
Saya suka Ceph. Saya telah bekerja dengannya selama 4 tahun (0.80.x - 12.2.6 , 12.2.5). Kadang-kadang saya sangat bersemangat tentang dia sehingga saya menghabiskan malam dan malam di perusahaannya, dan tidak dengan pacar saya. Saya telah mengalami berbagai masalah dalam produk ini, dan saya terus hidup dengan beberapa masalah sampai hari ini. Terkadang saya bersukacita dengan keputusan yang mudah, dan kadang-kadang saya bermimpi bertemu dengan pengembang untuk mengekspresikan kemarahan saya. Tetapi Ceph masih digunakan dalam proyek kami dan ada kemungkinan bahwa itu akan digunakan dalam tugas-tugas baru, setidaknya oleh saya. Dalam cerita ini, saya akan membagikan pengalaman kami dalam mengoperasikan Ceph, dalam beberapa hal saya akan mengekspresikan diri pada topik yang tidak saya sukai tentang solusi ini dan mungkin membantu mereka yang hanya melihatnya. Peristiwa yang dimulai sekitar setahun yang lalu ketika saya membawa Dell EMC ScaleIO, sekarang dikenal sebagai Dell EMC VxFlex OS, mendorong saya untuk menulis artikel ini.
Ini sama sekali bukan iklan untuk Dell EMC atau produk mereka! Secara pribadi, saya tidak terlalu baik dengan perusahaan besar, dan kotak hitam seperti VxFlex OS. Tapi seperti yang Anda tahu, semua yang ada di dunia bersifat relatif dan menggunakan contoh VxFlex OS, sangat mudah untuk menunjukkan apa itu Ceph dari sudut pandang operasi, dan saya akan mencoba melakukannya.
Parameter Ini tentang angka 4 digit!
Layanan Ceph seperti MON, OSD, dll. memiliki berbagai parameter untuk mengatur semua jenis subsistem. Parameter diatur dalam file konfigurasi, daemon membacanya pada saat peluncuran. Beberapa nilai dapat dengan mudah diubah dengan cepat menggunakan mekanisme "injeksi", yang dijelaskan di bawah ini. Semuanya hampir super, jika Anda menghilangkan momen yang ada ratusan parameter:
Palu:
> ceph daemon mon.a config show | wc -l 863
Bercahaya:
> ceph daemon mon.a config show | wc -l 1401
Ternyata ~ 500 parameter baru dalam dua tahun. Secara umum, parameterisasi itu keren, tidak keren ada kesulitan memahami 80% dari daftar ini. Dokumentasi menjelaskan oleh perkiraan saya ~ 20% dan di beberapa tempat ambigu. Pemahaman tentang arti sebagian besar parameter harus ditemukan di github proyek atau di milis, tetapi ini tidak selalu membantu.
Berikut adalah contoh beberapa parameter yang baru saja saya minati, saya menemukannya di blog salah satu Ceph-gadfly:
throttler_perf_counter = false // enable/disable throttler perf counter osd_enable_op_tracker = false // enable/disable OSD op tracking
Komentar kode dalam semangat praktik terbaik. Seolah-olah, saya mengerti kata-kata itu dan bahkan kira-kira tentang apa kata-katanya, tetapi apa yang akan saya dapatkan tidak.
Atau di sini: osd_op_threads di Luminous hilang dan hanya kode sumber yang membantu menemukan nama baru: osd_peering_wq utas
Saya juga suka bahwa ada opsi terutama holistik. Di sini dude menunjukkan bahwa meningkatkan rgw_num _rados_handles bagus :
dan pria lain berpikir bahwa> 1 tidak mungkin dan bahkan berbahaya .
Dan hal favorit saya adalah ketika pemula memberikan contoh konfigurasi dalam posting blog mereka, di mana semua parameter tanpa pertimbangan (menurut saya) disalin dari blog lain dengan jenis yang sama, dan begitu banyak parameter yang tidak diketahui oleh siapa pun kecuali pembuat kode berkeliaran dari config ke config.
Saya juga hanya membakar secara liar dengan apa yang mereka lakukan di Luminous. Ada fitur super keren - mengubah parameter dengan cepat, tanpa memulai kembali proses. Anda dapat, misalnya, mengubah parameter OSD tertentu:
> ceph tell osd.12 injectargs '--filestore_fd_cache_size=512'
atau letakkan '*' alih-alih 12 dan nilainya akan diubah pada semua OSD. Sangat keren, sungguh. Tapi, seperti banyak di Ceph, ini dilakukan dengan kaki kiri. Desain Bai tidak semua nilai parameter dapat diubah dengan cepat. Lebih tepatnya, mereka dapat diatur dan mereka akan tampak berubah dalam output, tetapi pada kenyataannya, hanya beberapa yang dibaca kembali dan diterapkan kembali. Misalnya, Anda tidak dapat mengubah ukuran kumpulan utas tanpa memulai kembali proses. Sehingga pelaksana tim memahami bahwa tidak ada gunanya mengubah parameter dengan cara ini - mereka memutuskan untuk mencetak pesan. Halo
Sebagai contoh:
> ceph tell mon.* injectargs '--mon_allow_pool_delete=true' mon.c: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart) mon.a: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart) mon.b: injectargs:mon_allow_pool_delete = 'true' (not observed, change may require restart)
Ambigu. Bahkan, penghapusan kolam menjadi mungkin setelah injeksi. Artinya, peringatan ini tidak relevan untuk parameter ini. Ok, tetapi masih ada ratusan parameter, termasuk yang sangat berguna, yang juga memiliki peringatan dan tidak ada cara untuk memeriksa penerapannya yang sebenarnya. Saat ini, saya bahkan tidak bisa mengerti dengan kode parameter mana yang diterapkan setelah injeksi dan mana yang tidak. Untuk keandalan, Anda harus memulai kembali layanan dan ini, Anda tahu, membuat marah. Amarah karena saya tahu ada mekanisme injeksi.
