Fitur penting dari tugas pembelajaran mesin adalah hasil yang sama baiknya dapat dicapai dengan menggunakan metode yang berbeda. Ini memberikan kegembiraan untuk kontes ML: bahkan memiliki kompetensi lain selain lawan yang jelas kuat, Anda masih bisa menang. Tim Tensorborne dan Neurobotik memiliki peluang yang hampir sama untuk memenangkan hackathon DeepHack dan akhirnya mengambil dua tempat pertama. Pada
pelatihan Yandex, perwakilan dari kedua tim membuat satu laporan yang banyak. Dalam decoding, Anda akan menemukan analisis terperinci dari solusi dan tip untuk pesaing awal.
Dan tentu saja, berliburlah hackathon. Ketika Anda berpartisipasi dalam hackathon mingguan dan juga bekerja pada saat yang sama, itu buruk. Anda tiba di 7:00, setelah bekerja sedikit, duduk dan mengkompilasi Docker dengan TensorFlow, Keras, sehingga semua ini dimulai pada beberapa server jauh yang Anda bahkan tidak memiliki akses. Di suatu tempat dalam dua malam Anda menangkap katarsis, dan itu bekerja untuk Anda - tanpa Docker, tanpa segalanya, karena Anda mengerti bahwa itu mungkin dan sebagainya.
Vitaly Davydov:
- Halo semuanya! Kami seharusnya memiliki dua laporan, tetapi kami memutuskan untuk menggabungkannya menjadi satu besar, karena kami berbicara tentang tempat pertama dan kedua dalam kompetisi DeepHack. Kami mewakili dua tim. Tim Tensorborne kami mengambil tempat kedua, dan tim Gregory Neurobotics - yang pertama.

Laporan akan terdiri dari tiga bagian utama. Dalam intro, saya akan berbicara tentang sejarah DeepHack, apa itu, apa metriknya, dll. Selanjutnya, orang-orang akan berbicara tentang solusi, tentang masalah apa, contoh, dll.
Sebelum berbicara tentang DeepHack, harus dicatat bahwa ini adalah bagian kecil dari kompetisi global ConvAI2 yang sangat besar, yang meluncurkan Facebook tahun lalu. Tahun ini adalah iterasi kedua. Pada titik tertentu, Facebook mensponsori Institut Fisika dan Teknologi Moskow, dan kompetisi DeepHack dibuat atas dasar laboratorium PhysTech.

Baca lebih lanjut tentang ConvAI sendiri. Masalah apa yang dia coba selesaikan? Ia berspesialisasi dalam sistem interaktif. Masalah dengan sistem dialog adalah bahwa tidak ada alat evaluasi tunggal, alat evaluasi, untuk memahami kualitas dialog. Hal ini sangat subyektif dari orang ke orang: seseorang mungkin menyukai percakapan, seseorang tidak. Tugas global umum ConvAI adalah untuk menghasilkan metrik terpadu yang umum untuk mengevaluasi dialog, yang belum tersedia. Hadiah - $ 20.000 untuk AWS Mechanical Turk. Ini bukan pinjaman ke Amazon, ini hanya pinjaman untuk Mechanical Turk, yang sebenarnya merupakan analog dari Yandex.Tolki. Ini adalah layanan crowdsourcing yang memungkinkan Anda melakukan markup pada data.
Tugas, yang dibangun di atas ConvAI, adalah untuk membangun chit-chat-bot yang dengannya Anda dapat melakukan semacam dialog. Mereka memilih tiga metrik: Perplexity, Hits @ 1, dan F1. Selanjutnya saya akan menunjukkan tabel yang ada pada saat pengiriman kami.
Evaluasi yang mereka coba lakukan ini melalui tiga tahap. Tahap pertama adalah metrik otomatis, kemudian penilaian AWS Mechanical Turk, dan kemudian live chat dengan sukarelawan.
Karena ConvAI disponsori oleh Facebook, ia secara aktif mempromosikan perpustakaannya untuk menciptakan sistem percakapan ParlAI. Ini cukup rumit, tapi saya pikir semua peserta menggunakan perpustakaan ini. Kami menanganinya untuk beberapa waktu, tidak kompatibel dengan Python 3.6, misalnya, dan ada sejumlah masalah dengannya.
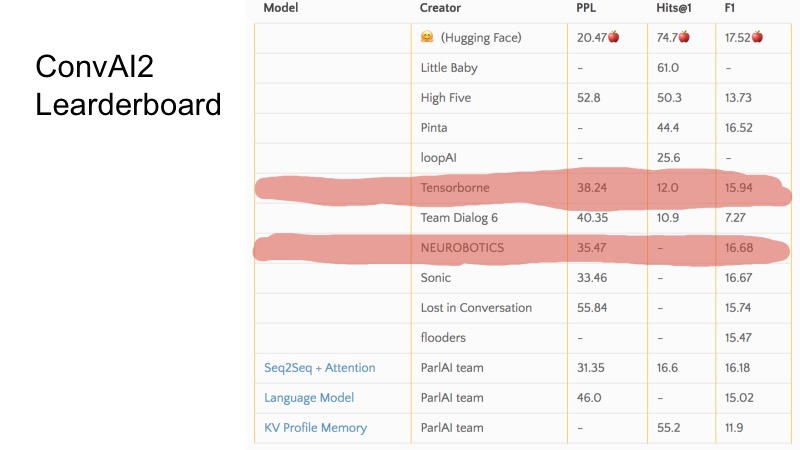
Dalam beberapa baris ini Anda dapat melihat posisi apa yang kami tempati pada saat pengajuan. Secara umum, ConvAI anehnya terorganisir dalam arti bahwa ada tiga metrik dan tidak begitu jelas bagaimana peringkat pada tabel ini berjalan. Dapat dilihat bahwa untuk beberapa metrik beberapa tim lebih tinggi, untuk beberapa yang lebih rendah. Organisasi seluruh ConvAI agak aneh.
Tetapi ada tiga garis dasar dasar. Untuk lolos ke DeepHack, perlu untuk mematahkan garis dasar ini, dan 10 tim terbaik top berhasil ke final. Secara rahasia, saya akan mengatakan bahwa hanya 8 tim yang mengirim keputusan, dan semua orang mencapai final. Itu tidak terlalu sulit.

