Beberapa tahun yang lalu, sistem rekomendasi baru saja mulai memenangkan konsumen mereka. Toko online aktif menggunakan algoritma rekomendasi, menawarkan pelanggan mereka lebih banyak dan lebih banyak produk baru berdasarkan sejarah belanja mereka.
Dalam layanan klien, sistem rekomendasi telah menjadi relevan belum lama ini. Karena peningkatan konten yang ditawarkan, pelanggan mulai tersesat dalam arus informasi apa, di mana dan kapan mereka perlu melihat. Operator TV berbayar dan teater film online membuat pusing pecinta konten video.

Sebagai cara yang efektif untuk memecahkan masalah kekal "apa yang harus dilihat?" sistem rekomendasi telah muncul yang bekerja berdasarkan model matematika tertentu.
Dua tahun lalu, kami memperkenalkan sistem rekomendasi, kemudian menambahkannya dengan pilihan editorial dan merasakan efek yang nyata baik dalam penjualan maupun dalam durasi menggunakan layanan kami.
Apa itu sistem rekomendasi
Sistem pemberi rekomendasi adalah ketika Anda ingin melihat sesuatu, tetapi tidak tahu persisnya, dan TV berhasil menebak preferensi Anda. Ini adalah pemfilteran konten yang memilih film dan acara TV berdasarkan preferensi dan analisis perilaku pengguna. Sistem yang digunakan oleh operator harus memprediksi reaksi pemirsa terhadap elemen tertentu dan menawarkan konten yang ia sukai.
Saat memprogram sistem rekomendasi, tiga metode utama digunakan: penyaringan kolaboratif, penyaringan berbasis konten, dan sistem pakar (sistem berbasis pengetahuan).
Penyaringan kolaboratif didasarkan pada tiga tahap: mengumpulkan informasi pengguna, membangun sebuah matriks untuk menghitung asosiasi dan mengeluarkan rekomendasi yang dapat diandalkan.
Contoh penyaringan kolaboratif yang baik adalah Cinematch, yang digunakan Netflix. Pengguna secara eksplisit atau implisit memberikan peringkat untuk film yang ditonton, dan rekomendasi dibentuk dengan mempertimbangkan peringkat pengguna mereka dan orang-orang dari pemirsa lain. Untuk melakukan ini, sistem memilih pengguna dengan preferensi yang serupa, yang peringkatnya dekat dengan mereka. Berdasarkan pendapat lingkaran orang ini, pemirsa secara otomatis diberikan rekomendasi: untuk menonton film tertentu.
Untuk operasi maksimum yang benar dari sistem pemberi rekomendasi, tentu saja, data yang dikumpulkan dan dikumpulkan memainkan peran mendasar. Semakin banyak data terakumulasi tentang profil konsumsi pelanggan tertentu, rekomendasi yang lebih akurat dikeluarkan kepadanya.
Sistem rekomendasi konten dirumuskan berdasarkan pada atribut yang ditetapkan untuk setiap elemen. Jika Anda menonton film dari genre tertentu, sistem akan secara otomatis menawarkan konten yang dekat dengan genre Anda pada posisi tertentu. Atas dasar sistem rekomendasi itulah situs web Pandora berfungsi.
Sistem rekomendasi ahli menawarkan rekomendasi tidak berdasarkan peringkat, tetapi berdasarkan kesamaan antara persyaratan pengguna dan deskripsi produk, atau tergantung pada batasan yang ditetapkan oleh pengguna saat menentukan produk yang diinginkan. Oleh karena itu, jenis sistem ini unik, karena memungkinkan klien untuk secara eksplisit menunjukkan apa yang diinginkannya.
Sistem pakar paling efektif dalam konteks di mana jumlah data yang tersedia terbatas, dan penyaringan kolaboratif bekerja paling baik di lingkungan di mana ada sejumlah besar data. Tetapi ketika data terdiversifikasi, dimungkinkan untuk memecahkan masalah yang sama dengan metode yang berbeda. Ini berarti bahwa secara optimal akan menggabungkan rekomendasi yang diterima dalam beberapa cara, sehingga meningkatkan kualitas sistem secara keseluruhan.
