Terjemahan dari tutorial TensorFlow Object Detection API - Pelatihan dan Mengevaluasi Custom Object Detector .Kita semua tahu cara mengendarai mobil, cukup mudah, bukan? Tapi apa yang akan Anda lakukan jika seseorang meminta Anda naik ke pesawat? Itu benar - Anda akan membaca instruksinya. Demikian juga, manual di bawah ini akan membantu Anda mengatur API Anda dan menikmati penerbangan yang menyenangkan.
Pertama-tama, klon repositori dengan
referensi . Saya harap Anda sudah menginstal
TensorFlow .
git clone github.com/tensorflow/models.gitDalam pembelajaran mesin, kami biasanya melatih dan menguji suatu model menggunakan file CSV. Tetapi dalam kasus ini, kami bertindak sesuai dengan skema yang ditunjukkan pada gambar:

Sebelum melanjutkan, mari kita memikirkan struktur direktori yang akan kita gunakan.
- data / - Ini akan berisi catatan dan file CSV.
- images / - Berikut ini adalah dataset untuk melatih model kami.
- pelatihan / - Di sini kita menyimpan model yang terlatih.
- eval / - Ini akan menyimpan hasil evaluasi model.
Langkah 1: menyimpan gambar ke CSV
Semuanya sangat sederhana di sini. Kami tidak akan mempelajari tugas ini, saya hanya akan memberikan beberapa tautan bermanfaat.
Tugas kita adalah memberi tag pada gambar dan membuat file train.CSV dan test.CSV.
- Menggunakan alat labelImg, tandai gambar. Cara melakukannya, lihat di sini .
- Konversi XML ke CSV, seperti yang ditunjukkan di sini .
Ada banyak cara untuk membuat file CSV, lebih atau kurang cocok untuk bekerja dengan setiap set data tertentu.
Sebagai bagian dari proyek kami, kami akan mencoba untuk mencapai deteksi nodus paru menggunakan
dataset LUNA . Koordinat node sudah diketahui, dan karena itu pembuatan file CSV tidak sulit. Untuk menemukan node, kami menggunakan 6 koordinat yang ditunjukkan di bawah ini:
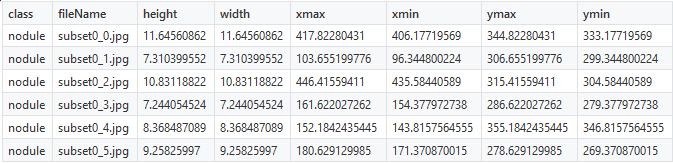
Anda harus mengoreksi hanya nama
nodules kelas (node), semua yang lain akan tetap tidak berubah. Setelah objek yang ditandai disajikan dalam bentuk angka, Anda dapat melanjutkan ke pembuatan TFRecords.
Langkah 2: buat TFRecords
API Deteksi Objek TensorFlow tidak menerima input untuk melatih model dalam format CSV, jadi Anda perlu membuat TFRecords menggunakan
file ini. """ Usage: # From tensorflow/models/ # Create train data: python generate_tfrecord.py --csv_input=data/train_labels.csv --output_path=train.record # Create test data: python generate_tfrecord.py --csv_input=data/test_labels.csv --output_path=test.record """ from __future__ import division from __future__ import print_function from __future__ import absolute_import import os import io import pandas as pd import tensorflow as tf from PIL import Image from object_detection.utils import dataset_util from collections import namedtuple, OrderedDict flags = tf.app.flags flags.DEFINE_string('csv_input', '', 'Path to the CSV input') flags.DEFINE_string('output_path', '', 'Path to output TFRecord') FLAGS = flags.FLAGS
Setelah mengunduh file, buat satu perubahan kecil: pada baris 31, alih-alih kata
raccoon beri tanda Anda sendiri. Dalam contoh yang diberikan, ini adalah
nodules , node. Jika model Anda perlu mendefinisikan beberapa jenis objek, buat kelas tambahan.
