System.IO.Pipelines adalah perpustakaan baru yang menyederhanakan organisasi kode di .NET. Sulit untuk memastikan kinerja dan akurasi tinggi jika Anda harus berurusan dengan kode yang rumit. Tugas System.IO.Pipelines adalah menyederhanakan kode. Lebih detail di bawah cut!

Perpustakaan muncul sebagai hasil dari upaya tim pengembangan .NET Core untuk menjadikan Kestrel salah satu
server web tercepat di industri . Awalnya dirancang sebagai bagian dari implementasi Kestrel, tetapi telah berkembang menjadi API yang dapat digunakan kembali, tersedia dalam versi 2.1 sebagai API BCL kelas pertama (System.IO.Pipelines).
Masalah apa yang dia pecahkan?
Untuk menganalisis data dengan benar dari aliran atau soket, Anda perlu menulis sejumlah besar kode standar. Pada saat yang sama, ada banyak jebakan yang menyulitkan kode itu sendiri dan dukungannya.
Kesulitan apa yang muncul hari ini?
Mari kita mulai dengan tugas sederhana. Kita perlu menulis server TCP yang menerima pesan yang dibatasi baris (\ n) dari klien.
TCP Server dengan NetworkStream
DEVIASI: seperti dalam tugas apa pun yang membutuhkan kinerja tinggi, setiap kasus spesifik harus dipertimbangkan berdasarkan fitur aplikasi Anda. Mungkin tidak masuk akal untuk menghabiskan sumber daya pada penggunaan berbagai pendekatan, yang akan dibahas nanti, jika skala aplikasi jaringan tidak terlalu besar.
Kode .NET biasa sebelum menggunakan jaringan pipa terlihat seperti ini:
async Task ProcessLinesAsync(NetworkStream stream) { var buffer = new byte[1024]; await stream.ReadAsync(buffer, 0, buffer.Length);
lihat
sample1.cs di
githubKode ini mungkin akan bekerja dengan pengujian lokal, tetapi memiliki sejumlah kesalahan:
- Mungkin setelah satu panggilan ke ReadAsync, seluruh pesan tidak akan diterima (sampai akhir baris).
- Ini mengabaikan hasil dari metode stream.ReadAsync () - jumlah data yang sebenarnya ditransfer ke buffer.
- Kode tidak menangani menerima beberapa baris dalam satu panggilan ReadAsync.
Ini adalah kesalahan pembacaan data streaming yang paling umum. Untuk menghindarinya, Anda perlu melakukan sejumlah perubahan:
- Anda perlu melakukan buffer data yang masuk sampai baris baru ditemukan.
- Penting untuk menganalisis semua baris yang dikembalikan ke buffer.
async Task ProcessLinesAsync(NetworkStream stream) { var buffer = new byte[1024]; var bytesBuffered = 0; var bytesConsumed = 0; while (true) { var bytesRead = await stream.ReadAsync(buffer, bytesBuffered, buffer.Length - bytesBuffered); if (bytesRead == 0) {
lihat
sample2.cs di
githubSaya ulangi: ini bisa bekerja dengan pengujian lokal, tetapi kadang-kadang ada string yang lebih panjang dari 1 Kb (1024 byte). Penting untuk meningkatkan ukuran buffer input hingga baris baru ditemukan.
Selain itu, kami mengumpulkan buffer ke dalam array saat memproses string panjang. Kami dapat meningkatkan proses ini dengan ArrayPool, yang menghindari alokasi ulang buffer selama analisis garis panjang dari klien.
async Task ProcessLinesAsync(NetworkStream stream) { byte[] buffer = ArrayPool<byte>.Shared.Rent(1024); var bytesBuffered = 0; var bytesConsumed = 0; while (true) {
lihat sample3.cs di githubKode berfungsi, tetapi sekarang ukuran buffer telah berubah, sebagai akibatnya, banyak salinannya muncul. Lebih banyak memori juga digunakan, karena logika tidak mengurangi buffer setelah memproses baris. Untuk menghindari ini, Anda dapat menyimpan daftar buffer, daripada mengubah ukuran buffer setiap kali sebuah string datang lebih dari 1 Kb.
Selain itu, kami tidak menambah ukuran buffer 1 KB, sampai benar-benar kosong. Ini berarti bahwa kami akan mentransfer buffer yang lebih kecil dan lebih kecil ke ReadAsync, sebagai akibatnya, jumlah panggilan ke sistem operasi akan meningkat.
