
Sayangnya di Internet tidak ada cukup informasi tentang migrasi aplikasi nyata dan operasi produksi Cluster Percona XtraDB (selanjutnya disebut PXC). Saya akan mencoba memperbaiki situasi ini dan menceritakan pengalaman kami dengan kisah saya. Tidak akan ada petunjuk instalasi langkah-demi-langkah dan artikel tidak boleh dianggap sebagai pengganti untuk off-dokumentasi, tetapi sebagai kumpulan rekomendasi.
Masalah
Saya bekerja sebagai administrator sistem di
ultimate-guitar.com . Karena kami menyediakan layanan web, secara alami kami memiliki backend dan database, yang merupakan inti dari layanan tersebut. Waktu aktif layanan secara langsung tergantung pada kinerja database.
Percona MySQL 5.7 digunakan sebagai basis data. Reservasi diimplementasikan menggunakan master skema replikasi master. Budak digunakan untuk membaca beberapa data.
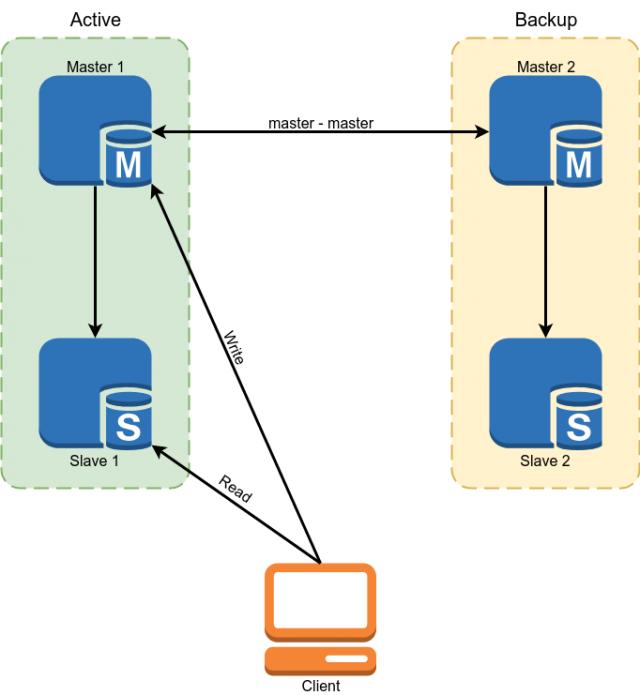
Tetapi skema ini tidak sesuai dengan kami dengan kerugian berikut:
- Karena fakta bahwa dalam replikasi MySQL, budak asinkron bisa tertinggal tanpa batas. Semua data penting harus dibaca dari master.
- Dari paragraf sebelumnya mengikuti kompleksitas pengembangan. Pengembang tidak bisa hanya membuat permintaan ke database, tetapi berkewajiban untuk memikirkan apakah ia siap dalam setiap kasus tertentu ke tumpukan budak dan jika tidak, maka baca data dari wizard.
- Pergantian manual jika terjadi kecelakaan. Menerapkan pengalihan otomatis bermasalah karena fakta bahwa arsitektur MySQL tidak memiliki perlindungan bawaan terhadap otak yang terbelah. Kita harus menulis diri kita sendiri seorang wasit dengan logika kompleks untuk memilih seorang master. Saat menulis kepada kedua tuan, konflik dapat muncul pada saat yang sama, melanggar replikasi induk dan mengarah ke otak yang terbelah klasik.
Beberapa angka kering, sehingga Anda memahami apa yang kami kerjakan:
Ukuran Basis Data: 300 GB
QPS: ~ 10k
Rasio RW: 96/4%
Konfigurasi Master Server:
CPU: 2x E5-2620 v3
RAM: 128 Gb
SSD: Intel Optane 905p 960 Gb
Jaringan: 1 Gbps
Kami memiliki beban OLTP klasik dengan banyak bacaan, yang perlu dilakukan dengan sangat cepat dan dengan sedikit penulisan. Muatan pada database cukup kecil karena fakta bahwa caching secara aktif digunakan dalam Redis dan Memcached.
Pemilihan keputusan
Seperti yang sudah Anda tebak dari judulnya, kami memilih PXC, tetapi di sini saya akan menjelaskan mengapa kami memilihnya.
Kami memiliki 4 opsi:
- Ubah DBMS
- Replikasi Grup MySQL
- Sekrup fungsi yang diperlukan sendiri menggunakan skrip di atas master replikasi master.
- MySQL Galera cluster (atau forks-nya, misalnya PXC)
Opsi dengan mengubah database praktis tidak dipertimbangkan, karena aplikasi ini besar, di banyak tempat itu terkait dengan fungsionalitas atau sintaks mysql, dan migrasi ke PostgreSQL, misalnya, akan membutuhkan banyak waktu dan sumber daya.
