Pada artikel ini, saya ingin berbicara tentang beberapa teknik untuk bekerja dengan data saat melatih model. Khususnya, cara menarik segmentasi objek pada kotak, serta cara melatih model dan mendapatkan markup dataset, menandai hanya beberapa sampel.
Tantangan
Ada proses tertentu membuat pizza dan foto dari berbagai tahapannya (termasuk tidak hanya pizza). Diketahui bahwa jika resep adonan rusak, maka akan timbul jerawat putih di kulitnya. Ada juga tanda biner dari kualitas tes untuk setiap contoh pizza, yang dibuat oleh para ahli. Perlu untuk mengembangkan algoritma yang akan menentukan kualitas tes sesuai dengan foto.
Dataset terdiri dari foto yang diambil dari ponsel yang berbeda, dalam kondisi berbeda, sudut berbeda. Mesin pembuat pizza - 17k. Total foto - 60rb.
Menurut pendapat saya, tugas ini cukup tipikal dan cocok untuk menunjukkan berbagai pendekatan penanganan data. Untuk mengatasinya, Anda harus:
1. Pilih foto di mana ada kerak pizza;
2. Pada foto yang dipilih, sorot kue;
3. Latih jaringan saraf di area yang dipilih.
Memfilter foto
Pada pandangan pertama sepertinya cara termudah adalah memberikan tugas ini kepada juru tulis, dan kemudian melatih dataset tentang data bersih. Namun, saya memutuskan bahwa lebih mudah bagi saya untuk menandai sebagian kecil diri saya daripada menjelaskan dengan juru tulis sudut mana yang benar. Selain itu, saya tidak memiliki kriteria keras untuk sudut yang tepat.
Jadi inilah yang saya lakukan:
1. Ditandai 100 foto tepi;

2. Saya menghitung fitur setelah penarikan global dari grid resnet-152 dengan bobot dari imagenet11k_places365;
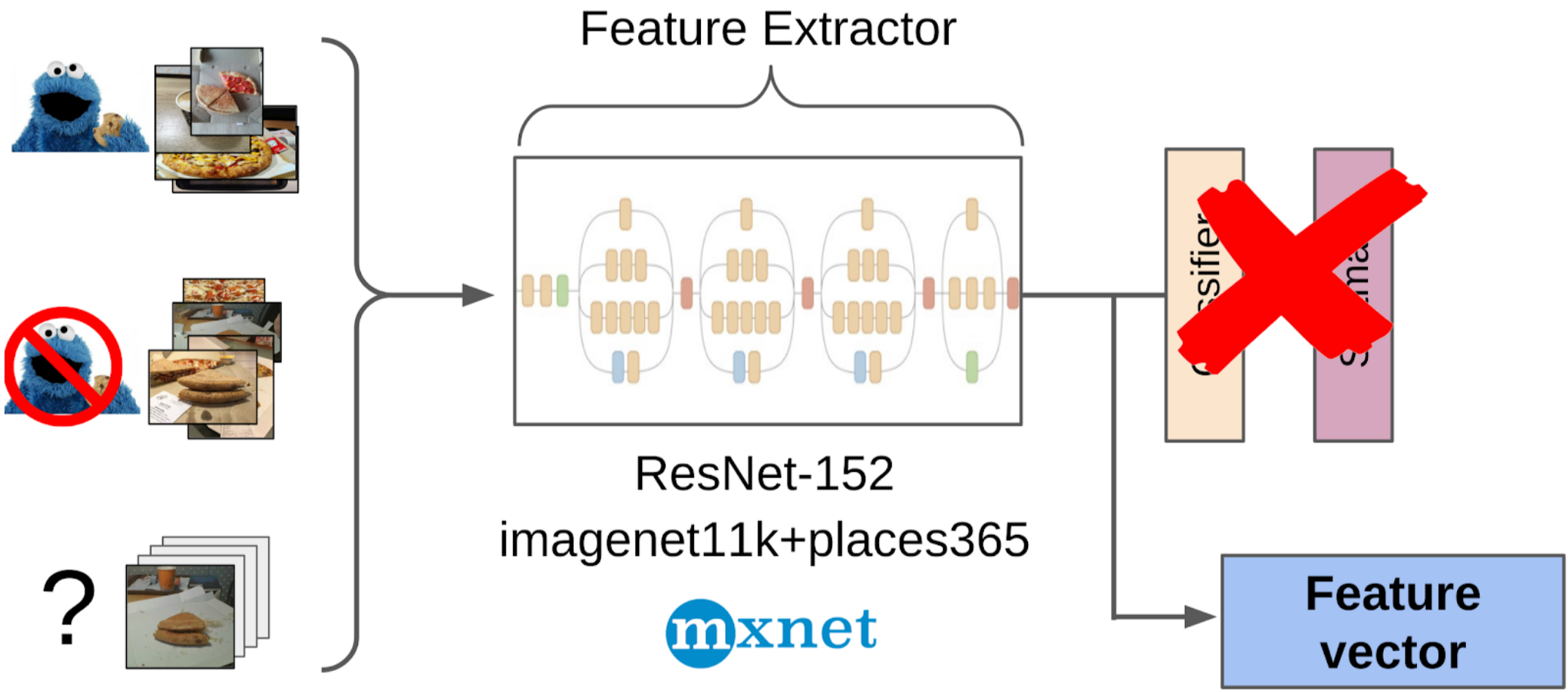
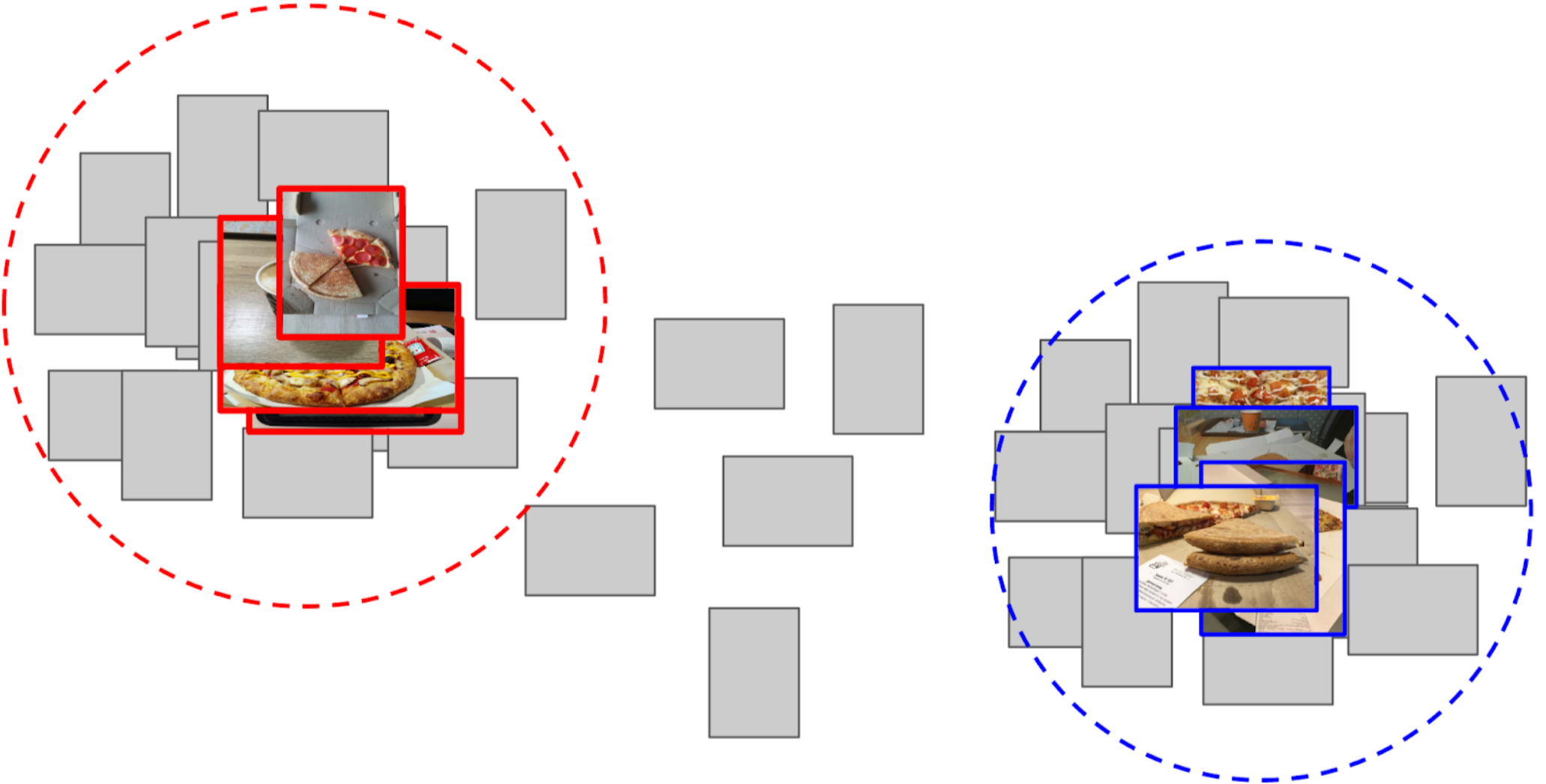
3. Mengambil rata-rata fitur dari setiap kelas, menerima dua jangkar;
4. Saya menghitung jarak dari setiap jangkar ke semua fitur dari 50k foto yang tersisa;
5. 300 teratas yang dekat dengan satu jangkar relevan dengan kelas positif, 500 teratas yang paling dekat dengan jangkar lainnya adalah negatif;
6. Saya melatih LightGBM pada sampel ini dengan fitur yang sama (XGboost ditunjukkan dalam gambar, karena memiliki logo dan lebih mudah dikenali, tetapi LightGBM tidak memiliki logo);
7. Menggunakan model ini, saya mendapat markup seluruh dataset.

Saya menggunakan pendekatan yang kira-kira sama dalam kompetisi kaggle sebagai
garis dasar .
