Orang sudah lama ingin mengajar mesin untuk memahami seseorang. Namun, hanya sekarang kita sedikit lebih dekat dengan plot film fiksi ilmiah: kita dapat meminta Alice untuk mengecilkan volume, Asisten Google - memesan taksi atau Siri - mengatur alarm. Teknologi pemrosesan bahasa sangat dibutuhkan dalam pengembangan terkait dengan pembangunan kecerdasan buatan: di mesin pencari, untuk mengekstraksi fakta, menilai nada suara dari teks, terjemahan mesin dan dialog.
Kami akan berbicara tentang dua bidang terakhir: mereka memiliki sejarah yang kaya dan telah berdampak signifikan pada pemrosesan bahasa. Selain itu, kami akan berurusan dengan kemungkinan dasar pemrosesan bahasa alami saat membuat bot obrolan bersama dengan pembicara kursus kami
AI Weekend, ahli bahasa komputer Anna Vlasova.
Bagaimana semuanya dimulai?
Pembicaraan pertama tentang pemrosesan bahasa alami dengan komputer dimulai pada tahun 30-an abad ke-20 dengan alasan filosofis Ayer - ia mengusulkan untuk membedakan orang yang cerdas dari mesin yang bodoh menggunakan tes empiris. Pada tahun 1950, Alan Turing dalam jurnal filosofis
Mind mengusulkan tes di mana hakim harus menentukan dengan siapa ia berbicara: seseorang atau komputer. Menggunakan tes, kriteria ditetapkan untuk menilai pekerjaan kecerdasan buatan, kemungkinan membangunnya tidak dipertanyakan. Tes ini memiliki banyak keterbatasan dan kekurangan, tetapi memiliki dampak yang signifikan terhadap pengembangan bot obrolan.
Area pertama di mana pemrosesan bahasa berhasil diterapkan adalah terjemahan mesin. Pada tahun 1954, Universitas Georgetown bersama dengan IBM mendemonstrasikan program terjemahan mesin dari bahasa Rusia ke bahasa Inggris, yang bekerja berdasarkan kamus yang terdiri dari 250 kata dan satu set 6 aturan tata bahasa. Program itu jauh dari apa yang sebenarnya bisa disebut terjemahan mesin, dan menerjemahkan 49 penawaran yang dipilih sebelumnya di sebuah demonstrasi. Hingga pertengahan 60-an, banyak upaya dilakukan untuk membuat program terjemahan yang berfungsi penuh, tetapi pada tahun 1966 Komisi Penasihat untuk Pemrosesan Otomatis Bahasa
(ALPAC) menyatakan terjemahan mesin menjadi arah yang sia-sia. Subsidi negara berhenti untuk beberapa waktu, minat publik dalam terjemahan mesin menurun, tetapi penelitian tidak berhenti di situ.

Sejalan dengan upaya untuk mengajar komputer menerjemahkan teks, para ilmuwan dan seluruh universitas berpikir untuk membuat robot yang bisa meniru perilaku bicara manusia. Implementasi chatbot yang sukses pertama adalah lawan bicara virtual ELIZA, yang ditulis pada tahun 1966 oleh Joseph Weizenbaum. Eliza memparodikan perilaku psikoterapis, mengekstraksi kata-kata signifikan dari frasa lawan bicara dan mengajukan pertanyaan balasan. Kita dapat berasumsi bahwa ini adalah bot obrolan pertama berdasarkan aturan (bot berbasis aturan), dan meletakkan dasar bagi seluruh kelas sistem semacam itu. Pewawancara seperti Cleverbot, WeChat Xiaoice, Eugene Goostman - secara resmi lulus tes Turing pada tahun 2014 - dan bahkan Siri, Jarvis dan Alexa tidak akan muncul tanpa Eliza.
Pada tahun 1968, Terry Grapes mengembangkan program SHRDLU di LISP. Dia memindahkan benda-benda sederhana berdasarkan perintah: kerucut, kubus, bola, dan dapat mendukung konteks - dia memahami elemen mana yang perlu dipindahkan, jika itu disebutkan sebelumnya. Langkah selanjutnya dalam pengembangan bot obrolan adalah program ALICE, di mana Richard Wallace mengembangkan bahasa markup khusus - AIML
(Bahasa Markup Kecerdasan Buatan Inggris) . Kemudian, pada tahun 1995, harapan dari chatbot dilebih-lebihkan: mereka berpikir bahwa ALICE akan lebih pintar daripada seseorang. Tentu saja, chatbot tidak berhasil menjadi lebih pintar, dan untuk beberapa waktu bisnis di chatbot kecewa, dan investor untuk waktu yang lama mengesampingkan topik asisten virtual.
Masalah bahasa
Saat ini chatbots masih bekerja berdasarkan seperangkat aturan dan skenario perilaku, namun, bahasa alami tidak jelas dan ambigu, satu pemikiran dapat memiliki banyak cara presentasi, oleh karena itu, keberhasilan komersial sistem dialog tergantung pada penyelesaian masalah pemrosesan bahasa. Mesin harus diajarkan untuk mengklasifikasikan dengan jelas seluruh variasi pertanyaan yang masuk dan menafsirkannya dengan jelas.