Ini adalah sistem hybrid dari E-Contenta yang bekerja di layanan
TV WiFire kami. Itu dimasukkan ke dalam operasi dan debugging pada bulan Desember 2016 dan bekerja sesuai dengan prinsip berikut: jika sistem tahu banyak tentang pengguna atau tentang konten, maka algoritma penyaringan kolaboratif menang. Jika konten tersebut baru, atau informasi yang tidak memadai dikumpulkan tentang interaksi pengguna dengannya, maka algoritma konten digunakan untuk mengevaluasi kesamaan konten berdasarkan metadata yang ada.
Bagaimana rekomendasi algoritma dibangun
Untuk membangun pilihan yang dipersonalisasi dalam E-Contenta, perlu untuk menentukan peringkat semua konten yang tersedia dengan probabilitas bahwa pengguna tertentu akan tertarik pada konten ini.
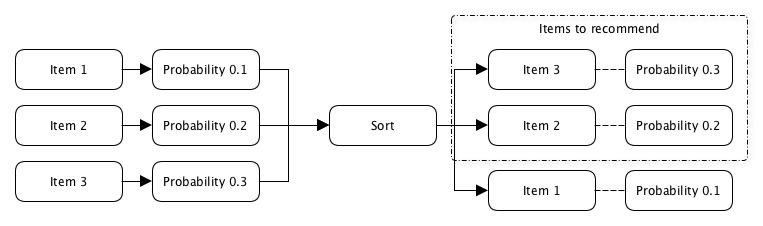
Minat pengguna terutama ditentukan pada saat dia mengklik konten yang direkomendasikan kepadanya, dan probabilitasnya didefinisikan sebagai rasio jumlah klik dengan jumlah kali ketika konten ini direkomendasikan kepada pengguna ini.
p (klik) = N klik / N menampilkanKesulitannya terletak pada kenyataan bahwa Anda perlu merekomendasikan kepada pengguna sesuatu yang belum pernah dilihatnya, yang berarti bahwa tidak ada data tentang jumlah klik atau tayangan untuk menghitung probabilitas ini.
Oleh karena itu, alih-alih probabilitas aktual, diputuskan untuk menggunakan estimasi probabilitas ini, dengan kata lain, nilai prediksi.
Gagasan filter kolaboratif sederhana:
- Ambil data historis tentang pengguna yang melihat konten
- Berdasarkan data ini, kelompokkan pengguna berdasarkan konten yang mereka lihat
- Untuk pengguna tertentu untuk memprediksi kemungkinan minatnya pada unit konten tertentu, berdasarkan data historis pengguna lain dalam grup yang sama.
Dengan demikian, pengguna bersama-sama berpartisipasi dalam proses pemilihan konten.
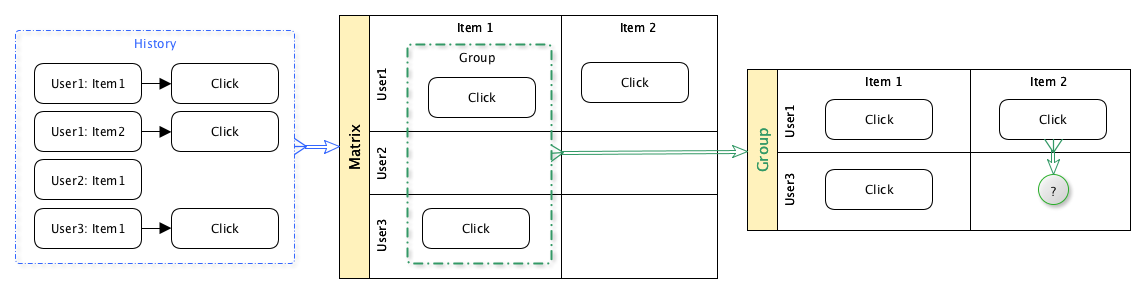
Ada banyak opsi berbeda untuk menerapkan pendekatan ini:
1. Buat model menggunakan pengidentifikasi langsung unit konten:
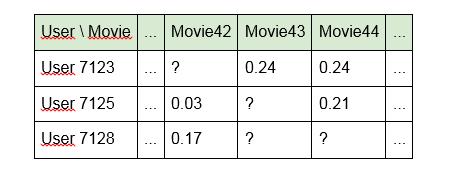
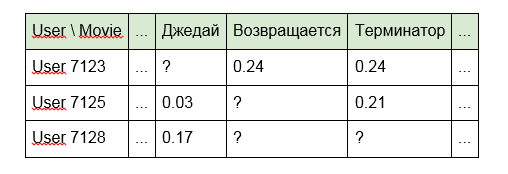
Kerugian dari pendekatan ini adalah bahwa model "tidak melihat" tautan apa pun antara unit konten. Misalnya, "Terminator" dan "Terminator 2" untuknya akan jauh dari satu sama lain sebagai "Alien" dan "Selamat malam, Anak-anak!". Selain itu, matriks itu sendiri ternyata sangat jarang (banyak sel kosong dan sedikit terisi).
