Ruang Dunia sekitarnya dipenuhi dengan peristiwa individu dan rantai mereka - peristiwa ini tercermin di media, di akun blogger dan orang-orang biasa di jejaring sosial. Gambaran tentang realitas di sekitarnya, yang mengklaim tingkat objektivitas tertentu, hanya dapat diperoleh jika kita mengumpulkan sudut pandang berbeda tentang masalah yang sama. Pengkategorisasi acara adalah alat yang “mengumpulkan” informasi yang dikumpulkan: versi deskripsi peristiwa. Selanjutnya, berikan akses ke informasi tentang acara kepada pengguna melalui alat pencarian, rekomendasi, dan representasi visual dari urutan waktu peristiwa.
Hari ini kita akan berbicara tentang sistem kita, lebih tepatnya tentang inti perangkat lunaknya, dengan nama kode "Varya" - untuk menghormati pengembang utama.
Kami belum dapat menyebutkan nama startup kami, atas permintaan administrasi Habrahabr, sekarang kami telah mengirimkan aplikasi untuk menetapkan status Startup. Namun, kami dapat memberi tahu Anda tentang fungsionalitas dan gagasan kami sekarang. Sistem kami memastikan relevansi informasi acara dengan pengguna dan manajemen data yang kompeten - dalam sistem, setiap pengguna sendiri menentukan apa yang harus ditonton dan dibaca, mengontrol pencarian dan rekomendasi.
Proyek kami adalah startup dengan tim 8 orang dengan kompetensi dalam desain sistem, pemrograman, pemasaran, dan manajemen yang kompleks secara teknis dan algoritmik.
Bersama-sama, setiap hari tim bekerja pada proyek - algoritma untuk mengkategorikan, mencari dan menyajikan informasi telah dilaksanakan. Implementasi algoritma yang terkait dengan rekomendasi untuk pengguna masih di depan: berdasarkan hubungan peristiwa, orang, dan analisis aktivitas dan minat pengguna.
Tugas apa yang kita selesaikan dan mengapa kita membicarakannya? Kami membantu orang mendapatkan informasi terperinci tentang peristiwa dalam skala apa pun, di mana pun dan kapan pun peristiwa itu terjadi.
Proyek ini memberi pengguna sebuah platform untuk mendiskusikan berbagai peristiwa dalam lingkaran orang-orang yang berpikiran sama, memungkinkan Anda untuk membagikan komentar atau versi Anda sendiri tentang apa yang terjadi. Platform media sosial diciptakan untuk mereka yang ingin tahu "di atas rata-rata" dan memiliki pendapat pribadi tentang peristiwa utama masa lalu, sekarang dan masa depan.
Pengguna sendiri menemukan dan membuat konten yang bermanfaat di ruang media dan memantau keandalannya. Kami menyimpan kenangan tentang peristiwa kehidupan mereka.
Sekarang proyek ini pada tahap MVP, kami menguji hipotesis tentang fungsi dan pekerjaan pengkategorisasi untuk menentukan arah yang tepat untuk pengembangan lebih lanjut. Dalam artikel ini kita akan berbicara tentang teknologi yang dengannya kita menyelesaikan tugas kita dan berbagi praktik terbaik kita.
Tugas pemrosesan kata mesin diselesaikan oleh mesin pencari: Yandex, Google, Bing, dll. Sistem yang ideal untuk bekerja dengan arus informasi dan mengisolasi peristiwa di dalamnya dapat terlihat sebagai berikut.
Infrastruktur mirip dengan Yandex dan Google dibangun untuk sistem, seluruh Internet dipindai secara real time untuk pembaruan, dan kemudian dalam aliran informasi dialokasikan kernel acara, di mana aglomerasi versi mereka dan konten terkait terbentuk. Implementasi perangkat lunak layanan ini didasarkan pada jaringan saraf pembelajaran yang dalam dan / atau solusi yang didasarkan pada perpustakaan Yandex - CatBoost.
Keren Namun, kami belum memiliki volume data yang demikian, dan tidak ada sumber daya komputasi yang sesuai untuk asimilasi.
