Pada presentasi NVIDIA SIGGRAPH 2018, CEO perusahaan Jensen Juan secara resmi meluncurkan arsitektur Turing GPU yang telah lama ditunggu-tunggu dan berspekulasi. GPU NVIDIA generasi berikutnya, Turing, akan menyertakan sejumlah fitur baru dan akan melihat dunia tahun ini. Meskipun visualisasi profesional (ProViz) telah menjadi fokus pengumuman hari ini, kami berharap arsitektur baru ini dapat digunakan dalam produk NVIDIA mendatang lainnya. Ulasan hari ini bukan hanya daftar semua fitur Turing.

Rendering Hibrid dan Jaringan Saraf Tiruan: RT & Tensor Cores
Jadi apa yang istimewa dan baru tentang arsitektur Turing? Marquee, setidaknya untuk komunitas NVIDIA ProViz, dirancang untuk rendering hybrid, yang menggabungkan penelusuran sinar dengan rasterisasi tradisional.

Perubahan besar: NVIDIA telah menyertakan lebih banyak lagi peralatan ray tracing di Turing untuk menawarkan penelusuran ray akselerasi perangkat keras tercepat. Baru untuk arsitektur Turing adalah unit komputasi RT Core khusus, seperti NVIDIA menyebutnya, saat ini tidak ada informasi yang cukup tentang hal itu, hanya diketahui bahwa fungsinya adalah dukungan untuk penelusuran sinar. Unit prosesor ini mempercepat pemeriksaan persimpangan sinar dan segitiga, serta memanipulasi BVH (hierarki volume pembatas).
NVIDIA mengklaim bahwa komponen Turing tercepat dapat menghitung 10 miliar (Giga) sinar per detik, yang merupakan peningkatan 25 kali lipat dalam kinerja penelusuran sinar dibandingkan dengan Pascal yang tidak dipercepat.
Arsitektur Turing termasuk kernel tensor Volta yang telah diperkuat. Kernel Tensor adalah aspek penting dari beberapa inisiatif NVIDIA. Seiring dengan mempercepat ray tracing, alat penting dalam "tas trik sulap" NVIDIA adalah untuk mengurangi jumlah sinar yang dibutuhkan dalam adegan menggunakan pengurangan noise AI untuk menghapus gambar, di sini core tensor melakukan yang terbaik. Tentu saja, ini bukan satu-satunya area di mana mereka baik - semua jaringan saraf dan kerajaan AI dari NVIDIA dibangun di atasnya.
Turing ditandai dengan dukungan rentang akurasi yang lebih luas, yang berarti kemungkinan akselerasi signifikan dalam beban kerja yang tidak memiliki persyaratan akurasi tinggi. Selain mode presisi Volta FP16, kernel Turing tensor mendukung INT8 dan bahkan INT4. Ini 2 dan 4 kali lebih cepat daripada FP16, masing-masing. Meskipun NVIDIA tidak ingin membahas secara rinci pada presentasi, saya menyarankan agar mereka mengimplementasikan sesuatu yang mirip dengan pengemasan data, yang digunakan untuk operasi presisi rendah pada core CUDA. Meskipun akurasi jaringan saraf berkurang (pengembalian berkurang - menurut INT4 kami hanya mendapatkan 16 (!) Nilai) - ada model tertentu yang benar-benar membutuhkan tingkat akurasi rendah ini. Akibatnya, mode akurasi yang dikurangi akan menunjukkan throughput yang baik, terutama dalam tugas-tugas output, yang pasti akan menyenangkan beberapa pengguna.
Kembali ke rendering hybrid secara umum, menarik bahwa terlepas dari akselerasi individu yang besar ini, keseluruhan janji NVIDIA akan peningkatan kinerja terlihat sedikit lebih sederhana. Meskipun perusahaan berjanji untuk meningkatkan produktivitas hingga 6 kali lipat dibandingkan Pascal, apakah sudah waktunya untuk menanyakan bagian mana yang dipercepat, dan dibandingkan dengan yang mana. Waktu akan memberi tahu.