Bagaimana dengan VxFlex OS? Proses serupa seperti MON (dalam VxFlex itu adalah MDM), OSD (SDS di VxFlex) juga memiliki file konfigurasi, di mana ada lusinan parameter untuk semua. Benar, nama mereka juga tidak mengatakan apa-apa, tetapi kabar baiknya adalah bahwa kita tidak pernah menggunakan mereka untuk membakar sebanyak dengan Ceph.
Utang teknis
Ketika Anda mulai berkenalan dengan Ceph dengan versi yang paling relevan untuk hari ini, maka semuanya tampak baik-baik saja, dan Anda ingin menulis artikel yang positif. Tetapi ketika Anda tinggal bersamanya di prod dari versi 0.80, maka semuanya tidak terlihat begitu cerah.
Sebelum Jewel, proses Ceph berjalan sebagai root. Jewel memutuskan bahwa mereka harus bekerja dari pengguna 'ceph' dan ini memerlukan perubahan kepemilikan untuk semua direktori yang digunakan oleh layanan Ceph. Tampaknya ini? Bayangkan sebuah OSD yang melayani disk magnetik SATA kapasitas 2 TB penuh. Jadi, chown dari disk seperti itu, secara paralel (ke subdirektori berbeda) dengan pemanfaatan disk penuh membutuhkan waktu 3-4 jam. Bayangkan, misalnya, Anda memiliki 3 ratusan disk seperti itu. Bahkan jika Anda memperbarui node (chown segera 8-12 disk), Anda mendapatkan pembaruan yang agak lama, di mana cluster akan memiliki OSD versi yang berbeda dan satu replika data kurang pada saat server diperbarui. Secara umum, kami pikir itu tidak masuk akal, membangun kembali paket Ceph dan membiarkan OSD berjalan sebagai root. Kami memutuskan bahwa ketika kami memasuki atau mengganti OSD, kami akan mentransfernya ke pengguna baru. Sekarang kami mengganti 2-3 drive per bulan dan menambahkan 1-2, saya pikir kami dapat mengatasinya pada tahun 2022).
CRUSH Tunables
CRUSH adalah jantung Ceph, semuanya berputar di sekitarnya. Ini adalah algoritma di mana, secara pseudo-acak, lokasi data dipilih dan berkat klien yang bekerja dengan cluster RADOS mengetahui OSD mana data (objek) yang mereka butuhkan disimpan. Fitur utama CRUSH adalah bahwa tidak ada kebutuhan untuk server metadata apa pun, seperti Lustre atau IBM GPFS (sekarang Spectrum Scale). CRUSH memungkinkan klien dan OSD untuk berinteraksi langsung satu sama lain. Meskipun, tentu saja, sulit untuk membandingkan penyimpanan objek RADOS primitif dan sistem file, yang saya berikan sebagai contoh, tapi saya pikir idenya jelas.
Tunables CRUSH, pada gilirannya, adalah seperangkat parameter / flag yang memengaruhi operasi CRUSH, membuatnya lebih efisien, setidaknya secara teori.
Jadi, ketika meningkatkan dari Hammer ke Jewel (uji secara alami), sebuah peringatan muncul, mengatakan bahwa profil tunable memiliki parameter yang tidak optimal untuk versi saat ini (Jewel) dan disarankan untuk mengganti profil ke yang optimal. Secara umum, semuanya jelas. Dok mengatakan bahwa ini sangat penting dan ini adalah cara yang benar, tetapi juga dikatakan bahwa setelah pengalihan data akan terjadi pemberontakan sebesar 10% dari data. 10% - ini tidak terdengar menakutkan, tetapi kami memutuskan untuk mengujinya. Untuk sebuah cluster, itu sekitar 10 kali lebih sedikit daripada pada prod, dengan jumlah PG yang sama per OSD, diisi dengan data uji, kami mendapat pemberontakan 60%! Bayangkan, misalnya, dengan 100TB data, 60TB mulai bergerak di antara OSD dan ini dengan beban klien yang terus-menerus menuntut latensi! Jika saya belum mengatakan, kami menyediakan s3 dan kami tidak memiliki beban lebih sedikit pada rgw bahkan di malam hari, yang ada 8 dan 4 lainnya di bawah situs web statis. Secara umum, kami memutuskan bahwa ini bukan cara kami, terutama karena melakukan pembangunan kembali pada versi yang baru, yang sebelumnya kami tidak bekerja di prod, setidaknya terlalu optimis. Selain itu, kami memiliki indeks bucket besar yang pembangunannya sangat buruk dan ini juga menjadi alasan keterlambatan dalam beralih profil. Tentang indeks akan terpisah sedikit lebih rendah. Pada akhirnya, kami hanya menghapus peringatan dan memutuskan untuk kembali ke sini nanti.
Dan ketika mengganti profil dalam pengujian, cephfs-klien yang berada di kernel CentOS 7.2 jatuh karena mereka tidak dapat bekerja dengan algoritma hashing yang lebih baru dari profil baru yang datang. Kami tidak menggunakan cephfs di prod, tetapi jika kami terbiasa, ini akan menjadi alasan lain untuk tidak mengganti profil.
