Dalam artikel ini, kita akan berbicara tentang bagaimana dan mengapa kami mengembangkan
Sistem Interaksi - mekanisme yang mentransfer informasi antara aplikasi klien dan 1C: Server perusahaan - dari menetapkan tugas hingga memikirkan arsitektur dan detail implementasi.
Sistem Interaksi (selanjutnya disebut CB) adalah sistem pesan toleransi kesalahan yang didistribusikan dengan pengiriman yang terjamin. CB dirancang sebagai layanan yang sangat sarat dengan skalabilitas tinggi, dan tersedia baik sebagai layanan online (disediakan oleh 1C) dan sebagai produk sirkulasi yang dapat digunakan pada kapasitas servernya.
CB menggunakan penyimpanan terdistribusi
Hazelcast dan mesin pencari
Elasticsearch . Kami juga akan berbicara tentang Java dan bagaimana kami skala PostgreSQL secara horizontal.

Pernyataan masalah
Untuk menjelaskan mengapa kami membuat Sistem Interaksi, saya akan memberi tahu Anda sedikit tentang bagaimana pengembangan aplikasi bisnis dalam 1C bekerja.
Untuk mulai dengan, sedikit tentang kami untuk mereka yang belum tahu apa yang kami lakukan :) Kami menciptakan 1C: platform teknologi perusahaan. Platform ini mencakup alat untuk mengembangkan aplikasi bisnis, serta runtime, yang memungkinkan aplikasi bisnis untuk bekerja di lingkungan lintas platform.
Paradigma pengembangan client-server
Aplikasi bisnis yang dibuat di "1C: Enterprise" beroperasi dalam arsitektur
klien-server tiga tingkat "DBMS - server aplikasi - klien". Kode aplikasi yang ditulis dalam
bahasa tertanam 1C dapat dijalankan di server aplikasi atau di klien. Semua bekerja dengan objek aplikasi (direktori, dokumen, dll.), Serta membaca dan menulis ke database, dilakukan hanya di server. Fungsionalitas bentuk dan antarmuka perintah juga diterapkan di server. Klien menerima, membuka dan menampilkan formulir, "berkomunikasi" dengan pengguna (peringatan, pertanyaan ...), perhitungan kecil dalam bentuk yang memerlukan reaksi cepat (misalnya, mengalikan harga dengan jumlah), bekerja dengan file lokal, bekerja dengan peralatan.
Dalam kode aplikasi, tajuk prosedur dan fungsi harus secara eksplisit menunjukkan di mana kode akan dieksekusi - menggunakan arahan & Di Klien / & Di Server (& AtClient / & AtServer dalam versi bahasa Inggris). Pengembang di 1C akan mengoreksi saya sekarang, mengatakan bahwa sebenarnya ada
lebih banyak arahan, tetapi bagi kami ini tidak penting sekarang.
Kode server dapat dipanggil dari kode klien, tetapi kode klien tidak dapat dipanggil dari kode server. Ini adalah batasan mendasar yang kami buat karena sejumlah alasan. Secara khusus, karena kode server harus ditulis sehingga dieksekusi secara merata, di mana pun namanya - dari klien atau dari server. Dan dalam hal memanggil kode server dari kode server lain, klien tidak ada. Dan karena selama eksekusi kode server, klien yang menyebabkannya bisa menutup, keluar dari aplikasi, dan server tidak akan memanggil siapa pun.