Opsi kedua adalah Replikasi Grup MySQL. Keuntungan yang tidak diragukan lagi adalah bahwa ia berkembang di cabang vanilla MySQL, yang berarti bahwa di masa depan akan menjadi luas dan akan memiliki banyak pengguna aktif.
Tapi dia punya beberapa kekurangan. Pertama, ia memberlakukan lebih banyak pembatasan pada skema aplikasi dan database, yang berarti akan lebih sulit untuk bermigrasi. Kedua, Replikasi Grup memecahkan masalah toleransi kesalahan dan membagi otak, tetapi replikasi dalam cluster masih asinkron.
Kami juga tidak menyukai opsi ketiga untuk terlalu banyak sepeda, yang mau tidak mau harus kami laksanakan ketika memecahkan masalah dengan cara ini.
Galera diizinkan untuk sepenuhnya menyelesaikan masalah failover MySQL dan menyelesaikan sebagian masalah dengan relevansi data pada budak. Sebagian karena asynchrony replikasi dipertahankan. Setelah transaksi dilakukan pada node lokal, perubahan didorong ke node yang tersisa secara tidak serempak, tetapi cluster memastikan bahwa node tidak ketinggalan terlalu banyak dan jika mereka mulai ketinggalan, itu secara artifisial memperlambat pekerjaan. Cluster memastikan bahwa setelah melakukan transaksi tidak ada yang bisa melakukan perubahan yang bertentangan bahkan pada node yang belum mereplikasi perubahan.
Setelah migrasi, skema operasi basis data akan terlihat seperti ini:
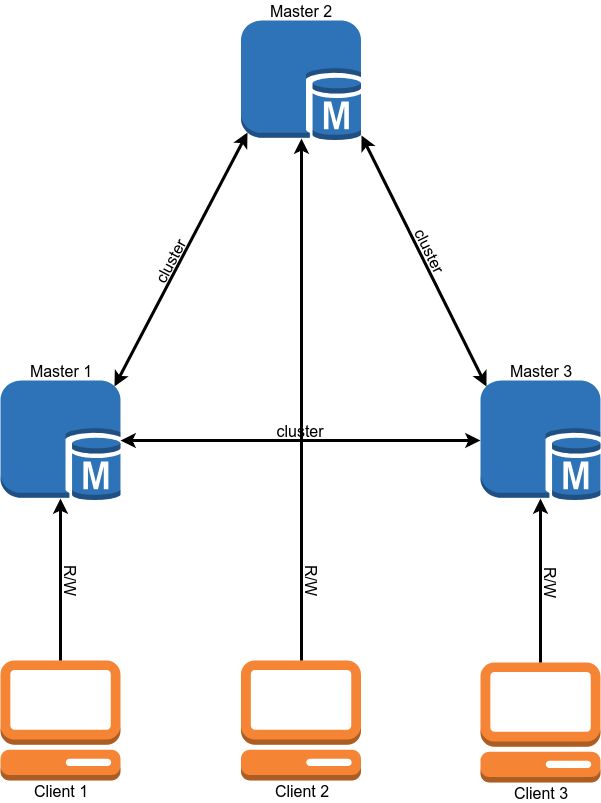
Migrasi
Mengapa migrasi item kedua setelah memilih solusi? Sederhana - cluster berisi sejumlah persyaratan yang harus diikuti oleh aplikasi dan database, dan kita harus memenuhinya sebelum migrasi.
- Mesin InnoDB untuk semua tabel. MyISAM, Memori, dan backend lainnya tidak didukung. Ini diperbaiki cukup sederhana - kami mengonversi semua tabel ke InnoDB.
- Binlog dalam format ROW. Cluster tidak membutuhkan binlog untuk berfungsi, dan jika Anda tidak membutuhkan budak klasik, Anda bisa mematikannya, tetapi format binlog harus ROW.
- Semua tabel harus memiliki KUNCI UTAMA / ASING. Ini diperlukan untuk penulisan bersamaan yang benar ke tabel yang sama dari node yang berbeda. Untuk tabel yang tidak mengandung kunci unik, Anda bisa menggunakan kunci primer gabungan atau kenaikan otomatis.
- Jangan gunakan 'LOCK TABLES', 'GET_LOCK () / RELEASE_LOCK ()', 'FLUSH TABLES {{table}} DENGAN READ LOCK' atau tingkat isolasi 'SERIALIZABLE' untuk transaksi.
- Jangan gunakan permintaan 'CREATE TABLE ... AS SELECT' , karena mereka menggabungkan skema dan perubahan data. Itu mudah dibagi menjadi 2 query, yang pertama membuat tabel, dan yang kedua mengisi data.
- Jangan gunakan 'DISCARD TABLESPACE' dan 'IMPORT TABLESPACE' , karena mereka tidak direplikasi
- Setel opsi 'innodb_autoinc_lock_mode' ke '2'. Opsi ini dapat merusak data saat bekerja dengan replikasi PERNYATAAN, tetapi karena hanya replikasi ROW yang diizinkan di cluster, tidak akan ada masalah.
