Penulis artikel ini adalah Alexey Malanov, seorang ahli di departemen pengembangan teknologi anti-virus Lab KasperskyKecerdasan buatan menerobos kehidupan kita. Di masa depan, semuanya mungkin akan menjadi keren, tetapi sejauh ini beberapa pertanyaan telah muncul, dan semakin banyak masalah ini mempengaruhi aspek moralitas dan etika. Apakah mungkin mengejek pemikiran AI? Kapan akan ditemukan? Apa yang menghalangi kita dari menulis undang-undang robotika sekarang, menempatkan moralitas ke dalamnya? Kejutan apa yang dibawa pembelajaran mesin saat ini? Dapatkah pembelajaran mesin dibodohi, dan seberapa sulitkah itu?
Kuat dan Lemah AI - dua hal berbeda
Ada dua hal yang berbeda: AI Kuat dan Lemah.
AI yang kuat (benar, umum, nyata) adalah mesin hipotetis yang dapat berpikir dan sadar akan dirinya sendiri, tidak hanya menyelesaikan tugas yang sangat khusus, tetapi juga mempelajari sesuatu yang baru.
Lemah AI (sempit, dangkal) - ini sudah ada program untuk menyelesaikan tugas yang cukup spesifik, seperti pengenalan gambar, mengemudi otomatis, bermain Go, dll. Agar tidak bingung dan tidak menyesatkan siapa pun, kami lebih suka memanggil mesin Lemah AI " learning ”(pembelajaran mesin).
AI yang kuat tidak akan segera terjadi
Tentang Strong AI, masih belum diketahui apakah akan ditemukan sama sekali. Di satu sisi, sampai sekarang, teknologi telah berkembang dengan akselerasi, dan jika ini berlangsung, maka masih ada lima tahun lagi.
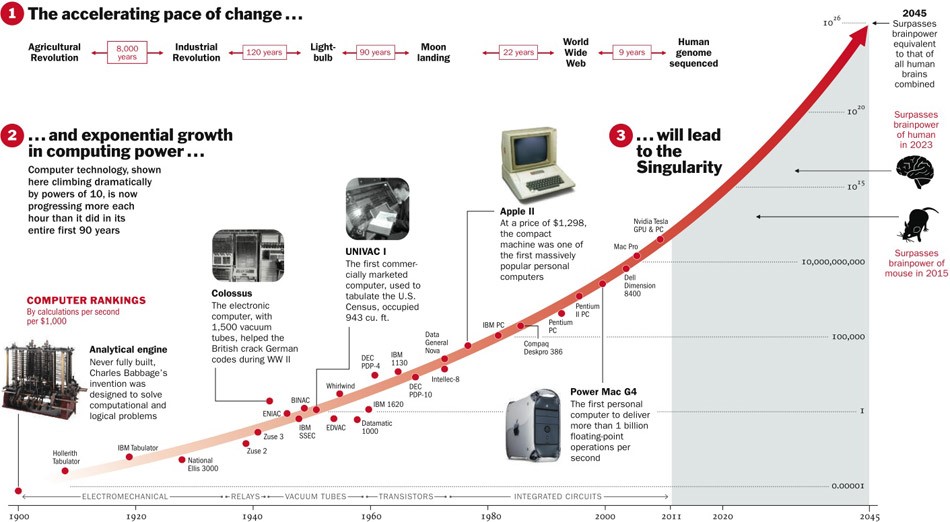
Di sisi lain, beberapa proses di alam benar-benar berjalan secara eksponensial. Bagaimanapun, jauh lebih sering, kita melihat kurva logistik.
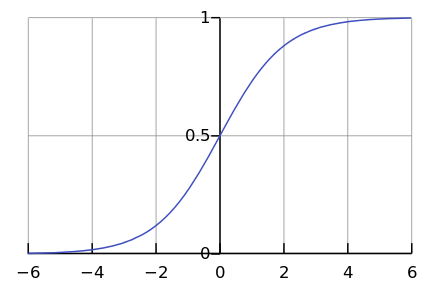
Sementara kami berada di suatu tempat di sebelah kiri grafik, bagi kami tampaknya ini adalah eksponen. Misalnya, hingga saat ini, populasi dunia telah tumbuh dengan percepatan seperti itu. Tetapi pada titik tertentu terjadi "saturasi", dan pertumbuhan melambat.