Sementara itu, agar dapat menggunakan kernel tensor dengan lebih baik di luar ray tracing dan tugas pembelajaran mendalam yang difokuskan secara sempit, NVIDIA akan menggunakan SDK, NVIDIA NGX, yang akan memungkinkan integrasi jaringan saraf dalam pemrosesan gambar. NVIDIA mengharapkan penggunaan jaringan saraf dan inti tensor untuk pemrosesan gambar dan video tambahan, termasuk metode seperti Deep-Anti-Aliasing (DLAA) mendatang.
Turing SM: core INT khusus, cache tunggal, Naungan Tingkat Variabel
Bersama dengan RT dan kernel tensor, arsitektur Turing Streaming Multiprocessor (SM) sendiri memperkenalkan trik baru. Secara khusus, salah satu perubahan Volta terbaru diwariskan, sebagai akibatnya core Integer dialokasikan di blok mereka sendiri, dan bukan bagian dari core titik mengambang CUDA. Keuntungannya adalah menghasilkan alamat yang lebih cepat dan kinerja Fused Multiply Add (FMA).
Adapun ALU (saya masih menunggu konfirmasi untuk Turing) - mendukung operasi yang lebih cepat dengan akurasi rendah (misalnya, FP16 cepat). Di Volta, ini diimplementasikan sebagai operasi FP16 pada frekuensi ganda relatif terhadap FP32, dan operasi INT8 pada kecepatan 4x. Kernel Tensor sudah mendukung konsep ini, jadi akan logis untuk mentransfernya ke kernel CUDA.
Fast FP16, teknologi Rapid Packed Math, dan cara lain untuk mengemas beberapa operasi kecil menjadi satu operasi besar adalah semua komponen kunci untuk meningkatkan kinerja GPU pada saat Hukum Moore melambat.
Menggunakan tipe data besar (tepat) hanya jika diperlukan, mereka dapat dikemas bersama untuk melakukan lebih banyak pekerjaan dalam periode waktu yang sama. Ini terutama penting untuk output dari jaringan saraf, serta untuk pengembangan game. Faktanya adalah bahwa tidak semua program shader membutuhkan presisi FP32, dan mengurangi akurasi dapat meningkatkan kinerja dan mengurangi bandwidth memori yang berguna dan penggunaan file registri.
Turing SM menyertakan sesuatu yang NVIDIA sebut “arsitektur cache terpadu”. Karena saya masih mengharapkan diagram SMID resmi dari NVIDIA, tidak jelas apakah ini adalah penyatuan yang sama yang kami lihat di Volta - di mana cache L1 dikombinasikan dengan memori bersama - atau NVIDIA mengambilnya selangkah lebih maju. Bagaimanapun, NVIDIA mengklaim bahwa ia sekarang menawarkan bandwidth dua kali lebih banyak dibandingkan dengan "generasi sebelumnya", tetapi tidak jelas apakah itu berarti "Pascal" atau "Volta" (yang terakhir lebih mungkin).
Akhirnya, sangat tersembunyi dalam siaran pers Turing, disebutkan dibuat dukungan naungan tingkat variabel. Ini adalah teknologi rendering grafik yang relatif muda dan berkembang, yang hanya ada sedikit informasi (terutama tentang bagaimana tepatnya diterapkan oleh NVIDIA). Tetapi pada tingkat abstraksi yang sangat tinggi, ini terdengar seperti "teknologi generasi NVIDIA berikutnya yang memungkinkan Anda menerapkan naungan dengan resolusi yang berbeda, yang memungkinkan pengembang untuk menampilkan area layar yang berbeda pada resolusi efektif yang berbeda untuk kualitas konsentrasi (dan waktu render) di area yang paling dibutuhkan" .
Feed the Beast: Dukungan GDDR6
Karena memori yang digunakan oleh GPU dikembangkan oleh perusahaan pihak ketiga, tidak ada rahasia. JEDEC dan 3 anggota besar Samsung, SK Hynix dan Micron sedang mengembangkan memori GDDR6 sebagai penerus GDDR5 dan GDDR5X. NVIDIA telah mengkonfirmasi bahwa Turing akan mendukungnya. Tergantung pada pabrikannya, GDDR6 generasi pertama diiklankan memiliki bandwidth memori hingga 16 Gb / s per bus, yang dua kali lipat kartu NVIDIA GDDR5 generasi terbaru, dan 40% lebih cepat daripada kartu NVIDIA GDDR5X terbaru.
