Artikel ini akan fokus pada penyeimbangan beban dalam proyek web. Banyak yang percaya bahwa solusi untuk masalah ini dalam distribusi beban antar server - semakin akurat, semakin baik. Tetapi kita tahu bahwa ini tidak sepenuhnya benar.
Stabilitas sistem jauh lebih penting dari sudut pandang bisnis .
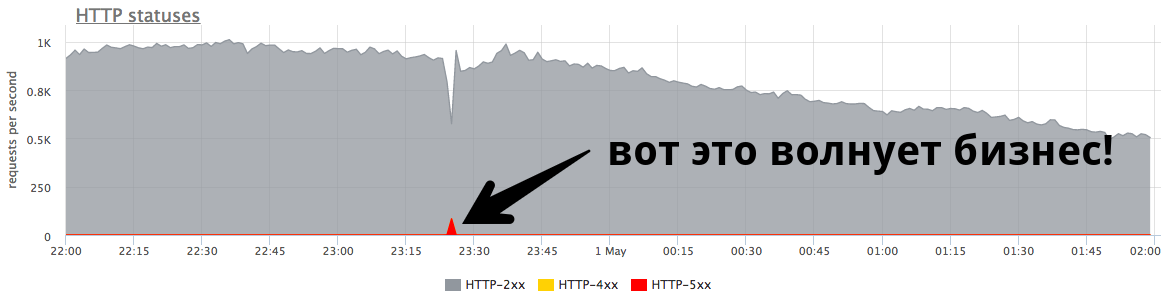
Puncak menit kecil di 84 RPS "lima ratus" adalah lima ribu kesalahan yang diterima pengguna nyata. Ini banyak dan sangat penting. Penting untuk mencari alasan, mengerjakan kesalahan dan mencoba terus mencegah situasi seperti itu.
Nikolay Sivko (
NikolaySivko ) dalam laporannya tentang RootConf 2018 berbicara tentang aspek penyeimbangan beban yang halus dan belum populer:
- kapan harus mengulangi permintaan (coba lagi);
- cara memilih nilai untuk waktu habis;
- bagaimana tidak membunuh server yang mendasarinya pada saat kecelakaan / kemacetan;
- apakah pemeriksaan kesehatan diperlukan;
- bagaimana menangani masalah yang berkedip-kedip.
Di bawah decoding kucing laporan ini.
Tentang pembicara: Nikolay Sivko, pendiri okmeter.io. Dia bekerja sebagai administrator sistem dan pemimpin sekelompok administrator. Operasi yang diawasi di hh.ru. Ia mendirikan layanan pemantauan okmeter.io. Sebagai bagian dari laporan ini, pengalaman pemantauan pemantauan adalah sumber utama kasus.
Apa yang akan kita bicarakan?
Artikel ini akan berbicara tentang proyek web. Di bawah ini adalah contoh produksi langsung: grafik menunjukkan permintaan per detik untuk layanan web tertentu.
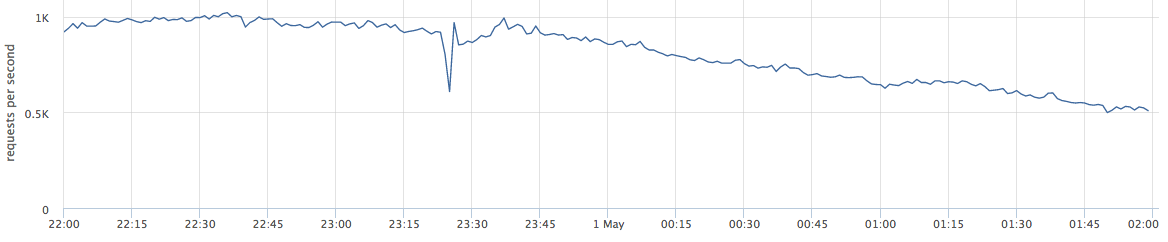
Ketika saya berbicara tentang penyeimbangan, banyak yang melihatnya sebagai "kita perlu mendistribusikan beban antar server - semakin akurat, semakin baik."
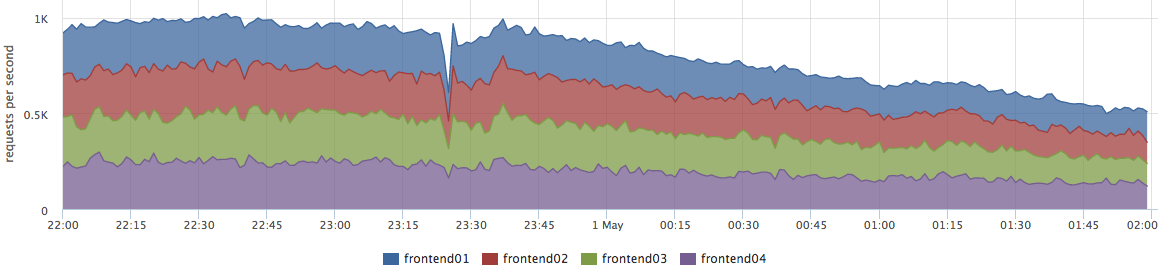
Sebenarnya, ini tidak sepenuhnya benar. Masalah ini relevan untuk sejumlah kecil perusahaan. Lebih sering bisnis khawatir tentang kesalahan dan stabilitas sistem.
Puncak kecil pada grafik adalah "lima ratus", yang dikembalikan oleh server dalam satu menit, dan kemudian berhenti. Dari sudut pandang bisnis, seperti toko online, puncak kecil ini di 84 RPS "lima ratus" adalah 5040 kesalahan untuk pengguna nyata. Beberapa tidak menemukan sesuatu di katalog Anda, yang lain tidak bisa memasukkan barang ke keranjang. Dan ini sangat penting. Meskipun puncak ini tidak terlihat sangat besar pada grafik,
ini banyak di pengguna nyata .