Kami akan mencoba menghilangkan ini dan akan mengalokasikan buffer baru segera setelah ukuran yang ada menjadi kurang dari 512 byte:
public class BufferSegment { public byte[] Buffer { get; set; } public int Count { get; set; } public int Remaining => Buffer.Length - Count; } async Task ProcessLinesAsync(NetworkStream stream) { const int minimumBufferSize = 512; var segments = new List<BufferSegment>(); var bytesConsumed = 0; var bytesConsumedBufferIndex = 0; var segment = new BufferSegment { Buffer = ArrayPool<byte>.Shared.Rent(1024) }; segments.Add(segment); while (true) {
lihat sample4.cs di githubAkibatnya, kode ini sangat rumit. Selama pencarian pembatas, kami melacak buffer yang diisi. Untuk melakukan ini, gunakan Daftar, yang menampilkan data buffer saat mencari pemisah baris baru. Akibatnya, ProcessLine dan IndexOf akan menerima Daftar alih-alih byte [], offset dan hitung. Logika parsing akan mulai memproses satu segmen buffer atau beberapa.
Dan sekarang server akan memproses sebagian pesan dan menggunakan memori bersama untuk mengurangi konsumsi memori secara keseluruhan. Namun, sejumlah perubahan perlu dilakukan:
- Dari ArrayPoolbyte kami hanya menggunakan Byte [] - array yang dikelola secara standar. Dengan kata lain, ketika fungsi ReadAsync atau WriteAsync dieksekusi, periode validitas buffer terikat dengan waktu operasi asinkron (untuk berinteraksi dengan API I / O sistem operasi sendiri). Karena memori yang disematkan tidak dapat dipindahkan, ini mempengaruhi kinerja pengumpul sampah dan dapat menyebabkan fragmentasi array. Anda mungkin perlu mengubah implementasi kumpulan, tergantung pada berapa lama operasi asinkron akan menunggu eksekusi.
- Throughput dapat ditingkatkan dengan memutus tautan antara logika baca dan proses. Kami mendapatkan efek pemrosesan batch, dan sekarang logika parsing akan dapat membaca sejumlah besar data, memproses blok buffer yang besar, daripada menganalisis setiap baris. Akibatnya, kode ini menjadi lebih rumit:
- Anda perlu membuat dua siklus yang bekerja secara independen satu sama lain. Yang pertama akan membaca data dari soket, dan yang kedua akan menganalisis buffer.
- Yang diperlukan adalah cara untuk memberi tahu logika parsing bahwa data menjadi tersedia.
- Penting juga untuk menentukan apa yang terjadi jika loop membaca data dari soket terlalu cepat. Kita perlu cara untuk menyesuaikan siklus baca jika logika parsing tidak mengikutinya. Ini biasanya disebut sebagai "kontrol aliran" atau "hambatan aliran."
- Kita harus memastikan bahwa data ditransmisikan dengan aman. Sekarang set buffer digunakan oleh siklus baca dan siklus parsing, mereka bekerja secara independen satu sama lain pada utas yang berbeda.
- Logika manajemen memori juga terlibat dalam dua bagian kode yang berbeda: meminjam data dari buffer pool, yang membaca data dari socket, dan kembali dari pool buffer, yang merupakan logika parsing.
- Seseorang harus sangat berhati-hati dengan mengembalikan buffer setelah mengeksekusi logika parsing. Jika tidak, ada kemungkinan bahwa kami akan mengembalikan buffer ke mana logika baca soket masih ditulis.
Kompleksitas mulai menembus atap (dan ini jauh dari semua kasus!). Untuk membuat jaringan berkinerja tinggi, Anda perlu menulis kode yang sangat kompleks.
Tujuan System.IO.Pipelines adalah untuk menyederhanakan prosedur ini.
Server TCP dan System.IO.Pipelines
Mari kita lihat bagaimana System.IO.Pipelines bekerja:
async Task ProcessLinesAsync(Socket socket) { var pipe = new Pipe(); Task writing = FillPipeAsync(socket, pipe.Writer); Task reading = ReadPipeAsync(pipe.Reader); return Task.WhenAll(reading, writing); } async Task FillPipeAsync(Socket socket, PipeWriter writer) { const int minimumBufferSize = 512; while (true) {
lihat sample5.cs di githubVersi pipelined dari pembaca baris kami memiliki dua loop:
- FillPipeAsync membaca dari soket dan menulis ke PipeWriter.
- ReadPipeAsync membaca dari PipeReader dan mem-parsing garis masuk.
Berbeda dengan contoh pertama, tidak ada buffer yang ditugaskan secara khusus. Ini adalah salah satu fungsi utama System.IO.Pipelines. Semua tugas manajemen buffer ditransfer ke implementasi PipeReader / PipeWriter.
