Di awal karir saya, saya bekerja di sebuah perusahaan yang merilis sistem manajemen konten. CMS ini membantu departemen pemasaran mengelola situs mereka sendiri, daripada mengandalkan pengembang untuk setiap perubahan. Sistem ini telah membantu pelanggan mengurangi biaya pengoperasian, dan bagi saya - untuk mempelajari cara membuat aplikasi web.
Meskipun produk itu sendiri memiliki tujuan yang sangat umum, pelanggan biasanya menggunakannya untuk tugas-tugas tertentu. Tugas-tugas ini menekan keluar maksimum dari CMS, dan pengembang harus mencari solusi untuk masalah tersebut. Setelah sepuluh tahun bekerja di lingkungan seperti itu, saya belajar banyak cara bagaimana aplikasi web dalam produksi dapat rusak. Beberapa dari mereka akan dibahas dalam artikel ini.
Salah satu pelajaran yang dipetik selama bertahun-tahun adalah bahwa insinyur perorangan biasanya membenamkan diri sangat dalam di bidang yang diminati mereka, dan mempelajari sisanya secara dangkal. Skema ini bekerja secara normal di tim insinyur dengan komunikasi yang baik, di mana pengetahuan saling melengkapi dan mengisi celah masing-masing. Tetapi dalam tim dengan sedikit pengalaman atau untuk insinyur individu, kegagalan terjadi.
Jika Anda mulai bekerja di lingkungan seperti itu, dan kemudian mulai membuat dan menggunakan aplikasi web dari awal, maka Anda akan dengan cepat mempelajari apa itu "pengetahuan permukaan yang berbahaya".
Ada sejumlah solusi dalam industri untuk mengatasi masalah ini: aplikasi web yang dikelola (Beanstalk, AppEngine, dll.), Manajemen kontainer (Kubernetes, ECS, dll.) Dan banyak lainnya. Mereka bekerja dengan baik di luar kotak dan dapat memecahkan masalah dengan sempurna. Tetapi ini adalah kompleksitas yang tidak perlu ketika meluncurkan aplikasi web, dan biasanya solusi semacam itu "hanya bekerja".
Sayangnya, mereka tidak selalu “hanya bekerja.” Jika ada nuansa, maka saya ingin tahu lebih banyak tentang kotak hitam yang menyeramkan ini.
Dalam artikel tersebut, kami mengambil sistem yang tidak dapat diandalkan dan memodifikasinya ke tingkat keandalan yang wajar. Di setiap langkah, masalah nyata digunakan, solusinya membawa kita ke tahap berikutnya. Saya percaya bahwa lebih efisien untuk tidak menganalisis semua bagian dari desain akhir, tetapi hanya menggunakan pendekatan bertahap seperti itu. Dia lebih baik menunjukkan kapan dan dalam urutan apa untuk membuat keputusan tertentu. Pada akhirnya, kami akan membangun dari awal struktur dasar layanan hosting untuk aplikasi web yang dikelola, dan saya harap kami akan menjelaskan secara terperinci alasan keberadaan setiap bagiannya.
Mulai
Bayangkan anggaran Anda untuk hosting adalah $ 500 per tahun, jadi Anda memutuskan untuk menyewa satu server perantara di Amazon AWS. Pada saat penulisan, ini adalah sekitar $ 400 per tahun.