Sebagai aturan, setiap orang memiliki puncak seperti itu, dan admin tidak selalu meresponsnya. Sangat sering, ketika sebuah bisnis bertanya apa itu, mereka menjawabnya:
- "Ini ledakan singkat!"
- "Ini hanya rilis bergulir."
- "Server sudah mati, tetapi semuanya sudah beres."
- "Vasya mengganti jaringan salah satu backend."
Seringkali orang
bahkan tidak mencoba untuk memahami alasan mengapa hal ini terjadi, dan tidak melakukan pasca kerja sehingga tidak terjadi lagi.
Nada yang bagus
Saya menyebut laporan "Fine tuning" (Inggris. Fine tuning), karena saya pikir tidak semua orang dapat melakukan tugas ini, tetapi akan sia-sia. Kenapa mereka tidak ke sana?
- Tidak semua orang mendapatkan tugas ini, karena ketika semuanya bekerja, itu tidak terlihat. Ini sangat penting untuk masalah. Fakapa tidak terjadi setiap hari, dan masalah sekecil itu membutuhkan upaya yang sangat serius untuk menyelesaikannya.
- Anda harus banyak berpikir. Sangat sering, admin - orang yang mengatur keseimbangan - tidak dapat secara mandiri menyelesaikan masalah ini. Selanjutnya kita akan lihat alasannya.
- Ini menangkap level yang mendasarinya. Tugas ini sangat terkait erat dengan pengembangan, dengan adopsi keputusan yang memengaruhi produk dan pengguna Anda.
Saya menegaskan bahwa inilah saatnya untuk melakukan tugas ini karena beberapa alasan:- Dunia berubah, menjadi lebih dinamis, ada banyak rilis. Mereka mengatakan bahwa sekarang sudah benar untuk melepaskan 100 kali sehari, dan rilis adalah fakap masa depan dengan probabilitas 50 hingga 50 (sama seperti kemungkinan bertemu dinosaurus)
- Dari sudut pandang teknologi, semuanya juga sangat dinamis. Kubernet dan orkestra lainnya muncul. Tidak ada penerapan lama yang baik, ketika satu backend pada beberapa IP dimatikan, pembaruan digulir, dan layanan naik. Sekarang dalam proses peluncuran di k8s daftar IP upstream benar-benar berubah.
- Layanan Mikro: sekarang semua orang berkomunikasi melalui jaringan, yang berarti Anda harus melakukan ini dengan andal. Keseimbangan memainkan peran penting.
Test stand
Mari kita mulai dengan kasus yang sederhana dan jelas. Untuk kejelasan, saya akan menggunakan bangku tes. Ini adalah aplikasi Golang yang memberikan http-200, atau Anda dapat mengubahnya ke mode "beri http-503".
Kami memulai 3 contoh:
- 127.0.0.1.10001
- 127.0.0.1.10002
- 127.0.0.1.10003
Kami melayani 100rps melalui yandex.tank via nginx.
Nginx di luar kotak:
upstream backends { server 127.0.0.1:20001; server 127.0.0.1:20002; server 127.0.0.1:20003; } server { listen 127.0.0.1:30000; location / { proxy_pass http://backends; } }
Skenario primitif
Pada titik tertentu, nyalakan salah satu backend dalam mode beri 503, dan kami mendapatkan tepat sepertiga dari kesalahan.
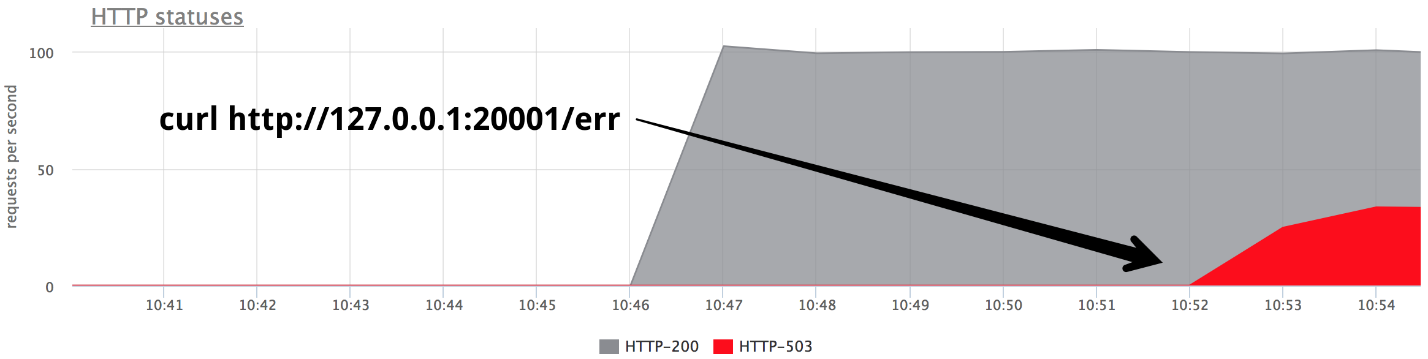
Jelas bahwa tidak ada yang berfungsi di luar kotak: nginx tidak mencoba kembali dari kotak jika menerima
respons dari server.
Nginx default: proxy_next_upstream error timeout;
Sebenarnya, ini cukup logis dari sisi pengembang nginx: nginx tidak memiliki hak untuk memutuskan untuk Anda apa yang ingin Anda retray dan yang tidak.
Karena itu, kita perlu mencoba lagi - coba lagi, dan kita mulai membicarakannya.
Coba lagi
Penting untuk menemukan kompromi antara:
- Permintaan pengguna itu suci, terluka, tetapi jawab. Kami ingin menjawab pengguna di semua biaya, pengguna adalah yang paling penting.
- Lebih baik menjawab dengan kesalahan daripada membebani server.
- Integritas data (untuk permintaan non-idempoten), yaitu mustahil untuk mengulangi jenis permintaan tertentu.