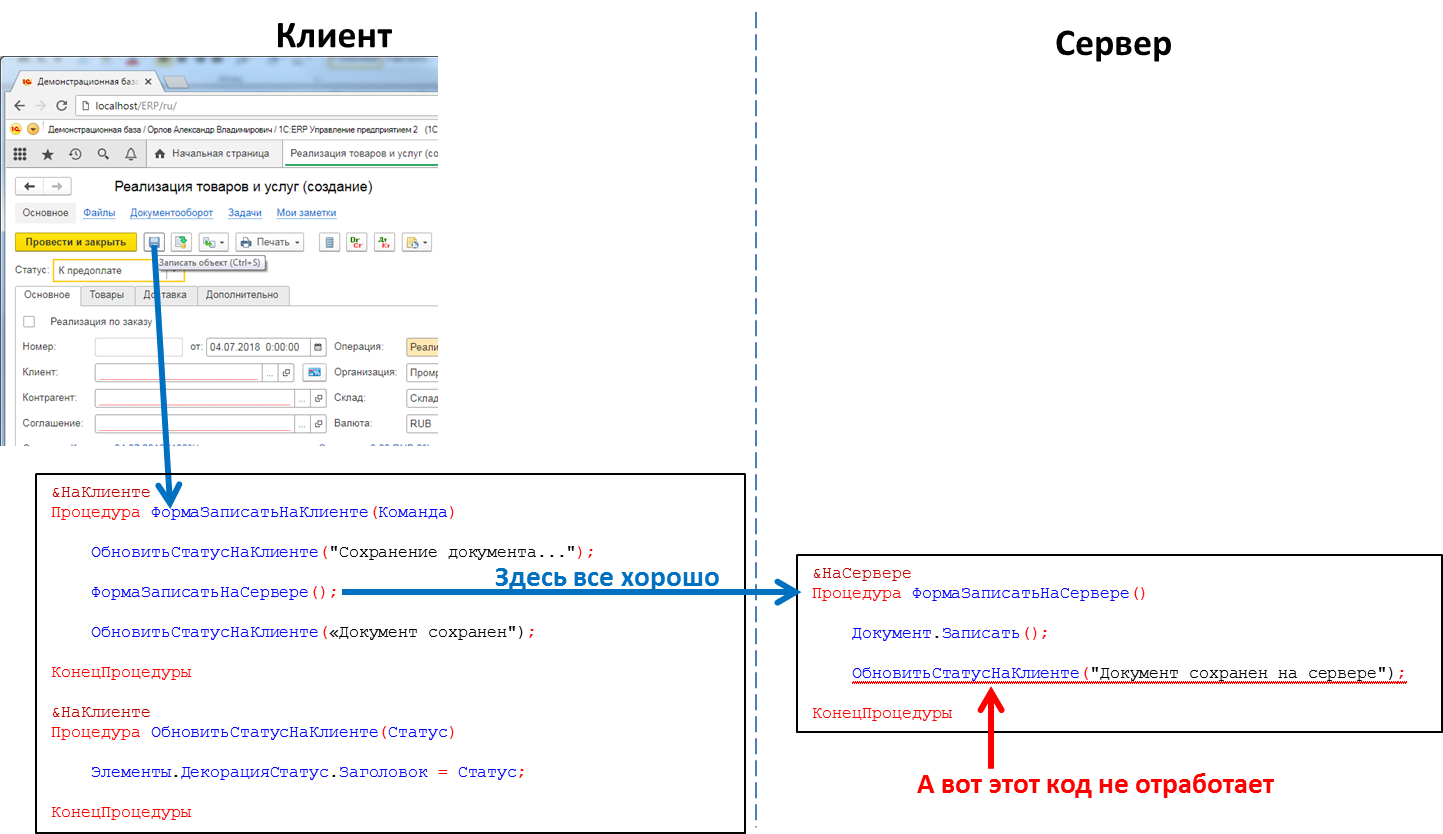 Kode yang memproses klik tombol: panggilan prosedur server dari klien akan berfungsi, panggilan prosedur klien dari server tidak akan
Kode yang memproses klik tombol: panggilan prosedur server dari klien akan berfungsi, panggilan prosedur klien dari server tidak akanIni berarti bahwa jika kami ingin mentransfer beberapa pesan ke aplikasi klien dari server, misalnya, bahwa pembentukan laporan "lama bermain" telah berakhir dan laporan dapat dilihat, kami tidak memiliki metode seperti itu. Kita harus pergi ke trik, misalnya, dari kode klien untuk polling server secara berkala. Tetapi pendekatan ini memuat sistem dengan panggilan yang tidak perlu, dan memang tidak terlihat sangat elegan.
Dan ada juga kebutuhan, misalnya, ketika panggilan telepon
SIP tiba, beri tahu aplikasi klien tentang hal itu sehingga dengan jumlah pemanggil ia menemukannya di basis data pihak lawan dan memperlihatkan informasi pengguna tentang pihak lawan panggilan. Atau, misalnya, setelah menerima pesanan di gudang, beri tahu aplikasi klien tentang hal ini. Secara umum, ada banyak kasus di mana mekanisme seperti itu akan berguna.
Sebenarnya pementasan
Buat mesin olahpesan. Cepat, andal, dengan pengiriman terjamin, dengan kemampuan mencari pesan secara fleksibel. Berdasarkan mekanisme, mengimplementasikan messenger (pesan, panggilan video) yang berfungsi di dalam aplikasi 1C.
Desain sistem yang dapat diskalakan secara horizontal. Peningkatan beban harus ditutup dengan meningkatkan jumlah node.
Implementasi
Kami memutuskan untuk tidak menanamkan bagian server SV langsung ke platform 1C: Enterprise, tetapi untuk mengimplementasikannya sebagai produk terpisah, API yang dapat dipanggil dari kode aplikasi 1C. Ini dilakukan karena sejumlah alasan, yang utamanya - saya ingin memungkinkan untuk bertukar pesan antara aplikasi 1C yang berbeda (misalnya, antara Kantor Perdagangan dan Akuntansi). Aplikasi 1C yang berbeda dapat berjalan pada versi 1C yang berbeda: platform Enterprise, berada di server yang berbeda, dll. Dalam kondisi seperti itu, penerapan CB sebagai produk terpisah yang terletak "di sisi" instalasi 1C adalah solusi optimal.
Jadi, kami memutuskan untuk menjadikan CB sebagai produk terpisah. Untuk perusahaan kecil, kami sarankan untuk menggunakan server CB yang kami instal di cloud kami (wss: //1cdialog.com) untuk menghindari overhead yang terkait dengan menginstal dan mengkonfigurasi server secara lokal. Pelanggan besar, bagaimanapun, mungkin merasa pantas untuk menginstal server CB mereka sendiri di fasilitas mereka. Kami menggunakan pendekatan serupa di produk SaaS berbasis cloud
1cFresh kami - dirilis sebagai produk sirkulasi untuk pemasangan oleh pelanggan dan juga digunakan di cloud kami
https://1cfresh.com/ .
Aplikasi
Untuk load balancing dan toleransi kesalahan, kami tidak akan menerapkan satu aplikasi Java, tetapi beberapa, kami akan menempatkan load balancer di depannya. Jika Anda perlu mentransfer pesan dari node ke node - gunakan terbitkan / berlangganan di Hazelcast.
