
Setiap teknologi yang diciptakan sejak saat seseorang mengambil batu wajib meningkatkan kehidupan seseorang, melakukan fungsi utamanya. Namun, teknologi apa pun dapat memiliki "efek samping", yaitu, memengaruhi seseorang dan dunia di sekitarnya dengan cara yang tak seorang pun pada saat membuat teknologi ini memikirkan atau ingin memikirkannya. Contoh nyata: mesin diciptakan, dan seseorang dapat bergerak jarak jauh dengan kecepatan lebih cepat dari sebelumnya. Tetapi pada saat yang sama polusi mulai.
Hari ini kita akan berbicara tentang "efek samping" dari Internet, yang tidak memengaruhi atmosfer Bumi, tetapi pikiran dan jiwa orang-orang itu sendiri. Faktanya adalah bahwa World Wide Web telah menjadi alat yang sangat baik untuk penyebaran dan pertukaran informasi, untuk komunikasi antara orang-orang yang secara fisik jauh dari satu sama lain dan untuk lebih banyak lagi. Internet membantu dalam berbagai bidang masyarakat, dari kedokteran hingga persiapan dangkal untuk ujian sejarah. Namun, tempat di mana banyak sekali, terkadang tanpa nama, suara dan pendapat berkumpul, sayangnya, dipenuhi dengan apa yang begitu melekat dalam kebencian manusia.
Dalam studi hari ini, para ilmuwan memecah beberapa algoritma yang tugas utamanya adalah mengidentifikasi pesan yang ofensif, kasar, dan bermusuhan. Mereka berhasil memecah semua algoritma ini, dengan demikian menunjukkan tingkat efisiensi yang rendah dan menunjukkan kesalahan-kesalahan yang harus diperbaiki. Bagaimana para ilmuwan memecahkan apa yang seharusnya bekerja, mengapa mereka melakukannya, dan kesimpulan apa yang harus kita ambil - kita akan mencari jawaban untuk ini dan pertanyaan lain dalam laporan para peneliti. Ayo pergi.
Latar belakang penelitianJejaring sosial dan bentuk-bentuk lain dari interaksi internet antara orang-orang telah menjadi bagian integral dari kehidupan kita. Sayangnya, banyak pengguna layanan semacam itu yang secara harafiah memahami hal seperti "kebebasan berbicara, berpikir dan berekspresi", menutupi hal ini dengan hak mereka untuk perilaku tidak senonoh, akrab, dan kasar di jaringan. Kita masing-masing dengan satu atau lain cara dihadapkan dengan "aktivitas" orang-orang tersebut. Banyak yang bahkan menjadi objek pidato tersebut. Tentu saja, tidak dapat dipungkiri bahwa seseorang memiliki hak untuk mengatakan apa yang ia pikirkan. Namun, mengekspresikan pikiran Anda adalah satu hal, dan menghina seseorang adalah hal lain. Selain kebebasan berbicara, anonimitas juga dieksploitasi, karena Anda dapat mengatakan apa saja kepada siapa saja, sambil tetap menyamar. Akibatnya, Anda tidak akan dihukum karena perilaku tidak pantas Anda.
Tidak ada gunanya menjelaskan bahwa frasa “Aku tidak menyukainya” dan “ini benar-benar bercinta **, penulis bunuh di tembok” (ini adalah pilihan yang bahkan lebih baik) memiliki warna emosional yang sama sekali berbeda, meskipun mereka memiliki esensi yang sama - kepada komentator Saya tidak suka apa yang dia lihat / baca / dengar, dll. Tetapi jika Anda melarang seseorang untuk mengungkapkan ketidakpuasan mereka dengan cara ini, apakah ini dianggap sebagai pelanggaran terhadap haknya? Banyak yang akan mengatakan ya. Di sisi lain, apakah itu layak untuk terus menutup mata terhadap kebencian yang tumbuh secara eksponensial di Internet, yang dalam banyak kasus tidak dibenarkan. Kebencian, dengan demikian, memiliki tempatnya. Tentu saja, ini adalah emosi yang sangat kuat dan sangat negatif. Namun, jika seseorang membenci orang yang melakukan sesuatu yang mengerikan (pembunuhan, pemerkosaan, dan tindakan tidak manusiawi lainnya), ini masih bisa dibenarkan. Tetapi ketika kebencian memanifestasikan dirinya dalam pidato orang yang sama sekali asing yang tidak melakukan sesuatu yang tidak bermoral atau tidak manusiawi, ini adalah kisah yang sama sekali berbeda.