Prosedur ini disederhanakan: kami menggunakan kode hanya untuk logika bisnis, alih-alih menerapkan manajemen buffer yang kompleks.
Pada loop pertama, PipeWriter.GetMemory (int) pertama kali dipanggil untuk mendapatkan sejumlah memori dari penulis utama. Kemudian PipeWriter.Advance (int) dipanggil, yang memberitahu PipeWriter berapa banyak data yang sebenarnya ditulis ke buffer. Ini diikuti oleh panggilan ke PipeWriter.FlushAsync () sehingga PipeReader dapat mengakses data.
Loop kedua mengkonsumsi buffer yang ditulis oleh PipeWriter tetapi awalnya diterima dari soket. Ketika permintaan dikembalikan ke PipeReader.ReadAsync (), kita mendapatkan ReadResult yang berisi dua pesan penting: data membaca dalam bentuk ReadOnlySequence, serta tipe data logis IsCompleted, yang memberi tahu pembaca apakah penulis telah selesai bekerja (EOF). Ketika line terminator (EOL) ditemukan dan string diuraikan, kami akan membagi buffer menjadi bagian-bagian untuk melewati fragmen yang telah diproses. Setelah itu, PipeReader.AdvanceTo dipanggil dan ia memberi tahu PipeReader berapa banyak data yang telah dikonsumsi.
Pada akhir setiap siklus, pembaca dan penulis selesai. Akibatnya, saluran utama melepaskan semua memori yang dialokasikan.
System.io.pipelines
Membaca sebagian
Selain mengelola memori, System.IO.Pipelines melakukan fungsi penting lainnya: memindai data di saluran, tetapi tidak mengkonsumsinya.
PipeReader memiliki dua API utama: ReadAsync dan AdvanceTo. ReadAsync menerima data dari saluran, AdvanceTo memberi tahu PipeReader bahwa buffer ini tidak lagi diperlukan oleh pembaca, sehingga Anda dapat membuangnya (misalnya, mengembalikannya ke kumpulan buffer utama).
Berikut ini adalah contoh penganalisis HTTP yang membaca data dari buffer data saluran sebagian hingga menerima garis awal yang sesuai.

BacaHanya KesetaraanT
Implementasi saluran menyimpan daftar buffer terkait yang dilewati antara PipeWriter dan PipeReader. PipeReader.ReadAsync mengekspos ReadOnlySequence, yang merupakan tipe baru BCL dan terdiri dari satu atau lebih segmen ReadOnlyMemory <T>. Ini mirip dengan Rentang atau Memori, yang memberi kita kesempatan untuk melihat array dan string.
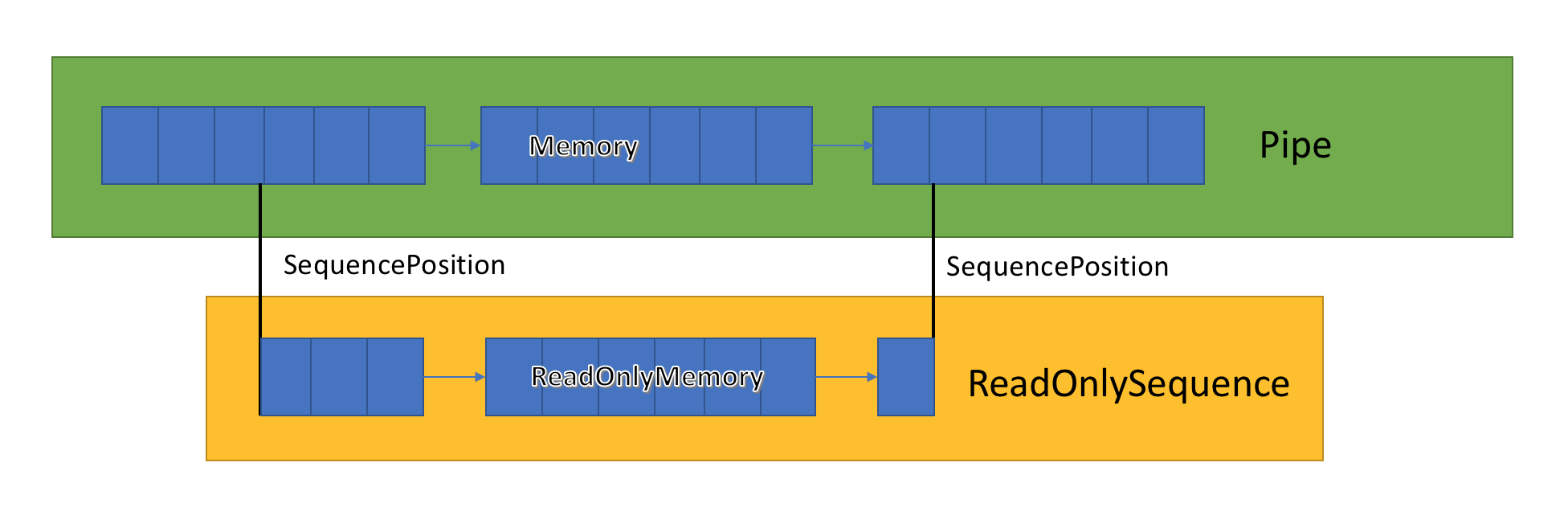
Di dalam saluran ada petunjuk yang menunjukkan di mana pembaca dan penulis berada di set umum data yang disorot, dan juga memperbaruinya saat data ditulis dan dibaca. SequencePosition adalah satu titik di daftar buffer yang ditautkan dan digunakan untuk memisahkan ReadOnlySequence <T> secara efisien.
