 Terjemahan artikel: Aturan Eksperimen Jempol
Terjemahan artikel: Aturan Eksperimen JempolPemilik portal web, dari yang terkecil hingga yang terbesar, seperti Amazon, Facebook, Google, LinkedIn, Microsoft dan Yahoo, mencoba meningkatkan situs mereka dengan mengoptimalkan berbagai metrik, dari jumlah waktu yang digunakan kembali hingga waktu dan pendapatan mereka. Kami telah tertarik pada ribuan percobaan di Amazon, Booking.com, LinkedIn dan Microsoft, dan kami ingin berbagi tujuh aturan praktis yang kami simpulkan dari percobaan ini dan hasilnya. Kami percaya bahwa aturan ini dapat diterapkan secara luas baik saat mengoptimalkan web, dan selama analisis di luar eksperimen kontrol. Meski ada pengecualian.
Untuk membuat aturan ini lebih signifikan, kami akan memberikan contoh nyata dari pekerjaan kami, yang sebagian besar akan diterbitkan untuk pertama kalinya. Beberapa aturan telah disuarakan sebelumnya (misalnya, "Masalah kecepatan"), tetapi kami menambahkannya dengan asumsi yang dapat digunakan dalam merancang eksperimen, dan berbagi contoh tambahan yang meningkatkan pemahaman kami tentang di mana kecepatan sangat penting dan di area mana di web halaman itu tidak kritis.
Artikel ini memiliki dua tujuan.
Pertama : ajari para peneliti aturan tentang selera yang baik, yang akan membantu mengoptimalkan situs.
Kedua : untuk memberi komunitas KDD topik baru untuk mengeksplorasi penerapan aturan-aturan ini, perbaikannya dan keberadaan pengecualian.
Pendahuluan
Pemilik portal web dari yang terkecil hingga raksasa terbesar berusaha meningkatkan situs mereka. Perusahaan-perusahaan terkemuka menggunakan tes benchmarking (seperti tes A / B) untuk mengevaluasi perubahan. Ini dilakukan oleh Amazon [1], Ebay, Etsy [2], Facebook [3], Google [4], Groupon, Intuit [5], LinkedIn [6], Microsoft [7], Netflix [8], ShopDirect [9] , Yahoo, dan Zynga [10].
Kami telah memperoleh pengalaman dalam optimasi situs web, bekerja dengan banyak perusahaan, termasuk Amazon, Booking.com, LinkedIn dan Microsoft. Misalnya, Bing dan LinkedIn melakukan ratusan percobaan paralel pada waktu tertentu [6; 11]. Karena keragaman dan beragamnya eksperimen yang kami ikuti, aturan praktis telah dikembangkan, yang akan kami diskusikan di sini. Mereka dikonfirmasi oleh proyek nyata, tetapi ada pengecualian untuk aturan apa pun (kami juga akan membicarakannya). Misalnya, aturan 72 adalah contoh yang baik dari aturan praktis yang berguna di bidang keuangan. Ia mengklaim bahwa Anda perlu melipatgandakan persentase pertumbuhan tahunan sebesar 72 untuk secara kasar menentukan berapa tahun Anda akan menggandakan investasi Anda. Dalam situasi normal, aturan ini sangat berguna (ketika tingkat bunga berfluktuasi antara 4 dan 12%), tetapi di daerah lain tidak berfungsi.
Karena aturan ini dirumuskan sesuai dengan hasil eksperimen kontrol, mereka berlaku untuk optimasi situs dan analisis sederhana, bahkan jika eksperimen kontrol tidak dilakukan di situs (walaupun dalam kasus ini tidak akan mungkin untuk secara akurat menilai efek dari perubahan yang dibuat).
Apa yang akan Anda temukan di artikel ini:
- Aturan yang berguna untuk bereksperimen dengan situs web. Mereka masih berkembang, dan kita perlu menilai luasnya aplikasi mereka dan mencari tahu apakah ada pengecualian baru untuk aturan ini. Pentingnya menggunakan eksperimen kontrol dibahas dalam artikel "Eksperimen Terkontrol Online pada Skala Besar" [11]
- Perbaikan aturan sebelumnya. Pengamatan seperti "masalah kecepatan" telah disuarakan oleh penulis lain [12; 13] dan kami [14]. Tetapi kami membuat beberapa asumsi ketika merancang percobaan, dan kami akan berbicara tentang studi yang menunjukkan bahwa di beberapa area halaman, kecepatan sangat penting, dan yang lain tidak. Kami juga memperbaiki aturan lama "ribuan pengguna", yang menjawab pertanyaan tentang berapa banyak orang yang diperlukan untuk melakukan eksperimen kontrol.
- Contoh nyata dari eksperimen kontrol dipublikasikan untuk pertama kali. Di Amazon, Bing, dan LinkedIn, eksperimen kontrol digunakan sebagai bagian dari proses pengembangan [7; 11]. Banyak perusahaan yang masih tidak menggunakan eksperimen kontrol dapat sangat diuntungkan dari contoh tambahan bekerja dengan perubahan dengan pengenalan paradigma pengembangan baru [7, 15]. Perusahaan yang sudah menggunakan eksperimen kontrol akan mendapat manfaat dari wawasan yang dijelaskan.
Kontrol eksperimen, data, dan proses mengekstraksi pengetahuan dari data
Kami akan membahas di sini mengontrol eksperimen online di mana pengguna dibagi menjadi beberapa kelompok secara acak (misalnya, untuk menampilkan berbagai opsi situs). Selain itu, pembagian tersebut dilakukan secara berkelanjutan, yaitu, setiap pengguna akan memiliki pengalaman yang sama selama percobaan (ia akan selalu ditampilkan versi situs yang sama). Interaksi pengguna dengan situs (klik, tampilan halaman, dll.) Direkam, dan metrik kunci (RKT, jumlah sesi per pengguna, pendapatan dari pengguna) dihitung berdasarkan basisnya. Tes statistik dilakukan untuk menganalisis metrik yang dihitung. Dan jika perbedaan antara metrik grup kontrol (yang melihat versi lama situs) dan eksperimental (yang melihat versi baru) dari grup adalah signifikan secara statistik, maka kita juga dapat mengatakan dengan probabilitas tinggi bahwa perubahan yang dilakukan akan memengaruhi metrik yang diamati dalam percobaan. Rinciannya dijelaskan dalam "Eksperimen terkendali di web: survei dan panduan praktis" [16].
Kami berpartisipasi dalam banyak percobaan yang hasilnya salah, dan menghabiskan banyak waktu dan upaya untuk memahami alasannya dan menemukan cara untuk memperbaikinya. Banyak perangkap dijelaskan dalam artikel [17] dan [18]. Kami ingin menyoroti beberapa pertanyaan tentang data yang digunakan dalam melakukan eksperimen kontrol online, dan tentang proses memperoleh pengetahuan dari data ini:
- Sumber data adalah situs nyata yang kita bicarakan di atas. Tidak akan ada informasi yang dihasilkan secara artifisial. Semua contoh didasarkan pada interaksi pengguna nyata, dan metrik dihitung setelah menghapus bot [16].