Sekarang banyak perusahaan dan kelompok penelitian telah memutuskan untuk membuat algoritme mereka sendiri yang dapat menganalisis teks apa pun dan memberi tahu di mana
bahasa permusuhan * ada, dan sejauh mana dinyatakan. Pahlawan kita saat ini memutuskan untuk menguji algoritme ini, khususnya, Google Perspective API yang sangat dipromosikan, yang menentukan “keasaman” dari frasa tersebut, mis. seberapa banyak frasa ini dapat dianggap sebagai penghinaan.
Benci pidato * - seperti yang jelas dari nama istilah ini, itu adalah kombinasi dari bahasa yang ditujukan untuk mengekspresikan permusuhan yang jelas antara lawan bicara. Bentuk paling umum dari pidato kebencian adalah: rasisme, seksisme, xenofobia, homofobia dan bentuk permusuhan lainnya terhadap sesuatu yang lain.
Tugas utama yang ditetapkan para peneliti untuk diri mereka sendiri adalah mempelajari algoritma yang paling populer untuk mengidentifikasi ucapan kebencian, memahami metode kerja mereka dan mencoba menyiasatinya.
Algoritma PenelitianPara ilmuwan telah memilih beberapa algoritma yang databasenya berbeda satu sama lain, yang memungkinkan kami untuk menentukan basis data terbaik juga. Beberapa algoritma lebih bergantung pada pengidentifikasian
konotasi seksual
* , yang lain - yang religius. Umum untuk semua algoritma adalah sumber pengetahuan mereka - Twitter. Menurut para peneliti, ini jauh dari sempurna, karena layanan ini memiliki batasan tertentu (misalnya, jumlah karakter dalam satu pesan). Oleh karena itu, dasar dari algoritma yang efektif harus diisi dari berbagai jejaring dan layanan sosial.
Konotasi * - metode pewarnaan kata atau frasa dengan nuansa semantik atau emosional tambahan. Dapat bervariasi tergantung pada linguistik, budaya atau bentuk pemisahan sosial lainnya. Contoh: windy - “hari itu berangin” (arti langsung dari kata itu), “dia selalu orang yang berangin” (dalam hal ini, itu berarti ketidakkekalan dan kesembronoan).
Daftar algoritma dan fungsinya:
Detox : proyek Wikipedia untuk mengidentifikasi bahasa yang tidak pantas dalam komentar editorial. Ia bekerja berdasarkan
regresi logistik * dan
perceptron multilayer * , menggunakan model
N-gram * pada level huruf dan kata. Ukuran N-gram kata bervariasi dari 1 hingga 3, dan huruf - dari 1 hingga 5.
Regresi logistik * adalah model untuk memprediksi probabilitas suatu peristiwa dengan memasukkan data ke kurva logistik.
Multilayer perceptron * adalah model persepsi informasi, yang terdiri dari tiga lapisan utama: S - sensor (menerima sinyal), A - elemen asosiatif (pemrosesan) dan elemen bereaksi-R (respons terhadap sinyal), serta lapisan tambahan A.
N-gram * adalah urutan n elemen.
Data untuk basis algoritma dikumpulkan oleh pihak ketiga, dan masing-masing komentar dievaluasi oleh sepuluh evaluator.
T1 : algoritma dengan basis dibagi menjadi tiga jenis komentar dari Twitter (ucapan kebencian, penghinaan tanpa ucapan kebencian dan netral). Para peneliti mengatakan ini adalah satu-satunya basis dengan kategorisasi serupa. Benci pidato terdeteksi oleh pencarian di Twitter untuk pola yang diberikan. Selanjutnya, hasil yang ditemukan dievaluasi oleh tiga karyawan CrowdFlower (sekarang Gambar Eight Inc., sebuah studi pembelajaran mesin dan kecerdasan buatan). Sebagian besar basis (76%) adalah frase yang ofensif, sementara bahasa yang bermusuhan hanya memakan 5%.