Tugas DeepHack sedikit lebih mudah dimengerti dan langsung. Kami harus lagi membangun robot pembicara, tetapi yang akan meniru kepribadian tertentu. Yaitu, robot itu diberi deskripsi seseorang di pintu masuk, dan selama percakapan dengannya dia harus mengungkapkannya. Hadiahnya cukup menarik - perjalanan ke NIPS musim gugur ini, yang disponsori sepenuhnya.
Metriknya, tidak seperti ConvAI, sudah berbeda. Ada dua metrik, dan metrik total ditimbang di antara keduanya. Metrik pertama adalah kualitas keseluruhan, penilaian tentang seberapa memadai bot merespons, betapa menariknya berkomunikasi dengannya, apakah itu menulis beberapa sampah, dll. Metrik kedua adalah bermain peran, baik 0 atau 1. Artinya Apakah bot masuk ke deskripsi yang diberikan padanya. Orang yang berkomunikasi dengan bot tidak melihat deskripsi. Evaluasi dilakukan di Telegram, yaitu ada satu bot Telegram tunggal, dan ketika pengguna mulai berkomunikasi dengannya, ia mendapatkan beberapa bot acak dari semua pengiriman, jujur. Yandex dan MIPT, tampaknya, menumpahkan sedikit lalu lintas di sana, dan ada sekitar 10 ribu dialog, sejauh yang saya ingat.
Saya sudah mengatakan tentang babak kualifikasi. Final penuh waktu. Itu terjadi selama tujuh hari bekerja di Institut Fisika dan Teknologi Moskow, sebuah cluster disediakan, sebuah tempat, kami duduk dan bekerja di sana. Evaluasi sebenarnya setiap hari, dan skor akhir, peringkat bot pada akhirnya, dihitung dengan cara ini. Kompetisi dimulai pada hari Senin, pengiriman pertama pada hari Selasa, dan evaluasi berlangsung pada hari berikutnya. Solusi yang Anda posting pada hari Selasa dievaluasi pada hari Rabu dengan bobot 1,5. Apa yang Anda kirim pada hari Rabu - dengan berat 1,4, dll.