Klasifikasi berdasarkan topik adalah tugas yang populer, ada banyak algoritma untuk menyelesaikannya: pengklasifikasi naif Bayes, penempatan Dirichlet laten, meningkatkan pohon keputusan dan jaringan saraf. Seperti, mungkin, dalam semua masalah pembelajaran mesin, saat menggunakan algoritma yang dijelaskan, dua masalah muncul:
Pertama, dari mana mendapatkan banyak data?
Kedua, bagaimana menempatkannya dengan murah dan marah?
Pendekatan apa yang kami pilih untuk sistem berbasis acara?
Produk kami berfungsi dengan acara. Peristiwa agak berbeda dari artikel biasa.
Untuk mengatasi "awal yang dingin", kami memutuskan untuk menggunakan dua proyek WikiMedia: Wikipedia dan Wikinews. Satu artikel Wikipedia dapat menggambarkan beberapa peristiwa (misalnya, sejarah pengembangan Sun Microsystems, biografi Mayakovsky, atau perjalanan Perang Patriotik Hebat).
Sumber informasi acara lainnya adalah umpan RSS. Berita itu terjadi dengan cara yang berbeda: artikel analitis besar berisi beberapa peristiwa, seperti teks Wikipedia, dan pesan informasi pendek dari berbagai sumber mewakili peristiwa yang sama.
Dengan demikian, artikel dan acara membentuk hubungan banyak-ke-banyak. Tetapi pada tahap MVP, kami membuat asumsi bahwa satu artikel adalah satu peristiwa.
Melihat antarmuka Google atau Yandex, Anda mungkin berpikir bahwa mesin pencari hanya mencari kata kunci. Ini hanya untuk pengecer online yang sangat sederhana. Sebagian besar mesin pencari adalah multi-kriteria, dan mesin proyek kami tidak terkecuali. Selain itu, jauh dari semua parameter yang diperhitungkan selama pencarian ditampilkan di antarmuka pengguna. Proyek kami memiliki daftar parameter yang dipilih pengguna, seperti:
topik dan kata kunci -
"apa?" ; lokasi -
"di mana?" ; tanggal -
"kapan?" ;
Mereka yang menulis mesin pencari tahu bahwa kata kunci saja menyebabkan banyak masalah. Nah, sisa opsi juga tidak begitu sederhana.
Pokok bahasan acara tersebut adalah hal yang sangat sulit. Otak manusia dirancang sedemikian rupa sehingga ia suka mengategorikan segala sesuatu, dan dunia nyata sangat tidak setuju dengan ini. Artikel yang masuk ingin membentuk kelompok topik mereka sendiri, dan itu sama sekali bukan yang kami dan pengguna antusias kami distribusikan.
Kami sekarang memiliki 15 topik utama acara, dan daftar ini telah direvisi beberapa kali, dan, setidaknya, akan tumbuh.
Lokasi dan tanggal diatur sedikit lebih formal, tetapi di sini ada jebakan.
Jadi, kami memiliki seperangkat kriteria formal dan data mentah yang kami perlukan untuk memetakan kriteria ini. Dan inilah cara kami melakukannya.
Laba-laba
Tugas laba-laba adalah melipat artikel yang masuk sehingga mereka dapat dengan cepat dicari. Untuk melakukan ini, laba-laba harus dapat mengaitkan topik, lokasi dan tanggal dengan artikel, serta beberapa parameter lain yang diperlukan untuk peringkat. Input spider kami menerima model teks dari artikel yang dibuat oleh crawler. Model teks adalah daftar bagian-bagian artikel dan teks-teks yang sesuai. Misalnya, hampir setiap artikel setidaknya memiliki judul dan teks isi. Bahkan, dia masih memiliki paragraf pertama, seperangkat kategori yang merujuk teks ini ke sumbernya, dan daftar bidang kotak info (untuk Wikipedia dan sumber yang memiliki tag metadata seperti itu). Masih ada tanggal publikasi. Untuk peringkat di mesin pencari, penting bagi kita untuk mengetahui apakah, misalnya, tanggal ditemukan di header atau di suatu tempat di akhir teks. Model teks digunakan untuk membangun model topik, model lokasi, dan model tanggal, dan kemudian hasilnya ditambahkan ke indeks. Artikel terpisah dapat ditulis tentang masing-masing model ini, jadi di sini kami hanya akan menjelaskan secara singkat pendekatannya.
