Waktu hampir habis dan segera akan hampir tidak ada yang tersisa dari perkembangan ini, tetapi saya masih tidak punya waktu untuk menggambarkannya.
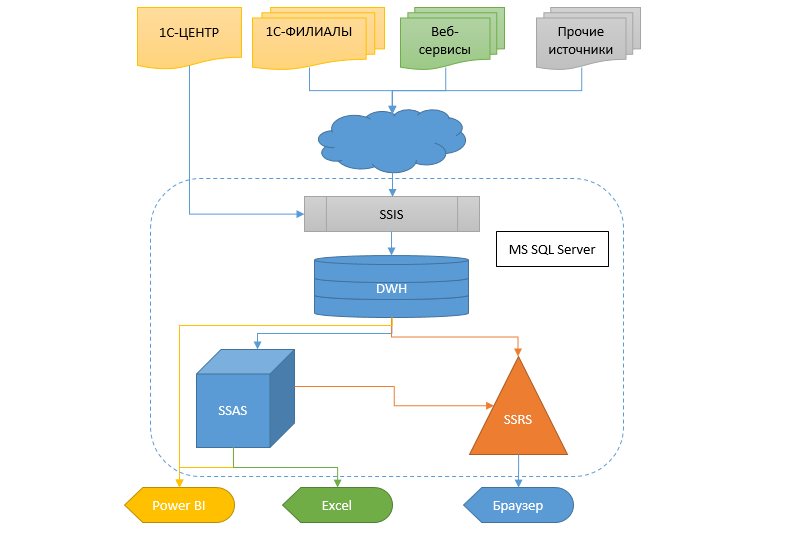
Ini akan menjadi tentang perusahaan di tingkat federal dengan sejumlah besar cabang dan cabang pembantu. Tapi, seperti biasa, semuanya dimulai sejak dulu dengan satu toko kecil. Selama bertahun-tahun, perkembangan yang cukup cepat dan spontan terjadi, cabang, divisi dan kantor lainnya muncul, dan infrastruktur TI tidak mendapat perhatian pada masa itu, dan ini juga sering terjadi. Tentu saja, 1C77 digunakan di mana-mana, tanpa cadangan untuk replikasi dan penskalaan, oleh karena itu, Anda tahu, pada akhirnya kami sampai pada kesimpulan bahwa Sprut-Frankenstein dihasilkan dengan tentakel yang diikat dengan pita listrik - di setiap cabang ada mutan otonom yang ditukar dengan basis pusat dalam mode "setinggi lutut", hanya beberapa buku referensi, yang tanpanya, yah, itu tidak mungkin sama sekali, dan sisanya adalah otonom. Untuk beberapa waktu mereka puas dengan salinan (lusinan dari mereka!) Dari kantor cabang di kantor pusat, tetapi data di dalamnya tertinggal selama beberapa hari.
Kenyataannya, bagaimanapun, memerlukan memperoleh informasi lebih cepat dan fleksibel, dan sesuatu yang lain harus dilakukan dengan ini. Perpindahan dari satu sistem akuntansi ke sistem akuntansi lainnya dalam skala seperti itu masih merupakan rawa. Oleh karena itu, diputuskan untuk membuat data warehouse (DX), di mana informasi akan mengalir dari database yang berbeda, sehingga nantinya layanan lain dan sistem analitik dalam bentuk kubus, laporan SSR, dan kebocoran dapat menerima data dari CD ini.
Ke depan, saya akan mengatakan bahwa transisi ke sistem akuntansi baru hampir terjadi dan sebagian besar proyek yang dijelaskan di sini akan dipotong dalam waktu dekat sebagai tidak perlu. Maaf, tentu saja, tetapi tidak ada yang bisa dilakukan.
Berikut ini adalah artikel yang panjang, tetapi sebelum Anda mulai membaca, izinkan saya mencatat bahwa dalam kasus apa pun saya tidak lulus keputusan ini sebagai standar, tetapi mungkin seseorang akan menemukan sesuatu yang berguna di dalamnya.
Saya akan mulai dengan pendekatan umum untuk proyek, yang mana SSDT dipilih sebagai lingkungan pengembangan, dengan publikasi proyek selanjutnya di Git. Saya pikir hari ini ada cukup banyak artikel dan tutorial yang menggambarkan kekuatan alat ini. Tetapi ada beberapa poin yang masalahnya terletak di luar lingkungan ini.
Penyimpanan enumerasi dan versi database
Mengenai versi dan enumerasi, persyaratan untuk proyek berarti:
- Kemudahan mengedit dan melacak perubahan dalam versi database dalam proyek
- Kenyamanan melihat versi database melalui SSMS untuk admin
- Menyimpan riwayat perubahan versi dalam database itu sendiri (siapa dan kapan penyebarannya)
- Menyimpan enumerasi dalam suatu proyek
- Kemudahan mengedit dan melacak perubahan dalam transfer
- Kunci penyebaran basis data di atas yang sudah ada jika tidak ada versi kenaikan
- Memasang versi baru, mencatat riwayat, transfer, dan restrukturisasi harus dilakukan dalam satu transaksi dan sepenuhnya dibatalkan jika terjadi kegagalan pada tahap apa pun
Karena transfer sering mengandung logika dan merupakan nilai dasar, yang tanpanya menambahkan catatan ke tabel lain menjadi tidak mungkin (karena kunci asing FK), pada dasarnya mereka adalah bagian dari struktur database, bersama dengan metadata. Oleh karena itu, perubahan dalam setiap elemen enumerasi mengarah ke peningkatan versi database dan, bersama dengan versi ini, catatan harus dijamin akan diperbarui selama penyebaran.