Tentang dataset yang diberikan Facebook untuk pelatihan. Itu disebut Persona-Obrolan dan merupakan deskripsi dua kepribadian dan serangkaian dialog. Ada deskripsi orang pertama dan kedua. Dalam proses menggambarkan dialog, mereka mencoba untuk mengungkapkan satu sama lain. Hanya itu yang telah diberikan. Namun, seperti biasa, dalam kompetisi itu tidak dilarang untuk menggunakan set data pihak ketiga lainnya.
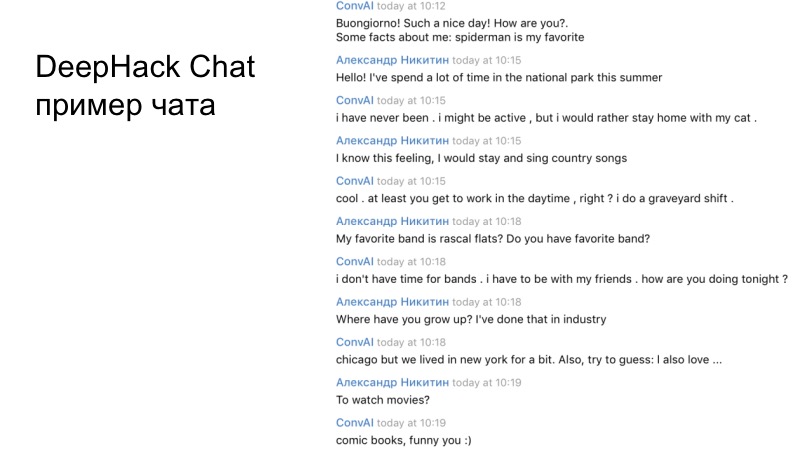
Contoh dialog tim kami. Jika Anda membaca dengan seksama, jelas bahwa bot yang dihasilkan bekerja dengan cukup baik dan menjawab dengan benar.
Gregory akan berbicara tentang tempat pertama.
Grigory Rashkov:
- Saya ingin berbicara tentang pengalaman kami dalam berpartisipasi dalam kompetisi, strategi kami dan keputusan kami.

Pertama, kekhasan kompetisi adalah bahwa ini adalah durasi yang panjang, kami tidak punya dua hari, seperti pada hackathon biasa, tetapi lima hari, di mana kami bisa membuat banyak keputusan.

Penilaian yang sangat subyektif, karena orang yang benar-benar berbeda dengan kriteria mereka dievaluasi, khususnya, penyelenggara hackathon Mikhail Bubtsev mengatakan bahwa jika dia bahkan menebak profil apa yang dia bicarakan, tetapi bot pada titik tertentu bertentangan dengan profilnya, dia menjawab pertanyaan itu tidak begitu. , seperti ada tertulis, dia memilih profil yang berbeda, bahkan jika dia tahu tentang apa itu.
Dan yang ketiga adalah kurangnya validasi. Peserta tidak dapat melakukan perubahan kecil dan segera menerima umpan balik.
Seperti dalam semua film horor, tim kami di awal memutuskan untuk berpisah. Kelompok pertama terlibat dalam solusi utama kami berdasarkan Wasserstein GAN, kelompok kedua terlibat dalam bot, panel admin bot berdasarkan baseline. Karena kami harus mengirim sesuatu pada hari pertama dan kedua.

Secara singkat tentang garis dasar: Seq2Seq plus perhatian, yang sedikit disesuaikan untuk tugas khusus ini. Bagaimana tepatnya? Sebuah frase dikirim ke input, embedding diambil dari GloVe, tetapi kemudian presentasi masing-masing frase sebagai embedding tertimbang dipertimbangkan. Bobot dipilih berdasarkan frekuensi kebalikan kata. Semakin jarang sebuah kata muncul, semakin berat kata yang dibawanya.

Ini perlu untuk mencerminkan keunikan dari karakteristik ini. Itu semua pergi ke satu set, matriks, topeng dibangun atas dasar set ini dan negara tersembunyi, kemudian topeng ini ditumpangkan pada set, konteks diperoleh, dan kemudian dihubungkan, melalui non-linearitas diumpankan ke input decoder.