Kebenaran, seperti biasa, ada di suatu tempat antara - kita dipaksa untuk menyeimbangkan antara tiga poin ini. Mari kita coba memahami apa dan bagaimana.
Saya membagi upaya yang gagal menjadi 3 kategori:
1.
Kesalahan transportasiUntuk transport HTTP adalah TCP, dan sebagai aturan, di sini kita berbicara tentang kesalahan pengaturan koneksi dan batas waktu pengaturan koneksi. Dalam laporan saya, saya akan menyebutkan 3 penyeimbang umum (kami akan berbicara tentang Utusan sedikit lebih jauh):
- nginx : kesalahan + batas waktu (proxy_connect_timeout);
- HAProxy : batas waktu koneksi;
- Utusan : koneksi-kegagalan + aliran ditolak.
Nginx memiliki kesempatan untuk mengatakan bahwa upaya yang gagal adalah kesalahan koneksi dan batas waktu koneksi; HAProxy memiliki batas waktu koneksi, Utusan juga memiliki semuanya standar dan normal.
2.
Batas waktu permintaan:Misalkan kita mengirim permintaan ke server, berhasil terkoneksi ke sana, tetapi jawabannya tidak datang kepada kita, kita menunggu dan kita mengerti bahwa tidak ada gunanya menunggu lagi. Ini disebut batas waktu permintaan:
- Nginx memiliki: batas waktu (prox_send_timeout * + proxy_read_timeout *);
- HAProxy memiliki OOPS :( - pada prinsipnya tidak ada. Banyak orang tidak tahu bahwa HAProxy, jika telah berhasil membuat koneksi, tidak akan pernah mencoba mengirim ulang permintaan.
- Utusan dapat melakukan segalanya: batas waktu || per_try_timeout.
3.
status HTTPSemua penyeimbang, kecuali untuk HAProxy, dapat memproses, jika bagaimanapun backend menjawab Anda, tetapi dengan semacam kode yang salah.
- nginx : http_ *
- HAProxy : OOPS :(
- Utusan : 5xx, gateway-error (502, 503, 504), retriable-4xx (409)
Batas waktu
Sekarang mari kita bicara secara rinci tentang batas waktu, bagi saya tampaknya perlu memperhatikan hal ini. Tidak akan ada lagi ilmu roket - ini hanya informasi terstruktur tentang apa yang umumnya terjadi dan bagaimana kaitannya dengannya.
Hubungkan batas waktu
Connect timeout adalah waktu untuk membuat koneksi. Ini adalah karakteristik jaringan Anda dan server spesifik Anda, dan tidak tergantung pada permintaan. Biasanya, nilai default untuk koneksi habis diatur ke kecil. Di semua proxy, nilai default cukup besar, dan ini salah - itu harus
unit, terkadang puluhan milidetik (jika kita berbicara tentang jaringan dalam satu DC).
Jika Anda ingin mengidentifikasi server bermasalah sedikit lebih cepat dari unit-puluhan milidetik ini, Anda dapat menyesuaikan beban di backend dengan mengatur backlog kecil untuk menerima koneksi TCP. Dalam hal ini, Anda dapat, ketika jaminan simpanan aplikasi sudah penuh, suruh Linux untuk mengatur ulang untuk melimpahkan jaminan simpanan. Maka Anda akan dapat menembak backend "buruk" kelebihan beban sedikit lebih awal dari batas waktu koneksi:
fail fast: listen backlog + net.ipv4.tcp_abort_on_overflow
Permintaan batas waktu
Batas waktu permintaan bukanlah karakteristik jaringan, tetapi
karakteristik sekelompok permintaan (penangan). Ada permintaan yang berbeda - mereka berbeda dalam keparahan, mereka memiliki logika yang sangat berbeda di dalam, mereka perlu mengakses repositori yang sama sekali berbeda.
Nginx sendiri
tidak memiliki batas waktu untuk seluruh permintaan. Dia memiliki:
- proxy_send_timeout: waktu antara dua operasi tulis yang berhasil tulis ();
- proxy_read_timeout: waktu antara dua bacaan berhasil dibaca ().
Artinya, jika Anda memiliki backend perlahan, satu byte kali, memberikan sesuatu dalam batas waktu, maka semuanya baik-baik saja. Karena itu, nginx tidak memiliki request_timeout. Tetapi kita berbicara tentang hulu. Di pusat data kami, mereka dikendalikan oleh kami, oleh karena itu, dengan asumsi bahwa jaringan tidak memiliki kukang, maka, pada prinsipnya, read_timeout dapat digunakan sebagai request_timeout.
Utusan memiliki semuanya: batas waktu || per_try_timeout.
Pilih batas waktu permintaan
Sekarang hal yang paling penting, menurut saya, adalah request_timeout yang akan dimasukkan. Kami melanjutkan dari berapa lama yang diizinkan bagi pengguna untuk menunggu - ini adalah maksimum tertentu. Jelas bahwa pengguna tidak akan menunggu lebih dari 10 detik, jadi Anda harus menjawabnya lebih cepat.
- Jika kami ingin menangani kegagalan satu server tunggal, maka batas waktu harus kurang dari batas waktu maksimum yang diizinkan: request_timeout <maks.
- Jika Anda ingin memiliki 2 upaya yang dijamin untuk mengirim permintaan ke dua backend yang berbeda, maka batas waktu untuk satu upaya sama dengan setengah dari interval yang diperbolehkan ini: per_try_timeout = 0,5 * maks.
- Ada juga opsi perantara - 2 upaya optimis jika backend pertama telah "tumpul", tetapi yang kedua akan merespons dengan cepat: per_try_timeout = k * max (di mana k> 0,5).