- Karena 'log_output' hanya 'FILE' yang didukung. Jika Anda memiliki entri log di tabel, Anda harus menghapusnya.
- Transaksi XA tidak didukung. Jika mereka digunakan, Anda harus menulis ulang kode tanpa mereka.
Saya harus mencatat bahwa hampir semua pembatasan ini dapat dihapus jika Anda menetapkan variabel 'pxc_strict_mode = PERMISSIVE', tetapi jika data Anda penting bagi Anda, maka lebih baik untuk tidak melakukan ini. Jika Anda memiliki set 'pxc_strict_mode = ENFORCING', maka MySQL tidak akan mengizinkan Anda untuk melakukan operasi di atas atau mencegah simpul memulai.
Setelah kami memenuhi semua persyaratan untuk basis data dan menguji dengan seksama pengoperasian aplikasi kami di lingkungan pengembang, kami dapat melanjutkan ke tahap berikutnya.
Penyebaran dan Konfigurasi Cluster
Kami memiliki beberapa database yang berjalan di server database kami dan database lain tidak perlu bermigrasi ke cluster. Tetapi sebuah paket dengan MySQL cluster menggantikan mysql klasik. Kami memiliki beberapa solusi untuk masalah ini:
- Gunakan virtualisasi dan mulai cluster di VM. Kami tidak menyukai opsi ini karena biaya overhead yang besar (dibandingkan dengan yang lain) dan penampilan entitas lain yang perlu diservis
- Bangun versi paket Anda, yang akan menempatkan mysql di tempat yang tidak standar. Dengan demikian, dimungkinkan untuk memiliki beberapa versi mysql di satu server. Pilihan yang baik jika Anda memiliki banyak server, tetapi dukungan terus-menerus dari paket Anda, yang perlu diperbarui secara berkala, dapat memakan banyak waktu.
- Gunakan Docker.
Kami telah memilih Docker, tetapi kami menggunakannya dalam opsi minimum. Untuk penyimpanan data, volume lokal digunakan. Mode operasi '--net host' digunakan untuk mengurangi latensi jaringan dan beban CPU.
Kami juga harus membuat versi Docker kami sendiri. Alasannya adalah bahwa gambar standar dari Percona tidak mendukung mengembalikan posisi saat startup. Ini berarti bahwa setiap kali instance dimulai kembali, itu tidak melakukan sinkronisasi IST cepat, yang hanya mengunggah perubahan yang diperlukan, tetapi SST lambat, yang benar-benar memuat ulang database.
Masalah lainnya adalah ukuran cluster. Dalam sebuah cluster, setiap node menyimpan seluruh kumpulan data. Oleh karena itu, membaca skala dengan sempurna dengan meningkatnya ukuran cluster. Dengan catatan, situasinya sebaliknya - ketika melakukan, setiap transaksi divalidasi karena tidak ada konflik pada semua node. Secara alami, semakin banyak node, semakin banyak waktu yang dibutuhkan komit.
Di sini kami juga memiliki beberapa opsi:
- 2 node + arbiter. 2 node + arbiter. Pilihan yang bagus untuk tes. Selama penyebaran node kedua, master tidak boleh merekam.
- 3 node. Versi klasik. Keseimbangan kecepatan dan keandalan. Harap dicatat bahwa dalam konfigurasi ini satu node harus meregangkan seluruh beban, karena pada saat menambahkan simpul ke-3, yang kedua adalah donor.
- 4+ node. Dengan jumlah genap yang genap, perlu menambahkan arbiter untuk menghindari split-brain. Opsi yang berfungsi baik untuk jumlah bacaan yang sangat besar. Keandalan cluster juga meningkat.
Kami sejauh ini menetapkan opsi dengan 3 node.
Konfigurasi cluster hampir sepenuhnya menyalin konfigurasi MySQL mandiri dan hanya berbeda dalam beberapa opsi:
"Wsrep_sst_method = xtrabackup-v2" Opsi ini mengatur metode menyalin node. Opsi lainnya adalah mysqldump dan rsync, tetapi mereka memblokir node selama durasi penyalinan. Saya tidak melihat alasan untuk menggunakan metode salin non-xtrabackup-v2.