2. Alih-alih pengidentifikasi, gunakan kata-kata yang termasuk dalam judul artikel, program, atau film:
3. Untuk film, nama aktor, sutradara atau data dari IMDb:
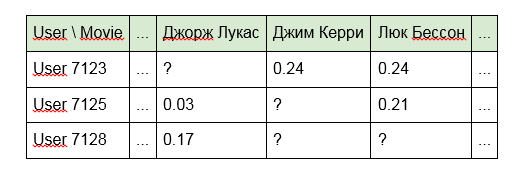
Opsi kedua dan ketiga menghilangkan sebagian kelemahan dari pendekatan pertama, mengingat koneksi konten yang memiliki fitur umum (dari sutradara yang sama atau kata-kata yang sama dalam judul). Namun, sparsity dari matriks juga berkurang, tetapi seperti yang mereka katakan, tidak ada batasan untuk kesempurnaan.
Menjaga berbagai peringkat pengguna dalam memori cukup mahal. Mengambil perkiraan kasar jumlah pengguna Runet pada 80 juta orang dan ukuran basis data IMDb pada 370 ribu film, kami mendapatkan ukuran yang diperlukan 27 Terabyte. Dekomposisi singular adalah metode untuk mengurangi dimensi matriks.
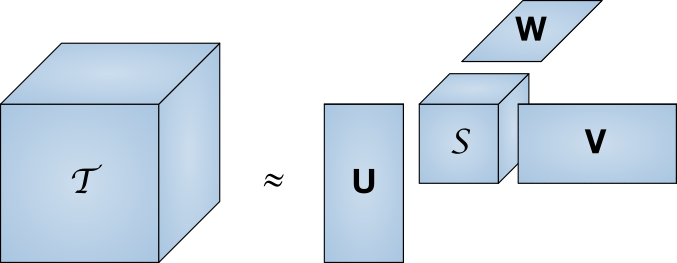 Matriks T besar direpresentasikan sebagai produk dari serangkaian matriks yang lebih kecil
Matriks T besar direpresentasikan sebagai produk dari serangkaian matriks yang lebih kecilDengan kata lain, pencarian matriks "inti", yang memiliki sifat yang sama dengan matriks penuh, tetapi jauh lebih kecil. Seiring dengan penurunan dimensi, pemakaian juga menurun. Pada artikel ini, kita tidak akan membahas seluk-beluk implementasi, terutama karena perpustakaan yang sudah jadi sudah ada untuk sejumlah bahasa pemrograman.
Kesulitan teknis
Mulai dinginSituasi ketika kurangnya data untuk konten baru atau pengguna tidak memungkinkan untuk memberikan rekomendasi berkualitas tinggi, juga dikenal sebagai "Cold Start", adalah masalah khas untuk penyaringan kolaboratif.
Salah satu solusinya adalah mencampur beberapa unit konten ke dalam rekomendasi yang tidak mengumpulkan cukup data. Pada saat yang sama, konten paling populer akan direkomendasikan kepada pengguna baru.
Paling populerDengan menggunakan pendekatan di atas, penting untuk tidak lupa bahwa konsekuensinya akan menjadi peningkatan sistematis dalam frekuensi terjadinya "paling populer" dalam daftar yang direkomendasikan. Belajar dari perilaku pengguna yang sering ditawari "paling populer," sistem merekomendasikan risiko belajar merekomendasikan secara eksklusif konten yang paling populer.
