
Menskalakan DBMS adalah masa depan yang terus maju. DBMS meningkat dan skala lebih baik pada platform perangkat keras, sementara platform perangkat keras itu sendiri meningkatkan produktivitas, jumlah core, dan memori - Achilles mengejar ketinggalan dengan kura-kura, tetapi masih belum. Masalah penskalaan DBMS sedang dalam ayunan penuh.
Postgres Professional memiliki masalah dengan penskalaan tidak hanya secara teoritis, tetapi juga secara praktis: dengan pelanggannya. Dan lebih dari sekali. Salah satu kasus seperti itu akan dibahas dalam artikel ini.
PostgreSQL memiliki skala yang baik pada sistem NUMA jika merupakan motherboard tunggal dengan banyak prosesor dan beberapa bus data. Beberapa optimasi dapat dibaca di
sini dan di
sini . Namun, ada kelas lain dari sistem, mereka memiliki beberapa motherboard, pertukaran data di antaranya dilakukan dengan menggunakan interkoneksi, sementara satu instance dari OS bekerja pada mereka dan untuk pengguna desain ini terlihat seperti mesin tunggal. Dan meskipun secara formal sistem tersebut juga dapat dikaitkan dengan NUMA, tetapi pada dasarnya mereka lebih dekat ke superkomputer, seperti akses ke memori lokal dari node dan akses ke memori dari node tetangga berbeda secara radikal. Komunitas PostgreSQL percaya bahwa satu-satunya instance Postgres yang berjalan pada arsitektur seperti itu adalah sumber masalah, dan belum ada pendekatan sistematis untuk menyelesaikannya.
Ini karena arsitektur perangkat lunak yang menggunakan memori bersama pada dasarnya dirancang untuk fakta bahwa waktu akses berbagai proses ke memori mereka sendiri dan jarak jauh lebih atau kurang sebanding. Dalam kasus ketika kita bekerja dengan banyak node, taruhan pada memori bersama sebagai saluran komunikasi cepat berhenti untuk membenarkan dirinya sendiri, karena karena latensi itu jauh "lebih murah" untuk mengirim permintaan untuk tindakan tertentu ke node (node) di mana ia berada data menarik daripada mengirim data ini di bus. Oleh karena itu, untuk superkomputer dan, secara umum, sistem dengan banyak node, solusi cluster relevan.
Ini tidak berarti bahwa kombinasi dari sistem multi-simpul dan arsitektur shared-memory khas Postgres harus diakhiri. Lagi pula, jika proses postgres menghabiskan sebagian besar waktu mereka melakukan perhitungan kompleks secara lokal, maka arsitektur ini bahkan akan sangat efisien. Dalam situasi kami, klien telah membeli server multi-node yang kuat, dan kami harus menyelesaikan masalah PostgreSQL di dalamnya.
Tetapi masalahnya serius: permintaan penulisan paling sederhana (ubah beberapa nilai bidang dalam satu catatan) dieksekusi dalam periode beberapa menit hingga satu jam. Seperti yang kemudian dikonfirmasikan, masalah-masalah ini memanifestasikan diri mereka dalam semua kemuliaan mereka justru karena banyaknya inti dan, karenanya, paralelisme radikal dalam pelaksanaan permintaan dengan pertukaran yang relatif lambat antara node.
Karenanya, artikel tersebut akan berubah, seolah-olah, untuk tujuan ganda:
- Berbagi pengalaman: apa yang harus dilakukan jika dalam sistem multi-simpul database melambat dengan sungguh-sungguh. Mulai dari mana, cara mendiagnosis ke mana harus pindah.
- Jelaskan bagaimana masalah DBMS PostgreSQL itu sendiri dapat diselesaikan dengan konkurensi tingkat tinggi. Termasuk bagaimana perubahan dalam algoritma untuk mengambil kunci mempengaruhi kinerja PostgreSQL.
Server dan DB
Sistem ini terdiri dari 8 bilah dengan masing-masing 2 soket. Secara total, lebih dari 300 core (tidak termasuk hypertreading). Ban cepat (teknologi pabrikan berpemilik) menghubungkan bilah. Bukan berarti itu superkomputer, tetapi untuk satu contoh DBMS, konfigurasi sangat mengesankan.
Bebannya juga agak besar. Data lebih dari 1 terabyte. Sekitar 3000 transaksi per detik. Lebih dari 1000 koneksi ke postgres.
