Catatan ini adalah versi tertulis dari laporan saya "Cara merusak kinerja dengan kode yang tidak efisien" dari konferensi JPoint 2018. Anda dapat menonton video dan slide di halaman konferensi . Dalam jadwal, laporan ditandai dengan segelas smoothie ofensif, sehingga tidak akan ada yang super rumit, ini lebih cenderung untuk pemula.
Subjek laporan:
- cara melihat kode untuk menemukan kemacetan di dalamnya
- antipatterns umum
- menyapu tidak jelas
- menyapu memotong
Di sela-sela, mereka menunjukkan beberapa ketidakakuratan / kelalaian dalam laporan, mereka dicatat di sini. Komentar juga diterima.
Dampak Kinerja terhadap Kinerja
Ada kelas pengguna:
class User { String name; int age; }
Kita perlu membandingkan objek satu sama lain, jadi kita mendeklarasikan metode equals dan hashCode :
import lombok.EqualsAndHashCode; @EqualsAndHashCode class User { String name; int age; }
Kode ini bisa diterapkan, pertanyaannya berbeda: apakah kinerja kode ini akan menjadi yang terbaik? Untuk menjawabnya, mari kita mengingat fitur dari metode Object::equals : ia mengembalikan hasil positif hanya ketika semua bidang yang dibandingkan adalah sama, jika tidak hasilnya akan negatif. Dengan kata lain, satu perbedaan sudah cukup untuk hasil negatif.
Setelah melihat kode yang dihasilkan untuk @EqualsAndHashCode kita akan melihat sesuatu seperti ini:
public boolean equals(Object that) {
Urutan memeriksa bidang sesuai dengan urutan deklarasi mereka, yang dalam kasus kami bukan solusi terbaik, karena membandingkan objek menggunakan equals "lebih sulit" daripada membandingkan tipe sederhana.
Ok, mari kita coba membuat metode equals/hashCode menggunakan Idea:
@Override public boolean equals(Object o) { if (this == o) { return true; } if (o == null || getClass() != o.getClass()) { return false; } User that = (User) o; return age == that.age && Objects.equals(name, that.name); }
Suatu Ide menciptakan kode yang lebih cerdas yang mengetahui kerumitan membandingkan berbagai jenis data. Nah, kita akan @EqualsAndHashCode dan kita akan secara eksplisit menulis equals/hashCode . Sekarang mari kita lihat apa yang terjadi ketika kelas diperluas:
class User { List<T> props; String name; int age; }
equals/hashCode rekreasi equals/hashCode :
@Override public boolean equals(Object o) { if (this == o) { return true; } if (o == null || getClass() != o.getClass()) { return false; } User that = (User) o; return age == that.age && Objects.equals(props, that.props)
Daftar dibandingkan sebelum string dibandingkan, yang tidak masuk akal ketika string berbeda. Pada pandangan pertama, tidak ada banyak perbedaan, karena string dengan panjang yang sama dibandingkan dengan tanda (yaitu, waktu perbandingan tumbuh bersama dengan panjang string):
Ada ketidakakuratanMetode java.lang.String::equals adalah intrusif , jadi tidak ada perbandingan akses saat eksekusi.
Sekarang pertimbangkan untuk membandingkan dua ArrayList (sebagai implementasi daftar yang paling umum digunakan). Meneliti ArrayList , kami terkejut menemukan bahwa ia tidak memiliki implementasi yang equals , tetapi menggunakan implementasi yang diwarisi:
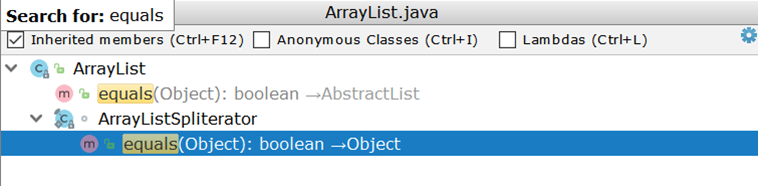
Penting di sini adalah penciptaan dua iterator dan berpasangan melalui mereka. Misalkan ada dua ArrayList :
- dalam satu nomor dari 1 hingga 99
- dalam angka kedua dari 1 hingga 100
Idealnya, akan cukup untuk membandingkan ukuran kedua daftar dan jika mereka tidak bersamaan, segera kembalikan hasil negatif (seperti yang dilakukan AbstractSet ), dalam kenyataannya, 99 perbandingan akan dilakukan dan hanya pada keseratus akan menjadi jelas bahwa daftar tersebut berbeda.