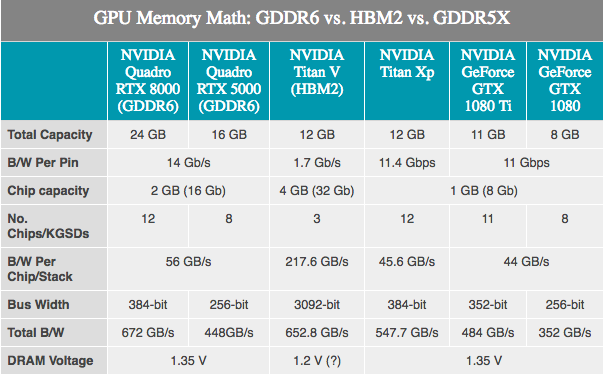
Dibandingkan dengan GDDR5X, GDDR6 tidak terlihat seperti terobosan besar, karena banyak inovasi GDDR6 telah diterapkan pada GDDR5X. Perubahan mendasar di sini termasuk tegangan operasi yang lebih rendah (1,35v), dan memori internal sekarang dibagi: dua saluran memori per mikrosirkuit. Untuk chip 32-bit standar - dua saluran memori 16-bit, secara total kami memiliki 16 saluran tersebut pada kartu 256-bit. Meskipun ini, pada gilirannya, mengatakan bahwa ada jumlah saluran yang sangat besar, GPU akan mendapatkan manfaat maksimal dari inovasi, karena secara historis mereka adalah perangkat yang paling "paralel".

NVIDIA, untuk bagiannya, telah mengkonfirmasi bahwa kartu Turing Quadro pertama akan menggunakan GDDR6 pada 14 Gb / s. Pada saat yang sama, NVIDIA juga mengkonfirmasi penggunaan memori Samsung, terutama untuk perangkat canggih 16-gigabyte. Ini penting karena itu berarti bahwa NVIDIA GPU 256-bit khas dapat dilengkapi dengan 8 modul standar dan mendapatkan 16 GB kapasitas memori total, atau bahkan 32 GB jika mereka menggunakan mode clamshell (memungkinkan menangani memori 32 GB pada standar 256-bit bus).
Segala macam detail: NVLink, VirtualLink dan 8K HEVC
Sudah berakhir dengan ulasan arsitektur Turing, NVIDIA dengan santai mengkonfirmasi dukungan untuk beberapa fitur I / O eksternal baru. Dukungan NVLink akan hadir di setidaknya beberapa produk Turing. Ingatlah bahwa NVIDIA menggunakannya di ketiga kartu Quadro baru. NVIDIA menawarkan konfigurasi GPU dua arah.
Poin penting (sebelum bagian dari audiens kami yang berorientasi game masuk jauh ke dalam membaca): kehadiran NVLink di peralatan Turing tidak berarti bahwa itu akan digunakan dalam kartu video konsumen. Mungkin semuanya akan dibatasi hanya untuk kartu Quadro dan Tesla.
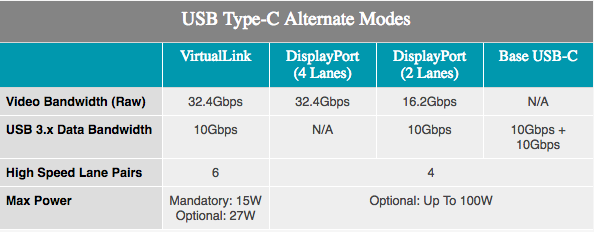
Dengan tambahan dukungan VirtualLink, pemain dan pengguna ProViz akan mendapatkan apa yang diharapkan dari VR. Mode USB Type-C alternatif diumumkan bulan lalu dan mendukung daya 15 W +, transfer data 10 Gb / s berkat USB 3.1 Gen 2, 4 pita DisplayPort HBR3 pada satu kabel. Dengan kata lain, ini adalah koneksi DisplayPort 1.4 dengan data dan daya tambahan. Ini memungkinkan kartu video untuk secara langsung mengontrol headset VR. Standar ini didukung oleh NVIDIA, AMD, Oculus, Valve dan Microsoft, sehingga produk Turing akan menjadi yang pertama dari sejumlah produk yang akan mendukung standar baru.
