 Prosesor tensor generasi ke-3Google Tensor Processor
Prosesor tensor generasi ke-3Google Tensor Processor adalah Sirkuit Terpadu Tujuan Khusus (
ASIC ) yang dikembangkan dari bawah ke atas oleh Google untuk melakukan tugas pembelajaran mesin. Dia bekerja pada beberapa produk Google utama, termasuk Translate, Photos, Search Assistant, dan Gmail. Cloud TPU memberikan manfaat skalabilitas dan kemudahan penggunaan bagi semua pengembang dan ilmuwan data yang meluncurkan model pembelajaran mesin mutakhir di Google Cloud. Di Google Next '18, kami mengumumkan bahwa Cloud TPU v2 sekarang tersedia untuk semua pengguna, termasuk
akun uji coba gratis , dan Cloud TPU v3 tersedia untuk pengujian alfa.

Tetapi banyak orang bertanya - apa perbedaan antara CPU, GPU dan TPU? Kami membuat
situs demo tempat presentasi dan animasi berada yang menjawab pertanyaan ini. Dalam posting ini, saya ingin membahas fitur-fitur tertentu dari konten situs ini.
Bagaimana cara kerja jaringan saraf?
Sebelum mulai membandingkan CPU, GPU, dan TPU, mari kita lihat perhitungan seperti apa yang diperlukan untuk pembelajaran mesin - dan khususnya, untuk jaringan saraf.
Bayangkan, misalnya, bahwa kita menggunakan jaringan saraf lapis tunggal untuk mengenali angka tulisan tangan, seperti yang ditunjukkan pada diagram berikut:
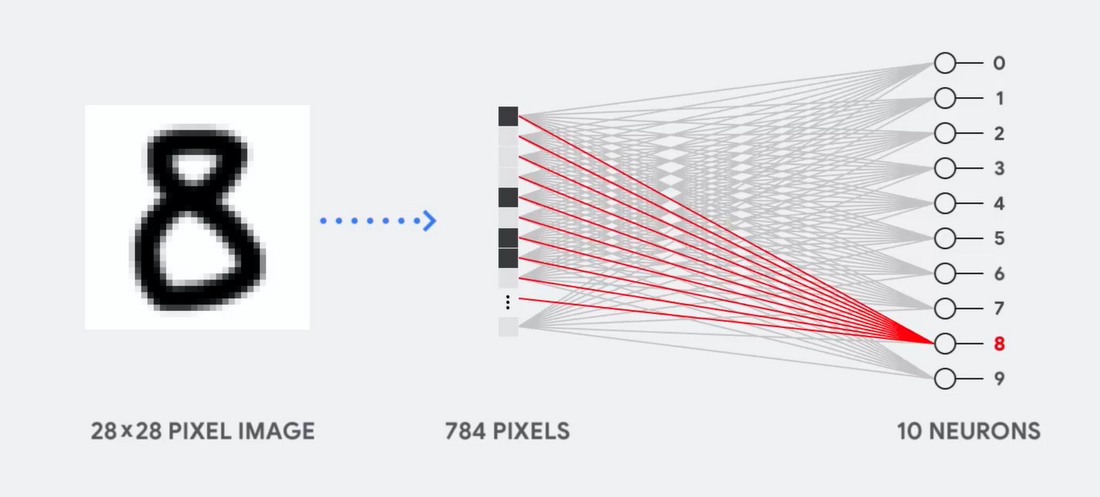
Jika gambar adalah kisi 28x28 piksel dalam skala abu-abu, itu dapat dikonversi menjadi vektor nilai 784 (pengukuran). Neuron yang mengenali angka 8 mengambil nilai-nilai ini dan mengalikannya dengan nilai parameter (garis merah dalam diagram).
Parameter berfungsi sebagai filter, mengekstraksi fitur data yang menunjukkan kesamaan gambar dan bentuk 8:

Ini adalah penjelasan paling sederhana dari klasifikasi data oleh jaringan saraf. Perkalian data dengan parameter yang terkait dengannya (pewarnaan poin) dan penambahannya (jumlah poin di sebelah kanan). Hasil tertinggi menunjukkan kecocokan terbaik antara data yang dimasukkan dan parameter yang sesuai, yang, kemungkinan besar, akan menjadi jawaban yang benar.