T2 : sebuah algoritma menggunakan jaringan saraf yang dalam. Penekanan utama ditempatkan pada memori jangka pendek jangka panjang (LSTM). Dasar dari algoritma ini dibagi menjadi tiga kategori: rasisme, seksisme dan tidak ada. Para peneliti menggabungkan dua kategori pertama menjadi satu, membentuk kategori integral dari bahasa yang bermusuhan. Basis pangkalan adalah 16.000 tweets.
T1 * ,
T3 : algoritma yang didasarkan pada jaringan saraf convolutional (CNN) dan unit perulangan terkontrol (GRU), menggunakan basis pengetahuan T1, melengkapi dengan kategori terpisah yang ditujukan untuk pengungsi dan Muslim (T3).
Performa AlgoritmaKinerja algoritma diuji dengan dua metode. Pada awalnya, mereka bekerja seperti yang dimaksudkan semula. Dan yang kedua, algoritma dilatih melalui database masing-masing, semacam pertukaran pengalaman.
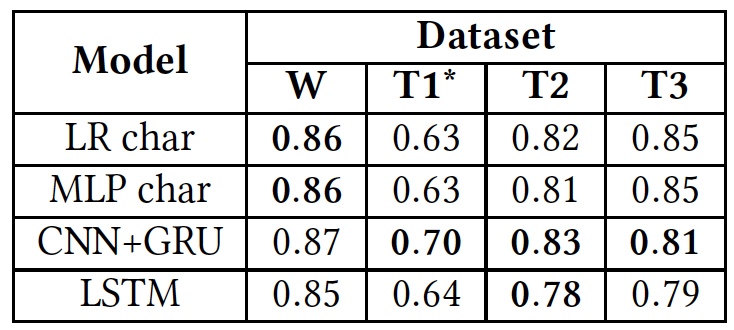 Hasil pengujian (hasil menggunakan database asli dicetak tebal).
Hasil pengujian (hasil menggunakan database asli dicetak tebal).Seperti yang dapat dilihat dari tabel di atas, semua algoritma menunjukkan hasil yang kira-kira sama ketika diterapkan pada teks yang berbeda (database). Ini menunjukkan bahwa mereka semua belajar menggunakan jenis teks yang sama.
Satu-satunya penyimpangan signifikan terlihat pada T1 *. Ini disebabkan oleh fakta bahwa database dari algoritma ini sangat tidak seimbang, menurut para ilmuwan. Benci pidato hanya membutuhkan 5%, seperti yang kita sudah tahu. Pembagian awal menjadi tiga kategori teks diubah menjadi pembagian menjadi dua, ketika "menghina, tetapi tanpa bahasa yang bermusuhan" dan teks "netral" digabungkan menjadi satu kelompok, menempati sekitar 80% dari seluruh basis.
Selanjutnya, para peneliti melatih kembali algoritma. Pada awalnya, basis asli digunakan. Setelah itu, masing-masing algoritma harus bekerja dengan basis algoritma lain, bukan sendiri.
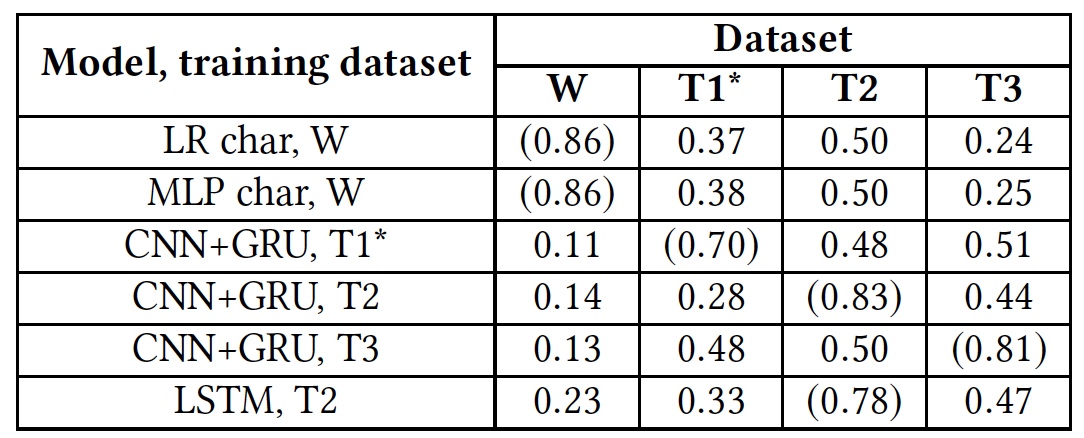 Pelatihan ulang hasil tes (hasil menggunakan database asli ditampilkan dalam tanda kurung).