"Gcache" adalah analog dari binlog cluster. Ini adalah buffer melingkar (dalam file) dengan ukuran tetap di mana semua perubahan ditulis. Jika Anda mematikan salah satu node cluster dan kemudian menyalakannya kembali, itu akan mencoba membaca perubahan yang hilang dari Gcache (sinkronisasi IST). Jika tidak ada perubahan yang diperlukan oleh node, maka reload lengkap node (sinkronisasi SST) akan diperlukan. Ukuran gcache diatur sebagai berikut: wsrep_provider_options = 'gcache.size = 20G;'.
wsrep_slave_threads Tidak seperti replikasi klasik dalam sebuah cluster, dimungkinkan untuk menerapkan beberapa "set penulisan" ke database yang sama secara paralel. Opsi ini menunjukkan jumlah pekerja yang menerapkan perubahan. Lebih baik tidak meninggalkan nilai default 1, karena selama aplikasi pekerja dari set tulis besar, sisanya akan menunggu dalam antrian dan replikasi simpul akan mulai tertinggal. Beberapa menyarankan pengaturan parameter ini ke 2 * CPU THREADS, tapi saya pikir Anda perlu melihat jumlah operasi penulisan bersamaan yang Anda miliki.
Kami menetapkan nilai 64. Pada nilai yang lebih rendah, gugus terkadang tidak berhasil menerapkan semua set tulis dari antrian selama semburan beban (misalnya, saat memulai mahkota yang berat).
wsrep_max_ws_size Ukuran transaksi tunggal dalam sebuah cluster dibatasi hingga 2 GB. Tetapi transaksi besar tidak cocok dengan konsep PXC. Lebih baik menyelesaikan 100 transaksi masing-masing 20 MB dari satu per 2 GB. Oleh karena itu, pertama-tama kami membatasi ukuran transaksi di cluster hingga 100 MB, dan kemudian mengurangi batasnya menjadi 50 MB.
Jika Anda mengaktifkan mode ketat, Anda dapat mengatur variabel "
binlog_row_image " menjadi "minimal". Ini akan mengurangi ukuran entri dalam binlog beberapa kali (10 kali dalam pengujian dari Percona). Ini akan menghemat ruang disk dan memungkinkan transaksi yang tidak sesuai dengan batas dengan "binlog_row_image = full".
Batas untuk SST. Untuk Xtrabackup, yang digunakan untuk mengisi node, Anda dapat menetapkan batas penggunaan jaringan, jumlah utas dan metode kompresi. Ini diperlukan agar ketika node diisi, server donor tidak mulai melambat. Untuk melakukan ini, bagian "sst" ditambahkan ke file my.cnf:
[sst] rlimit = 80m compressor = "pigz -3" decompressor = "pigz -dc" backup_threads = 4
Kami membatasi kecepatan salin hingga 80 Mb / s. Kami menggunakan pigz untuk kompresi, ini adalah versi gzip multi-threaded.
GTID Jika Anda menggunakan slave klasik, saya sarankan mengaktifkan GTID di cluster. Ini akan memungkinkan Anda untuk menghubungkan slave ke sembarang node dari cluster tanpa memuat ulang slave.
Selain itu, saya ingin berbicara tentang 2 mekanisme klaster, maknanya dan konfigurasi.
Kontrol aliran
Kontrol aliran adalah cara untuk mengelola beban tulis dalam sebuah cluster. Itu tidak memungkinkan node untuk ketinggalan terlalu jauh dalam replikasi. Dengan cara ini, replikasi "hampir sinkron" tercapai. Mekanisme operasi cukup sederhana - segera setelah panjang antrian penerimaan mencapai nilai yang ditetapkan, ia mengirim pesan "Flow control pause" ke node lain, yang memberitahu mereka untuk berhenti sejenak dengan melakukan transaksi baru sampai node lagging selesai menyapu antrian. .
Beberapa hal mengikuti dari ini:
- Perekaman dalam cluster akan terjadi pada kecepatan node paling lambat. (Tapi itu bisa diperketat.)
- Jika Anda memiliki banyak konflik saat melakukan transaksi, maka Anda dapat mengonfigurasikan Flow Control lebih agresif, yang seharusnya mengurangi jumlahnya.
- Kelambatan maksimum dari sebuah simpul dalam sebuah cluster adalah konstan, tetapi bukan oleh waktu, tetapi oleh jumlah transaksi dalam antrian. Waktu jeda tergantung pada ukuran transaksi rata-rata dan jumlah wsrep_slave_threads.
Anda dapat melihat pengaturan Kontrol aliran seperti ini:
mysql> SHOW GLOBAL STATUS LIKE 'wsrep_flow_control_interval_%';
wsrep_flow_control_interval_low | 36
wsrep_flow_control_interval_high | 71
Pertama-tama, kami tertarik pada parameter wsrep_flow_control_interval_high. Ini mengontrol panjang antrian, setelah itu FC jeda dihidupkan. Parameter ini dihitung dengan rumus: gcs.fc_limit * √N (di mana N = jumlah node dalam cluster.).
Parameter kedua adalah wsrep_flow_control_interval_low. Ia bertanggung jawab atas nilai panjang antrian, setelah mencapai FC mana yang dimatikan. Dihitung dengan rumus: wsrep_flow_control_interval_high * gcs.fc_factor. Secara default, gcs.fc_factor = 1.