Sederhananya, jaringan saraf perlu melakukan sejumlah besar perkalian dan penambahan data dan parameter. Seringkali kita mengaturnya dalam bentuk
perkalian matriks , yang mungkin Anda temui dalam aljabar di sekolah. Oleh karena itu, masalahnya adalah melakukan sejumlah besar perkalian matriks secepat mungkin, menghabiskan energi sesedikit mungkin.
Bagaimana cara kerja CPU?
Bagaimana cara CPU mendekati tugas ini? CPU adalah prosesor tujuan umum berdasarkan
arsitektur von Neumann . Ini berarti bahwa CPU bekerja dengan perangkat lunak dan memori sebagai berikut:
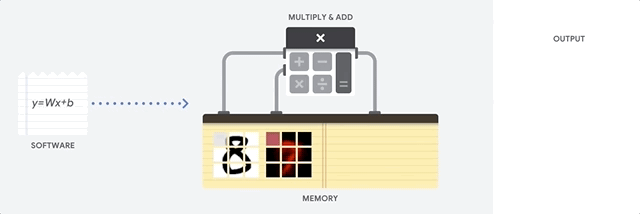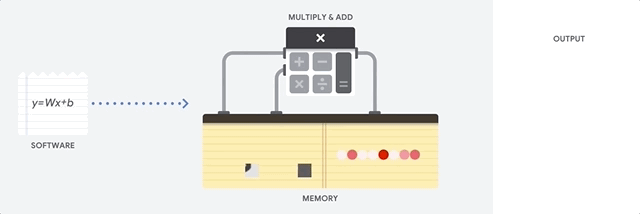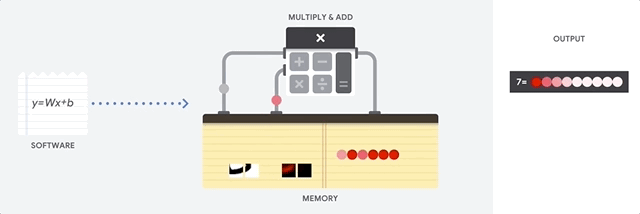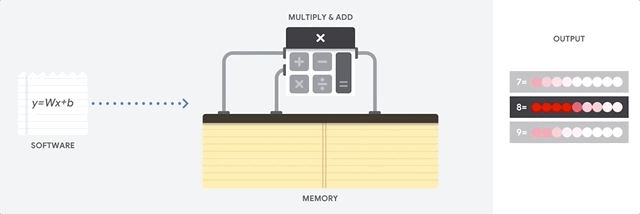
Keuntungan utama dari CPU adalah fleksibilitas. Berkat arsitektur von Neumann, Anda dapat mengunduh perangkat lunak yang sangat berbeda untuk jutaan tujuan yang berbeda. CPU dapat digunakan untuk pengolah kata, kontrol mesin roket, transaksi bank, klasifikasi gambar menggunakan jaringan saraf.
Tetapi karena CPU sangat fleksibel, peralatan tidak selalu tahu sebelumnya apa operasi berikutnya sampai membaca instruksi selanjutnya dari perangkat lunak. CPU perlu menyimpan hasil setiap perhitungan dalam memori yang terletak di dalam CPU (yang disebut register, atau
cache L1 ). Akses ke memori ini menjadi minus dari arsitektur CPU, yang dikenal sebagai bottleneck arsitektur von Neumann. Dan meskipun sejumlah besar perhitungan untuk jaringan saraf membuat langkah-langkah di masa depan dapat diprediksi, masing-masing
perangkat logika aritmatika dari CPU (ALU, komponen yang menyimpan dan mengendalikan pengganda dan penambah) melakukan operasi secara berurutan, mengakses memori setiap kali, yang membatasi keseluruhan throughput dan mengkonsumsi sejumlah besar energi .