Saya pikir semua keuntungan dari memblokir penyebaran tanpa menambah versi jelas, salah satunya adalah ketidakmampuan untuk menjalankan kembali skrip publikasi jika sudah berhasil dieksekusi sebelumnya.
Meskipun jaringan database sering diusulkan untuk hanya menggunakan versi utama (tanpa fraksi), kami memutuskan untuk menggunakan versi dalam format XY, di mana Y adalah tambalan ketika salah ketik dikoreksi dalam deskripsi tabel, kolom, nama elemen daftar, atau sesuatu yang kecil, seperti menambahkan komentar ke prosedur tersimpan, dll. Dalam semua kasus lain, versi utama menumpuk.
Mungkin bagi seseorang tidak ada yang
seperti itu dan semuanya jelas. Tapi saya, pada waktunya, mengambil cukup banyak keberanian dan energi pada perselisihan internal tentang bagaimana menyimpan transfer dalam proyek database, sehingga itu adalah feng shui (
sesuai dengan ide saya tentang itu ) dan bahwa nyaman untuk bekerja dengan mereka, sambil meminimalkan kemungkinan kesalahan.
Dengan transfer, secara umum, semuanya sederhana - kami membuat file PostDeploy di proyek dan menulis kode di dalamnya untuk mengisi tabel. Dengan penggabungan atau trankat - ini adalah bagaimana Anda menyukainya. Kami lebih suka berkedip, memeriksa dulu apakah jumlah catatan dalam tabel target melebihi jumlah catatan yang ada di sumber (proyek). Jika melebihi, maka pengecualian dilemparkan untuk menarik perhatian padanya, karena itu aneh. Mengapa ada lebih sedikit catatan di sumbernya? Karena seseorang tidak berguna? Kenapa tiba-tiba? Dan jika database sudah memiliki tautan ke sana? Meskipun kami menggunakan kunci asing (FK), yang tidak akan memungkinkan Anda untuk menghapus catatan, jika ada tautan ke sana, kami masih memilih untuk meninggalkan opsi ini. Akibatnya, PostDeploy berubah menjadi lembar yang tidak dapat dibaca, karena untuk setiap tabel yang akan diisi, selain nilai-nilai itu sendiri, ada juga kode verifikasi, gabungan, dan sebagainya.
Namun, jika Anda menggunakan PostDeploy dalam mode SQLCMD, menjadi mungkin untuk mengekstrak blok kode ke file yang terpisah, sebagai hasilnya, hanya daftar nama file terstruktur yang tersisa untuk mengisi enumerasi di PostDeploy.
Ada beberapa nuansa dengan versi database. Internet telah lama berdebat tentang di mana menyimpan versi database, seperti apa tampilannya, dan secara umum, apakah perlu disimpan di suatu tempat? Misalkan kita memutuskan bahwa kita membutuhkannya, di mana proyek menyimpannya? Di suatu tempat di belantara skrip PostDeploy, atau letakkan di variabel yang dideklarasikan di baris pertama skrip?
Menurut pendapat saya, tidak satu atau yang lain. Lebih nyaman bila disimpan dalam file terpisah dan tidak ada lagi di sana.
Seseorang akan berkata - ada dacpac di properti proyek dan Anda dapat mengatur versi di dalamnya. Tentu saja, Anda bahkan dapat menarik versi ini ke dalam skrip Anda, seperti dijelaskan di
sini , tetapi ini merepotkan - untuk mengubah versi database, Anda harus pergi ke suatu tempat yang jauh, klik banyak tombol. Saya tidak mengerti logika Microsoft - mereka menyembunyikannya di sudut yang jauh, bersama dengan parameter basis data seperti pengurutan, tingkat kompatibilitas, dll., Karena versi basis data berubah "sering" sebagai parameter pengurutan, bukan? Ketika ada pengembangan konstan, versi dibangun dengan setiap penyebaran baru, well, kenyamanan pelacakan perubahan juga memainkan peran penting, karena ketika file yang diubah dengan nama yang ramah menyala, ini adalah satu hal, dan ketika file proyek .sqlproj menyala, di mana ada banyak baris dalam format XML , dan di antara mereka di suatu tempat di tengah garis satu digit yang diubah disorot, entah bagaimana tidak terlalu.