Setelah mulai berurusan dengan harapan perekaman per jam, hal pertama yang kami lakukan adalah menulis ke disk sebagai penyebab penundaan. Segera setelah penundaan yang tidak dapat dipahami dimulai, tes mulai dilakukan secara eksklusif pada
tmpfs . Gambar tidak berubah. Disk tidak ada hubungannya dengan itu.
Memulai dengan Diagnosis: Tampilan
Karena masalah muncul kemungkinan besar karena tingginya persaingan proses yang "mengetuk" objek yang sama, hal pertama yang perlu diperiksa adalah kunci. Di PostgreSQL, ada tampilan
pg.catalog.pg_locks dan
pg_stat_activity untuk
pg_stat_activity semacam itu. Yang kedua, sudah dalam versi 9.6, menambahkan informasi tentang apa proses menunggu (
Amit Kapila, Ildus Kurbangaliev ) -
wait_event_type . Nilai yang mungkin untuk bidang ini dijelaskan di
sini .
Tapi pertama-tama, hitung saja:
postgres=
Ini adalah bilangan real. Mencapai hingga 200.000 kunci.
Pada saat yang sama, kunci seperti itu tergantung pada permintaan naas:
SELECT COUNT(mode), mode FROM pg_locks WHERE pid =580707 GROUP BY mode; count | mode —
Saat membaca buffer, DBMS menggunakan kunci
share , sambil menulis -
exclusive . Artinya, menulis kunci menyumbang kurang dari 1% dari semua permintaan.
Dalam tampilan
pg_locks , tipe kunci tidak selalu terlihat seperti yang dijelaskan
dalam dokumentasi pengguna.
Ini plat pertandingannya:
AccessShareLock = LockTupleKeyShare RowShareLock = LockTupleShare ExclusiveLock = LockTupleNoKeyExclusive AccessExclusiveLock = LockTupleExclusive
Mode SELECT FROM permintaan pg_locks menunjukkan bahwa CREATE INDEX (tanpa CONCURRENTLY) akan menunggu 234 INSERT dan 390 INSERT untuk
buffer content lock . Solusi yang mungkin adalah "mengajar" INSERT dari sesi yang berbeda untuk memotong lebih sedikit buffer.
Saatnya menggunakan perf
Utilitas
perf mengumpulkan banyak informasi diagnostik. Dalam mode
record ... ini menulis statistik peristiwa sistem ke file (secara default mereka berada di
./perf_data ), dan dalam mode
report ini menganalisis data yang dikumpulkan, misalnya, Anda dapat memfilter peristiwa yang hanya menyangkut
postgres atau
pid diberikan:
$ perf record -u postgres $ perf record -p 76876 , $ perf report > ./my_results
Akibatnya, kita akan melihat sesuatu seperti
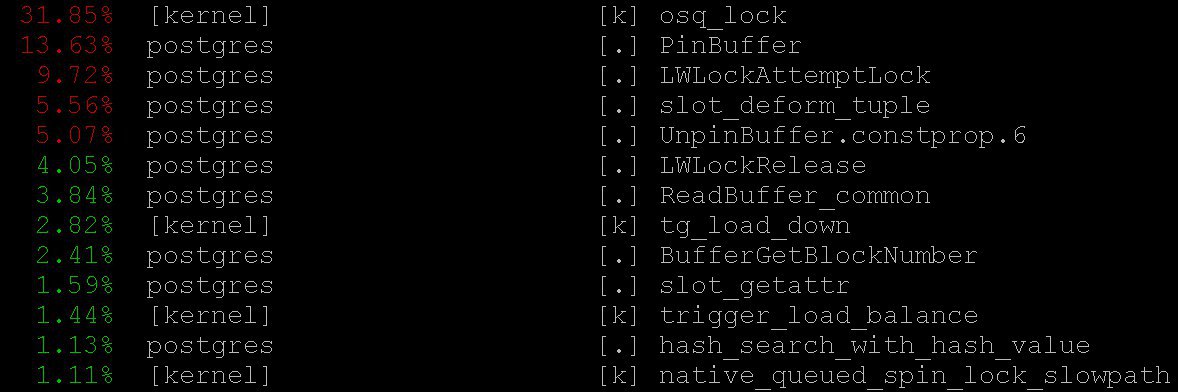
Cara menggunakan
perf untuk mendiagnosis PostgreSQL dijelaskan, misalnya, di
sini , serta di
wiki pg .
Dalam kasus kami, bahkan mode paling sederhana pun memberikan informasi penting -
perf top , yang berfungsi, tentu saja, dalam semangat sistem operasi
top . Dengan
perf top kami melihat bahwa sebagian besar waktu yang dihabiskan prosesor dalam
PinBuffer() inti, serta dalam fungsi
PinBuffer() dan
LWLockAttemptLock(). .