Meskipun NVIDIA hanya sedikit menyinggung topik, kita tahu bahwa unit encoder video NVENC telah diperbarui di Turing. Iterasi NVENC terbaru menambahkan dukungan pengkodean HEKC 8K khusus. Sementara itu, NVIDIA mampu meningkatkan kualitas encoder-nya, memungkinkannya mencapai kualitas yang sama seperti sebelumnya, dengan bitrate video 25% lebih rendah.
Indikator kinerja
Seiring dengan spesifikasi perangkat keras yang diumumkan, NVIDIA menunjukkan beberapa angka kinerja peralatan Turing. Perlu dicatat bahwa di sini kita tahu sangat, sangat sedikit. Komponen-komponen tersebut berdasarkan pada Turing SKU yang disertakan secara penuh dan sebagian dengan 4608 core CUDA dan 576 core tensor. Frekuensi tidak diungkapkan, karena angka-angka ini diprofilkan untuk perangkat keras Quadro, kita cenderung melihat kecepatan clock yang lebih rendah daripada peralatan konsumen mana pun.

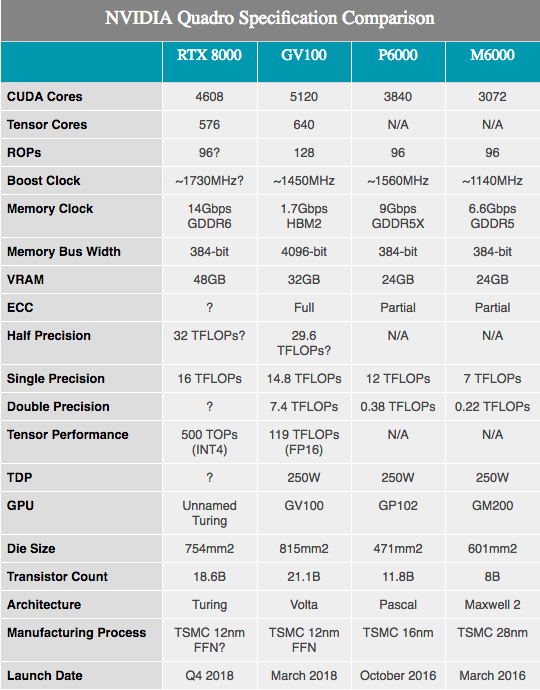
Seiring dengan 10GigaRays / detik untuk RT core yang disebutkan di atas, kinerja NVIDIA tensor core adalah 500 triliun operasi tensor per detik (TOP 500T). Sebagai referensi, NVIDIA sering menyebut GPU GV100 sebagai mampu memberikan maksimum 120T TOP, tetapi ini bukan hal yang sama. Secara khusus, sementara GV100 disebutkan dalam pemrosesan operasi FP16, kinerja Turing dikutip dengan INT4 presisi sangat rendah, yang hanya seperempat ukuran FP16 dan, karenanya, meningkatkan throughput empat kali. Jika kita menormalkan akurasi, maka kernel tensor Turing tampaknya tidak memiliki throughput terbaik per core, tetapi lebih menawarkan opsi akurasi lebih dari Volta. Dalam kasus apa pun, 576 core tensor dalam chip ini hampir setara dengan GV100, yang memiliki 640 core tersebut.
Mengenai core CUDA, NVIDIA mengklaim bahwa Turing GPU dapat menawarkan kinerja 16 TFLOPS. Ini sedikit di depan kinerja 15 TFLOPS dengan ketepatan tunggal Tesla V100, atau bahkan lebih maju dari 13,8 TFLOPS dari Titan V. Jika Anda mencari informasi yang lebih ramah konsumen, ini sekitar 32% lebih banyak daripada Titan Xp. Setelah membuat sketsa beberapa perhitungan kasar di atas kertas, kita dapat mengasumsikan kecepatan clock GPU sekitar 1730 MHz, mengingat bahwa pada level SM tidak ada perubahan tambahan yang akan mengubah formula kinerja ALU tradisional.
Sementara itu, NVIDIA mengumumkan bahwa kartu Quadro akan datang dengan memori GDDR6 yang beroperasi pada 14 Gb / s. Dan melihat dua SKU Quadro terbaik yang menawarkan masing-masing 48 GB dan 24 GB GDDR6, kita hampir melihat bus memori 384-bit pada GPU Turing ini. Beralih ke angka, ini berarti bandwidth memori 672 GB / s untuk dua kartu Quadro top-end.