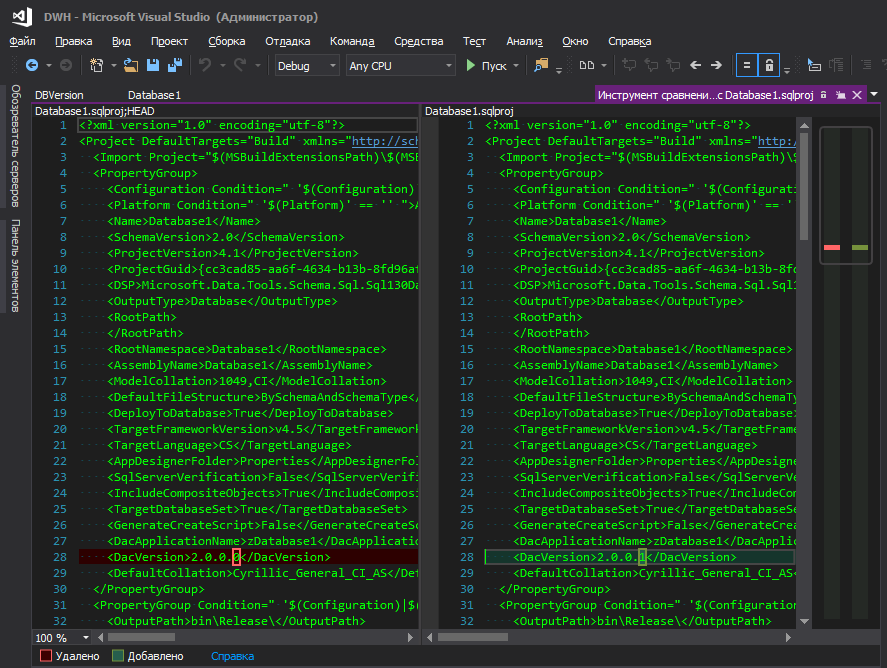
Itu lebih baik
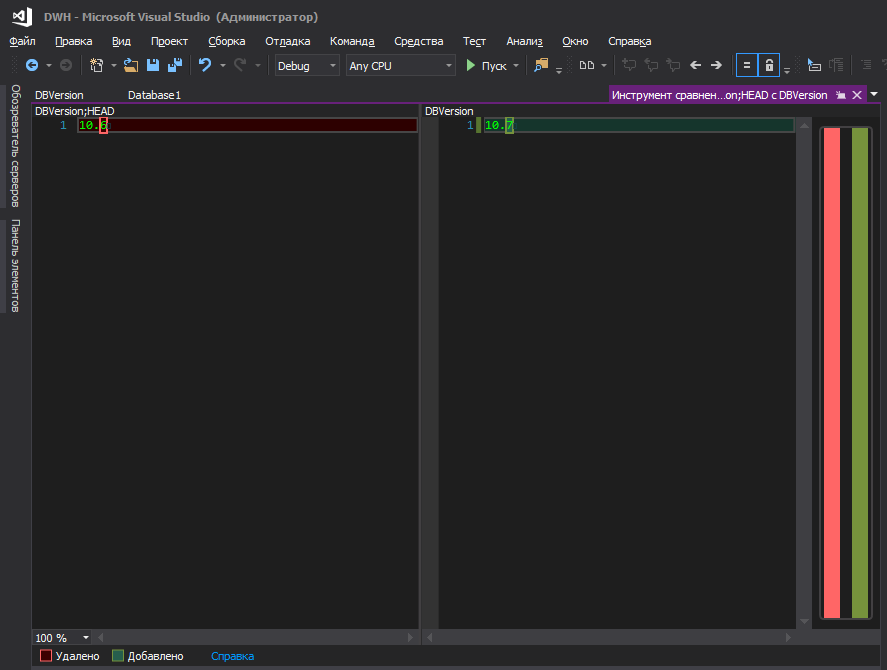
Namun, mungkin ini hanya kecoak saya dan Anda tidak harus memperhatikannya.
Sekarang pertanyaannya adalah: di mana menyimpan versi ini sudah dalam database yang digunakan. Sekali lagi, tampaknya dacpac melakukannya dengan indah - ia menulis segalanya ke pelat sistem, tetapi untuk melihat versinya, Anda perlu menjalankan permintaan (atau bisakah sebaliknya, tetapi saya tidak tahu cara memasaknya? Tampaknya di versi SSMS yang lebih lama ada antarmuka untuk ini, dan sekarang tidak)
select * from msdb.dbo.sysdac_instances_internal
untuk administrator (dan tidak hanya) sangat tidak nyaman. Jauh lebih logis bahwa versi tersebut akan ditampilkan secara langsung di properti dari database itu sendiri.

Atau tidak?
Untuk melakukan ini, Anda perlu menambahkan file ke proyek, termasuk dalam build, yang menggambarkan properti tingkat lanjut
EXECUTE sp_addextendedproperty @name = N'DeployerName', @value = ''; GO EXECUTE sp_addextendedproperty @name = N'DeploymentDate', @value = ''; GO EXECUTE sp_addextendedproperty @name = N'DBVersion', @value = '';
Ya, mereka kosong, dan terlihat jelek dalam skrip publikasi, tetapi Anda tidak dapat melakukannya tanpa mereka. Jika mereka tidak dijelaskan dalam proyek, dan mereka akan berada di database, maka studio akan mencoba untuk menghapusnya setiap kali dikerahkan. (Ada banyak upaya untuk menyiasati hal ini secara ringkas dan tanpa opsi penyebaran yang tidak perlu, tetapi tidak berhasil)
Kami akan menetapkan nilai untuknya dalam skrip PostDeploy.
declare @username varchar(256) = suser_sname() ,@curdatetime varchar(20) = format(getdate(),'dd.MM.yyyy HH:mm:ss') EXECUTE sp_updateextendedproperty @name = N'DeployerName', @value = @username; EXECUTE sp_updateextendedproperty @name = N'DBVersion', @value = [$(DBVersion)]; EXECUTE sp_updateextendedproperty @name = N'DeploymentDate', @value = @curdatetime;
sp_updateextendedproperty tanpa pemeriksaan apa pun, karena pada saat blok dimulai dari PostDeploy, semua properti sudah dibuat jika tidak ada di sana.
Yah, akan menyenangkan untuk menyimpan sejarah, tentang siapa dan kapan menyebarkan database.
Penerapan perubahan metadata dapat dilakukan dalam transaksi menggunakan alat standar dengan mencentang kotak
Aktifkan skrip transaksi di jendela
Opsi penerbitan lanjutan . Tetapi flag ini tidak mempengaruhi penyebaran skrip (Pra / Pasca) dan mereka terus berjalan tanpa transaksi. Tentu saja, tidak ada yang mencegah transaksi dimulai pada awal skrip PostDeploy, tetapi itu akan menjadi transaksi yang terpisah dari metadata, dan kami memiliki tugas untuk mengembalikan perubahan metadata jika pengecualian terjadi di PostDeploy.
Solusinya sederhana - mulai transaksi di PreDeploy, dan komit di PostDeploy, dan jangan gunakan tanda centang apa pun dalam pengaturan publikasi untuk tujuan ini.