Komunikasi klien dengan server - oleh websocket. Ini sangat cocok untuk sistem waktu nyata.
Tembolok yang didistribusikan
Pilih antara Redis, Hazelcast dan Ehcache. Di halaman 2015. Redis baru saja meluncurkan cluster baru (terlalu baru, menakutkan), ada Sentinel dengan banyak pembatasan. Ehcache tidak tahu bagaimana cara merakit menjadi sebuah cluster (fungsi ini muncul kemudian). Kami memutuskan untuk mencoba dengan Hazelcast 3.4.
Hazelcast akan pergi ke cluster di luar kotak. Dalam mode single-node, itu tidak terlalu berguna dan hanya bisa muat sebagai cache - tidak tahu cara membuang data ke disk, kehilangan satu node - kehilangan data. Kami menyebarkan beberapa Hazelcasts di antaranya kami mencadangkan data penting. Cache bukan cadangan - sayang sekali.
Bagi kami, Hazelcast adalah:
- Repositori sesi pengguna. Setiap kali, pergi ke database untuk suatu sesi adalah waktu yang lama, jadi kami menempatkan semua sesi di Hazelcast.
- Cache. Mencari profil pengguna - periksa di cache. Menulis pesan baru - taruh di cache.
- Topik untuk mengkomunikasikan instance aplikasi. Noda menghasilkan suatu acara dan memasukkannya ke dalam topik Hazelcast. Node aplikasi lain yang berlangganan topik ini menerima dan memproses acara tersebut.
- Kunci kluster. Misalnya, kami membuat diskusi tentang kunci unik (diskusi-tunggal dalam kerangka kerja 1C basis data):
conversationKeyChecker.check(""); doInClusterLock("", () -> { conversationKeyChecker.check(""); createChannel(""); });
Diperiksa tidak ada saluran. Mereka mengambil kunci, memeriksa lagi, menciptakan. Jika Anda tidak memeriksa kunci setelah mengambilnya, maka ada kemungkinan bahwa utas lain pada saat itu juga memeriksa dan sekarang akan mencoba membuat diskusi yang sama - tetapi sudah ada. Tidak mungkin untuk melakukan penguncian melalui java Lock yang disinkronkan atau biasa. Melalui basis - perlahan, dan basis sangat disayangkan, melalui Hazelcast - apa yang Anda butuhkan.
Memilih DBMS
Kami memiliki pengalaman luas dan sukses bekerja dengan PostgreSQL dan berkolaborasi dengan pengembang DBMS ini.
PostgreSQL tidak mudah dengan sebuah cluster - ia memiliki
XL ,
XC ,
Citus , tetapi, secara umum, ini bukan noSQL, yang keluar dari kotak. NoSQL tidak dianggap sebagai repositori utama, cukup kami mengambil Hazelcast, yang belum pernah kami kerjakan sebelumnya.
Karena Anda perlu mengukur basis data relasional, itu artinya
sharding . Seperti yang Anda ketahui, saat sharding, kami membagi basis data menjadi beberapa bagian sehingga masing-masing dapat dipindahkan ke server yang terpisah.
Versi pertama dari sharding kami menyiratkan kemampuan untuk mendistribusikan masing-masing tabel aplikasi kami ke server yang berbeda dalam proporsi yang berbeda. Ada banyak pesan di server A - tolong, mari kita transfer bagian dari tabel ini ke server B. Solusi semacam itu hanya berteriak tentang optimasi prematur, jadi kami memutuskan untuk membatasi diri pada pendekatan multi-tenant.
Anda dapat
membaca tentang multi-tenant, misalnya, di situs web
Citus Data .
Dalam SV ada konsep aplikasi dan pelanggan. Aplikasi adalah instalasi khusus aplikasi bisnis, seperti ERP atau Akuntansi, dengan penggunanya dan data bisnis. Pelanggan adalah organisasi atau individu yang atas nama aplikasi terdaftar di server CB. Pelanggan dapat mendaftarkan beberapa aplikasi, dan aplikasi ini dapat saling bertukar pesan. Pelanggan juga menjadi penyewa dalam sistem kami. Pesan dari beberapa pelanggan bisa dalam satu basis fisik; jika kita melihat bahwa beberapa pelanggan mulai menghasilkan banyak lalu lintas - kita membawanya ke basis fisik yang terpisah (atau bahkan server database terpisah).
Kami memiliki basis data utama tempat tabel perutean dengan informasi tentang lokasi semua basis data pelanggan disimpan.
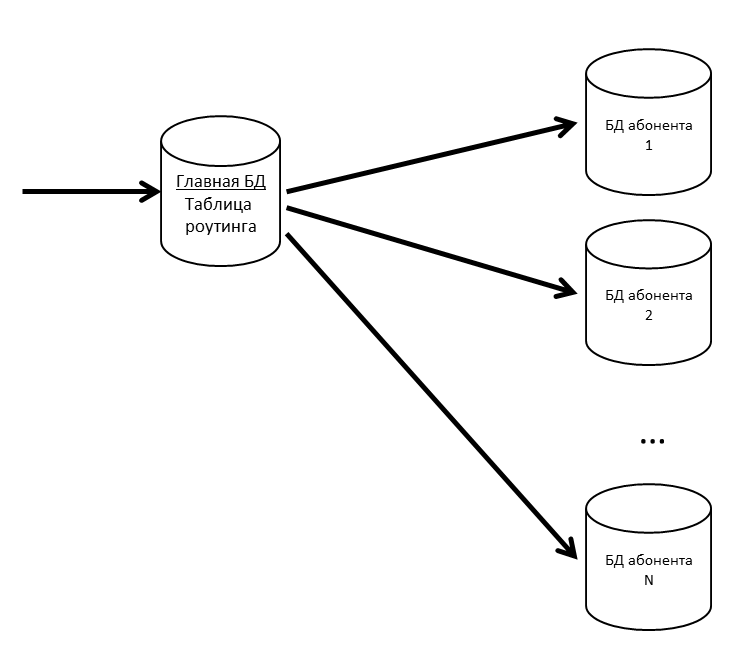
Agar basis data utama bukan hambatan, kami menyimpan tabel perutean (dan data lainnya yang sering diminta) di cache.
