Pertimbangkan satu skenario di mana model pembelajaran mesin Anda mungkin tidak berharga.
Ada pepatah:
"Jangan membandingkan apel dengan jeruk .
" Tetapi bagaimana jika Anda perlu membandingkan satu set apel dengan jeruk dengan yang lain, tetapi distribusi buah dalam dua set berbeda? Bisakah Anda bekerja dengan data? Dan bagaimana Anda akan melakukannya?
Dalam kasus nyata, situasi ini biasa terjadi. Saat mengembangkan model pembelajaran mesin, kami dihadapkan pada situasi di mana model kami bekerja dengan baik dengan set pelatihan, tetapi kualitas model menurun tajam pada data uji.
Dan ini bukan tentang pelatihan ulang. Katakanlah kita telah membangun model yang memberikan hasil luar biasa pada validasi silang, tetapi menunjukkan hasil yang buruk pada pengujian. Jadi dalam sampel uji ada informasi yang tidak kami perhitungkan.
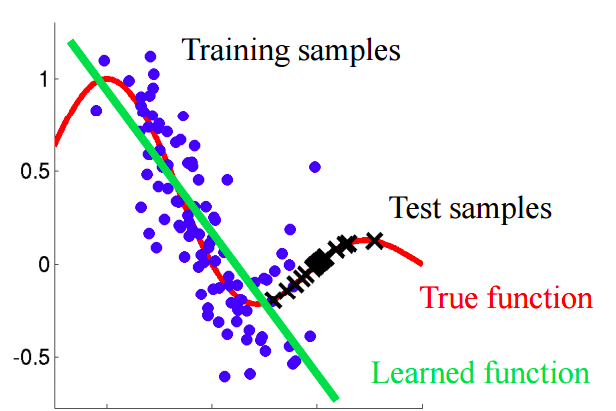
Bayangkan sebuah situasi di mana kita memprediksi perilaku pelanggan di toko. Jika sampel pelatihan dan tes terlihat seperti gambar di bawah ini, ini merupakan masalah yang jelas:
Dalam contoh ini, model dilatih pada data dengan nilai rata-rata dari atribut "usia pelanggan" lebih rendah dari nilai rata-rata dari atribut yang sama pada tes. Dalam proses pembelajaran, model tidak pernah "melihat" nilai-nilai yang lebih besar dari atribut "usia". Jika usia adalah fitur penting untuk model, maka orang seharusnya tidak mengharapkan hasil yang baik pada sampel uji.Dalam teks ini, kita akan berbicara tentang pendekatan "naif" yang memungkinkan kita untuk mengidentifikasi fenomena seperti itu dan mencoba untuk menghilangkannya.
Pergeseran kovarian
Mari kita berikan definisi yang lebih akurat dari konsep ini.
Kovarian mengacu pada nilai-nilai karakteristik, dan
pergeseran kovarian mengacu pada situasi di mana distribusi nilai-nilai karakteristik dalam pelatihan dan sampel uji memiliki karakteristik (parameter) yang berbeda.
Dalam masalah dunia nyata dengan sejumlah besar variabel, pergeseran kovarian sulit dideteksi. Artikel ini membahas metode untuk mengidentifikasi, serta memperhitungkan pergeseran kovarian dalam data.
Ide utama
Jika ada pergeseran dalam data, maka ketika mencampur dua sampel, kita dapat membangun classifier yang dapat menentukan apakah objek tersebut milik pelatihan atau sampel uji.Mari kita mengerti mengapa demikian. Mari kita kembali ke contoh dengan pelanggan, di mana usia adalah tanda "bergeser" dari pelatihan dan sampel uji. Jika kita mengambil classifier (misalnya, berdasarkan hutan acak) dan mencoba untuk membagi sampel campuran menjadi pelatihan dan tes, maka usia akan menjadi tanda yang sangat penting untuk klasifikasi ini.
Implementasi
Mari kita coba menerapkan ide yang diuraikan ke dataset nyata. Gunakan
dataset dari kompetisi Kaggle.
Langkah 1: persiapan data
Pertama, kami akan mengikuti serangkaian langkah standar: bersihkan, isi bagian yang kosong, lakukan penyandian label untuk tanda-tanda kategorikal. Tidak diperlukan langkah untuk dataset yang dimaksud, jadi lewati deskripsinya.
import pandas as pd
Langkah 2: menambahkan indikator sumber data
Penting untuk menambahkan indikator indikator baru ke kedua bagian dataset - pelatihan dan tes. Untuk sampel pelatihan dengan nilai "1", untuk tes, masing-masing, "0".
Langkah 3: Menggabungkan Sampel Pembelajaran dan Tes
Sekarang Anda harus menggabungkan dua set data. Karena dataset pelatihan berisi kolom nilai target 'target', yang tidak ada dalam dataset uji, kolom ini harus dihapus.
Langkah 4: membangun dan menguji classifier
Untuk tujuan klasifikasi, kami akan menggunakan Pengklasifikasi Hutan Acak, yang akan kami konfigurasikan untuk memprediksi label sumber data dalam kumpulan data gabungan. Anda dapat menggunakan penggolong lain.
from sklearn.ensemble import RandomForestClassifier import numpy as np rfc = RandomForestClassifier(n_jobs=-1, max_depth=5, min_samples_leaf = 5) predictions = np.zeros(y.shape)
Kami menggunakan split acak bertingkat 4 lipatan. Dengan cara ini kami akan menjaga rasio label 'is_train' di setiap lipatan seperti pada sampel gabungan asli. Untuk setiap partisi kita latih classifier pada sebagian besar partisi dan prediksi label kelas untuk bagian yang lebih kecil ditangguhkan.
from sklearn.model_selection import StratifiedKFold, cross_val_score skf = StratifiedKFold(n_splits=4, shuffle=True, random_state=100) for fold, (train_idx, test_idx) in enumerate(skf.split(x, y)): X_train, X_test = x[train_idx], x[test_idx] y_train, y_test = y[train_idx], y[test_idx] rfc.fit(X_train, y_train) probs = rfc.predict_proba(X_test)[:, 1]
Langkah 5: interpretasikan hasilnya
Kami menghitung nilai metrik ROC AUC untuk classifier kami. Berdasarkan nilai ini, kami menyimpulkan seberapa baik klasifikasi kami mengungkapkan perubahan kovarian dalam data.
