 Kami baru-baru ini berbicara tentang mengapa kami membuat segmenter RFM kami sendiri , yang membantu melakukan analisis RFM dalam 20 detik , dan menunjukkan bagaimana menggunakan hasilnya dalam pemasaran.
Kami baru-baru ini berbicara tentang mengapa kami membuat segmenter RFM kami sendiri , yang membantu melakukan analisis RFM dalam 20 detik , dan menunjukkan bagaimana menggunakan hasilnya dalam pemasaran.
Sekarang kita katakan bagaimana itu diatur.
Tugas: tulis algoritma analisis RFM baru
Kami tidak puas dengan pendekatan yang tersedia untuk analisis RFM. Karena itu, kami memutuskan untuk membuat segmenter sendiri, yang:
- Ini berfungsi sepenuhnya secara otomatis.
- Dibangun dari 3 hingga 15 segmen.
- Beradaptasi dengan bidang aktivitas apa pun dari klien (tidak peduli apa pun itu: toko bunga atau perkakas listrik).
- Ini menentukan jumlah dan lokasi segmen berdasarkan data yang tersedia, dan bukan parameter yang telah ditentukan yang tidak bisa universal.
- Itu memilih segmen sehingga mereka selalu memiliki konsumen (tidak seperti beberapa pendekatan ketika beberapa segmen kosong).
Bagaimana mengatasi masalah tersebut
Ketika kami menyadari tugas itu, kami menyadari bahwa itu di luar kekuatan manusia, dan meminta bantuan dari kecerdasan buatan. Untuk mengajarkan mobil membagi konsumen menjadi segmen, kami memutuskan untuk menggunakan metode pengelompokan .
Metode pengelompokan digunakan untuk mencari struktur dalam data dan memilih kelompok objek serupa di dalamnya - hanya apa yang Anda butuhkan untuk analisis RFM.
Clustering mengacu pada metode pembelajaran mesin dari kelas " belajar tanpa guru ." Kelas disebut seperti itu karena ada data, tetapi tidak ada yang tahu apa yang harus dilakukan dengannya, oleh karena itu tidak dapat mengajarkan mesin.
Kami tidak dapat menemukan perusahaan yang menggunakan pendekatan ini di pasar. Meskipun mereka menemukan satu artikel di mana penulis melakukan penelitian ilmiah tentang topik ini. Tapi, seperti yang kita pahami dari pengalaman kita sendiri, dari sains ke bisnis sama sekali bukan satu langkah.
Tahap 1. Pemrosesan Data
Data perlu disiapkan untuk pengelompokan.
Pertama, kami memeriksanya untuk nilai yang salah: nilai negatif, dll.
Lalu kami menghilangkan emisi - konsumen dengan karakteristik yang tidak biasa. Ada beberapa dari mereka, tetapi mereka dapat sangat mempengaruhi hasilnya, dan tidak menjadi lebih baik. Untuk memisahkan mereka, kami menggunakan metode pembelajaran mesin khusus - Local Outlier Factor .

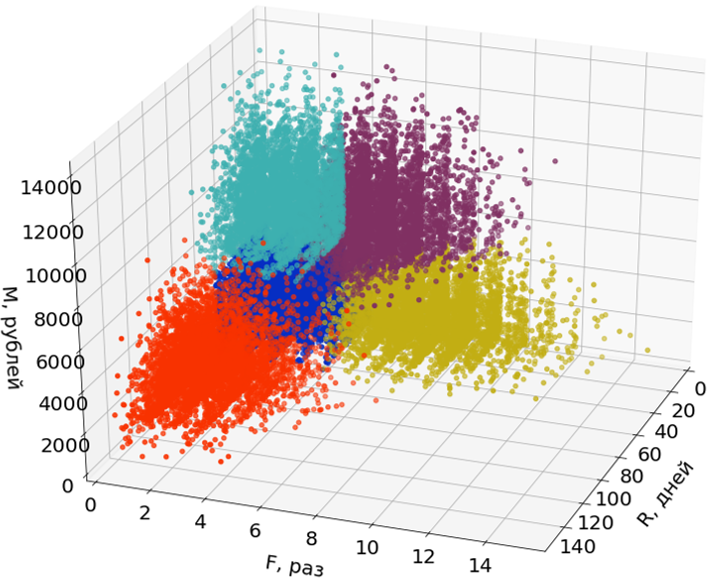
Di sini, di gambar saya hanya menggunakan dua dari tiga dimensi (R dan M) dari tiga untuk memfasilitasi persepsi.
