
Ini adalah artikel terakhir dari serangkaian artikel pelatihan untuk pengembang di bidang kecerdasan buatan. Ini membahas langkah-langkah untuk membuat model pembelajaran yang mendalam untuk generasi musik, memilih model yang tepat dan preprocessing data, dan menjelaskan prosedur untuk pengaturan, pelatihan, pengujian dan modifikasi BachBot.
Generasi Musik - Berpikir Tentang Suatu Tugas
Langkah pertama dalam memecahkan banyak masalah menggunakan kecerdasan buatan (AI) adalah untuk mengurangi masalah menjadi masalah dasar yang dapat diselesaikan dengan cara AI. Salah satu masalah tersebut adalah prediksi urutan, yang digunakan dalam terjemahan bahasa alami dan aplikasi pemrosesan. Tugas kita menghasilkan musik dapat direduksi menjadi masalah memprediksi urutan, dan prediksi akan dilakukan untuk urutan catatan musik.
Pemilihan model
Ada beberapa jenis jaringan saraf yang dapat dianggap sebagai model: jaringan saraf distribusi langsung, jaringan saraf berulang, dan jaringan saraf memori jangka panjang.
Neuron adalah elemen abstrak dasar yang bergabung membentuk jaringan saraf. Pada dasarnya, neuron adalah fungsi yang menerima data pada input dan output hasilnya.
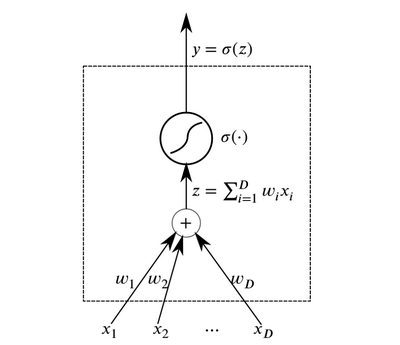 Neuron
NeuronLapisan neuron yang menerima data yang sama pada input dan output yang terhubung dapat dikombinasikan untuk membangun
jaringan saraf dengan propagasi langsung . Jaringan saraf tersebut menunjukkan hasil yang tinggi karena komposisi fungsi aktivasi nonlinier ketika melewatkan data melalui beberapa lapisan (yang disebut deep learning).
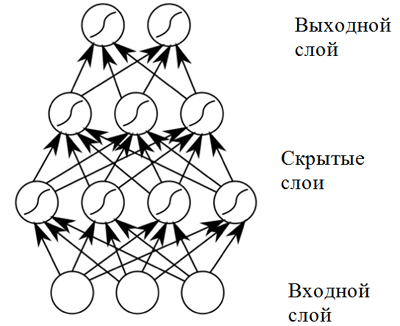 Jaringan saraf distribusi langsung
Jaringan saraf distribusi langsungJaringan saraf distribusi langsung menunjukkan hasil yang baik dalam berbagai aplikasi. Namun, jaringan saraf semacam itu memiliki satu kelemahan yang tidak memungkinkannya digunakan dalam tugas yang berkaitan dengan komposisi musik (prediksi urutan): ia memiliki dimensi data input yang tetap, dan komposisi musik dapat memiliki panjang yang berbeda. Selain itu,
jaringan saraf distribusi langsung tidak mempertimbangkan input dari langkah waktu sebelumnya, yang membuatnya tidak terlalu berguna untuk memecahkan masalah prediksi urutan! Model yang disebut
jaringan saraf berulang lebih cocok untuk tugas ini.
Jaringan saraf rekursif menyelesaikan kedua masalah ini dengan memperkenalkan tautan antara simpul tersembunyi: dalam hal ini, pada langkah waktu berikutnya, simpul dapat menerima informasi tentang data pada langkah waktu sebelumnya.
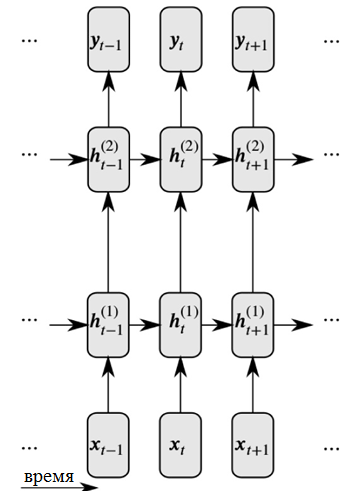 Representasi terperinci dari jaringan saraf berulang
Representasi terperinci dari jaringan saraf berulangSeperti yang Anda lihat pada gambar, setiap neuron sekarang menerima input dari kedua lapisan saraf sebelumnya dan waktu sebelumnya.
