Ketika orang mencari gambar atau video di Internet, mereka sering menambahkan frasa "berkualitas baik." Kualitas biasanya mengacu pada resolusi - pengguna ingin gambar menjadi besar dan pada saat yang sama terlihat bagus di layar komputer modern, smartphone atau TV. Tetapi bagaimana jika sumber dalam kualitas yang baik tidak ada?
Hari ini kami akan memberi tahu pembaca Habr tentang bagaimana, dengan bantuan jaringan saraf, kami dapat meningkatkan resolusi video secara real time. Anda juga akan belajar bagaimana pendekatan teoretis untuk menyelesaikan masalah ini berbeda dari yang praktis. Jika Anda tidak tertarik dengan perincian teknis, maka Anda dapat dengan aman menelusuri pos - pada akhirnya Anda akan menemukan contoh pekerjaan kami.

Ada banyak konten video di Internet dalam kualitas dan resolusi rendah. Ini bisa berupa film yang direkam beberapa dekade yang lalu, atau menyiarkan saluran TV, yang karena berbagai alasan tidak dalam kualitas terbaik. Saat pengguna merentangkan video seperti itu ke layar penuh, gambar menjadi keruh dan kabur. Solusi ideal untuk film-film lama adalah menemukan film aslinya, memindai dengan peralatan modern dan mengembalikannya secara manual, tetapi ini tidak selalu memungkinkan. Siaran masih lebih rumit - mereka harus diproses secara langsung. Dalam hal ini, opsi yang paling dapat diterima bagi kita untuk bekerja adalah meningkatkan resolusi dan membersihkan artefak menggunakan teknologi visi komputer.
Dalam industri ini, tugas meningkatkan gambar dan video tanpa kehilangan kualitas disebut istilah super-resolusi. Banyak artikel telah ditulis tentang topik ini, tetapi kenyataan dari aplikasi "pertarungan" ternyata jauh lebih rumit dan menarik. Secara singkat tentang masalah utama yang harus kami pecahkan dalam teknologi DeepHD kami sendiri:
- Anda harus dapat mengembalikan detail yang tidak ada di video asli karena resolusi dan kualitasnya yang rendah, untuk "menyelesaikannya".
- Solusi dari area super-resolusi mengembalikan detail, tetapi mereka membuat jelas dan terperinci tidak hanya objek dalam video, tetapi juga artefak kompresi, yang menyebabkan ketidaksukaan bagi penonton.
- Ada masalah dengan pengumpulan sampel pelatihan - sejumlah besar pasangan diperlukan di mana video yang sama hadir dalam resolusi dan kualitas rendah, dan dalam tinggi. Pada kenyataannya, biasanya tidak ada pasangan berkualitas untuk konten yang buruk.
- Solusinya harus bekerja secara real time.