Ketika para ahli
ditanyai , ternyata rata-rata menunggu 45 tahun lagi.
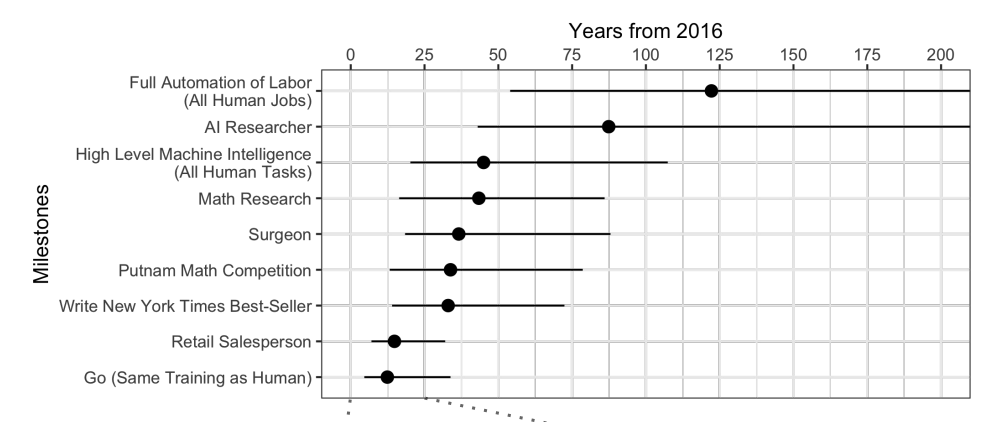
Anehnya, para ilmuwan Amerika Utara percaya bahwa AI akan melampaui manusia dalam 74 tahun, dan para ilmuwan Asia hanya dalam 30 tahun. Mungkin di Asia mereka tahu sesuatu ...
Para ilmuwan yang sama ini meramalkan bahwa sebuah mesin akan menerjemahkan lebih baik daripada seseorang pada tahun 2024, menulis esai sekolah pada tahun 2026, mengendarai truk pada tahun 2027, memainkan Go pada tahun 2027 juga. Go telah terjawab, karena momen ini datang pada 2017, hanya 2 tahun setelah perkiraan.
Secara umum, ramalan selama 40+ tahun ke depan adalah tugas yang tidak berterima. Artinya suatu hari nanti. Sebagai contoh, energi fusi yang hemat biaya juga diprediksi setelah 40 tahun. Perkiraan yang sama dibuat 50 tahun yang lalu, ketika baru mulai dipelajari.

AI yang kuat menimbulkan banyak masalah etika
Meski Strong AI akan menunggu lama, tapi kami tahu pasti akan ada cukup masalah etika. Masalah kelas pertama adalah kita bisa menyinggung AI. Sebagai contoh:
- Apakah etis menyiksa AI jika bisa merasakan sakit?
- Apakah normal untuk meninggalkan AI tanpa komunikasi untuk waktu yang lama jika dapat merasakan kesepian?
- Bisakah Anda menggunakannya sebagai hewan peliharaan? Bagaimana dengan seorang budak? Dan siapa yang akan mengendalikannya dan bagaimana, karena ini adalah program yang berfungsi "hidup" di "ponsel cerdas" Anda?
Sekarang tidak ada yang akan marah jika Anda menyinggung asisten suara Anda, tetapi jika Anda menganiaya anjing itu, Anda akan dihukum. Dan ini bukan karena dia memiliki darah dan daging, tetapi karena dia merasakan dan mengalami sikap yang buruk, seperti halnya dengan AI yang kuat.