- Grup pengguna dalam contoh diambil secara acak dari distribusi seragam dari target audiens (yaitu, pengguna yang, misalnya, harus mengklik tautan untuk melihat perubahan yang sedang dipelajari) [16]. Metode identifikasi pengguna tergantung pada situs: jika pengguna tidak login, cookie digunakan, dan jika dia login, maka loginnya digunakan.
- Ukuran grup pengguna, setelah membersihkan bot, berkisar dari ratusan ribu hingga jutaan (nilai yang tepat ditunjukkan dalam contoh). Dalam sebagian besar percobaan, ini diperlukan agar perbedaan kecil dalam metrik memiliki signifikansi statistik yang tinggi.
- Hasil yang dicatat secara statistik signifikan pada nilai-p <0,05, dan biasanya bahkan lebih sedikit. Hasil yang luar biasa (dalam aturan 1) direproduksi setidaknya sekali lagi, sehingga nilai p kumulatif berdasarkan uji probabilitas kumulatif Fisher memiliki nilai jauh lebih sedikit dari yang diperlukan.
- Setiap percobaan adalah pengalaman pribadi kami, diverifikasi oleh setidaknya salah satu penulis untuk keberadaan perangkap standar. Setiap percobaan dilakukan setidaknya selama seminggu. Bagian pemirsa yang mendemonstrasikan opsi situs stabil selama seluruh periode percobaan (untuk menghindari efek paradoks Simpson) dan rasio antara pemirsa yang kami amati selama percobaan bertepatan dengan rasio yang kami tetapkan ketika percobaan diluncurkan [17].
Aturan praktis untuk eksperimen
Tiga aturan pertama terkait dengan dampak perubahan pada metrik utama:
- perubahan kecil dapat memiliki dampak besar;
- perubahan jarang memiliki efek positif yang besar;
- upaya Anda untuk mengulang kesuksesan bintang yang diumumkan oleh orang lain lebih mungkin kurang berhasil.
4 aturan berikut ini tidak tergantung satu sama lain, tetapi masing-masing sangat berguna.
Aturan # 1: perubahan kecil dapat berdampak besar pada metrik utama
Siapa pun yang menemukan kehidupan situs tahu bahwa setiap perubahan kecil dapat memiliki dampak negatif besar pada metrik utama. Kesalahan JavaScript kecil dapat membuat pembayaran menjadi tidak mungkin, dan bug kecil yang menghancurkan tumpukan dapat menyebabkan server mogok. Tetapi kami akan fokus pada perubahan positif dalam metrik utama. Berita baiknya adalah ada banyak contoh di mana perubahan kecil telah menyebabkan peningkatan metrik utama. Bryan Eisenberg menulis bahwa menghapus bidang input kupon pada formulir pembelian meningkatkan konversi sebesar 1000% di situs web Doctor Footcare [20]. Jared Spool menulis bahwa menghapus persyaratan untuk mendaftar pada saat pembelian membawa pengecer besar $ 300 juta per tahun [21].
Namun demikian, kami tidak melihat perubahan signifikan dalam proses percobaan yang dilakukan secara pribadi. Tetapi kami melihat peningkatan yang signifikan dari perubahan kecil dengan pengembalian investasi yang sangat tinggi (rasio laba yang tinggi terhadap biaya usaha yang diinvestasikan).
Kami juga ingin mencatat bahwa kami sedang membahas efek yang distabilkan, bukan “flash on the Sun” atau fitur dengan berita khusus / efek viral. Contoh dari sesuatu yang tidak kita cari dijelaskan dalam buku Ya!: 50 cara ilmiah terbukti persuasif [22]. Collen Szot, penulis acara televisi yang memecahkan rekor penjualan selama 20 tahun di saluran TV Couch Store, mengganti tiga kata di bar ticker informasi standar, yang menyebabkan lompatan besar dalam jumlah pembelian. Alih-alih frasa "Operator menunggu, silakan hubungi sekarang", Collen menyimpulkan "jika operator sibuk, hubungi kembali lagi." Para penulis menjelaskan ini dengan bukti sosiologis berikut: pemirsa berpikir bahwa jika salurannya sibuk, maka orang-orang seperti mereka yang menonton saluran berita juga menelepon.
Jika trik seperti yang disebutkan di atas digunakan secara teratur, maka efeknya diratakan, karena pengguna terbiasa dengannya. Dalam percobaan kontrol dalam kasus seperti itu, efeknya dengan cepat menghilang. Karena itu, kami menyarankan Anda melakukan percobaan selama setidaknya dua minggu dan memantau dinamika. Meskipun dalam praktiknya, hal-hal seperti itu jarang terjadi [11; 18]. Situasi di mana kami mengamati efek positif dari dampak perubahan tersebut dikaitkan dengan sistem rekomendasi ketika perubahan itu sendiri memberikan efek jangka pendek atau ketika sumber daya final digunakan untuk diproses.
Misalnya, ketika LinkedIn mengubah algoritme fitur "orang yang mungkin Anda kenal", itu hanya menghasilkan lonjakan satu kali dalam metrik klik. Selain itu, bahkan jika algoritma bekerja jauh lebih baik, maka setiap pengguna tahu jumlah orang yang terbatas, dan setelah dia menghubungi kenalan utamanya, efek dari setiap algoritma baru akan turun.
Contoh: Membuka tautan di tab baru. Serangkaian tiga percobaan
Pada Agustus 2008, MSN UK melakukan percobaan untuk lebih dari 900.000 pengguna, di mana tautan ke HotMail dibuka di tab baru (atau jendela baru di peramban lama). Kami sebelumnya melaporkan [7] bahwa perubahan minimal ini (satu baris kode) menyebabkan peningkatan keterlibatan pengguna MSN. Keterlibatan, diukur dalam jumlah klik per pengguna di halaman beranda, tumbuh sebesar 8,9% di antara pengguna yang mengklik HotMail.
Pada Juni 2010, kami mereproduksi percobaan pada audiens 2,7 juta pengguna MSN di Amerika Serikat, dan hasilnya serupa. Bahkan, ini juga merupakan contoh fitur dengan efek kebaruan. Pada hari pertama peluncurannya ke semua pengguna, 20% ulasan negatif. Pada minggu kedua, bagian yang tidak puas turun menjadi 4%, dan selama minggu ketiga dan keempat - menjadi 2%. Peningkatan dalam metrik kunci telah stabil selama ini.
Pada April 2011, MSN di Amerika Serikat melakukan percobaan yang sangat besar dengan lebih dari 12 juta pengguna yang membuka halaman dengan hasil pencarian di tab baru. Keterlibatan, diukur dalam klik pada pengguna, tumbuh sebesar 5%. Ini adalah salah satu fitur terbaik yang terkait dengan keterlibatan pengguna yang pernah diterapkan MSN, dan itu adalah perubahan kode yang sepele.
Semua mesin pencari utama bereksperimen dengan membuka tautan di tab / windows baru, tetapi hasil untuk "halaman hasil pencarian" tidak begitu mengesankan.