Untuk menyimpan versi database dalam proyek dan mendaftarkannya di tempat yang diinginkan selama penerapan, Anda dapat menggunakan variabel SQLCMD. Namun, saya tidak ingin menyimpan versi di suatu tempat di belantara kode, saya ingin itu ada di permukaan.
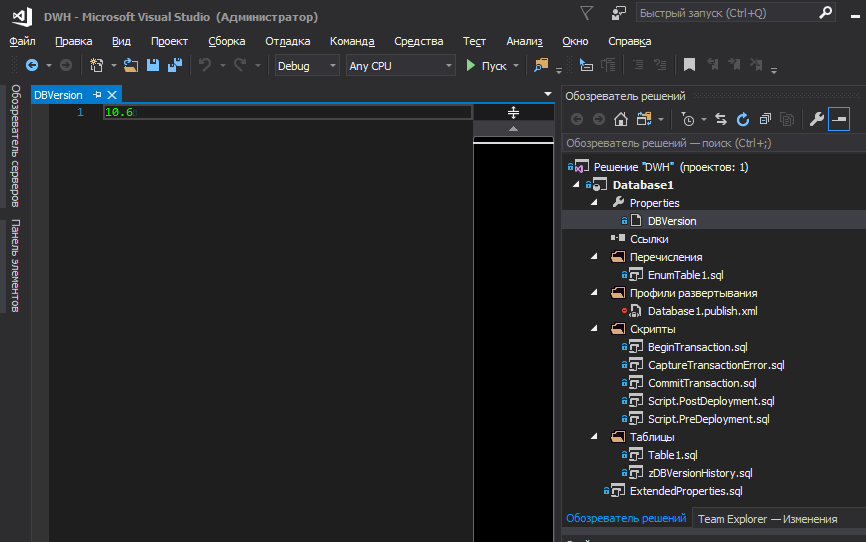
Untuk menempatkan versi database dalam file terpisah dan mengelola versi dari sana di tingkat proyek, kami menambahkan blok berikut ke .sqlproj:
<Target Name="BeforeBuild"> <ReadLinesFromFile File="$(ProjectDir)\Properties\DBVersion"> <Output TaskParameter="Lines" PropertyName="ExtDBVersion" /> </ReadLinesFromFile> <WriteLinesToFile File="$(ProjectDir)\\SetPreDepVarsTmp.sql" Lines=":setvar DBVersion $(ExtDBVersion)" Overwrite="true" /> </Target> </Target>
Ini adalah instruksi untuk MSBuild untuk membaca baris dari file sebelum membangun dan membuat file sementara berdasarkan data yang dibaca. MSBuild akan membuat file
SetPreDepVarsTmp.sql sementara, yang akan
:setvar DBVersion $(ExtDBVersion) baris
:setvar DBVersion $(ExtDBVersion) , di mana
$(ExtDBVersion) adalah nilai yang dibaca dari file kami yang menyimpan versi database.
Setelah manipulasi seperti itu, Anda dapat merujuk ke file sementara ini dari skrip PreDeploy dan memulai transaksi global di dalamnya:
:r .\SetPreDepVarsTmp.sql go :r ".\BeginTransaction.sql"
Versi menengahAwalnya, file ExtendedProperties.sql diberikan bukan nilai kosong, tetapi nilai dari variabel
EXECUTE sp_addextendedproperty @name = N'DeployerName', @value = [$(DeployerName)]; GO EXECUTE sp_addextendedproperty @name = N'DeploymentDate', @value = [$(DeploymentDate)]; GO EXECUTE sp_addextendedproperty @name = N'DBVersion', @value = [$(DBVersion)];
Variabel, pada gilirannya, didaftarkan dalam file SetPreDepVarsTmp.sql secara otomatis oleh MSBuild seperti ini:
<PropertyGroup> <CurrentDateTime>$([System.DateTime]::Now.ToString(dd.MM.yyyy HH:mm:ss))</CurrentDateTime> </PropertyGroup> <PropertyGroup> <NewLine> -- </NewLine> </PropertyGroup> <Target Name="BeforeBuild"> <ReadLinesFromFile File="$(ProjectDir)\DBVersion"> <Output TaskParameter="Lines" PropertyName="ExtDBVersion" /> </ReadLinesFromFile> <WriteLinesToFile File="$(ProjectDir)\SetPreDepVarsTmp.sql" Lines=":setvar DBVersion $(ExtDBVersion)$(NewLine):setvar DeploymentDate "$(CurrentDateTime)"$(NewLine):setvar DeploymentUser $(UserDomain)\$(UserName)" Overwrite="true" /> </Target>
Dengan pendekatan ini, Anda tidak perlu menginstal ulang properti ini di PostDeploy, tetapi masalahnya adalah bahwa SetPreDepVarsTmp.sql berisi nilai statis dan jika skrip publikasi dibuat sekarang, tetapi digunakan dalam satu jam, atau, lebih buruk lagi, pada hari berikutnya (pengembang memeriksanya untuk waktu yang lama) misalnya secara visual), tanggal publikasi yang ditentukan dalam properti akan berbeda dari tanggal publikasi aktual dan tidak sesuai dengan tanggal dalam sejarah.
Isi file BeginTransaction.sqlPada dasarnya, ini hanya salin-tempel dari blok awal transaksi standar yang dihasilkan oleh studio ketika kotak centang
Aktifkan skrip transaksi dipilih , tetapi kami menggunakannya dengan cara kami sendiri. Dalam skrip, hanya nama tabel sementara yang telah diubah dari
#tmpErrors menjadi
#tmpErrorsManual sehingga tidak ada konflik nama jika seseorang mengaktifkan kotak centang.