Penjelasan di jari mengapa pendekatan ini bahkan berhasilJaringan saraf dapat dianggap sebagai transformasi gambar yang sangat non-linear. Dalam kasus klasifikasi, gambar diubah menjadi probabilitas kelas yang ada di set pelatihan. Dan probabilitas ini pada dasarnya dapat digunakan sebagai fitur untuk Light GBM. Namun, ini adalah deskripsi yang agak buruk, dan dalam hal pizza kita akan mengatakan bahwa kelas kue kondisional 0,3 kucing dan 0,7 anjing, dan sisanya adalah sisanya. Sebagai gantinya, Anda dapat menggunakan lebih sedikit fitur setelah Global Average Pooling. Mereka memiliki sifat sedemikian rupa sehingga fitur dihasilkan dari sampel set pelatihan, yang harus dipisahkan oleh transformasi linear (lapisan yang sepenuhnya terhubung dengan Softmax). Namun, karena fakta bahwa tidak ada pizza eksplisit di kereta imagenet, lebih baik untuk mengambil transformasi non-linear dalam bentuk pohon untuk memisahkan kelas-kelas dari set pelatihan baru. Pada prinsipnya, Anda dapat melangkah lebih jauh dan mengambil fitur dari beberapa lapisan menengah dari jaringan saraf. Mereka akan menjadi lebih baik karena mereka belum kehilangan lokasi benda. Tetapi mereka jauh lebih buruk karena ukuran vektor fitur. Dan selain itu, mereka kurang linier daripada di depan lapisan yang sepenuhnya terhubung.
Sedikit penyimpangan
ODS baru-baru ini mengeluh bahwa tidak ada yang menulis tentang kegagalan mereka. Memperbaiki situasi. Sekitar setahun yang lalu, saya berpartisipasi dalam kompetisi
Kaggle Sea Lions dengan
Eugene Nizhibitsky . Tugasnya adalah untuk menghitung anjing laut berbulu dalam gambar dari drone. Markup diberikan hanya dalam bentuk koordinat bangkai, tetapi pada titik tertentu
Vladimir Iglovikov menandainya dengan kotak-kotak dan dengan murah hati membagikannya dengan komunitas. Pada saat itu, saya menganggap diri saya sebagai ayah dari segmentasi semantik (setelah
Kaggle Dstl ) dan memutuskan bahwa Unet akan sangat memudahkan tugas menghitung jika saya belajar membedakan kucing secara klasik.
Penjelasan segmentasi semantikSegmentasi semantik pada dasarnya adalah klasifikasi piksel-demi-piksel dari suatu gambar. Artinya, setiap piksel sumber gambar perlu dikaitkan dengan kelas. Dalam kasus segmentasi biner (kasus artikel), itu akan menjadi kelas positif atau negatif. Dalam hal segmentasi multi-kelas, setiap piksel akan diberi kelas dari set pelatihan (latar belakang, rumput, kucing, manusia, dll.). Dalam kasus segmentasi biner, arsitektur jaringan saraf
U-net bekerja dengan baik pada waktu itu. Jaringan saraf ini memiliki struktur yang mirip dengan encoder-decoder konvensional, tetapi dengan fitur penerusan dari bagian encoder ke decoder pada tahapan ukuran yang sesuai.

Namun dalam bentuk vanilla, tidak ada yang menggunakannya lagi, tetapi setidaknya mereka menambahkan Batch Norm. Sebagai aturan, mereka mengambil
encoder yang gemuk dan mengembang decoder. Arsitektur seperti U-net telah digantikan oleh grid segmentasi
FPN baru , yang menunjukkan kinerja yang baik pada beberapa tugas. Namun, arsitektur mirip Unet belum kehilangan relevansinya hingga hari ini. Mereka bekerja dengan baik sebagai garis dasar, mereka mudah untuk dilatih, dan sangat sederhana untuk memvariasikan kedalaman / ukuran neuroscience dengan mengubah eccoder yang berbeda.
Oleh karena itu, saya mulai mengajarkan segmentasi, karena pada awalnya hanya menjadi target kucing tinju. Setelah tahap pertama pelatihan, saya memprediksi kereta dan melihat bagaimana prediksi itu terlihat. Dengan bantuan heuristik, seseorang dapat memilih kepercayaan abstrak dari topeng dan secara kondisional membagi prediksi menjadi dua kelompok: di mana semuanya baik dan di mana semuanya buruk.

Prediksi di mana semuanya baik-baik dapat digunakan untuk melatih iterasi model berikutnya. Prediksi, di mana semuanya buruk, bisa dipilih dengan area besar tanpa segel, bertopeng tangan, dan juga dilemparkan ke kereta. Dan dengan iteratif, Eugene dan saya melatih model yang bahkan belajar untuk membagi sirip anjing laut untuk individu besar.