Jika basis data pelanggan mulai melambat, kami akan memotongnya menjadi partisi di dalamnya. Pada proyek lain, kami menggunakan pg_pathman untuk mempartisi tabel besar.
Karena kehilangan pesan pengguna adalah buruk, kami mendukung basis data kami dengan replika. Kombinasi replika sinkron dan asinkron memungkinkan Anda aman jika kehilangan basis data utama. Kehilangan pesan hanya akan terjadi jika terjadi kegagalan simultan dari database utama dan replika sinkronnya.
Jika replika sinkron hilang, replika asinkron menjadi sinkron.
Jika database utama hilang, replika sinkron menjadi basis data utama, replika asinkron menjadi replika sinkron.
Elasticsearch untuk pencarian
Karena, antara lain, CB juga merupakan pembawa pesan, di sini Anda memerlukan pencarian yang cepat, nyaman dan fleksibel, dengan mempertimbangkan morfologi, dengan pertandingan yang tidak akurat. Kami memutuskan untuk tidak menemukan kembali roda dan menggunakan mesin pencari Elasticsearch gratis, berdasarkan perpustakaan
Lucene . Kami juga menggunakan Elasticsearch dalam sebuah cluster (master - data - data) untuk menghilangkan masalah jika terjadi kegagalan node aplikasi.
Di github, kami menemukan
plugin morfologi Rusia untuk Elasticsearch dan menggunakannya. Dalam indeks Elasticsearch, kami menyimpan akar kata-kata (yang didefinisikan oleh plugin) dan N-gram. Saat pengguna memasukkan teks untuk mencari, kami mencari teks yang diketik di antara N-gram. Saat disimpan dalam indeks, kata "teks" akan dibagi menjadi N-gram berikut:
[itu, tech, tex, teks, teks, ek, ex, ekst, eksts, ks, kst, kst, st, st, you,],
Dan juga akar kata "teks" akan disimpan. Pendekatan ini memungkinkan Anda untuk mencari di awal, di tengah, dan di akhir kata.
Gambaran keseluruhan
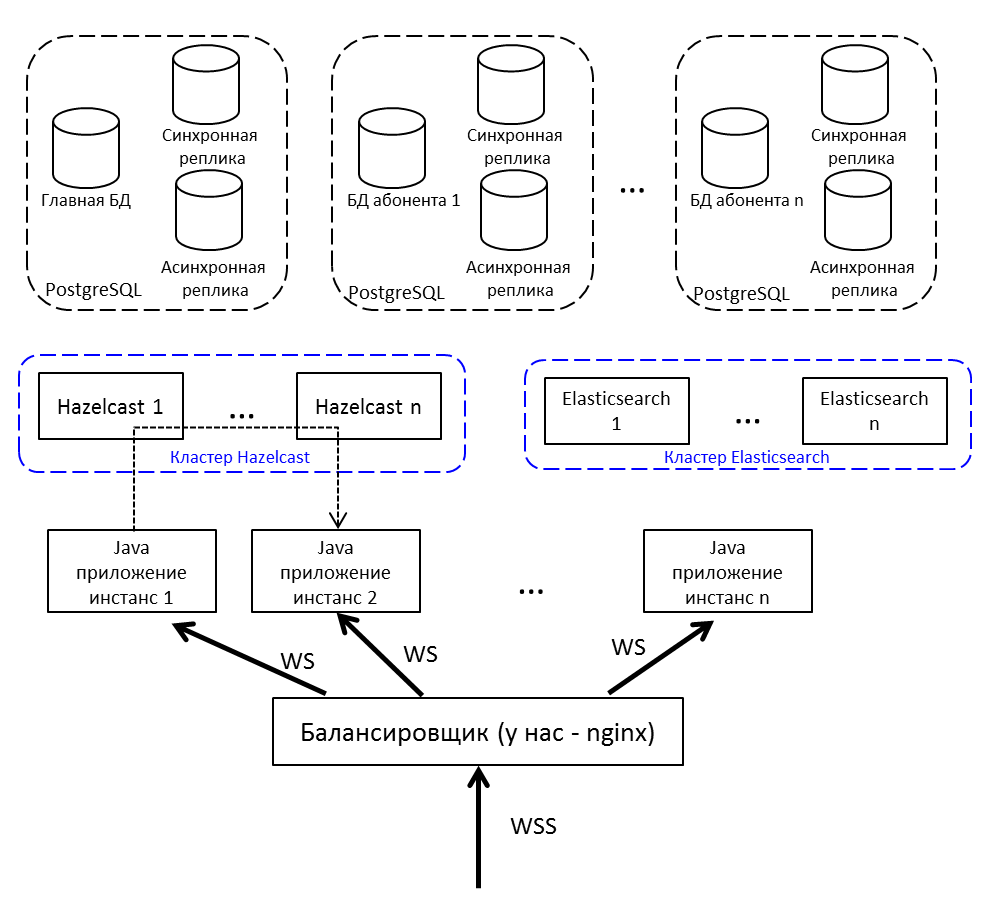
Mengulang gambar dari awal artikel, tetapi dengan penjelasan:
- Penyeimbang internet; kami punya nginx, bisa apa saja.