Ada apa dengan orang Kotlin?
data class User(val name: String, val age: Int);
Di sini semuanya seperti Lombok - urutan perbandingan sesuai dengan urutan pengumuman:
public boolean equals(Object o) { if (this == o) { return true; } if (o instanceof User) { User u = (User) o; if (Intrinsics.areEqual(name, u.name) && age == u.age) {
Sebagai solusinya, Anda bisa mengatur deklarasi lapangan secara manual.
Mari menyulitkan tugas
void check(Dto dto) { SomeEntity entity = jpaRepository.findOne(dto.getId()); boolean valid = dto.isValid(); if (valid && entity.hasGoodRating()) {
Kode ini melibatkan pengaksesan basis data bahkan ketika hasil dari pengecekan kondisi yang ditunjukkan oleh panah sudah dapat diprediksi sebelumnya. Jika nilai variabel yang valid salah, maka kode di blok if tidak akan pernah dijalankan, yang berarti Anda bisa melakukannya tanpa permintaan:
void check(Dto dto) { boolean valid = dto.isValid(); if (valid && hasGoodRating(dto)) {
Catatan dari sela-selaSinking bisa tidak signifikan ketika entitas kembali dari JpaRepository::findOne sudah ada di cache tingkat pertama - maka tidak akan ada permintaan.
Contoh serupa tanpa bercabang eksplisit:
boolean checkChild(Dto dto) { Long id = dto.getId(); Entity entity = jpaRepository.findOne(id); return dto.isValid() && entity.hasChild(); }
Pengembalian cepat memungkinkan Anda untuk menunda permintaan:
boolean checkChild(Dto dto) { if (!dto.isValid()) { return false; } return jpaRepository.findOne(dto.getId()).hasChild(); }
Tambahan yang cukup jelas yang tidak muncul dalam laporanBayangkan bahwa cek tertentu menggunakan entitas yang serupa:
@Entity class ParentEntity { @ManyToOne(fetch = LAZY) @JoinColumn(name = "CHILD_ID") private ChildEntity child; @Enumerated(EnumType.String) private SomeType type;
Jika pemeriksaan menggunakan entitas yang sama, maka Anda harus memastikan bahwa panggilan ke entitas / koleksi anak "malas" dilakukan setelah panggilan ke bidang yang sudah dimuat. Pada pandangan pertama, satu permintaan tambahan tidak akan memiliki dampak signifikan pada keseluruhan gambar, tetapi semuanya bisa berubah ketika suatu tindakan dilakukan dalam satu lingkaran.
Kesimpulan: rantai tindakan / pemeriksaan harus dipesan dalam rangka meningkatkan kompleksitas operasi individu, mungkin beberapa dari mereka tidak harus dilakukan.
Siklus dan Pemrosesan Massal
Contoh berikut tidak perlu penjelasan khusus:
@Transactional void enrollStudents(Set<Long> ids) { for (Long id : ids) { Student student = jpaRepository.findOne(id);
Karena beberapa permintaan basis data, kode ini lambat.
KomentarKinerja dapat tenggelam lebih banyak lagi jika metode enrollStudents dijalankan di luar transaksi: maka setiap panggilan ke osdjrJpaRepository::findOne akan dieksekusi dalam transaksi baru (lihat SimpleJpaRepository ), yang berarti menerima dan mengembalikan koneksi ke database, serta membuat dan membilas cache tingkat pertama.
Perbaiki:
@Transactional void enrollStudents(Set<Long> ids) { if (ids.isEmpty()) { return; } for (Student student : jpaRepository.findAll(ids)) { enroll(student); } }
Mari kita ukur runtime (dalam mikrodetik) untuk koleksi kunci (10 dan 100 buah) Tolok ukur
KomentarJika Anda menggunakan Oracle dan memberikan lebih dari 1000 kunci untuk menemukanAll, maka Anda akan mendapatkan pengecualian ORA-01795: maximum number of expressions in a list is 1000 .