Dengan demikian, dengan mengubah panjang antrian, kita dapat mengontrol lag replikasi. Mengurangi panjang antrian akan meningkatkan waktu yang dihabiskan cluster dalam jeda FC, tetapi mengurangi kelambatan node.
Anda dapat mengatur variabel sesi "
wsrep_sync_wait = 7". Ini akan memaksa PXC untuk menjalankan permintaan baca atau tulis hanya setelah menerapkan semua set-penulisan dalam antrian saat ini. Secara alami, ini akan meningkatkan latensi permintaan. Peningkatan latensi berbanding lurus dengan panjang antrian.
Juga diinginkan untuk mengurangi ukuran transaksi maksimum seminimal mungkin, sehingga transaksi lama tidak akan secara tidak sengaja lolos.
EVS atau Penggusuran Otomatis
Mekanisme ini memungkinkan Anda untuk membuang node yang tidak stabil (misalnya, kehilangan paket atau penundaan lama) atau yang merespons secara lambat. Berkat itu, masalah komunikasi dengan satu node tidak akan membuat seluruh cluster, tetapi membiarkan node dinonaktifkan dan terus bekerja dalam mode normal. Mekanisme ini sangat berguna ketika cluster beroperasi melalui WAN atau bagian dari jaringan yang tidak di bawah kendali Anda. Secara default, EVS tidak aktif.
Untuk mengaktifkannya, tambahkan opsi “evs.version = 1;” ke parameter
wsrep_provider_options dan "evs.auto_evict = 5;" (jumlah operasi setelah simpul dimatikan. Nilai 0 menonaktifkan EVS.) Ada juga beberapa parameter yang memungkinkan Anda menyempurnakan EVS:
- evs.delayed_margin Waktu yang diperlukan sebuah simpul untuk merespons. Secara default, 1 detik., Tetapi ketika bekerja di jaringan lokal, itu dapat dikurangi menjadi 0,05-0,1 detik. Atau lebih rendah.
- evs.inactive_check_ Period Periode pemeriksaan. Default 0,5 dtk
Bahkan, waktu dimana sebuah simpul dapat bekerja jika ada masalah sebelum EVS dipicu adalah evs.inactive_check_ Period * evs.auto_evict. Anda juga dapat mengatur "evs.inactive_timeout" dan sebuah simpul yang tidak merespons akan segera dibuang, secara default 15 detik.
Nuansa yang penting adalah bahwa mekanisme ini sendiri tidak akan mengembalikan simpul saat memulihkan komunikasi. Itu harus dimulai ulang dengan tangan.
Kami mendirikan EVS di rumah, tetapi kami belum memiliki kesempatan untuk mengujinya dalam pertempuran.
Load balancing
Agar klien dapat menggunakan sumber daya dari setiap node secara merata dan mengeksekusi permintaan hanya pada node cluster hidup, kita membutuhkan penyeimbang beban. Percona menawarkan 2 solusi:
- ProxySQL Ini adalah proxy L7 untuk MySQL.
- Haproxy. Tetapi Haproxy tidak tahu bagaimana memeriksa status node cluster dan menentukan apakah ia siap untuk menjalankan permintaan. Untuk mengatasi masalah ini, diusulkan untuk menggunakan skrip percona-clustercheck tambahan
Pada awalnya, kami ingin menggunakan ProxySQL, tetapi setelah menguji kinerja, ternyata dalam latensi kehilangan sekitar 15-20% menjadi Haproxy bahkan ketika menggunakan mode fast_forward (permintaan rewrights, perutean dan banyak fungsi ProxySQL lainnya tidak berfungsi dalam mode ini, permintaan diproksikan seperti apa adanya) .
Haproxy lebih cepat, tetapi skrip Percona memiliki beberapa kelemahan.
Pertama, ditulis dalam bash, yang tidak berkontribusi pada penyesuaiannya. Masalah yang lebih serius adalah ia tidak men-cache hasil pemeriksaan MySQL. Jadi, jika kita memiliki 100 klien, yang masing-masing memeriksa keadaan simpul setiap 1 detik, maka skrip akan membuat permintaan ke MySQL setiap 10 ms. Jika karena alasan tertentu MySQL mulai bekerja lambat, maka skrip validasi akan mulai membuat sejumlah besar proses, yang pasti tidak akan memperbaiki situasi.
Diputuskan untuk menulis
solusi di mana memeriksa status MySQL dan respon Haproxy tidak terkait satu sama lain. Script memeriksa keadaan node di latar belakang secara berkala dan menyimpan hasilnya. Server web memberi Haproxy hasil cache.
