Pengenalan AI pada level chip memungkinkan Anda untuk memproses lebih banyak data secara lokal, karena peningkatan jumlah perangkat tidak lagi memberikan efek yang sama
Pembuat chip sedang mengerjakan arsitektur baru yang secara signifikan meningkatkan jumlah data yang diproses per watt dan siklus. Tanah ditetapkan untuk salah satu revolusi terbesar dalam arsitektur chip dalam beberapa dekade terakhir.
Semua produsen utama chip dan sistem mengubah arah pengembangan. Mereka memasuki perlombaan arsitektur, yang menyediakan untuk perubahan paradigma dalam segala hal: dari membaca dan menulis metode ke memori, ke pemrosesan mereka dan, pada akhirnya, tata letak berbagai elemen pada sebuah chip. Meskipun miniaturisasi terus berlanjut, tidak ada yang bertaruh pada penskalaan untuk mengatasi ledakan pertumbuhan data dari sensor dan meningkatkan volume lalu lintas antar mesin.
Di antara perubahan dalam arsitektur baru:
- Metode baru untuk memproses jumlah data yang lebih besar dalam siklus 1 jam, terkadang dengan akurasi kurang atau dengan prioritas operasi tertentu, tergantung pada aplikasi.
- Arsitektur memori baru yang mengubah cara kita menyimpan, membaca, menulis, dan mengakses data.
- Modul pemrosesan yang lebih khusus terletak di seluruh sistem dekat dengan memori. Alih-alih prosesor sentral, akselerator dipilih tergantung pada jenis data dan aplikasi.
- Di bidang AI, pekerjaan sedang dilakukan untuk menggabungkan berbagai jenis data dalam bentuk templat, yang secara efektif meningkatkan kepadatan data sambil meminimalkan perbedaan di antara berbagai jenis.
- Sekarang tata letak dalam kasus ini adalah komponen utama dari arsitektur, dengan semakin banyak perhatian diberikan pada kemudahan mengubah desain ini.
"Ada beberapa tren yang memengaruhi kemajuan teknologi," kata Stephen Wu, seorang insinyur Rambus terkemuka. - Di pusat data, Anda memanfaatkan perangkat keras dan perangkat lunak secara maksimal. Dari sudut ini, pemilik pusat data melihat ekonomi. Memperkenalkan sesuatu yang baru itu mahal. Tapi kemacetan berubah, jadi chip khusus diperkenalkan untuk komputasi yang lebih efisien. Dan jika Anda mengurangi arus data bolak-balik ke I / O dan memori, ini bisa berdampak besar. "
Perubahan lebih jelas di tepi infrastruktur komputasi, yaitu, di antara sensor akhir. Pabrikan tiba-tiba menyadari bahwa puluhan miliar perangkat akan menghasilkan terlalu banyak data: volume seperti itu tidak dapat dikirim ke cloud untuk diproses. Tetapi memproses semua data ini secara langsung menimbulkan masalah lain: membutuhkan peningkatan kinerja besar tanpa peningkatan konsumsi daya yang signifikan.
"Ada tren baru ke arah akurasi yang lebih rendah," kata Robert Ober, arsitek platform utama Tesla di Nvidia. - Ini bukan hanya siklus komputasi. Ini adalah pengemasan data yang lebih intensif dalam memori, di mana format instruksi 16-bit digunakan. "
Aubert percaya bahwa berkat serangkaian optimisasi arsitektur di masa mendatang, Anda dapat menggandakan kecepatan pemrosesan setiap beberapa tahun. "Kami akan melihat peningkatan dramatis dalam produktivitas," katanya. - Untuk ini, Anda perlu melakukan tiga hal. Yang pertama adalah komputasi. Yang kedua adalah memori. Area ketiga adalah bandwidth host dan bandwidth I / O. Banyak pekerjaan yang perlu dilakukan untuk mengoptimalkan penyimpanan dan tumpukan jaringan. "
Sesuatu sudah diterapkan. Dalam presentasi di konferensi Hot Chips 2018, Jeff Rupley, arsitek utama di Austin Research Center Samsung, menunjukkan beberapa perubahan arsitektur utama pada prosesor M3. Satu menyertakan lebih banyak instruksi per beat - enam bukan empat dalam chip M2 terakhir. Selain itu, prediksi cabang pada jaringan saraf diimplementasikan dan antrian instruksi digandakan.