Omong-omong, dok mengatakan bahwa jika apa yang terjadi selama pemberontakan tidak sesuai dengan Anda, Anda dapat memutar kembali profil. Faktanya, setelah instalasi bersih dari versi Hammer dan upgrade ke Jewel, profilnya terlihat seperti ini:
> ceph osd crush show-tunables { ... "straw_calc_version": 1, "allowed_bucket_algs": 22, "profile": "unknown", "optimal_tunables": 0, ... }
Adalah penting bahwa itu "tidak diketahui" dan jika Anda mencoba menghentikan pembangunan kembali dengan mengubahnya menjadi "warisan" (seperti yang dinyatakan di dermaga) atau bahkan ke "palu", maka pemberontakan tidak akan berhenti, itu hanya akan berlanjut sesuai dengan merdu lainnya, dan tidak " optimal. " Secara umum, semuanya perlu diperiksa secara menyeluruh dan diperiksa ulang, karena ceph tidak dipercaya.
CRUSH trade-of
Seperti yang Anda ketahui, segala sesuatu di dunia ini seimbang dan kerugian diterapkan untuk semua keuntungan. Kerugian CRUSH adalah bahwa PG didistribusikan secara tidak merata di berbagai OSD bahkan dengan bobot yang sama dari yang terakhir. Plus, tidak ada yang mencegah PG berbeda dari tumbuh pada kecepatan yang berbeda, sementara fungsi hash akan turun. Secara khusus, kami memiliki kisaran pemanfaatan OSD 48-84%, meskipun faktanya mereka memiliki ukuran yang sama dan, karenanya, berat. Kami bahkan mencoba membuat server sama beratnya, tetapi ini benar, hanya kesempurnaan kami, tidak lebih. Dan buah ara dengan fakta bahwa IO didistribusikan secara tidak merata di seluruh disk, hal terburuk adalah ketika Anda mencapai status penuh (95%) dari setidaknya satu OSD di kluster, seluruh rekaman berhenti dan kluster berjalan hanya baca. Seluruh kluster! Dan tidak masalah bahwa cluster masih penuh ruang. Semuanya, final, keluar! Ini adalah fitur arsitektur CRUSH. Bayangkan Anda sedang berlibur, beberapa OSD mematahkan nilai 85% (peringatan pertama secara default), dan Anda memiliki stok 10% untuk mencegah perekaman berhenti. Dan 10% dengan perekaman yang aktif tidak terlalu lama. Idealnya, dengan desain seperti itu, Ceph membutuhkan seseorang yang bertugas yang dapat mengikuti instruksi yang disiapkan dalam kasus tersebut.
Jadi, kami memutuskan itu berarti ketidakseimbangan data di cluster, karena beberapa OSD mendekati tanda hampir penuh (85%).
Ada beberapa cara:
Cara termudah adalah sedikit boros dan tidak terlalu efektif, karena data itu sendiri mungkin tidak bergerak dari OSD yang ramai atau gerakan akan diabaikan.
- Ubah bobot permanen OSD (BERAT)
Hal ini menyebabkan perubahan pada berat semua hierarki bucket (terminologi CRUSH) yang lebih tinggi, server OSD, pusat data, dll. dan, sebagai akibatnya, untuk pergerakan data, termasuk bukan dari OSD yang darinya diperlukan.
Kami mencoba, mengurangi bobot satu OSD, setelah data membangun kembali yang lain terisi, kami menguranginya, lalu yang ketiga dan kami menyadari bahwa kami akan memainkan ini untuk waktu yang lama.
- Ubah bobot OSD tidak permanen (REWEIGHT)
Inilah yang dilakukan dengan memanggil 'ceph osd reweight-by-utilization'. Ini menyebabkan perubahan pada apa yang disebut bobot penyesuaian OSD, dan bobot bucket yang lebih tinggi tidak berubah. Akibatnya, data diseimbangkan antara OSD yang berbeda dari satu server, seolah-olah, tanpa melampaui batas-batas ember CRUSH. Kami sangat menyukai pendekatan ini, kami melihat pada dry run perubahan apa yang akan terjadi dan dilakukan pada prod. Semuanya baik-baik saja sampai proses pemberontakan dipertaruhkan di tengah. Lagi-lagi googling, membaca buletin, bereksperimen dengan opsi yang berbeda, dan pada akhirnya ternyata penghentian itu disebabkan oleh kurangnya beberapa merdu dalam profil yang disebutkan di atas. Sekali lagi kami terjebak dalam hutang teknis. Sebagai hasilnya, kami mengikuti jalur penambahan disk dan pembangunan kembali yang paling tidak efektif. Untungnya, kami masih perlu melakukan ini karena Direncanakan untuk mengganti profil CRUSH dengan kapasitas yang memadai.
Ya, kita tahu tentang penyeimbang (Bercahaya dan lebih tinggi), yang merupakan bagian dari mgr, yang dirancang untuk menyelesaikan masalah distribusi data yang tidak merata dengan memindahkan PG antar OSD, misalnya, pada malam hari. Tapi saya belum mendengar ulasan positif tentang karyanya, bahkan dalam Mimic saat ini.
Anda mungkin akan mengatakan bahwa hutang teknis adalah murni masalah kita dan saya mungkin akan setuju. Tetapi selama empat tahun dengan Ceph di prod, kami hanya memiliki satu downtime s3 direkam, yang berlangsung 1 jam penuh. Dan kemudian, masalahnya bukan pada RADOS, tetapi di RGW, yang, setelah mengetik 100 utas defaultnya, sangat ketat dan sebagian besar pengguna tidak memenuhi permintaan. Itu masih di Hammer. Menurut pendapat saya, ini adalah indikator yang baik dan dicapai karena fakta bahwa kami tidak melakukan gerakan tiba-tiba dan agak skeptis tentang segala sesuatu di Ceph.
