mengurangi jumlah "latihan" yang menganggur:
Kerugian dari profil statistik adalah bahwa mereka dipandu oleh pengalaman masa lalu dalam mengidentifikasi pelanggaran. Untuk skema terkenal.
Jika dalam sejarah pengendalian pabean ada kasus-kasus meremehkan saat mengimpor barang, algoritme akan menemukan tanda-tanda pelanggar dan membentuk profil risiko statistik. Jika kita mencari beberapa pelanggaran baru yang belum menjadi perhatian lembaga negara, dan kita tidak tahu karakteristiknya, maka kita harus bertindak "dengan sentuhan" - dengan coba-coba.
Pencarian tidak dikenal
Anda dapat merasakan hal yang tidak diketahui dengan beberapa cara.
Yang pertama adalah
random sampling . Kami mengambil objek yang sewenang-wenang (dalam kekuasaan kami) - produk, perusahaan, bangunan atau warga negara - dan dengan cermat mempertimbangkannya. Pendekatan ini cukup adil, tetapi tidak terlalu efektif - subjek yang terhormat dapat juga jatuh ke bawah "debriefing". Kekuatan lembaga negara dan uang anggaran akan dihabiskan dengan sia-sia.
Yang kedua adalah
identifikasi anomali . Dalam hal ini, sebuah objek diambil untuk verifikasi, yang parameternya dibedakan dari yang lainnya. Ketika kami menganalisis peristiwa abnormal, dan tidak hanya secara acak "menyodok" banyak objek, probabilitas menemukan pelanggaran lebih tinggi.
Misalnya, ketika melakukan pengawasan lingkungan, ternyata pabrik mengkonsumsi banyak listrik secara tak terduga:
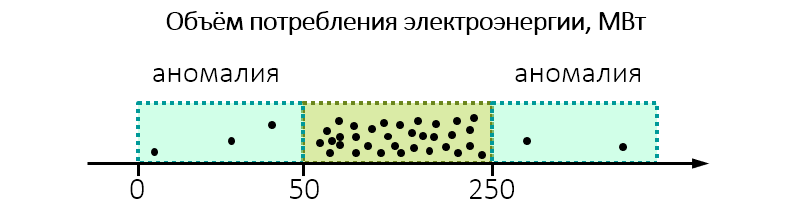
Mungkin ada baiknya melihat lebih dekat dan memeriksa apakah pabrik tidak dibuang ke air atau udara lebih dari yang diizinkan.
Atau barang di pabean memiliki rasio yang tidak biasa dari berat barang dan kemasan:
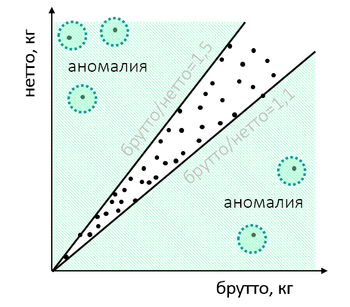
Setelah memeriksa, ternyata importir “bermain” dengan berat untuk menutupi beberapa pelanggaran: meremehkan biaya dan dengan demikian ingin memperketat salah satu nilai pengujian atau mengeluarkan beberapa barang dengan kedok orang lain. Karakteristik berat “alami”, jika Anda gali dengan baik, berbeda dari yang fiktif.