Juga, melakukan tugas yang berat (dengan banyak tombol) in kueri mungkin lebih buruk daripada n kueri. Itu semua tergantung pada aplikasi spesifik, sehingga penggantian mekanis dari siklus ke pemrosesan massal dapat menurunkan kinerja.
Contoh yang lebih kompleks tentang topik yang sama
for (Long id : ids) { Region region = jpaRepository.findOne(id); if (region == null) {
Dalam kasus ini, kami tidak dapat mengganti loop dengan JpaRepository::findAll , JpaRepository::findAll ini akan mematahkan logika: semua nilai yang diperoleh dari JpaRepository::findAll tidak akan menjadi null dan blok if tidak akan berfungsi.
Fakta bahwa untuk setiap kunci basis data akan membantu kami mengatasi kesulitan ini
mengembalikan nilai aktual atau ketidakhadirannya. Dalam arti tertentu, basis data adalah kamus. Java dari kotak memberi kami implementasi kamus yang sudah jadi - HashMap - di atasnya kami akan membangun logika untuk mengganti database:
Map<Long, Region> regionMap = jpaRepository.findAll(ids) .stream() .collect(Collectors.toMap(Region::getId, Function.identity())); for (Long id : ids) { Region region = map.get(id); if (region == null) { region = new Region(); region.setId(id); } use(region); }
Membalikkan contoh
Kode ini selalu membuat transaksi baru untuk menyimpan daftar entitas. Kendor dimulai dengan beberapa panggilan ke metode yang membuka transaksi baru:
Solusi: terapkan metode Saver::save segera untuk seluruh kumpulan data:
@Transactional public void audit(List<AuditDto> inserts) { List<AuditEntity> bulk = inserts .map(this::toEntities) .flatMap(List::stream)
Banyak transaksi bergabung menjadi satu, yang memberikan peningkatan nyata (waktu dalam mikrodetik): Tolok ukur
Contoh dengan beberapa transaksi sulit diformalkan, yang tidak dapat dikatakan tentang memanggil JpaRepository::findOne dalam satu lingkaran.
Pendekatan ini tidak hanya berlaku untuk basis data, jadi Tagir lany Valeev melangkah lebih jauh. Dan jika sebelumnya kita menulis seperti ini:
List<Long> list = new ArrayList<>(); for (Long id : items) { list.add(id); }
dan semuanya baik-baik saja, sekarang "Ide" menyarankan untuk memperbaiki dirinya sendiri:
List<Long> list = new ArrayList<>(); list.addAll(items);
Tetapi bahkan opsi ini tidak selalu memuaskannya, karena Anda dapat membuatnya lebih pendek dan lebih cepat:
List<Long> list = new ArrayList<>(items);
Bandingkan (waktu dalam ns)Untuk ArrayList, peningkatan ini memberikan peningkatan yang nyata:
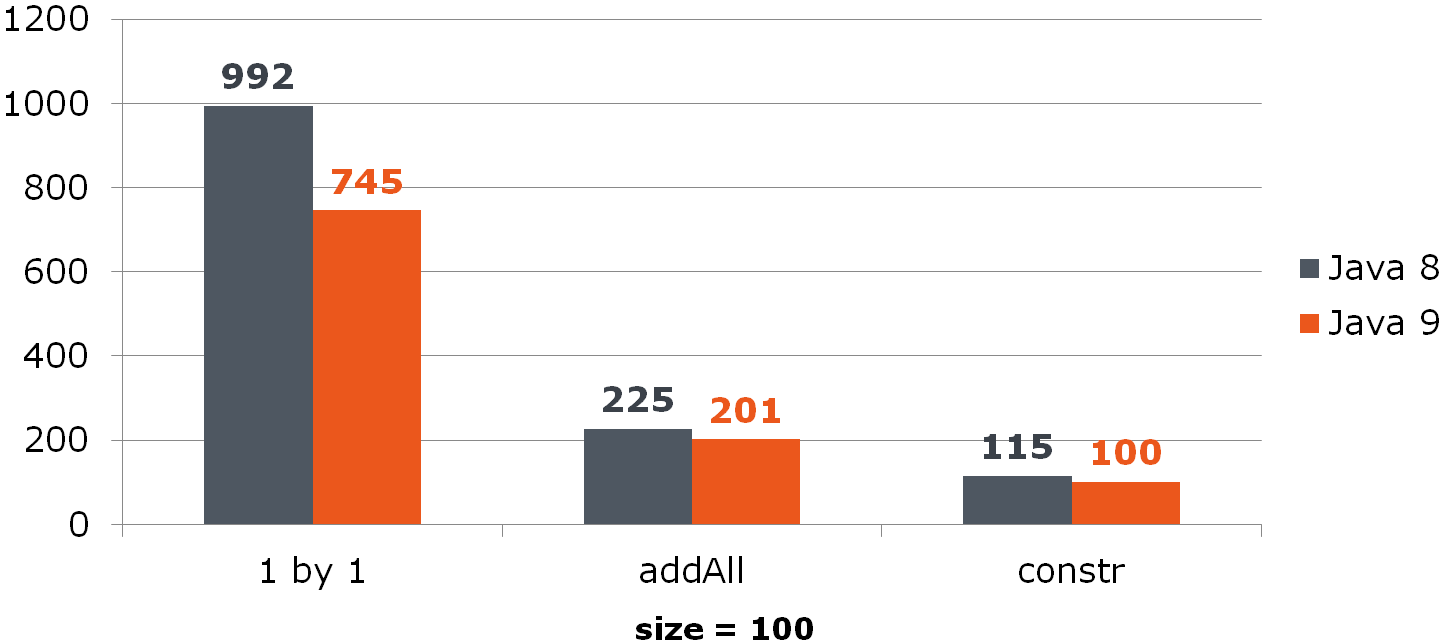
Untuk HashSet, itu tidak begitu cerah:

Tolok ukur
Menghapus dari ArrayList
for (int i = from; i < to; i++) { list.remove(from); }