Anda tahu sebelumnya bahwa Anda akan memiliki sistem otorisasi dan bahwa Anda perlu menyimpan informasi tentang pengguna, sehingga Anda memerlukan database. Karena anggaran terbatas, kami akan menempatkannya di satu-satunya server kami. Pada akhirnya, kami mendapatkan infrastruktur berikut:
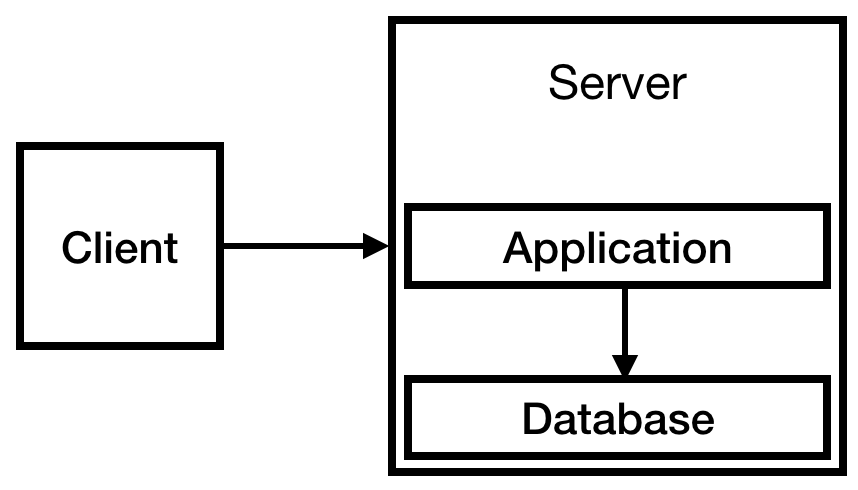 Fig. 1
Fig. 1Ini sudah cukup untuk saat ini. Bahkan, sistem seperti itu dapat bekerja untuk beberapa waktu. Layanannya kecil, kurang dari 10 kunjungan per hari. Mungkin contoh kecil sudah cukup, tetapi kami optimis tentang pertumbuhan perusahaan, jadi kami dengan hati-hati mengambil 2.medium.
Nilai bisnis ada di database, jadi ini sangat penting. Anda perlu memastikan bahwa jika server gagal, Anda tidak akan kehilangan data. Anda mungkin harus memastikan bahwa isi basis data tidak disimpan pada disk sementara. Lagipula, jika instance dihapus, Anda akan kehilangan data Anda. Ini adalah pemikiran yang sangat menakutkan.
Anda juga harus memastikan bahwa Anda memiliki cadangan ke penyimpanan eksternal. S3 sepertinya tempat yang bagus untuk mereka, dan relatif murah, jadi mari kita atur juga. Dan Anda harus memastikan bahwa cadangan berfungsi, mengembalikan cadangan secara berkala.
Sekarang sistemnya terlihat seperti ini:
 Fig. 2
Fig. 2Anda telah meningkatkan keandalan database, dan sekarang saatnya untuk mempersiapkan "habraeffect" dengan menjalankan uji beban pada server. Semuanya berjalan dengan baik hingga 500 kesalahan muncul, dan kemudian aliran 404 kesalahan, jadi Anda sedang menyelidiki apa yang terjadi.
Ternyata Anda tidak tahu apa yang terjadi karena Anda menulis log ke konsol dan tidak mengarahkan output ke file. Anda juga melihat bahwa prosesnya tidak berhasil, jadi Anda kemungkinan besar dapat berasumsi bahwa inilah sebabnya 404 kesalahan muncul. Gelombang kelegaan muncul karena Anda telah menjalankan uji beban lokal dengan benar, dan tidak menyebabkan efek Habra nyata sebagai beban uji.
Anda memperbaiki masalah dengan restart otomatis dengan membuat layanan
systemd , memulai server web, yang secara bersamaan memecahkan masalah logging. Kemudian jalankan uji beban lain untuk memverifikasi.
Dan lagi kita melihat kesalahan 500 (untungnya, tanpa 404). Anda memeriksa log. Terdeteksi bahwa kumpulan koneksi database penuh karena batas kecil 10 koneksi telah ditetapkan. Perbarui pembatasan, mulai ulang basis data, dan jalankan uji beban lagi. Semuanya berjalan baik, jadi Anda memutuskan untuk membicarakan situs Anda di Habré.
Hari peluncuran
Bunda Tuhan! Layanan Anda langsung menjadi hit. Anda sampai di halaman utama dan mendapatkan 5000 tampilan dalam 30 menit pertama - dan Anda melihat komentar. Apa yang mereka tulis di sana?
Saya memiliki kesalahan 404, jadi saya harus membuka versi halaman yang di-cache. Inilah tautannya, jika ada yang membutuhkannya: ...