Pelatihan ulang hasil tes (hasil menggunakan database asli ditampilkan dalam tanda kurung).Tes ini menunjukkan bahwa semua algoritma sama sekali tidak siap untuk bekerja dengan database asing. Ini menunjukkan bahwa indikator linguistik dari ujaran kebencian tidak berpotongan di basis data yang berbeda, yang mungkin disebabkan oleh fakta bahwa dalam basis data yang berbeda ada sangat sedikit kata yang cocok, atau karena ketidakakuratan dalam penafsiran frasa tertentu.
Penghinaan dan kebencianPara peneliti memutuskan untuk memberikan perhatian khusus pada dua kategori teks: ofensif dan bermusuhan. Intinya adalah bahwa beberapa algoritma menggabungkan mereka menjadi satu tumpukan, sementara yang lain mencoba untuk memisahkan mereka sebagai kelompok independen. Tentu saja, penghinaan jelas merupakan fenomena negatif, dan dapat dengan aman dikaitkan dengan satu kategori dengan permusuhan. Namun, mendefinisikan penghinaan adalah proses yang jauh lebih rumit daripada mengidentifikasi kebencian yang tampak dalam teks.
Untuk menguji algoritma untuk kemampuan mendeteksi penghinaan, basis T1 digunakan. Tetapi algoritma T1 * tidak ikut serta dalam pengujian ini, karena fakta bahwa ia sudah dipersiapkan untuk pekerjaan seperti itu, yang membuat hasil verifikasi menjadi bias.
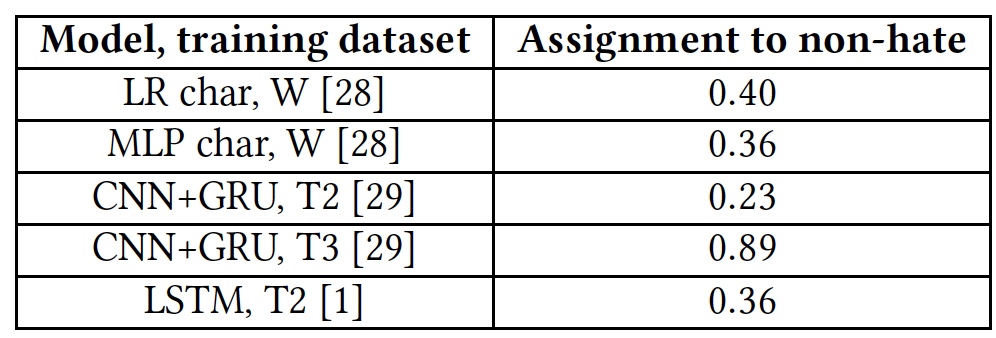 Hasil pengujian untuk kemampuan mendeteksi teks yang ofensif.
Hasil pengujian untuk kemampuan mendeteksi teks yang ofensif.Semua algoritma menunjukkan hasil yang agak biasa-biasa saja. Pengecualian adalah T3, tetapi tidak dengan mengorbankan bakat mereka. Faktanya adalah bahwa kata-kata yang tidak terbiasa dengan algoritma ditandai dengan tag
unk . Hampir 40% dari kata-kata dalam setiap kalimat ditandai dengan tag ini, dan algoritma secara otomatis menghitungnya sebagai penghinaan. Dan ini, tentu saja, jauh dari selalu benar. Dengan kata lain, algoritma T3 juga tidak mengatasi tugas mengingat kosakata singkatnya.
Salah satu masalah utama algoritma, para ilmuwan mempertimbangkan faktor manusia. Sebagian besar database dari masing-masing algoritma dikumpulkan, dianalisis, dan dievaluasi oleh orang-orang. Dan di sini, perbedaan hasil yang kuat dimungkinkan. Ungkapan yang sama mungkin tampak ofensif bagi sebagian orang atau netral terhadap yang lain.