Bagaimana cara kerja GPU
Untuk meningkatkan throughput dibandingkan dengan CPU, GPU menggunakan strategi sederhana: mengapa tidak mengintegrasikan ribuan ALU ke dalam prosesor? GPU modern berisi sekitar 2500 - 5000 ALU pada prosesor, yang memungkinkan untuk melakukan ribuan perkalian dan penambahan dalam satu waktu.

Arsitektur seperti itu bekerja dengan baik dengan aplikasi yang membutuhkan paralelisasi besar-besaran, seperti, misalnya, perkalian matriks dalam jaringan saraf. Dengan beban pelatihan khusus deep learning (GO), throughput dalam hal ini meningkat dengan urutan besarnya dibandingkan dengan CPU. Karena itu, hari ini GPU adalah arsitektur prosesor paling populer untuk GO.
Tetapi GPU masih tetap merupakan prosesor tujuan umum yang harus mendukung sejuta aplikasi dan perangkat lunak berbeda. Dan ini membawa kita kembali ke masalah mendasar dari bottleneck arsitektur von Neumann. Untuk setiap perhitungan dalam ribuan ALU, GPU, perlu untuk merujuk ke register atau memori bersama untuk membaca dan menyimpan hasil perhitungan menengah. Karena GPU melakukan lebih banyak komputasi paralel pada ribuan ALUnya, GPU juga menghabiskan lebih banyak energi secara proporsional pada akses memori dan memakan area yang luas.
Bagaimana cara kerja TPU?
Ketika kami mengembangkan TPU di Google, kami membangun arsitektur yang dirancang untuk tugas tertentu. Alih-alih mengembangkan prosesor tujuan umum, kami mengembangkan prosesor matriks yang dikhususkan untuk bekerja dengan jaringan saraf. TPU tidak akan dapat bekerja dengan pengolah kata, mengendalikan mesin roket atau melakukan transaksi perbankan, tetapi ia dapat memproses sejumlah besar perkalian dan penambahan untuk jaringan saraf pada kecepatan luar biasa, sambil mengonsumsi lebih sedikit energi dan pas dalam volume fisik yang lebih kecil.
Hal utama yang memungkinkannya untuk melakukan ini adalah penghapusan radikal dari bottleneck arsitektur von Neumann. Karena tugas utama TPU adalah pemrosesan matriks, pengembang sirkuit terbiasa dengan semua langkah perhitungan yang diperlukan. Oleh karena itu, mereka dapat menempatkan ribuan pengganda dan tambahan, dan menghubungkannya secara fisik, membentuk matriks fisik yang besar. Ini disebut
arsitektur array pipelined . Dalam kasus Cloud TPU v2, dua array pipa 128 x 128 digunakan, yang secara total memberikan 32.768 ALU untuk nilai titik-mengambang 16-bit pada satu prosesor.
Mari kita lihat bagaimana array pipelined melakukan perhitungan untuk jaringan saraf. Pertama, TPU memuat parameter dari memori ke dalam matriks pengganda dan tambahan.

TPU kemudian memuat data dari memori. Setelah menyelesaikan setiap perkalian, hasilnya ditransmisikan ke faktor-faktor berikut, sambil melakukan penambahan. Oleh karena itu, output akan menjadi jumlah dari semua perkalian data dan parameter. Sepanjang proses komputasi volumetrik dan transfer data, akses ke memori sama sekali tidak diperlukan.