Perubahan seperti itu menggeser titik inovasi dari pembuatan sirkuit mikro langsung ke arsitektur dan desain di satu sisi dan ke tata letak elemen di sisi lain rantai produksi. Meskipun inovasi akan terus dilanjutkan dalam proses teknologi, hanya dengan mengorbankannya sangat sulit untuk mencapai peningkatan 15-20% dalam produktivitas dan daya di setiap model chip baru - dan ini tidak cukup untuk mengatasi pertumbuhan cepat dalam volume data.
"Perubahan terjadi pada tingkat eksponensial," kata Victor Pan, Presiden dan CEO Xilinx, dalam pidato di konferensi Hot Chips, "10 zettabytes [10
21 byte] data akan dihasilkan setiap tahun, dan sebagian besar tidak terstruktur."
Pendekatan baru terhadap memori
Bekerja dengan begitu banyak data memerlukan pemikiran ulang setiap komponen dalam sistem, dari metode pemrosesan data hingga penyimpanannya.
"Ada banyak upaya untuk menciptakan arsitektur memori baru," kata Carlos Machin, direktur inovasi senior di eSilicon EMEA. - Masalahnya adalah Anda harus membaca semua baris dan memilih satu bit di setiap baris. Salah satu opsi adalah membuat memori yang bisa dibaca dari kiri ke kanan, serta naik turun. Anda dapat melangkah lebih jauh dan menambahkan perhitungan ke memori. "
Perubahan-perubahan ini termasuk mengubah metode untuk membaca memori, lokasi dan jenis elemen pemrosesan, serta pengenalan AI untuk memprioritaskan penyimpanan, pemrosesan dan pergerakan data di seluruh sistem.
“Bagaimana jika, dalam kasus data jarang, kita hanya dapat membaca satu byte dari array ini pada satu waktu - atau mungkin delapan byte berturut-turut dari jalur byte yang sama tanpa membuang-buang energi pada jalur byte atau byte lain yang tidak kita minati ? "Tanya Mark Greenberg, Direktur Pemasaran Produk Irama." - Di masa depan, ini mungkin. Jika Anda melihat arsitektur HBM2, misalnya, maka tumpukan diatur dalam 16 saluran virtual masing-masing 64 bit, dan Anda hanya perlu mendapatkan 4 kata 64-bit berturut-turut untuk mengakses saluran virtual apa pun. Dengan demikian, dimungkinkan untuk membuat array data dengan lebar 1024 bit, menulis secara horizontal, tetapi membaca secara vertikal empat kata 64-bit sekaligus. "
Memori adalah salah satu komponen utama arsitektur von Neumann, tetapi sekarang juga telah menjadi salah satu arena utama untuk eksperimen. "Musuh utama adalah sistem memori virtual, di mana data dipindahkan dengan cara yang lebih tidak wajar," kata Dan Bouvier, kepala arsitek untuk produk klien di AMD. - Ini adalah siaran siaran. Kami terbiasa dengan ini di bidang grafis. Tetapi jika kita menyelesaikan konflik di bank memori DRAM, kita mendapatkan streaming yang jauh lebih efisien. Kemudian GPU terpisah dapat menggunakan DRAM dalam kisaran efisiensi 90%, yang sangat bagus. Tetapi jika Anda mengatur streaming tanpa gangguan, CPU dan APU juga akan jatuh ke kisaran efisiensi dari 80% hingga 85%. "
 Fig. 1. Arsitektur von Neumann. Sumber: Rekayasa Semikonduktor
Fig. 1. Arsitektur von Neumann. Sumber: Rekayasa SemikonduktorIBM sedang mengembangkan jenis arsitektur memori yang berbeda, yang pada dasarnya merupakan versi agregasi disk yang ditingkatkan. Tujuannya adalah bahwa alih-alih menggunakan drive tunggal, sistem dapat secara sewenang-wenang menggunakan memori apa pun yang tersedia melalui konektor, yang oleh Jeff Stucheli, seorang arsitek perangkat keras IBM, memanggil "Pisau Tentara Swiss" untuk menghubungkan elemen-elemen. Keuntungan dari pendekatan ini adalah memungkinkan Anda untuk mencampur dan mencocokkan berbagai jenis data.