Tema
Menentukan subjek dokumen adalah tugas yang umum. Subjek dapat dikaitkan secara manual oleh penulis dokumen, atau dapat ditentukan secara otomatis. Tentu saja, kami memiliki topik yang sumber berita dan Wikipedia dikaitkan dengan dokumen kami, tetapi topik ini bukan tentang acara. Apakah Anda sering menemukan topik "Liburan" di feed berita? Sebaliknya, Anda akan memenuhi tema "Masyarakat." Kami juga memiliki ini di salah satu edisi paling awal. Kami tidak dapat menentukan apa yang harus dikaitkan dengan itu, dan dipaksa untuk menghapusnya. Dan di samping itu, semua sumber memiliki serangkaian topik mereka sendiri.
Kami ingin mengelola daftar topik yang ditampilkan kepada pengguna kami di antarmuka, jadi bagi kami tugas menentukan topik dokumen adalah tugas klasifikasi fuzzy. Tugas klasifikasi memerlukan contoh berlabel, yaitu daftar dokumen yang telah dikaitkan dengan topik yang kita inginkan. Daftar kami mirip dengan semua daftar topik yang serupa, tetapi tidak sesuai dengan mereka, jadi kami tidak memiliki sampel berlabel. Anda juga bisa mendapatkannya secara manual atau otomatis, tetapi jika daftar topik kami berubah (dan itu akan!), Maka secara manual bukan merupakan pilihan.
Jika Anda tidak memiliki sampel berlabel, Anda dapat menggunakan penempatan Dirichlet laten dan algoritme pemodelan tematik lainnya, namun, himpunan yang Anda dapatkan akan menjadi yang dihasilkan, dan bukan yang Anda inginkan.
Di sini kita harus menyebutkan satu hal lagi: artikel kami berasal dari sumber yang berbeda. Semua model tematik dibangun satu atau lain cara berdasarkan kosakata yang digunakan. Untuk berita dan Wikipedia, itu berbeda, berbeda bahkan frekuensi tinggi yang diayak.
Jadi, kami menghadapi dua tugas:
1. Carilah cara untuk dengan cepat meletakkan dokumen kami dalam mode semi-otomatis.
2. Bangun model topik yang bisa dikembangkan berdasarkan pada dokumen-dokumen ini.
Untuk mengatasinya, kami membuat algoritma hybrid yang berisi tahapan otomatis dan manual yang ditunjukkan pada gambar.
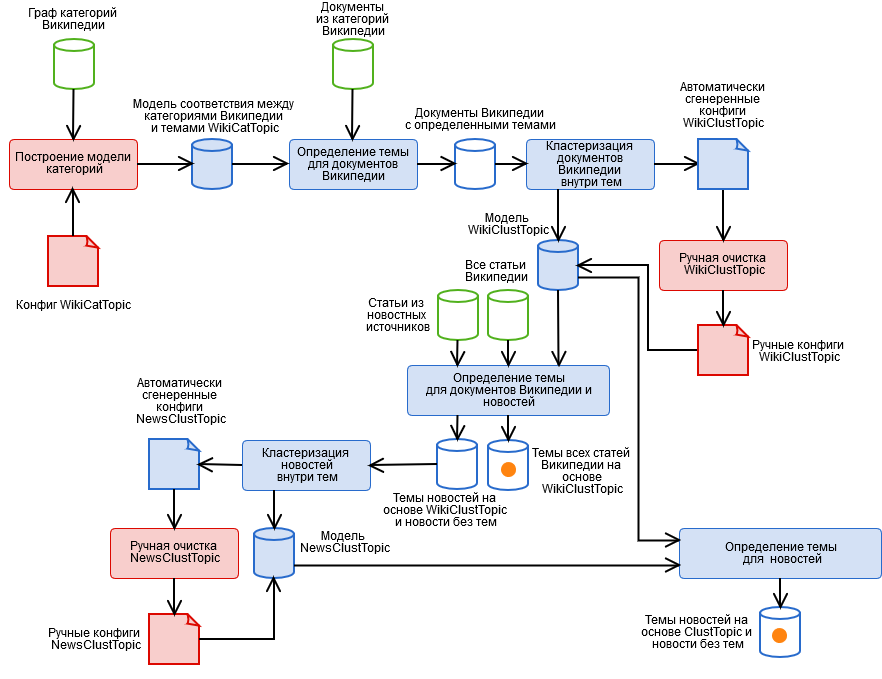
- Markup kategori Wikipedia manual dan mendapatkan model tema kategori WikiCatTopic. Pada tahap ini, konfigurasi dibangun yang memberikan subgraph dari kategori WT Wikipedia untuk setiap topik T kami. Wikipedia adalah pseudo-ontologi. Ini berarti bahwa jika sesuatu masuk ke dalam kategori "Sains", itu mungkin bukan tentang sains sama sekali, misalnya, dari subkategori "Teknologi Informasi" yang tidak berbahaya, Anda sebenarnya dapat mengunjungi artikel Wikipedia mana pun. Artikel terpisah diperlukan tentang cara hidup dengan ini.
