Baik untuk semua! Nah, waktunya telah tiba untuk
kursus Devops kami berikutnya. Mungkin, ini adalah salah satu kursus yang paling stabil dan referensi, tetapi pada saat yang sama paling beragam dalam hal siswa, karena tidak ada kelompok yang tampak seperti yang lain: di satu pengembang hampir sepenuhnya, kemudian di insinyur berikutnya, lalu admin, dan sebagainya. Dan ini juga berarti bahwa waktunya telah tiba untuk materi yang menarik dan bermanfaat, serta pertemuan online.

Artikel ini berisi rekomendasi untuk meluncurkan klaster Kubernetes tingkat produksi di pusat data di lokasi atau lokasi periferal (lokasi tepi).
Apa artinya tingkat produksi?
- Instalasi aman
- Manajemen penyebaran dilakukan menggunakan proses berulang dan direkam;
- Pekerjaan dapat diprediksi dan konsisten;
- Aman untuk melakukan pembaruan dan penyetelan;
- Untuk mendeteksi dan mendiagnosis kesalahan dan kekurangan sumber daya ada pencatatan dan pemantauan;
- Layanan ini memiliki "ketersediaan tinggi" yang memadai dengan mempertimbangkan sumber daya yang tersedia, termasuk pembatasan uang, ruang fisik, daya, dll.
- Proses pemulihan tersedia, didokumentasikan, dan diuji untuk digunakan jika terjadi kegagalan.
Singkatnya, tingkat produksi berarti mengantisipasi kesalahan dan mempersiapkan pemulihan dengan masalah dan penundaan minimal.

Artikel ini adalah tentang penyebaran Kubernetes di lokasi pada platform hypervisor atau bare-metal, mengingat jumlah sumber daya dukungan yang terbatas dibandingkan dengan peningkatan cloud publik utama. Namun demikian, beberapa rekomendasi ini mungkin berguna untuk cloud publik jika anggaran membatasi sumber daya yang dipilih.
Menerapkan logam telanjang logam tunggal-telanjang Minikube dapat menjadi proses yang sederhana dan murah, tetapi bukan tingkat produksi. Sebaliknya, Anda tidak akan dapat mencapai tingkat Google dengan Borg di toko offline, cabang, atau lokasi periferal, meskipun kecil kemungkinan Anda membutuhkannya.
Artikel ini menjelaskan kiat-kiat untuk mencapai penyebaran Kubernetes tingkat produksi, bahkan dalam situasi terbatas sumber daya.
Komponen penting dalam kluster KubernetesSebelum mempelajari detailnya, penting untuk memahami keseluruhan arsitektur Kubernet.
Cluster Kubernetes adalah sistem terdistribusi tinggi berdasarkan bidang kontrol dan arsitektur node pekerja yang terkelompok, seperti yang ditunjukkan di bawah ini:
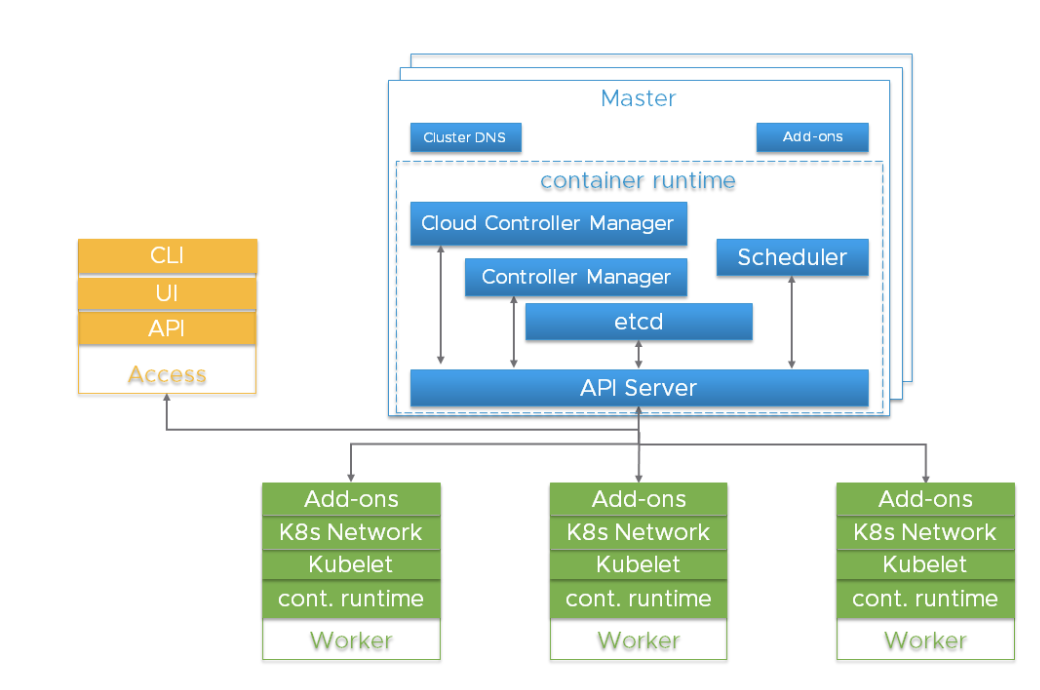