- Contoh aplikasi Java berkomunikasi satu sama lain melalui Hazelcast.
- Untuk bekerja dengan soket web kami menggunakan Netty .
- Aplikasi Java yang ditulis dalam Java 8, terdiri dari bundel OSGi . Rencana - migrasi ke Java 10 dan transisi ke modul.
Pengembangan dan pengujian
Dalam proses pengembangan dan pengujian CB, kami menemukan sejumlah fitur menarik dari produk yang digunakan oleh kami.
Muat pengujian dan kebocoran memori
Rilis setiap rilis CB adalah stress testing. Itu berhasil ketika:
- Tes bekerja selama beberapa hari dan tidak ada penolakan layanan
- Waktu respons untuk operasi utama tidak melebihi ambang batas nyaman
- Penurunan kinerja dibandingkan dengan versi sebelumnya tidak lebih dari 10%
Kami mengisi basis uji dengan data - untuk ini kami mendapatkan informasi tentang pelanggan paling aktif dari server produksi, kalikan jumlahnya dengan 5 (jumlah pesan, diskusi, pengguna) dan kami menguji.
Kami melakukan pengujian beban sistem interaksi dalam tiga konfigurasi:
- Tes stres
- Koneksi saja
- Registrasi Pelanggan
Selama stress test, kami memulai beberapa ratus utas, dan mereka tanpa henti memuat sistem: menulis pesan, membuat diskusi, mendapatkan daftar pesan. Kami mensimulasikan tindakan pengguna biasa (dapatkan daftar pesan saya yang belum dibaca, menulis kepada seseorang) dan solusi perangkat lunak (mentransfer paket dengan konfigurasi yang berbeda, memproses pemberitahuan).
Sebagai contoh, ini adalah bagian dari tes stres:
- Pengguna masuk.
- Minta Diskusi Belum Dibaca
- Kesempatan 50% untuk membaca pesan
- Dengan 50% probabilitas menulis pesan
- Pengguna selanjutnya:
- Dengan 20% kemungkinan menciptakan diskusi baru.
- Secara acak memilih salah satu diskusinya
- Masuk ke dalam
- Minta pesan, profil pengguna
- Membuat lima pesan yang ditujukan kepada pengguna acak dari diskusi ini.
- Keluar dari diskusi
- Diulang 20 kali
- Logout, kembali ke awal skrip
- Bot obrolan memasuki sistem (mengemulasikan pertukaran pesan dari kode solusi yang diterapkan)
- Dengan kemungkinan 50% menciptakan saluran baru untuk pertukaran data (diskusi khusus)
- Dengan probabilitas 50% menulis pesan ke salah satu saluran yang ada
Skenario "Hanya Koneksi" muncul karena suatu alasan. Ada situasi: pengguna menghubungkan sistem, tetapi belum terlibat. Setiap pengguna di pagi hari pukul 09:00 menyalakan komputer, membuat koneksi ke server dan diam. Orang-orang ini berbahaya, ada banyak dari mereka - dari paket mereka hanya memiliki PING / PONG, tetapi mereka menjaga koneksi ke server (mereka tidak dapat menyimpannya - tetapi tiba-tiba pesan baru). Tes mereproduksi situasi ketika dalam setengah jam sejumlah besar pengguna tersebut mencoba masuk ke sistem. Ini terlihat seperti tes stres, tetapi berfokus tepat pada pintu masuk pertama ini - sehingga tidak ada kegagalan (seseorang tidak menggunakan sistem, tetapi sudah jatuh - sulit untuk menemukan sesuatu yang lebih buruk).
Skenario pendaftaran pelanggan berasal dari peluncuran pertama. Kami melakukan tes stres dan yakin bahwa sistem tidak memperlambat korespondensi. Tetapi pengguna pergi dan pendaftaran mulai jatuh dalam batas waktu. Saat mendaftar, kami menggunakan
/ dev / random , yang terkait dengan entropi sistem. Server tidak berhasil mengakumulasi cukup entropi dan membeku selama puluhan detik ketika meminta SecureRandom baru. Ada banyak jalan keluar dari situasi ini, misalnya: beralih ke yang kurang aman / dev / urandom, letakkan papan khusus yang menghasilkan entropi, buat angka acak terlebih dahulu dan simpan di pool. Kami untuk sementara menutup masalah dengan kumpulan, tetapi sejak itu kami telah menjalankan tes terpisah untuk mendaftarkan pelanggan baru.
Sebagai generator beban kami menggunakan
JMeter . Dia tidak tahu cara bekerja dengan soket web, diperlukan plug-in. Yang pertama dalam hasil pencarian untuk "jmeter websocket" adalah
artikel dengan BlazeMeter , yang merekomendasikan
plugin dari Maciej Zaleski .
Dengan dia kami memutuskan untuk memulai.
