Dalam dunia pembelajaran mesin, salah satu jenis model yang paling populer adalah pohon yang menentukan dan ansambel berdasarkan pada mereka. Kelebihan pohon adalah: kemudahan interpretasi, tidak ada batasan pada jenis ketergantungan awal, persyaratan lunak pada ukuran sampel. Pohon juga memiliki kelemahan utama - kecenderungan untuk berlatih kembali. Oleh karena itu, hampir selalu pohon digabungkan menjadi ansambel: hutan acak, peningkatan gradien, dll. Tugas teoritis dan praktis yang kompleks adalah menyusun pohon dan menggabungkannya menjadi ansambel.
Dalam artikel yang sama, kami akan mempertimbangkan prosedur untuk menghasilkan prediksi dari model ansambel pohon yang sudah terlatih, fitur implementasi dalam gradien meningkatkan
XGBoost populer
XGBoost dan
LightGBM . Dan juga pembaca akan berkenalan dengan perpustakaan
leaves untuk Go, yang memungkinkan Anda membuat prediksi untuk ansambel pohon tanpa menggunakan API C dari perpustakaan asli.
Dari mana pohon itu tumbuh?
Pertimbangkan dulu ketentuan umum. Mereka biasanya bekerja dengan pohon, di mana:
- partisi dalam sebuah node terjadi sesuai dengan satu fitur
- pohon biner - setiap node memiliki keturunan kiri dan kanan
- dalam kasus atribut material, aturan keputusan terdiri dari membandingkan nilai atribut dengan nilai ambang batas
Saya mengambil ilustrasi ini dari
dokumentasi XGBoost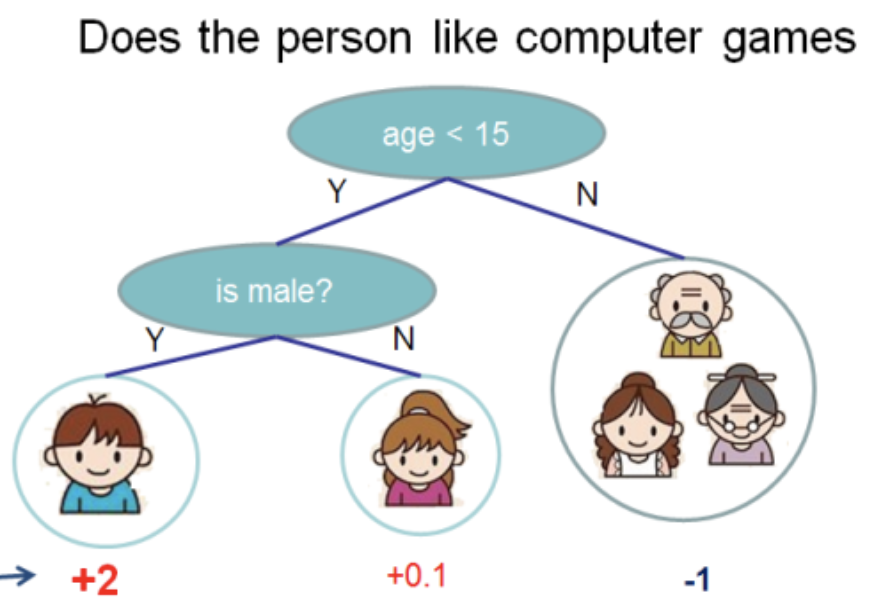
Di pohon ini kami memiliki 2 node, 2 aturan keputusan, dan 3 lembar. Di bawah lingkaran, nilai ditunjukkan - hasil menerapkan pohon ke beberapa objek. Biasanya, fungsi transformasi diterapkan pada hasil komputasi pohon atau ansambel pohon. Misalnya,
sigmoid untuk masalah klasifikasi biner.
Untuk mendapatkan prediksi dari ansambel pohon yang diperoleh dengan gradient boosting, Anda perlu menambahkan hasil prediksi semua pohon:
double pred = 0.0; for (auto& tree: trees) pred += tree->Predict(feature_values);
Selanjutnya, akan ada
C++ , sebagai dalam bahasa inilah
XGBoost dan
LightGBM ditulis. Saya akan menghilangkan detail yang tidak relevan dan mencoba memberikan kode yang paling ringkas.
Selanjutnya, pertimbangkan apa yang disembunyikan di
Predict dan bagaimana struktur data pohon terstruktur.