Contoh: Warna Huruf
Pada 2013, Bing melakukan serangkaian percobaan dengan warna font. Pilihan yang menang ditunjukkan pada Gambar 1 di sebelah kanan. Inilah cara ketiga warna diubah:
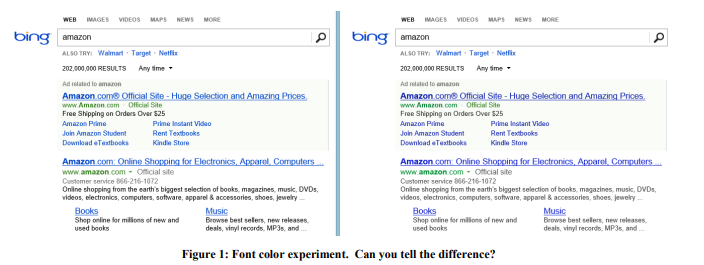
Biaya perubahan seperti itu? Murah: cukup ganti beberapa warna dalam file CSS. Dan hasil percobaan menunjukkan bahwa pengguna mencapai tujuan mereka (definisi kesuksesan yang ketat adalah rahasia dagang) lebih cepat, dan monetisasi dari revisi ini meningkat lebih dari $ 10 juta per tahun. Kami skeptis dengan hasil yang luar biasa, jadi kami mereproduksi percobaan ini pada sampel yang jauh lebih besar dari 32 juta pengguna, dan hasilnya dikonfirmasi.

Contoh: Tawaran yang tepat di waktu yang tepat
Kembali pada tahun 2004, halaman awal Amazon berisi dua slot, yang isinya diuji secara otomatis, sehingga konten yang lebih baik meningkatkan metrik target ditampilkan lebih sering. Tawaran untuk mendapatkan kartu kredit Amazon mencapai slot teratas, yang mengejutkan sejak itu tawaran ini memiliki sangat sedikit klik per tayangan. Tetapi kenyataannya adalah bahwa aplikasi ini sangat menguntungkan, oleh karena itu, meskipun CTR kecil, nilai yang diharapkan sangat tinggi. Tetapi apakah tempat pengumuman tersebut berhasil dipilih? Tidak! Akibatnya, proposal, bersama dengan contoh sederhana manfaatnya, dipindahkan ke keranjang belanja yang dilihat pengguna setelah menambahkan produk. Dengan demikian, keunggulan proposal ini ditekankan pada contoh masing-masing produk. Jika pengguna telah menambahkan barang ke keranjang, ini adalah niat yang jelas untuk melakukan pembelian dan inilah saatnya untuk penawaran semacam itu.

Eksperimen kontrol menunjukkan bahwa perubahan sederhana seperti itu menghasilkan puluhan juta dolar setahun.
Contoh: Antivirus
Iklan adalah bisnis yang menguntungkan, dan perangkat lunak "gratis" yang dipasang oleh pengguna sering kali mengandung bagian jahat yang menyumbat halaman dengan iklan. Misalnya, Gambar 2 menunjukkan seperti apa halaman hasil Bing bagi pengguna dengan program jahat yang telah menambahkan banyak iklan ke halaman tersebut (disorot dengan warna merah).
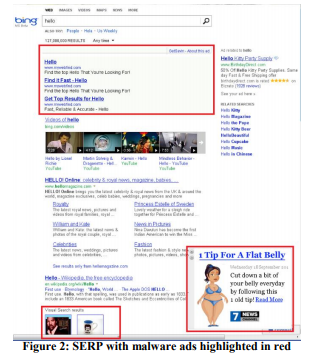
Pengguna biasanya bahkan tidak memperhatikan bahwa begitu banyak iklan ditampilkan bukan oleh situs yang mereka kunjungi, tetapi oleh kode jahat yang tidak sengaja mereka pasang. Eksperimen itu sulit diimplementasikan, tetapi secara ideologis relatif sederhana: mengubah prosedur dasar yang memodifikasi DOM, dan membatasi aplikasi yang mampu memodifikasi halaman. Percobaan ini dilakukan lebih dari 3,8 juta pengguna yang komputernya memiliki kode pihak ketiga yang mengedit DOM. Di grup uji, perubahan ini diblokir. Hasilnya menunjukkan peningkatan dalam semua metrik utama, termasuk yang memandu seperti jumlah sesi per pengguna, yaitu orang-orang datang ke situs lebih sering. Selain itu, pengguna menyelesaikan tugas mereka dengan lebih sukses dan lebih cepat, dan pendapatan tahunan meningkat beberapa juta dolar. Kecepatan pemuatan halaman, yang akan kita bahas dalam aturan No. 4, telah menurun ratusan milidetik untuk halaman yang dipengaruhi oleh percobaan.
Dua perubahan kecil lainnya pada Bing, yang sangat rahasia, membutuhkan waktu berhari-hari untuk dikembangkan, dan masing-masing menghasilkan peningkatan pendapatan iklan hampir $ 100 juta per tahun. Dalam laporan triwulanan dari Microsoft pada Oktober 2013, dikatakan: "Pendapatan iklan dari pencarian telah tumbuh sebesar 47% karena peningkatan keuntungan dari setiap pencarian dan setiap halaman." Kedua perubahan tersebut memberikan kontribusi yang signifikan terhadap pertumbuhan laba yang disebutkan.
Setelah contoh-contoh ini, Anda mungkin berpikir bahwa organisasi harus fokus pada banyak perubahan kecil. Tetapi di bawah ini Anda akan melihat bahwa ini sama sekali tidak terjadi. Ya, berjerawat terjadi berdasarkan perubahan kecil, tetapi sangat jarang dan tidak terduga: di Bing, mungkin satu dari 500 percobaan mencapai ROI yang tinggi dan hasil positif yang dapat direproduksi. Kami tidak mengklaim bahwa hasil ini akan dapat direproduksi di domain lain, kami hanya ingin menyampaikan gagasan: melakukan eksperimen sederhana sepadan dengan usaha dan pada akhirnya dapat mengarah pada terobosan.
Bahaya yang timbul dari fokus pada perubahan kecil adalah inkrementalisme: sebuah organisasi yang menghargai diri sendiri harus memiliki serangkaian perubahan dengan ROI yang berpotensi tinggi, tetapi pada saat yang sama, harus ada beberapa perubahan besar untuk memecahkan jackpot besar [23].
Aturan nomor 2: Perubahan jarang berdampak positif besar pada metrik utama
Seperti yang dikatakan Al Pacino dalam film Every Sunday, kemenangan diberikan sentimeter demi sentimeter. Ratusan dan ribuan eksperimen setiap tahun berjalan di situs-situs seperti Bing. Sebagian besar gagal, dan yang berhasil mempengaruhi metrik kunci sebesar 0,1% -1,0%, menambahkan penurunan pada dampak keseluruhan. Perubahan kecil dengan efek besar yang dijelaskan dalam aturan sebelumnya terjadi, tetapi jarang terjadi.