Ada beberapa pendekatan berbeda, tetapi secara umum,
memilih batas waktu itu sulit . Akan selalu ada kasus batas, misalnya, penangan yang sama dalam 99% kasus diproses dalam 10 ms, tetapi ada 1% kasus ketika kita menunggu 500 ms, dan ini normal. Ini harus diselesaikan.
Dengan 1% ini, sesuatu perlu dilakukan, karena seluruh grup permintaan harus, misalnya, mematuhi SLA dan memenuhi 100 ms. Sangat sering pada saat-saat ini aplikasi diproses:
- Paging muncul di tempat-tempat di mana tidak mungkin untuk mengembalikan semua data dalam batas waktu.
- Admin / laporan dipisahkan menjadi grup url terpisah untuk meningkatkan batas waktu untuknya, dan ya untuk menurunkan permintaan pengguna.
- Kami memperbaiki / mengoptimalkan permintaan yang tidak sesuai dengan batas waktu kami.
Segera, kita perlu mengambil keputusan yang tidak terlalu sederhana dari sudut pandang psikologis bahwa jika kita tidak punya waktu untuk menjawab pengguna dalam waktu yang ditentukan, kita memberikan kesalahan (ini seperti dalam pepatah Tiongkok kuno: "Jika kuda mati, turun!")
.Setelah itu, proses pemantauan layanan Anda dari sudut pandang pengguna disederhanakan:
- Jika ada kesalahan, semuanya buruk, itu perlu diperbaiki.
- Jika tidak ada kesalahan, kami masuk ke dalam waktu respon yang tepat, maka semuanya baik-baik saja.
Coba lagi secara spekulatif # nifig
Kami memastikan bahwa memilih nilai batas waktu cukup sulit. Seperti yang Anda tahu, untuk menyederhanakan sesuatu, Anda perlu menyulitkan sesuatu :)
Retray spekulatif - permintaan berulang ke server lain, yang diluncurkan oleh beberapa kondisi, tetapi permintaan pertama tidak terganggu. Kami mengambil jawaban dari server yang menjawab lebih cepat.
Saya tidak melihat fitur ini dalam balancers yang saya kenal, tetapi ada contoh yang bagus dengan Cassandra (perlindungan baca cepat):
speculative_retry = N ms |
Persentil ke -3Dengan cara ini Anda
tidak perlu istirahat . Anda dapat membiarkannya pada tingkat yang dapat diterima dan dalam kasus apa pun memiliki upaya kedua untuk mendapatkan respons terhadap permintaan tersebut.
Cassandra memiliki peluang menarik untuk menetapkan spekulatif_retri statis atau dinamis, maka upaya kedua akan dilakukan melalui persentil waktu respons. Cassandra mengumpulkan statistik pada waktu respons dari permintaan sebelumnya dan menyesuaikan nilai batas waktu tertentu. Ini bekerja dengan cukup baik.
Dalam pendekatan ini, semuanya bertumpu pada keseimbangan antara keandalan dan beban palsu. Bukan server. Anda memberikan keandalan, tetapi kadang-kadang Anda mendapatkan permintaan tambahan ke server. Jika Anda terburu-buru di suatu tempat dan mengirim permintaan kedua, tetapi yang pertama masih menjawab, server menerima sedikit lebih banyak beban. Dalam satu kasus, ini adalah masalah kecil.

Konsistensi batas waktu adalah aspek penting lainnya. Kami akan berbicara lebih banyak tentang pembatalan permintaan, tetapi secara umum, jika batas waktu untuk seluruh permintaan pengguna adalah 100 ms, maka tidak masuk akal untuk menetapkan batas waktu untuk permintaan dalam basis data selama 1 detik. Ada sistem yang memungkinkan Anda melakukan ini secara dinamis: layanan ke layanan mentransfer sisa waktu yang Anda tunggu jawaban untuk permintaan ini. Ini rumit, tetapi jika Anda tiba-tiba membutuhkannya, Anda dapat dengan mudah menemukan cara melakukannya di Utusan yang sama.
Apa lagi yang perlu Anda ketahui tentang coba lagi?
Point of no return (V1)
Di sini V1 bukan versi 1. Dalam penerbangan ada konsep seperti itu - kecepatan V1. Ini adalah kecepatan setelah itu tidak mungkin untuk memperlambat akselerasi di landasan. Hal ini diperlukan untuk lepas landas, dan kemudian membuat keputusan tentang apa yang harus dilakukan selanjutnya.
Titik tanpa pengembalian yang sama ada di penyeimbang beban:
ketika Anda melewatkan 1 byte respons ke klien Anda, tidak ada kesalahan yang bisa diperbaiki . Jika backend mati pada saat ini, tidak ada percobaan ulang akan membantu. Anda hanya dapat mengurangi kemungkinan skenario seperti itu dipicu, melakukan shutdown anggun, yaitu, memberi tahu aplikasi Anda: "Anda tidak menerima permintaan baru sekarang, tetapi memodifikasi yang lama!", Dan hanya kemudian memadamkannya.
Jika Anda mengontrol klien, ini adalah Ajax atau aplikasi seluler yang rumit, mungkin mencoba mengulangi permintaan, dan kemudian Anda dapat keluar dari situasi ini.
Point of No Return [Utusan]
Utusan punya trik aneh. Ada per_try_timeout - membatasi berapa banyak upaya untuk mendapatkan respons terhadap permintaan. Jika batas waktu ini berhasil, tetapi backend sudah mulai merespons ke klien, maka semuanya terputus, klien menerima kesalahan.
Rekan saya Pavel Trukhanov (
tru_pablo ) membuat
tambalan , yang sudah ada di master Utvoy dan akan berada di 1.7. Sekarang berfungsi sebagaimana mestinya: jika respons sudah mulai dikirim, hanya batas waktu global yang akan bekerja.