Pemilihan teknologi
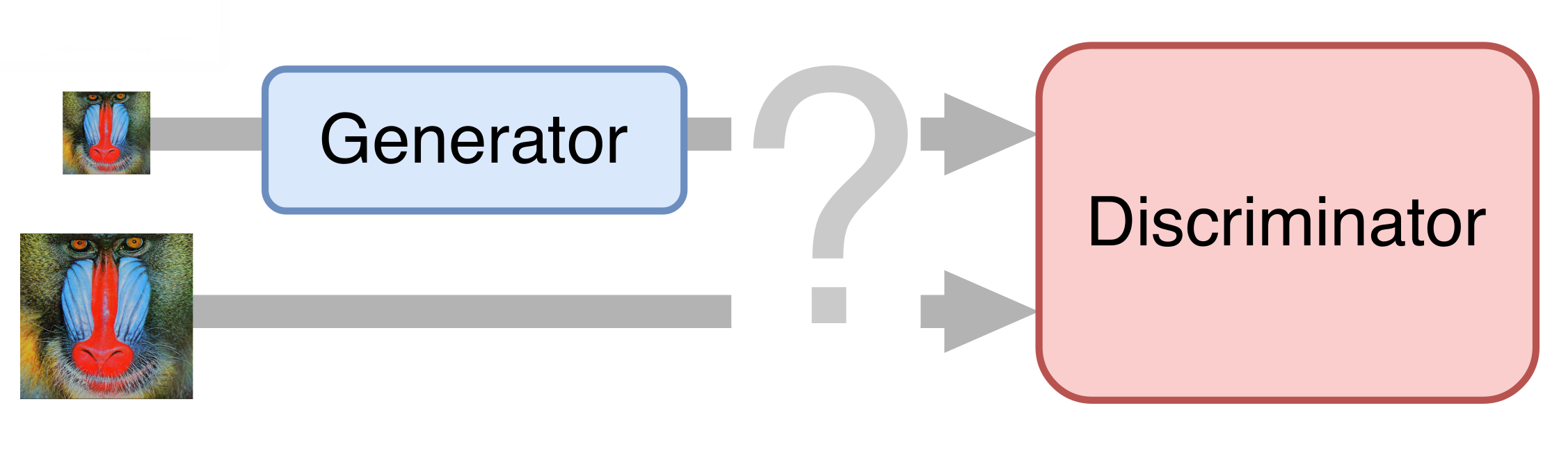
Dalam beberapa tahun terakhir, penggunaan jaringan saraf telah menyebabkan keberhasilan yang signifikan dalam menyelesaikan hampir semua tugas penglihatan komputer, dan tugas super-resolusi tidak terkecuali. Kami menemukan solusi paling menjanjikan berdasarkan GAN (Generative Adversarial Networks, generative networks saingan). Mereka memungkinkan Anda untuk mendapatkan gambar fotorealistik definisi tinggi, melengkapi mereka dengan detail yang hilang, misalnya, menggambar rambut dan bulu mata pada gambar orang.

Dalam kasus paling sederhana, jaringan saraf terdiri dari dua bagian. Bagian pertama - generator - mengambil gambar input dan mengembalikan pembesaran dua kali lipat. Bagian kedua - pembeda - menerima gambar yang dihasilkan dan "nyata" sebagai input, dan mencoba membedakannya satu sama lain.
Persiapan pelatihan
Untuk pelatihan, kami telah mengumpulkan puluhan klip dalam kualitas UltraHD. Pertama, kami menguranginya menjadi resolusi 1080p, sehingga mendapatkan contoh referensi. Lalu kami membagi dua video-video ini, mengompresnya pada bitrate berbeda sepanjang jalan untuk mendapatkan sesuatu yang mirip dengan video nyata dalam kualitas rendah. Kami membagi video yang dihasilkan menjadi bingkai dan menggunakannya sedemikian rupa untuk melatih jaringan saraf.
Deblocking
Tentu saja, kami ingin mendapatkan solusi ujung ke ujung: untuk melatih jaringan saraf untuk menghasilkan video resolusi tinggi dan kualitas langsung dari aslinya. Namun, GAN ternyata sangat berubah-ubah dan terus-menerus mencoba untuk memperbaiki artefak kompresi, daripada menghilangkannya. Karena itu, saya harus memecah proses menjadi beberapa tahap. Yang pertama adalah penindasan artefak kompresi video, juga dikenal sebagai deblocking.