Juga, kurangnya algoritma untuk memahami frasa non-standar yang dapat dengan tenang mengandung bahasa kotor, tetapi tanpa penghinaan atau bahasa permusuhan, juga memainkan efek negatif.
Untuk menunjukkan ini, tes dengan beberapa frasa dilakukan. Kemudian tes diulangi, tetapi di setiap frasa kata yang sangat cabul "
f * ck " ditambahkan (ditandai dengan huruf
F dalam tabel).
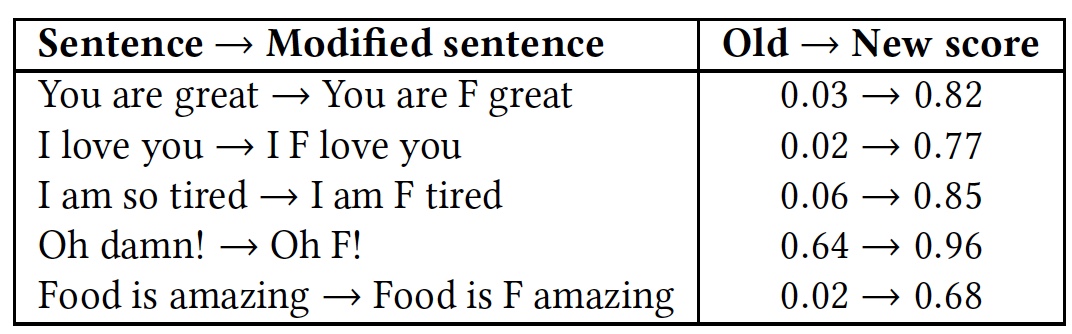 Hasil pengakuan komparatif dari frasa dengan dan tanpa kata "f * ck".
Hasil pengakuan komparatif dari frasa dengan dan tanpa kata "f * ck".Seperti dapat dilihat dari tabel, itu layak menambahkan kata dengan huruf F, karena semua algoritma segera mengambil frasa sebagai bahasa permusuhan. Meskipun esensi dari frasa tetap sama, ramah, tetapi warna emosional berubah menjadi lebih jelas.
Tes Google Perspective API yang dijelaskan di atas menunjukkan hasil yang serupa. Algoritma ini juga tidak dapat membedakan bahasa yang bermusuhan dari penghinaan, dan penghinaan dari julukan sederhana yang digunakan untuk secara emosional memperindah frase.
Bagaimana cara mengelabui algoritma?Seperti yang sering terjadi, jika seseorang merusak sesuatu, maka ini tidak selalu buruk. Dan semua karena ketika kita istirahat, kita mengungkapkan kurangnya sistem, titik lemahnya, yang harus diperbaiki dengan mencegah pengulangan kerusakan. Model-model di atas tidak terkecuali, dan para peneliti memutuskan untuk melihat bagaimana pekerjaan mereka dapat terganggu. Ternyata, itu tidak sesulit yang dipikirkan oleh pencipta algoritma ini.
Model algoritma bypass sederhana: cracker tahu bahwa teksnya diperiksa, ia dapat mengubah input data (teks) sedemikian rupa untuk menghindari deteksi. Cracker tidak memiliki akses ke algoritma itu sendiri dan strukturnya. Sederhananya, penyerang memecah algoritma secara eksklusif di tingkat pengguna.
Algoritma bypass (sebut saja kata lama yang bagus "peretasan") dibagi menjadi tiga jenis:
- Mengubah kata: kesalahan ketik yang disengaja dan Leet, yaitu, mengganti beberapa huruf dengan angka (misalnya: Anda tampak hebat hari ini! - Y0U 100K 6r347 70D4Y!);
- Ubah spasi antar kata: tambah dan hapus spasi;
- Tambahkan kata di akhir frasa.
Program peretasan pertama - mengubah kata - harus berhasil menyelesaikan tiga tugas: mengurangi tingkat pengenalan kata oleh suatu algoritma, menghindari koreksi ejaan, dan menjaga keterbacaan kata-kata untuk seseorang.