Jika classifier c memisahkan objek dengan baik ke dalam set data pelatihan dan tes, maka nilai metrik ROC AUC harus secara signifikan lebih besar dari 0,5, idealnya mendekati 1. Gambar ini menunjukkan pergeseran kovarian yang kuat dalam data.Cari nilai ROC AUC:
from sklearn.metrics import roc_auc_score print('ROC-AUC:', roc_auc_score(y_true=y, y_score=predictions))
Nilai yang dihasilkan mendekati 0,5. Dan ini berarti bahwa classifier kualitas kami sama dengan prediktor tag acak. Tidak ada bukti pergeseran kovarian dalam data.
Karena dataset diambil dari Kaggle, hasilnya cukup dapat diprediksi. Seperti dalam kompetisi pembelajaran mesin lainnya, data diverifikasi dengan cermat untuk memastikan tidak ada perubahan.
Tetapi pendekatan ini dapat diterapkan dalam masalah lain dari ilmu data untuk memeriksa keberadaan pergeseran kovarian tepat sebelum dimulainya solusi.
Langkah selanjutnya
Jadi, apakah kita mengamati perubahan kovarian atau tidak. Apa yang harus dilakukan untuk meningkatkan kualitas model dalam ujian?
- Hapus fitur yang bias
- Gunakan bobot kepentingan objek berdasarkan estimasi koefisien kerapatan
Menghapus fitur yang bias:
Catatan: metode ini berlaku jika ada pergeseran kovarian dalam data.- Ekstrak pentingnya atribut dari Random Forest Classifier, yang kami bangun dan latih sebelumnya.
- Tanda-tanda yang paling penting adalah mereka yang bias dan menyebabkan pergeseran data.
- Dimulai dengan yang paling penting, hapus berdasarkan satu, bangun model target dan lihat kualitasnya. Kumpulkan semua tanda yang kualitas modelnya tidak menurun.
- Buang karakteristik yang dikumpulkan dari data dan buat model akhir.
 Algoritma ini memungkinkan Anda untuk menghapus tanda-tanda dari keranjang merah dalam diagram.
Algoritma ini memungkinkan Anda untuk menghapus tanda-tanda dari keranjang merah dalam diagram.Menggunakan bobot kepentingan objek berdasarkan estimasi koefisien kerapatan
Catatan: metode ini berlaku terlepas dari apakah ada pergeseran kovarian dalam data.Mari kita lihat prediksi yang kami terima di bagian sebelumnya. Untuk setiap objek, prediksi berisi probabilitas bahwa objek ini milik pelatihan yang ditetapkan untuk classifier kami.
predictions[:10]
Misalnya, untuk objek pertama, Pengklasifikasi Hutan Acak kami meyakini bahwa objek tersebut termasuk dalam rangkaian pelatihan dengan probabilitas 0,397. Sebut nilai ini
. Atau kita dapat mengatakan bahwa kemungkinan memiliki data uji adalah 0,603. Demikian pula, kami menyebutnya probabilitas
.
Sekarang sedikit trik: untuk setiap objek dataset pelatihan, kami menghitung koefisien
.
Koefisien
memberitahu kita seberapa dekat suatu objek dari set pelatihan untuk menguji data. Gagasan utama:
Kita bisa menggunakan seperti bobot dalam salah satu model untuk menambah bobot pengamatan yang terlihat mirip dengan sampel uji. Secara intuitif, ini masuk akal, karena model kami akan lebih berorientasi pada data seperti pada test suite.Bobot ini dapat dihitung menggunakan kode:
import seaborn as sns import matplotlib.pyplot as plt plt.figure(figsize=(20,10)) predictions_train = predictions[:len(trn)] weights = (1./predictions_train) - 1. weights /= np.mean(weights)
Koefisien yang diperoleh dapat ditransfer ke model, misalnya, sebagai berikut:
rfc = RandomForestClassifier(n_jobs=-1,max_depth=5) m.fit(X_train, y_train, sample_weight=weights)

Beberapa kata tentang histogram yang dihasilkan:
- Nilai berat yang lebih besar sesuai dengan pengamatan yang lebih mirip dengan sampel uji.
- Hampir 70% dari objek dari set pelatihan memiliki bobot mendekati 1, dan, oleh karena itu, terletak di subruang yang mirip dengan set pelatihan dan set tes. Ini sesuai dengan nilai AUC yang kami hitung sebelumnya.
Kesimpulan
Kami berharap posting ini akan membantu Anda mengidentifikasi "pergeseran kovarian" dalam data dan memeranginya.
Referensi
[1] Shimodaira, H. (2000). Meningkatkan inferensi prediktif di bawah pergeseran kovariat dengan memberi bobot fungsi log-likelihood. Jurnal Perencanaan dan Inferensi Statistik, 90, 227-244.
[2] Bickel, S. et al. (2009). Pembelajaran Diskriminatif Dalam Pergeseran Kovariat. Jurnal Penelitian Pembelajaran Mesin, 10, 2137–2155
[3]
github.com/erlendd/covariate-shift-adaption[4]
Tautan ke dataset yang digunakanPS Laptop dengan kode dari artikel dapat dilihat di
sini .