Gc liar
Seperti yang Anda tahu, menghapus data langsung dari disk adalah tugas yang agak berat dan dalam sistem yang canggih, menghapus data tertunda atau tidak dilakukan sama sekali. Ceph juga merupakan sistem canggih, dan dalam kasus RGW, ketika menghapus objek s3, objek RADOS yang sesuai tidak segera dihapus dari disk. RGW menandai objek s3 sebagai dihapus, dan aliran gc yang terpisah menghapus objek langsung dari kumpulan RADOS dan, karenanya, ditunda dari disk. Setelah memperbarui ke Luminous, perilaku gc berubah secara nyata, mulai bekerja lebih agresif, meskipun parameter gc tetap sama. Dengan kata nyata, maksud saya bahwa kami mulai melihat gc bekerja pada pemantauan eksternal layanan untuk melompat latensi. Ini disertai oleh IO tinggi di kolam rgw.gc. Tetapi masalah yang kita hadapi jauh lebih epik daripada hanya IO. Saat gc berjalan, banyak log dari formulir dihasilkan:
0 <cls> /builddir/build/BUILD/ceph-12.2.5/src/cls/rgw/cls_rgw.cc:3284: gc_iterate_entries end_key=1_01530264199.726582828
Di mana 0 di awal adalah level logging di mana pesan ini dicetak. Seolah-olah, tidak ada tempat untuk penebangan yang lebih rendah di bawah nol. Akibatnya, ~ 1 GB log dihasilkan di dalam kita oleh satu OSD dalam beberapa jam, dan semuanya akan baik-baik saja jika node ceph tidak diskless ... Kami memuat OS melalui PXE langsung ke memori dan tidak menggunakan disk lokal atau NFS, NBD untuk partisi sistem (/). Ternyata server stateless. Setelah reboot, seluruh negara bagian digulirkan oleh otomatisasi. Cara kerjanya, entah bagaimana saya akan jelaskan dalam artikel terpisah, sekarang penting bahwa 6 GB memori dialokasikan untuk "/", yang ~ 4 biasanya gratis. Kami mengirim semua log ke Graylog dan menggunakan kebijakan rotasi log yang agak agresif dan biasanya tidak mengalami masalah dengan overflow disk / RAM. Tapi kami tidak siap untuk ini, dengan 12 OSD, server "/" terisi dengan sangat cepat, petugas tepat waktu tidak menanggapi pemicu di Zabbix dan OSD baru mulai berhenti karena ketidakmampuan untuk menulis log. Akibatnya, kami mengurangi intensitas gc, tiket tidak dimulai karena Itu sudah ada di sana, dan kami menambahkan skrip ke cron, di mana kami memaksa log OSD untuk memotong ketika jumlah tertentu terlampaui tanpa menunggu logrotate. Omong-omong, tingkat penebangan meningkat .
Grup Penempatan dan Skalabilitas yang Dipuji
Menurut saya, PG adalah abstraksi yang paling sulit untuk dipahami. PG diperlukan untuk membuat CRUSH lebih efektif. Tujuan utama PG adalah untuk mengelompokkan objek untuk mengurangi konsumsi sumber daya, meningkatkan produktivitas, dan skalabilitas. Mengatasi objek secara langsung, individual, tanpa menggabungkannya ke PG akan sangat mahal.
Masalah utama PG adalah menentukan jumlah mereka untuk kumpulan baru. Dari blog Ceph:
"Memilih jumlah PG yang tepat untuk klustermu adalah sedikit seni hitam - dan mimpi buruk kegunaan."
Ini selalu sangat spesifik untuk instalasi tertentu dan membutuhkan banyak pemikiran dan perhitungan.
Rekomendasi utama:
- Terlalu banyak PG di OSD yang buruk, akan ada pengeluaran berlebihan sumber daya untuk pemeliharaan dan rem selama penyeimbangan / pemulihan.
- Beberapa PG di OSD buruk, kinerjanya akan buruk, dan OSD akan dihuni secara tidak merata.
- Angka PG harus kelipatan derajat 2. Ini akan membantu mendapatkan "kekuatan CRUSH."
Dan di sini terbakar bersama saya. Pg tidak terbatas dalam volume atau jumlah objek. Berapa banyak sumber daya (dalam bilangan real) yang dibutuhkan untuk melayani satu PG? Apakah ini tergantung pada ukurannya? Apakah itu tergantung pada jumlah replika dari PG ini? Haruskah saya mandi uap jika saya memiliki cukup memori, CPU cepat dan jaringan yang bagus?
Dan Anda juga perlu memikirkan pertumbuhan cluster di masa depan. Nomor PG tidak dapat dikurangi - hanya bertambah. Pada saat yang sama, tidak dianjurkan untuk melakukan ini, karena ini akan memerlukan, pada dasarnya, membagi sebagian PG ke pembangunan kembali yang baru dan liar.
"Meningkatkan Jumlah PG dari kumpulan adalah salah satu peristiwa yang paling berdampak dalam Ceph Cluster, dan harus dihindari untuk kluster produksi jika memungkinkan."
Karena itu, Anda perlu memikirkan masa depan segera, jika memungkinkan.
Contoh nyata.
Sekelompok 3 server dengan masing-masing 14x2 TB OSD, total 42 OSD. Replika 3, tempat yang berguna ~ 28 TB. Untuk digunakan di bawah S3, Anda perlu menghitung jumlah PG untuk kumpulan data dan kumpulan indeks. RGW menggunakan lebih banyak kumpulan, tetapi keduanya primer.
Kami masuk ke kalkulator PG (ada kalkulator seperti itu), kami mempertimbangkan dengan 100 PG yang direkomendasikan pada OSD, kami hanya mendapatkan 1.312 PG. Tapi tidak semuanya begitu sederhana: kami memiliki yang pengantar - cluster pasti akan tumbuh tiga kali dalam setahun, tetapi besi akan dibeli sedikit kemudian. Kami meningkatkan "Target PG per OSD" tiga kali, menjadi 300 dan kami mendapatkan 4480 PG.