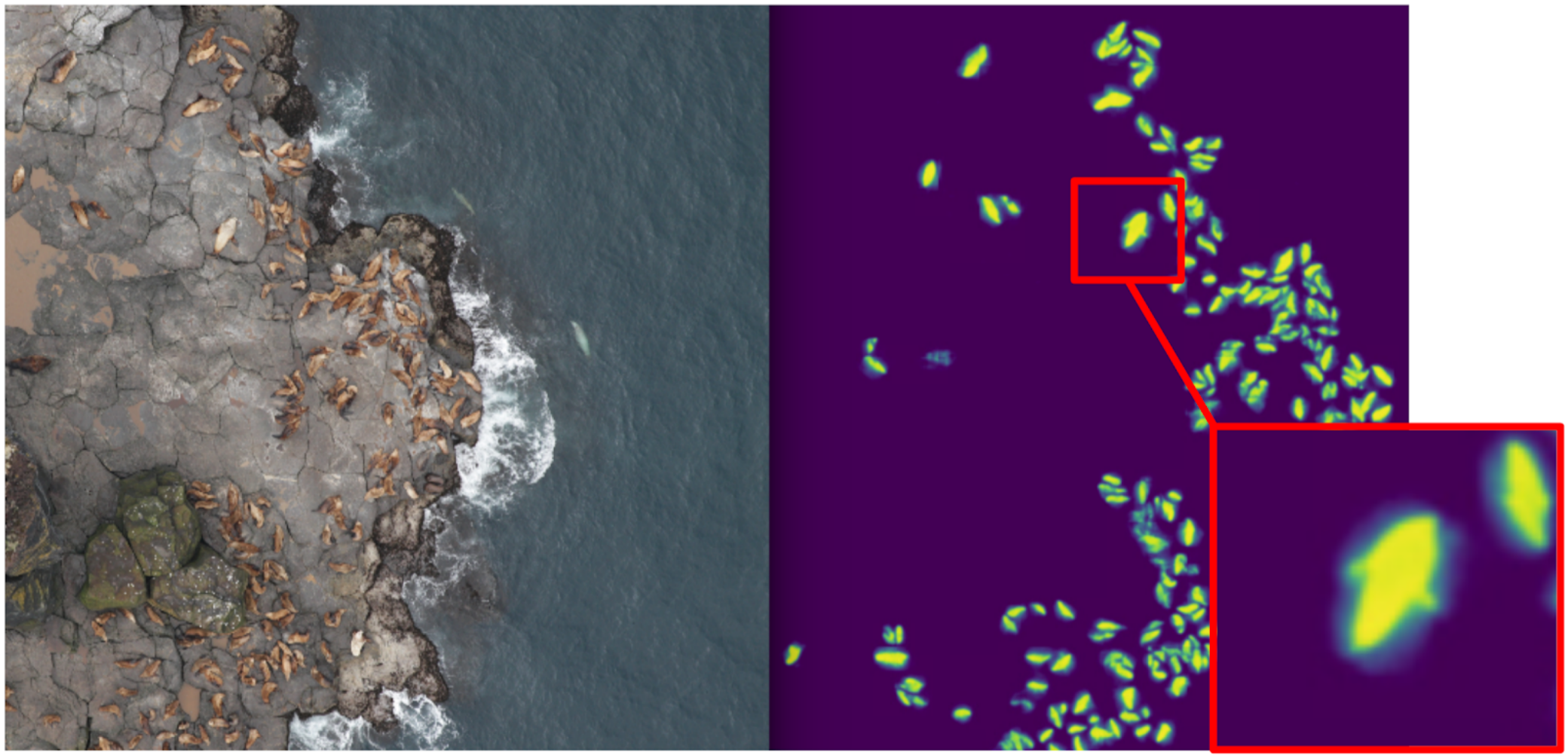
Tapi itu adalah kegagalan yang hebat: kami menghabiskan banyak waktu untuk belajar bagaimana membagi kucing yang keren dan ... Itu hampir tidak membantu dalam perhitungan mereka. Asumsi bahwa kerapatan segel (jumlah individu per unit luas topeng) konstan tidak berfungsi, karena drone terbang pada ketinggian yang berbeda, dan gambar memiliki skala yang berbeda. Dan pada saat yang sama, segmentasi masih tidak memilih individu individu jika mereka berbaring ketat - yang sering terjadi. Dan sebelum
pendekatan inovatif untuk pemisahan objek tim Tocoder di DSB2018, masih ada satu tahun lagi. Sebagai hasilnya, kami hanya bertahan di tempat ke-40 dari 600 tim.
Namun, saya membuat dua kesimpulan: segmentasi semantik adalah pendekatan yang nyaman untuk memvisualisasikan dan menganalisis operasi algoritma, dan topeng dapat dilas dari kotak dengan beberapa upaya.
Tapi kembali ke pizza. Untuk menyorot kue pada foto yang dipilih dan difilter, opsi yang paling benar adalah memberikan tugas kepada juru tulis. Pada saat itu, kami sudah menerapkan kotak dan algoritma konsensus untuk mereka. Jadi saya hanya melemparkan beberapa contoh dan memberikannya ke markup. Hasilnya, saya mendapat 500 sampel dengan area kerak yang dipilih dengan tepat.