Penting untuk mencatat dua hal:
- Metrik kunci bukanlah sesuatu yang spesifik yang berkaitan dengan fitur individual yang dapat dengan mudah ditingkatkan, melainkan metrik yang signifikan untuk seluruh organisasi: misalnya, jumlah sesi per pengguna [18] atau waktu untuk mencapai tujuan pengguna [24].
Saat mengembangkan fitur, sangat mudah untuk secara signifikan meningkatkan jumlah klik pada fitur ini (atau metrik fitur lainnya) dengan hanya menyorotnya atau membuatnya lebih besar. Tetapi untuk meningkatkan RKT seluruh halaman atau seluruh pengalaman pengguna - ini adalah tantangannya. Sebagian besar fitur hanya mendorong klik pada halaman, mendistribusikannya di antara area yang berbeda. - Metrik harus dibagi menjadi segmen kecil, sehingga lebih mudah dioptimalkan. Misalnya, dapatkah tim dengan mudah meningkatkan metrik untuk permintaan cuaca di Bing atau membeli program TV di Amazon? menambahkan alat perbandingan yang bagus. Namun, peningkatan 10 persen dalam metrik utama akan larut dalam metrik seluruh produk karena ukuran segmen. Misalnya, peningkatan 10 persen di segmen 1 persen akan memengaruhi seluruh proyek sekitar 0,1% (kira-kira, karena jika metrik segmen berbeda dari rata-rata, maka pengaruhnya juga bisa berbeda).
Pentingnya aturan ini sangat bagus karena kesalahan positif palsu terjadi selama percobaan. Mereka memiliki dua macam alasan:
- Yang pertama disebabkan oleh statistik. Jika kita melakukan seribu percobaan per tahun, maka probabilitas kesalahan positif palsu 0,05 mengarah pada fakta bahwa untuk metrik tetap kita akan mendapatkan hasil positif palsu ratusan kali. Dan jika kita menggunakan beberapa metrik yang tidak saling berkorelasi, maka hasil ini hanya menguat. Bahkan situs besar seperti Bing tidak memiliki lalu lintas yang cukup untuk meningkatkan sensitivitas dan menarik kesimpulan dengan nilai p yang lebih rendah untuk metrik seperti jumlah sesi per pengguna.
- , , .
[11]. [25;26]. , , p-value 0,05 - .
:
jika kita memiliki probabilitas awal keberhasilan yang sama dengan ⅓ (seperti yang kami katakan dalam [7], ini adalah nilai rata-rata di antara eksperimen di Microsoft), maka probabilitas posterior dari percobaan signifikan yang benar-benar positif secara statistik adalah 89%. Dan jika percobaan adalah salah satu yang kami bicarakan dalam aturan pertama, ketika hanya 1 dari 500 yang berisi solusi terobosan, maka probabilitas turun menjadi 3,1%.
Konsekuensi lucu dari aturan ini adalah kenyataan bahwa berpegangan pada seseorang jauh lebih mudah daripada berkembang sendirian. Keputusan yang dibuat dalam perusahaan yang berfokus pada signifikansi statistik lebih cenderung memiliki efek positif. Misalnya, jika kami memiliki tingkat keberhasilan percobaan 10-20%, maka jika kami mengambil tes fitur-fitur yang berhasil dan diluncurkan untuk bertarung di mesin pencari lain, maka tingkat keberhasilan kami akan lebih tinggi. Kebalikannya juga benar: mesin pencari lain juga harus menguji dan menerapkan hal-hal yang telah diterapkan Bing.
Dengan pengalaman, kami telah belajar untuk tidak memercayai hasil yang terlihat terlalu bagus untuk menjadi kenyataan. Orang bereaksi berbeda terhadap situasi yang berbeda. Mereka mencurigai ada sesuatu yang salah dan mempelajari hasil negatif dari eksperimen dengan fitur baru mereka yang hebat, mengajukan pertanyaan dan terjun lebih dalam ke pencarian untuk alasan hasil ini. Tetapi jika hasilnya hanya positif, maka kecurigaan surut dan orang-orang mulai merayakan, dan tidak belajar lebih dalam dan tidak mencari anomali.
Ketika hasilnya luar biasa luar biasa, kita terbiasa mengikuti hukum Twyman [27]: Segala sesuatu yang terlihat menarik atau berbeda biasanya salah.
Hukum Twyman dapat dijelaskan dengan inferensi Bayesian. Dalam pengalaman kami, kami tahu bahwa terobosan jarang terjadi. Misalnya, beberapa percobaan secara signifikan meningkatkan metrik penuntun kami, jumlah sesi per pengguna. Bayangkan bahwa distribusi yang kami temui dalam eksperimen adalah normal, berpusat pada titik 0 dan dengan standar deviasi 0,25%. Jika percobaan menunjukkan + 2% dengan nilai metrik kunci, maka kami memanggil hukum Twyman dan mengatakan bahwa ini adalah hasil yang sangat menarik, yaitu pada jarak 8 standar deviasi dari rata-rata dan memiliki probabilitas 10
-15 , tidak termasuk faktor lain. Bahkan dengan signifikansi statistik, ekspektasi awal begitu kuat sehingga kami akan menunda perayaan kesuksesan dan masuk lebih dalam ke pencarian penyebab kesalahan positif palsu tipe kedua. Hukum Twyman sering diterapkan untuk membuktikan bahwa
=NP . Hari ini, tidak ada editor situs yang akan senang jika ia menerima bukti seperti itu. Kemungkinan besar, dia akan segera menjawab dengan jawaban templat: "dalam bukti Anda bahwa P = NP, kesalahan telah dilakukan pada halaman X."
Contoh: Metrik Office Online Pengganti
Cook dan timnya [17] berbicara tentang percobaan menarik yang mereka lakukan dengan Microsoft Office Online. Tim menguji desain halaman baru di mana sebuah tombol menonjol, menyerukan untuk membayar produk. Metrik utama yang ingin diukur tim: jumlah pembelian per pengguna. Tetapi melacak pembelian nyata diperlukan memodifikasi sistem penagihan, dan pada saat itu sulit dilakukan. Kemudian tim memutuskan untuk menggunakan metrik "klik yang mengarah ke pembelian" dan menerapkan rumus
( ) * = , di mana konversi dari klik ke pembelian diambil.
Yang mengejutkan mereka, dalam percobaan, jumlah klik berkurang 64%. Hasil yang mengejutkan tersebut memaksa analisis data yang lebih dalam, dan ternyata asumsi konversi yang stabil dari klik ke pembelian adalah salah. Halaman percobaan, yang menunjukkan biaya produk, menarik lebih sedikit klik, tetapi pengguna yang mengkliknya lebih berkualitas dan memiliki konversi yang jauh lebih besar dari klik ke pembelian.