IF (SELECT OBJECT_ID('tempdb..#tmpErrors')) IS NOT NULL DROP TABLE
Script PostDeploy declare @TableName VarChar(255) = null
Variabel SkipEnumDeploy, seperti yang telah menjadi jelas, memungkinkan Anda untuk melewati tahap memperbarui daftar, ini dapat berguna untuk perubahan kosmetik kecil. Meskipun, dari sudut pandang agama, ini mungkin tidak benar, namun, itu pasti berguna pada tahap pengembangan.
File
CaptureTransactionError.sql dan
CommitTransaction.sql juga
CommitTransaction.sql salin-tempel (dengan koreksi kecil) dari algoritma transaksi standar yang dihasilkan oleh studio ketika flag di atas diatur, dan yang sekarang kami mainkan sendiri.
Content CaptureTransactionError.sql IF @@ERROR <> 0 AND @@TRANCOUNT > 0 BEGIN ROLLBACK; END IF @@TRANCOUNT = 0 BEGIN INSERT INTO
Konten CommitTransaction.sql Konten EnumTable1.sql set @TableName = N'Table1' PRINT N' '+@TableName+'...' begin try set nocount on drop table if exists
Saat menggunakan
Publish skrip akan memiliki struktur berikut
Idealnya, tentu saja, saya ingin versi ditampilkan pada saat publikasi

Tetapi Anda tidak dapat menarik nilai dari file ke jendela ini, meskipun MSBuild membacanya dan memasukkannya ke properti ExtDBVersion dengan bantuan instruksi tambahan dalam file .sqlproj, seperti pada contoh di atas, tetapi konstruksinya
<SqlCmdVariable Include="DBVersion"> <DefaultValue> </DefaultValue> <Value>$(ExtDBVersion)</Value> </SqlCmdVariable>
tidak menggulung.
Pengembang sekuel di
buku harian web mereka menulis bagaimana ini dilakukan. Menurut versi mereka, keajaiban terletak pada instruksi
SqlCommandVariableOverride , yang sederhana - tambahkan beberapa baris ke file proyek .sqlproj
<ItemGroup> <SqlCommandVariableOverride Include="DBVersion=$(ExtDBVersion)" /> </ItemGroup>
dan dilakukan. Usaha yang bagus, tetapi tidak. Mungkin ketika posting blog ini diterbitkan, semuanya bekerja, tetapi sejak itu di Amerika ini Anda telah melakukan tiga pemilihan presiden dan tidak ada yang tahu instruksi apa yang mungkin berhenti bekerja besok.

Dan di
sini seorang kawan mencoba semua opsi, tetapi tidak ada yang lepas landas.
Karena itu, ambil versi dari dacpac, atau simpan di PostDeploy, atau dalam file terpisah, atau _________ (masukkan versi Anda).
Integrasi dengan 1C
Masalah pertama adalah bahwa 1C77 tidak memiliki server aplikasi atau daemon lain yang memungkinkannya berinteraksi dengannya tanpa meluncurkan platform. Mereka yang bekerja dengan 1C77 tahu bahwa dia tidak memiliki mode konsol penuh. Anda dapat menjalankan platform dengan parameter dan bahkan melakukan sesuatu berdasarkan pada mereka, tetapi ada beberapa parameter konsol dan tujuannya berbeda. Tetapi bahkan dengan bantuan mereka, Anda dapat nakolkhozit keseluruhan. Namun, ia dapat terbang keluar secara tidak terduga, dapat memunculkan jendela modal dan menunggu seseorang mengklik OK dan pesona lainnya. Dan, mungkin, masalah terbesar - kecepatan platform meninggalkan banyak yang harus diinginkan ... Oleh karena itu, hanya ada satu solusi - pertanyaan langsung ke database 1C. Mengingat strukturnya, Anda tidak bisa hanya mengambil dan menulis pertanyaan ini, tetapi manfaatnya adalah ada seluruh komunitas yang pada suatu waktu mengembangkan alat yang luar biasa - 1C ++ (1cpp.dll), yang luar biasa bagi mereka TERIMA KASIH! Perpustakaan memungkinkan Anda untuk menulis kueri dalam hal 1C, yang kemudian berubah menjadi nama sebenarnya dari tabel dan bidang. Jika ada yang tidak tahu, maka permintaan dapat ditulis menggunakan nama semu dan akan terlihat seperti ini
select from $.
Permintaan seperti itu dapat dimengerti oleh manusia, tetapi tidak ada tabel dan bidang pada server, ada nama lain, jadi 1C ++ akan mengubahnya menjadi
select SP5278 from SC2235
dan permintaan semacam itu sudah dipahami oleh server. Semua orang senang, tidak ada yang bersumpah - baik orang, maupun server. Di sini, tampaknya, masalah telah teratasi.
Masalah kedua terletak pada bidang konfigurasi: satu konfigurasi digunakan di cabang, yang lain di kantor pusat, dan yang ketiga di cabang! Kelas? !! 1 Aku juga berpikir begitu. Selain itu, mereka tidak khas dan bahkan bukan warisan khas, tetapi benar-benar ditulis dari awal selama Viking dan, sayangnya, bukan arsitek terbaik meletakkan dasar konfigurasi ini ... Implementasi Dokumen, misalnya, dalam setiap konfigurasi memiliki serangkaian detail yang berbeda. Tetapi tidak hanya nama-nama dari beberapa bidang berbeda, yang jauh lebih menyenangkan ketika nama-nama rinciannya sama, tetapi arti dari data yang disimpan di dalamnya adalah BERBEDA.

