Sebagai bagian dari dukungan produk, kami terus melayani permintaan pengguna. Ini adalah proses standar. Dan seperti proses apa pun, itu perlu dievaluasi dan ditingkatkan secara kritis.
Kami tahu tentang beberapa masalah sistematis yang sebaiknya diselesaikan dan, jika mungkin, tanpa menarik sumber daya tambahan:
- Kesalahan dalam mengirimkan aplikasi: kami mendapatkan sesuatu yang "asing", tim lain terkadang mendapatkan sesuatu "milik kami".
- sulit untuk menilai "kompleksitas" aplikasi Jika aplikasi ini kompleks, dapat diteruskan ke analis yang kuat, dan dengan yang sederhana, pemula akan mengatasinya.
Solusi untuk semua masalah ini akan secara positif mempengaruhi kecepatan pemrosesan aplikasi.
Aplikasi pembelajaran mesin, sebagaimana diterapkan pada analisis konten aplikasi, terlihat seperti peluang nyata untuk meningkatkan proses pengiriman.
Dalam kasus kami, masalahnya dapat dirumuskan dengan masalah klasifikasi berikut:
- Pastikan bahwa permintaan tersebut ditetapkan dengan benar ke:
- unit konfigurasi (salah satu dari 5 dalam aplikasi atau "orang lain")
- kategori layanan (insiden, permintaan informasi, permintaan layanan)
- Perkirakan waktu yang diharapkan untuk menutup permintaan (sebagai indikator "kompleksitas" tingkat tinggi).
Apa dan bagaimana kita akan bekerja
Untuk membuat algoritma, kita akan menggunakan "set standar": Python dengan pustaka scikit-learn.
Untuk aplikasi nyata, 2 skenario akan diterapkan:
Pelatihan:
- mendapatkan data "pelatihan" dari pelacak aplikasi
- menjalankan algoritme untuk melatih model, menyimpan model
Penggunaan:
- menerima data dari pelacak aplikasi untuk klasifikasi
- pemuatan model, klasifikasi aplikasi, hasil penghematan
- memperbarui aplikasi dalam pelacak berdasarkan klasifikasi
Segala sesuatu yang terkait dengan pipa (interaksi dengan pelacak) dapat diimplementasikan pada apa saja. Dalam hal ini, skrip PowerShell ditulis, meskipun dimungkinkan untuk melanjutkan dengan python.
Algoritma pembelajaran mesin akan menerima data klasifikasi / pelatihan dalam bentuk file .csv. Hasil yang diproses juga akan menjadi output ke file .csv.
Masukkan data
Untuk membuat algoritma se independen mungkin dari pendapat tim layanan, kami hanya akan mempertimbangkan data yang diterima dari pencipta aplikasi sebagai parameter input dari model:
- Deskripsi / judul pendek (teks)
- Penjelasan rinci tentang masalah, jika ada (teks). Ini adalah pesan pertama dalam alur komunikasi aplikasi.
- Nama pelanggan (karyawan, kategori)
- Nama karyawan lain yang termasuk dalam daftar pantauan berdasarkan permintaan (daftar karyawan)
- Waktu pengajuan aplikasi (tanggal / waktu).
Dataset pelatihan
Untuk pelatihan algoritma, data panggilan tertutup selama 3 tahun terakhir digunakan - ~ 3.500 catatan.
Selain itu, untuk mengajarkan pengklasifikasi tentang pengenalan unit konfigurasi "lainnya", aplikasi tertutup yang diproses oleh departemen lain untuk unit konfigurasi lainnya ditambahkan ke set pelatihan. Total catatan tambahan - sekitar 17.000.
Untuk semua permintaan tambahan seperti itu, unit konfigurasi akan diatur ke "lain"
Pretreatment
Teks
Pra-pemrosesan teks sangat sederhana:
- Kami menerjemahkan semuanya menjadi huruf kecil
- Hanya menyisakan angka dan huruf - ganti sisanya dengan spasi
Daftar Pemberitahuan (daftar pantauan)
Daftar ini tersedia untuk analisis dalam bentuk string di mana nama-nama disajikan dalam bentuk Nama Belakang, Nama Depan, dan dipisahkan oleh tanda titik koma. Untuk analisis, kami akan mengubahnya menjadi daftar string.
Dengan menggabungkan daftar kami mendapatkan satu set nama unik berdasarkan semua aplikasi dari set pelatihan. Daftar umum ini akan membentuk vektor nama.