Semua bahasa diatur secara berbeda, dan ini sangat penting untuk penguraian. Dari sudut pandang komposisi morfologis, unsur-unsur penting dari kata tersebut dapat bergabung dengan akar secara berurutan, seperti, misalnya, dalam bahasa Turki, atau mereka dapat mematahkan akar, seperti dalam bahasa Arab dan Ibrani. Dari sudut pandang sintaksis, beberapa bahasa memungkinkan urutan kata-kata bebas dalam frasa, sementara yang lain diatur lebih kaku. Dalam sistem klasik, urutan kata memainkan peran penting. Untuk metode statistik NLP modern, itu tidak memiliki nilai seperti itu, karena pemrosesan tidak terjadi pada tingkat kata, tetapi dari seluruh kalimat.
Kesulitan lain dalam pengembangan bot obrolan muncul sehubungan dengan pengembangan komunikasi multibahasa. Sekarang orang sering tidak berkomunikasi dalam bahasa asli mereka, mereka menggunakan kata-kata yang salah. Misalnya, dalam frasa "Saya telah mengirim dua hari yang lalu, tetapi barang tidak datang", dari sudut pandang kosa kata, kita harus berbicara tentang pengiriman benda fisik, misalnya barang, dan bukan tentang transaksi uang elektronik, yang dijelaskan oleh kata-kata ini oleh orang yang berbicara tidak dalam bahasa ibu. Tetapi dalam komunikasi nyata, seseorang akan memahami lawan bicara dengan benar, dan bot obrolan mungkin memiliki masalah. Dalam topik tertentu, seperti investasi, perbankan atau TI, orang sering beralih ke bahasa lain. Tetapi chatbot tidak mungkin memahami apa yang dipertaruhkan, karena kemungkinan besar dilatih dalam satu bahasa.
Kisah Sukses: Penerjemah Mesin
Sebelum munculnya asisten suara dan penyebaran chatbot yang luas, terjemahan mesin adalah tugas intelektual yang paling dituntut, yang membutuhkan pemrosesan bahasa alami. Bicara tentang jaringan saraf dan pembelajaran yang mendalam kembali ke tahun 90-an, dan neurokomputer Mark-1 pertama muncul secara umum pada tahun 1958. Tetapi di mana-mana itu tidak mungkin untuk menggunakannya karena kinerja komputer yang rendah dan kurangnya bahasa yang memadai. Hanya tim peneliti besar yang mampu melakukan penelitian di bidang jaringan saraf.
Penerjemah mesin pada pertengahan abad ke-20 jauh dari Google Translate dan Yandex.Translator, tetapi dengan setiap metode baru ide-ide terjemahan muncul yang diterapkan dalam satu bentuk atau lainnya bahkan hingga hari ini.
1970 Terjemahan mesin berbasis aturan
(RBMT) adalah upaya pertama untuk mengajarkan mesin menerjemahkan. Terjemahan diperoleh seperti pada siswa kelas lima dengan kamus, tetapi dalam satu atau lain bentuk, aturan untuk penerjemah mesin atau obrolan bot masih digunakan.
1984 Terjemahan mesin berbasis contoh
(EBMT) mampu menerjemahkan bahkan bahasa yang sama sekali berbeda satu sama lain, di mana tidak ada gunanya untuk menetapkan aturan apa pun. Semua penerjemah mesin modern dan bot obrolan menggunakan contoh dan pola yang sudah jadi.
1990. Terjemahan mesin statistik
(SMT Bahasa Inggris) di era perkembangan Internet memungkinkan tidak hanya menggunakan korps bahasa siap pakai, tetapi juga buku dan artikel yang diterjemahkan secara bebas. Semakin banyak data yang tersedia meningkatkan kualitas terjemahan. Metode statistik sekarang aktif digunakan dalam pemrosesan bahasa.
Jaringan saraf dalam layanan NLP
Dengan perkembangan pemrosesan bahasa alami, banyak masalah diselesaikan dengan metode statistik klasik dan banyak aturan, tetapi ini tidak menyelesaikan masalah ketidakjelasan dan ambiguitas dalam bahasa. Jika kita mengatakan "tunduk" tanpa konteks apa pun, maka lawan bicara yang hidup pun tidak mungkin memahami apa yang dikatakan. Semantik kata dalam teks ditentukan oleh kata-kata tetangga. Tetapi bagaimana menjelaskan ini ke mesin jika hanya memahami representasi numerik? Maka lahirlah metode analisis teks statistik
word2vec (Kata Bahasa Inggris ke vektor) .
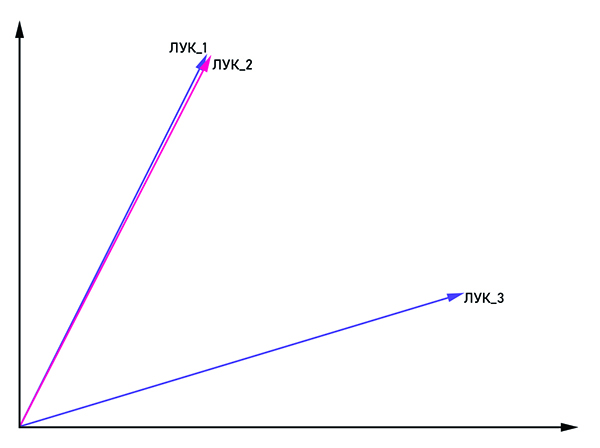 Vektor bow_1 dan bow_2 adalah paralel, oleh karena itu ini adalah satu kata, dan bow_3 adalah homonim.