Namun, ini adalah contoh paling sederhana yang bisa dilihat seseorang. Pada kenyataannya, pencarian anomali terjadi dalam ruang atribut multidimensi - mungkin ada ratusan. Algoritme melakukan apa yang manusia tidak dapat lakukan - ia menemukan objek yang berbeda secara signifikan dari yang lain pada saat yang sama dalam sejumlah besar tanda, dan menentukan apa yang disebut outlier multidimensi (dalam tangkapan layar SAS Visual Statistics):
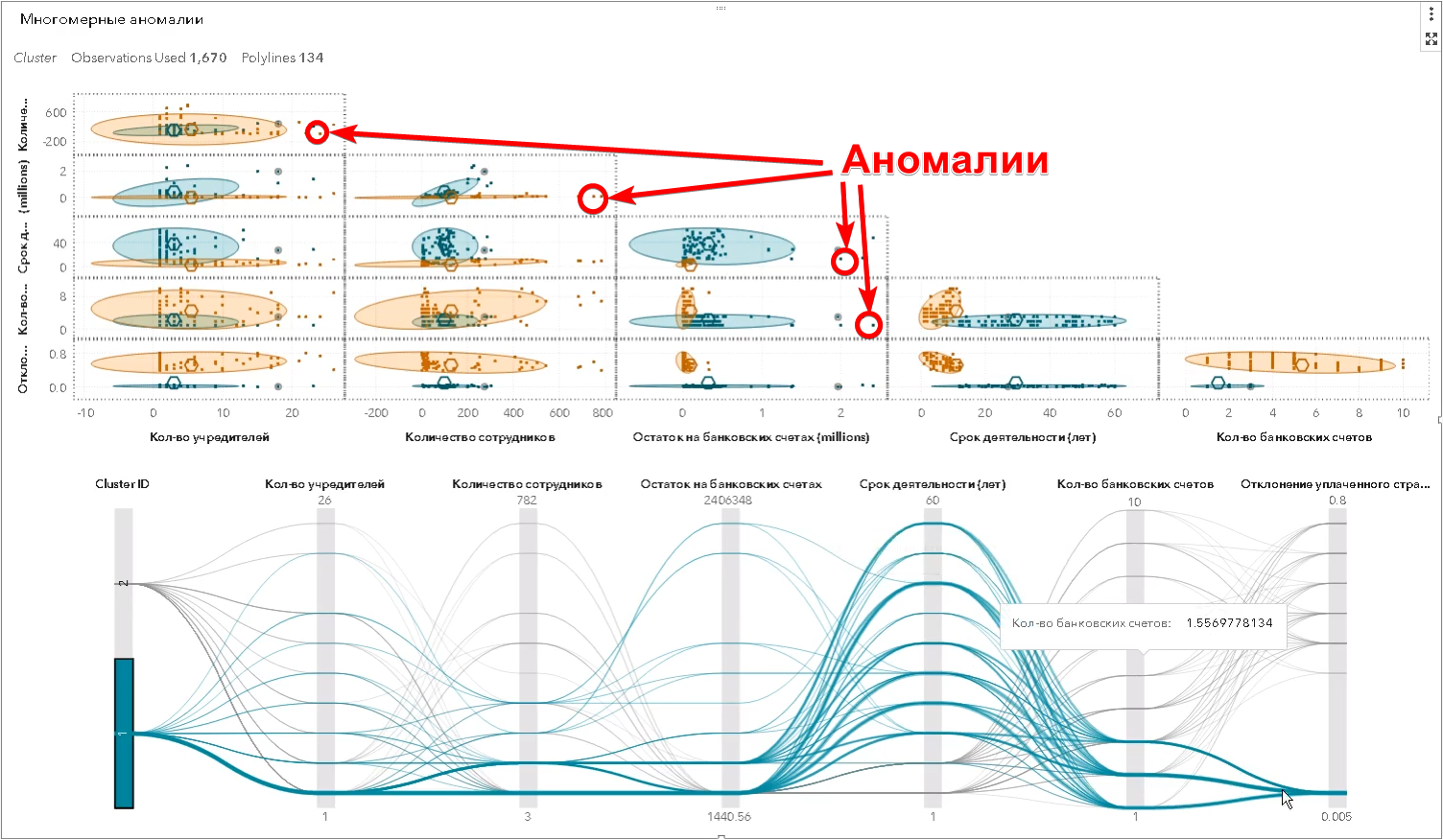
Selain itu, di luar batas persepsi manusia, ada berbagai hubungan hukum antara berbagai perusahaan yang divisualisasikan menggunakan grafik (dalam tangkapan layar SAS Social Network Analysis):
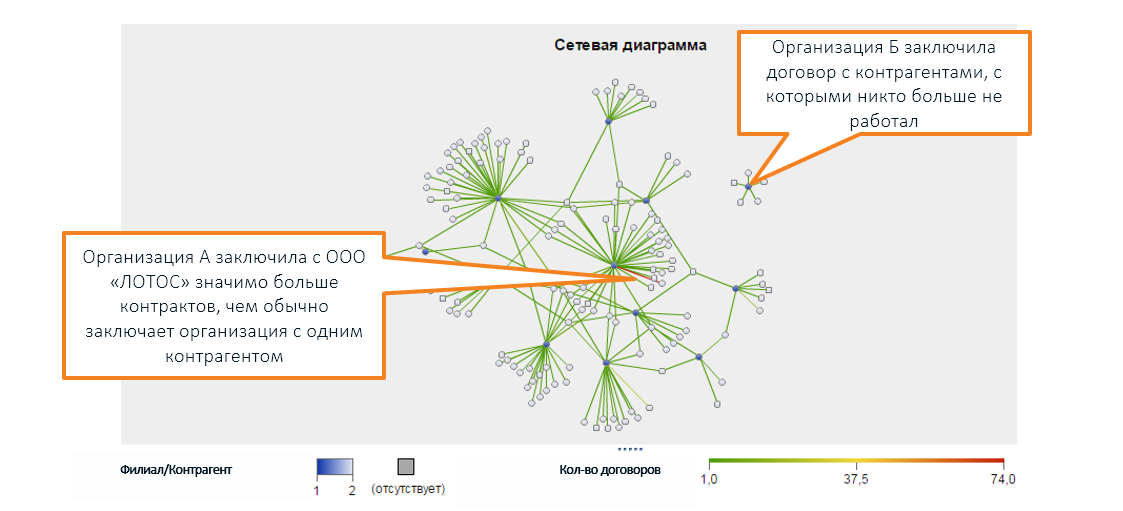 * Nama-nama organisasi diciptakan, kebetulan dengan perusahaan nyata adalah acak
* Nama-nama organisasi diciptakan, kebetulan dengan perusahaan nyata adalah acakKarakteristik yang tidak biasa tidak selalu mengindikasikan masalah. Cek mungkin tidak menunjukkan apa-apa: ya, indikatornya aneh, tetapi tidak ada pelanggaran.