Pohon XGBoost
XGBoost memiliki beberapa kelas (dalam arti OOP) pohon. Kita akan berbicara tentang
RegTree (lihat
include/xgboost/tree_model.h ), yang, menurut dokumentasi, adalah yang utama. Jika Anda hanya meninggalkan detail yang penting untuk prediksi, maka anggota kelas terlihat sesederhana mungkin:
class RegTree {
Aturan
GetNext diimplementasikan dalam fungsi
GetNext . Kode sedikit dimodifikasi, tanpa mempengaruhi hasil perhitungan:
Dua hal mengikuti dari sini:
RegTree hanya berfungsi dengan atribut nyata (tipe float )- nilai-nilai karakteristik yang dilewati didukung
Pusatnya adalah kelas
Node . Ini berisi struktur lokal pohon, aturan keputusan dan nilai lembar:
class Node { public:
Fitur-fitur berikut dapat dibedakan:
- sheet direpresentasikan sebagai node yang
cleft_ = -1 - bidang
info_ direpresentasikan sebagai union , mis. dua jenis data (dalam hal ini sama) berbagi satu keping memori tergantung pada jenis simpul - bit paling signifikan dalam
sindex_ bertanggung jawab atas objek yang nilai atributnya dilewati
Agar dapat melacak lintasan dari memanggil metode
RegTree::Predict hingga menerima jawabannya, saya akan memberikan dua fungsi yang hilang:
float RegTree::Predict(const RegTree::FVec& feat, unsigned root_id) const { int pid = this->GetLeafIndex(feat, root_id); return nodes_[pid].leaf_value; } int RegTree::GetLeafIndex(const RegTree::FVec& feat, unsigned root_id) const { auto pid = static_cast<int>(root_id); while (!nodes_[pid].IsLeaf()) { unsigned split_index = nodes_[pid].SplitIndex(); pid = this->GetNext(pid, feat.Fvalue(split_index), feat.IsMissing(split_index)); } return pid; }
Dalam fungsi
GetLeafIndex kita turun simpul pohon dalam satu lingkaran sampai kita menekan daun.
Pohon LightGBM
LightGBM tidak memiliki struktur data untuk node. Sebagai gantinya, struktur data pohon
Tree (
include/LightGBM/tree.h file
include/LightGBM/tree.h ) berisi array nilai, di mana nomor simpul digunakan sebagai indeks. Nilai dalam daun juga disimpan dalam array yang terpisah.
class Tree {
LightGBM mendukung fitur-fitur kategorikal. Dukungan diberikan menggunakan bidang bit, yang disimpan di
cat_threshold_ untuk semua node. Dalam
cat_boundaries_ menyimpan ke simpul mana bagian dari bidang bit yang sesuai. Bidang
threshold_ untuk kasus kategorikal dikonversi ke
int dan sesuai dengan indeks dalam
cat_boundaries_ untuk mencari awal bidang bit.
Pertimbangkan aturan yang menentukan untuk atribut kategorikal:
int CategoricalDecision(double fval, int node) const { uint8_t missing_type = GetMissingType(decision_type_[node]); int int_fval = static_cast<int>(fval); if (int_fval < 0) { return right_child_[node];; } else if (std::isnan(fval)) {
Dapat dilihat bahwa, tergantung pada
missing_type nilai
NaN secara otomatis menurunkan solusi di sepanjang cabang kanan pohon. Jika tidak,
NaN diganti dengan 0. Mencari nilai dalam bidang bit cukup sederhana:
bool FindInBitset(const uint32_t* bits, int n, int pos) { int i1 = pos / 32; if (i1 >= n) { return false; } int i2 = pos % 32; return (bits[i1] >> i2) & 1; }
mis., misalnya, untuk atribut kategorikal
int_fval=42 diperiksa apakah bit ke-41 (penomoran dari 0) diatur dalam array.
Pendekatan ini memiliki satu kelemahan signifikan: jika atribut kategorikal dapat mengambil nilai besar, misalnya 100500, maka untuk setiap aturan keputusan untuk atribut ini bidang bit akan dibuat hingga ukuran 12564 byte!
Oleh karena itu, diinginkan untuk memberi nomor baru pada nilai atribut kategorikal sehingga mereka terus menerus dari 0 ke nilai maksimum .
Untuk bagian saya, saya membuat perubahan jelas ke
LightGBM dan
menerimanya .