Contoh: Lebih banyak klik dari halaman yang lambat
JavaScript telah ditambahkan ke halaman hasil pencarian Bing. Skrip ini biasanya memperlambat halaman, sehingga setiap orang diharapkan melihat sedikit dampak negatif pada metrik keterlibatan utama, seperti jumlah klik pada pengguna. Tetapi hasilnya menunjukkan sebaliknya, ada lebih banyak klik! [18] Meskipun dinamika positif, kami mengikuti hukum Twyman dan memecahkan teka-teki. Pelacak klik didasarkan pada suar web, dan beberapa browser tidak melakukan panggilan jika pengguna meninggalkan halaman. [28] Dengan demikian, JavaScript memengaruhi akurasi jumlah klik.
Contoh: Bing Edge
Selama beberapa bulan di tahun 2013, Bing mengubah Jaringan Pengiriman Kontennya dari Akamai ke Bing Edge-nya sendiri. Mengalihkan lalu lintas ke Bing Edge telah digabungkan dengan banyak peningkatan lainnya. Beberapa tim melaporkan bahwa mereka meningkatkan metrik kunci: RKPT beranda Bing meningkat, fitur mulai lebih sering digunakan, dan arus keluar mulai menurun. Dan ternyata semua peningkatan ini terkait dengan jumlah klik bersih: Bing Edge tidak hanya meningkatkan kecepatan halaman, tetapi juga kemampuan pengiriman klik. Untuk mengevaluasi efeknya, kami meluncurkan percobaan di mana pendekatan mercusuar untuk melacak klik digantikan oleh pendekatan dengan pemuatan ulang halaman. Teknik ini digunakan dalam iklan dan menyebabkan sedikit kehilangan klik, memperlambat efek setiap klik. Hasilnya menunjukkan bahwa persentase klik yang hilang turun lebih dari 60%! Dan sebagian besar pencapaian yang diumumkan selama periode itu adalah hasil dari pengiriman klik yang ditingkatkan.
Contoh: Pencarian Bing MSN
Penyelesaian otomatis adalah daftar drop-down yang menawarkan opsi untuk menyelesaikan permintaan saat seseorang mengetiknya. MSN berencana untuk meningkatkan fitur ini dengan algoritma baru dan lebih baik (fitur tim pengembangan selalu siap untuk menjelaskan mengapa algoritma baru mereka lebih baik daripada yang lama, tetapi mereka sering frustrasi ketika mereka melihat hasil percobaan). Eksperimen itu sukses besar, jumlah pencarian yang datang ke Bing dengan MSN meningkat secara signifikan. Mengikuti aturan kami, kami mulai memahami dan menemukan bahwa ketika pengguna mengklik prompt, kode baru membuat dua permintaan pencarian (salah satunya segera ditutup oleh browser segera setelah hasil pencarian muncul).
Jadi penjelasan untuk banyak hasil positif mungkin tidak menarik. Dan tugas kami adalah menemukan dampak nyata pada pengguna, dan aturan Twyman sangat membantu dalam hal ini dan dalam memahami banyak hasil eksperimen.
Peraturan nomor 3. Keuntungan Anda akan bervariasi.
Ada banyak contoh percobaan percobaan kontrol yang berhasil. Misalnya, "
Tes Yang Menang? " Berisi ratusan contoh tes A / B, dan daftar diperbarui setiap minggu.
Meskipun ini adalah penghasil gagasan yang hebat, contoh-contoh ini memiliki beberapa masalah:
- Kualitas bervariasi. Dalam studi ini, seseorang dari perusahaan berbicara tentang hasil tes A / B. Apakah ada penilaian ahli? Apakah itu dilakukan dengan benar? Apakah ada emisi? Apakah nilai p cukup kecil (kami melihat tes A / B yang dipublikasikan dengan nilai p lebih besar dari 0,05, yang biasanya dianggap tidak signifikan secara statistik)? Apakah ada jebakan yang telah kita bicarakan sebelumnya, dan yang tidak diperiksa dengan benar oleh penulis tes?
- Apa yang berfungsi di satu domain mungkin tidak berfungsi di domain lain. Misalnya, Neil Patel [29] merekomendasikan penggunaan kata "gratis" dalam iklan yang menawarkan versi uji coba 30 hari alih-alih "jaminan uang kembali 30 hari". Ini mungkin bekerja dengan satu produk dan satu audiens, tetapi kami menduga bahwa hasilnya akan sangat tergantung pada produk dan audiens. Joshua Porter [30] menyatakan bahwa "Merah lebih baik daripada hijau" untuk tombol-tombol yang memanggil untuk bergabung dengan "Mulailah Sekarang". Tetapi karena kita belum melihat banyak situs dengan tombol ajakan bertindak merah, maka, tampaknya, hasil ini tidak direproduksi dengan baik.
- Efek kebaruan dan pertama kalinya. Kami mencapai stabilitas dalam percobaan kami, dan banyak percobaan dalam banyak contoh belum dilakukan cukup lama untuk memeriksa efek seperti itu.
- Interpretasi hasil yang salah. Beberapa alasan tersembunyi atau faktor tertentu mungkin tidak diakui atau disalahpahami. Kami memberikan dua contoh. Salah satunya adalah percobaan kontrol terdokumentasi pertama.
Contoh 1 Penyakit kudis adalah penyakit yang disebabkan oleh kekurangan vitamin C. Penyakit ini menewaskan lebih dari 100.000 orang pada abad 16-18, kebanyakan dari mereka adalah pelaut yang melakukan perjalanan panjang dan tinggal di laut lebih lama daripada buah-buahan dan sayuran dapat bertahan hidup. Pada 1747, Dr. James Lind mencatat bahwa penyakit kudis kurang terpengaruh pada kapal-kapal di Mediterania. Dia mulai memberikan lemon dan jeruk ke beberapa pelaut, meninggalkan yang lain untuk diet biasa. Eksperimen itu sangat sukses, tetapi dokter tidak mengerti alasannya. Di Royal Maritime Hospital di Inggris, ia merawat pasien kudis dengan jus lemon pekat, yang ia sebut rob. Dokter mengonsentrasikannya dengan pemanasan, yang menghancurkan vitamin C. Lind kehilangan kepercayaan dan sering terpaksa melakukan pertumpahan darah. Pada 1793, tes nyata dilakukan. dan jus lemon telah menjadi bagian dari makanan sehari-hari para pelaut. Penyakit kudis cepat hilang, dan pelaut Inggris masih disebut serai.
Contoh 2 Marissa Mayer berbicara tentang percobaan di mana Google meningkatkan jumlah hasil pada halaman pencarian dari 10 menjadi 30. Lalu lintas dan keuntungan dari pengguna yang mencari di Google turun 20%. Dan bagaimana dia menjelaskan ini? Seperti, halaman membutuhkan setengah detik lebih untuk dihasilkan. Tentu saja, produktivitas adalah faktor penting, tetapi kami menduga bahwa ini hanya memengaruhi sebagian kecil dari kerugian. Inilah visi kami tentang penyebabnya:
- Bing melakukan eksperimen lambat yang terisolasi [11], di mana hanya kinerja yang berubah. Penundaan respons server sebesar 250 milidetik memengaruhi pendapatan sekitar 1,5% dan RKT 0,25%. Ini adalah pengaruh besar, dan dapat diasumsikan bahwa 500 milidetik masing-masing akan memengaruhi pendapatan dan RKPT masing-masing sebesar 3% dan 0,5%, tetapi tidak sebesar 20% (misalkan perkiraan linier berlaku di sini). Tes lama di Bing [32] menunjukkan efek yang sama pada klik dan lebih sedikit berdampak pada pendapatan dengan penundaan 2 detik.