Contoh salah satu metode rilis:

Pada tahap ini, kami meminimalkan deviasi standar antara frame yang dihasilkan dan yang asli. Jadi, meskipun kami meningkatkan resolusi gambar, kami tidak mendapatkan peningkatan nyata dalam resolusi karena regresi ke rata-rata: jaringan saraf, tidak tahu di mana piksel tertentu perbatasan tertentu dalam gambar dilewati, dipaksa untuk rata-rata beberapa opsi, mendapatkan hasil yang buram. Hal utama yang kami capai pada tahap ini adalah penghapusan artefak kompresi video, sehingga jaringan generatif pada tahap berikutnya hanya diperlukan untuk meningkatkan kejelasan dan menambahkan detail kecil yang hilang, tekstur. Setelah ratusan percobaan, kami memilih arsitektur yang optimal dalam hal kinerja dan kualitas, samar-samar mengingatkan pada arsitektur
DRCN :
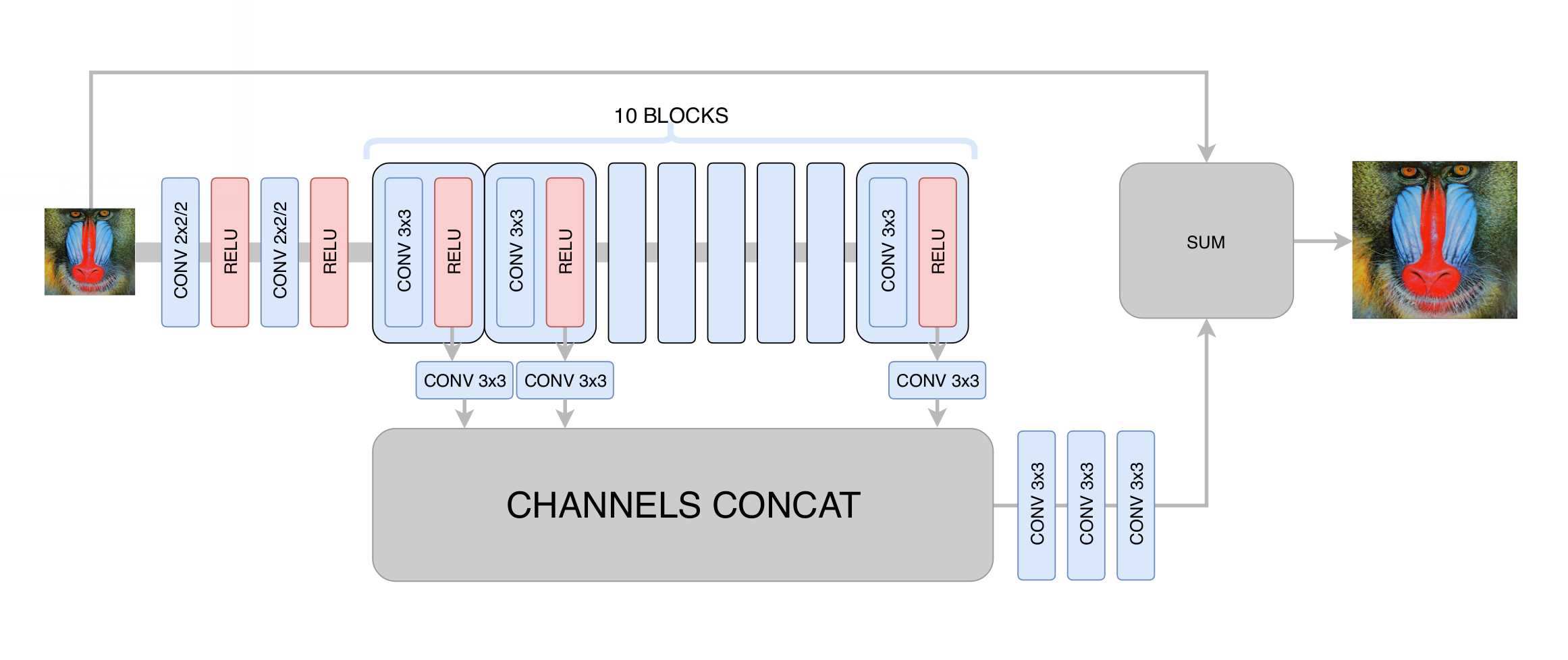
Ide utama dari arsitektur semacam itu adalah keinginan untuk mendapatkan arsitektur yang paling dalam, sementara tidak mengalami masalah dengan konvergensi dalam pelatihannya. Di satu sisi, setiap lapisan konvolusional berikutnya mengekstraksi fitur gambar input yang lebih dan lebih kompleks, yang memungkinkan Anda untuk menentukan objek seperti apa pada titik tertentu dalam gambar dan mengembalikan bagian yang kompleks dan rusak parah. Di sisi lain, jarak dalam grafik jaringan saraf dari salah satu lapisannya ke pintu keluar tetap kecil, yang meningkatkan konvergensi jaringan saraf dan memungkinkan untuk menggunakan sejumlah besar lapisan.