Berurusan dengan atribut fisik tidak jauh berbeda dari
XGBoost , dan saya akan melewatkan ini untuk singkatnya.
leaves - library untuk prediksi di Go
XGBoost dan
LightGBM perpustakaan
LightGBM sangat kuat untuk membangun model
LightGBM gradien pada pohon keputusan. Untuk menggunakannya dalam layanan backend, di mana algoritma pembelajaran mesin diperlukan, perlu untuk menyelesaikan tugas-tugas berikut:
- Pelatihan berkala model offline
- Pengiriman model dalam layanan backend
- Model jajak pendapat online
Untuk menulis layanan backend yang dimuat,
Go adalah bahasa yang populer.
XGBoost atau
LightGBM melalui API C dan cgo bukan solusi termudah - pembuatan program ini rumit, karena penanganan yang ceroboh, Anda dapat menangkap
SIGTERM , masalah dengan jumlah utas sistem (OpenMP di dalam perpustakaan vs utas runtime utas).
Jadi saya memutuskan untuk menulis perpustakaan di
Go murni untuk prediksi menggunakan model yang dibangun di
XGBoost atau
LightGBM . Ini disebut
leaves .

Fitur utama perpustakaan:
- Untuk model
LightGBM
- Membaca model dari format standar (teks)
- Dukungan untuk atribut fisik dan kategorikal
- Dukungan Nilai Hilang
- Optimalisasi kerja dengan variabel kategori
- Optimasi Prediksi dengan Struktur Data Hanya-Prediksi
- Untuk model
XGBoost
- Membaca model dari format standar (biner)
- Dukungan Nilai Hilang
- Optimasi Prediksi
Berikut adalah program
Go minimal yang memuat model dari disk dan menampilkan prediksi:
package main import ( "bufio" "fmt" "os" "github.com/dmitryikh/leaves" ) func main() {
API perpustakaan minimal. Untuk menggunakan model
XGBoost cukup panggil metode
leaves.XGEnsembleFromReader alih-alih yang di atas. Prediksi dapat dibuat dalam batch dengan memanggil metode
PredictDense atau
PredictDense . Lebih banyak skenario penggunaan dapat ditemukan dalam
tes daun .
Terlepas dari kenyataan bahwa
Go berjalan lebih lambat daripada
C++ (terutama karena pemeriksaan runtime dan runtime yang lebih berat), berkat sejumlah optimisasi, dimungkinkan untuk mencapai tingkat prediksi yang sebanding dengan memanggil API C dari perpustakaan asli.
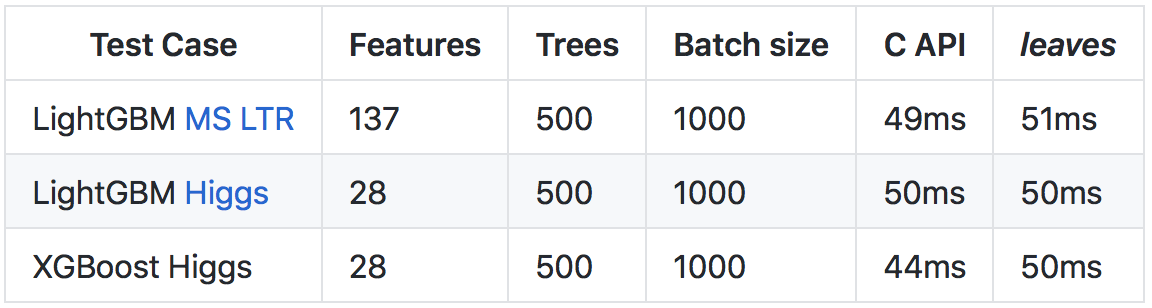
Rincian lebih lanjut tentang hasil dan metode perbandingan ada di
repositori di github .
Lihat akarnya
Saya harap artikel ini membuka pintu bagi implementasi pohon di
XGBoost dan
LightGBM . Seperti yang Anda lihat, konstruksi dasarnya cukup sederhana, dan saya mendorong pembaca untuk memanfaatkan open source - untuk mempelajari kode ketika ada pertanyaan tentang cara kerjanya.
Bagi mereka yang tertarik pada topik menggunakan model meningkatkan gradien dalam layanan mereka dalam bahasa Go, saya sarankan Anda membiasakan diri dengan perpustakaan
daun . Dengan menggunakan
leaves Anda dapat dengan mudah menggunakan solusi terdepan dalam pembelajaran mesin di lingkungan produksi Anda, hampir tanpa kehilangan kecepatan dibandingkan dengan implementasi C ++ asli.
Semoga beruntung