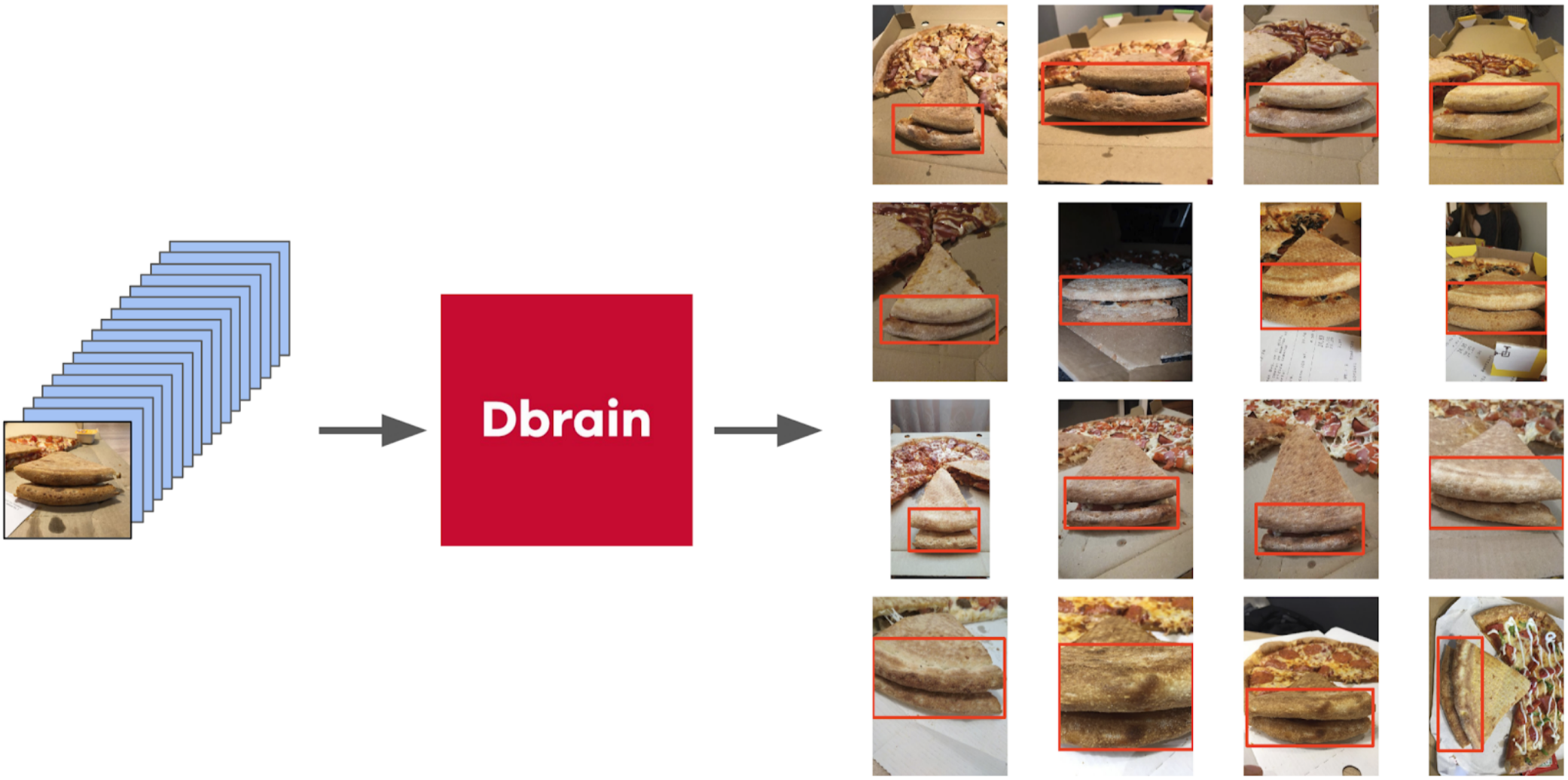
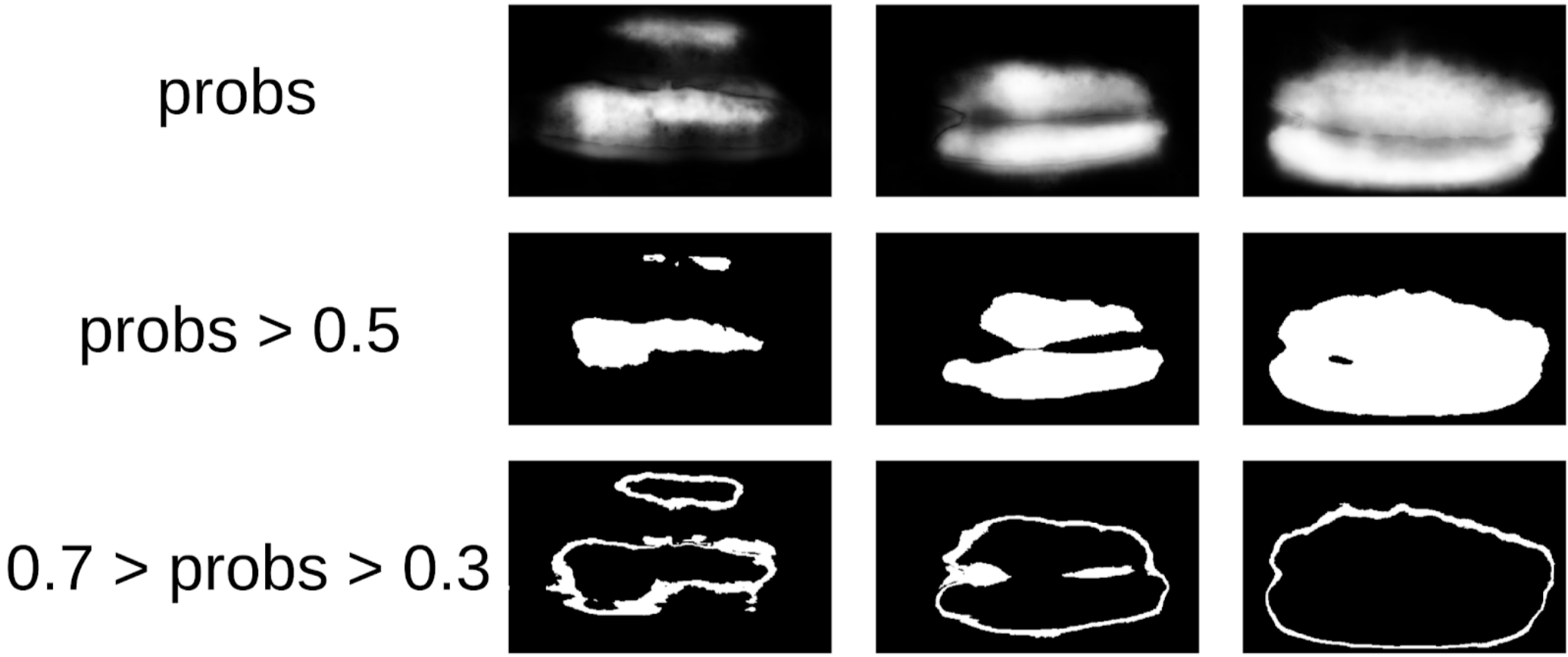
Kemudian saya menggali kode saya dari segel dan lebih formal mendekati prosedur saat ini. Setelah iterasi pertama pelatihan, juga terlihat jelas di mana model itu keliru. Dan keyakinan prediksi dapat didefinisikan sebagai berikut:
1 - (area abu-abu) / (area topeng) # akan ada formula, saya janji
Sekarang, untuk membuat iterasi berikutnya dengan menarik kotak pada topeng, sebuah ensemble kecil akan memprediksi kereta TTA. Ini dapat dianggap sebagai distilasi pengetahuan WAAAAGH sampai batas tertentu, tetapi lebih tepat untuk memanggil Pseudo Labeling.