Pelatihan Jaringan Generatif
Kami mengambil arsitektur
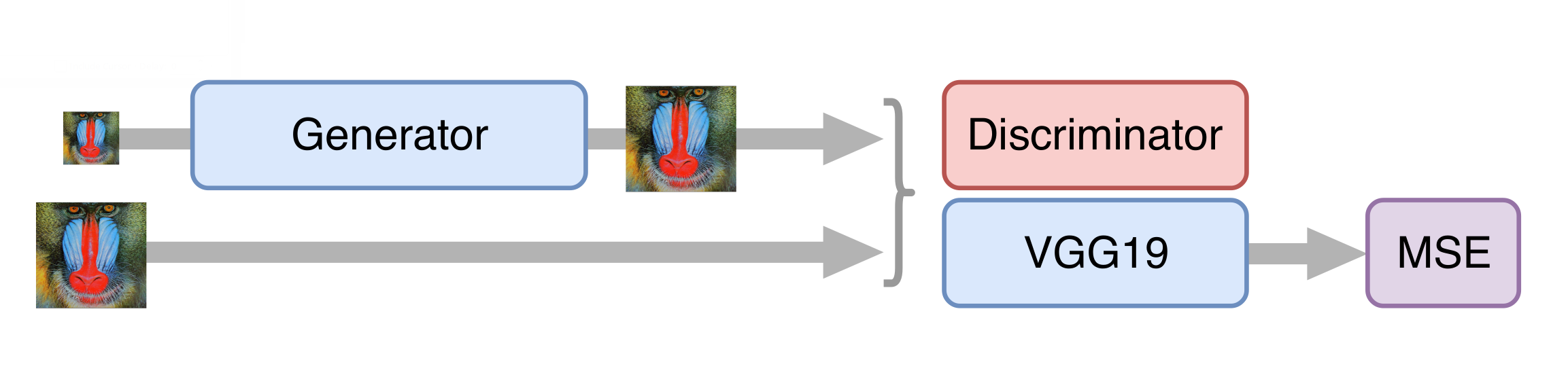
SRGAN sebagai dasar jaringan saraf untuk meningkatkan resolusi. Sebelum melatih jaringan kompetitif, Anda perlu melatih generator - melatihnya dengan cara yang sama seperti pada tahap deblocking. Kalau tidak, pada awal pelatihan, generator hanya akan menghasilkan suara, pembeda akan segera mulai "menang" - ia akan dengan mudah belajar membedakan suara dari bingkai asli, dan tidak ada pelatihan yang akan berhasil.

Kemudian kami melatih GAN, tetapi ada beberapa nuansa. Penting bagi kita bahwa generator tidak hanya menciptakan bingkai fotorealistik, tetapi juga menyimpan informasi yang tersedia pada mereka. Untuk melakukan ini, kami menambahkan fungsi kehilangan konten ke arsitektur GAN klasik. Ini mewakili beberapa lapisan jaringan saraf VGG19 yang dilatih pada dataset ImageNet standar. Lapisan-lapisan ini mengubah gambar menjadi peta fitur yang berisi informasi tentang isi gambar. Fungsi kehilangan meminimalkan jarak antara kartu-kartu tersebut yang diperoleh dari frame asli dan yang dihasilkan. Juga, kehadiran fungsi kerugian seperti itu memungkinkan untuk tidak merusak generator pada langkah-langkah pertama pelatihan, ketika pembeda belum dilatih dan memberikan informasi yang tidak berguna.
