Apakah Anda pernah menganalisis lowongan?
Mereka mengajukan pertanyaan, di mana teknologi yang paling diminati pasar tenaga kerja saat ini? Sebulan yang lalu? Setahun yang lalu?
Seberapa sering lowongan kerja baru di Jawa terbuka di area spesifik kota Anda dan seberapa aktif mereka menutup?
Dalam artikel ini saya akan memberi tahu Anda bagaimana Anda dapat mencapai hasil yang diinginkan dan membangun sistem pelaporan pada topik yang menarik bagi kami. Ayo pergi!
(Sumber gambar)Mungkin banyak dari Anda yang akrab dan bahkan menggunakan sumber daya seperti
Headhunter.ru . Ribuan lowongan baru di berbagai bidang diposting di situs ini setiap hari. HeadHunter juga memiliki API yang memungkinkan pengembang untuk berinteraksi dengan data sumber daya ini.
Toolkit
Dengan menggunakan contoh sederhana, kami mempertimbangkan konstruksi proses mendapatkan data untuk sistem pelaporan, yang didasarkan pada bekerja dengan situs API Headhunter.ru. Sebagai penyimpanan informasi antara, kami akan menggunakan DBMS SQLite yang disematkan, data yang diproses akan disimpan dalam database NoSQL MongoDB, Python 3.4 sebagai bahasa utama.
API HHKemampuan API HeadHunter cukup luas dan dijelaskan dengan baik dalam dokumentasi resmi tentang
GitHib . Pertama-tama, ini adalah kemampuan untuk mengirim permintaan anonim yang tidak memerlukan otorisasi untuk menerima informasi pekerjaan dalam format JSON. Baru-baru ini, sejumlah metode telah dibayar (metode pemberi kerja), tetapi mereka tidak akan dipertimbangkan dalam tugas ini.
Setiap lowongan menggantung di situs selama 30 hari, setelah itu, jika tidak diperbarui, itu akan diarsipkan. Jika lowongan diarsipkan sebelum berakhir 30 hari, maka ditutup oleh majikan.
HeadHunter API (selanjutnya disebut sebagai HH API) memungkinkan Anda untuk menerima serangkaian lowongan yang dipublikasikan untuk tanggal apa pun dalam 30 hari terakhir, yang akan kami gunakan - kami akan mengumpulkan lowongan yang dipublikasikan untuk setiap hari setiap hari.
Implementasi
- Hubungkan SQLite DB
import sqlite3 conn_db = sqlite3.connect('hr.db', timeout=10) c = conn_db.cursor()
- Tabel untuk menyimpan perubahan status pekerjaan
Untuk kenyamanan, kami akan menyimpan riwayat perubahan status lowongan (ketersediaan berdasarkan tanggal) dalam tabel khusus dari basis data SQLite. Berkat tabel lowongan_history, kami akan mengetahui ketersediaan lowongan di situs pada setiap tanggal pengunggahan, mis. tanggal berapa dia aktif.
c.execute(''' create table if not exists vacancy_history ( id_vacancy integer, date_load text, date_from text, date_to text )''')
- Penyaringan kekosongan
Ada batasan bahwa satu permintaan tidak dapat mengembalikan lebih dari 2000 koleksi, dan karena mungkin ada lebih banyak lowongan yang diterbitkan di situs dalam satu hari, kami akan meletakkan filter di badan permintaan, misalnya: lowongan hanya di St. Petersburg (area = 2) , oleh spesialisasi IT (spesialisasi = 1)
path = ("/vacancies?area=2&specialization=1&page={}&per_page={}&date_from={}&date_to={}".format(page, per_page, date_from, date_to))
- Ketentuan pemilihan tambahan
Pasar tenaga kerja tumbuh dengan cepat dan bahkan dengan mempertimbangkan filter, jumlah lowongan dapat melebihi 2000, jadi kami akan menetapkan batas tambahan dalam bentuk peluncuran terpisah untuk setiap hari: lowongan untuk paruh pertama hari itu dan lowongan untuk paruh kedua hari itu
def get_vacancy_history(): ... count_days = 30 hours = 0 while count_days >= 0: while hours < 24: date_from = (cur_date.replace(hour=hours, minute=0, second=0) - td(days=count_days)).strftime('%Y-%m-%dT%H:%M:%S') date_to = (cur_date.replace(hour=hours + 11, minute=59, second=59) - td(days=count_days)).strftime('%Y-%m-%dT%H:%M:%S') while count == per_page: path = ("/vacancies?area=2&specialization=1&page={} &per_page={}&date_from={}&date_to={}" .format(page, per_page, date_from, date_to)) conn.request("GET", path, headers=headers) response = conn.getresponse() vacancies = response.read() conn.close() count = len(json.loads(vacancies)['items']) ...