- Secara otomatis mendeteksi topik untuk dokumen Wikipedia berdasarkan WikiCatTopic. Dokumen ini diberikan topik T jika termasuk dalam salah satu kategori grafik CT. Perhatikan bahwa metode ini hanya berlaku untuk artikel Wikipedia. Untuk menggeneralisasi definisi topik menjadi teks sewenang-wenang, dimungkinkan untuk membuat sekumpulan kata-kata dari setiap topik, dan mempertimbangkan jarak kosinus ke topik (dan kami mencoba, tidak ada yang baik), tetapi di sini tiga hal harus diperhitungkan.
- Topik semacam itu mengandung artikel yang sangat beragam, sehingga gambar topik dalam ruang kata tidak akan koheren, yang berarti bahwa "kepercayaan" model semacam itu dalam menentukan topik sangat rendah (setelah semua, artikel mirip dengan satu set kecil artikel, tetapi tidak untuk sisanya).
- Teks sewenang-wenang, terutama berita, berbeda dalam komposisi leksikal dari Wikipedia, ini juga tidak menambah model "kepastian". Selain itu, beberapa topik tidak dapat dibangun di Wikipedia.
- Tahap 1 adalah pekerjaan yang sangat melelahkan, dan semua orang terlalu malas untuk melakukannya.
- Klaster dokumen dalam topik berdasarkan hasil paragraf 2 menggunakan metode k-means dan mendapatkan model kluster tema WikiClustTopic. Sebuah langkah yang cukup sederhana, yang memungkinkan kami untuk memecahkan dua dari tiga masalah dari paragraf 2. Untuk klaster, kami membuat sekumpulan kata-kata, dan menjadi bagian dari suatu topik didefinisikan sebagai jarak kosinus maksimum ke klusternya. Model ini dijelaskan dalam file konfigurasi kami korespondensi antara cluster dan dokumen Wikipedia.
- Pembersihan manual model WikiClustTopic, memungkinkan-nonaktifkan-transfer cluster. Di sini kami juga kembali ke tahap 1, ketika kluster yang sepenuhnya salah ditemukan.
- Secara otomatis mendeteksi topik WikiClustTopic untuk dokumen dan berita Wikipedia.
- Mengelompokkan berita dalam topik berdasarkan hasil paragraf 5 menggunakan metode k-means, serta berita yang tidak menerima topik, dan mendapatkan model kluster topik NewsClustTopic. Sekarang kami memiliki model tema yang memperhitungkan spesifik berita (serta informasi yang tak ternilai tentang kualitas pekerjaan perayap).
- Pembersihan manual model NewsClustTopic.
- Memetakan kembali topik berita berdasarkan model terintegrasi ClustTopic = WikiClustTopic + NewsClustTopic. Berdasarkan model ini, topik dokumen baru ditentukan.