Karena ReadOnlySequence <T> mendukung satu atau lebih segmen, operasi standar logika berkinerja tinggi adalah memisahkan jalur cepat dan lambat berdasarkan jumlah segmen.
Sebagai contoh, berikut adalah fungsi yang mengubah ASCII ReadOnlySequence menjadi string:
string GetAsciiString(ReadOnlySequence<byte> buffer) { if (buffer.IsSingleSegment) { return Encoding.ASCII.GetString(buffer.First.Span); } return string.Create((int)buffer.Length, buffer, (span, sequence) => { foreach (var segment in sequence) { Encoding.ASCII.GetChars(segment.Span, span); span = span.Slice(segment.Length); } }); }
lihat
sample6.cs di
githubResistensi aliran dan kontrol aliran
Idealnya, membaca dan menganalisis bekerja bersama: arus baca mengkonsumsi data dari jaringan dan menempatkannya dalam buffer, sementara aliran analisis menciptakan struktur data yang sesuai. Analisis biasanya memakan waktu lebih lama dari sekadar menyalin blok data dari jaringan. Akibatnya, aliran baca dapat dengan mudah membebani aliran analisis. Oleh karena itu, aliran baca akan dipaksa untuk memperlambat atau menggunakan lebih banyak memori untuk menyimpan data untuk aliran analisis. Untuk memastikan kinerja yang optimal, diperlukan keseimbangan antara frekuensi jeda dan alokasi sejumlah besar memori.
Untuk mengatasi masalah ini, pipa memiliki dua fungsi kontrol aliran data: PauseWriterThreshold dan ResumeWriterThreshold. PauseWriterThreshold menentukan berapa banyak data yang perlu di-buffer sebelum PipeWriter.FlushAsync dijeda. ResumeWriterThreshold menentukan berapa banyak memori yang dapat dikonsumsi pembaca sebelum perekam melanjutkan operasi.
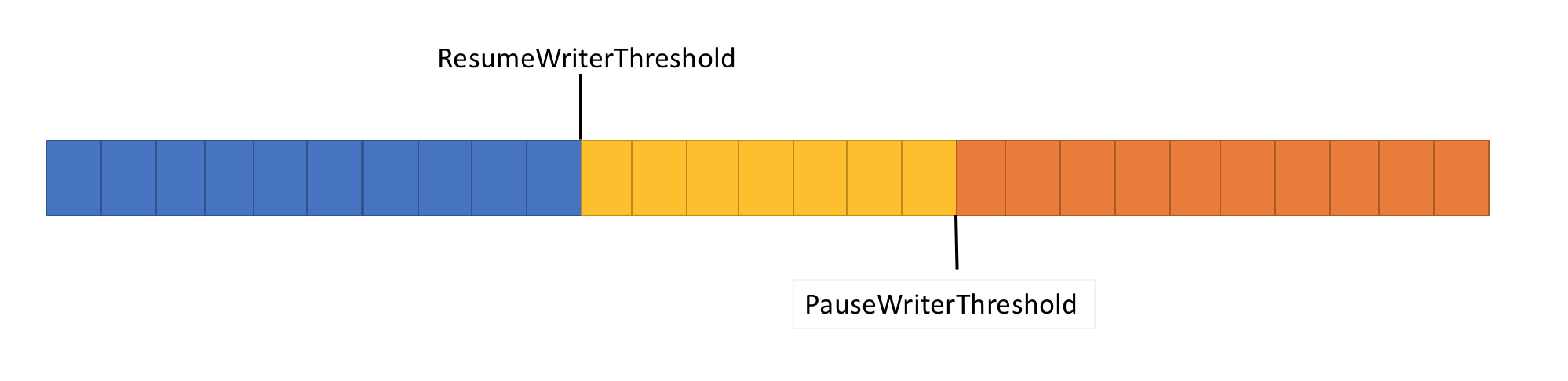
PipeWriter.FlushAsync "mengunci" ketika jumlah data dalam aliran pipelined melebihi batas yang ditetapkan di PauseWriterThreshold, dan "membuka kunci" ketika jatuh di bawah batas yang ditetapkan di ResumeWriterThreshold. Untuk mencegah melebihi batas konsumsi, hanya dua nilai yang digunakan.