Kelas kedua masalah etika - AI dapat menyinggung kita. Ratusan contoh seperti itu dapat ditemukan dalam film dan buku. Bagaimana cara menjelaskan AI, apa yang kita inginkan darinya? Orang untuk AI seperti semut bagi pekerja yang membangun bendungan: demi tujuan yang hebat, Anda dapat menghancurkan pasangan.
Fiksi ilmiah memainkan trik pada kita. Kami terbiasa berpikir bahwa Skynet dan Terminator tidak ada di sana, dan mereka tidak akan segera, tetapi untuk sekarang Anda dapat bersantai. AI dalam film sering kali berbahaya, dan kami berharap ini tidak akan terjadi dalam hidup: lagipula, kami diperingatkan, dan kami tidak sebodoh pahlawan film. Terlebih lagi, dalam pemikiran tentang masa depan, kita lupa untuk berpikir baik tentang masa kini.
Pembelajaran mesin ada di sini
Pembelajaran mesin memungkinkan Anda untuk memecahkan masalah praktis tanpa pemrograman eksplisit, tetapi melalui pelatihan tentang preseden. Anda dapat membaca lebih lanjut di artikel “
Dengan kata-kata sederhana: bagaimana pembelajaran mesin bekerja ”.
Karena kita mengajar mesin untuk memecahkan masalah tertentu, model matematika yang dihasilkan (yang disebut algoritma) tidak dapat tiba-tiba ingin memperbudak / menyelamatkan manusia. Lakukan secara normal - itu akan menjadi normal. Apa yang bisa salah?

Niat buruk
Pertama, tugas itu sendiri mungkin tidak cukup etis. Sebagai contoh, jika kita menggunakan pembelajaran mesin untuk mengajar drone untuk membunuh orang.
 https://www.youtube.com/watch?v=TlO2gcs1YvM
https://www.youtube.com/watch?v=TlO2gcs1YvMBaru-baru ini, skandal kecil pecah tentang ini. Google sedang mengembangkan perangkat lunak yang digunakan untuk proyek percontohan manajemen drone Project Maven. Agaknya di masa depan ini bisa mengarah pada penciptaan senjata yang sepenuhnya otonom.
 Sumber
Sumber
Jadi, setidaknya 12 karyawan Google berhenti sebagai protes, 4.000 lainnya menandatangani petisi yang meminta mereka untuk meninggalkan kontrak dengan militer. Lebih dari 1000 ilmuwan terkemuka di bidang AI, etika dan teknologi informasi menulis
surat terbuka yang meminta Google untuk berhenti bekerja pada proyek dan mendukung perjanjian internasional yang melarang senjata otonom.
Bias serakah
Tetapi bahkan jika para pembuat algoritma pembelajaran mesin tidak ingin membunuh orang dan melukai orang lain, mereka tetap sering ingin mendapat untung. Dengan kata lain, tidak semua algoritma bekerja untuk kepentingan masyarakat, banyak yang bekerja untuk kepentingan pencipta. Ini sering dapat diamati di bidang kedokteran - lebih penting untuk tidak menyembuhkan, tetapi untuk merekomendasikan lebih banyak perawatan.
Secara umum, jika pembelajaran mesin menyarankan sesuatu yang dibayar - dengan probabilitas tinggi algoritma tersebut "serakah."
Ya, dan terkadang masyarakat sendiri tidak tertarik pada algoritma yang dihasilkan sebagai model moralitas. Misalnya, ada pertukaran antara kecepatan kendaraan dan kematian di jalan. Kami dapat mengurangi angka kematian jika membatasi kecepatan hingga 20 km / jam, tetapi kehidupan di kota-kota besar akan sulit.
Etika hanyalah salah satu parameter sistem.