"Prosesor berubah menjadi pusat antarmuka pensinyalan berkinerja tinggi," kata Stucelli. "Jika Anda mengubah mikroarsitektur, inti melakukan lebih banyak operasi per siklus pada frekuensi yang sama."
Konektivitas dan throughput harus memastikan pemrosesan volume data yang dihasilkan secara radikal meningkat. "Kemacetan utama sekarang di lokasi pergerakan data," kata Wu dari Rambus. "Industri ini telah melakukan pekerjaan luar biasa meningkatkan kecepatan komputasi." Tetapi jika Anda mengharapkan data atau templat data khusus, maka Anda harus menjalankan memori lebih cepat. Jadi, jika Anda melihat DRAM dan NVM, kinerjanya tergantung pada pola lalu lintas. Jika data mengalir, maka memori akan memberikan kinerja yang sangat baik. Tetapi jika data datang dalam tetes acak, itu kurang efisien. Dan apa pun yang Anda lakukan, dengan peningkatan volume Anda masih harus melakukannya lebih cepat. "
Lebih banyak komputasi, lebih sedikit lalu lintas.
Masalahnya diperparah oleh kenyataan bahwa ada beberapa jenis data yang berbeda yang dihasilkan pada frekuensi dan kecepatan yang berbeda oleh perangkat di tepi. Agar data ini dapat bergerak bebas di antara modul pemrosesan yang berbeda, manajemen harus menjadi jauh lebih efisien daripada di masa lalu.
"Ada empat konfigurasi utama: banyak-ke-banyak, subsistem memori, IO berdaya rendah, dan topologi grid dan ring," kata Charlie Janak, ketua dan CEO Arteris IP. - Anda dapat menempatkan keempatnya dalam satu chip, yang terjadi dengan chip IoT kunci. Atau Anda dapat menambahkan subsistem HBM throughput tinggi. Tetapi kompleksitasnya sangat besar, karena beberapa dari beban kerja ini sangat spesifik, dan chip memiliki beberapa tugas kerja yang berbeda. Jika Anda melihat beberapa microchip ini, mereka mendapatkan sejumlah besar data. Ini ada dalam sistem seperti radar mobil dan sitar. Mereka tidak dapat eksis tanpa beberapa interkoneksi tingkat lanjut. "
Tugasnya adalah bagaimana meminimalkan pergerakan data, tetapi pada saat yang sama memaksimalkan aliran data saat dibutuhkan - dan entah bagaimana menemukan keseimbangan antara pemrosesan lokal dan terpusat tanpa peningkatan konsumsi energi yang tidak perlu.
"Di satu sisi, ini adalah masalah bandwidth," kata Rajesh Ramanujam, manajer pemasaran produk untuk NetSpeed Systems. - Anda ingin mengurangi lalu lintas sebanyak mungkin, jadi transfer data lebih dekat ke prosesor. Tetapi jika Anda masih perlu memindahkan data, disarankan untuk memadatkannya sebanyak mungkin. Tetapi tidak ada yang eksis dengan sendirinya. Semuanya perlu direncanakan dari tingkat sistem. Pada setiap langkah, beberapa sumbu saling tergantung harus dipertimbangkan. Mereka menentukan apakah Anda menggunakan memori dengan cara tradisional membaca dan menulis, atau apakah Anda menggunakan teknologi baru. Dalam beberapa kasus, Anda mungkin perlu mengubah cara Anda menyimpan data itu sendiri. Jika Anda membutuhkan kinerja yang lebih tinggi, ini biasanya berarti peningkatan area chip, yang mempengaruhi pembuangan panas. Dan sekarang, dengan mempertimbangkan keamanan fungsional, kelebihan data tidak bisa diizinkan. ”
Itulah sebabnya begitu banyak perhatian diberikan pada pemrosesan data di tepi dan saluran bandwidth oleh berbagai modul pemrosesan data. Tetapi ketika Anda mengembangkan arsitektur yang berbeda, sangat berbeda bagaimana dan di mana pemrosesan data ini dilaksanakan.