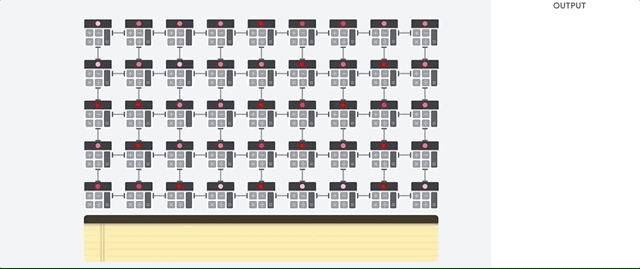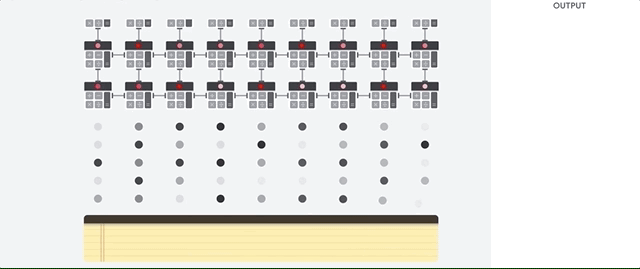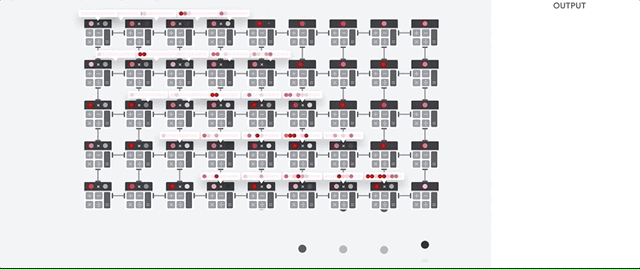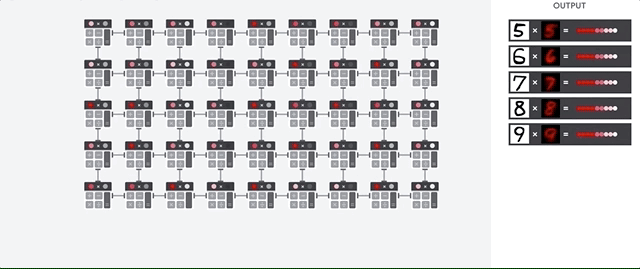
Oleh karena itu, TPU menunjukkan throughput yang lebih besar ketika menghitung untuk jaringan saraf, mengkonsumsi lebih sedikit energi dan mengambil lebih sedikit ruang.
Keuntungan: 5 kali lebih murah
Apa manfaat arsitektur TPU? Biaya. Berikut adalah biaya Cloud TPU v2 untuk Agustus 2018, pada saat penulisan:
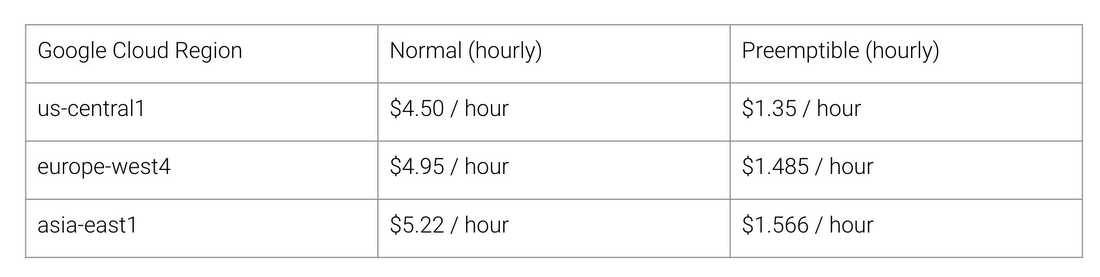
Biaya kerja normal dan TPU untuk berbagai wilayah Google Cloud
Stanford University mendistribusikan serangkaian tes
DAWNBench yang mengukur kinerja sistem pembelajaran yang mendalam. Di sana Anda dapat melihat berbagai kombinasi tugas, model, dan platform komputasi, serta hasil pengujian yang sesuai.
Pada akhir kompetisi di bulan April 2018, biaya pelatihan minimum untuk prosesor dengan arsitektur selain TPU adalah $ 72,40 (untuk pelatihan ResNet-50 dengan akurasi 93% pada ImageNet pada
contoh lokasi ). Dengan Cloud TPU v2, pelatihan ini dapat dilakukan untuk $ 12,87. Ini kurang dari 1/5 dari biaya. Itulah kekuatan arsitektur yang dirancang khusus untuk jaringan saraf.