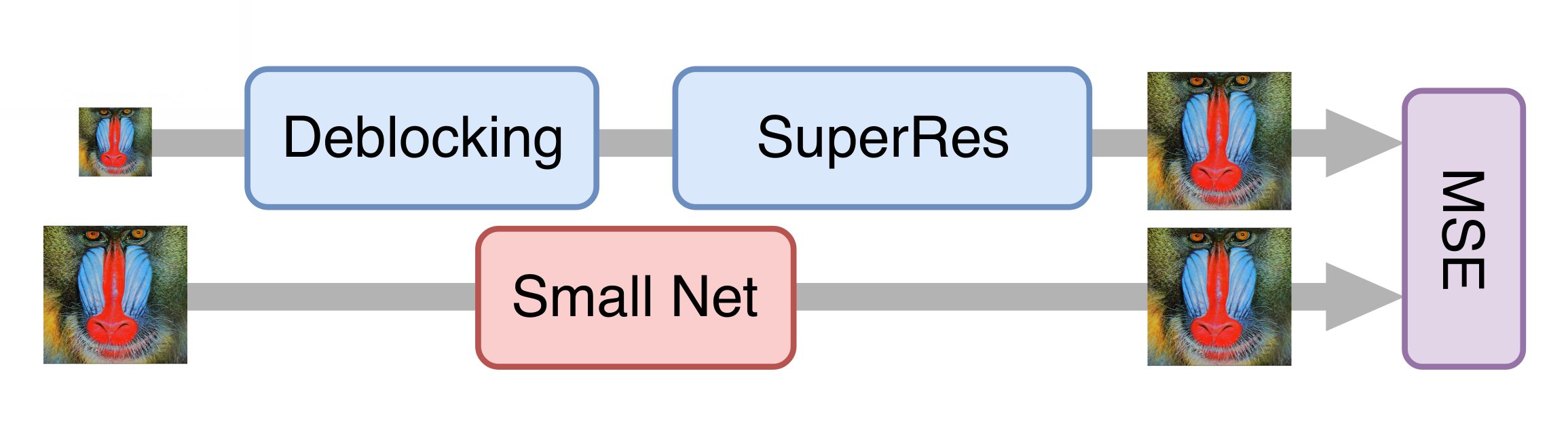
Akselerasi jaringan saraf
Semuanya berjalan dengan baik, dan setelah serangkaian percobaan, kami mendapatkan model yang bagus yang sudah bisa diterapkan pada film-film lama. Namun, masih terlalu lambat untuk memproses video streaming. Ternyata tidak mungkin hanya mengurangi generator tanpa kehilangan yang signifikan dalam kualitas model akhir. Kemudian pendekatan penyulingan pengetahuan datang membantu kami. Metode ini melibatkan pelatihan model yang lebih ringan sehingga mengulangi hasil yang lebih berat. Kami mengambil banyak video nyata dalam kualitas rendah, memprosesnya dengan jaringan saraf generatif yang diperoleh pada langkah sebelumnya, dan melatih jaringan yang lebih ringan untuk mendapatkan hasil yang sama dari frame yang sama. Karena teknik ini, kami mendapatkan jaringan yang kualitasnya tidak kalah dengan aslinya, tetapi sepuluh kali lebih cepat daripada itu: untuk memproses satu saluran TV dalam resolusi 576p, diperlukan satu kartu NVIDIA Tesla V100.
Penilaian kualitas solusi
Mungkin saat yang paling sulit ketika bekerja dengan jaringan generatif adalah penilaian kualitas model yang dihasilkan. Tidak ada fungsi kesalahan yang jelas, seperti, misalnya, ketika menyelesaikan masalah klasifikasi. Alih-alih, kami hanya mengetahui keakuratan pembeda, yang tidak mencerminkan kualitas generator yang menarik minat kami (pembaca yang terbiasa dengan bidang ini dapat menyarankan penggunaan
metrik Wasserstein , tetapi, sayangnya, hasilnya jauh lebih buruk).