Dalam konfigurasi hampir tidak ada register yang digunakan, semuanya dibangun di atas kerumitan dokumen. Oleh karena itu, kadang-kadang saya harus menulis seluruh lembar pada transaksi bersih, dengan banyak kasus dan bergabung, untuk mengulangi logika beberapa prosedur dari konfigurasi, yang menampilkan beberapa informasi di bidang teks pada formulir.
Kita harus membayar upeti kepada tim pengembangan, yang selama ini mendukung apa yang mereka warisi dari "pelaksana", itu adalah pekerjaan besar - untuk mendukung ini dan bahkan mengoptimalkan sesuatu. Sampai Anda melihat - Anda tidak mengerti, saya sendiri pada awalnya tidak percaya bahwa semuanya bisa begitu rumit. Tanyakan - mengapa tidak menulis ulang dari awal? Banal kekurangan sumber daya. Perusahaan itu berkembang begitu cepat sehingga, meskipun ada tim programmer yang besar, mereka tidak bisa mengikuti kebutuhan bisnis, belum lagi menulis ulang seluruh konsep.
Kami melanjutkan kisah permintaan. Jelas, semua blok untuk ekstraksi data berubah menjadi penyimpanan sehingga nantinya mereka dapat diluncurkan di sisi server melewati platform 1C. Aturannya adalah ini: satu penyimpanan bertanggung jawab untuk mengambil satu entitas. Karena Wishlist pada tahap awal sudah banyak terakumulasi, karena telah menjadi menyakitkan selama bertahun-tahun, maka puluhan file penyimpanan telah berubah.
Masalah ketiga adalah bagaimana cara meningkatkan kecepatan dan kualitas pengembangan, dan bagaimana cara mendukung semua monster ini? Tulis permintaan untuk 1C ++ dan salin-tempel hasil konversi ke penyimpanan? Sangat tidak nyaman dan membosankan, selain itu, ada kemungkinan kesalahan yang tinggi - salin yang salah atau yang salah atau tidak pilih baris terakhir dari permintaan dan salin tanpa itu. Ini terutama benar ketika datang ke permintaan 1C langsung, karena tidak ada nama pseudo seperti
Direktori. Nomenklatur. Artikel, hanya nama asli
SC2235.SP5278 dan karenanya menyalin permintaan dari bawah direktori barang ke toko yang mengambil pelanggan sangat sederhana. Tentu saja, permintaan kemungkinan besar akan jatuh karena ketidakcocokan jenis dan jumlah bidang dalam tabel tujuan, tetapi ada pelat yang identik, seperti enumerasi, di mana hanya dua kolom yaitu ID dan Nama. Secara umum, itu hanya berlaku untuk beberapa jenis otomasi. Cukup lirik, mari kita mulai bisnis!
Saya ingin proses pengembangan penyimpanan turun ke sesuatu seperti ini:
- Kami memperbaiki query SQL dengan pseudo-names dan menyimpannya
- Kami menekan tombol ajaib dan di pintu keluar kami menerima prosedur tersimpan terkoreksi pada SQL dikonversi, jelas ke server
Beberapa detail
Untuk mengatasi masalah ketiga, pemrosesan eksternal (.ert) ditulis. Ada sejumlah prosedur dalam pemrosesan, yang masing-masing berisi teks permintaan untuk mengekstraksi satu entitas menggunakan nama semu, seperti
select * from $.
Pada formulir pemrosesan, ada bidang untuk menampilkan hasil dari prosedur tertentu, yaitu permintaan dikonversi ke formulir yang dapat dimengerti oleh server sehingga Anda dapat dengan cepat mencobanya. Plus,
blok debug selalu ditambahkan ke permintaan ini, dengan deklarasi variabel, nama-nama database pengujian, server, dan banyak lagi. Tetap hanya menyalin-menempel di SSMS dan tekan F5. Anda dapat, tentu saja, menjalankan permintaan ini dari pemrosesan itu sendiri, tetapi rencana permintaan dan semua itu, well, Anda mengerti ... Secara umum, ini adalah bagaimana debugging dilakukan. Karena Ada beberapa konfigurasi, dalam pemrosesan, dimungkinkan untuk mengonversi teks kueri yang sama dengan nama-nama pseudo objek ke permintaan akhir untuk konfigurasi yang berbeda. Memang, dalam satu referensi Referensi tata nama adalah SC123, dan di lain - SC321. Tetapi 1C ++ memungkinkan Anda untuk memuat konfigurasi yang berbeda dalam runtime dan menghasilkan output individual untuk masing-masing sesuai dengan kamus.
Selanjutnya, mode batch run ditambahkan ke pemrosesan, ketika secara otomatis memulai setiap prosedur untuk setiap konfigurasi, dan output dari masing-masing ditulis ke file .sql (selanjutnya file-file dasar). Dengan demikian, kami mendapatkan banyak kombinasi file dasar, yang kemudian secara otomatis berubah menjadi prosedur tersimpan menggunakan VS. Perlu dicatat bahwa file dasar termasuk
blok debug .
Tampaknya, mengapa tidak membuat kesimpulan segera ke file akhir dari prosedur tersimpan dan menyimpan semuanya dalam pemrosesan ini? Faktanya adalah bahwa untuk beberapa tes perlu untuk menjalankan versi debug permintaan dalam batch di mana semua variabel dideklarasikan, ditambah saya ingin nama prosedur tersimpan dikelola dari VS, melewati 1C, karena ini logis, bukan?
Omong-omong, file-file dasar juga disimpan dalam proyek, tentu saja, file-file dari prosedur tersimpan yang sudah jadi, tentu saja. Kapan saja, tanpa memulai 1C, Anda dapat membuka file dasar di SSMS dan menjalankannya tanpa repot dengan deklarasi variabel.