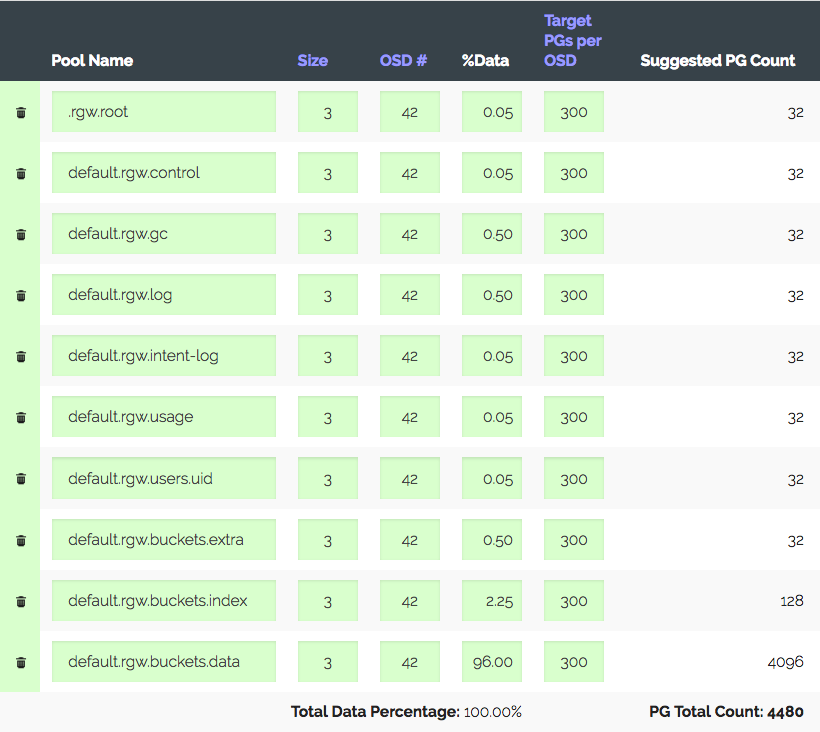
Tetapkan jumlah PG untuk kumpulan yang sesuai - kami mendapat peringatan: terlalu banyak PG Per OSD ... yang tiba. Menerima ~ 300 PG pada OSD dengan batas 200 (Luminous). Omong-omong, 300. Dan hal yang paling menarik adalah bahwa semua PG yang tidak perlu tidak boleh mengintip, yaitu, ini bukan hanya peringatan. Sebagai hasilnya, kami percaya bahwa kami melakukan segalanya dengan benar, menaikkan batas, mematikan peringatan, dan melanjutkan.
Contoh nyata lainnya lebih menarik.
S3, 152 TB volume yang dapat digunakan, 252 OSD pada 1,81 TB, ~ 105 PG pada OSD. Cluster tumbuh secara bertahap, semuanya baik-baik saja sampai dengan undang-undang baru di negara kita ada kebutuhan untuk pertumbuhan menjadi 1 PB, yaitu + ~ 850 TB, dan pada saat yang sama Anda perlu mempertahankan kinerja, yang sekarang cukup bagus untuk S3. Misalkan kita mengambil disk 6 (5,7 nyata) TB dan dengan mempertimbangkan replika akun 3 kita mendapatkan + 447 OSD. Dengan mempertimbangkan yang saat ini, kami mendapatkan 699 OSD masing-masing dengan 37 PG, dan jika kami mempertimbangkan bobot yang berbeda, ternyata OSD lama hanya memiliki selusin PG. Jadi Anda memberi tahu saya seberapa lumayan ini akan bekerja? Kinerja sebuah cluster dengan jumlah PG yang berbeda cukup sulit untuk diukur secara sintetis, tetapi tes yang saya lakukan menunjukkan bahwa untuk kinerja yang optimal diperlukan dari 50 PG menjadi 2 TB OSD. Dan bagaimana dengan pertumbuhan selanjutnya? Tanpa menambah jumlah PG, Anda bisa pergi ke pemetaan PG ke OSD 1: 1. Mungkin saya tidak mengerti sesuatu?
Ya, Anda dapat membuat kumpulan baru untuk RGW dengan jumlah PG yang diinginkan dan memetakan wilayah S3 terpisah untuknya. Atau bahkan membangun kluster baru di dekatnya. Tetapi Anda harus mengakui bahwa ini semua adalah tongkat penyangga. Dan ternyata Ceph tampaknya berskala baik karena konsepnya, PG berskala dengan reservasi. Anda harus hidup dengan penilaian yang dinonaktifkan dalam persiapan untuk pertumbuhan, atau pada suatu saat membangun kembali semua data dalam cluster, atau skor pada kinerja dan hidup dengan apa yang terjadi. Atau lalui semua itu.
Saya senang bahwa pengembang Ceph memahami bahwa PG adalah abstraksi yang kompleks dan berlebihan bagi pengguna dan dia lebih baik tidak mengetahuinya.
"Di Luminous kami telah mengambil langkah-langkah besar untuk akhirnya menghilangkan salah satu cara paling umum untuk mengarahkan kluster Anda ke parit, dan berharap kami pada akhirnya bertujuan menyembunyikan PG sepenuhnya sehingga mereka bukan sesuatu yang sebagian besar pengguna harus pernah tahu atau pikirkan tentang ".