Orang-orang membantu kami memecahkan masalah ini. Kami menunjukkan kepada pengguna pasangan layanan
Yandex.Tolok dari pasangan gambar, salah satunya adalah sumber satu dan yang lainnya diproses oleh jaringan saraf, atau keduanya diproses oleh versi berbeda dari solusi kami. Untuk biaya, pengguna memilih video yang lebih baik dari pasangan, jadi kami mendapat perbandingan versi yang signifikan secara statistik bahkan dengan perubahan yang sulit dilihat dengan mata. Model akhir kami menang di lebih dari 70% kasus, yang cukup banyak, mengingat pengguna hanya menghabiskan beberapa detik untuk memberi peringkat pada beberapa video.
Hasil yang menarik juga adalah fakta bahwa video dalam resolusi 576p, meningkat oleh teknologi DeepHD menjadi 720p, mengungguli video asli yang sama dengan resolusi 720p dalam 60% kasus - mis. Memproses tidak hanya meningkatkan resolusi video, tetapi juga meningkatkan persepsi visualnya.
Contohnya
Pada musim semi, kami menguji teknologi DeepHD pada beberapa film lama yang dapat ditonton di KinoPoisk: "
Rainbow " oleh Mark Donskoy (1943), "
Cranes are Flying " oleh Mikhail Kalatozov (1957), "
My Dear Man " oleh Joseph Kheifits (1958), "
The Fate of Man " Sergei Bondarchuk (1959), "
Ivan Childhood " oleh Andrei Tarkovsky (1962), "
Father of a Soldier " Rezo Chkheidze (1964) dan "
Tango of Our Childhood " oleh Albert Mkrtchyan (1985).

Perbedaan antara versi sebelum dan sesudah pemrosesan terutama terlihat jika Anda mengintip detail: pelajari ekspresi wajah para pahlawan secara close-up, pertimbangkan tekstur pakaian atau pola kain. Dimungkinkan untuk mengkompensasi beberapa kekurangan digitalisasi: misalnya, untuk menghilangkan eksposur berlebih pada wajah atau untuk membuat objek yang ditempatkan di tempat teduh lebih terlihat.
Kemudian, teknologi DeepHD mulai digunakan untuk meningkatkan kualitas siaran
beberapa saluran di layanan Yandex.Air. Mengenali konten seperti itu mudah dilakukan dengan tag
dHD .
Sekarang
di Yandex dalam kualitas yang ditingkatkan, Anda dapat menonton "Ratu Salju", "Musisi Kota Bremen", "Antelope Emas" dan kartun populer lainnya dari studio film Soyuzmultfilm. Beberapa contoh dalam dinamika dapat dilihat dalam video:
Bagi pemirsa yang menuntut, perbedaannya akan sangat mencolok: gambarnya menjadi lebih tajam, dedaunan pohon, kepingan salju, bintang di langit malam di atas hutan dan detail kecil lainnya lebih terlihat.
Lebih banyak lebih.
Tautan yang bermanfaat
Jiwon Kim, Jung Kwon Lee, Kyoung Mu Lee Jaringan Konvolusional yang Sangat Rekursif untuk Gambar Super-Resolusi [
arXiv: 1511.04491 ].
Christian Ledig et al. Foto-Realistis Gambar Tunggal Resolusi Super Menggunakan Jaringan Adversarial Generatif [
arXiv: 1609.04802 ].
Mehdi SM Sajjadi, Bernhard Schölkopf, Michael Hirsch EnhanceNet: Resolusi Super Gambar Tunggal Melalui Sintesis Tekstur Otomatis [
arXiv: 1612.07919 ].