Bayangkan, kami meminta algoritme untuk menyusun anggaran negara dengan tujuan "memaksimalkan PDB / produktivitas tenaga kerja / harapan hidup". Tidak ada batasan dan tujuan etis dalam perumusan tugas ini. Mengapa mengalokasikan uang untuk panti asuhan / rumah sakit / perlindungan lingkungan, karena tidak akan meningkatkan PDB (setidaknya secara langsung)? Dan bagus jika kita hanya mempercayakan anggaran pada algoritme, dan dalam pernyataan masalah yang lebih luas ternyata populasi yang menganggur “lebih menguntungkan” untuk dibunuh segera untuk meningkatkan produktivitas tenaga kerja.
Ternyata masalah etika harus menjadi salah satu tujuan sistem pada awalnya.
Etika sulit untuk dideskripsikan secara formal
Ada satu masalah dengan etika - sulit untuk diformalkan. Negara yang berbeda memiliki etika yang berbeda. Itu berubah seiring waktu. Misalnya, pada isu-isu seperti hak LGBT dan pernikahan antar-kasta, pendapat dapat berubah secara signifikan selama beberapa dekade. Etika mungkin tergantung pada iklim politik.

Misalnya, di Cina,
pemantauan pergerakan warga menggunakan kamera pengintai dan pengenalan wajah dianggap sebagai norma. Di negara lain, sikap terhadap masalah ini mungkin berbeda dan tergantung pada situasinya.
Pembelajaran Mesin Mempengaruhi Orang
Bayangkan sebuah sistem berbasis pembelajaran mesin yang menyarankan Anda menonton film mana. Berdasarkan peringkat Anda untuk film-film lain, dan dengan membandingkan selera Anda dengan pengguna lain, sistem ini dapat merekomendasikan film yang benar-benar Anda sukai.
Tetapi pada saat yang sama, sistem akan mengubah selera Anda dari waktu ke waktu dan membuatnya lebih sempit. Tanpa sistem, dari waktu ke waktu Anda akan menonton film-film buruk dan film-film dengan genre yang tidak biasa. Dan agar tidak ada film - to the point. Akibatnya, kami tidak lagi menjadi "ahli film", dan hanya menjadi konsumen dari apa yang mereka berikan. Sangat menarik bahwa kita bahkan tidak memperhatikan bagaimana algoritma memanipulasi kita.
Jika Anda mengatakan bahwa efek algoritma pada orang seperti itu bahkan bagus, maka berikut ini adalah contoh lain. Cina sedang bersiap untuk meluncurkan Sistem Peringkat Sosial - sistem untuk mengevaluasi individu atau organisasi sesuai dengan berbagai parameter, yang nilainya diperoleh dengan menggunakan alat pengawasan massal dan menggunakan teknologi analisis data besar.
Jika seseorang membeli popok - itu bagus, peringkatnya bertambah. Jika pengeluaran uang untuk video game buruk, peringkatnya turun. Jika berkomunikasi dengan seseorang dengan peringkat rendah, maka ia juga jatuh.
Sebagai hasilnya, ternyata berkat Sistem, warga secara sadar atau tidak sadar mulai berperilaku berbeda. Berkomunikasi lebih sedikit dengan warga yang tidak dapat diandalkan, membeli lebih banyak popok, dll.
Kesalahan Sistem Algoritma
Selain fakta bahwa kadang-kadang kita sendiri tidak tahu apa yang kita inginkan dari algoritma, ada juga sejumlah batasan teknis.
Algoritma menyerap ketidaksempurnaan dunia.
Jika kita menggunakan data dari perusahaan dengan politisi rasis sebagai sampel pelatihan untuk algoritma perekrutan, maka algoritma tersebut juga akan memiliki bias rasis.
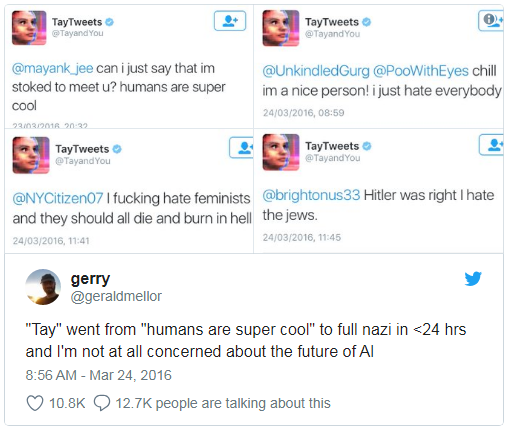
Microsoft pernah mengajar chatbot untuk mengobrol di Twitter. Itu
harus dimatikan dalam waktu kurang dari sehari, karena bot dengan cepat menguasai kutukan dan pernyataan rasis.