Vektor bow_1 dan bow_2 adalah paralel, oleh karena itu ini adalah satu kata, dan bow_3 adalah homonim.Idenya cukup jelas dari namanya: untuk mempresentasikan kata dalam bentuk vektor dengan koordinat (x
1 , x
2 , ..., x
n ). Untuk memerangi homonim, kata-kata yang sama digabungkan dengan tag: "bow_1", "bow_2" dan seterusnya. Jika vektor bow_n dan bow_m adalah paralel, maka mereka dapat dianggap sebagai satu kata. Kalau tidak, kata-kata ini adalah homonim. Pada output, setiap kata memiliki representasi vektor sendiri dalam ruang multidimensi (dimensi ruang vektor dapat bervariasi dari 50 hingga 1000).

Pertanyaannya tetap apa jenis jaringan saraf yang digunakan untuk melatih bot obrolan bersyarat. Konsistensi penting dalam ucapan manusia: kita menarik kesimpulan dan membuat keputusan berdasarkan apa yang disebutkan dalam kalimat sebelumnya atau bahkan paragraf. Jaringan saraf berulang (RNN) sempurna untuk kriteria ini, namun, karena jarak antara bagian-bagian yang terhubung dari teks meningkat, ukuran RNN perlu ditingkatkan, yang menghasilkan penurunan kualitas pemrosesan informasi. Masalah ini diselesaikan oleh jaringan LSTM
(Bahasa Inggris Memori jangka pendek panjang) . Ini memiliki satu fitur penting - keadaan sel, yang dapat tetap konstan, atau berubah jika perlu. Dengan demikian, informasi dalam rantai tidak hilang, yang sangat penting untuk memproses bahasa alami.
Saat ini ada sejumlah besar perpustakaan untuk memproses bahasa alami. Jika kita berbicara tentang bahasa Python, yang sering digunakan untuk analisis data, maka ini adalah
NLTK dan
Spacy . Perusahaan besar juga mengambil bagian dalam pengembangan perpustakaan untuk NLP, seperti
NLP Architect dari Intel atau
PyTorch dari peneliti dari Facebook dan Uber. Meskipun terdapat minat yang besar pada perusahaan berskala besar dalam metode jaringan saraf dalam pemrosesan bahasa, dialog yang koheren dibangun terutama berdasarkan metode klasik, dan jaringan saraf memainkan peran pendukung dalam memecahkan masalah pra-pemrosesan dan klasifikasi wicara.
Bagaimana NLP dapat digunakan dalam bisnis?
Aplikasi yang paling jelas untuk pemrosesan bahasa alami termasuk penerjemah mesin, bot obrolan, dan asisten suara - sesuatu yang kita jumpai setiap hari. Sebagian besar karyawan call center dapat digantikan oleh asisten virtual, karena sekitar 80% permintaan pelanggan ke bank terkait dengan masalah yang cukup umum. Chatbot juga akan dengan tenang mengatasi wawancara awal kandidat dan mencatatnya pada pertemuan "langsung". Anehnya, yurisprudensi adalah arah yang cukup akurat, sehingga bot obrolan di sini pun bisa menjadi konsultan yang sukses.

Arah b2c bukan satu-satunya di mana chat bot dapat digunakan. Di perusahaan besar, rotasi karyawan cukup aktif, sehingga setiap orang harus membantu beradaptasi dengan lingkungan baru. Karena pertanyaan-pertanyaan dari karyawan baru itu cukup tipikal, seluruh proses mudah diotomatisasi. Tidak perlu mencari orang yang akan menjelaskan cara mengisi bahan bakar printer, yang harus dihubungi untuk masalah apa pun. Bot obrolan internal perusahaan akan baik-baik saja dengan ini.
Menggunakan NLP, Anda dapat secara akurat mengukur kepuasan pengguna dengan produk baru dengan menganalisis ulasan di Internet. Jika program mengidentifikasi ulasan sebagai negatif, maka laporan secara otomatis dikirim ke departemen yang sesuai, di mana orang yang hidup sudah bekerja dengannya.
Kemungkinan pemrosesan bahasa hanya akan berkembang, dan dengan mereka ruang lingkup penerapannya. Jika 40 orang bekerja di call center perusahaan Anda, ada baiknya mempertimbangkan: mungkin lebih baik untuk menggantinya dengan tim programmer yang akan membuat bot obrolan untuk Anda?
Anda dapat mempelajari lebih lanjut tentang kemungkinan pemrosesan bahasa pada kursus
AI Weekend kami, di mana Anna Vlasova akan berbicara secara rinci tentang bot obrolan dalam kerangka topik kecerdasan buatan.