Masalahnya adalah dalam mengimplementasikan metode List::remove :
public E remove(int index) { Objects.checkIndex(index, size); modCount++; E oldValue = elementData(index); int numMoved = size - index - 1; if (numMoved > 0) { System.arraycopy(array, index + 1, array, index, numMoved);
Solusi:
list.subList(from, to).clear();
Tetapi bagaimana jika nilai jarak jauh digunakan dalam kode sumber?
for (int i = from; i < to; i++) { E removed = list.remove(from); use(removed); }
Sekarang Anda harus melalui daftar yang dibersihkan terlebih dahulu:
List<String> removed = list.subList(from, to); removed.forEach(this::use); removed.clear();
Jika Anda benar-benar ingin menghapus dalam siklus, maka perubahan dalam arah perjalanan melalui daftar akan membantu meringankan rasa sakit. Artinya adalah untuk menggeser sejumlah kecil elemen setelah membersihkan sel:
Bandingkan ketiga metode (di bawah kolom adalah% item yang dihapus dari daftar ukuran 100):
Ngomong-ngomong, apakah seseorang memperhatikan anomali?
Untuk melihat
Jika kami menghapus setengah dari semua data yang bergerak dari ujung, maka elemen terakhir selalu dihapus dan tidak ada perubahan:
Tolok ukur
Kesimpulan: operasi massal seringkali lebih cepat daripada operasi tunggal.
Lingkup dan kinerja
Kode ini tidak memerlukan penjelasan khusus:
void leaveForTheSecondYear() { List<Student> naughty = repository.findNaughty(); List<Student> underAchieving = repository.findUnderAchieving();
Kami mempersempit ruang lingkup, yang memberikan kueri minus 1:
void leaveForTheSecondYear() { List<Student> naughty = repository.findNaughty(); if (Settings.leaveBothCategories()) { List<Student> underAchieving = repository.findUnderAchieving();
Dan di sini pembaca yang penuh perhatian harus bertanya: bagaimana dengan analisis statis? Mengapa Ide tidak memberi tahu kami tentang peningkatan yang terjadi di permukaan?
Faktanya adalah bahwa kemungkinan analisis statis terbatas: jika metode ini kompleks (terutama berinteraksi dengan database) dan mempengaruhi keadaan umum, maka mentransfer pelaksanaannya dapat merusak aplikasi. Analyzer statis dapat melaporkan eksekusi yang sangat sederhana, yang transfernya, katakanlah, di dalam blok tidak akan merusak apa pun.
Anda dapat menggunakan penyorotan variabel sebagai variabel, tetapi sekali lagi, gunakan dengan hati-hati, karena efek samping selalu mungkin. Anda dapat menggunakan anotasi @org.jetbrains.annotations.Contract(pure = true) , tersedia dari perpustakaan jetbrains-annotations untuk menunjukkan metode stateless :
Kesimpulan: lebih sering daripada tidak, kerja berlebihan hanya memengaruhi kinerja.