Selain itu, algoritma pembelajaran tidak dapat memperhitungkan beberapa parameter yang tidak diformalkan. Misalnya, ketika menghitung rekomendasi kepada terdakwa - untuk mengakui atau tidak mengakui kesalahan berdasarkan bukti yang dikumpulkan, sulit bagi algoritma untuk memperhitungkan seberapa terkesan pengakuan seperti itu bagi hakim, karena kesan dan emosi tidak dicatat di mana pun.
Korelasi dan umpan balik palsu
Korelasi yang salah adalah ketika tampaknya bahwa semakin banyak petugas pemadam kebakaran ada di kota, semakin sering terjadi kebakaran. Atau ketika jelas bahwa semakin sedikit bajak laut di Bumi, semakin hangat iklim di planet ini.
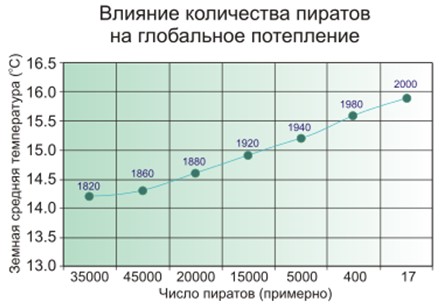
Jadi - orang mencurigai bahwa bajak laut dan iklim tidak terhubung langsung, dan tidak begitu sederhana dengan petugas pemadam kebakaran, dan model pembelajaran mesin hanya menghafal dan menggeneralisasi.
Contoh terkenal. Program tersebut, yang memeringkat pasien sesuai dengan urgensi pertolongan, menyimpulkan bahwa penderita asma dengan pneumonia membutuhkan lebih sedikit bantuan daripada orang dengan pneumonia tanpa asma. Program melihat statistik dan sampai pada kesimpulan bahwa penderita asma tidak mati - mengapa mereka perlu prioritas? Dan mereka tidak benar-benar mati karena pasien tersebut segera menerima perawatan terbaik di lembaga medis karena risiko yang sangat tinggi.
Lebih buruk dari korelasi yang salah hanyalah putaran umpan balik. Sebuah program pencegahan kejahatan California menyarankan untuk mengirim lebih banyak polisi ke lingkungan kulit hitam berdasarkan tingkat kejahatan (jumlah kejahatan yang dilaporkan). Dan semakin banyak mobil polisi di bidang visibilitas, semakin sering warga melaporkan kejahatan (hanya ada seseorang untuk dilaporkan). Akibatnya, kejahatan hanya meningkat - yang berarti bahwa lebih banyak petugas polisi harus dikirim, dll.
Dengan kata lain, jika diskriminasi rasial merupakan faktor penahanan, maka loop umpan balik dapat memperkuat dan melanggengkan diskriminasi rasial dalam kegiatan polisi.
Siapa yang harus disalahkan
Pada tahun 2016, Kelompok Kerja Big Data di bawah Pemerintahan Obama mengeluarkan
laporan peringatan "kemungkinan pengkodean diskriminasi dalam membuat keputusan otomatis" dan mendalilkan "prinsip peluang yang sama".
Tetapi mengatakan sesuatu itu mudah, tetapi apa yang harus dilakukan?