...
Tidak ada yang terbuka. Juga, saya menonaktifkan Javascript. Mengapa orang berpikir bahwa saya ingin memuat Javascript 2 MB ...
...
Mengunduh beranda membutuhkan waktu 4 detik. Traceroute dari Australia menunjukkan bahwa server terletak di suatu tempat di Texas. Juga, mengapa halaman pertama memuat 2 megabita Javascript?
Dengan terburu-buru, Anda mengonfigurasi Nginx sebagai server proxy terbalik untuk aplikasi Anda dan mengonfigurasi halaman 404 statis di sana. Anda juga mengubah prosedur penyebaran untuk mengirim file statis ke S3: ini diperlukan agar CloudFront CDN berfungsi untuk mengurangi waktu pemuatan di Australia.
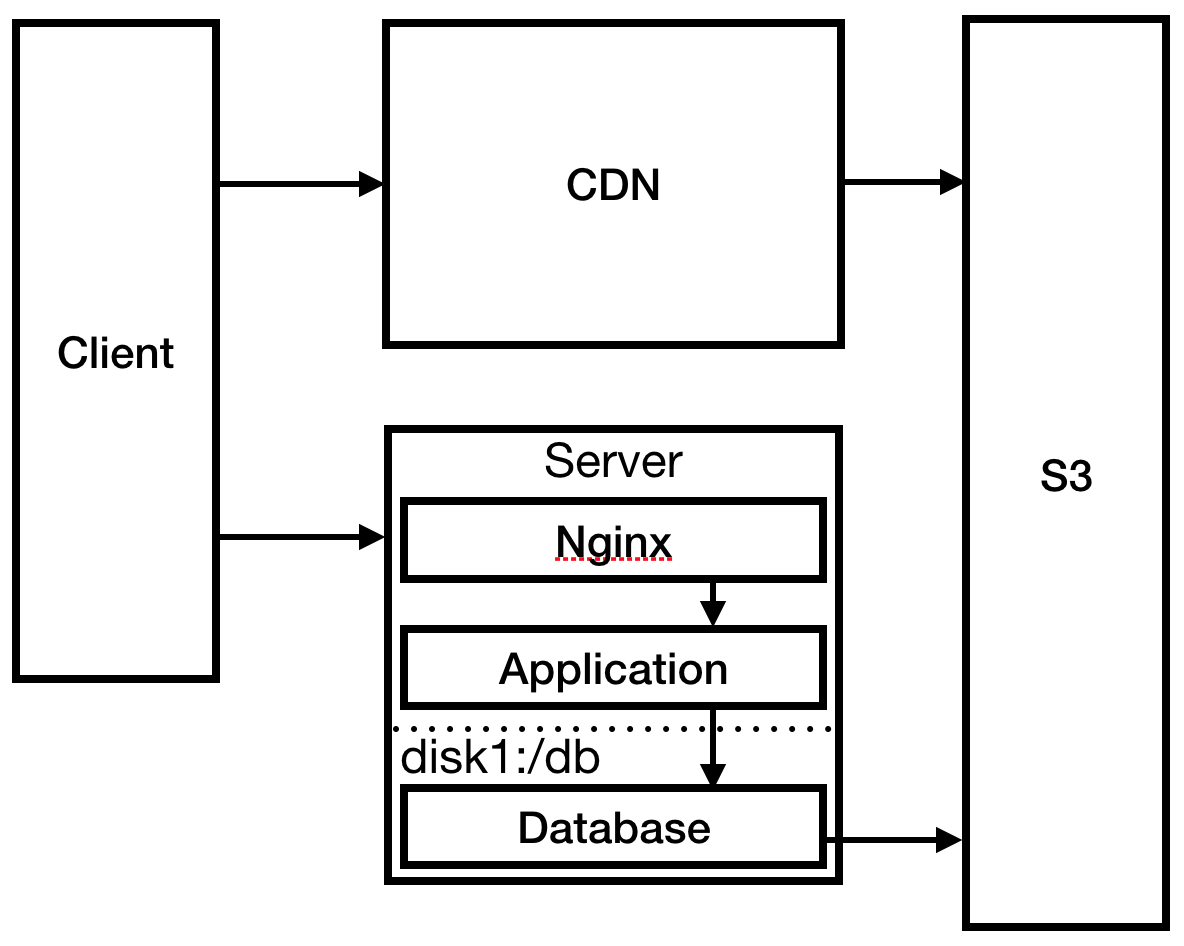 Fig. 3
Fig. 3Anda telah memecahkan masalah yang paling mendesak, buka server dan periksa log. Koneksi SSH Anda mengalami keterlambatan luar biasa. Setelah beberapa penelitian, Anda melihat bahwa file log telah sepenuhnya menggunakan ruang disk, yang menyebabkan proses macet dan mencegahnya restart. Buat disk yang jauh lebih besar dan pasang log di sana. Konfigurasikan
logrotate agar file log tidak lagi tumbuh dengan ukuran seperti itu.