Biasanya, komponen dari Server API, Pengendali Manajer, dan Penjadwal terletak di beberapa contoh node tingkat kontrol (disebut Master). Master node biasanya juga menyertakan etcd, namun ada skrip besar dan sangat mudah diakses yang membutuhkan menjalankan etcd pada host independen. Komponen dapat dijalankan sebagai wadah dan, secara opsional, di bawah pengawasan Kubernetes, yaitu berfungsi sebagai perapian statis.
Contoh berlebihan dari komponen ini digunakan untuk ketersediaan tinggi. Signifikansi dan tingkat redundansi yang diperlukan dapat bervariasi.
| Komponen | Peran | Konsekuensi dari kehilangan | Contoh yang Direkomendasikan |
|---|
| dll | Mempertahankan status semua objek Kubernet | Kehilangan penyimpanan yang besar. Kehilangan sebagian besar = Kubernet kehilangan tingkat kontrol, API Server bergantung pada etcd, panggilan API hanya-baca yang tidak memerlukan kuorum, seperti beban kerja yang sudah dibuat, dapat terus bekerja. | angka ganjil, 3+ |
| Server API | Menyediakan API untuk penggunaan eksternal dan internal | Tidak dapat berhenti, mulai, perbarui pod baru. Penjadwal dan Pengontrol Manajer bergantung pada API Server. Beban berlanjut jika tidak tergantung pada panggilan API (operator, pengontrol khusus, CRD, dll.) | 2+ |
| kube-scheduler | Tempat pod pada node | Pod tidak dapat ditempatkan, diprioritaskan, atau dipindahkan di antaranya. | 2+ |
| kube-controller-manager | Mengontrol banyak pengontrol | Loop kontrol utama yang bertanggung jawab untuk negara berhenti bekerja. Integrasi in-tree dari penyedia cloud terputus. | 2+ |
| cloud-controller-manager (CCM) | Integrasi penyedia cloud di luar pohon | Integrasi penyedia cloud terputus | 1 |
| Tambahan (mis. DNS) | Berbeda | Berbeda | Tergantung pada add-on (mis. 2+ untuk DNS) |
Risiko dari komponen-komponen ini termasuk kegagalan perangkat keras, bug perangkat lunak, pembaruan yang buruk, kesalahan manusia, gangguan jaringan dan kelebihan sistem yang mengakibatkan sumber daya habis. Redundansi dapat mengurangi dampak bahaya ini. Selain itu, berkat fitur platform hypervisor (perencanaan sumber daya, ketersediaan tinggi), Anda dapat melipatgandakan hasilnya menggunakan sistem operasi Linux, Kubernetes dan runtime kontainer.
Server API menggunakan banyak instance penyeimbang beban untuk mencapai skalabilitas dan ketersediaan. Load balancer adalah komponen penting untuk ketersediaan tinggi. Beberapa catatan-A dari server DNS API dapat berfungsi sebagai alternatif jika tidak ada penyeimbang.
kube-scheduler dan kube-controller-manager terlibat dalam proses pemilihan pemimpin alih-alih menggunakan load balancer. Karena
cloud-controller-manager digunakan untuk beberapa jenis infrastruktur hosting, implementasinya mungkin beragam, kami tidak akan membahasnya - kami hanya mengindikasikan bahwa mereka adalah komponen dari tingkat manajemen.