Kasus penggunaan pertamaMisalkan kita dihadapkan dengan tugas mengidentifikasi lowongan yang telah ditutup untuk interval waktu tertentu, misalnya, untuk Juli 2018. Ini dipecahkan sebagai berikut: hasil dari query SQL sederhana ke tabel lowongan_history akan mengembalikan data yang kita butuhkan, yang dapat diteruskan ke DataFrame untuk analisis lebih lanjut:
c.execute(""" select a.id_vacancy, date(a.date_load) as date_last_load, date(a.date_from) as date_publish, ifnull(a.date_next, date(a.date_load, '+1 day')) as date_close from ( select vh1.id_vacancy, vh1.date_load, vh1.date_from, min(vh2.date_load) as date_next from vacancy_history vh1 left join vacancy_history vh2 on vh1.id_vacancy = vh2.id_vacancy and vh1.date_load < vh2.date_load where date(vh1.date_load) between :date_in and :date_out group by vh1.id_vacancy, vh1.date_load, vh1.date_from ) as a where a.date_next is null """, {"date_in" : date_in, "date_out" : date_out}) date_in = dt.datetime(2018, 7, 1) date_out = dt.datetime(2018, 7, 31) closed_vacancies = get_closed_by_period(date_in, date_out) df = pd.DataFrame(closed_vacancies, columns = ['id_vacancy', 'date_last_load', 'date_publish', 'date_close']) df.head()
Kami mendapatkan hasil dari tipe ini:
Jika kami ingin menganalisis menggunakan alat Excel atau alat BI pihak ketiga, kami dapat mengunggah tabel lowongan_history ke file csv untuk analisis lebih lanjut:
Artileri berat
Tetapi bagaimana jika kita perlu melakukan analisis data yang lebih kompleks? Di sini, database NoSQL yang berorientasi pada dokumen
MongoDB datang untuk menyelamatkan, yang memungkinkan Anda untuk menyimpan data dalam format JSON.
Tindakan yang disebutkan di atas untuk mengumpulkan lowongan diluncurkan setiap hari, sehingga tidak perlu melihat semua lowongan setiap kali dan menerima informasi terperinci untuk masing-masing lowongan. Kami hanya akan menerima yang diterima dalam lima hari terakhir.