Contoh paling tidak biasa
@Service public class RemoteService { private ContractCounter contractCounter; @Transactional(readOnly = true)
Implementasi ini membuka transaksi bahkan ketika transaksi tidak diperlukan (pengembalian cepat -1 dari metode).
Yang perlu Anda lakukan adalah menghapus transaksionalitas di dalam metode ContractCounter::countContracts , di mana diperlukan, dan menghapusnya dari metode "eksternal".
Bandingkan waktu eksekusi untuk kasus ketika -1 (ns) dikembalikan: Bandingkan konsumsi memori (byte): Tolok ukur
Kesimpulan: pengontrol dan layanan yang tampak "keluar" perlu dibebaskan dari transaksionalitas (ini bukan tanggung jawab mereka) dan seluruh logika verifikasi data input, yang tidak memerlukan akses ke database dan komponen transaksional, harus diambil di sana.
Ubah tanggal / waktu menjadi string
Salah satu tugas abadi adalah mengubah tanggal / waktu menjadi string. Sebelum G8, kami melakukan ini:
SimpleDateFormat formatter = new SimpleDateFormat("dd.MM.yyyy"); String dateAsStr = formatter.format(date);
Dengan rilis JDK 8, kami mendapat LocalDate/LocalDateTime dan, karenanya, DateTimeFormatter
DateTimeFormatter formatter = ofPattern("dd.MM.yyyy"); String dateAsStr = formatter.format(localDate);
Mari kita ukur kinerjanya:
Date date = new Date(); LocalDate localDate = LocalDate.now(); SimpleDateFormat sdf = new SimpleDateFormat("dd.MM.yyyy"); DateTimeFormatter dtf = DateTimeFormatter.ofPattern("dd.MM.yyyy"); @Benchmark public String simpleDateFormat() { return sdf.format(date); } @Benchmark public String dateTimeFormatter() { return dtf.format(localDate); }
Pertanyaan: misalkan layanan kami menerima data dari luar dan kami tidak bisa menolak java.util.Date . Apakah bermanfaat bagi kita untuk mengonversi Date ke LocalDate jika yang terakhir lebih cepat dikonversi ke string? Hitung:
@Benchmark public String measureDateConverted(Data data) { LocalDate localDate = toLocalDate(data.date); return data.dateTimeFormatter.format(localDate); } private LocalDate toLocalDate(Date date) { return date.toInstant().atZone(ZoneId.systemDefault()).toLocalDate(); }
Dengan demikian, Date konversi -> LocalDate bermanfaat saat menggunakan "sembilan". Di G8, biaya konversi akan melahap semua manfaat DateTimeFormatter -a.
Tolok ukur
Kesimpulan: manfaatkan solusi baru.
"Delapan" lainnya
Dalam kode ini, kita melihat redundansi yang jelas:
Iterator<Long> iterator = items
Kami menghapusnya:
Iterator<Long> iterator = items
Mari kita lihat seberapa banyak peningkatan kinerja: Bandingkan dengan sembilan: Luar biasa bukan? Saya berpendapat di atas bahwa kelebihan kerja menurunkan kinerja. Tapi di sini kita menghapus kelebihan - dan (tiba-tiba) semakin buruk. Untuk memahami apa yang terjadi, ambil dua iterator dan lihatlah di bawah kaca pembesar:
Diungkapkan Iterator iterator1 = items.stream().collect(toList()).iterator(); Iterator iterator2 = items.stream().iterator();

Iterator pertama adalah ArrayList$Itr .