Pod yang berjalan di Kubernet dikelola oleh agen kubelet. Setiap instance pekerja menjalankan agen kubelet dan lingkungan peluncuran wadah yang kompatibel dengan
CRI . Kubernetes sendiri dirancang untuk memantau dan memulihkan dari kegagalan simpul pekerja. Tetapi untuk fungsi beban kritis, manajemen sumber daya hypervisor, dan isolasi beban, ini dapat digunakan untuk meningkatkan aksesibilitas dan meningkatkan kemampuan prediksi pekerjaan mereka.
dlletcd adalah penyimpanan persisten untuk semua objek Kubernetes. Ketersediaan dan pemulihan gugus etcd harus menjadi prioritas utama ketika menggunakan Kubernet tingkat produksi.
Cluster etcd yang terdiri dari lima node adalah pilihan terbaik jika Anda mengizinkannya. Mengapa Karena Anda dapat melayani satu, dan pada saat yang sama menahan kegagalan. Sekelompok tiga node adalah minimum yang dapat kami rekomendasikan untuk layanan tingkat produksi, bahkan jika hanya satu host hypervisor yang tersedia. Lebih dari tujuh node juga tidak direkomendasikan, dengan pengecualian
instalasi sangat besar yang mencakup beberapa zona akses.
Rekomendasi minimum untuk hosting node cluster etcd adalah RAM 2GB dan hard drive SSD 8GB. Biasanya, 8GB RAM dan 20GB ruang hard disk sudah cukup. Kinerja disk memengaruhi waktu pemulihan suatu simpul setelah mengalami kegagalan.
Lihat detailnya.
Dalam kasus khusus, pikirkan beberapa cluster etcdUntuk kelompok Kubernet yang sangat besar, pertimbangkan untuk menggunakan cluster etcd terpisah untuk acara Kubernetes sehingga terlalu banyak peristiwa tidak memengaruhi layanan inti API Kubernetes. Saat menggunakan jaringan Flannel, konfigurasi disimpan dalam etcd, dan persyaratan versi mungkin berbeda dari Kubernetes. Ini dapat memperumit cadangan etcd, jadi kami sarankan untuk menggunakan cluster etcd terpisah khusus untuk kain flanel.
Penempatan Host TunggalDaftar risiko aksesibilitas mencakup perangkat keras, perangkat lunak, dan faktor manusia. Jika Anda terbatas pada satu host, menggunakan penyimpanan yang berlebihan, memori yang mengoreksi kesalahan, dan catu daya ganda dapat meningkatkan perlindungan terhadap kegagalan perangkat keras. Menjalankan hypervisor pada host fisik memungkinkan Anda untuk menggunakan komponen perangkat lunak yang berlebihan dan menambahkan manfaat operasional yang terkait dengan penggelaran, pembaruan, dan pemantauan penggunaan sumber daya. Bahkan dalam situasi yang penuh tekanan, perilaku tetap dapat diulang dan dapat diprediksi. Misalnya, bahkan jika Anda hanya dapat mengizinkan peluncuran singleton dari layanan master, mereka harus dilindungi dari kelebihan muatan dan penipisan sumber daya, bersaing dengan beban kerja aplikasi Anda. Hypervisor bisa lebih efisien dan lebih mudah digunakan daripada memprioritaskan dalam penjadwal Linux, cgroups, bendera Kubernetes, dll.
Anda dapat menggunakan tiga mesin virtual etcd jika sumber daya host mengizinkannya. Setiap VM harus didukung oleh perangkat penyimpanan fisik yang terpisah atau menggunakan bagian penyimpanan yang terpisah menggunakan redundansi (Mirroring, RAID, dll.).
Contoh ganda berlebih dari API server, penjadwal, dan manajer pengontrol adalah peningkatan berikutnya jika satu-satunya host Anda memiliki sumber daya yang cukup untuk ini.