Hampir segera setelah dimulainya pengujian serius, kami menemukan bahwa kebocoran memori dimulai pada JMeter.
Plugin ini adalah cerita besar yang terpisah, dengan 176 bintang memiliki 132 garpu di github. Penulis sendiri tidak berkomitmen untuk itu sejak 2015 (kami mengambilnya di 2015, maka ini tidak menimbulkan kecurigaan), beberapa masalah github tentang kebocoran memori, 7 permintaan tarik tertutup.
Jika Anda memutuskan untuk melakukan pengujian beban dengan plugin ini, perhatikan diskusi berikut:
- Dalam lingkungan multi-utas, LinkedList biasa digunakan, sebagai hasilnya, mereka menerima NPE dalam runtime. Itu diselesaikan baik dengan beralih ke ConcurrentLinkedDeque, atau dengan blok yang disinkronkan. Mereka memilih opsi pertama untuk diri mereka sendiri ( https://github.com/maciejzaleski/JMeter-WebSocketSampler/issues/43 ).
- Kebocoran memori, putuskan sambungan tidak menghapus informasi koneksi ( https://github.com/maciejzaleski/JMeter-WebSocketSampler/issues/44 ).
- Dalam mode streaming (ketika soket web tidak menutup pada akhir sampel, tetapi digunakan lebih lanjut dalam rencana), pola Respons ( https://github.com/maciejzaleski/JMeter-WebSocketSampler/issues/19 ) tidak berfungsi.
Ini adalah salah satu yang ada di github. Apa yang telah kami lakukan:
- Mereka mengambil garpu Elyran Kogan (@elyrank) - masalah 1 dan 3 diperbaiki di dalamnya
- Memecahkan masalah 2
- Dermaga diperbarui dari 9.2.14 hingga 9.3.12
- SimpleDateFormat yang Dibungkus di ThreadLocal; SimpleDateFormat bukan thread aman, yang menyebabkan runtime NPE
- Dieliminasi satu lagi kebocoran memori (koneksi ditutup dengan tidak benar ketika terputus)
Namun itu mengalir!
Ingatan mulai berakhir bukan dalam sehari, melainkan dua. Sama sekali tidak ada waktu lagi, mereka memutuskan untuk menjalankan lebih sedikit utas, tetapi pada empat agen. Itu seharusnya sudah cukup untuk setidaknya satu minggu.
Dua hari telah berlalu ...
Sekarang ingatan mulai habis di Hazelcast. Terbukti dalam log bahwa setelah beberapa hari pengujian, Hazelcast mulai mengeluh tentang kurangnya memori, dan setelah beberapa saat, cluster berantakan, dan node terus mati secara individual. Kami menghubungkan JVisualVM ke hazelcast dan melihat "naiknya gergaji" - ia secara teratur memanggil GC, tetapi tidak dapat menghapus ingatannya.
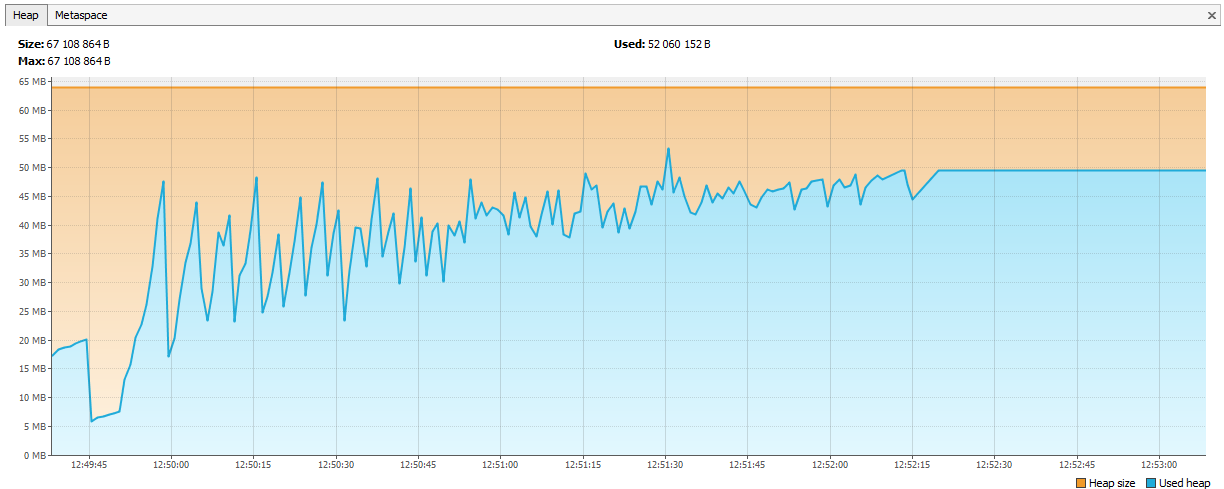
Ternyata di hazelcast 3.4, saat menghapus peta / multiMap (map.destroy ()), memori tidak sepenuhnya dibebaskan:
github.com/hazelcast/hazelcast/issues/6317github.com/hazelcast/hazelcast/issues/4888Sekarang bug diperbaiki di 3.5, tapi kemudian itu masalah. Kami membuat multi-peta baru dengan nama dinamis dan dihapus sesuai dengan logika kami. Kode tersebut terlihat seperti ini:
public void join(Authentication auth, String sub) { MultiMap<UUID, Authentication> sessions = instance.getMultiMap(sub); sessions.put(auth.getUserId(), auth); } public void leave(Authentication auth, String sub) { MultiMap<UUID, Authentication> sessions = instance.getMultiMap(sub); sessions.remove(auth.getUserId(), auth); if (sessions.size() == 0) { sessions.destroy(); } }
Hubungi:
service.join(auth1, "____UUID1"); service.join(auth2, "____UUID1");
multiMap dibuat untuk setiap langganan dan dihapus ketika tidak diperlukan. Kami memutuskan bahwa kami akan memulai Peta <String, Set>, kuncinya akan menjadi nama langganan, dan nilainya akan menjadi pengidentifikasi sesi (dari mana Anda kemudian bisa mendapatkan ID pengguna, jika perlu).