PinBuffer() adalah fungsi yang meningkatkan counter referensi ke buffer (memetakan halaman data ke RAM), berkat proses postgres yang tahu buffer mana yang dapat dipaksa keluar dan mana yang tidak bisa.
LWLockAttemptLock() - fungsi penangkapan
LWLock .
LWLock adalah sejenis kunci dengan dua tingkat yang
shared dan
exclusive , tanpa menentukan
deadlock , kunci telah dialokasikan sebelumnya ke
shared memory , proses menunggu menunggu dalam antrian.
Fungsi-fungsi ini telah dioptimalkan secara serius di PostgreSQL 9.5 dan 9.6. Spinlocks di dalamnya digantikan oleh penggunaan langsung operasi atom.
Grafik nyala
Tidak mungkin tanpa mereka: bahkan jika mereka tidak berguna, masih layak diceritakan tentang mereka - mereka luar biasa cantik. Tetapi mereka bermanfaat. Ini adalah ilustrasi dari
github , bukan dari kasus kami (kami maupun klien belum siap untuk mengungkapkan detailnya).

Gambar-gambar indah ini dengan sangat jelas menunjukkan apa yang dilakukan siklus prosesor.
perf sama dapat mengumpulkan data, tetapi
flame graph cerdas memvisualisasikan data, dan membangun pohon berdasarkan tumpukan panggilan yang dikumpulkan. Anda dapat membaca lebih lanjut tentang pembuatan profil dengan grafik nyala, misalnya, di
sini , dan unduh semua yang Anda butuhkan di
sini .
Dalam kasus kami, sejumlah besar
nestloop terlihat pada grafik nyala. Rupanya, GABUNGAN dari sejumlah besar tabel dalam berbagai permintaan baca bersamaan menyebabkan sejumlah besar kunci
access share .
Statistik yang dikumpulkan oleh
perf menunjukkan kemana siklus prosesor pergi. Dan meskipun kami melihat bahwa sebagian besar waktu prosesor melewati kunci, kami tidak melihat apa yang sebenarnya mengarah pada harapan kunci yang lama, karena kami tidak melihat dengan tepat di mana harapan kunci terjadi, karena Waktu CPU tidak sia-sia menunggu.
Untuk melihat harapan itu sendiri, Anda dapat membuat permintaan ke tampilan sistem
pg_stat_activity .
SELECT wait_event_type, wait_event, COUNT(*) FROM pg_stat_activity GROUP BY wait_event_type, wait_event;
mengungkapkan bahwa:
LWLockTranche | buffer_content | UPDATE ************* LWLockTranche | buffer_content | INSERT INTO ******** LWLockTranche | buffer_content | \r | | insert into B4_MUTEX | | values (nextval('hib | | returning ID Lock | relation | INSERT INTO B4_***** LWLockTranche | buffer_content | UPDATE ************* Lock | relation | INSERT INTO ******** LWLockTranche | buffer_mapping | INSERT INTO ******** LWLockTranche | buffer_content | \r
(tanda bintang di sini hanya mengganti detail permintaan yang tidak kami ungkapkan).
Anda dapat melihat nilai
buffer_content (memblokir konten buffer) dan
buffer_mapping (memblokir komponen dari plat hash
shared_buffers ).
Untuk bantuan ke gdb
Tetapi mengapa ada begitu banyak harapan untuk jenis kunci ini? Untuk informasi lebih rinci tentang harapan, saya harus menggunakan debugger
GDB . Dengan
GDB kita bisa mendapatkan setumpuk panggilan proses tertentu. Dengan menerapkan sampling, mis. Setelah mengumpulkan sejumlah tumpukan panggilan acak, Anda bisa mendapatkan gagasan tumpukan mana yang memiliki harapan terlama.
Pertimbangkan proses penyusunan statistik. Kami akan mempertimbangkan kumpulan statistik "manual", meskipun dalam kehidupan nyata skrip khusus digunakan yang melakukan ini secara otomatis.