Emisi tidak berpartisipasi dalam pembangunan segmen, tetapi dialokasikan untuk mereka setelah segmen terbentuk.
Tahap 2. Clustering Konsumen
Saya akan mengklarifikasi terminologinya: dengan kluster saya maksudkan kelompok objek yang diperoleh sebagai hasil dari penggunaan algoritma pengelompokan, dan segmen sebagai hasil akhir, yaitu, hasil analisis RFM.
Ada beberapa lusin algoritma pengelompokan. Contoh beberapa di antaranya dapat ditemukan di dokumentasi paket scikit-learn .
Kami mencoba delapan algoritma dengan berbagai modifikasi. Sebagian besar tidak memiliki cukup memori. Atau waktu kerja mereka cenderung tak terbatas. Hampir semua algoritma yang secara teknis berhasil mengatasi tugas tersebut memberikan hasil yang mengerikan: misalnya, DBSCAN yang populer menganggap 55% objek sebagai noise, dan membagi sisanya menjadi 4302 cluster.
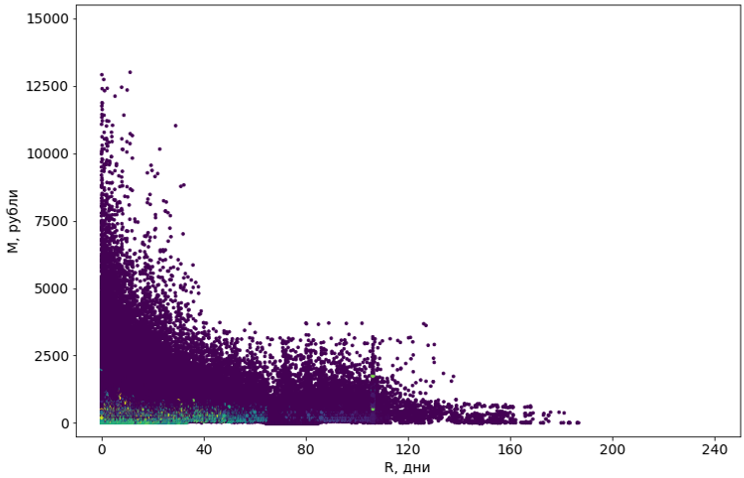
Objek Violet didefinisikan sebagai "noise"
Akibatnya, kami memilih algoritma K-Means (K-means) karena tidak mencari kelompok titik, tetapi hanya mengelompokkan titik-titik di sekitar pusat. Ternyata, ini adalah keputusan yang tepat.
Tetapi pertama-tama, kami memecahkan beberapa masalah:
Ketidakstabilan. Ini adalah masalah yang diketahui dengan sebagian besar algoritma pengelompokan, termasuk K-Means. Ketidakstabilan terletak pada fakta bahwa dengan peluncuran berulang, hasilnya bisa berbeda, karena unsur keacakan digunakan.
Oleh karena itu, kami mengelompokkan berkali-kali, dan kemudian mengelompokkan lagi, tetapi sudah menjadi pusat dari kluster. Sebagai pusat akhir dari cluster, kami mengambil pusat dari cluster yang dihasilkan (yaitu, cluster yang dibentuk oleh pusat dari cluster pertama).
Jumlah cluster. Data dapat berbeda, dan jumlah cluster juga harus berbeda.
Untuk menemukan jumlah cluster yang optimal untuk setiap basis pelanggan, kami melakukan clustering dengan jumlah cluster yang berbeda, dan kemudian memilih hasil terbaik .