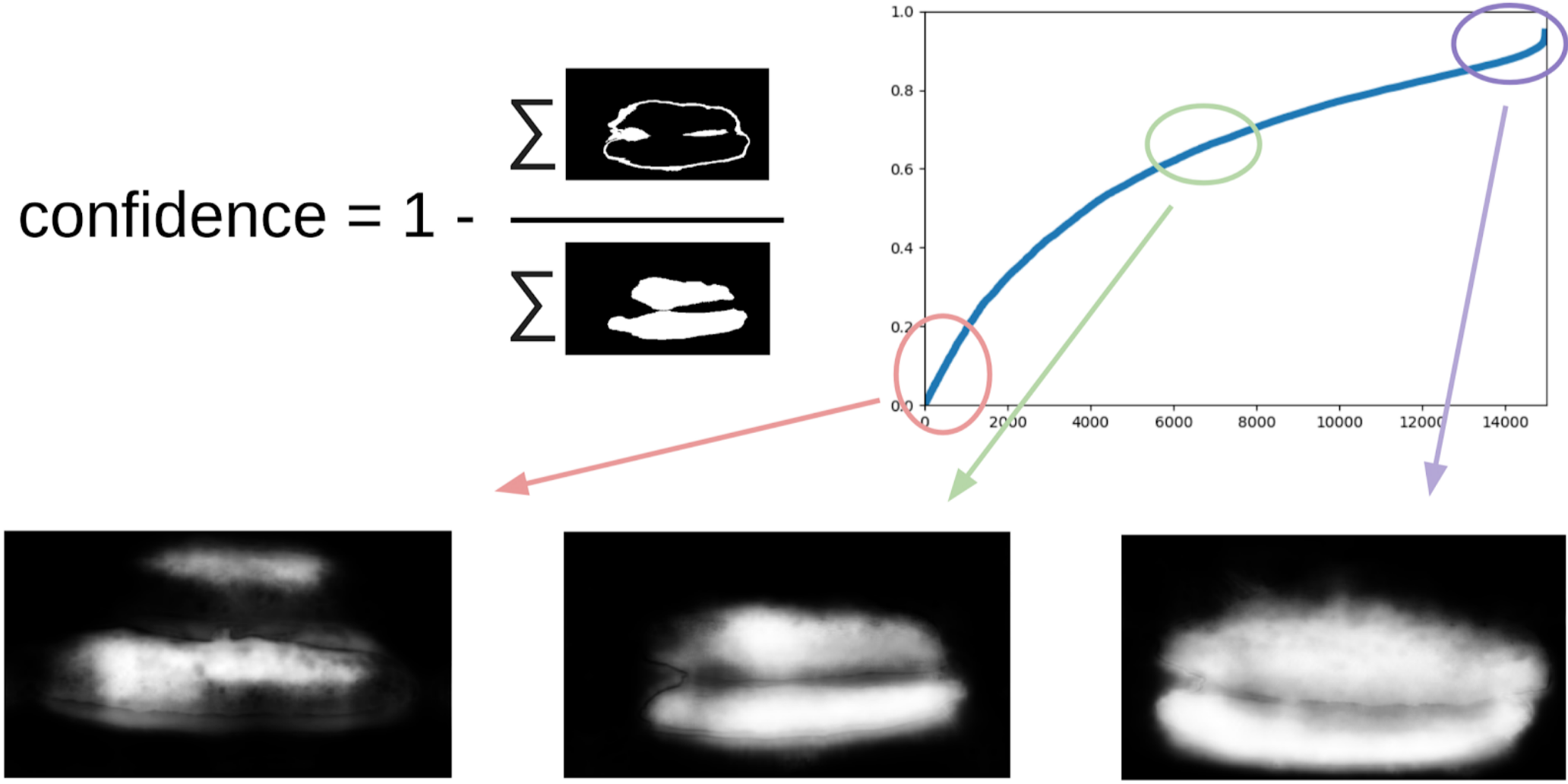
Selanjutnya, Anda perlu memilih dengan mata kepala Anda tingkat kepercayaan tertentu, mulai dari mana kami membentuk kereta baru. Dan opsional, Anda dapat menandai sampel paling kompleks yang tidak dapat ditangani oleh ansambel. Saya memutuskan bahwa itu akan berguna, dan melukis sekitar 20 gambar di suatu tempat sambil mencerna makan siang.