Pertama,
gdb harus dilampirkan ke proses PostgreSQL. Untuk melakukan ini, cari
pid proses server, katakan dari
$ ps aux | grep postgres
Katakanlah kita menemukan:
postgres 2025 0.0 0.1 172428 1240 pts/17 S 23 0:00 /usr/local/pgsql/bin/postgres -D /usr/local/pgsql/data
dan sekarang masukkan
pid ke debugger:
igor_le:~$gdb -p 2025
Setelah di dalam debugger, kami menulis
bt [yaitu,
backtrace ] atau di
where . Dan kami mendapatkan banyak informasi tentang jenis ini:
(gdb) bt #0 0x00007fbb65d01cd0 in __write_nocancel () from /lib64/libc.so.6 #1 0x00000000007c92f4 in write_pipe_chunks ( data=0x110e6e8 "2018‐06‐01 15:35:38 MSK [524647]: [392‐1] db=bp,user=bp,app=[unknown],client=192.168.70.163 (http://192.168.70.163) LOG: relation 23554 new block 493: 248.389503\n2018‐06‐01 15:35:38 MSK [524647]: [393‐1] db=bp,user=bp,app=["..., len=409, dest=dest@entry=1) at elog.c:3123 #2 0x00000000007cc07b in send_message_to_server_log (edata=0xc6ee60 <errordata>) at elog.c:3024 #3 EmitErrorReport () at elog.c:1479
Setelah mengumpulkan statistik, termasuk tumpukan panggilan dari semua proses postgres, dikumpulkan berulang kali pada titik waktu yang berbeda, kami melihat bahwa
buffer partition lock di dalam
relation extension lock berlangsung 3706 detik (sekitar satu jam), yaitu, mengunci sepotong tabel hash buffer manajer, yang diperlukan untuk mengganti buffer lama, untuk kemudian menggantinya dengan yang baru yang sesuai dengan bagian tabel yang diperpanjang. Sejumlah kunci
buffer content lock juga terlihat, yang sesuai dengan harapan mengunci halaman indeks
B-tree untuk dimasukkan.

Pada awalnya, dua penjelasan datang untuk waktu tunggu yang mengerikan:
- Orang lain mengambil
LWLock ini dan terjebak. Tapi ini tidak mungkin. Karena tidak ada yang rumit terjadi di dalam kunci partisi penyangga. - Kami menemukan beberapa perilaku patologis
LWLock . Artinya, terlepas dari kenyataan bahwa tidak ada yang mengambil kunci terlalu lama, harapannya bertahan lama tidak masuk akal.
Tambalan diagnostik dan perawatan pohon
Dengan mengurangi jumlah koneksi simultan, kami mungkin akan mengalirkan aliran permintaan ke kunci. Tapi itu akan seperti menyerah. Alih-alih,
Alexander Korotkov , kepala arsitek Postgres Professional (tentu saja, ia membantu menyiapkan artikel ini), mengusulkan serangkaian tambalan.
Pertama-tama, perlu untuk mendapatkan gambaran yang lebih rinci tentang bencana. Tidak peduli sebagus apa pun alat yang digunakan, tambalan diagnostik buatan mereka sendiri juga akan bermanfaat.
Patch ditulis yang menambahkan pencatatan terperinci waktu yang dihabiskan dalam
relation extension , apa yang terjadi di dalam fungsi
RelationAddExtraBlocks() . Jadi kami mencari tahu berapa waktu yang dihabiskan di dalam
RelationAddExtraBlocks().Dan untuk mendukungnya, tambalan lain ditulis melaporkan dalam
pg_stat_activity tentang apa yang kita lakukan sekarang dalam
relation extension . Itu dilakukan dengan cara ini: ketika
relation berkembang,
application_name menjadi
RelationAddExtraBlocks . Proses ini sekarang mudah dianalisis dengan detail maksimum menggunakan
gdb bt dan
perf .
Sebenarnya tambalan medis (dan bukan diagnostik) ditulis dua. Tambalan pertama mengubah perilaku kunci daun
B‐tree : sebelumnya, ketika diminta untuk memasukkan, daun diblokir sebagai
share , dan setelah itu menjadi
exclusive . Sekarang dia langsung menjadi
exclusive . Sekarang tambalan
ini telah dikomit untuk
PostgreSQL 12 . Untungnya, tahun ini
Alexander Korotkov menerima
status committer - committer PostgreSQL kedua di Rusia dan yang kedua di perusahaan.
Nilai
NUM_BUFFER_PARTITIONS juga ditingkatkan dari 128 menjadi 512 untuk mengurangi beban pada kunci pemetaan: tabel hash manajer buffer dibagi menjadi potongan-potongan yang lebih kecil, dengan harapan bahwa beban pada setiap bagian tertentu akan berkurang.