- Google Jake Brutlag menulis dalam sebuah posting blog tentang percobaan [12] yang menunjukkan bahwa memperlambat hasil pencarian dari 100 milidetik menjadi 400 memiliki efek signifikan pada jumlah pencarian tertentu dan berkisar antara 0,2% dan 0,6%, yang bekerja dengan sangat baik dengan eksperimen kami, tetapi sangat jauh dari hasil Marissa Mayer.
- BIng melakukan percobaan dengan menampilkan 20 hasil pencarian alih-alih 10. Hilangnya laba sepenuhnya menghilangkan penambahan iklan tambahan (yang membuat halaman menjadi sedikit lebih lambat). Kami percaya bahwa rasio periklanan untuk algoritma pencarian jauh lebih penting daripada kinerja.
Kami skeptis dengan banyak hasil luar biasa dari tes A / B yang diterbitkan di berbagai sumber. Saat memeriksa hasil eksperimen, tanyakan pada diri sendiri tingkat kepercayaan apa yang Anda miliki di dalamnya? Dan ingat, meskipun ide itu bekerja di satu situs, itu tidak perlu bahwa itu akan berfungsi di situs lain. Hal terbaik yang dapat kita lakukan adalah berbicara tentang reproduksi percobaan dan keberhasilan atau kegagalannya. Ini akan sangat bermanfaat bagi sains.
Peraturan nomor 4: Kecepatan sangat berarti
Pengembang web yang menguji fitur mereka menggunakan eksperimen kontrol dengan cepat menyadari bahwa kinerja atau kecepatan situs adalah parameter penting [13; 14; 33]. Bahkan sedikit keterlambatan dalam pengoperasian situs dapat memengaruhi metrik kunci dari kelompok uji.
Cara terbaik untuk mengevaluasi efek kinerja adalah dengan melakukan eksperimen perlambatan yang terisolasi, mis. cukup dengan add delay. Gambar 3 menunjukkan grafik standar hubungan antara kinerja dan metrik yang sedang diuji (RKT, tingkat keberhasilan unit dan pendapatan). Biasanya semakin cepat situs, semakin baik (lebih tinggi pada grafik ini). Melambatkan pekerjaan kelompok uji dalam kaitannya dengan kelompok kontrol, Anda dapat mengukur dampak kinerja pada metrik yang Anda minati. Penting untuk dicatat:
- Efek perlambatan pada kelompok uji diukur di sini dan sekarang (garis putus-putus pada grafik) dan tergantung pada situs dan audiens. Jika situs atau pemirsa berubah, maka penurunan kinerja dapat memengaruhi metrik kunci secara berbeda.
- Eksperimen menunjukkan efek perlambatan pada metrik kunci. Ini bisa sangat berguna ketika Anda mencoba untuk mengukur efek dari fitur baru yang implementasi pertamanya tidak efektif. Anggap itu meningkatkan metrik M sebesar X%, dan pada saat yang sama memperlambat situs sebesar T%. Menggunakan percobaan dengan deselerasi, kita dapat mengevaluasi efek deselerasi pada metrik M, mengoreksi efek fitur dan memperoleh efek prediksi X '% (logis untuk mengasumsikan bahwa efek ini memiliki sifat aditivitas). Jadi kita dapat menjawab pertanyaan: "Bagaimana pengaruhnya terhadap metrik kunci jika diterapkan secara efektif?".
- Kita dapat mengasumsikan bagaimana fakta bahwa situs akan mulai bekerja lebih cepat dan membantu menghitung ROI dari upaya pengoptimalan akan memengaruhi metrik utama. Dengan menggunakan pendekatan linier (istilah pertama dari seri Taylor), kita dapat mengasumsikan bahwa efek pada metrik sama di kedua arah. Kami berasumsi bahwa delta vertikal adalah sama di kedua arah dan hanya berbeda dalam tanda. Oleh karena itu, bereksperimen dengan perlambatan pada berbagai nilai, kita dapat membayangkan bagaimana percepatan akan mempengaruhi nilai-nilai yang sama. Kami melakukan tes seperti itu di Bing dan teori kami telah dikonfirmasi sepenuhnya.
Seberapa pentingkah kinerja? Sangat penting. Di Amazon, pelambatan 100 milidetik menyebabkan penurunan 1% dalam penjualan, seperti yang dikatakan Greg Linded [34 hal.10]. Dan pembicara dari Bing dan Google [32] menunjukkan dampak kinerja yang signifikan pada metrik utama.
Contoh: Eksperimen pelambatan server
Kami melakukan percobaan dua minggu di Bing untuk memperlambat layanan oleh 100 milidetik untuk 10% pengguna, oleh 250 milidetik untuk 10% pengguna lainnya. Ternyata setiap 100 milidetik percepatan layanan meningkatkan pendapatan sebesar 0,6%. Dari sini, bahkan sebuah frasa muncul yang mencerminkan esensi organisasi kami:
Seorang insinyur yang akan meningkatkan kinerja server hingga 10 milidetik (1/30 dari kecepatan kedipan mata kami) akan memberi perusahaannya penghasilan lebih dari setahun. Setiap milidetik penting.
Dalam percobaan yang dijelaskan, kami memperlambat waktu respons server, lalu memperlambat waktu operasi semua elemen di halaman. Tetapi halaman memiliki bagian yang lebih penting, dan ada bagian yang kurang penting. Misalnya, pengguna mungkin tidak tahu bahwa item di luar ruang lingkup layar belum dimuat. Tetapi apakah ada elemen yang segera ditampilkan yang dapat diperlambat tanpa merugikan pengguna? Seperti yang akan Anda lihat di bawah, ada elemen-elemen seperti itu.
Contoh: kinerja panel kanan tidak begitu kritis
Di Bing, beberapa elemen yang disebut snapshots terletak di panel kanan dan dimuat terlambat (setelah acara window.onload). Kami baru-baru ini melakukan percobaan: elemen panel kanan melambat 250 milidetik. Jika ini memengaruhi metrik kunci, sangat tidak signifikan sehingga kami tidak melihat apa pun. Dan percobaan melibatkan hampir 20 juta pengguna.
Waktu pemuatan halaman (PLT) sering dihitung menggunakan peristiwa window.onload, sebagai tanda penyelesaian aktivitas browser yang berguna. Tetapi hari ini, metrik ini memiliki kelemahan serius ketika bekerja dengan browser modern. Seperti yang ditunjukkan Steve Souders [32], bagian atas halaman Amazon ditampilkan dalam 2 detik, sementara windows.onload menyala dalam 5,2 detik. Schurman [32] menyatakan bahwa mereka dapat membuat halaman secara dinamis, jadi penting bagi mereka untuk menampilkan header dengan sangat cepat. Yang sebaliknya juga benar: di Gmail, windows.onload menyala setelah 3,3 detik, sementara pada saat itu hanya bilah unduhan muncul di layar, dan semua konten akan ditampilkan dalam 4,8 detik.