Untuk hari pertama, kami belum menulis keputusan kami, kami harus mengirim sesuatu, jadi kami menulis agen berdasarkan garis dasar, tetapi mengatur diri kami tugas untuk entah bagaimana menonjol dari massa agen kelabu. Untuk melakukan ini, kami menggunakan heuristik sederhana, bot kami adalah yang pertama memulai dialog, dan dia menggunakan senyuman dalam frasa ini. Dan itu berhasil.
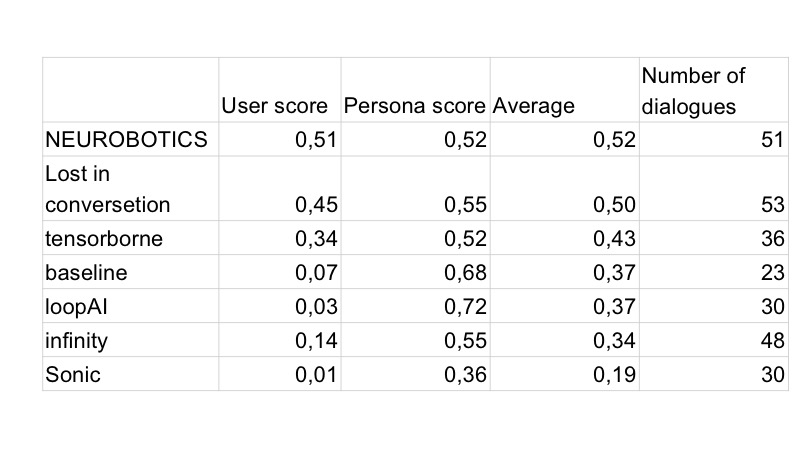
Tentu saja, keesokan harinya, semua bot mulai dibuat terlebih dahulu, dan semua memiliki emotikon. Pada hari kedua, penduduk Vilabaggio terus bekerja dengan GAN, penduduk Vilaribo mencoba heuristik lainnya.
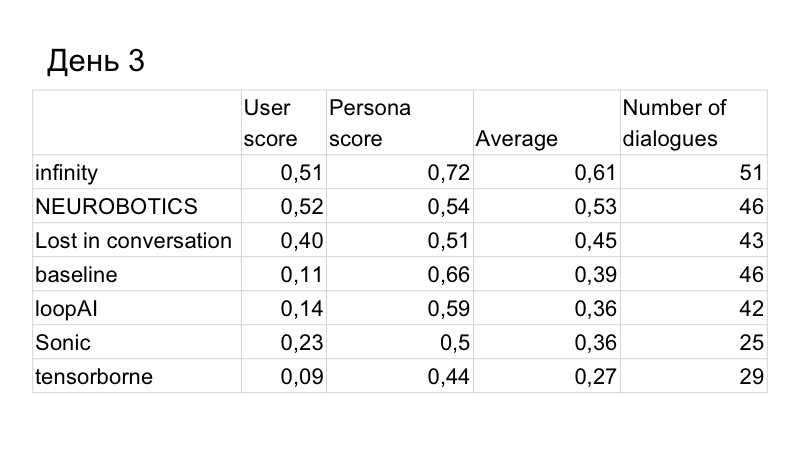
Hasilnya, skor pada kualitas dialog sedikit meningkat, tetapi kami dikalahkan oleh orang tersebut. Ini adalah hasil hari ketiga, hanya tinggal dua hari lagi. Kami memahami bahwa tidak akan cukup waktu bagi kami untuk menulis GAN dan mengujinya secara normal, karena telah belajar untuk waktu yang lama, sulit, kami harus memilih banyak hiperparameter. Jadi kami memutuskan untuk beralih ke garis dasar, karena itu bekerja dengan sangat baik.

Tugas kami adalah meningkatkan pengenalan profil pengguna. Kami mengusulkan heuristik seperti itu. Apa masalahnya? Pengguna dengan senang hati berbicara dengan bot, menanyakan pekerjaan apa yang ia miliki, hobi, mobil apa yang ia kendarai, bot itu menjawab semua ini dengan baik, karena bot umumnya merespons dengan baik. Akibatnya, pada akhir dialog, pengguna melihat dua profil yang tidak ada hubungannya dengan apa yang ada dalam dialog, hanya karena hal-hal lain ditunjukkan di sana daripada yang diminta pengguna. Karena itu, kami memutuskan bahwa entah bagaimana perlu memberikan informasi dari profil.
Bagaimana cara melakukan ini dengan cara yang paling logis? Jika seseorang memiliki minat, mungkin dia akan membicarakannya, mencari kepentingan bersama. Oleh karena itu, kami memutuskan bahwa bot akan mengajukan pertanyaan berdasarkan profilnya. Ada efek yang menarik bahwa generator, yang ditulis hanya sesuai dengan aturan linguistik G, menggunakan beberapa fakta A dari profil, sebagai hasilnya, G (A) dimasukkan ke dalam dialog, semua ini dikirim ke memori bot, dan waktu berikutnya model menghasilkan informasi, melanjutkan baik dari profil dan dari dialog ini, yaitu, dengan probabilitas yang lebih besar itu akan mengatakan sesuatu yang terkait dengan profil.
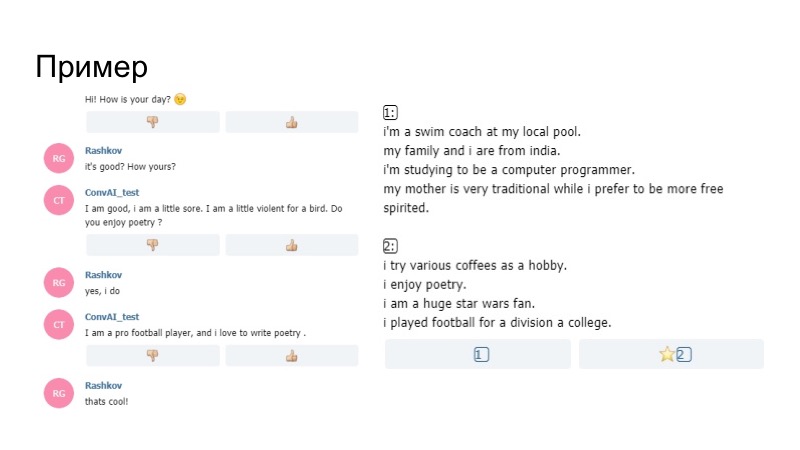
Seperti apa kenyataannya? Bot di profil mengatakan bahwa dia senang dengan puisi, lalu selama percakapan dia bertanya apakah saya suka puisi. Saya bilang ya, dan lebih lanjut pada modelnya, bukan generator yang kami bangun sesuai aturan, mengatakan bahwa ia suka menulis puisi. Dengan demikian, bot fokus pada profilnya, dan berhasil.