Anomali bukan risiko, itu hanya "sesuatu yang tidak biasa." Profil anomali diperlukan untuk menyediakan "bahan baku" baru untuk ahli bangunan atau profil statistik, karena hasil verifikasi anomali termasuk dalam sejarah pengamatan objek yang dikendalikan.
Pendekatan hybrid
Hasil terbaik dalam kegiatan kontrol dan pengawasan badan-badan negara (dan tidak hanya di dalamnya) dapat dicapai dengan menggabungkan ketiga metode mengidentifikasi risiko: aturan ahli, profil risiko statistik berdasarkan teknologi pembelajaran mesin dan profil anomali. Pada saat yang sama, lebih baik untuk mengurangi cakupan objek dengan aturan ahli, meninggalkannya hanya untuk pengaruh administratif yang ditargetkan (misalnya, menjatuhkan sanksi - kami memblokir barang dari negara-negara ini):
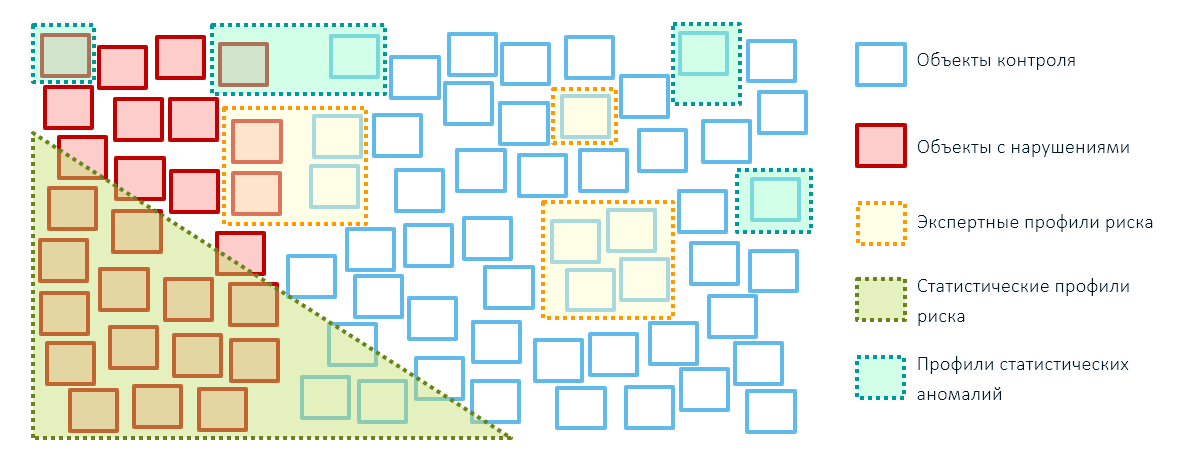