Setelah menerapkan tambalan ini, kunci pada konten buffer hilang, tetapi meskipun ada peningkatan
NUM_BUFFER_PARTITIONS ,
buffer_mapping tetap ada, yaitu, kami mengingatkan Anda tentang memblokir bagian dari tabel hash manajer buffer:
locks_count | active_session | buffer_content | buffer_mapping ----‐‐‐--‐‐‐+‐------‐‐‐‐‐‐‐‐‐+‐‐‐------‐‐‐‐‐‐‐+‐‐------‐‐‐ 12549 | 1218 | 0 | 15
Dan itu pun tidak banyak. B - tree tidak lagi menjadi hambatan. Perpanjangan
heap- datang ke depan.
Perawatan hati nurani
Selanjutnya, Alexander mengajukan hipotesis dan solusi berikut:
Kami menunggu banyak waktu pada
buffer parittion lock ketika
buffer parittion lock buffer. Mungkin pada
buffer parittion lock sama ada beberapa halaman yang sangat dituntut, misalnya, root dari beberapa
B‐tree . Pada titik ini ada aliran permintaan terus menerus untuk
shared lock dari permintaan membaca.
LWLock di
LWLock “tidak adil.” Karena
shared lock dapat diambil sebanyak yang dibutuhkan sekaligus, maka jika
shared lock sudah diambil, maka
shared lock selanjutnya lewat tanpa antrian. Dengan demikian, jika aliran kunci bersama adalah intensitas yang cukup sehingga tidak ada "jendela" di antara mereka, maka menunggu
exclusive lock berjalan hampir hingga tak terbatas.
Untuk memperbaikinya, Anda dapat mencoba menawarkan - sepetak kunci "sopan" dari kunci. Ini membangkitkan hati nurani dari
shared locker dan mereka jujur mengantri ketika sudah ada
exclusive lock (yang menarik, kunci berat -
hwlock - tidak memiliki masalah dengan hati nurani: mereka selalu jujur mengantri)
locks_count | active_session | buffer_content | buffer_mapping | reladdextra | inserts>30sec ‐‐‐‐‐‐-‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐+‐‐‐‐‐‐‐‐‐‐‐--‐-‐+‐‐‐‐‐‐-‐‐‐‐‐‐+‐‐‐‐------ 173985 | 1802 | 0 | 569 | 0 | 0
Semuanya baik-baik saja! Tidak ada
insert panjang. Meskipun kunci pada potongan pelat hash tetap ada. Tapi apa yang harus dilakukan, ini adalah sifat-sifat ban superkomputer kecil kami.
Tambalan ini juga
ditawarkan kepada komunitas . Tetapi tidak peduli bagaimana nasib patch ini dalam komunitas berkembang, tidak ada yang menghalangi mereka untuk masuk ke versi
Postgres Pro Enterprise berikutnya , yang dirancang khusus untuk pelanggan dengan sistem yang sarat muatan.
Akhlak
Kunci
share ringan bermoral tinggi - blok
exclusive melewatkan antrian - telah memecahkan masalah keterlambatan per jam dalam sistem multi-simpul. Tag hash
buffer manager tidak berfungsi karena terlalu banyak aliran
share lock , yang tidak memberikan peluang bagi kunci yang diperlukan untuk mengganti buffer lama dan memuat yang baru. Masalah dengan ekstensi buffer untuk tabel database hanya konsekuensi dari ini. Sebelum ini, adalah mungkin untuk memperluas bottleneck dengan akses ke root
B-tree .
PostgreSQL tidak dirancang untuk arsitektur dan superkomputer NUMA. Beradaptasi dengan arsitektur Postgres seperti itu adalah pekerjaan besar yang akan membutuhkan (dan mungkin memerlukan) upaya terkoordinasi dari banyak orang dan bahkan perusahaan. Tetapi konsekuensi yang tidak menyenangkan dari masalah arsitektur ini dapat dikurangi. Dan kita harus: jenis-jenis beban yang menyebabkan penundaan yang serupa dengan yang dijelaskan cukup tipikal, sinyal marabahaya yang serupa dari tempat lain terus mendatangi kita. Masalah serupa muncul sebelumnya - pada sistem dengan core lebih sedikit, hanya konsekuensinya tidak begitu mengerikan, dan gejalanya diobati dengan metode lain dan patch lainnya. Sekarang obat lain telah muncul - tidak universal, tetapi jelas bermanfaat.
Jadi, ketika PostgreSQL bekerja dengan memori seluruh sistem sebagai lokal, tidak ada bus berkecepatan tinggi antara node yang dapat dibandingkan dengan waktu akses ke memori lokal. Tugas muncul karena ini sulit, seringkali mendesak, tetapi menarik. Dan pengalaman memecahkannya bermanfaat tidak hanya untuk yang menentukan, tetapi juga untuk seluruh komunitas.