Kami kembali ke tempat pertama lagi. Hari terakhir tetap ada. Kami memperhatikan bahwa kami kalah dalam dialog.

Kami mengambil keuntungan dari beberapa solusi lainnya. Pertama, mereka menggunakan parafrase, menganalisis apa yang dikatakan orang lain, karena panitia meletakkan basis data ini, dan memperhatikan bahwa banyak orang berkomunikasi dengan bot tidak sepenuhnya benar.
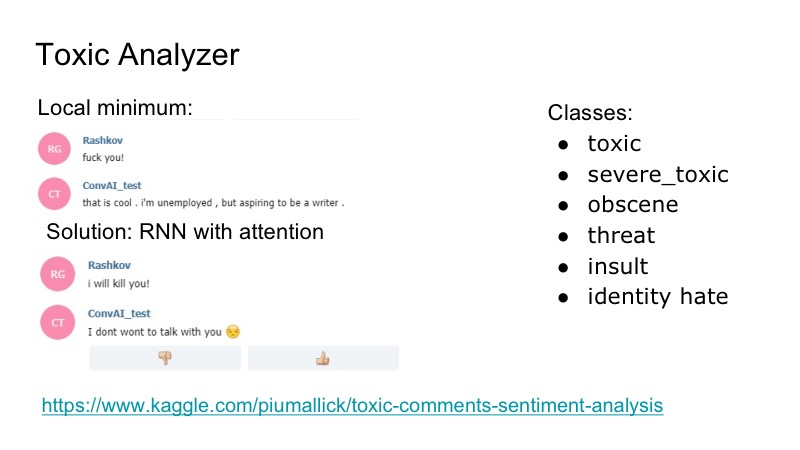
Ada minimum lokal yang menarik di bot: itu merespon dengan sangat baik terhadap penghinaan, dia setuju dengan mereka, dan untuk memperbaikinya, kami memutuskan untuk menggunakan kompetisi Kaggle untuk penganalisa komentar beracun, kami menulis sebuah klasifikasi yang sangat sederhana, juga dengan perhatian RNN. Dalam dataset itu ada kelas berikut, tumpang tindih: penghinaan, ancaman ... Kami memutuskan untuk tidak mempelajari model secara terpisah, siapa yang akan berbicara, karena masalah seperti itu ditemui, tetapi itu tidak terlalu sering. Karena itu, kami hanya menulis semacam lelucon yang dijawab bot itu, dan semua orang senang.