Penjadwalan I / O
Saat menggunakan async / menunggu, operasi selanjutnya biasanya disebut di thread pool atau di SynchronizationContext saat ini.
Saat melakukan I / O, sangat penting untuk memantau dengan hati-hati di mana itu dilaksanakan untuk memanfaatkan cache prosesor dengan lebih baik. Ini penting untuk aplikasi berkinerja tinggi seperti server web. System.IO.Pipelines menggunakan PipeScheduler untuk menentukan tempat untuk melakukan panggilan balik asinkron. Ini memungkinkan Anda untuk mengontrol aliran mana yang harus digunakan untuk I / O.
Contoh aplikasi praktis adalah transportasi Kestrel Libuv, di mana panggilan balik I / O dilakukan pada saluran khusus pada loop acara.
Ada manfaat lain untuk templat PipeReader.
- Beberapa sistem basis mendukung "tunggu tanpa buffering": Anda tidak perlu mengalokasikan buffer hingga data yang tersedia muncul di sistem dasar. Jadi, di Linux dengan epoll, Anda tidak dapat menyediakan buffer baca hingga data siap. Ini menghindari situasi ketika ada banyak utas menunggu data, dan Anda harus segera memesan sejumlah besar memori.
- Pipa default memudahkan untuk menulis tes unit kode jaringan: logika parsing terpisah dari kode jaringan, dan tes unit hanya menjalankan logika ini dalam buffer dalam memori, daripada memakannya langsung dari jaringan. Ini juga membuatnya mudah untuk menguji pola yang kompleks dengan mengirim data parsial. ASP.NET Core menggunakannya untuk menguji berbagai aspek alat parsing http Kestrel.
- Sistem yang memungkinkan kode pengguna untuk menggunakan buffer OS utama (misalnya, API Windows I / O terdaftar) pada awalnya cocok untuk menggunakan jaringan pipa karena implementasi PipeReader selalu menyediakan buffer.
Jenis terkait lainnya
Kami juga menambahkan sejumlah tipe BCL sederhana baru ke System.IO.Pipelines:
- MemoryPoolT , IMemoryOwnerT , MemoryManagerT . ArrayPoolT ditambahkan dalam .NET Core 1.0, dan .NET Core 2.1 sekarang ada representasi abstrak yang lebih umum untuk kumpulan yang bekerja dengan MemoryT. Kami mendapatkan titik ekstensibilitas yang memungkinkan kami menerapkan strategi distribusi yang lebih maju, serta mengontrol manajemen buffer (misalnya, menggunakan buffer yang telah ditentukan alih-alih array yang dikelola secara eksklusif).
- IBufferWriterT adalah penerima untuk merekam data buffered yang disinkronkan (diimplementasikan oleh PipeWriter).
- IValueTaskSource - ValueTaskT telah ada sejak rilis .NET Core 1.1, tetapi dalam. NET Core 2.1 telah memperoleh alat yang sangat efektif yang menyediakan operasi asinkron tanpa gangguan tanpa distribusi. Lihat di sini untuk informasi lebih lanjut.
Bagaimana cara menggunakan conveyor?
API berada dalam paket nuget
System.IO.Pipelines .
Untuk contoh aplikasi server .NET Server 2.1 yang menggunakan jaringan pipa untuk memproses pesan huruf kecil (dari contoh di atas), lihat di
sini . Itu bisa mulai menggunakan dotnet run (atau Visual Studio). Dalam contoh tersebut, data diharapkan dikirim dari soket pada port 8087, kemudian pesan yang diterima ditulis ke konsol. Anda dapat menggunakan klien, seperti netcat atau dempul, untuk terhubung ke port 8087. Kirim pesan kecil dan lihat cara kerjanya.
Saat ini, pipeline berjalan pada Kestrel dan SignalR, dan kami berharap akan menemukan aplikasi yang lebih luas di banyak pustaka jaringan dan komponen komunitas .NET di masa mendatang.