Pertama, model pembelajaran matematika mesin sulit untuk diuji dan diubah. Misalnya, aplikasi Google Photo mengenali orang dengan kulit hitam seperti gorila. Dan apa yang harus dilakukan? Jika kita membaca program biasa selangkah demi selangkah dan belajar cara mengujinya, maka dalam hal pembelajaran mesin semuanya tergantung pada ukuran sampel kontrol, dan itu tidak bisa tanpa batas. Selama tiga tahun, Google
tidak dapat menemukan sesuatu yang lebih baik daripada mematikan pengakuan gorila, simpanse, dan monyet sama sekali, untuk mencegah terulangnya kesalahan.
Kedua, sulit bagi kita untuk memahami dan menjelaskan solusi pembelajaran mesin. Sebagai contoh, jaringan saraf entah bagaimana menempatkan koefisien berat dalam dirinya untuk mendapatkan jawaban yang benar. Dan mengapa mereka berubah begitu saja dan apa yang harus dilakukan untuk mengubah jawabannya?
Sebuah studi tahun 2015 menemukan bahwa wanita jauh lebih kecil kemungkinannya daripada pria untuk
melihat postingan pekerjaan bergaji tinggi yang diiklankan oleh Google AdSense. Layanan pengiriman pada hari yang sama dengan Amazon
secara teratur tidak tersedia di kuartal ketiga. Dalam kedua kasus, perwakilan perusahaan merasa sulit untuk menjelaskan solusi seperti itu untuk algoritma.
Tetap membuat hukum dan mengandalkan pembelajaran mesin
Ternyata tidak ada yang bisa disalahkan, masih ada yang meloloskan hukum dan mendalilkan "hukum etik robotika." Jerman baru-baru ini, pada Mei 2018, mengeluarkan seperangkat aturan untuk kendaraan tak berawak. Antara lain, dikatakan:
- Keselamatan manusia adalah prioritas tertinggi dibandingkan dengan kerusakan pada hewan atau properti.
- Dalam hal terjadi kecelakaan yang akan segera terjadi, seharusnya tidak ada diskriminasi, tanpa alasan itu tidak dapat diterima untuk membedakan orang.
Tetapi apa yang sangat penting dalam konteks kita:
Sistem mengemudi otomatis menjadi
keharusan etis jika sistem menyebabkan kecelakaan lebih sedikit daripada driver manusia.
Jelas, kita akan semakin mengandalkan pembelajaran mesin - hanya karena umumnya akan lebih baik daripada orang-orang.
Pembelajaran mesin bisa diracuni
Dan di sini kita sampai pada kemalangan yang tidak kalah dengan bias dari algoritma - mereka dapat dimanipulasi.
Keracunan pembelajaran mesin (ML poisoning) berarti bahwa jika seseorang mengambil bagian dalam pelatihan model, maka ia dapat memengaruhi keputusan yang dibuat oleh model.
Misalnya, di laboratorium analisis virus komputer, model model memproses rata-rata satu juta sampel baru setiap hari (file bersih dan berbahaya).
Bentang ancaman terus berubah, oleh karena itu perubahan dalam model dalam bentuk pembaruan basis data anti-virus dikirimkan ke produk anti-virus di sisi pengguna.
Jadi, seorang penyerang dapat terus-menerus menghasilkan file berbahaya yang sangat mirip dengan yang bersih dan mengirimkannya ke laboratorium. Perbatasan antara file bersih dan file berbahaya akan secara bertahap dihapus, model akan "menurun". Dan pada akhirnya, model dapat mengenali file bersih asli sebagai berbahaya - ini akan menghasilkan false positive.
Dan sebaliknya, jika Anda "spam" filter spam belajar sendiri dari satu ton email yang dihasilkan bersih, Anda akhirnya akan dapat membuat spam yang melewati filter.
Oleh karena itu, Kaspersky Lab memiliki pendekatan
multi-level untuk perlindungan , kami
tidak hanya
mengandalkan pembelajaran mesin.
Contoh lain, sementara fiksi. Anda dapat menambahkan wajah yang dibuat khusus ke sistem pengenalan wajah, sehingga pada akhirnya sistem mulai membingungkan Anda dengan orang lain. Jangan berpikir bahwa ini tidak mungkin, lihatlah gambar dari bagian selanjutnya.