Kecepatan. Algoritma K-means tidak terlalu cepat, tetapi dapat diterima (beberapa menit untuk basis rata-rata beberapa ratus ribu konsumen). Namun, kami menjalankannya berkali-kali: pertama, untuk meningkatkan stabilitas, dan kedua, untuk memilih jumlah cluster. Dan waktu operasi meningkat sangat banyak.
Untuk akselerasi, kami menggunakan modifikasi Mini Batch K-Means . Ini menghitung ulang pusat cluster di setiap iterasi tidak untuk semua objek, tetapi hanya untuk subsampel kecil. Kualitas turun cukup sedikit, tetapi waktu berkurang secara signifikan.
Segera setelah kami menyelesaikan masalah ini, pengelompokan mulai berjalan dengan sukses.
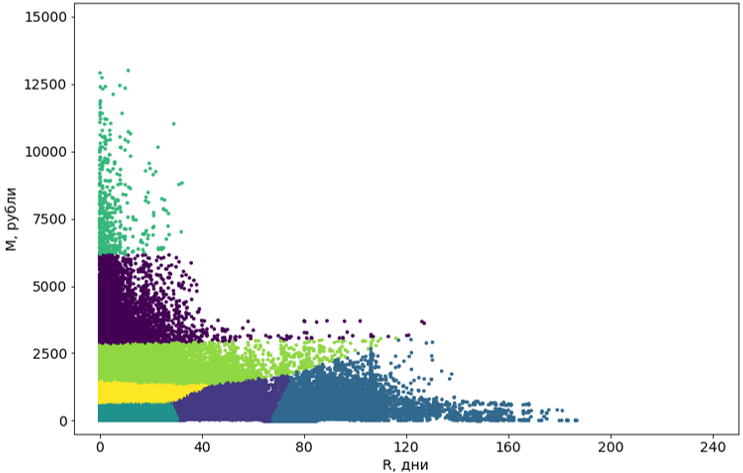
Tahap 3. Pasca-pemrosesan cluster
Cluster yang diperoleh dengan menggunakan algoritma harus dibawa ke bentuk yang nyaman untuk persepsi.
Pertama, kami mengubah kelompok ini dari kurva menjadi yang persegi panjang. Sebenarnya, ini membuat mereka segmen. Persegi panjang segmen adalah persyaratan sistem kami dan, di samping itu, menambah pemahaman untuk segmen itu sendiri. Untuk mengkonversi, kami menggunakan algoritma pembelajaran mesin lain - pohon keputusan .
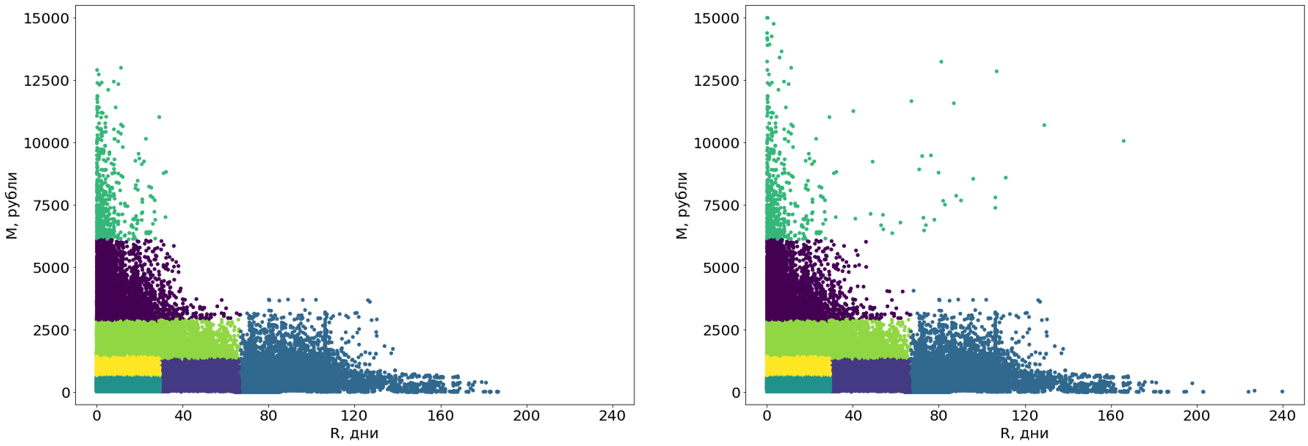
Pohon keputusan dibangun berdasarkan data bebas-outlier, dan outlier kemudian dialokasikan ke segmen yang sudah selesai
Kedua, kami melakukan hal keren lainnya - deskripsi segmen. Algoritma khusus, menggunakan kamus, menggambarkan setiap segmen dalam bahasa Rusia langsung, sehingga orang tidak merasa rindu ketika melihat angka tanpa jiwa.