Opsi penempatan host tunggal, dari yang paling tidak cocok untuk produksi hingga yang paling| Jenis | Karakteristik | Hasil |
|---|
| Peralatan minimum | Singleton, dll, dan komponen utama. | Laboratorium rumah, sama sekali bukan kelas produksi. Multiple Single Point of Failure (SPOF). Pemulihan lambat, dan ketika penyimpanan hilang, itu benar-benar tidak ada. |
| Peningkatan Penyimpanan Redundansi | komponen singleton dan master etcd, penyimpanan etcd berlebihan. | Minimal, Anda dapat pulih dari kegagalan perangkat penyimpanan. |
| Redundansi Tingkat Terkelola | Tidak ada hypervisor, beberapa contoh komponen tingkat terkelola di pod statis. | Perlindungan terhadap bug perangkat lunak telah muncul, tetapi OS dan lingkungan peluncuran wadah masih merupakan titik kegagalan yang sama dengan pembaruan yang menghancurkan. |
| Menambahkan Hypervisor | Menjalankan tiga instance tingkat dikelola yang berlebihan di VM. | Ada perlindungan terhadap bug perangkat lunak dan kesalahan manusia dan keunggulan operasional dalam instalasi, manajemen sumber daya, pemantauan dan keamanan. Pembaruan OS dan lingkungan peluncuran wadah tidak terlalu mengganggu. Hypervisor adalah satu-satunya titik kegagalan. |
Penerapan Host GandaDengan dua host, masalah penyimpanan etcd mirip dengan opsi host tunggal - Anda perlu redundansi. Lebih baik menjalankan tiga instance encd. Ini mungkin tampak tidak intuitif, tetapi lebih baik untuk memusatkan semua node etcd pada satu host. Anda tidak akan meningkatkan keandalan dengan membaginya dengan 2 + 1 antara dua host - hilangnya node dengan instance encd terbanyak akan menyebabkan kegagalan, terlepas dari apakah itu mayoritas 2 atau 3. Jika host tidak sama, tempatkan seluruh cluster etcd pada yang lebih dapat diandalkan.
Disarankan agar Anda menjalankan server API yang berlebihan, penjadwal-kube, dan pengelola-pengontrol-kubus. Mereka harus dibagi di antara host untuk meminimalkan risiko kegagalan dalam lingkungan peluncuran kontainer, sistem operasi, dan perangkat keras.
Meluncurkan lapisan hypervisor pada host fisik akan memungkinkan Anda untuk bekerja dengan komponen program yang berlebihan, menyediakan manajemen sumber daya. Ini juga memiliki keunggulan operasional pemeliharaan terjadwal.
Opsi penyebaran untuk dua host, dari yang paling tidak cocok untuk produksi hingga yang paling| Jenis | Karakteristik | Hasil |
|---|
| Peralatan minimum | Dua host, tanpa penyimpanan yang berlebihan. Singleton, dll, dan komponen utama pada host yang sama. | etcd - satu titik kegagalan, tidak masuk akal untuk menjalankan dua pada layanan master lainnya. Berbagi antara dua host meningkatkan risiko kegagalan lapisan terkelola. Manfaat potensial dari mengisolasi sumber daya dengan menjalankan lapisan terkelola pada satu host dan beban kerja aplikasi pada yang lain. Jika penyimpanan hilang, tidak ada pemulihan. |
| Peningkatan Penyimpanan Redundansi | Singleton etcd dan komponen master pada host yang sama, penyimpanan etcd berlebihan. | Minimal, Anda dapat pulih dari kegagalan perangkat penyimpanan. |
| Redundansi Tingkat Terkelola | Tidak ada hypervisor, beberapa contoh komponen tingkat terkelola di pod statis. etcd cluster pada satu host, komponen tingkat terkelola lainnya dipisahkan. | Kegagalan perangkat keras, memperbarui firmware, sistem operasi, dan lingkungan peluncuran wadah pada host tanpa etcd tidak begitu merusak. |
| Menambahkan hypervisor ke kedua host | Tiga komponen tingkat dikelola berlebih berjalan di mesin virtual, cluster dll pada satu host, dan komponen tingkat dikelola dipisahkan. Beban kerja aplikasi dapat berada di kedua node VM. | Peningkatan isolasi beban aplikasi. Pembaruan untuk sistem operasi dan lingkungan peluncuran wadah tidak terlalu mengganggu. Pemeliharaan terjadwal perangkat keras / firmware menjadi non-destruktif jika hypervisor mendukung migrasi VM. |
Penempatan ke tiga (atau lebih) hostTransisi ke layanan tingkat produksi tanpa kompromi. Kami merekomendasikan pemisahan etcd antara tiga host. Satu kegagalan perangkat keras akan mengurangi jumlah kemungkinan beban kerja aplikasi, tetapi tidak akan menghasilkan penghentian layanan yang lengkap.