public void join(Authentication auth, String sub) { addValueToMap(sub, auth.getSessionId()); } public void leave(Authentication auth, String sub) { removeValueFromMap(sub, auth.getSessionId()); }
Grafik diluruskan.
Apa lagi yang kami pelajari tentang stress testing
- JSR223 perlu ditulis dalam groovy dan cache kompilasi yang diaktifkan - ini jauh lebih cepat. Tautan
- Grafik Jmeter-Plugins lebih mudah dipahami daripada standar. Tautan
Tentang pengalaman kami dengan Hazelcast
Hazelcast adalah produk baru bagi kami, kami mulai bekerja dengannya dari versi 3.4.1, sekarang server produksi kami memiliki versi 3.9.2 (pada saat penulisan, Hazelcast versi terbaru adalah 3.10).
Pembuatan ID
Kami mulai dengan pengidentifikasi integer. Mari kita bayangkan bahwa kita membutuhkan Long lagi untuk entitas baru. Urutan tidak sesuai dalam database, tabel berpartisipasi dalam sharding - ternyata ada pesan ID = 1 di DB1 dan ID pesan = 1 di DB2, Anda tidak dapat memasukkan ID seperti itu di Elasticsearch, baik di Hazelcast, tetapi yang terburuk adalah jika Anda ingin mengurangi data dari dua basis data menjadi satu (misalnya, memutuskan bahwa satu basis data cukup untuk pelanggan ini). Anda dapat membuat beberapa AtomicLong di Hazelcast dan menyimpan penghitung di sana, maka kinerja mendapatkan ID baru adalah incrementAndGet ditambah waktu untuk permintaan di Hazelcast. Tetapi ada sesuatu yang lebih optimal tentang Hazelcast - FlakeIdGenerator. Setiap klien diberi rentang ID saat kontak, misalnya, yang pertama dari 1 hingga 10.000, yang kedua dari 10.001 hingga 20.000, dan seterusnya. Sekarang klien dapat mengeluarkan pengidentifikasi baru secara mandiri hingga rentang yang dikeluarkan untuk itu berakhir. Ini bekerja dengan cepat, tetapi ketika Anda me-restart aplikasi (dan klien Hazelcast), urutan baru dimulai - maka ada celah, dll. Selain itu, pengembang tidak begitu jelas mengapa ID adalah integer, tetapi mereka berjalan sangat berbeda. Kami semua menimbang dan beralih ke UUID.
Omong-omong, bagi mereka yang ingin menjadi seperti Twitter, ada perpustakaan Snowcast - ini adalah implementasi Snowflake di atas Hazelcast. Anda bisa melihatnya di sini:
github.com/noctarius/snowcastgithub.com/twitter/snowflakeTapi kami belum meraih tangannya.
TransactionalMap.replace
Kejutan lain: TransactionalMap.replace tidak berfungsi. Ini tesnya:
@Test public void replaceInMap_putsAndGetsInsideTransaction() { hazelcastInstance.executeTransaction(context -> { HazelcastTransactionContextHolder.setContext(context); try { context.getMap("map").put("key", "oldValue"); context.getMap("map").replace("key", "oldValue", "newValue"); String value = (String) context.getMap("map").get("key"); assertEquals("newValue", value); return null; } finally { HazelcastTransactionContextHolder.clearContext(); } }); } Expected : newValue Actual : oldValue
Saya harus menulis pengganti saya menggunakan getForUpdate:
protected <K,V> boolean replaceInMap(String mapName, K key, V oldValue, V newValue) { TransactionalTaskContext context = HazelcastTransactionContextHolder.getContext(); if (context != null) { log.trace("[CACHE] Replacing value in a transactional map"); TransactionalMap<K, V> map = context.getMap(mapName); V value = map.getForUpdate(key); if (oldValue.equals(value)) { map.put(key, newValue); return true; } return false; } log.trace("[CACHE] Replacing value in a not transactional map"); IMap<K, V> map = hazelcastInstance.getMap(mapName); return map.replace(key, oldValue, newValue); }
Uji tidak hanya struktur data reguler, tetapi juga versi transaksionalnya. Itu terjadi bahwa IMap bekerja, tetapi TransactionalMap hilang.