Coba lagi: perlu dibatasi
Retries itu bagus, tetapi ada yang disebut permintaan killer: queri berat yang banyak melakukan logika mengakses database dan sering tidak cocok dengan per_try_timeout. Jika kami mengirim coba lagi dan lagi, maka kami membunuh basis kami. Karena
di sebagian besar (99,9%) layanan basis data tidak ada permintaan pembatalan .
Pembatalan permintaan berarti bahwa klien telah melepaskan ikatan, Anda harus menghentikan semua pekerjaan sekarang. Golang aktif mempromosikan pendekatan ini, tetapi sayangnya berakhir dengan backend, dan banyak repositori database tidak mendukung ini.
Karena itu, coba ulang harus dibatasi, yang memungkinkan hampir semua penyeimbang (kami berhenti mempertimbangkan HAProxy mulai sekarang).
Nginx:- proxy_next_upstream_timeout (global)
- proxt_read_timeout ** sebagai per_try_timeout
- proxy_next_upstream_tries
Utusan:- batas waktu (global)
- per_try_timeout
- num_retries
Dalam Nginx, kita dapat mengatakan bahwa kita mencoba melakukan percobaan ulang melalui jendela X, yaitu, pada interval waktu tertentu, misalnya, 500 ms, kita melakukan percobaan sebanyak yang sesuai. Atau ada pengaturan yang membatasi jumlah sampel yang diulang. Dalam
Utusan , hal yang sama adalah kuantitas atau batas waktu (global).
Coba lagi: terapkan [nginx]
Pertimbangkan contoh: kami menetapkan upaya coba lagi di nginx 2 - karena itu, setelah menerima HTTP 503, kami mencoba mengirim permintaan ke server lagi. Lalu matikan
kedua backend.
upstream backends { server 127.0.0.1:20001; server 127.0.0.1:20002; server 127.0.0.1:20003; } server { listen 127.0.0.1:30000; proxy_next_upstream error timeout http_503; proxy_next_upstream_tries 2; location / { proxy_pass http://backends; } }
Di bawah ini adalah grafik dari bangku tes kami. Tidak ada kesalahan pada grafik atas, karena sangat sedikit dari mereka. Jika Anda hanya meninggalkan kesalahan, jelas itu salah.
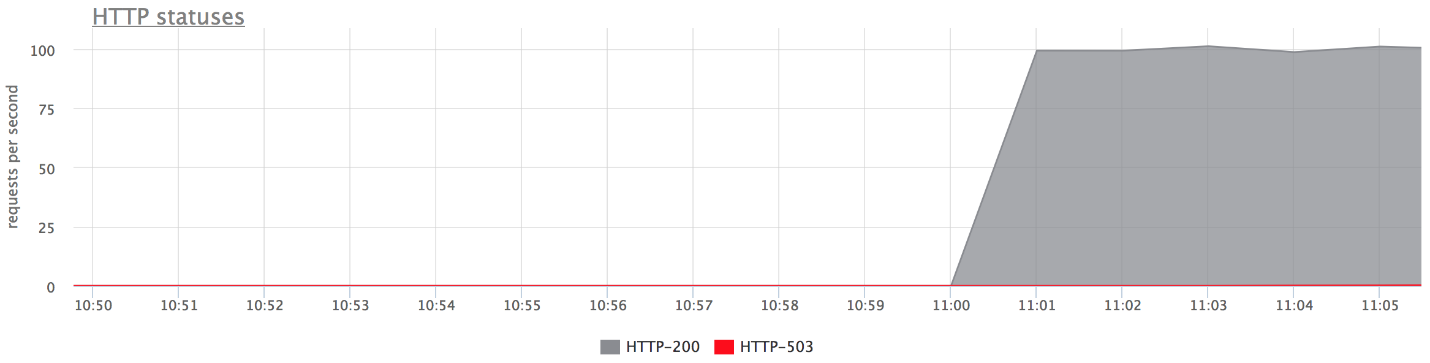
 Apa yang terjadi
Apa yang terjadi- proxy_next_upstream_tries = 2.
- Dalam kasus ketika Anda melakukan upaya pertama ke server "mati", dan yang kedua - ke "mati" lainnya, Anda mendapatkan HTTP-503 jika kedua upaya tersebut dilakukan ke server "buruk".
- Ada beberapa kesalahan, karena nginx "mencekal" server yang buruk. Artinya, jika dalam nginx beberapa kesalahan telah kembali dari backend, berhenti membuat upaya berikut untuk mengirim permintaan ke sana. Ini diatur oleh variabel fail_timeout.
Tetapi ada kesalahan, dan ini tidak cocok untuk kita.
Apa yang harus dilakukan?Kita dapat meningkatkan jumlah percobaan ulang (tapi kemudian kembali ke masalah "permintaan pembunuh"), atau kita dapat mengurangi kemungkinan permintaan menjadi backend "mati". Ini dapat dilakukan dengan
pemeriksaan kesehatan.Pemeriksaan kesehatan
Saya sarankan mempertimbangkan pemeriksaan kesehatan sebagai optimisasi proses pemilihan server "langsung".
Ini sama sekali tidak memberikan jaminan apa pun. Oleh karena itu, selama eksekusi permintaan pengguna, kami lebih cenderung mendapatkan hanya server "langsung". Penyeimbang secara teratur mengakses URL tertentu, server menjawabnya: "Saya hidup dan siap."
Pemeriksaan kesehatan: dalam hal backend
Dari sudut pandang backend, Anda dapat melakukan hal-hal menarik:
- Periksa kesiapan untuk operasi semua subsistem yang mendasari di mana operasi backend tergantung: jumlah koneksi yang diperlukan ke database dibuat, kumpulan memiliki koneksi gratis, dll, dll.