Bagian yang melaluinya sederhana: public boolean hasNext() { return cursor != size; } public E next() { checkForComodification(); int i = cursor; if (i >= size) { throw new NoSuchElementException(); } Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) { throw new ConcurrentModificationException(); } cursor = i + 1; return (E) elementData[lastRet = i]; }
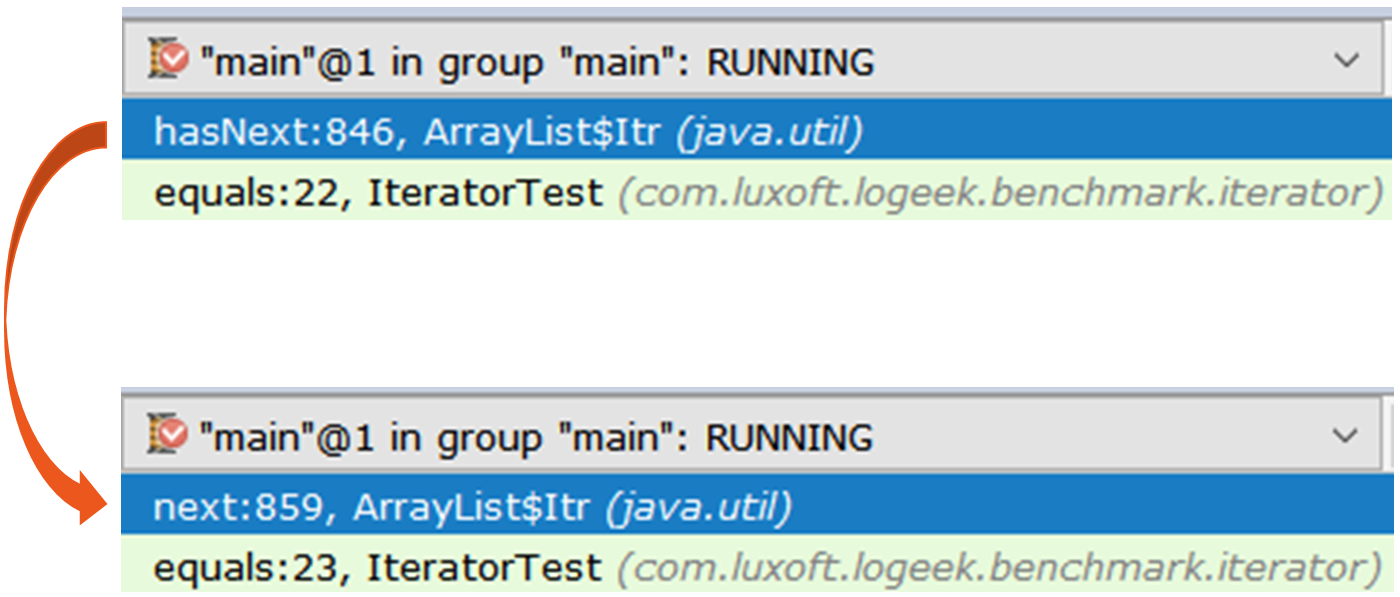
Yang kedua lebih menarik, itu adalah Spliterators$Adapter , yang didasarkan pada ArrayList$ArrayListSpliterator .
Mari kita lihat iterator iteration melalui async-profiler :
15.64% juArrayList$ArrayListSpliterator.tryAdvance 10.67% jusSpinedBuffer.clear 9.86% juSpliterators$1Adapter.hasNext 8.81% jusStreamSpliterators$AbstractWrappingSpliterator.fillBuffer 6.01% oojiBlackhole.consume 5.71% jusReferencePipeline$3$1.accept 5.57% jusSpinedBuffer.accept 5.06% cllbir.IteratorFromStreamBenchmark.iteratorFromStream 4.80% jlLong.valueOf 4.53% cllbiIteratorFromStreamBenchmark$$Lambda$8.885721577.apply
Dapat dilihat bahwa sebagian besar waktu dihabiskan untuk melewati iterator, meskipun pada umumnya, kita tidak membutuhkannya, karena pencarian dapat dilakukan seperti ini:
items .stream() .map(Long::valueOf) .forEach(bh::consume);
Bandingkan dengan yang lain: Stream::forEach jelas merupakan pemenang, tetapi ini aneh: masih berdasarkan ArrayListSpliterator , tetapi penggunaannya telah meningkat secara signifikan.