Sebagai contoh, Marvell memperkenalkan pengontrol SSD dengan AI bawaan untuk menangani beban komputasi yang berat di bagian tepi. Mesin AI dapat digunakan untuk analisis tepat di dalam drive SSD.
"Anda dapat memuat model langsung ke perangkat keras dan melakukan pemrosesan perangkat keras pada pengontrol SSD," kata Ned Varnitsa, chief engineer Marvell. - Hari ini ia membuat server di cloud (host). Tetapi jika setiap disk mengirim data ke cloud, ini akan menciptakan sejumlah besar lalu lintas jaringan. Lebih baik melakukan pemrosesan di tepi, dan tuan rumah hanya mengeluarkan perintah, yang hanya metadata. Semakin banyak drive yang Anda miliki, semakin banyak kekuatan pemrosesan. Ini adalah manfaat besar dari pengurangan lalu lintas. "
Pendekatan ini sangat menarik karena dapat beradaptasi dengan data yang berbeda tergantung pada aplikasinya. Jadi, tuan rumah dapat menghasilkan tugas dan mengirimkannya ke perangkat penyimpanan untuk diproses, setelah itu hanya metadata atau hasil perhitungan yang dikirim kembali. Dalam skenario lain, perangkat penyimpanan dapat menyimpan data, melakukan pra-proses, dan menghasilkan metadata, tag, dan indeks, yang kemudian diambil oleh host sesuai kebutuhan untuk analisis lebih lanjut.
Ini adalah salah satu opsi yang memungkinkan. Ada yang lain. Rupli Samsung menekankan pentingnya pemrosesan dan penggabungan idiom yang dapat memecahkan kode dua instruksi dan menggabungkannya menjadi satu operasi.
AI berurusan dengan kontrol dan optimisasi
Di semua level optimisasi, Artificial Intelligence digunakan - ini adalah salah satu elemen yang benar-benar baru dalam arsitektur chip. Alih-alih membiarkan sistem operasi dan middleware untuk mengelola fungsi, fungsi pemantauan ini didistribusikan di seluruh chip, di antara chip, dan di tingkat sistem. Dalam beberapa kasus, jaringan saraf perangkat keras diperkenalkan.
“Intinya bukan untuk mengemas lebih banyak lagi, tetapi untuk mengubah arsitektur tradisional,” kata Mike Gianfanya, wakil presiden pemasaran, eSilicon. - Dengan bantuan AI dan pembelajaran mesin, Anda dapat mendistribusikan elemen di seluruh sistem, mendapatkan pemrosesan yang lebih efisien dengan peramalan. Atau Anda dapat menggunakan chip terpisah yang berfungsi secara independen dalam sistem atau dalam modul. "
ARM telah mengembangkan chip pembelajaran mesin pertamanya, yang rencananya akan dirilis akhir tahun ini untuk beberapa pasar. "Ini adalah jenis prosesor baru," kata Ian Bratt, Insinyur yang Terhormat dari ARM. - Ini termasuk blok fundamental - itu adalah mesin komputasi, serta mesin MAC, mesin DMA dengan modul kontrol dan jaringan siaran. Total ada 16 core komputasi yang dibuat menggunakan teknologi proses 7 nm, yang menghasilkan 4 TeraOps pada frekuensi 1 GHz. "
Karena ARM bekerja dengan ekosistem mitra, chipnya lebih fleksibel dan dapat disesuaikan daripada chip AI / ML lainnya yang sedang dikembangkan. Alih-alih struktur monolitik, ia memisahkan pemrosesan berdasarkan fungsi, sehingga setiap modul komputasi bekerja pada peta fitur yang terpisah. Bratt mengidentifikasi empat bahan utama: perencanaan statis, lipat efisien, mekanisme penyempitan dan adaptasi terprogram untuk perubahan desain masa depan.