Anda tidak dapat melakukannya tanpa aturan ahli pada tahap awal membangun sistem manajemen risiko, karena diperlukan basis preseden untuk membuat model analitik. Untuk membuatnya, perlu melakukan pemeriksaan berdasarkan profil risiko ahli dan baru kemudian beralih ke model matematika.
Kami di SAS percaya bahwa masa depan kegiatan kontrol dan pengawasan negara didasarkan pada pendekatan hybrid yang akan menggabungkan pengalaman badan-badan negara dan pengetahuan ahli karyawannya dengan teknologi pembelajaran mesin modern. Dalam hal ini, kami mengurangi hasil dari ketiga modul menjadi satu penilaian risiko terintegrasi:
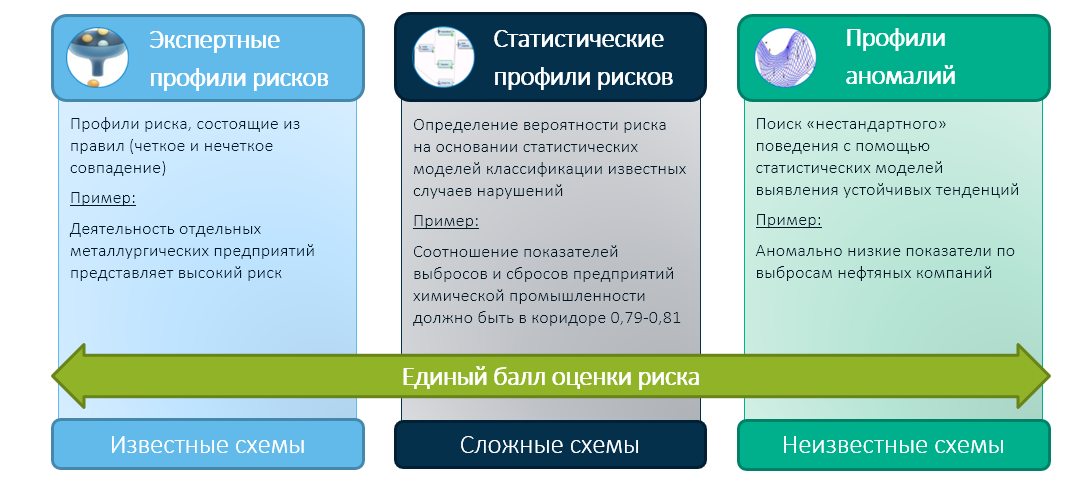
Dan sudah penilaian terintegrasi (misalnya, berdasarkan matriks keputusan ahli) menentukan pilihan badan kontrol - siapa yang akan diperiksa dan siapa yang harus dipercaya.
Pada artikel selanjutnya, kami akan menganalisis metode untuk meminimalkan ancaman yang teridentifikasi dan memikirkan mengapa umpan balik dan penilaian risiko dinamis sangat penting.