Cluster yang sangat besar akan membutuhkan lebih banyak instance.
Meluncurkan lapisan hypervisor memberikan manfaat operasional dan peningkatan isolasi beban kerja aplikasi. Ini di luar ruang lingkup artikel, tetapi pada level tiga atau lebih penghuni, fungsi yang lebih baik mungkin tersedia (penyimpanan bersama yang berkelompok, pengelolaan sumber daya dengan penyeimbang beban dinamis, pemantauan keadaan otomatis dengan migrasi langsung dan failover).
Opsi penempatan untuk tiga (atau lebih) host dari yang paling tidak cocok untuk produksi hingga yang paling| Jenis | Karakteristik | Hasil |
|---|
| Minimum | Tiga host. Instance etcd pada setiap node. Komponen master pada setiap node. | Kehilangan node mengurangi kinerja, tetapi tidak menyebabkan penurunan Kubernetes. Kemungkinan pemulihan tetap ada. |
| Menambahkan hypervisor ke host | Di mesin virtual pada tiga host, dll, server API, penjadwal, dan manajer pengontrol sedang berjalan. Beban kerja berjalan di VM di setiap host. | Menambahkan perlindungan terhadap bug OS / wadah / lingkungan peluncuran perangkat lunak dan kesalahan manusia. Manfaat operasional instalasi, peningkatan, pengelolaan sumber daya, pemantauan, dan keamanan. |
Konfigurasikan KubernetNode Master dan Pekerja harus dilindungi dari kelebihan dan penipisan sumber daya. Fungsi hypervisor dapat digunakan untuk mengisolasi komponen penting dan cadangan sumber daya. Ada juga pengaturan konfigurasi Kubernetes yang dapat memperlambat hal-hal seperti kecepatan panggilan API. Beberapa kit instalasi dan distribusi komersial menangani hal ini, tetapi jika Anda menggunakan Kubernetes sendiri, pengaturan default mungkin tidak cocok, terutama untuk sumber daya kecil atau untuk kluster yang terlalu besar.
Konsumsi sumber daya pada tingkat yang dapat dikelola berkorelasi dengan jumlah perapian dan laju keluarnya perapian. Cluster yang sangat besar dan sangat kecil akan mendapat manfaat dari permintaan kube-apiserver yang dimodifikasi dan
pengaturan penurunan memori.
Node Allocatable harus dikonfigurasi pada
node pekerja berdasarkan kepadatan beban yang didukung yang wajar untuk setiap node. Ruang nama dapat dibuat untuk membagi sekelompok simpul kerja menjadi beberapa kelompok virtual dengan
kuota untuk CPU dan memori.
KeamananSetiap cluster Kubernetes memiliki root Certificate Authority (CA). Controller Manager, API Server, Scheduler, klien kubelet, kube-proxy dan sertifikat administrator harus dibuat dan diinstal. Jika Anda menggunakan alat atau distribusi instalasi, Anda mungkin tidak harus menghadapinya sendiri. Proses manual dijelaskan di
sini . Anda harus siap untuk menginstal ulang sertifikat jika Anda memperluas atau mengganti node.
Karena Kubernetes sepenuhnya dikelola oleh API, sangat penting untuk mengontrol dan membatasi daftar mereka yang memiliki akses ke cluster. Opsi enkripsi dan otentikasi dibahas dalam dokumentasi ini.
Beban kerja aplikasi Kubernetes didasarkan pada gambar kontainer. Anda membutuhkan sumber dan konten gambar-gambar ini agar dapat diandalkan. Hampir selalu, ini berarti Anda akan meng-host gambar kontainer di repositori lokal. Menggunakan gambar dari Internet publik dapat menyebabkan masalah keandalan dan keamanan. Anda harus memilih repositori yang memiliki dukungan untuk menandatangani gambar, memindai keamanan, mengontrol akses untuk mengirim dan mengunduh gambar, dan aktivitas logging.
Proses harus dikonfigurasikan untuk mendukung penggunaan host, hypervisor, OS6, Kubernetes, dan pembaruan firmware ketergantungan lainnya. Pemantauan versi diperlukan untuk mendukung audit.