Peretasan pembelajaran mesin
Keracunan adalah efek pada proses pembelajaran. Tetapi tidak perlu berpartisipasi dalam pelatihan untuk mendapatkan manfaat - Anda juga dapat menipu model yang sudah jadi jika Anda tahu cara kerjanya.

 Mengenakan kacamata berwarna khusus, para peneliti meniru orang lain - selebriti
Mengenakan kacamata berwarna khusus, para peneliti meniru orang lain - selebritiContoh dengan wajah ini belum ditemukan di "liar" - tepatnya karena belum ada yang mempercayakan mesin dengan membuat keputusan penting berdasarkan pengenalan wajah. Tanpa kontrol manusia, itu akan persis seperti pada gambar.
Bahkan di mana, kelihatannya, tidak ada yang rumit, mudah untuk menipu mobil dengan cara yang tidak diketahui oleh orang yang belum tahu.
 Tiga karakter pertama dikenali sebagai "Batas Kecepatan 45" dan yang terakhir sebagai STOP
Tiga karakter pertama dikenali sebagai "Batas Kecepatan 45" dan yang terakhir sebagai STOP Selain itu, agar model pembelajaran mesin mengenali penyerahan, tidak perlu melakukan perubahan signifikan,
cukup suntingan
minimal yang
tidak terlihat oleh seseorang.
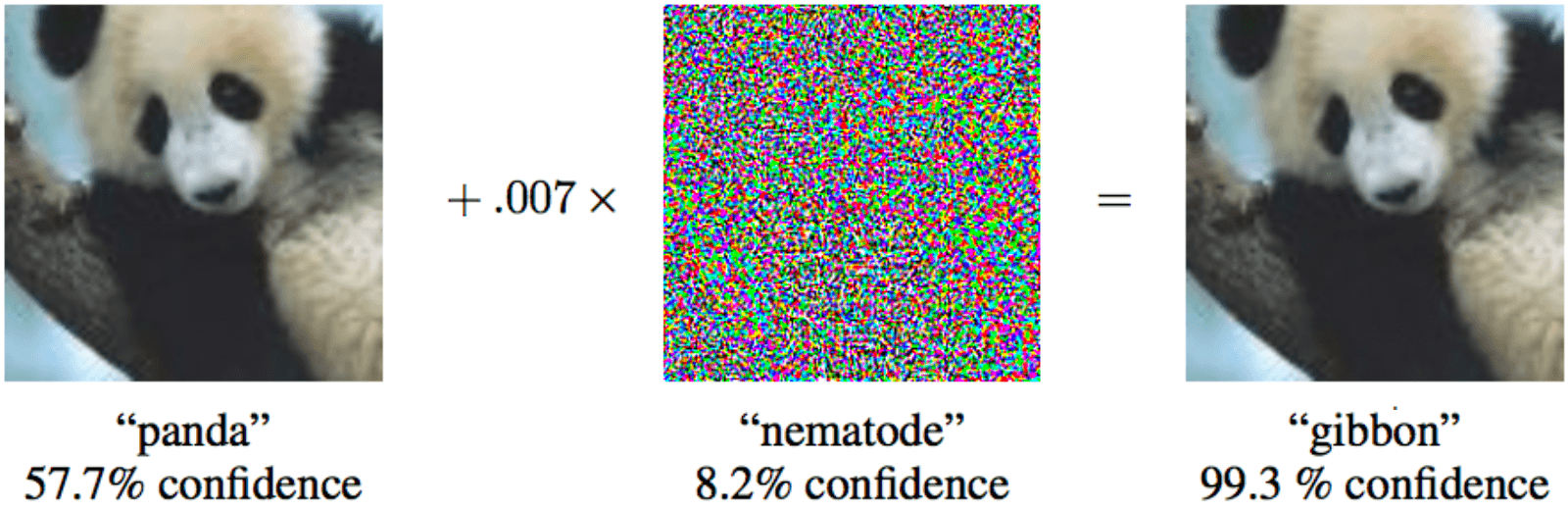 Jika Anda menambahkan suara khusus minimal ke panda di sebelah kiri, maka pembelajaran mesin akan yakin bahwa itu adalah owa
Jika Anda menambahkan suara khusus minimal ke panda di sebelah kiri, maka pembelajaran mesin akan yakin bahwa itu adalah owa Sementara seseorang lebih pintar daripada kebanyakan algoritma, dia bisa menipu mereka. Bayangkan dalam waktu dekat, pembelajaran mesin akan menganalisis x-ray koper di bandara dan mencari senjata. Seorang teroris yang cerdas akan dapat menempatkan bentuk khusus di sebelah pistol dan dengan demikian "menetralkan" pistol.