Di vxFlex tidak ada konsep PG atau analog. Anda cukup menambahkan disk ke pool dan hanya itu. Dan seterusnya hingga 16 PB. Bayangkan, tidak ada yang perlu dihitung, tidak ada tumpukan status PG ini, disk dibuang secara seragam sepanjang pertumbuhan. Karena disk diberikan kepada vxFlex secara keseluruhan (tidak ada sistem file di atasnya) tidak ada cara untuk menilai kepenuhan dan tidak ada masalah sama sekali. Saya bahkan tidak tahu bagaimana menyampaikan kepada Anda betapa menyenangkannya itu.
"Perlu menunggu SP1"
Kisah lain tentang "kesuksesan." Seperti yang Anda ketahui, RADOS adalah penyimpanan nilai kunci yang paling primitif. S3, diimplementasikan di atas RADOS, juga primitif, tetapi masih sedikit lebih fungsional. , S3 . , , RGW . — RADOS-, OSD. . , . OSD down. , , . , scrub' . , - 503, .
Bucket Index resharding — , (RADOS-) , , OSD, .
, , Jewel ! Hammer, .. -. ?
Hammer 20+ , , OSD Graylog , . , .. IO . Luminous, .. . Luminous, , . , . IO index-, , . , IO , . , … ; , :
, . , .. , .
, Hammer->Jewel - . OSD - . , OSD .
— , , . Hammer s3, . , . , , etag, body, . . , . Suspend . "" . , .
, 2 — , Cloudmouse. , Ceph, , .
vxFlex OS 2 . , . , . , . , , , Dell EMC.
. , ? . , . , Ceph, vxFlex . - . , .
9 ceph-devel : , CPU ( Xeon' !) IOPS All-NVMe Ceph 12.2.7 bluestore.
, , "" Ceph . ( Hammer) Ceph , s3 . , ScaleIO Ceph RBD . Ceph, — CPU. RDMA InfiniBand, jemalloc . , 10-20 , iops, io, Ceph . vxFlex . — Ceph system time, scaleio — io wait. , bluestore, , , -, , Ceph. ScaleIO . , , Ceph Dell EMC.
, , PG. (), IO. - PG IO, , . , nearfull. , .
vxFlex - , . ( ceph-volume), , .
Scrub
, . , , Ceph.
, . " " — - , . , 2 TB >50%, Ceph, . . , .
vxFlex OS , , . — bandwidth . . , .
, , vxFlex scrub-error. Ceph 2 .
Luminous — . . MGR- Zabbix (3 ). . , , - IO , gc, . — RGW .

. .
S3, "" :
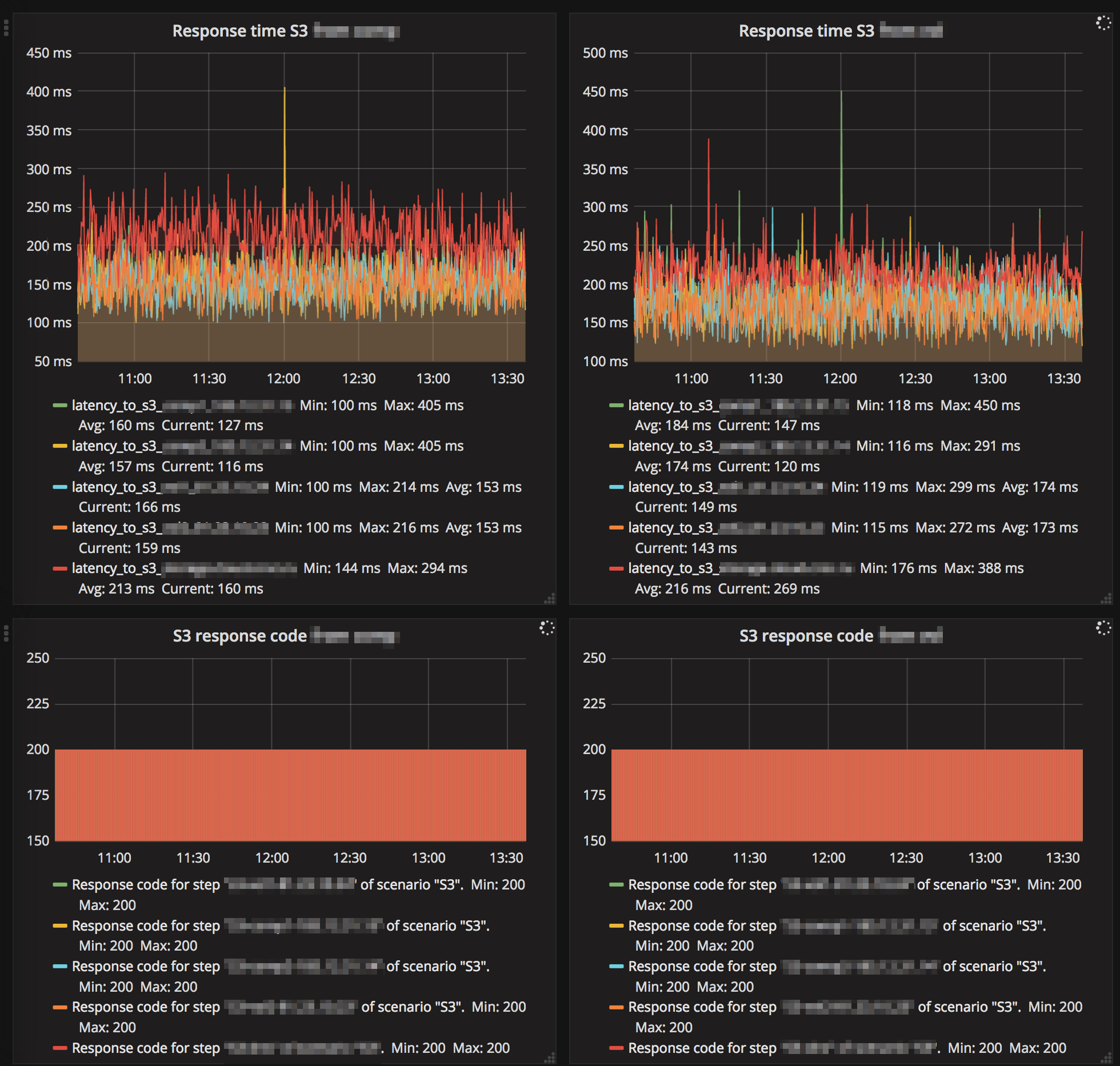
Ceph , , , , .