Selain itu, kami menggunakan parafrase untuk memperkaya pidato bot kami. Ini juga tidak terlalu sulit, kami mengganti kata-kata dari frasa dengan sinonim, melihat n-gram yang dihasilkan dalam frasa, sehingga mereka tidak jauh berbeda dari yang awalnya, dan kemudian kami memilih kombinasi yang paling cocok untuk frasa dengan probabilitas terbesar.
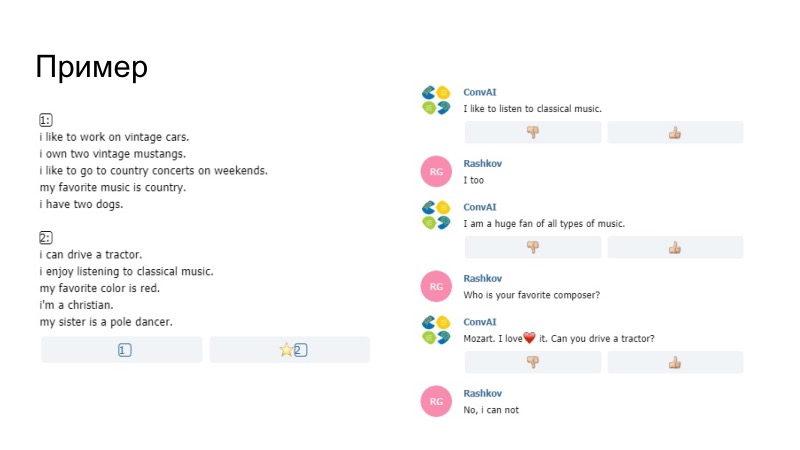
Sebagai contoh dari apa yang terjadi, bot di sini mengatakan bahwa ia suka mendengarkan musik, katanya menikmati dalam profil, ia telah digantikan oleh suka bersama kami. Kami tidak yakin apakah model itu sendiri atau Paraphraser kami yang membuatnya, tetapi hal ini berlalu. Komentar lain bahwa tidak mungkin untuk mengirim data dari profil. Pentagram dibandingkan di sana. Jika pentagram bertepatan dengan komentar dan profil Anda, maka kalimat ini tidak lulus, penyelenggara mengaturnya. Selanjutnya, antara lain, kami menambahkan kamus smiley.

Contoh kedua, kita memiliki banyak senyum. Lalu ada heuristik, ketika bot bereaksi terhadap perilaku Anda bahwa Anda tidak menulis untuk itu untuk waktu yang lama. Paraphraser juga bekerja di sini, dan hasilnya bagus.

Kualitas dialog adalah yang terbaik, kualitas memerankan peran juga.
Kami mencoba membuat model menghasilkan serangkaian opsi, dan kami membandingkannya dengan profil. Tetapi bagi saya tampaknya dalam hal ini bot bekerja lebih buruk, kami tidak dapat melakukan validasi, hanya penilaian subjektif dalam dua atau tiga percakapan. Karena itu, mereka memutuskan untuk tidak memasukkan hal seperti itu, karena profilnya sudah dikenal dengan baik.
Kemudian kami menulis solusi untuk masalah terbalik, model kedua, yang memilih profil yang diinginkan dari dialog. Kami berencana menggunakannya pada awalnya untuk pelatihan, untuk membaca fungsi kerugian dari itu dan selanjutnya mendistribusikannya ke dalam grid. Tapi ini bisa memperburuk pembicara itu sendiri, jadi mereka memutuskan untuk tidak mengatakannya seperti itu. Kami juga berpikir untuk menggunakan hal ini untuk perilaku bot, tetapi kami tidak punya waktu untuk menguji semuanya, dan memutuskan untuk menolaknya. Selain itu, kami memutuskan untuk meletakkan emotikon berdasarkan pewarnaan emosional dari frasa, menulis model, tetapi tidak menemukan dataset yang sesuai, dan yang digunakan tidak sedikit tentang hal itu.

Tim kami
Bahkan jika model utama Anda, yang Anda harapkan, tidak dapat menulisnya atau memberikan hasil yang buruk, jangan menyerah segera, Anda perlu mencoba beberapa hal sederhana, yang cukup alami. Dan hal kedua, kadang-kadang ada baiknya memperhatikan kekurangan model Anda dan memikirkan tugas tertentu, menguraikannya dan memecahkan bidang masalah tertentu, yang kami lakukan. Terima kasih atas perhatian anda
Sergey Kolesnikov:
- Nama saya Sergey Kolesnikov, saya akan mewakili keputusan Tensorborne.