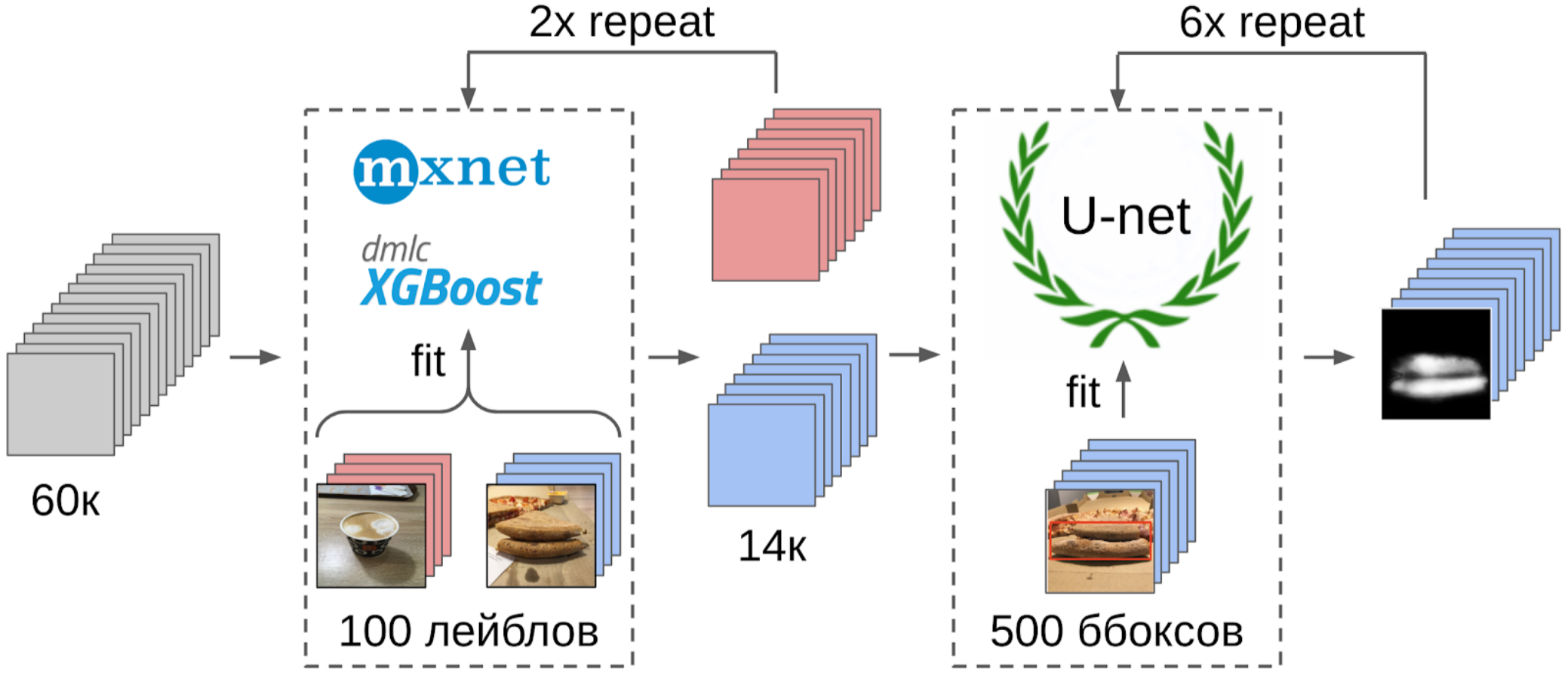
Dan sekarang bagian terakhir dari pipa: pelatihan model. Untuk menyiapkan sampel, saya mengekstraksi area masker kue. Saya juga menggembungkan topeng sedikit dengan dilatasi dan menerapkannya pada gambar untuk menghapus latar belakang, karena seharusnya tidak ada informasi tentang kualitas tes. Dan kemudian saya baru saja mengajukan beberapa model dari Kebun Binatang Imagenet. Secara total, saya bisa mengumpulkan sekitar 12k sampel percaya diri. Karena itu, saya tidak mengajarkan seluruh jaringan saraf, tetapi hanya kelompok konvolusi terakhir, sehingga model tidak akan dilatih ulang.
Mengapa Anda perlu membekukan lapisanAda dua keuntungan dari ini: 1. Jaringan belajar lebih cepat, karena Anda tidak perlu membaca gradien untuk lapisan beku. 2. Jaringan tidak dilatih ulang, karena sekarang memiliki lebih sedikit parameter gratis. Dikatakan bahwa beberapa kelompok konvolusi pertama selama pelatihan di Imagenet menghasilkan tanda-tanda yang cukup umum seperti transisi warna dan tekstur yang tajam yang sesuai untuk kelas objek yang sangat luas dalam fotografi. Ini berarti Anda tidak dapat melatih mereka selama Pembelajaran Transer.