Perbedaan utama antara rekomendasi pribadi dan rekomendasi dangkal dari konten yang paling populer adalah bahwa mereka mempertimbangkan selera masing-masing, yang dapat berbeda secara signifikan dari yang "rata-rata".
Dengan demikian, sampel reaksi pengguna terhadap konten yang digunakan untuk melatih model pemberi rekomendasi harus dinormalisasi.
Ketersediaan, Kegagalan, dan SkalabilitasJumlah pengguna sumber daya dapat membuat beban ratusan dan ribuan permintaan ke sistem rekomendasi per detik. Selain itu, kegagalan satu atau beberapa server tidak seharusnya mengarah pada penolakan layanan.
Dalam kasus ini, solusi klasik adalah menggunakan load balancer yang mengirimkan permintaan ke salah satu server cluster. Selain itu, masing-masing server dapat memproses permintaan masuk. Dalam hal terjadi kegagalan dari salah satu server di kluster, penyeimbang secara otomatis mengalihkan beban ke server yang tersisa di sistem. Dengan memilih HTTP sebagai protokol transport, kita dapat menggunakan Nginx sebagai penyeimbang beban.
Saat pemirsa sumber daya bertambah, jumlah server di kluster dapat bertambah. Dalam hal ini, penting untuk meminimalkan biaya mempersiapkan server baru.
Sistem pemberi rekomendasi membutuhkan pemasangan sejumlah komponen yang menjadi sandarannya secara fungsional. Docker digunakan untuk mengotomatiskan penyebaran sistem rekomendasi dengan semua dependensinya.
Docker memungkinkan Anda untuk mengumpulkan semua komponen yang diperlukan, "mengemas" komponen-komponen tersebut ke dalam gambar dan memasukkan gambar tersebut ke dalam repositori (registri), lalu mengunduh dan menggunakannya di server baru dalam hitungan menit. Keuntungan penting dari Docker adalah bahwa "overhead" ketika menggunakannya minimal: waktu panggilan aplikasi dalam wadah buruh pelabuhan meningkat beberapa nanodetik dibandingkan dengan aplikasi yang berjalan di sistem operasi biasa.
Keuntungan penting lainnya adalah kemampuan untuk dengan cepat kembali ke versi stabil aplikasi sebelumnya jika terjadi kegagalan baru (cukup ambil versi lama dari registri).
Tipe kedua dari permintaan sistem yang perlu Anda perhatikan adalah permintaan yang melacak aktivitas pengguna. Agar pengguna tidak harus menunggu sampai sistem benar-benar memproses tindakan yang ia lakukan, proses pemrosesan dilakukan terlepas dari proses tindakan perekaman.
Apache Kafka dipilih di E-Contenta sebagai platform yang menyediakan transfer data tindakan pengguna ke prosesor. Kafka mengimplementasikan pola arsitektur Message-Oriented Middleware), yang mampu memberikan jaminan pengiriman puluhan dan ratusan ribu pesan per detik dan bertindak sebagai penyangga yang melindungi penangan dari volume data yang berlebihan pada waktu puncak.
Belajar mandiri sepenuhnyaKonten baru dan pengguna baru muncul secara teratur - tanpa pelatihan reguler, kualitas model menurun. Pelatihan harus dilakukan pada server yang terpisah sehingga proses pelatihan, yang membutuhkan sumber daya komputasi yang signifikan, tidak mempengaruhi kinerja server tempur.
Solusi klasik untuk mengatur tugas yang didistribusikan secara reguler adalah Jenkins. Layanan terjadwal mulai menerima dan menormalkan sampel pelatihan baru, melatih model rekomendasi, memberikan model baru dan memperbarui semua server cluster, yang memungkinkan menjaga kualitas rekomendasi tanpa upaya tambahan. Dalam hal terjadi kegagalan pada salah satu langkah, Jenkins secara mandiri mengembalikan sistem ke kondisi stabil sebelumnya dan memberi tahu administrator tentang kegagalan tersebut.
Tentang bagaimana kami menerapkannya di WifireTV
Selain itu, agar sistem berfungsi dengan benar, kami mengundang meter televisi independen dan mengundangnya untuk mengukur teleview pelanggan. Data unik yang dihasilkan dianimasikan menggunakan algoritma ilmu data. Umpan balik yang terus-menerus bekerja dari pelanggan yang berinteraksi dengan rekomendasi mengisi dasar preseden untuk algoritma pembelajaran mesin dan memungkinkan rekomendasi untuk berubah tergantung pada tanda-tanda implisit dari perubahan preferensi pelanggan, seperti waktu dalam setahun, mendekati liburan, atau mengubah komposisi keluarga.