Masalah kinerja
Bulan berlalu. Penonton bertambah. Situs mulai melambat. Anda perhatikan dalam pemantauan CloudWatch bahwa ini hanya terjadi antara 00:00 dan 12:00 UTC. Karena waktu jeda mulai dan akhir yang sama, Anda menyadari bahwa ini adalah karena tugas yang dijadwalkan pada server. Periksa crontab dan sadari bahwa satu pekerjaan dijadwalkan untuk tengah malam: cadangan. Tentu saja, pencadangan membutuhkan waktu dua belas jam dan menyebabkan kelebihan database, menyebabkan pelambatan yang signifikan di situs.
Anda membaca tentang ini sebelumnya - dan memutuskan untuk menjalankan backup dalam database slave. Kemudian ingat: Anda tidak memiliki database bawahan, jadi Anda harus membuatnya. Tidak masuk akal untuk menjalankan database budak di server yang sama, jadi Anda memutuskan untuk memperluas. Buat dua server baru: satu untuk database master dan satu untuk database slave. Ubah cadangan untuk bekerja dengan basis data bawahan.
 Fig. 4
Fig. 4Pertumbuhan tim
Untuk sementara, semuanya berjalan lancar. Bulan berlalu. Anda merekrut pengembang. Salah satu pendatang baru memperkenalkan bug yang menurunkan server produksi. Pengembang menyalahkan lingkungan pengembangan, yang berbeda dari produksi. Ada beberapa kebenaran dalam kata-katanya. Karena Anda adalah orang yang rasional dengan karakter yang baik, Anda menganggap peristiwa ini sebagai pelajaran.
Saatnya menciptakan lingkungan tambahan: pementasan, QA, dan produksi. Untungnya, sejak hari pertama Anda mengotomatiskan pembuatan infrastruktur, sehingga semuanya berjalan lancar dan sederhana. Anda juga telah menetapkan praktik pengiriman berkelanjutan yang baik sejak hari pertama, sehingga Anda dapat dengan mudah mengumpulkan konveyor dari cabang baru.
Departemen pemasaran mendorong untuk versi 2.0. Anda tidak begitu mengerti apa arti 2.0, tetapi Anda setuju. Sudah waktunya untuk mempersiapkan lonjakan lalu lintas berikutnya. Anda sudah mendekati puncak pada server saat ini, jadi sudah waktunya untuk menyeimbangkan beban. Amazon ELB membuat ini mudah. Sekitar waktu ini, Anda memperhatikan bahwa diagram berlapis dalam artikel ini harus menunjukkan lapisan dari atas ke bawah, dan bukan dari kiri ke kanan.
 Fig. 5
Fig. 5Yakin bahwa Anda akan mengatasi beban, Anda lagi menyebutkan situs Anda di Habré. Oh keajaiban, itu bisa menahan lalu lintas. Sukses besar!
Segalanya tampak berjalan baik sampai Anda pergi untuk memeriksa log. Butuh waktu satu jam untuk menguji 12 server (empat server di setiap lingkungan). Kerumitan yang nyata. Untungnya, ada cukup uang untuk membeli tumpukan ELK (ElasticSearch, LogStash, Kibana). Anda menyebarkannya dan mengarahkan server di sana dari semua lingkungan.