- Mendapatkan serangkaian lowongan selama 5 hari terakhir dari database SQLite:
def get_list_of_vacancies_sql(): conn_db = sqlite3.connect('hr.db', timeout=10) conn_db.row_factory = lambda cursor, row: row[0] c = conn_db.cursor() items = c.execute(""" select distinct id_vacancy from vacancy_history where date(date_load) >= date('now', '-5 day') """).fetchall() conn_db.close() return items
- Mendapatkan berbagai pekerjaan selama lima hari terakhir dari MongoDB:
def get_list_of_vacancies_nosql(): date_load = (dt.datetime.now() - td(days=5)).strftime('%Y-%m-%d') vacancies_from_mongo = [] for item in VacancyMongo.find({"date_load" : {"$gte" : date_load}}, {"id" : 1, "_id" : 0}): vacancies_from_mongo.append(int(item['id'])) return vacancies_from_mongo
- Masih menemukan perbedaan antara dua array, untuk lowongan yang tidak ada di MongoDB, dapatkan informasi terperinci dan tulis ke database:
sql_list = get_list_of_vacancies_sql() mongo_list = get_list_of_vacancies_nosql() vac_for_pro = [] s = set(mongo_list) vac_for_pro = [x for x in sql_list if x not in s] vac_id_chunks = [vac_for_pro[x: x + 500] for x in range(0, len(vac_for_pro), 500)]
- Jadi, kami memiliki array dengan lowongan baru yang belum tersedia di MongoDB, untuk masing-masing kami akan menerima informasi terperinci menggunakan permintaan di API HH, sebelum memprosesnya langsung ke MongoDB, kami akan memproses setiap dokumen:
- Kami membawa jumlah upah setara dengan rubel;
- Tambahkan kelulusan tingkat spesialis untuk setiap lowongan (Junior / Tengah / Senior dll)
Semua ini diimplementasikan dalam fungsi vacancies_processing:
from nltk.stem.snowball import SnowballStemmer stemmer = SnowballStemmer("russian") def vacancies_processing(vacancies_list): cur_date = dt.datetime.now().strftime('%Y-%m-%d') for vacancy_id in vacancies_list: conn = http.client.HTTPSConnection("api.hh.ru") conn.request("GET", "/vacancies/{}".format(vacancy_id), headers=headers) response = conn.getresponse() if response.status != 404: vacancy_txt = response.read() conn.close() vacancy = json.loads(vacancy_txt)
- Memperoleh informasi terperinci dengan mengakses API HH, pra-pemrosesan diterima
MongoDB akan melaksanakan data dan memasukkannya ke dalam beberapa aliran, dengan masing-masing 500 lowongan:
t_num = 1 threads = [] for vac_id_chunk in vac_id_chunks: print('starting', t_num) t_num = t_num + 1 t = threading.Thread(target=vacancies_processing, kwargs={'vacancies_list': vac_id_chunk}) threads.append(t) t.start() for t in threads: t.join()
Koleksi terpopulasi di MongoDB terlihat seperti ini:
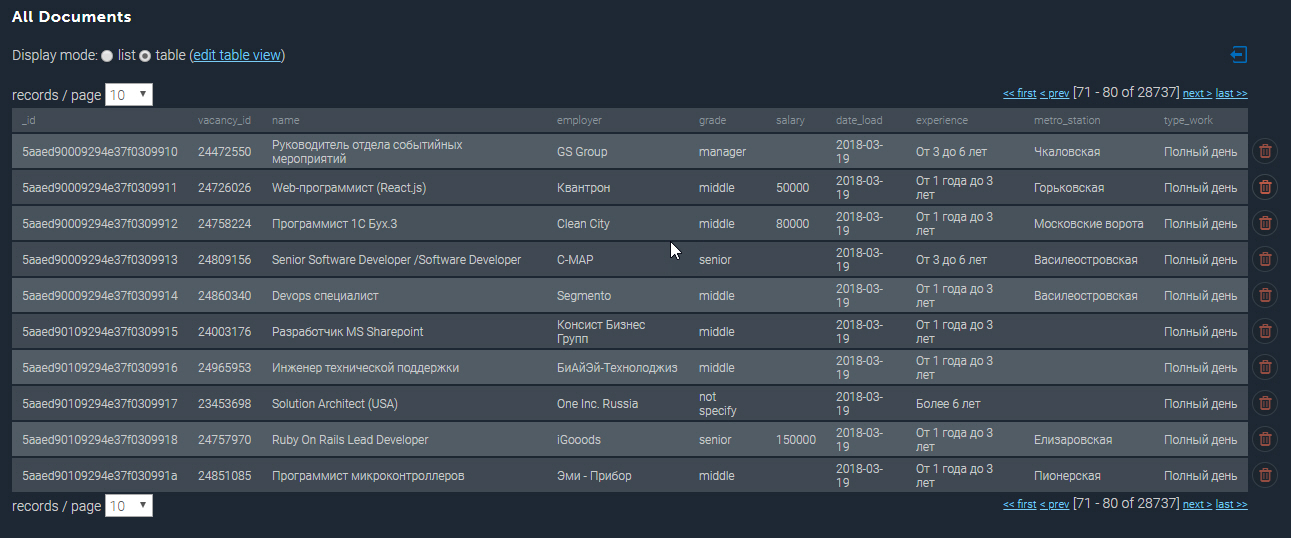
Beberapa contoh lagi
Memiliki basis data yang dikumpulkan yang kami miliki, kami dapat melakukan berbagai sampel analitik. Jadi, saya akan membawa keluar 10 lowongan paling tinggi dibayar pengembang Python di St. Petersburg:
cursor_mongo = VacancyMongo.find({"name" : {"$regex" : ".*[pP]ython*"}}) df_mongo = pd.DataFrame(list(cursor_mongo)) del df_mongo['_id'] pd.concat([df_mongo.drop(['employer'], axis=1), df_mongo['employer'].apply(pd.Series)['name']], axis=1)[['grade', 'name', 'salary_processed' ]].sort_values('salary_processed', ascending=False)[:10]
10 pekerjaan bayaran tertinggi Python| kelas | nama | nama | gaji_diproses |
|---|
| senior | Pimpinan / Arsitek Tim Web (Python / Django / React) | Investex ltd | 293901.0 |
| senior | Pengembang Python senior di Montenegro | Betmaster | 277141.0 |
| senior | Pengembang Python senior di Montenegro | Betmaster | 275289.0 |
| tengah | Pengembang Web Back-End (Python) | Soshace | 250000.0 |
| tengah | Pengembang Web Back-End (Python) | Soshace | 250000.0 |
| senior | Pimpin Insinyur Python untuk Startup Swiss | Assaia International AG | 250000.0 |
| tengah | Pengembang Web Back-End (Python) | Soshace | 250000.0 |
| tengah | Pengembang Web Back-End (Python) | Soshace | 250000.0 |
| senior | Tim Python memimpin | Digitalhr | 230000.0 |
| senior | Pengembang Utama (Python, PHP, Javascript) | IK GROUP | 220231.0 |
Sekarang mari kita cari tahu stasiun metro mana yang memiliki konsentrasi posting kosong tertinggi untuk pengembang Java. Dengan menggunakan ekspresi reguler, saya memfilter berdasarkan judul pekerjaan "Java", dan juga hanya memilih pekerjaan yang alamatnya ditentukan:
cursor_mongo = VacancyMongo.find({"name" : {"$regex" : ".*[jJ]ava[^sS]"}, "address" : {"$ne" : None}}) df_mongo = pd.DataFrame(list(cursor_mongo)) df_mongo['metro'] = df_mongo.apply(lambda x: x['address']['metro']['station_name'] if x['address']['metro'] is not None else None, axis = 1) df_mongo.groupby('metro')['_id'] \ .count() \ .reset_index(name='count') \ .sort_values(['count'], ascending=False) \ [:10]
Pekerjaan untuk Pengembang Java di Stasiun Metro| metro | masuk hitungan |
|---|
| Vasileostrovskaya | 87 |
| Petrogradskaya | 68 |
| Vyborg | 46 |
| Lenin Square | 45 |
| Gorkovskaya | 45 |
| Chkalovskaya | 43 |
| Narva | 32 |
| Lapangan Pemberontakan | Tanggal 29 |
| Desa Tua | Tanggal 29 |
| Elizarovskaya | 27 |
Ringkasan
Jadi, kemampuan analitis dari sistem yang dikembangkan benar-benar luas dan dapat digunakan untuk merencanakan startup atau membuka arah aktivitas baru.
Saya mencatat bahwa sejauh ini hanya fungsionalitas dasar dari sistem yang disajikan, di masa depan direncanakan untuk mengembangkan ke arah analisis oleh koordinat geografis dan memprediksi penampilan lowongan di area tertentu kota.
Kode sumber lengkap untuk artikel ini dapat ditemukan di tautan ke
GitHub saya.
Komentar
PS pada artikel ini disambut baik, saya akan dengan senang hati menjawab semua pertanyaan Anda dan mencari tahu pendapat Anda. Terima kasih