Ada metrik yang terkait dengan waktu, misalnya: waktu ke hasil pertama (katakanlah, waktu ke tweet pertama di Twitter, hasil pencarian pertama di halaman hasil). Tetapi istilah "Persepsi kinerja" selalu digunakan untuk menggambarkan kecepatan halaman sedemikian rupa sehingga pengguna merasa cukup penuh. Konsep "Persepsi kinerja" lebih mudah untuk dideskripsikan secara intuitif daripada yang diformulasikan secara ketat, oleh karena itu, tidak ada browser yang memiliki rencana untuk mengimplementasikan
perception.ready() . Untuk mengatasi masalah ini, banyak asumsi dan asumsi yang digunakan, misalnya:
- Waktu Top of Page (AFT) [37]. Diukur sebagai momen ketika semua piksel atas halaman ditampilkan. Implementasinya didasarkan pada heuristik yang sangat kompleks ketika berhadapan dengan video, gif, galeri gulir, dan konten dinamis lainnya yang mengubah bagian atas halaman. Ambang batas dapat diatur ke "persentase piksel yang ditarik" untuk menghindari pengaruh elemen kecil dan tidak signifikan yang dapat meningkatkan metrik yang diukur.
- Indeks Kecepatan [38] adalah beberapa generalisasi AFT yang rata-rata waktu selama elemen halaman yang terlihat muncul di layar. Kecepatan tidak menderita elemen kecil yang muncul terlambat, tetapi masih dipengaruhi oleh konten dinamis yang mengubah bagian atas halaman.
- Waktu fase halaman dan waktu ketersediaan pengguna [39]. Waktu Fase Halaman - Waktu yang diperlukan untuk setiap fase render halaman individual. , . — , .
W3C- , HTML, , , . , , , .
Bing , « » (TTS) [24] . — . , 30 . — «Perceived performance». , ; , , . , , , . , . , , , , — .
№5: — , —
, Bing — , , . , — , , . , , . , , .
:
Bing . , «data mining», Bing «Examples of data mining», «Advantages of Data Mining», «definition of data mining», «Data mining companies»,«data mining software» .. . 10 . , (p-value 0,64).
:
Bing , , , , . . 17 %, (p-value 0,71).
:
Bing , 10 . , :
- , , «ebay», CTR 75 %. 10 . : 8 , , 4 . (p-value 0,92), production.
- , «» , Bing (14 ). , 3 «» , : 1,8 % , 30 , 18 % ( ), (p-value 0,93). .
:
. 10 , 12 % ( $150 , ). , (p-value 0,83)
, , . , , .
, ( Microsoft, Amazon .), CTR. , , . , . , . «» . : — , — .
№6: ,
. .. [40]: « , , . , — ». , online-, , [17;41], , , . , . LinkedIn.
: LinkedIn
LinkedIn . 2013 , , , , — LinkedIn, . , : , . , , , . . : . , , , . , , - , , - . .
: LinkedIn
LinkedIn . , . , . , . , , . , . , , , . , , , . , , . , . , .
offline- , , online, , , [4;11]. (Mullty-Variable) , MV-. ( /B/C/D) .
— Agile, MVP [15]: MVT, , . , . , , .. MV- - .
: 1 % , . Agile- Knight Capital, 2012 440 Knights 75 %.
№7:
. , , . , , . , . , [42] , , n > 30, . , . — , Neil Patel , .
, ( ) [16], , . , , .
,
355 * s^2 , , .
s — , :
$$s = \frac{E (XE (X))^3}{\Var (X)^{3/2}}$$, 1. , , Bing:
|
|
|
|
Revenue/User
| 17,9
| 114 .
| 4,4 %
|
Revenue/User (capped)
| 5,2
| 9,7 .
| 10,5 %
|
Sessions/User
| 3,6
| 4,7 .
| 5,4 %
|
Time To Success
| 2,1
| 1,55 .
| 12,3 %
|
, « » 10, « » — 30. 95 % , , 0,025, 0,3 0,2. Boos Hughes-Oliver [43]. , . , 18,2, 114 . . 4 , 100 1000 , QQ. 95- , , 5 %. 100 000 , -2 2.

, - , . , « » , , 18 5, . , 30 % , .
, , . , , , , 0. , 1.
, [16]. bootstrap [44].
Kesimpulan
7 , , . , , , , . , Twyman' , , . , , , , . — — . , , , , — . , , (, ). , , . — , , , . , : , . , , . , . Agile. — , . , , . , — . , , , .
, , . Mujtaba Khambatti, John Psaroudakis, Sreenivas Addagatke, . Juan Lavista Ferres, Urszula Chajewska, Greben Langendijk, Lukas Vermeer, Jonas Alves. Eytan Bakshy, Brooks Bell Colin McFarland.
- Kohavi, Ron and Round, Matt. Front Line Internet Analytics at Amazon.com. [ed.] Jim Sterne. Santa Barbara, CA: sn, 2004. ai.stanford.edu/~ronnyk/emetricsAmazon.pdf .
- McKinley, Dan. Design for Continuous Experimentation: Talk and Slides. [Online] Dec 22, 2012. mcfunley.com/designfor-continuous-experimentation .
- Bakshy, Eytan and Eckles, Dean. Uncertainty in Online Experiments with Dependent Data: An Evaluation of Bootstrap Methods. KDD 2013: Proceedings of the 19th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2013.
- Tang, Diane, et al. Overlapping Experiment Infrastructure: More, Better, Faster Experimentation. Proceedings 16th Conference on Knowledge Discovery and Data Mining. 2010
- Moran, Mike. Multivariate Testing in Action: Quicken Loan's Regis Hadiaris on multivariate testing. Biznology Blog by Mike Moran. [Online] December 2008. www.biznology.com/2008/12/multivariate_testing_in_action .
- Posse, Christian. Key Lessons Learned Building LinkedIn Online Experimentation Platform. Slideshare. [Online] March 20, 2013. www.slideshare.net/HiveData/googlecontrolledexperimentationpanelthe-hive .
- Kohavi, Ron, Crook, Thomas and Longbotham, Roger. Online Experimentation at Microsoft. Third Workshop on Data Mining Case Studies and Practice Prize. 2009. http://expplatform.com/expMicrosoft.aspx .
- Amatriain, Xavier and Basilico, Justin. Netflix Recommendations: Beyond the 5 stars. [Online] April 2012. techblog.netflix.com/2012/04/netflix-recommendationsbeyond-5-stars.html .
- McFarland, Colin. Experiment!: Website conversion rate optimization with A/B and multivariate testing. sl: New Riders, 2012. 978-0321834607.
- Smietana, Brandon. Zynga: What is Zynga's core competency? Quora. [Online] Sept 2010. www.quora.com/Zynga/What-is-Zyngas-corecompetency/answer/Brandon-Smietana .