Lokasi
Penentuan lokasi otomatis adalah kasus khusus dari tugas mencari entitas bernama. Fitur di lokasi adalah sebagai berikut:
- Semua daftar lokasi berbeda dan tidak cocok bersama. Kami membangun sendiri, hibrid, yang memperhitungkan tidak hanya hierarki (Rusia termasuk wilayah Novosibirsk), tetapi juga perubahan nama historis (misalnya, RSFSR menjadi Rusia) berdasarkan: Geonames, Wikidata, dan sumber terbuka lainnya. Namun, kami masih harus menulis konverter geotag dengan Google Maps :)
- Beberapa lokasi terdiri dari beberapa kata, misalnya, Nizhny Novgorod, dan Anda harus dapat mengoleksinya.
- Lokasi mirip dengan kata-kata lain, terutama nama-nama mereka yang menghormatinya: Kirov, Zhukov, Vladimir. Ini homonim. Untuk mengatasinya, kami mengumpulkan statistik pada artikel Wikipedia yang menguraikan permukiman, di mana konteksnya nama-nama lokasi ditemukan, dan juga mencoba membuat daftar homonim seperti itu menggunakan kamus Open Corpora.
- Umat manusia tidak terlalu membebani imajinasi, dan banyak tempat dinamai sama. Contoh favorit kami: Karasuk di Kazakhstan dan di Rusia, dekat Novosibirsk. Ini homonim di dalam kelas lokasi. Kami menyelesaikannya, dengan mempertimbangkan lokasi lain yang ditemukan dengan yang ini, dan apakah mereka adalah orang tua atau anak untuk salah satu homonim. Heuristik ini tidak universal, tetapi bekerja dengan baik.
Tanggal
Tanggal - perwujudan formalitas dibandingkan dengan Tema dan Lokasi. Kami membuat parser yang dapat diperluas untuk mereka dengan ekspresi reguler, dan kami dapat mengurai tidak hanya hari-bulan-tahun, tetapi juga segala macam hal yang lebih menarik, seperti "akhir musim dingin 1941", "di tahun 90-an abad XIX" dan "bulan lalu ”, Memperhatikan era dan tanggal dasar dokumen, serta berusaha mengembalikan tahun yang hilang. Tentang kencan Anda perlu tahu bahwa tidak semuanya baik. Misalnya, di akhir artikel tentang pertempuran Perang Dunia Kedua, mungkin ada pembukaan memorial empat puluh tahun kemudian, untuk menangani kasus-kasus seperti itu, Anda perlu memotong artikel itu menjadi peristiwa, tetapi kami belum melakukannya. Jadi kami hanya mempertimbangkan tanggal yang paling penting: dari pos dan paragraf pertama.
Mesin pencari
Mesin pencari adalah alat yang, pertama, mencari dokumen berdasarkan permintaan, dan kedua, mengaturnya dalam urutan yang relevan dengan permintaan, yaitu, dalam mengurangi relevansi. Untuk menghitung relevansi, kami menggunakan banyak parameter, lebih dari sekadar trivance:
Sejauh mana dokumen itu termasuk dalam topik.
Tingkat kepemilikan dokumen lokasi (berapa kali dan di bagian mana dokumen ditemukan lokasi yang dipilih).
Sejauh mana dokumen cocok dengan tanggal (memperhitungkan jumlah hari di persimpangan interval dari permintaan dan tanggal dokumen, serta jumlah hari di persimpangan dikurangi serikat pekerja).
Panjang dokumen. Artikel panjang harus lebih tinggi.
Kehadiran gambar. Semua orang suka gambar, harus ada lebih banyak!
Jenis artikel Wikipedia. Kami dapat memisahkan artikel dengan deskripsi acara, dan artikel tersebut harus “menyembul” dalam sampel.
Sumber artikel. Berita dan artikel khusus harus lebih tinggi dari Wikipedia.
Sebagai mesin pencari, kami menggunakan Apache Lucene.
Crawler
Tugas crawler adalah mengumpulkan artikel untuk laba-laba. Dalam kasus kami, di sini kami juga menyertakan pembersihan utama teks, dan pembangunan model teks dokumen. Crawler berhak mendapatkan artikel terpisah.
PS Kami menyambut umpan balik, kami mengundang Anda untuk menguji proyek kami - untuk menerima tautan, menulis dalam pesan pribadi (kami tidak dapat menerbitkan di sini). Tinggalkan komentar Anda di bawah artikel, atau jika Anda mendapatkan layanan kami - di sana, melalui formulir umpan balik.