Hasil Pengujian
Produk sudah siap. Tetapi sebelum Anda mulai menjualnya perlu diuji. Yaitu, periksa apakah analisis RFM dilakukan seperti yang kita maksudkan.
Kami tahu bahwa cara terbaik untuk memahami jika kami telah melakukan sesuatu yang bermanfaat adalah untuk mengetahui seberapa berguna analisis ini bagi klien kami. Dan kami akan melakukannya. Tapi ini waktu yang lama, dan hasilnya nanti, dan kami ingin tahu seberapa sukses kami mengatasi tugas itu, sekarang.
Oleh karena itu, sebagai metrik yang lebih sederhana dan lebih cepat, kami menggunakan metode "kelompok kontrol historis".
Untuk melakukan ini, kami mengambil beberapa basis data dan mengelompokkannya menggunakan analisis RFM di berbagai titik di masa lalu: satu basis data untuk negara bagian enam bulan lalu, yang lain satu tahun lalu, dll.
Berdasarkan setiap segmentasi untuk setiap basis, kami membangun perkiraan tindakan pelanggan kami dari saat yang dipilih hingga saat ini. Kemudian mereka membandingkan ramalan ini dengan perilaku pelanggan yang sebenarnya.

Contoh pengujian pada kelompok kontrol historis dengan periode kontrol enam bulan
Dalam gambar:
- Kolom R, F dan M secara konvensional menunjukkan batas-batas segmen di sepanjang setiap sumbu. Ini adalah hasil dari segmentasi dasar dalam bentuk yang setengah tahun lalu.
- Kolom "Ukuran" menunjukkan ukuran segmen enam bulan lalu relatif terhadap ukuran total database.
- Kolom “Kemungkinan Pembelian” dan “Jumlah” adalah data tentang perilaku konsumen nyata selama enam bulan ke depan.
- Probabilitas pembelian didefinisikan sebagai rasio jumlah konsumen dari segmen yang melakukan pembelian terhadap jumlah total konsumen di segmen tersebut.
- Jumlah - jumlah total yang dihabiskan oleh konsumen dari segmen relatif terhadap jumlah yang dihabiskan oleh konsumen dari semua segmen.
Hasilnya konsisten. Misalnya, pelanggan dari segmen yang kami perkirakan memiliki frekuensi pembelian yang tinggi sebenarnya membeli lebih sering.
Meskipun kami tidak dapat menjamin operasi yang benar dari algoritma sebesar 100 persen berdasarkan pengujian tersebut, kami memutuskan bahwa itu berhasil.
Apa yang kita mengerti
Pembelajaran mesin benar-benar mampu membantu bisnis memecahkan masalah yang tidak dapat diselesaikan atau sangat tidak terpecahkan.
Namun tantangan sebenarnya bukanlah persaingan Kaggle. Di sini, selain mencapai kualitas yang lebih baik dalam metrik yang diberikan, Anda perlu memikirkan tentang seberapa banyak algoritma akan bekerja, apakah akan nyaman bagi orang-orang dan, secara umum, apakah perlu untuk menyelesaikan masalah menggunakan ML atau Anda dapat menemukan dengan cara yang lebih sederhana.
Dan akhirnya, kurangnya metrik kualitas formal mempersulit tugas beberapa kali, karena sulit untuk mengevaluasi hasilnya dengan benar.