 Fig. 6
Fig. 6Sekarang, Anda dapat kembali ke log, Anda melihatnya - dan melihat sesuatu yang aneh. Mereka penuh dengan entri seperti itu:
GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1 GET /wp-login.php HTTP/1.1" 404 169 "-" "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1
Anda tidak menggunakan PHP atau WordPress, jadi ini agak aneh. Anda melihat entri mencurigakan serupa dalam log dari server database dan bertanya-tanya bagaimana mereka bahkan terhubung ke Internet. Saatnya untuk mengimplementasikan subnet publik dan pribadi.
 Fig. 7
Fig. 7Periksa kembali log. Upaya peretasan tetap ada, tetapi sekarang mereka terbatas pada port 80 pada load balancer, yang sedikit menghibur, karena server aplikasi, server basis data, dan tumpukan ELK tidak lagi berada dalam domain publik.
Meskipun log terpusat, Anda lelah mencari downtime, memeriksa log secara manual. Melalui Amazon CloudWatch, Anda mengatur peringatan email saat drive, CPU, dan jaringan mencapai utilisasi 80%. Hebat!
Operasi lancar
Hanya bercanda! Tidak ada yang namanya kelancaran dalam perangkat lunak. Sesuatu pasti akan rusak. Untungnya, Anda sekarang memiliki banyak alat untuk menangani situasi ini.
Kami membuat aplikasi web yang dapat diskalakan dengan cadangan, kembalikan (menggunakan penyebaran biru / hijau antara produksi dan tahap perantara), log terpusat, pemantauan dan pemberitahuan. Penskalaan lebih lanjut, sebagai suatu peraturan, tergantung pada kebutuhan spesifik aplikasi.
Ada banyak opsi hosting di pasar yang mengambil sebagian besar tugas yang disebutkan. Alih-alih mengembangkan sendiri, Anda dapat mengandalkan Beanstalk, AppEngine, GKE, ECS, dll. Sebagian besar layanan ini secara otomatis mengkonfigurasi izin yang masuk akal, subsistem penyeimbangan beban, subnet, dll. Ini menghilangkan sebagian besar kerumitan saat menjalankan aplikasi web dengan cepat dan backend andal yang bekerja untuk waktu yang lama.
Meskipun demikian, saya merasa berguna untuk memahami fungsionalitas apa yang disediakan oleh masing-masing platform ini dan mengapa mereka menyediakannya. Ini membuatnya mudah untuk memilih platform berdasarkan kebutuhan Anda sendiri. Dengan hosting aplikasi pada platform semacam itu, Anda sudah tahu cara kerja modul-modul ini. Ketika terjadi kesalahan, penting untuk mengetahui alat untuk menyelesaikan masalah.
Kesimpulan
Artikel ini menghilangkan banyak detail. Itu tidak menjelaskan bagaimana mengotomatiskan penciptaan infrastruktur, bagaimana mempersiapkan dan mengkonfigurasi server. Itu tidak mencakup penciptaan lingkungan pengembangan, pengaturan pipa pengiriman kontinu, dan penggelaran dan penggulingan kembali. Kami tidak membahas keamanan jaringan, berbagi kunci, dan prinsip hak minimum. Mereka tidak berbicara tentang pentingnya infrastruktur yang tidak dapat diubah, server tanpa status dan migrasi. Setiap topik membutuhkan artikel terpisah.
Tujuan dari posting ini adalah gambaran umum tentang seperti apa tampilan aplikasi web yang wajar dalam produksi. Artikel yang akan datang dapat terhubung di sini dan memperluas topiknya.
Itu saja untuk saat ini.
Terima kasih telah membaca dan coding yang baik!
Catatan: jangan benar-benar mengambil urutan dari artikel ilustratif ini. Secara terpisah, semua peristiwa ini benar-benar terjadi pada saya, tetapi pada waktu yang berbeda, di lingkungan yang sama sekali berbeda dan pada tugas yang berbeda.