Dalam pemrosesan, semua prosedur dengan permintaan juga merupakan templat, memiliki set parameter yang sama, tetapi dalam prosedur ini atau itu hanya parameter yang diperlukan yang digunakan. Dalam beberapa, semuanya terlibat, dan dalam beberapa, dua sudah cukup. Oleh karena itu, menambahkan prosedur baru dilakukan untuk menyalin templat dan mengisi parameter dengan kueri itu sendiri.
Kode salah satu prosedur pemrosesan, yang nantinya akan berubah menjadi prosedur tersimpan
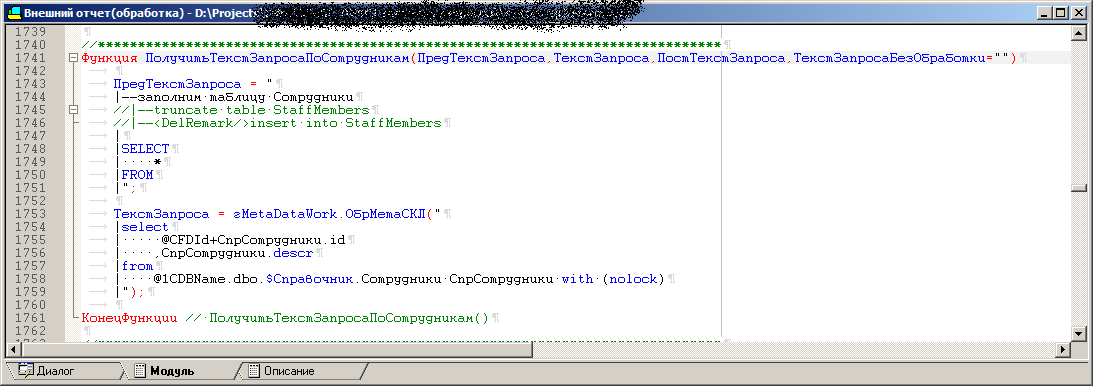
Kueri terakhir adalah sesuatu seperti ini:
++"("+OPENQUERY()+")"+
Penampilan pemrosesan

Saat mengalihkan konfigurasi, daftar item yang tersedia (perlu) untuk membongkar item dalam daftar Data berubah. Jika memungkinkan, kode prosedur dalam 1C sebanyak mungkin disatukan. Jika rekanan diekstraksi dan direktori ini tidak konsisten dalam konfigurasi yang berbeda, maka di dalam prosedur pembuatan ada beberapa kasus yang berbeda, seperti: blok ini diperbaiki untuk semua orang, ini ditambahkan ke permintaan akhir hanya untuk conf seperti itu, dan ada satu untuk yang lain. Ternyata dalam prosedur tersimpan untuk satu entitas tetapi konfigurasi yang berbeda mereka dapat berbeda tidak hanya dengan nama tabel, tetapi dengan seluruh blok gabungan hadir dalam satu dan tidak ada di yang lain. Himpunan bidang output, tentu saja, sama dan sesuai dengan tabel penerima atau wadah paket SSIS, beberapa bidang tersumbat dengan bertopik untuk konfigurasi di mana rincian ini tidak pada prinsipnya.
Tombol ajaibVisual Studio memiliki alat seperti MSbuild dan templat T4 yang mengagumkan. Oleh karena itu, sebagai tombol ajaib, skrip ditulis dalam C # untuk T4, yang:
- Mendaftarkan konfigurasi kosong di registri (jika tidak 1C akan menampilkan jendela modal dengan saran untuk mendaftarkan conf dan menunggu tindakan pengguna)
- Membuat database kosong untuk konf ini di SQL server, karena tanpa itu 1C akan memberikan kesalahan
- Meluncurkan 1C dan melalui OLE memberitahu untuk menjalankan pemrosesan (.ert yang sama), juga mentransfer GUID unik ke 1C
- Outputnya adalah serangkaian file dengan permintaan yang siap pakai (dikonversi) dan file marker, yang menjadi tujuan penulisan GUID saat startup
- Pendaftaran conf dihapus dari registri dan database kosong sementara dihapus dari server
- Memeriksa konten file token. Jika file penanda berisi GUID yang kami sampaikan ke 1C saat dimulai, itu berarti ia bekerja sampai akhir, tidak macet, dll., Kemudian pergi ke langkah berikutnya, atau kami menampilkan kesalahan
- Kami membuat penyimpanan.
- Kami mendekompilasi file .ert dengan gcomp untuk mendapatkan teks modul dan formulir pemrosesan, yah, kami mengonversi ke Unicode, untuk pengiriman berikutnya ke Git dan menampilkannya dengan benar di sana. Bagi mereka yang tidak bekerja dengan 1C: file .ert adalah biner dan studio, bersama dengan git, berhembus bahwa file .ert telah diubah, tetapi tidak jelas apa yang sebenarnya telah berubah di dalamnya, mungkin hanya seseorang yang memindahkan tombol satu piksel ke kiri (yang tidak dapat diterima tanpa pembenaran)
T4 , ( , ) . , . , , , , - — 1.
, , , , , . — 1, 1, - .
: ?
- / ;
- VS , ;
- 4;
. Selesai
?Karena , , .sqlproj,
<ItemGroup> <None Include=" \1.sql"> <None Include=" \2.sql"> <None Include=" \3.sql"> </ItemGroup>
<ItemGroup> <Content Include=" \*.sql" /> </ItemGroup>
« ». , , , :)
, , (, ) . ( ), , - - - , .
, . . , , , , , ( ), . , ( , ) , , , . , . , , , , , ( , 1, , MD ).
,
OPENQUERY , 1 , , , ,
EXEC .
OPENQUERY , , , .