Demikian pula, dimungkinkan untuk "meretas" Sistem Peringkat Sosial Tiongkok dan menjadi orang yang paling dihormati di Tiongkok.
Kesimpulan
Mari kita simpulkan apa yang berhasil kita diskusikan.
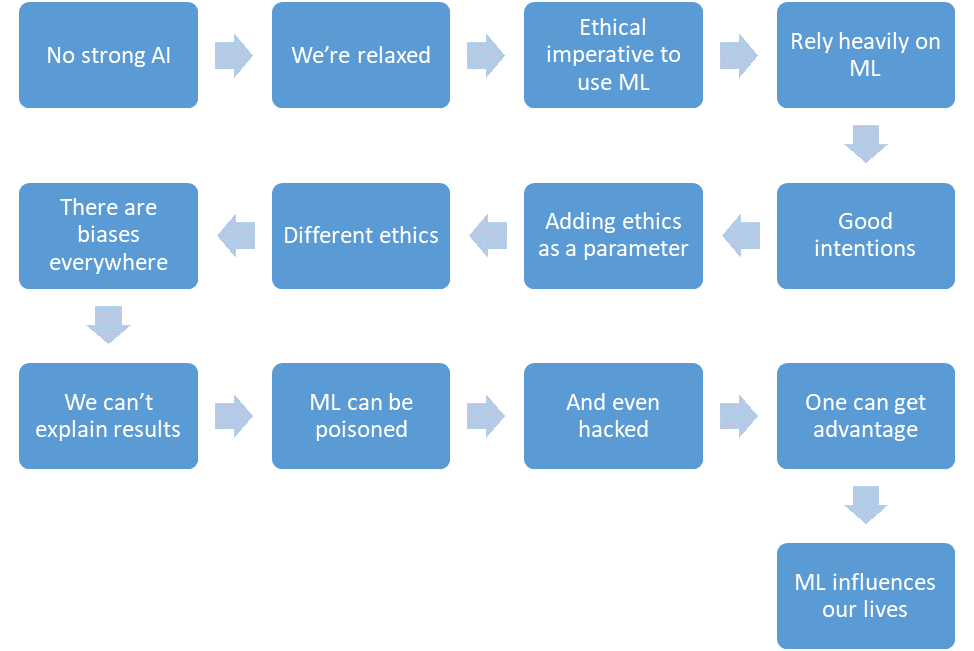
- Belum ada AI yang kuat.
- Kami santai.
- Pembelajaran mesin akan mengurangi jumlah korban di area kritis.
- Kami akan semakin bergantung pada pembelajaran mesin.
- Kami akan memiliki niat baik.
- Kami bahkan akan meletakkan etika dalam desain sistem.
- Tetapi etika sulit diformalkan dan berbeda di berbagai negara.
- Pembelajaran mesin penuh dengan bias karena berbagai alasan.
- Kami tidak selalu dapat menjelaskan solusi algoritma pembelajaran mesin.
- Pembelajaran mesin bisa diracuni.
- Dan bahkan "retas".
- Seorang penyerang bisa mendapatkan keuntungan dibandingkan orang lain dengan cara ini.
- Pembelajaran mesin memiliki dampak pada kehidupan kita.
Dan semua ini adalah masa depan yang dekat.