, eph Graylog GELF . , , OSD down, out, failed . , , OSD down , .
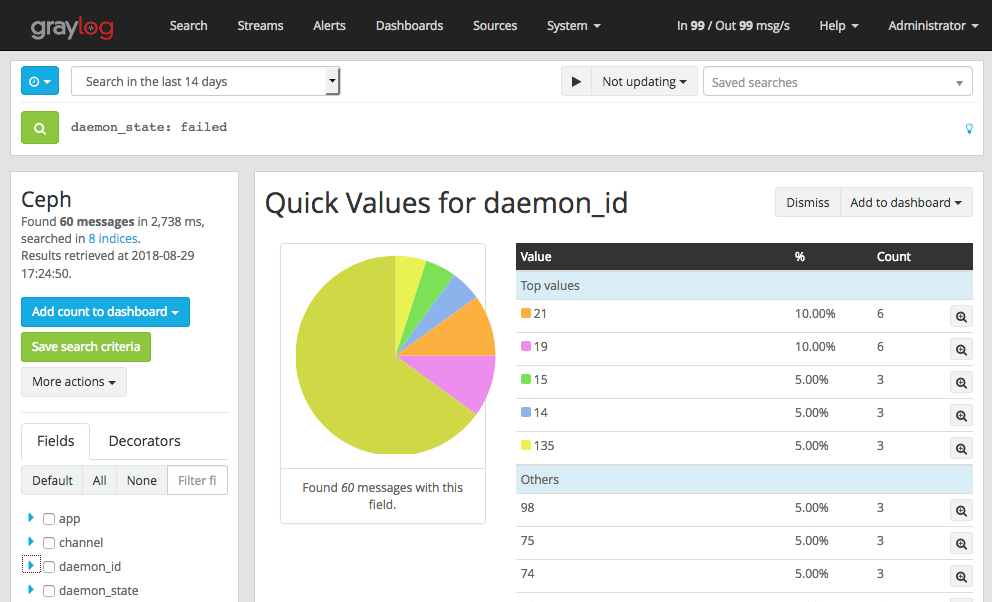
- , OSD heartbeat failed (. ). vm.zone_reclaim_mode=1 NUMA.
Ceph. c vxFlex . :
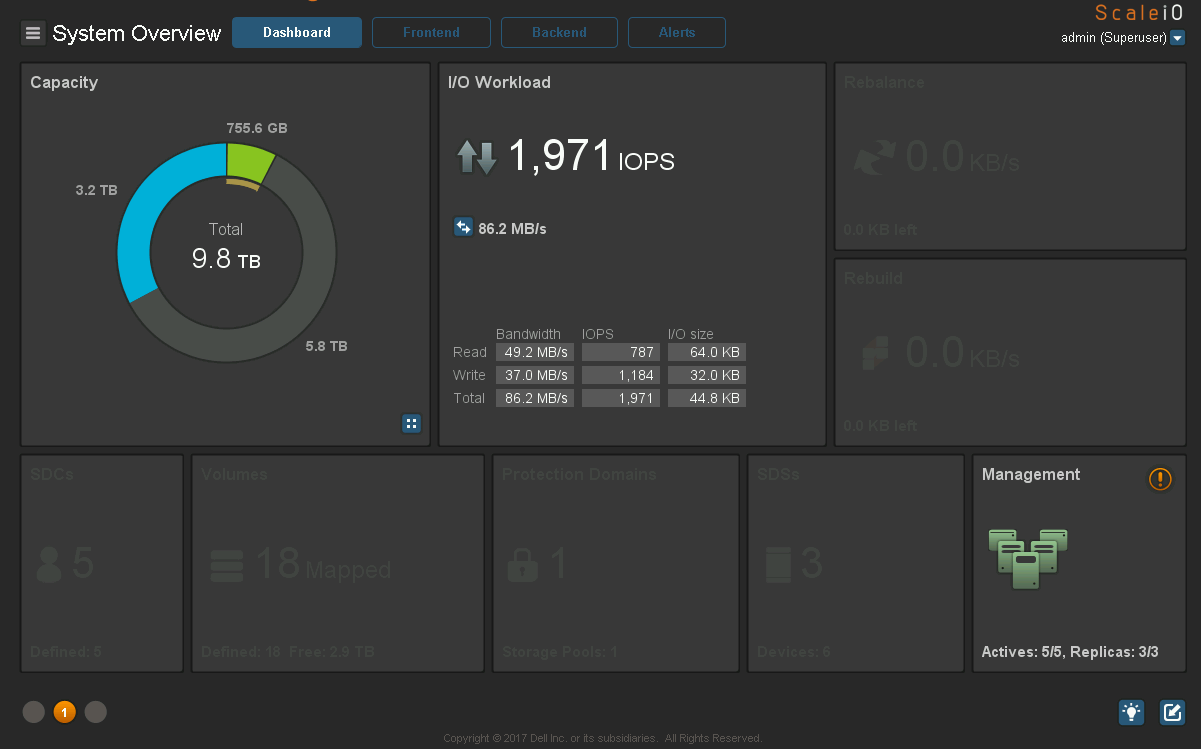
:

IO :
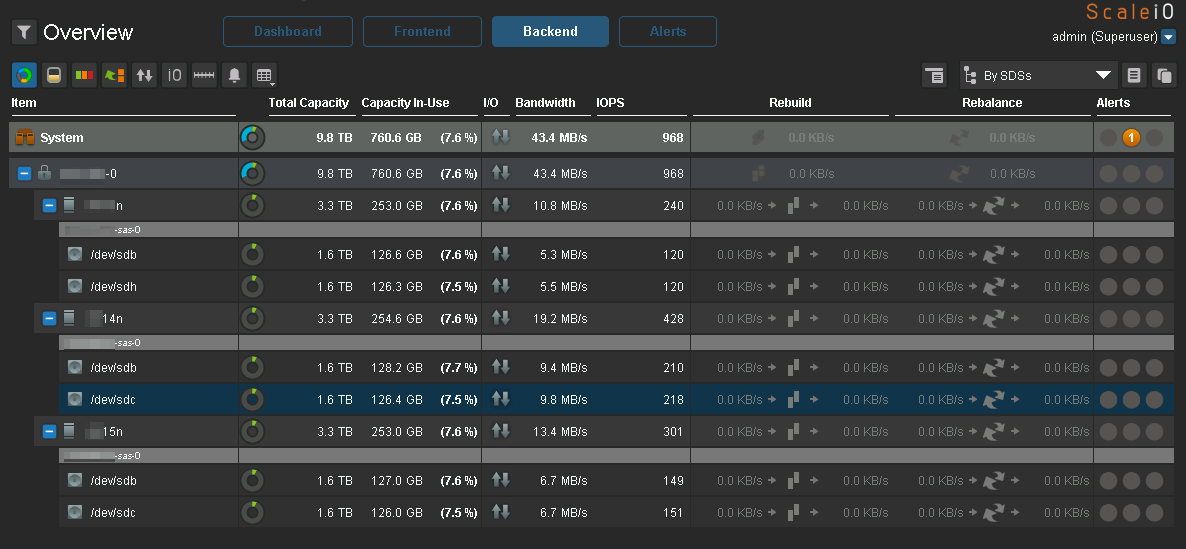
IO, Ceph.
:
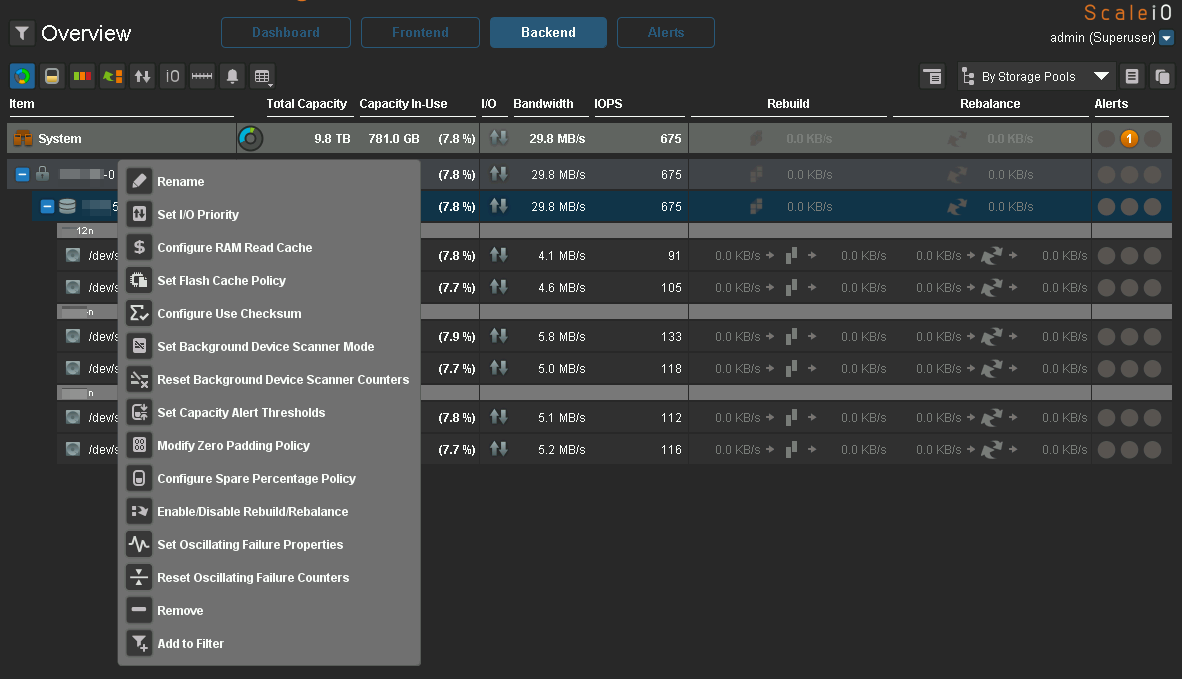
Ceph, Luminous . 2.0, Mimic , .
vxFlex
Degraded state , .
vxFlex — RH . 7.5 , . Ceph RBD cephfs — .
vxFlex Ceph. vxFlex — , , , .
16 PB, . eph 2 PB …
Kesimpulan
, Ceph , , , Ceph — . .
, Ceph " ". , " , , R&D, - ". . " ", Ceph , , .
Ceph 2k18 , . 24/7 ( S3, , EBS), , Ceph . , . — . / maintenance backfilling , c Ceph , , .
Ceph ? , " ". Ceph. . , , , , …
!
HEALTH_OK!