- Anda dapat menggantung logika Anda sendiri di URL pemeriksaan kesehatan jika penyeimbang yang digunakan tidak terlalu cerdas (misalnya, Anda mengambil Load Balancer dari host). Server dapat mengingat bahwa "pada menit terakhir saya memberikan begitu banyak kesalahan - saya mungkin semacam server" salah ", dan untuk 2 menit berikutnya saya akan merespons dengan" lima ratus "untuk pemeriksaan Kesehatan. Dengan demikian saya akan melarang diri saya sendiri! " Ini terkadang sangat membantu ketika Anda memiliki Load Balancer yang tidak terkontrol.
- Biasanya, interval pemeriksaan sekitar satu detik, dan Anda memerlukan penangan pemeriksaan Kesehatan untuk tidak membunuh server Anda. Itu harus ringan.
Pemeriksaan kesehatan: implementasi
Secara umum, semua yang ada di sini adalah sama untuk semua orang:
- Minta;
- Batas waktu di atasnya;
- Interval di mana kami melakukan pengecekan. Proxy tertipu memiliki jitter , yaitu, beberapa pengacakan sehingga semua cek kesehatan tidak datang ke backend sekaligus, dan jangan membunuhnya.
- Ambang tidak sehat - ambang berapa banyak pemeriksaan Kesehatan yang gagal harus dilewati agar layanan dapat menandainya sebagai Tidak Sehat.
- Ambang batas yang sehat - sebaliknya, berapa banyak upaya yang berhasil harus dilewati agar server kembali beroperasi.
- Logika tambahan. Anda dapat menguraikan Periksa status + tubuh, dll.
Nginx mengimplementasikan fungsi pemeriksaan kesehatan hanya dalam versi berbayar dari nginx +.
Saya perhatikan fitur
Utusan , ia memiliki
mode panik pemeriksaan Kesehatan
. Ketika kami mencekal, sebagai "tidak sehat", lebih dari N% host (katakanlah 70%), ia percaya bahwa semua cek Kesehatan kami bohong, dan semua host sebenarnya hidup. Dalam kasus yang sangat buruk, ini akan membantu Anda tidak mengalami situasi di mana Anda sendiri menembak kaki Anda dan melarang semua server. Ini cara aman lagi.
Menyatukan semuanya
Biasanya untuk pemeriksaan Kesehatan ditetapkan:
- Atau nginx +;
- Atau nginx + sesuatu yang lain :)
Di negara kami, ada kecenderungan untuk mengatur nginx + HAProxy, karena versi gratis nginx tidak memiliki pemeriksaan kesehatan, dan hingga 1.11.5 tidak ada batasan jumlah koneksi ke backend. Tetapi opsi ini buruk karena HAProxy tidak tahu bagaimana cara pensiun setelah membuat koneksi. Banyak orang berpikir bahwa jika HAProxy mengembalikan kesalahan pada nginx dan nginx retries, maka semuanya akan baik-baik saja. Tidak juga. Anda bisa mendapatkan HAProxy lain dan backend yang sama, karena pool backend sama. Jadi, Anda memperkenalkan satu tingkat abstraksi lagi untuk diri Anda sendiri, yang mengurangi keakuratan penyeimbangan Anda dan, dengan demikian, ketersediaan layanan.
Kami memiliki nginx + Utusan, tetapi jika Anda bingung, Anda dapat membatasi diri hanya untuk Utusan.
Utusan macam apa?
Utusan adalah penyeimbang beban pemuda yang trendi, awalnya dikembangkan di Lyft, ditulis dalam C ++.
Di luar kotak ia dapat melakukan banyak roti pada topik kita hari ini. Anda mungkin melihatnya sebagai Service Mesh untuk Kubernetes. Sebagai aturan, Utusan bertindak sebagai bidang data, yaitu secara langsung menyeimbangkan lalu lintas, dan ada juga bidang kontrol yang memberikan informasi tentang apa yang Anda butuhkan untuk mendistribusikan beban di antara (penemuan layanan, dll.).
Aku akan memberitahumu beberapa kata tentang roti nya.
Untuk meningkatkan kemungkinan respons coba lagi yang berhasil saat berikutnya Anda mencoba, Anda dapat tidur sedikit dan menunggu backend kembali ke akal sehatnya. Dengan cara ini kita akan menangani masalah basis data pendek. Utusan memiliki
backoff untuk retries - jeda antara retries. Selain itu, interval penundaan antara upaya meningkat secara eksponensial. Percobaan pertama terjadi setelah 0-24 ms, yang kedua setelah 0-74 ms, dan kemudian untuk setiap upaya berikutnya interval meningkat, dan penundaan spesifik dipilih secara acak dari interval ini.
Pendekatan kedua tidak khusus Utusan, tetapi pola yang disebut
Circuit breaking (lit. circuit breaker atau fuse). Ketika backend kita tumpul, sebenarnya kita berusaha menyelesaikannya setiap saat. Ini karena pengguna dalam situasi apa pun yang tidak dapat dipahami mengeklik laman refresh-at, mengirimkan lebih banyak permintaan baru kepada Anda. Penyeimbang Anda menjadi gugup, mengirim percobaan ulang, jumlah permintaan meningkat - beban bertambah, dan dalam situasi ini alangkah baiknya untuk tidak mengirim permintaan.
Pemutus sirkuit hanya memungkinkan Anda untuk menentukan bahwa kami berada dalam keadaan ini, dengan cepat menembak kesalahan dan memberikan backend "tenangkan napas."
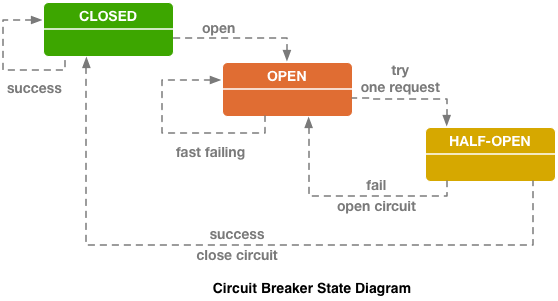 Circuit breaker (hystrix like libs), asli di blog ebay.