Contoh Konfigurasi Haproxylisten db
bind 127.0.0.1:3302
mode tcp
balance first
default-server inter 200 rise 6 fall 6
option httpchk HEAD /
server node1 192.168.0.1:3302 check port 9200 id 1
server node2 192.168.0.2:3302 check port 9200 backup id 2
server node3 192.168.0.3:3302 check port 9200 backup id 3
listen db_slave
bind 127.0.0.1:4302
mode tcp
balance leastconn
default-server inter 200 rise 6 fall 6
option httpchk HEAD /
server node1 192.168.0.1:3302 check port 9200 backup
server node2 192.168.0.2:3302 check port 9200
server node3 192.168.0.3:3302 check port 9200
Contoh ini menunjukkan konfigurasi wizard tunggal. Server cluster yang tersisa bertindak sebagai budak.
Pemantauan
Untuk memantau status cluster, kami menggunakan Prometheus + mysqld_exporter dan Grafana untuk memvisualisasikan data. Karena mysqld_exporter mengumpulkan banyak metrik untuk membuat sendiri dasbor cukup membosankan. Anda dapat mengambil
dasbor yang sudah jadi dari Percona dan menyesuaikannya sendiri.
Kami juga menggunakan Zabbix untuk mengumpulkan metrik dan peringatan kluster dasar.
Metrik kluster utama yang ingin Anda pantau:
- wsrep_cluster_status Harus disetel ke Utama pada semua node. Jika nilainya “non-Primer”, maka simpul ini telah kehilangan kontak dengan kuorum kluster.
- wsrep_cluster_size Jumlah node dalam cluster. Ini juga termasuk node "hilang", yang harus ada di cluster, tetapi karena beberapa alasan tidak tersedia. Ketika node dimatikan dengan lembut, nilai variabel ini menurun.
- wsrep_local_state Menunjukkan apakah node adalah anggota aktif cluster dan siap untuk pergi.
- wsrep_evs_state Parameter penting jika Anda mengaktifkan Penggusuran Otomatis (dinonaktifkan secara default). Variabel ini menunjukkan bahwa EVS menganggap simpul ini sehat.
- wsrep_evs_evict_list Daftar node yang dilemparkan oleh EVS dari cluster. Dalam situasi normal, daftar harus kosong.
- wsrep_evs_delayed Daftar kandidat untuk penghapusan EVS. Juga harus kosong.
Metrik kinerja utama:
- wsrep_evs_repl_latency Menunjukkan keterlambatan komunikasi (minimum / rata-rata / maksimum / deviasi senior / paket) dalam cluster. Artinya, ini mengukur latensi jaringan. Peningkatan nilai dapat mengindikasikan kelebihan jaringan atau node cluster. Metrik ini direkam bahkan ketika EVS mati.
- wsrep_flow_control_paused_ns Waktu (dalam ns) sejak node dimulai yang dihabiskan dalam jeda kontrol aliran. Idealnya, harus 0. Pertumbuhan parameter ini menunjukkan masalah dengan kinerja cluster atau kurangnya "wsrep_slave_threads". Anda dapat menentukan simpul mana yang melambat dengan parameter " wsrep_flow_control_sent ".
- wsrep_flow_control_paused Persentase waktu sejak eksekusi terakhir "FLUSH STATUS;" yang dihabiskan oleh simpul dalam jeda kontrol aliran. Seperti halnya variabel sebelumnya, harus cenderung nol.
- wsrep_flow_control_status Menunjukkan apakah Flow Control sedang berjalan. Pada node inisiasi jeda FC, nilai variabel ini akan ON.
- wsrep_local_recv_queue_avg Rata-rata menerima panjang antrian. Pertumbuhan parameter ini menunjukkan masalah dengan kinerja node.
- wsrep_local_send_queue_avg Rata-rata panjang antrian kirim. Pertumbuhan parameter ini menunjukkan masalah kinerja jaringan.
Tidak ada rekomendasi universal tentang nilai-nilai parameter ini. Jelas bahwa mereka cenderung cenderung nol, tetapi pada beban nyata ini kemungkinan besar tidak akan terjadi dan Anda harus menentukan sendiri di mana batas kondisi normal kluster dilewati.
Cadangkan
Cadangan Cluster praktis tidak berbeda dengan mysql mandiri. Untuk penggunaan produksi, kami memiliki beberapa opsi.
- Hapus cadangan dari salah satu node "gain" menggunakan xtrabackup. Opsi termudah, tetapi selama kinerja cluster cadangan akan sia-sia.
- Gunakan budak klasik dan cadangan dari replika.
Backup dengan standalone dan dengan versi cluster yang dibuat menggunakan xtrabackup adalah portable di antara mereka sendiri. Artinya, cadangan yang diambil dari cluster dapat digunakan untuk mandiri mysql dan sebaliknya. Secara alami, versi utama MySQL harus cocok, lebih disukai yang minor. Cadangan yang dibuat menggunakan mysqldump secara alami portabel juga.