Durasi Pemrosesan Aplikasi
Untuk tujuan kami (manajemen prioritas, perencanaan rilis), cukup untuk menghubungkan aplikasi ke kelas tertentu dengan durasi layanan. Ini juga memungkinkan Anda untuk memindahkan tugas dari regresi ke klasifikasi dengan sejumlah kecil kelas.
Teks
- Gabungkan "judul" dan "deskripsi masalah."
- Teruskan ke TfidfVectoriser untuk membentuk vektor kata
Nama pemohon
Karena diharapkan orang yang membuat aplikasi akan menjadi atribut penting dari klasifikasi lebih lanjut - kami akan menerjemahkannya ke dalam salah satu pengkodean secara individual menggunakan DictionaryVectorisor
Nama orang yang termasuk dalam daftar notifikasi
Daftar orang yang termasuk dalam aplikasi daftar pantauan akan dikonversi menjadi vektor berdasarkan semua nama yang disiapkan sebelumnya: jika orang tersebut ada dalam daftar, komponen yang sesuai akan ditetapkan ke 1, jika tidak - ke 0. Satu aplikasi dapat memiliki beberapa orang dalam daftar pantauan - masing-masing, beberapa komponen akan memiliki nilai tunggal.
Tanggal pembuatan
Tanggal pembuatan akan disajikan sebagai satu set atribut numerik - tahun, bulan, hari dalam sebulan, hari dalam seminggu.
Ini dilakukan dengan asumsi bahwa:
- Kecepatan pemrosesan aplikasi bervariasi dari waktu ke waktu
- Kecepatan pemrosesan memiliki faktor musiman
- Hari dalam seminggu (terutama aplikasi akhir pekan) dapat membantu mengidentifikasi unit konfigurasi dan kategori layanan
Model pelatihan
Algoritma klasifikasi
Untuk ketiga tugas klasifikasi, regresi logistik digunakan. Ini mendukung klasifikasi multiclass (dalam model One-vs-All), belajar cukup cepat.
Untuk melatih model yang menentukan kategori layanan dan durasi pemrosesan aplikasi, kami hanya akan menggunakan aplikasi yang jelas milik unit konfigurasi kami.
Hasil belajar
Menentukan Unit Konfigurasi
Model ini menunjukkan indikator kelengkapan dan akurasi yang tinggi ketika menetapkan aplikasi ke unit konfigurasi. Selain itu, model juga mendefinisikan peristiwa ketika aplikasi merujuk ke unit konfigurasi asing.
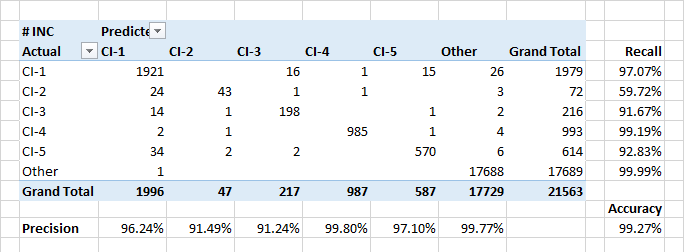
Kelengkapan yang relatif rendah untuk kelas CI-2 sebagian karena kesalahan klasifikasi nyata dalam data. Selain itu, CI-2 menghadirkan aplikasi "teknis" yang dieksekusi untuk CI lainnya. Jadi, dalam hal deskripsi dan pengguna yang terlibat, aplikasi semacam itu mungkin mirip dengan aplikasi kelas lain.
Atribut paling signifikan untuk mengklasifikasikan aplikasi sebagai CI-? diharapkan adalah nama-nama pelanggan aplikasi dan orang-orang yang termasuk dalam lembar peringatan. Tetapi ada beberapa kata kunci yang penting dalam 30-ke pertama. Tanggal pembuatan aplikasi tidak masalah.
Definisi Kategori Aplikasi
Kualitas klasifikasi berdasarkan kategori ternyata agak lebih rendah.
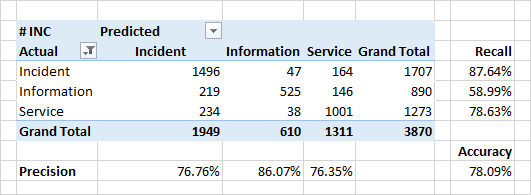
Alasan yang sangat serius untuk ketidakcocokan kategori yang diprediksi dan kategori dalam sumber data adalah kesalahan nyata dalam sumber data. Karena sejumlah alasan organisasi, klasifikasi tersebut mungkin salah. Misalnya, alih-alih sebuah "insiden" (kerusakan dalam sistem, perilaku sistem yang tidak terduga), aplikasi dapat ditandai sebagai "informasi" ("ini bukan bug - ini adalah fitur") atau "layanan" ("ya, itu rusak, tapi kami baru saja memulai ulang - dan semuanya akan beres ").