Kalau tidak, dengan perubahan dalam arsitektur, sulit untuk membuat banyak perbandingan kinerja yang berguna, terutama ketika membandingkan dengan Pascal. Dari apa yang kami lihat dengan Volta, kinerja keseluruhan NVIDIA telah meningkat, terutama dalam beban kerja komputasi yang dirancang dengan baik. Dengan demikian, peningkatan sekitar 33% dalam kinerja kertas dibandingkan dengan Quadro P6000 mungkin sesuatu yang jauh lebih besar.
Saya akan menyebutkan ukuran kristal GPU baru. Terletak di 754 mm2, bukan hanya besar, ini sangat besar. Dibandingkan dengan GPU lain, hanya NVIDIA GV100 yang berukuran kedua, yang saat ini tetap menjadi andalan NVIDIA. Tetapi dengan 18,6 miliar transistor, mudah untuk melihat mengapa chip yang dihasilkan harus sangat besar. Rupanya, NVIDIA memiliki rencana besar untuk GPU ini, yang pada akhirnya akan dapat membenarkan kehadiran dua prosesor grafis besar di tumpukan produknya.
NVIDIA, untuk bagiannya, belum menunjukkan nomor model spesifik untuk GPU ini - apakah itu adalah GPU kelas tradisional 102 atau bahkan kelas 100. Saya ingin tahu apakah kita akan melihat modifikasi GPU jenis ini untuk produk konsumen dalam satu atau lain bentuk; ini sangat besar sehingga NVIDIA mungkin ingin menyimpannya untuk GPU Quadro dan Tesla yang lebih menguntungkan.
Dirilis pada kuartal keempat 2018, jika tidak sebelumnya
Sebagai kesimpulan, saya akan mengatakan bahwa seiring dengan pengumuman arsitektur Turing, NVIDIA mengumumkan bahwa 4 kartu Quadro pertama berdasarkan GPU Turing - Quadro RTX 8000, RTX 6000 dan RTX 5000 akan mulai dikirimkan pada kuartal keempat tahun ini. Karena sifat dari pengumuman ini agak terbalik - biasanya NVIDIA pertama kali mengumumkan komponen konsumen - saya tidak akan menerapkan timeline yang sama untuk kartu konsumen yang tidak memiliki persyaratan validasi yang ketat. Kita akan melihat peralatan Turing pada kuartal keempat tahun ini, jika tidak sebelumnya. Mereka yang ingin membeli Quadro dapat mulai menabung sekarang: yang terbaik dari kartu Quadro RTX 8000 baru akan dikenakan biaya sekitar $ 10.000.
Akhirnya, untuk konsumen dengan NVIDIA's Tesla, peluncuran Turing membuat Volta limbo. NVIDIA tidak memberi tahu kami apakah Turing akhirnya akan berekspansi ke ruang kelas atas Tesla - menggantikan GV100 - atau apakah prosesor Volta terbaik mereka akan tetap menjadi penguasa domain selama berabad-abad. Namun, karena kartu Tesla lainnya sejauh ini didasarkan pada Pascal, mereka adalah kandidat pertama yang keluar dari Turing pada 2019.
Terima kasih telah tinggal bersama kami. Apakah Anda suka artikel kami? Ingin melihat materi yang lebih menarik? Dukung kami dengan melakukan pemesanan atau merekomendasikannya kepada teman-teman Anda,
diskon 30% untuk pengguna Habr pada analog unik dari server entry-level yang kami temukan untuk Anda: Seluruh kebenaran tentang VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps dari $ 20 atau bagaimana membagi server? (pilihan tersedia dengan RAID1 dan RAID10, hingga 24 core dan hingga 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps hingga Desember secara gratis ketika membayar untuk jangka waktu enam bulan, Anda dapat memesan di
sini .
Dell R730xd 2 kali lebih murah? Hanya kami yang memiliki
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV dari $ 249 di Belanda dan Amerika Serikat! Baca tentang
Cara Membangun Infrastruktur Bldg. kelas menggunakan server Dell R730xd E5-2650 v4 seharga 9.000 euro untuk satu sen?