Catatan Penomoran label harus dimulai dari satu, bukan dari nol. Misalnya, jika Anda menggunakan tiga jenis objek, mereka harus diberi nilai masing-masing 1, 2, dan 3.Gunakan kode berikut untuk membuat file
train.record :
python generate_tfRecord.py --CSV_input=data/train.CSV --output_path=data/train.record
Gunakan kode berikut untuk membuat file
test.record :
python generate_tfrecord.py — CSV_input=data/test.CSV — output_path=data/test.record
Langkah 3: pelatihan model
Setelah file yang kita butuhkan dibuat, kita hampir siap untuk mulai belajar.
- Pilih model yang akan diajarkan. Anda harus menemukan kompromi antara kecepatan dan akurasi: semakin tinggi kecepatan, semakin rendah keakuratan tekad, dan sebaliknya. Di sini,
sd_mobilenet_v1_coco digunakan sebagai contoh. - Setelah memutuskan model mana yang akan Anda gunakan, unduh file konfigurasi yang sesuai . Dalam contoh ini, ini adalah
ssd_mobilenet_v1_coco.config . - Buat file object-detection.pbtxt yang terlihat seperti ini:
item { id: 1 name: 'nodule' }
Beri nodule nama yang berbeda. Jika ada beberapa kelas, tambah nilai id dan masukkan nama baru.
Saatnya mengkonfigurasi file konfigurasi, membuat penyesuaian berikut.
Ubah jumlah kelas sesuai dengan kebutuhan Anda.
Jika kekuatan GPU Anda tidak mencukupi, turunkan nilai
batch_size .
batch_size: 24
Tentukan jalur ke model
ssd_mobilenet_v1_coco yang kami unduh sebelumnya.
Tentukan path ke file
train.record .
Tentukan path ke file
test.record.
Sekarang salin
data / dan
gambar / folder ke folder
model / penelitian / deteksi objek . Jika Anda diminta untuk menggabungkan folder, terima folder itu.
Selain itu, kita akan membutuhkan file
train.py yang terletak di
direktori deteksi objek /
. cd models/research/object-detection
Buat
pelatihan / folder di
objek-deteksi / folder
. Itu dalam
pelatihan / kami akan menyimpan model kami. Salin
ssd_mobilenet_v1_coco.config ke file
pelatihan / konfigurasi. Pelatihan dilakukan dengan menggunakan perintah:
python train.py --logtostderr \ --train_dir=training/ \ --pipeline_config_path=training/ssd_mobilenet_v1_coco.config
Jika semuanya berjalan sesuai rencana, Anda akan melihat bagaimana fungsi kerugian berubah di setiap tahap.
Langkah 4: Evaluasi Model
Akhirnya, kami mengevaluasi model yang disimpan dalam direktori
pelatihan / . Untuk melakukan ini, jalankan file
eval.py dan masukkan perintah berikut:
python eval.py \ --logtostderr \ --pipeline_config_path=training/ssd_mobilenet_v1_coco.config \ --checkpoint_dir=training/ \ --eval_dir=eval/
Hasil verifikasi akan tercermin dalam folder
/ eval . Mereka dapat divisualisasikan menggunakan TensorBoard.
Buka tautan melalui browser. Di tab
Gambar , Anda akan melihat hasil model:
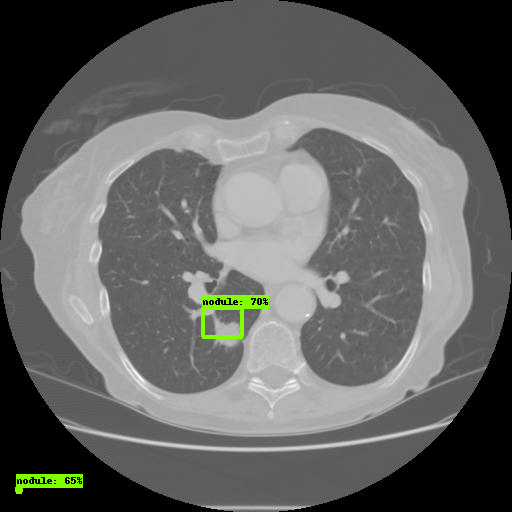
Itu saja, Anda telah berhasil mengonfigurasi API Deteksi Objek TensorFlow.
Salah satu kesalahan paling umum:
No module named deployment on object_detection/train.pyItu dipecahkan menggunakan perintah:
Anda dapat membaca tentang cara mengubah parameter Faster-RCNN / SSD di
sini .
Terima kasih atas perhatian anda!