Satu-satunya peringatan adalah bahwa setelah Anda menggunakan cadangan, Anda harus menjalankan skrip mysql_upgrade, yang akan memeriksa dan memperbaiki struktur beberapa tabel sistem.
Migrasi data
Sekarang kita telah mengetahui konfigurasi, pemantauan, dan hal-hal lain, kita dapat mulai bermigrasi ke prod.
Migrasi data dalam skema kami cukup sederhana, tetapi kami sedikit kacau;).
Legenda - master 1 dan master 2 dihubungkan oleh master replikasi master. Rekaman hanya untuk menguasai 1. Master 3 adalah server yang bersih.
Rencana migrasi kami (dalam rencana saya akan menghilangkan operasi dengan budak untuk kesederhanaan dan hanya akan berbicara tentang server master).
Percobaan 1
- Hapus cadangan basis data dari master 1 menggunakan xtrabackup.
- Salin cadangan ke master 3 dan jalankan cluster dalam mode single-node.
- Menyiapkan replikasi master antara master 3 dan 1.
- Alihkan membaca dan menulis ke master 3. Periksa aplikasi.
- Pada master 2, matikan replikasi dan mulai berkerumun MySQL. Kami menunggunya untuk menyalin database dari master 3. Selama penyalinan, kami memiliki sekelompok satu simpul dalam status "Donor" dan satu simpul masih tidak berfungsi. Selama penyalinan, kami mendapat banyak kunci dan pada akhirnya kedua node jatuh dengan kesalahan (membuat simpul baru tidak dapat diselesaikan karena kunci mati). Eksperimen kecil ini menghabiskan waktu empat menit untuk kami.
- Alihkan membaca dan menulis kembali ke master 1.
Migrasi tidak berfungsi karena fakta bahwa ketika menguji sirkuit di lingkungan dev pada database, praktis tidak ada traffic tulis, dan ketika mengulangi sirkuit yang sama di bawah beban, masalah keluar.
Kami sedikit mengubah skema migrasi untuk menghindari masalah ini dan mencoba lagi, untuk kedua kalinya berhasil;).
Percobaan 2
- Kami me-restart master 3 sehingga berfungsi lagi dalam mode single-node.
- Kami meningkatkan cluster MySQL lagi pada master 2. Saat ini, lalu lintas dari replikasi hanya pergi ke gugus, sehingga tidak ada masalah berulang dengan kunci dan simpul kedua berhasil ditambahkan ke gugus.
- Sekali lagi, alihkan pembacaan dan penulisan ke master 3. Kami memeriksa pengoperasian aplikasi.
- Menonaktifkan replikasi master dengan master 1. Nyalakan cluster mysql pada master 1 dan tunggu sampai mulai. Agar tidak menginjak menyapu yang sama, penting bahwa aplikasi tidak menulis ke simpul Donor (untuk detailnya, lihat bagian tentang load balancing). Setelah memulai node ketiga, kita akan memiliki cluster yang berfungsi penuh dari tiga node.
- Anda dapat menghapus cadangan dari salah satu node kluster dan membuat jumlah budak klasik yang Anda butuhkan.
Perbedaan antara skema kedua dan yang pertama adalah bahwa kami mengalihkan lalu lintas ke cluster hanya setelah menaikkan node kedua di cluster.
Prosedur ini memakan waktu sekitar 6 jam bagi kami.
Multi-master
Setelah migrasi, klaster kami bekerja dalam mode master tunggal, yaitu, seluruh catatan pergi ke salah satu server, dan hanya data yang dibaca dari yang lain.
Setelah mengalihkan produksi ke mode multi-master, kami mengalami masalah - konflik transaksi muncul lebih sering daripada yang kami harapkan. Terutama buruk dengan kueri yang memodifikasi banyak rekaman, misalnya memperbarui nilai semua catatan dalam tabel. Transaksi-transaksi yang berhasil dieksekusi pada node yang sama secara berurutan pada cluster dieksekusi secara paralel dan transaksi yang lebih lama menerima kesalahan jalan buntu. Saya tidak akan menunda, setelah beberapa upaya untuk memperbaikinya di level aplikasi, kami meninggalkan ide multi-master.
Nuansa lainnya
- Cluster mungkin seorang budak. Saat menggunakan fungsi ini, saya sarankan menambahkan ke config semua node kecuali yang merupakan opsi slave "skip_slave_start = 1". Jika tidak, setiap node baru akan memulai replikasi dari master, yang akan menyebabkan kesalahan replikasi atau kerusakan data pada replika.
- Seperti yang saya katakan Donor, sebuah node tidak dapat melayani klien dengan baik. Harus diingat bahwa dalam kluster tiga node, situasi mungkin terjadi ketika satu node telah terbang keluar, yang kedua adalah donor dan hanya satu node yang tersisa untuk layanan pelanggan.
Kesimpulan
Setelah migrasi dan beberapa waktu operasi, kami sampai pada kesimpulan berikut.