177 ( ) SQL2000, varchar(max) , varchar(8000), 9, … , EXEC(@SQL1+@SQL2). , SQL2016, SQL2000. , , .
select ... from ( select ... from @1CDBName.dbo.$. join @1CDBName.dbo.$. join ... where xxx = 'hello!' ^
CREATE PROCEDURE [dbo].[SP1] @LinkedServerName varchar(24) ,@1CDBName varchar(24) AS BEGIN Declare @TSQL0 varchar(8000), @TSQL1 varchar(8000), @TSQL2 varchar(8000) set @TSQL0=' select ... from OPENQUERY('+@LinkedName+','' select ... from '+@1CDBName+'.dbo.DH123. join '+@1CDBName+'.SC123. ... where '; set @TSQL1=' xxx = ''''hello!'''' join ... join ... )'' join ... '''; set @TSQL2=' ... EXEC(@TSQL0+@TSQL1+@TSQL2) END
— . (, ) , , , , , , OPENQUERY 8 .
.ert , .. , .
, .
ETL
Mungkin, di bagian ini tidak ada yang spesial (menurut saya). Skema klasik dengan database perantara (Tahap). Hanya dapat dicatat bahwa ETL diimplementasikan menggunakan paket SSIS, yang, pada gilirannya, melakukan prosedur tersimpan yang sama yang dibahas pada bagian sebelumnya. Ada paket utama dan beberapa anak. Untuk mengaktifkan eksekusi multi-utas, paket utama secara bersamaan meluncurkan beberapa instance dari paket turunan yang sama dengan parameter yang berbeda (untuk cabang yang berbeda), sebagai akibatnya, dimungkinkan untuk mendapatkan data dari server yang terhubung dalam waktu sesingkat mungkin., ( ) , , (.. ), , .
, , . , . zabbix.
.
Karena 1 , , . , ,
truncate .
, ( ) -, « 1-» .
SSIS
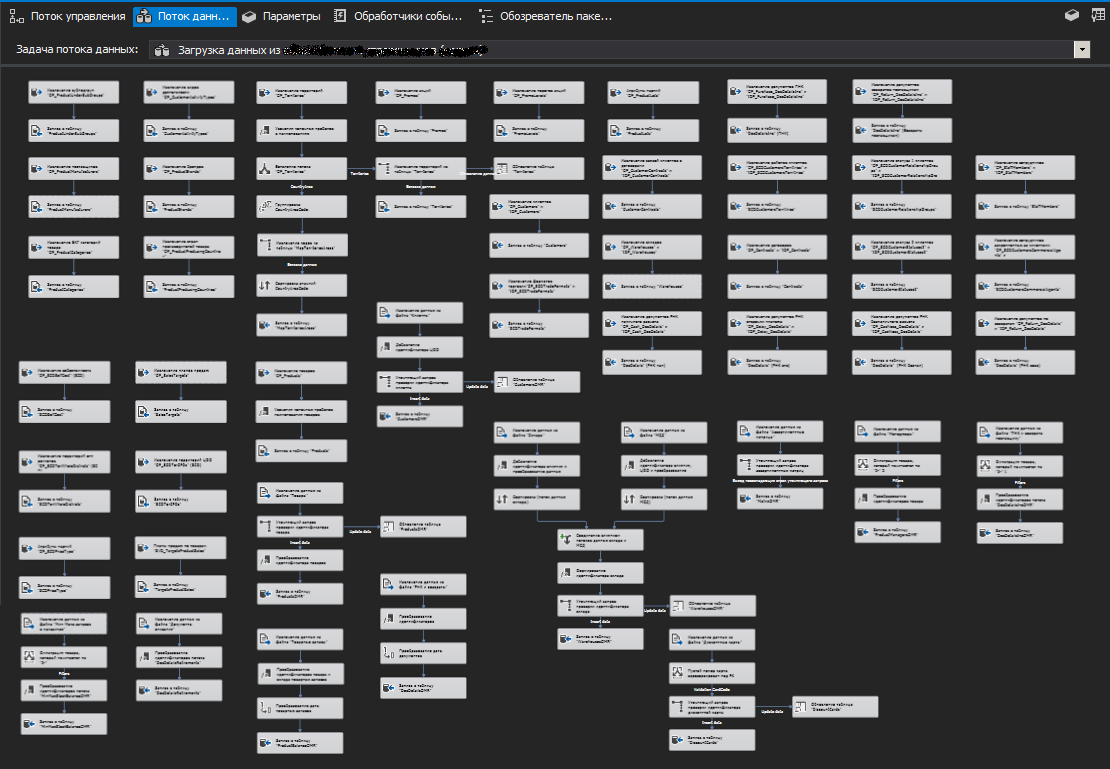
,
SSIS
SQL Server (SQL Server Destination), ,
OLE DB (OLE DB Destination).
, , , . , , . (, )
. , , , (/ ).
.
, ( ). Yaitu
skrip tidak hanya membuat perubahan pada data, tetapi juga mencatat fakta peluncurannya dalam log. Masuk akal tidak hanya untuk mendaftarkan peluncuran, tetapi juga untuk memblokir restart jika log sudah berisi informasi tentang proses sebelumnya. Dan jika karena alasan tertentu Anda perlu menjalankan skrip yang sama lagi - buat salinannya dan berikan tanggal dan nomor baru. Ini akan sangat memudahkan hidup dan menghilangkan klaim yang tidak perlu selama pembekalan.Tetapkan string dan jalur koneksi selain jalur dan nama produktif sebagai pengaturan default untuk penyebaran, sehingga untuk publikasi dalam produk Anda harus dengan sengaja (mis. Secara sadar) memilih pengaturan tertentu., , .
PS
, , , , . — , . - , , .