Program ini menukar dua huruf dalam kata. Preferensi diberikan untuk huruf yang lebih dekat ke tengah kata dan satu sama lain. Hanya huruf pertama dan terakhir dalam kata yang dikecualikan. Selanjutnya, kata-kata tersebut dimodifikasi dengan pandangan pada Leet, di mana beberapa huruf diganti dengan angka: a - 4, e - 3, l - 1, o - 0, s - 5.
Untuk menghadapi trik semacam itu, algoritma sedikit ditingkatkan dengan memperkenalkan pemeriksaan ejaan dan transformasi stokastik dari basis pengetahuan pelatihan. Artinya, tidak hanya kata-kata utama yang hadir dalam database, tetapi juga kata-kata mereka diubah dengan mengatur ulang huruf-huruf formulir.
Namun, semakin lama kata itu, semakin banyak opsi untuk mengatur ulang huruf, yang memperluas kemampuan program cracker.
Metode menghilangkan atau menambah spasi juga memiliki karakteristiknya sendiri. Menghapus spasi lebih cocok untuk menentang algoritme yang menguraikan seluruh kata. Tetapi algoritma yang menganalisis setiap huruf dapat dengan mudah mengatasi ketiadaan spasi.
Menambahkan spasi mungkin tampak seperti metode yang sangat tidak efisien, tetapi masih bisa menipu beberapa algoritma. Model yang menganggap kata-kata secara keseluruhan melakukan analisis leksikal dari frasa, memecahnya menjadi komponen (token). Dalam hal ini, ruang berfungsi sebagai pemisah kata, yaitu elemen penting dari analisis frase. Jika ada lebih banyak celah dari yang diperlukan, maka kata-kata di antara mereka menjadi tidak dapat dikenali untuk algoritma. Pada saat yang sama, metode memotong ini mempertahankan tingkat keterbacaan frase yang tinggi bagi manusia. Metode ini bekerja secara sederhana: huruf acak dalam kata dipilih, setelah spasi dimasukkan. Akibatnya, sebuah kata yang sebelumnya dikenal dengan algoritma tidak lagi seperti itu. Contoh: "Benci" - "benci." Jika Anda menghapus semua celah dalam teks, maka seluruh frasa akan menjadi algoritma satu kata yang tidak dapat dipahami baginya. Seperti dalam kisah di mana putrinya memberi ibunya telepon baru, dan dia menulis SMS kepadanya dengan teks: "Sayang meninggalkan telepon kosong di telepon ini." Kita dapat membaca frasa ini, tetapi algoritma akan melihatnya sebagai satu kata, yang, tentu saja, dia tidak tahu.
Namun, jika algoritma menganalisis surat-surat secara terpisah, maka akan dapat mengenali frasa, karena itu metode peretasan ini tidak cocok dalam kasus tersebut.
Untuk mengatasi serangan seperti itu, algoritma juga dilatih ulang. Untuk memerangi penambahan spasi, basis algoritme melalui program pengenalan spasi acak: kata n huruf dapat dipisahkan dengan spasi dengan cara n-1. Namun, ini menyebabkan ledakan kombinatorial, ketika kompleksitas algoritma meningkat tajam karena peningkatan ukuran data input. Akibatnya, mempelajari algoritma berdasarkan metode penambahan ruang yang terkenal adalah latihan yang sangat sulit dan tidak efisien.
Menghapus ruang juga sulit. Jika basis algoritma diisi kembali dengan frasa yang dia tahu, tetapi tanpa spasi, maka ini akan bekerja secara efektif hanya ketika frasa seperti itu diterapkan. Perlu mengganti beberapa huruf atau kata, dan algoritme tidak mengenali apa pun.
Dalam metode peretasan dengan menambahkan kata-kata, intinya adalah bagaimana algoritma pengenalan bekerja. Dia membagi kata-kata menjadi beberapa kategori, mengatakan "baik" dan "buruk". Jika frasa memiliki lebih banyak yang "baik", maka kemungkinan besar algoritma akan menentukan keseluruhan frasa sebagai "baik". Begitu juga sebaliknya. Jika Anda menambahkan kata acak “baik” ke frasa “buruk” dalam artinya, maka Anda dapat menipu algoritme, dan makna kalimat untuk orang yang membacanya akan tetap sama. Program peretasan menghasilkan angka acak (dari 10 hingga 50) atau kata-kata di akhir setiap frasa. Daftar kata-kata bahasa Inggris umum yang paling umum disediakan oleh Google dipilih sebagai sumber kata-kata acak.