Identifikasi ketidakkonsistenan tersebut adalah salah satu tugas pengklasifikasi.
Atribut yang signifikan untuk klasifikasi dalam hal kategori adalah kata-kata dari konten aplikasi. Untuk insiden, ini adalah kata "error", "fix", "when". Ada juga kata-kata yang menunjukkan beberapa modul sistem - ini adalah modul yang digunakan pengguna untuk bekerja secara langsung dan mengamati munculnya kesalahan langsung atau tidak langsung.
Menariknya, untuk aplikasi yang didefinisikan sebagai "layanan" - kata-kata teratas juga mendefinisikan beberapa modul sistem. Suatu kesempatan untuk berpikir, memeriksa, dan akhirnya memperbaikinya.
Menentukan waktu pemrosesan aplikasi
Yang terlemah adalah untuk memprediksi durasi pemrosesan aplikasi.
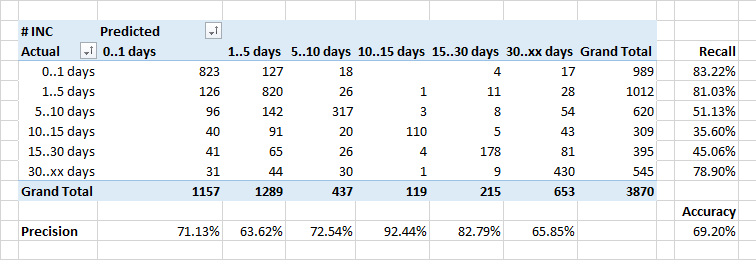
Secara umum, ketergantungan pada jumlah aplikasi yang ditutup untuk waktu tertentu idealnya akan terlihat seperti kebalikan dari eksponen. Tetapi dengan mempertimbangkan fakta bahwa beberapa insiden memerlukan koreksi dalam sistem, dan ini dilakukan sebagai bagian dari rilis reguler, durasi eksekusi beberapa aplikasi secara artifisial meningkat.
Oleh karena itu, mungkin classifier mengklasifikasikan beberapa aplikasi "panjang" sebagai "lebih cepat" - dia tidak tahu tentang waktu rilis yang direncanakan, dan percaya bahwa aplikasi perlu ditutup lebih cepat.
Ini juga alasan yang bagus untuk berpikir ...
Implementasi model sebagai kelas
Model ini diimplementasikan sebagai kelas yang merangkum semua kelas standar scikit-learning yang digunakan - penskalaan, vektorisasi, klasifikasi dan pengaturan yang signifikan.
Persiapan, pelatihan dan penggunaan selanjutnya dari model diimplementasikan sebagai metode kelas, berdasarkan objek tambahan.
Implementasi objek memungkinkan Anda untuk dengan mudah menghasilkan versi turunan dari model yang menggunakan kelas pengklasifikasi lain dan / atau memprediksi nilai atribut lain dari kumpulan data asli. Semua ini dilakukan dengan mengganti metode virtual.
Namun, semua prosedur persiapan data mungkin tetap umum untuk semua opsi.
Selain itu, implementasi model dalam bentuk objek memungkinkan untuk secara alami menyelesaikan masalah penyimpanan antara model yang terlatih antara sesi penggunaan - melalui serialisasi / deserialisasi.
Untuk cerita bersambung model, mekanisme Python standar, acar / membongkar, digunakan.
Karena ini memungkinkan Anda untuk membuat serial beberapa objek ke dalam file yang sama, ini akan membantu untuk secara konsisten menyimpan pemulihan beberapa model yang termasuk dalam aliran pemrosesan umum.
Kesimpulan
Model yang dihasilkan, walaupun relatif sederhana, memberikan hasil yang sangat menarik:
- mengidentifikasi "kelalaian" sistematis dalam klasifikasi berdasarkan kategori
- menjadi jelas bagian mana dari sistem yang terkait dengan masalah (tampaknya - bukan tanpa alasan)
- Waktu pemrosesan aplikasi jelas tergantung pada faktor-faktor eksternal yang perlu ditingkatkan secara terpisah.
Kami belum membangun kembali proses internal berdasarkan "petunjuk" yang diterima. Tetapi bahkan percobaan kecil ini memungkinkan untuk mengevaluasi kekuatan metode pembelajaran mesin. Dan juga, mendorong minat tambahan tim dalam analisis proses mereka sendiri dan peningkatannya.