Dalam proses pengujian, kami harus menyelesaikan masalah yang terkait dengan rekomendasi konten televisi - bagaimana membantu pelanggan kami memahami aliran siaran. Tugas ini juga rumit oleh layanan tampilan yang ditangguhkan. Kami telah membangun sebuah sistem yang alih-alih pengalihan saluran siklik yang tak ada habisnya membantu menemukan program yang menarik hanya dalam 2-3 penekanan tombol. Untuk ini, sistem rekomendasi memantau rilis serangkaian program baru dan memprediksi minat pemirsa dalam program tidak teratur dan siaran film. Bahkan, algoritma mesin menggantikan pekerjaan editor yang bertanggung jawab.
Bekerja dengan streaming televisi memiliki kekhasan tersendiri. Misalnya, sering acara TV yang sama populer di saluran yang berbeda. Dalam hal ini, sistem pemberi rekomendasi harus memahami duplikasi informasi dan memilih rekomendasi berdasarkan preferensi pelanggan mengenai saluran, waktu mulai transmisi, dll. Duplikasi informasi semacam itu juga terjadi ketika pelanggan berlangganan saluran versi SD dan HD.
Selama dua tahun ini, kami bereksperimen dengan versi berbeda dari sistem rekomendasi dan menemukan jalan tengah, yang memungkinkan kami untuk meningkatkan keterlibatan pemirsa dan lebih efektif memonetisasi konten yang ada. Kami menggunakan pilihan otomatis rekomendasi yang dijelaskan di atas bersama dengan penyetelan manual - pilihan editorial.
Pendekatan ini diizinkan untuk secara signifikan (10 kali) meningkatkan monetisasi layanan VOD dan SVOD.
Rekomendasi editorial adalah koleksi film dan seri tematik yang terkait dengan pertunjukan perdana, liburan, dan tanggal yang mengesankan. Sangat mudah untuk memberi tahu pelanggan dan memberi mereka kesempatan untuk menonton film baru, hit lama atau tidak populer, tetapi menurut kami film yang sangat menarik dalam hal konten dan plot. Kami berkomunikasi secara dekat dengan para pemasok kami (bioskop online dan layanan video tambahan, seperti ivi, megogo, amediateka) dan secara pribadi memilih setiap film yang akan menarik untuk ditonton oleh pelanggan kami.
Pada hari libur, kami membuat pilihan khusus pada topik tertentu. Misalnya, pada Hari Kemenangan, ini adalah film bertema militer. Pada tanggal 1 September - pemilihan konten untuk anak-anak, yang terdiri dari program pendidikan, kartun, dan film dokumenter.
Pemilihan manual dengan sempurna meningkatkan loyalitas pelanggan kami. Menurut perkiraan kami yang paling konservatif, sekitar 10% dari film menonton bulanan basis pelanggan kami yang kami rekomendasikan dan indikator ini terus tumbuh.
Apa hasilnya?
Wifire TV saat ini menjalankan sistem rekomendasi cerdas dari E-Contenta. Ini didasarkan pada ilmu data dan metadata dari 90% pelanggan operator. Algoritma memperhitungkan ratusan data akun: apa yang ditonton pelanggan, film dan program apa yang populer, ketika ia menggunakan layanan dan siapa yang sekarang di depan layar. Kami ingin menyampaikan kepada pelanggan kami nilai berlangganan paket saluran premium, mencampurkannya ke dalam rekomendasi yang relevan bagi pengguna. Kami juga ingin menunjukkan bahwa memperoleh dan menonton konten video legal adalah normal, nyaman, dan sederhana.
Sistem rekomendasi akan memberi tahu pelanggan film-film yang menarik, bahkan jika mereka telah lama keluar dari kategori produk baru: dengan demikian, direktori video yang luas berhenti menjadi perpustakaan yang berdebu, dan menjadi sebuah karya interaktif yang secara fleksibel menyesuaikan dengan selera dan suasana hati pelanggan.