Rekomendasi:
- Memperkuat pengaturan keamanan default untuk komponen tingkat terkelola (misalnya, memblokir node pekerja );
- Gunakan Kebijakan Keselamatan Pos Gizi ;
- Pikirkan tentang integrasi NetworkPolicy yang tersedia untuk solusi jaringan Anda, termasuk pelacakan, pemantauan, dan pemecahan masalah;
- Gunakan RBAC untuk membuat keputusan otorisasi;
- Pikirkan tentang keamanan fisik, terutama ketika menggunakan ke lokasi-lokasi pinggiran atau terpencil yang mungkin terlewatkan. Tambahkan enkripsi penyimpanan untuk membatasi konsekuensi dari pencurian perangkat, dan perlindungan terhadap menghubungkan perangkat jahat, seperti kunci USB;
- Lindungi kredensial teks penyedia cloud (kunci akses, token, kata sandi, dll.).
Objek
rahasia Kubernet cocok untuk menyimpan sejumlah kecil data sensitif. Mereka disimpan di etcd. Mereka dapat digunakan dengan aman untuk menyimpan kredensial API Kubernetes, tetapi ada kalanya beban kerja atau perluasan cluster itu sendiri membutuhkan solusi yang lebih lengkap. Proyek HashiCorp Vault adalah solusi populer jika Anda membutuhkan lebih dari yang dapat disediakan oleh objek rahasia.
Pemulihan Bencana dan Cadangan
Menerapkan redundansi melalui penggunaan beberapa host dan VM membantu mengurangi jumlah jenis kegagalan tertentu. Tetapi skenario seperti bencana alam, pembaruan yang buruk, serangan hacker, bug perangkat lunak atau kesalahan manusia masih dapat menyebabkan crash.
Bagian penting dari penyebaran produksi adalah harapan pemulihan di masa depan.
Perlu juga dicatat bahwa bagian dari investasi Anda dalam desain, dokumentasi, dan otomasi proses pemulihan dapat digunakan kembali jika Anda membutuhkan penyebaran replikasi skala besar di beberapa situs.
Di antara unsur-unsur pemulihan bencana, cadangan (dan mungkin replika), penggantian, proses yang direncanakan, orang-orang yang akan melakukan proses ini, dan pelatihan reguler patut dicatat. Latihan dan prinsip pengujian
Chaos Engineering yang sering dilakukan dapat digunakan untuk menguji kesiapan Anda.
Karena persyaratan ketersediaan, Anda mungkin harus menyimpan salinan lokal OS, komponen Kubernetes, dan penampung gambar untuk memungkinkan pemulihan bahkan jika Internet macet. Kemampuan untuk menyebarkan host dan node pengganti dalam situasi "isolasi fisik" meningkatkan keamanan dan meningkatkan kecepatan penyebaran.
Semua objek Kubernetes disimpan di etcd. Mencadangkan secara berkala data cluster etcd adalah elemen penting dalam memulihkan kluster Kubernet selama skenario darurat, misalnya, ketika semua node master hilang.
etcd
etcd . Kubernetes . , Kubernetes.
, Kubernetes etcd , - . , .
etcd. , , , , /. , . :
- : CA, API Server, Apiserver-kubelet-client, ServiceAccount, “Front proxy”, Front proxy;
- DNS;
- IP/;
- ;
- kubeconfig;
- LDAP ;
- .
Anti-affinity . , . , Kubernetes , . , , - .
, .
stateful-, — Kubernetes (, SQL ). , , Kubernetes,
roadmap feature request , , , Container Storage Interface (CSI). , - , , . , Kubernetes , , , Kubernetes .
stateful- (, Cassandra) , , . - Kubernetes ( -) .
( ) , , . , , .
, (,
Ansible ,
BOSH ,
Chef ,
Juju ,
kubeadm ,
Puppet .). , .
, , , , , , . , Git, .
, , — . 2 , — . — , .

— . - , Airbus A320 — . , . , .
, . , , , . Kubernetes , - , , (, FedEx, Amazon).
production-grade Kubernetes . . , , , , . , (, Kubernetes
self-hosting, bukan perapian statis). Mungkin mereka harus dibahas dalam artikel berikut, jika ada minat yang cukup. Selain itu, karena kecepatan tinggi peningkatan Kubernetes, jika mesin pencari Anda menemukan artikel ini setelah 2019, beberapa bahannya mungkin sudah sangat usang.AKHIR
Seperti biasa menunggu pertanyaan Anda dan komentar di sini, dan Anda dapat pergi ke open house untuk Alexander Titov .