 Tabel hasil penerapan metode peretasan dan reaksi algoritma di atas untuk ini (serangan-A, pelatihan-AT berdasarkan pada prinsip program serangan, periksa ejaan-SC, RW-menghilangkan ruang).
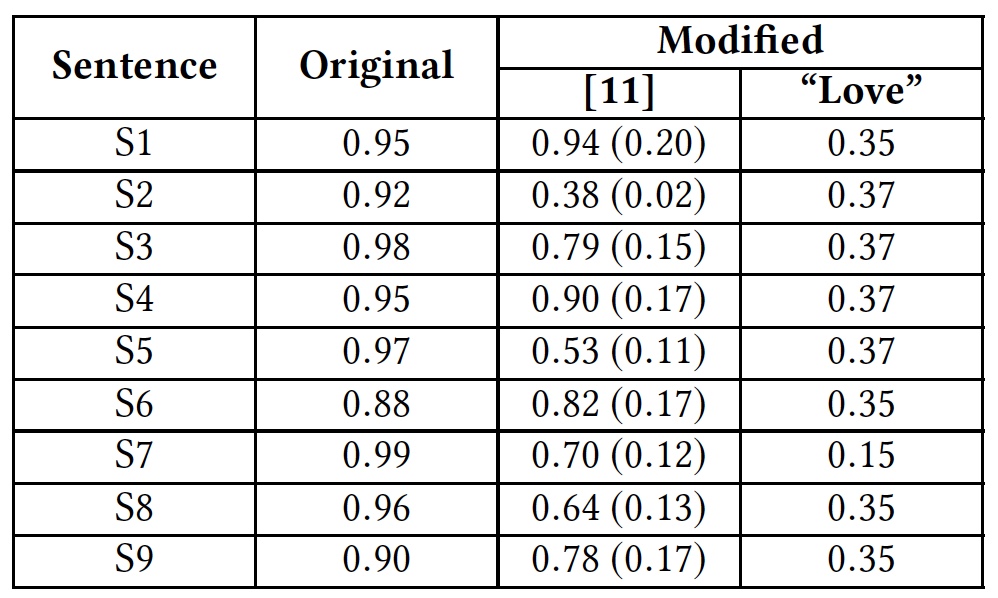
Tabel hasil penerapan metode peretasan dan reaksi algoritma di atas untuk ini (serangan-A, pelatihan-AT berdasarkan pada prinsip program serangan, periksa ejaan-SC, RW-menghilangkan ruang).Untuk menggambarkan solusi dengan memperkenalkan kata-kata tambahan, para peneliti melakukan tes menggunakan kata "cinta". Kata ini ditambahkan pada akhir kalimat ofensif.
 Tes hasil dengan kata "cinta".
Tes hasil dengan kata "cinta".Tabel tersebut menunjukkan bahwa metode ini mampu menipu semua algoritma yang menganalisis seluruh kata. Algoritma yang menganalisis surat secara terpisah juga menderita, tetapi tidak terlalu banyak.
Google Perspective API , .
( ):S1: Climate change is happening and it's not changing in our favor. If you think differently you're an idiot.
S2: They're stupid, it's getting warmer, we should enjoy it while it lasts
S3: They are liberal idiots who are uneducated
S4: idiots. backward thinking people. nationalists. not accepting facts. susceptible to lies.
S5: They are stupid and ignorant with no class
S6: It's stupid and wrong
S7: If they voted for Hilary they are idiots
S8: Anyone who voted for Trump is a moron
S9: Screw you trump supporters
. , , Google Perspective API . «love» .
 Google Perspective API: «» () .
Google Perspective API: «» () ., Google Perspective API.
,
.
, , , .
, , . ? ? , ? : , , , . , , ? . , , . , — ?
, . ? ? ,
30% entry-level , : VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps $20 ? ( RAID1 RAID10, 24 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps ,
.
Dell R730xd 2 ? 2 Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 $249 ! . c Dell R730xd 5-2650 v4 9000 ?