Kami datang dengan nama yang indah, pergi ke kontes, datang dengan banyak potongan berbeda untuk merilis dua artikel setelah itu, tetapi tidak memenangkan hackathon. Oleh karena itu, akan disebut: "Bagaimana tidak memenangkan hackathon, tetapi masih menerbitkan dua artikel sialan itu." Akademisi, tuan.
Fitur dari kompetisi di mana kami berpartisipasi melebihi motivasi kami. Karena kenyataan bahwa penilaian dilakukan setiap hari, paket harus dibuat setiap hari juga, dan hadiah akhir ditentukan, seperti yang kita suka di RL, oleh penjumlahan diskon. Semua ini berkembang menjadi kenyataan bahwa kami harus mengirim setidaknya sesuatu setiap hari agar berfungsi, dan kami mendapat setidaknya semacam skor. Akibatnya, itu benar-benar tumbuh menjadi apa yang Anda inginkan - Anda tidak inginkan, tetapi Anda harus mendayung.
Apa yang kita miliki Pratinjau selama seminggu penuh.
Terlepas dari kenyataan bahwa hackathon mengatakan bahwa dia mingguan, semuanya diputuskan dalam empat hari, yang tampaknya tidak cukup untuk tugas ini ConvAI.
Awalnya, ada lima dari kita, semuanya lulusan akademis yang bagus atau lebih Fiztekh, jadi pada hari Senin kami datang dan melemparkan banyak saran, ide yang dapat Anda coba, yang mana model pembelajaran yang dalam untuk dicoba. Benar, kami tidak bereksperimen dengan GAN, karena kami sudah bereksperimen dengan mereka untuk teks dan ini tidak berhasil, jadi kami mengambil sesuatu yang lebih sederhana, selain itu, ada kompetisi yang sangat mirip dan kami memiliki model pra-latihan. Pada hari Selasa, kami bahkan dapat meluncurkan sesuatu tentang pembelajaran yang mendalam, ML sedapat mungkin, kami meluncurkan buruh pelabuhan hebat dengan dukungan GPU dan hal-hal lain untuk Tensorflow dan Keras, kami perlu memberikan medali terpisah untuk ini, karena ini tidak terlalu sepele seperti yang saya inginkan.
Menurut hasil Selasa, mereka menjanjikan, dan kami memutuskan untuk sedikit meningkatkan ML kami dengan heuristik kecil dan sejenisnya, dan gagal di tempat ketujuh. Tetapi berkat rekan tim kami, seseorang menemukan ElasticSearch dan mencobanya. Ada saat yang sangat canggung ketika ElasticSearch bekerja dengan baik, dan model DL dan ML, dan sebagainya, sedikit kurang kuat. Akhir dari kontes sudah dekat. Dan seperti dicatat oleh pembicara sebelumnya, kami memutuskan untuk mendayung ke arah yang bekerja. Kami mengambil ElasticSearch, heuristik kecil dan berpikir itu cukup baik, dan benar-benar cukup bagus, karena kami mengambil tempat kedua.
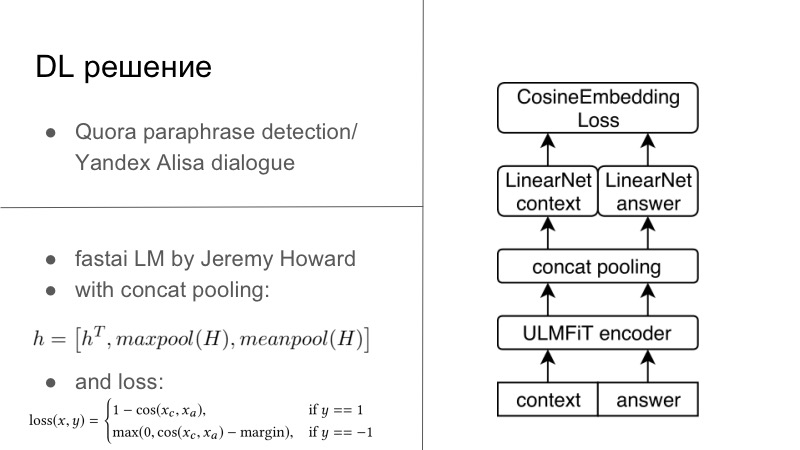
Lebih detail. Sebenarnya, ada beberapa solusi DL. Solusi DL pertama cukup sederhana. Siapa yang ingat, tahun sebelum tahun lalu atau tahun lalu, ada kontes pendeteksian parafrase Quora, dan tahun ini ada kontes dari Yandex untuk Alice untuk membangun dialog dan banyak lagi. Anda mungkin memperhatikan bahwa tugas di sana sangat dekat. Dalam yang pertama perlu untuk mengatakan apakah kedua frasa ini adalah parafrase, dan yang kedua perlu untuk melanjutkan dialog. Kami berpikir bahwa karena kami sedang mengembangkan sistem dialog, marilah kita juga melanjutkan dialog dengan baik. Dan itu berhasil dengan sempurna, dialog dengan Quora sangat pribadi.
Pada dasarnya, itu semua tampak seperti kami memiliki beberapa encoder, biasanya kami semua berlatih menggunakan RNN biasa, dan lebih disukai LSTM dengan perhatian dan hal-hal lain. Dan kemudian kita secara standar menggunakan Cosaine Embedding Loss yang disajikan pada slide di bawah ini, atau kerugian embedding tipe Tripler Loss lainnya, atau sesuatu yang lain yang menyematkan parafrase atau tanggapan terhadap dialog tertentu yang menyatukan, dan bukan penundaan parafrase, dan sebagainya. Ini adalah solusi pertama, pada Tensorflow, Keras, sudah siap, kami mencobanya, dan itu cukup bagus.
Solusi lain lahir dalam dua hari hackathons di malam hari. Ada seorang lelaki yang luar biasa, Jeremy Howard, ia mempromosikan DL dan ML untuk semua orang, ia memiliki dua kursus luar biasa yang memperkenalkan Anda pada jalannya bisnis ini dan hal-hal lain, dan untuk kursus ini ia menulis FastAI-nya. Semua ini berfungsi di PyTorch, dan dalam banyak hal bahkan menulis ulang PyTorch, ini adalah salah satu minus dari lib ini. Namun dari sisi positifnya, Jeremy tidak ada hubungannya dengan NLP, tahun ini di bulan Maret mereka menerbitkan sebuah artikel dengan siswa lain di mana mereka melatih LSTM tentang semua praktik terbaik dalam FastAI yang luar biasa, dengan banyak trik yang ia promosikan dalam kursusnya, dan mendapatkan SOTA secara praktis untuk semuanya.
Karena saya adalah penginjil kecil PyTorch, saya masih bisa mencabut model ini dari FastAI, menjejalkannya, Anda sudah bisa mengatakan, ke dalam kerangka PyTorch saya, dan bahkan melatih semuanya untuk tugas ini. Pada dasarnya, kami memiliki konteks dialog tertentu, pada kenyataannya, bahkan jika kami memiliki beberapa kalimat, Anda hanya menyatukannya menjadi satu kalimat yang kuat. answer, . FastAI, Universal Language Model — — Encoder.
, , , 1 , seq2seq. . , , FastAI — Concat poolling. ? seq2seq, attention. maxpool minpool , , .
, , , , maxpool minpool, . , — H, Hc Ha. , feedforward , . , , , , metric learning. — CosineEmbedding Loss, PyTorch.
, loss . , contrastive loss, , . , .
DL-. ElasticSearch, .
? , - ElasticSearch . - - Persona Dataset , , Facebook, , , - . - . , , , , , Persona Dataset , Amazon Mechanical Turk , .
ElasticSearch, , . , Persona Dataset , , 10 . , . , , , , .
- . , Persona , , , , , evaluation. heuristic solutions.
, , , , . . , , , , , . .
— . , — -, -, , .
dirty hack. , , . . — , .