Circuit breaker (hystrix like libs), asli di blog ebay.Di atas adalah sirkuit pemutus sirkuit Hystrix. Hystrix adalah perpustakaan Java Netflix yang dirancang untuk menerapkan pola toleransi kesalahan.
- "Sekering" bisa dalam keadaan "tertutup" ketika semua permintaan dikirim ke backend dan tidak ada kesalahan.
- Ketika ambang gagal tertentu dipicu, yaitu, beberapa kesalahan telah terjadi, pemutus sirkuit masuk ke status "Buka". Dengan cepat mengembalikan kesalahan ke klien, dan permintaan tidak sampai ke backend.
- Sekali dalam periode waktu tertentu, sebagian kecil dari permintaan dikirim ke backend. Jika kesalahan dipicu, statusnya tetap "Terbuka". Jika semuanya mulai bekerja dengan baik dan merespons, "sekering" menutup dan bekerja berlanjut.
Dalam Utusan, dengan demikian, ini tidak semua. Ada batas tingkat atas pada kenyataan bahwa tidak boleh ada lebih dari N permintaan untuk kelompok hulu tertentu. Jika lebih, ada sesuatu yang salah di sini - kami mengembalikan kesalahan. Tidak boleh ada lagi N percobaan ulang aktif (mis. Percobaan ulang yang sedang terjadi saat ini).
Anda tidak memiliki percobaan ulang, sesuatu yang meledak - kirim percobaan lagi. Utusan memahami bahwa lebih dari N tidak normal, dan semua permintaan harus ditembak dengan kesalahan.
Pemutus Sirkuit [Utusan]- Koneksi maks Cluster (upstream group)
- Permintaan cluster tertunda maks
- Permintaan kluster maks
- Cluster max percobaan aktif
Hal sederhana ini berfungsi dengan baik, dapat dikonfigurasi, Anda tidak perlu membuat parameter khusus, dan pengaturan defaultnya cukup bagus.
Pemutus sirkuit: pengalaman kami
Kami dulu memiliki pengumpul metrik HTTP, yaitu agen yang dipasang di server klien kami mengirim metrik ke cloud kami melalui HTTP. Jika kami memiliki masalah dalam infrastruktur, agen menulis metrik ke disk-nya dan kemudian mencoba mengirimkannya kepada kami.
Dan agen terus-menerus berupaya mengirim data kepada kami, mereka tidak kesal bahwa kami entah bagaimana merespons secara salah, dan tidak pergi.
( , ) , , .
nginx limit req. , , , 200 RPS. , , , limit req.
TCP HTTP ( nginx limit req). . limit req .
, , .
Circuit breaker, , N , , - , , . , , spool .
Circuit breaker + request cancellation ( ). , N Cassandra, N Elastic, , — , . — , .
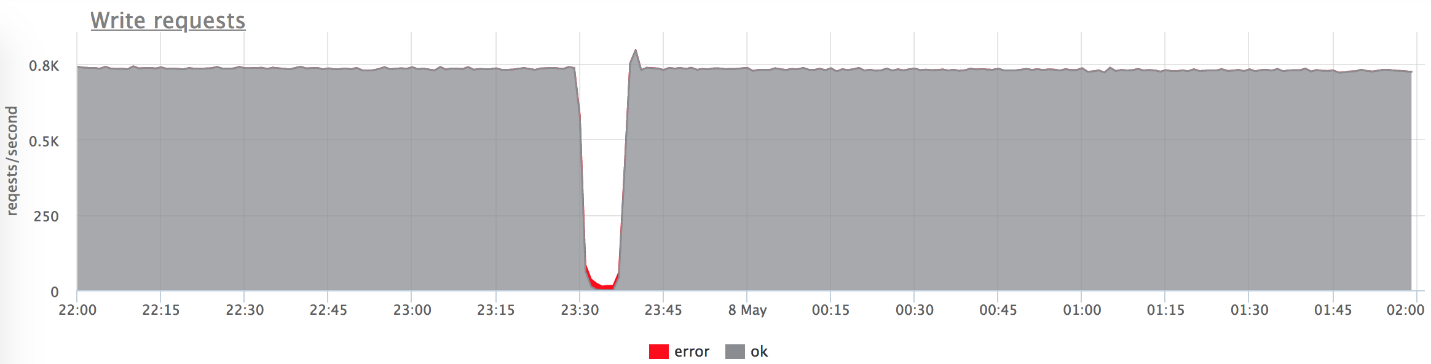
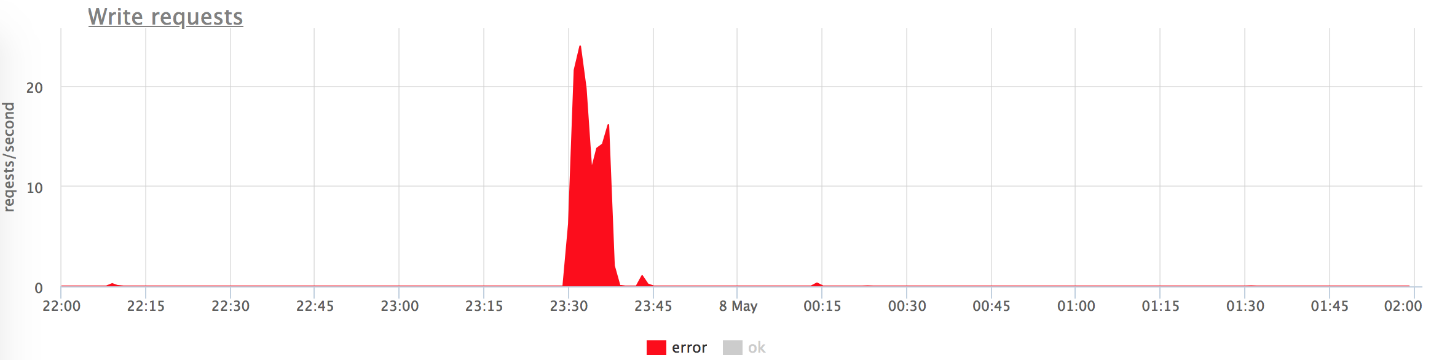
, (: — «», — «»). , 800 RPS 20-30. «», , .