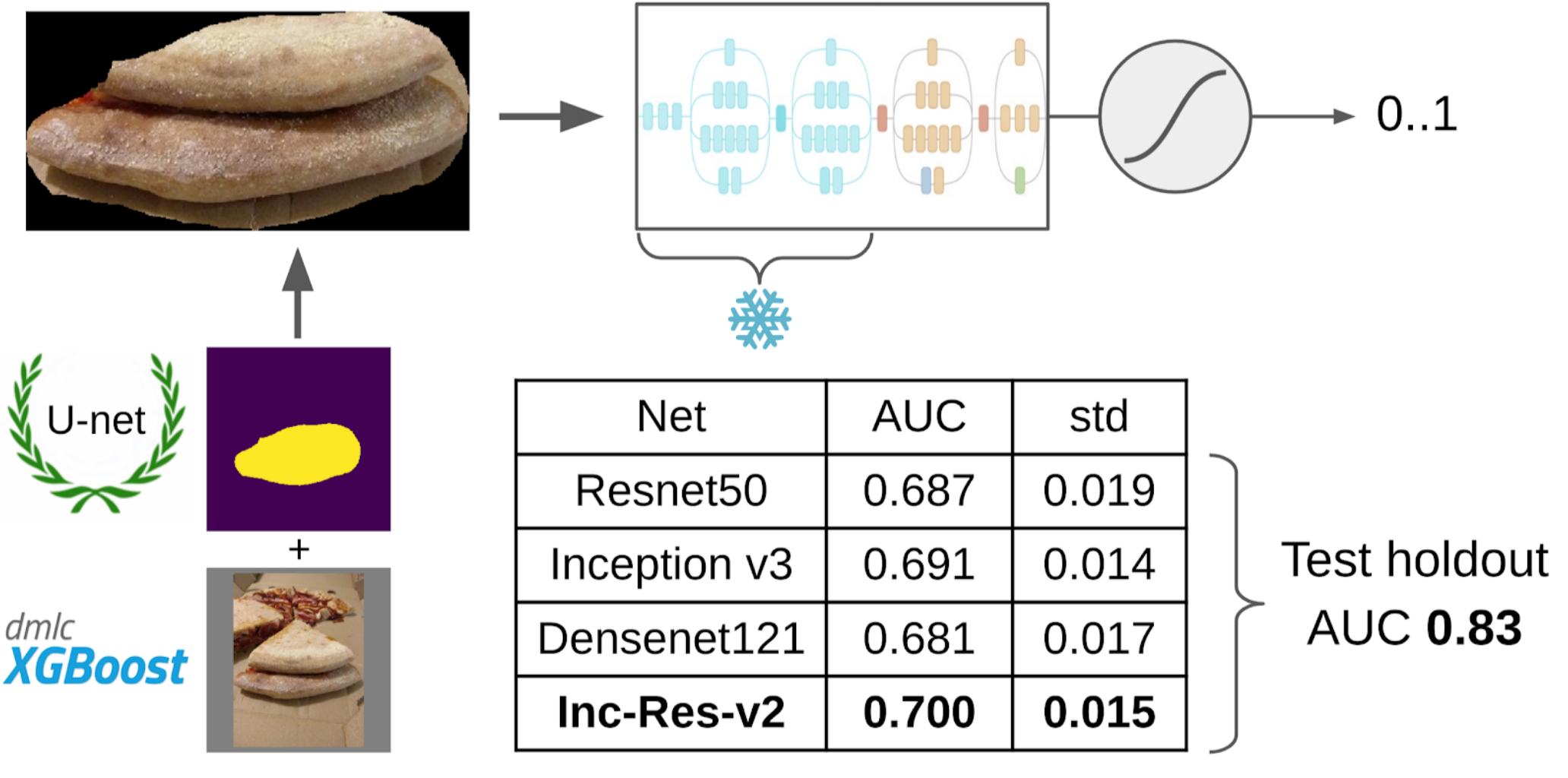
Model tunggal terbaik adalah Inception-Resnet-v2, dan baginya, ROC-AUC pada satu lipatan adalah 0,700. Jika Anda tidak memilih apa pun dan mengirimkan gambar mentah apa adanya, maka ROC-AUC adalah 0,58. Ketika saya sedang mengembangkan solusinya, kumpulan data berikutnya dimasak di pizza DODO, dan dimungkinkan untuk menguji seluruh pipa pada ketidaksepakatan yang jujur. Kami memeriksa seluruh pipa di atasnya dan mendapat ROC-AUC 0,83.
Mari kita lihat kesalahannya sekarang:
Negatif Salah Atas

Dapat dilihat di sini bahwa mereka terkait dengan kesalahan dalam menandai kue, karena ada tanda-tanda jelas dari uji manja.
False Positive

Di sini kesalahan terkait dengan fakta bahwa model pertama dipilih bukan sudut yang sangat baik, yang menurutnya sulit untuk menemukan tanda-tanda kunci kualitas pengujian.
Kesimpulan
Kadang-kadang kolega menggodaku bahwa saya memecahkan banyak masalah dengan segmentasi menggunakan Unet. Namun, menurut saya, ini adalah pendekatan yang cukup kuat dan nyaman. Ini memungkinkan Anda untuk memvisualisasikan kesalahan model dan keyakinan prediksi. Selain itu, seluruh payline terlihat sangat sederhana dan sekarang ada banyak repositori untuk kerangka kerja apa pun.