- Cluster Galera bekerja dan cukup stabil (setidaknya selama tidak ada tetes node yang abnormal atau perilaku abnormal mereka). Dalam hal toleransi kesalahan, kami mendapatkan apa yang kami inginkan.
- Pernyataan multi-master Percona utamanya adalah pemasaran. Ya, dimungkinkan untuk menggunakan cluster dalam mode ini, tetapi ini akan membutuhkan perubahan mendalam dari aplikasi untuk model penggunaan ini.
- Tidak ada replikasi sinkron, tetapi sekarang kami mengontrol jeda node maksimum (dalam transaksi). Bersama dengan batasan ukuran transaksi maksimum 50 MB, kita dapat memprediksi secara akurat waktu jeda maksimum node. Menjadi lebih mudah bagi pengembang untuk menulis kode.
- Dalam pemantauan, kami mengamati puncak jangka pendek dalam pertumbuhan antrian replikasi. Alasannya ada di jaringan 1 Gbit / s kami. Dimungkinkan untuk mengoperasikan kluster pada jaringan seperti itu, tetapi masalah muncul selama semburan beban. Sekarang kami berencana untuk meningkatkan jaringan ke 10 Gbit / dtk.
Total tiga "Wishlist" yang kami terima sekitar satu setengah. Persyaratan yang paling penting adalah toleransi kesalahan.
File konfigurasi PXC kami untuk mereka yang tertarik:
my.cnf[mysqld]
#Main
server-id = 1
datadir = /var/lib/mysql
socket = mysql.sock
port = 3302
pid-file = mysql.pid
tmpdir = /tmp
large_pages = 1
skip_slave_start = 1
read_only = 0
secure-file-priv = /tmp/
#Engine
innodb_numa_interleave = 1
innodb_flush_method = O_DIRECT
innodb_flush_log_at_trx_commit = 2
innodb_file_format = Barracuda
join_buffer_size = 1048576
tmp-table-size = 512M
max-heap-table-size = 1G
innodb_file_per_table = 1
sql_mode = "NO_ENGINE_SUBSTITUTION,NO_AUTO_CREATE_USER,ERROR_FOR_DIVISION_BY_ZERO"
default_storage_engine = InnoDB
innodb_autoinc_lock_mode = 2
#Wsrep
wsrep_provider = "/usr/lib64/galera3/libgalera_smm.so"
wsrep_cluster_address = "gcomm://192.168.0.1:4577,192.168.0.2:4577,192.168.0.3:4577"
wsrep_cluster_name = "prod"
wsrep_node_name = node1
wsrep_node_address = "192.168.0.1"
wsrep_sst_method = xtrabackup-v2
wsrep_sst_auth = "USER:PASS"
pxc_strict_mode = ENFORCING
wsrep_slave_threads = 64
wsrep_sst_receive_address = "192.168.0.1:4444"
wsrep_max_ws_size = 50M
wsrep_retry_autocommit = 2
wsrep_provider_options = "gmcast.listen_addr=tcp://192.168.0.1:4577; ist.recv_addr=192.168.0.1:4578; gcache.size=30G; pc.checksum=true; evs.version=1; evs.auto_evict=5; gcs.fc_limit=80; gcs.fc_factor=0.75; gcs.max_packet_size=64500;"
#Binlog
expire-logs-days = 4
relay-log = mysql-relay-bin
log_slave_updates = 1
binlog_format = ROW
binlog_row_image = minimal
log_bin = mysql-bin
log_bin_trust_function_creators = 1
#Replication
slave-skip-errors = OFF
relay_log_info_repository = TABLE
relay_log_recovery = ON
master_info_repository = TABLE
gtid-mode = ON
enforce-gtid-consistency = ON
#Cache
query_cache_size = 0
query_cache_type = 0
thread_cache_size = 512
table-open-cache = 4096
innodb_buffer_pool_size = 72G
innodb_buffer_pool_instances = 36
key_buffer_size = 16M
#Logging
log-error = /var/log/stdout.log
log_error_verbosity = 1
slow_query_log = 0
long_query_time = 10
log_output = FILE
innodb_monitor_enable = "all"
#Timeout
max_allowed_packet = 512M
net_read_timeout = 1200
net_write_timeout = 1200
interactive_timeout = 28800
wait_timeout = 28800
max_connections = 22000
max_connect_errors = 18446744073709551615
slave-net-timeout = 60
#Static Values
ignore_db_dir = "lost+found"
[sst]
rlimit = 80m
compressor = "pigz -3"
decompressor = "pigz -dc"
backup_threads = 8
Sumber dan tautan bermanfaat
→
Gambar Docker kami→
Percona XtraDB Cluster 5.7 Dokumentasi→
Pemantauan Status Cluster - Dokumentasi Cluster Galera→
Variabel Status Galera - Dokumentasi Cluster Galera