— , .
, , — . .
, , , , Health checks — HTTP 200.
.
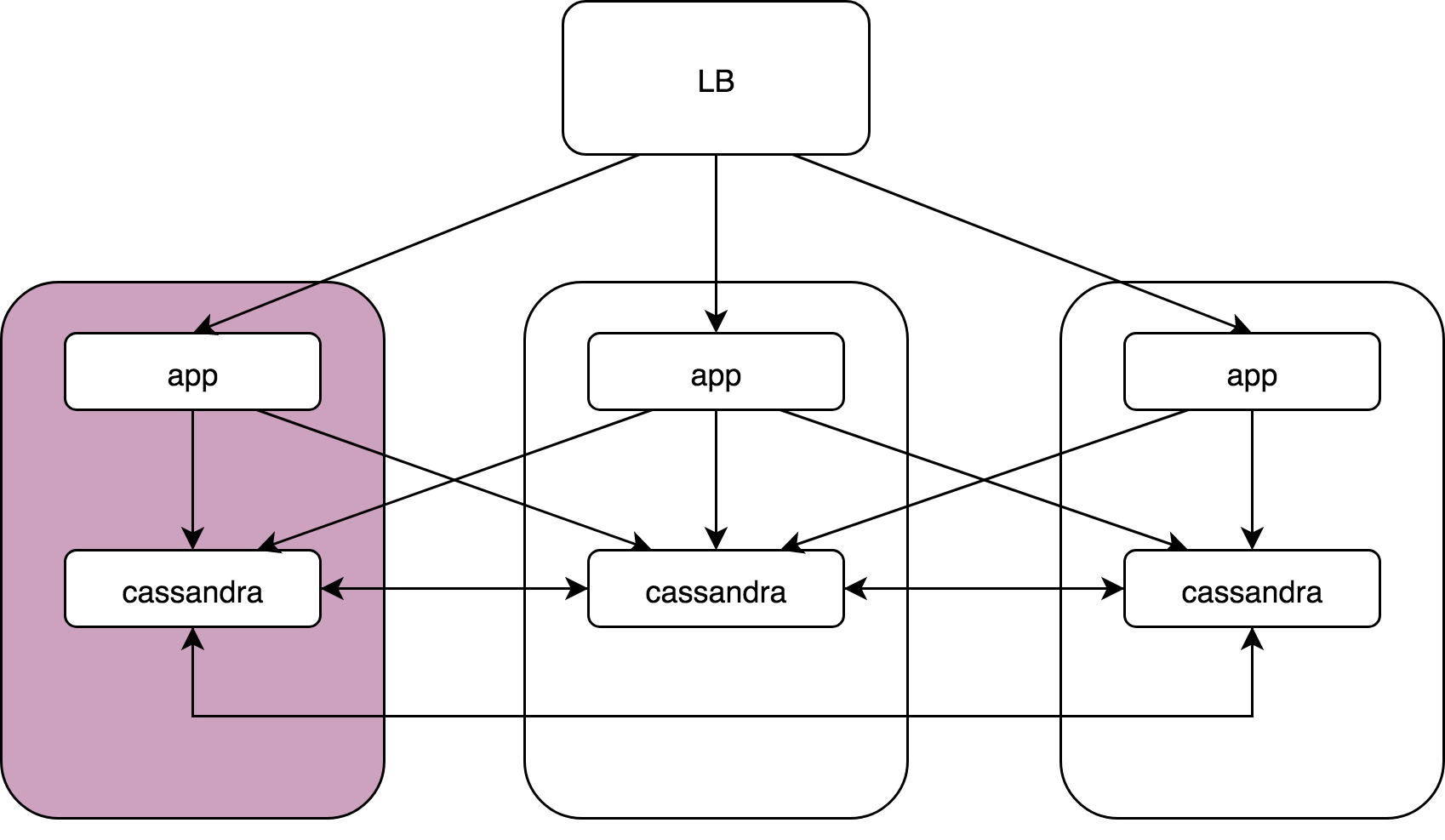
Load Balancer, 3 , Cassandra. Cassandra, Cassandra , Cassandra data noda.
— :
kernel: NETDEV WATCHDOG: eth0 (ixgbe): transmit queue 3 timed out.: ( ), 64 . , 1/64 . reboot, .
, , , . , , , . , , . , .
Cassandra: coordinator -> nodesCassandra, (speculative retries), . latency 99 , .
App -> cassandra coordinator. Cassandra «» , , , latency ..
gocql — cassandra client. . HostSelectionPolicy,
bitly/go-hostpool . Epsilon greedy , .
,
Epsilon-greedy .
(multi-armed bandit): , , N .
:
- « explore» — : 10 , , .
- « exploit» — .
, (10 — 30%)
round -
robin , , , . 70 — 90% .
Host-pool . . ( — , , ). . , , , .
«» () —Cassandra Cassandra coordinator-data. (nginx, Envoy — ) «» Application, Cassandra , , .
Envoy
Outlier detection :
- Consecutive http-5xx.
- Consecutive gateway errors (502,503,504).
- Success rate.
«» , - , . , . — , , . , , .
, «», max_ejection_percent. , outlier, . , 70% — , — , !
, — !
, , . , latency , :
,
, . , , , — , .
. 99% nginx/
HAProxy /Envoy. proxy , «».
proxy ( HAProxy:)),
, .DevOpsConf Russia Kubernetes . .
, — DevOps.
, , YouTube- — .