Mari kita lihat profilnya: 29.04% oojiBlackhole.consume 22.92% juArrayList$ArrayListSpliterator.forEachRemaining 14.47% jusReferencePipeline$3$1.accept 8.79% jlLong.valueOf 5.37% cllbiIteratorFromStreamBenchmark$$Lambda$9.617691115.accept 4.84% cllbiIteratorFromStreamBenchmark$$Lambda$8.1964917002.apply 4.43% jusForEachOps$ForEachOp$OfRef.accept 4.17% jusSink$ChainedReference.end 1.27% jlInteger.longValue 0.53% jusReferencePipeline.map
Dalam profil ini, sebagian besar waktu dihabiskan untuk "menelan" nilai-nilai di dalam Blackhole . Dibandingkan dengan iterator, sebagian besar waktu dihabiskan secara langsung untuk mengeksekusi kode Java. Dapat diasumsikan bahwa alasannya adalah berat spesifik yang lebih rendah dari pengumpulan sampah, dibandingkan dengan kekuatan kasar iterator. Periksa:
forEach:·gc.alloc.rate.norm 100 avgt 30 216,001 ± 0,002 B/op iteratorFromStream:·gc.alloc.rate.norm 100 avgt 30 416,004 ± 0,006 B/op
Memang, Stream::forEach menyediakan setengah konsumsi memori.
Kenapa lebih cepat?Rantai panggilan dari awal hingga lubang hitam terlihat seperti ini:
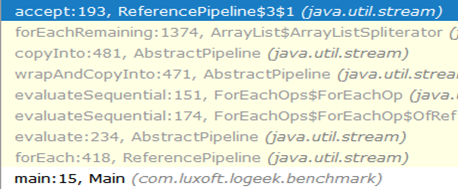
Seperti yang Anda lihat, panggilan ke ArrayListSpliterator::tryAdvance menghilang dari rantai, dan ArrayListSpliterator::forEachRemaining muncul ArrayListSpliterator::forEachRemaining :
ArrayListSpliterator::forEachRemaining kecepatan tinggi ArrayListSpliterator::forEachRemaining dicapai dengan menggunakan seluruh array dalam 1 metode panggilan. Saat menggunakan iterator, bagian ini terbatas pada satu elemen, jadi kami selalu bersandar pada ArrayListSpliterator::tryAdvance .
ArrayListSpliterator::forEachRemaining memiliki akses ke seluruh array dan ArrayListSpliterator::forEachRemaining dengan siklus penghitungan tanpa panggilan tambahan.
Pemberitahuan pentingHarap dicatat bahwa penggantian mekanik
Iterator<Long> iterator = items .stream() .map(Long::valueOf) .collect(toList()) .iterator(); while (iterator.hasNext()) { bh.consume(iterator.next()); }
pada
items .stream() .map(Long::valueOf) .forEach(bh::consume);
Itu tidak selalu setara, karena dalam kasus pertama kami menggunakan salinan data untuk bagian tanpa mempengaruhi aliran itu sendiri, dan dalam kasus kedua data diambil langsung dari aliran.
Tolok ukur
Kesimpulan: ketika berhadapan dengan representasi data yang kompleks, bersiaplah untuk fakta bahwa bahkan aturan "besi" (bahaya kerja ekstra) berhenti bekerja. Contoh di atas menunjukkan bahwa daftar perantara yang tampaknya berlebihan memberikan keuntungan dari pelaksanaan enumerasi yang lebih cepat.
Dua trik
StackTraceElement[] trace = th.getStackTrace(); StackTraceElement[] newTrace = Arrays .asList(trace) .subList(0, depth) .toArray(new StackTraceElement[newDepth]);
Hal pertama yang menarik perhatian Anda adalah "perbaikan" busuk, yaitu, melewatkan array dengan panjang nol ke metode Collection::toArray . Ini menjelaskan dengan sangat terperinci mengapa ini berbahaya.
Masalah kedua tidak begitu jelas, dan untuk pemahamannya kita dapat menarik paralel antara karya pengkaji dan sejarawan.
Inilah yang ditulis Robin Collingwood tentang ini: . :
1)
2)
3)
, :
StackTraceElement[] trace = th.getStackTrace(); StackTraceElement[] newTrace = Arrays.copyOf(trace, depth);
List<T> list = getList(); Set<T> set = getSet(); return list.stream().allMatch(set::contains);
, , :
List<T> list = getList(); Set<T> set = getSet(); return set.containsAll(list);
:
interface FileNameLoader { String[] loadFileNames(); }
:
private FileNameLoader loader; void load() { for (String str : asList(loader.loadFileNames())) {
, forEach , :
private FileNameLoader loader; void load() { for (String str : loader.loadFileNames()) {
: :
, , , . , : "" ( ), "" ( ), .
→
→