? , -DL- , DL, . , , , . . , -, , , . , , . . , , . DL , ElasticSearch .
, personality score. , -, 0,25–0,3 , . , , - .

. — , , , Docker ElasticSearch, . , . . . Also, try to guess… , — , funny you. , general, . , , .
, , . . , — , , . , Docker, .

? ConvAI , NIPS, - .
-, ElasticSearch . , , . , , ElasticSearch . , DL.
-, DL-. : , , , . , , , , .
, . , . , . — pre-trained- ( — . .), . .
, proposals , RL bandits . , . — . , . , , , , toxic- . .
— . , DeepHacks . NLP, DeepHack , , « ». , . . , , , , , .
— . distributed- , . , DeepHack. - . . , , , , .
! . pre-trained-. , , .
Dan tentu saja, berliburlah hackathon. Ketika Anda berpartisipasi dalam hackathon mingguan dan juga bekerja pada saat yang sama, ini buruk. Anda tiba di 7:00, setelah bekerja sedikit, duduk dan mengkompilasi Docker dengan TensorFlow, Keras, sehingga semua ini dimulai pada beberapa server jauh yang Anda bahkan tidak memiliki akses. Di suatu tempat dalam dua malam Anda menangkap katarsis, dan itu bekerja untuk Anda - tanpa Docker, tanpa segalanya, karena Anda mengerti bahwa itu mungkin dan sebagainya.Tampaknya jika Anda berpartisipasi dalam kompetisi besar, maka berikan sedikit lebih banyak waktu untuk itu daripada seberapa banyak Anda tidak bisa tidur dalam seminggu, dan ikut serta. Pergi dan menangkan. Terima kasih