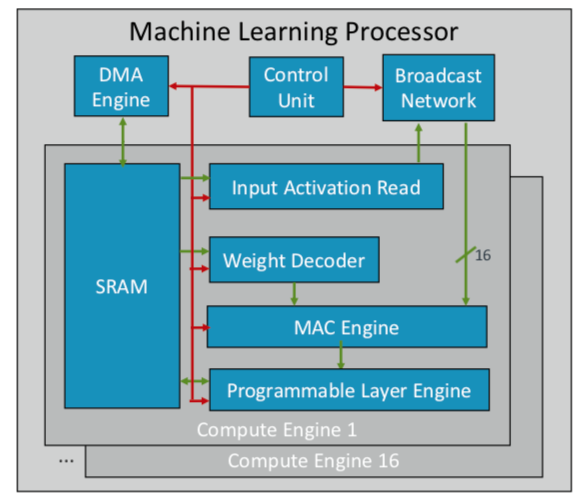 Fig. 2. Prosesor arsitektur ARM ML. Sumber: ARM / Hot Chips
Fig. 2. Prosesor arsitektur ARM ML. Sumber: ARM / Hot ChipsSementara itu, Nvidia memilih taktik yang berbeda: menciptakan mesin pembelajaran dalam yang berdedikasi di sebelah GPU untuk mengoptimalkan pemrosesan gambar dan video.
Kesimpulan
Menggunakan beberapa atau semua pendekatan ini, produsen chip berharap untuk menggandakan kinerja setiap dua tahun, mengikuti pertumbuhan data yang eksplosif, sambil tetap berada dalam kerangka ketat anggaran konsumsi energi. Tapi ini bukan hanya komputasi. Ini adalah perubahan dalam platform desain chip dan sistem, ketika volume data yang tumbuh, bukannya keterbatasan perangkat keras dan perangkat lunak, menjadi faktor utama.
"Ketika komputer muncul di perusahaan-perusahaan, tampaknya bagi banyak orang di dunia kita telah mengalami percepatan," kata Aart de Gues, ketua dan kepala eksekutif Synopsys. - Mereka melakukan akuntansi pada selembar kertas dengan tumpukan buku. Buku besar telah berubah menjadi setumpuk kartu punch untuk pencetakan dan komputasi. Perubahan luar biasa telah terjadi, dan kami melihatnya lagi. Dengan munculnya komputer komputasi sederhana secara mental, algoritme tindakan tidak berubah: Anda dapat melacak setiap langkah. Tetapi sekarang sesuatu yang lain terjadi yang dapat mengarah pada akselerasi baru. Ini seperti di ladang pertanian untuk memasukkan penyiraman dan menerapkan jenis pupuk tertentu hanya pada hari tertentu, ketika suhu mencapai tingkat yang diinginkan. Penggunaan pembelajaran mesin ini merupakan optimasi yang tidak jelas di masa lalu. "
Dia tidak sendirian dalam penilaian ini. "Arsitektur baru akan diadopsi," kata Wally Raines, presiden dan CEO Mentor, Siemens Business. - Mereka akan dirancang. Pembelajaran mesin akan digunakan dalam banyak atau sebagian besar kasus, karena otak Anda belajar dari pengalamannya sendiri. Saya mengunjungi 20 atau lebih perusahaan yang mengembangkan prosesor AI khusus dari satu jenis atau lainnya, dan masing-masing memiliki ceruk kecil sendiri. Tetapi Anda akan semakin melihat aplikasinya dalam aplikasi spesifik, dan mereka akan melengkapi arsitektur von Neumann tradisional. Komputasi neuromorfik akan menjadi arus utama. Ini adalah langkah besar dalam efisiensi komputasi dan pengurangan biaya. Perangkat dan sensor seluler akan mulai melakukan pekerjaan yang dilakukan server hari ini. "