Pasang JAR baru tanpa downtime
Pertama, kami memutuskan untuk merekam objek kelas kami di Hazelcast. Sebagai contoh, kami memiliki Aplikasi kelas, kami ingin menyimpan dan membacanya. Simpan:
IMap<UUID, Application> map = hazelcastInstance.getMap("application"); map.set(id, application);
Kami membaca:
IMap<UUID, Application> map = hazelcastInstance.getMap("application"); return map.get(id);
Semuanya berfungsi. Kemudian kami memutuskan untuk membuat indeks di Hazelcast untuk mencarinya:
map.addIndex("subscriberId", false);
Dan ketika menulis entitas baru, mereka mulai menerima ClassNotFoundException. Hazelcast mencoba menambah indeks, tetapi tidak tahu apa-apa tentang kelas kami dan ingin memiliki JAR dengan kelas ini. Kami melakukannya, semuanya berfungsi, tetapi muncul masalah baru: bagaimana cara memperbarui JAR tanpa menghentikan cluster sepenuhnya? Hazelcast tidak mengambil JAR baru selama peningkatan pod-wise. Pada saat ini, kami memutuskan bahwa kami dapat hidup dengan baik tanpa mencari berdasarkan indeks. Lagi pula, jika Anda menggunakan Hazelcast sebagai penyimpanan nilai kunci, apakah semuanya akan berfungsi? Tidak juga. Di sini sekali lagi, perilaku IMAP dan TransactionalMap berbeda. Di mana IMap tidak masalah, TransactionalMap melempar kesalahan.
IMap Kami menulis 5.000 objek, membacanya. Segalanya diharapkan.
@Test void get5000() { IMap<UUID, Application> map = hazelcastInstance.getMap("application"); UUID subscriberId = UUID.randomUUID(); for (int i = 0; i < 5000; i++) { UUID id = UUID.randomUUID(); String title = RandomStringUtils.random(5); Application application = new Application(id, title, subscriberId); map.set(id, application); Application retrieved = map.get(id); assertEquals(id, retrieved.getId()); } }
Dan itu tidak berfungsi dalam transaksi, kami mendapatkan ClassNotFoundException:
@Test void get_transaction() { IMap<UUID, Application> map = hazelcastInstance.getMap("application_t"); UUID subscriberId = UUID.randomUUID(); UUID id = UUID.randomUUID(); Application application = new Application(id, "qwer", subscriberId); map.set(id, application); Application retrievedOutside = map.get(id); assertEquals(id, retrievedOutside.getId()); hazelcastInstance.executeTransaction(context -> { HazelcastTransactionContextHolder.setContext(context); try { TransactionalMap<UUID, Application> transactionalMap = context.getMap("application_t"); Application retrievedInside = transactionalMap.get(id); assertEquals(id, retrievedInside.getId()); return null; } finally { HazelcastTransactionContextHolder.clearContext(); } }); }
Di 3.8, mekanisme Penerapan Kelas Pengguna muncul. Anda dapat menetapkan satu simpul utama dan memperbarui file JAR di atasnya.
Sekarang kami telah sepenuhnya mengubah pendekatan: kami membuat serial dalam JSON dan menyimpannya di Hazelcast. Hazelcast tidak perlu mengetahui struktur kelas kami, tetapi kami dapat memperbarui tanpa downtime. Versi objek domain dikendalikan oleh aplikasi. Versi aplikasi yang berbeda dapat diluncurkan secara bersamaan, dan ada kemungkinan bahwa aplikasi baru menulis objek dengan bidang baru, tetapi yang lama tidak tahu tentang bidang ini. Dan pada saat yang sama, aplikasi baru membacakan objek yang direkam oleh aplikasi lama, di mana tidak ada bidang baru. Kami menangani situasi seperti itu di dalam aplikasi, tetapi untuk kesederhanaan kami tidak mengubah atau menghapus bidang, kami hanya memperluas kelas dengan menambahkan bidang baru.
Bagaimana kami memberikan kinerja tinggi
Empat perjalanan ke Hazelcast - bagus, dua ke database - buruk
Pergi ke cache untuk data selalu lebih baik daripada dalam database, tetapi Anda tidak ingin menyimpan catatan yang tidak diklaim. Keputusan tentang apa yang akan di-cache, kami menunda ke tahap terakhir pengembangan. Ketika fungsionalitas baru dikodekan, kita menyalakan PostgreSQL untuk mencatat semua pertanyaan (log_min_duration_statement ke 0) dan menjalankan pengujian beban selama 20 menit. Menggunakan log yang dikumpulkan, utilitas seperti pgFouine dan pgBadger dapat membuat laporan analitik. Dalam laporan, kami terutama mencari kueri yang lambat dan sering. Untuk permintaan yang lambat, kami membangun rencana eksekusi (JELASKAN) dan mengevaluasi apakah permintaan seperti itu dapat dipercepat. Permintaan yang sering untuk data input yang sama di-cache dengan baik. Kami mencoba untuk menjaga permintaan "flat", satu tabel per permintaan.
Operasi
SV sebagai layanan online diluncurkan pada musim semi 2017, sebagai produk SV terpisah dirilis pada November 2017 (saat itu dalam status beta).
Lebih dari satu tahun beroperasi, masalah serius dalam pengoperasian layanan online CB tidak terjadi. Kami memantau layanan online melalui
Zabbix , mengumpulkan dan menggunakan dari
Bamboo .
Kit distribusi server CB dikirimkan dalam bentuk paket asli: RPM, DEB, MSI. Plus untuk Windows, kami menyediakan satu penginstal dalam bentuk satu EXE, yang memasang server, Hazelcast, dan Elasticsearch pada satu mesin. Awalnya kami menyebut versi instalasi ini "demo", tetapi sekarang menjadi jelas bahwa ini adalah opsi penyebaran yang paling populer.