- Kohavi, Ron, et al. Online Controlled Experiments at Large Scale. KDD 2013: Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. 2013. bit.ly/ExPScale .
- Brutlag, Jake. Speed Matters. Google Research blog. [Online] June 23, 2009. googleresearch.blogspot.com/2009/06/speed-matters.html .
- Sullivan, Nicole. Design Fast Websites. Slideshare. [Online] Oct 14, 2008. www.slideshare.net/stubbornella/designingfast-websites-presentation .
- Kohavi, Ron, Henne, Randal M and Sommerfield, Dan. Practical Guide to Controlled Experiments on the Web: Listen to Your Customers not to the HiPPO. The Thirteenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2007). August 2007, pp. 959-967. www.expplatform.com/Documents/GuideControlledExperiments.pdf .
- Ries, Eric. The Lean Startup: How Today's Entrepreneurs Use Continuous Innovation to Create Radically Successful Businesses. sl: Crown Business, 2011. 978-0307887894.
- Kohavi, Ron, et al. Controlled experiments on the web: survey and practical guide. Data Mining and Knowledge Discovery. February 2009, Vol. 18, 1, pp. 140-181. www.exp-platform.com/Pages/hippo_long.aspx .
- Crook, Thomas, et al. Seven Pitfalls to Avoid when Running Controlled Experiments on the Web. [ed.] Peter Flach and Mohammed Zaki. KDD '09: Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining. 2009, pp. 1105-1114. www.expplatform.com/Pages/ExPpitfalls.aspx .
- Kohavi, Ron, et al. Trustworthy online controlled experiments: Five puzzling outcomes explained. Proceedings of the 18th Conference on Knowledge Discovery and Data Mining. 2012, www.expplatform.com/Pages/PuzzingOutcomesExplained.aspx .
- Wikipedia contributors. Fisher's method. Wikipedia. [Online] Jan 2014. http://en.wikipedia.org/wiki/Fisher %27s_method .
- Eisenberg, Bryan. How to Increase Conversion Rate 1,000 Percent. ClickZ. [Online] Feb 28, 2003. www.clickz.com/showPage.html?page=1756031 .
- Spool, Jared. The $300 Million Button. USer Interface Engineering. [Online] 2009. www.uie.com/articles/three_hund_million_button .
- Goldstein, Noah J, Martin, Steve J and Cialdini, Robert B. Yes!: 50 Scientifically Proven Ways to Be Persuasive. sl: Free Press, 2008. 1416570969.
- Collins, Jim and Porras, Jerry I. Built to Last: Successful Habits of Visionary Companies. sl: HarperBusiness, 2004. 978- 0060566104.
- Badam, Kiran. Looking Beyond Page Load Times – How a relentless focus on Task Completion Times can benefit your users. Velocity: Web Performance and Operations. 2013. velocityconf.com/velocityny2013/public/schedule/detail/32 820.
- Why Most Published Research Findings Are False. Ioannidis, John P. 8, 2005, PLoS Medicine, Vol. 2, p. e124. www.plosmedicine.org/article/info :doi/10.1371/journal.pme d.0020124.
- Wacholder, Sholom, et al. Assessing the Probability That a Positive Report is False: An Approach for Molecular Epidemiology Studies. Journal of the National Cancer Institute. 2004, Vol. 96, 6. jnci.oxfordjournals.org/content/96/6/434.long .
- Ehrenberg, ASC The Teaching of Statistics: Corrections and Comments. Journal of the Royal Statistical Society. Series A, 1974, Vol. 138, 4.
- Ron Kohavi, David Messner,Seth Eliot, Juan Lavista Ferres, Randy Henne, Vignesh Kannappan,Justin Wang. Tracking Users' Clicks and Submits: Tradeoffs between User Experience and Data Loss. Redmond: sn, 2010.
- Patel, Neil. 11 Obvious A/B Tests You Should Try. QuickSprout. [Online] Jan 14, 2013. http://www.quicksprout.com/2013/01/14/11-obvious-ab-tests-youshould-try/ .
- Porter, Joshua. The Button Color A/B Test: Red Beats Green. Hutspot. [Online] Aug 2, 2011. blog.hubspot.com/blog/tabid/6307/bid/20566/The-ButtonColor-AB-Test-Red-Beats-Green.aspx .
- Linden, Greg. Marissa Mayer at Web 2.0. Geeking with Greg. [Online] Nov 9, 2006. glinden.blogspot.com/2006/11/marissa-mayer-at-web20.html .
- Performance Related Changes and their User Impact. Schurman, Eric and Brutlag, Jake. sl: Velocity 09: Velocity Web Performance and Operations Conference, 2009.
- Souders, Steve. High Performance Web Sites: Essential Knowledge for Front-End Engineers. sl: O'Reilly Media, 2007. 978-0596529307.
- Linden, Greg. Make Data Useful. [Online] Dec 2006. sites.google.com/site/glinden/Home/StanfordDataMining.20 06-11-28.ppt.
- Wikipedia contributors. Above the fold. Wikipedia, The Free Encyclopedia. [Online] Jan 2014. en.wikipedia.org/wiki/Above_the_fold .
- Souders, Steve. Moving beyond window.onload (). High Performance Web Sites Blog. [Online] May 13, 2013. www.stevesouders.com/blog/2013/05/13/moving-beyondwindow-onload .
- Brutlag, Jake, Abrams, Zoe and Meenan, Pat. Above the Fold Time: Measuring Web Page Performance Visually. Velocity: Web Performance and Operations Conference. 2011. en.oreilly.com/velocitymar2011/public/schedule/detail/18692 .
- Meenan, Patrick. Speed Index. WebPagetest. [Online] April 2012. sites.google.com/a/webpagetest.org/docs/usingwebpagetest/metrics/speed-index .
- Meenan, Patrick, Feng, Chao (Ray) and Petrovich, Mike. Going Beyond onload — How Fast Does It Feel? Velocity: Web Performance and Operations. 2013. velocityconf.com/velocityny2013/public/schedule/detail/31 344.
- Fisher, Ronald A. Presidential Address. Sankhyā: The Indian Journal of Statistics. 1938, Vol. 4, 1. www.jstor.org/stable/40383882 .
- Kohavi, Ron and Longbotham, Roger. Unexpected Results in Online Controlled Experiments. SIGKDD Explorations. 2010, Vol. 12, 2. www.exp-platform.com/Documents/2010- 12 %20ExPUnexpectedSIGKDD.pdf.
- Montgomery, Douglas C. Applied Statistics and Probability for Engineers. 5th. sl: John Wiley & Sons, Inc, 2010. 978- 0470053041.
- Boos, Dennis D and Hughes-Oliver, Jacqueline M. How Large Does n Have to be for Z and t Intervals? The American Statistician. 2000, Vol. 54, 2, pp. 121-128.
- Efron, Bradley and Robert J. Tibshirani. An Introduction to the Bootstrap. New York: Chapman & Hall, 1993. 0-412-04231- 2.