Jaringan saraf rekursif yang berurusan dengan sekuens input besar menghadapi apa yang disebut
masalah gradien menghilang : ini berarti bahwa pengaruh dari langkah waktu sebelumnya dengan cepat menghilang. Masalah ini adalah karakteristik tugas komposisi musik, karena ada ketergantungan jangka panjang yang penting dalam karya musik yang harus diperhitungkan.
Untuk mengatasi masalah gradien yang hilang, modifikasi jaringan berulang, yang disebut
jaringan saraf dengan memori jangka pendek (atau jaringan saraf LSTM), dapat digunakan . Masalah ini diselesaikan dengan memperkenalkan sel-sel memori, yang dipantau dengan cermat oleh tiga jenis "gerbang". Klik tautan berikut untuk informasi lebih lanjut:
Informasi umum tentang jaringan saraf LSTM .
Dengan demikian, BachBot menggunakan model yang didasarkan pada jaringan saraf LSTM.
Pretreatment
Musik adalah bentuk seni yang sangat kompleks dan mencakup berbagai dimensi: nada, irama, tempo, nuansa dinamis, artikulasi dan banyak lagi. Untuk menyederhanakan musik untuk keperluan proyek ini
, hanya nada dan durasi suara yang dipertimbangkan . Selain itu, semua paduan suara
dialihkan ke kunci dalam C mayor atau A minor, dan durasi nada
dihitung dalam waktu (dibulatkan) ke kelipatan terdekat dari nada keenam belas. Tindakan ini diambil untuk mengurangi kompleksitas komposisi dan meningkatkan kinerja jaringan, sementara konten dasar musik tetap tidak berubah. Operasi untuk menormalkan nada dan durasi nada dilakukan menggunakan perpustakaan music21.
def standardize_key(score): """Converts into the key of C major or A minor. Adapted from https://gist.github.com/aldous-rey/68c6c43450517aa47474 """
Kode yang digunakan untuk membakukan karakter kunci dalam karya yang dikumpulkan, kunci dalam C mayor atau A minor digunakan dalam outputKuantisasi waktu untuk kelipatan terdekat dari catatan keenambelas dilakukan menggunakan fungsi
Stream.quantize () dari perpustakaan
music21 . Berikut ini adalah perbandingan statistik yang terkait dengan kumpulan data sebelum dan sesudah pemrosesan pendahuluan:
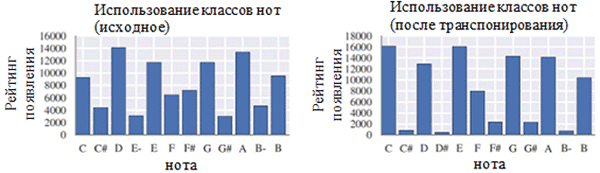 Menggunakan setiap kelas catatan sebelum (kiri) dan setelah preprocessing (kanan). Kelas catatan adalah catatan terlepas dari oktafnya.
Menggunakan setiap kelas catatan sebelum (kiri) dan setelah preprocessing (kanan). Kelas catatan adalah catatan terlepas dari oktafnya.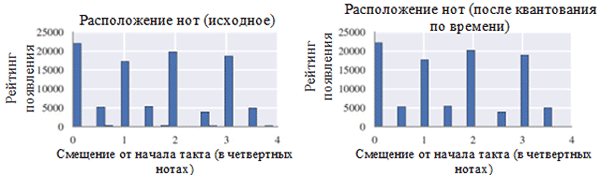 Lokasi catatan sebelum (kiri) dan setelah preprocessing (kanan)
Lokasi catatan sebelum (kiri) dan setelah preprocessing (kanan)Seperti yang Anda lihat pada gambar di atas, transposisi kunci asli paduan suara ke kunci C mayor atau C minor (A minor) secara signifikan memengaruhi kelas nada yang digunakan dalam karya yang dikumpulkan. Secara khusus, jumlah kemunculan untuk catatan dalam kunci di kunci utama (C mayor) dan A minor (A minor) (C, D, E, F, G, A, B) meningkat. Anda juga dapat mengamati puncak kecil untuk catatan F # dan G # karena keberadaannya dalam urutan melodi A minor (A, B, C, D, E, F # dan G #).
Di sisi lain, kuantisasi waktu memiliki efek yang jauh lebih kecil. Ini dapat dijelaskan dengan resolusi tinggi kuantisasi (mirip dengan pembulatan ke banyak digit signifikan).
Coding
Setelah data telah diproses sebelumnya, perlu untuk menyandikan paduan suara ke dalam format yang dapat dengan mudah diproses menggunakan jaringan saraf berulang. Format yang diperlukan adalah
urutan token . Untuk proyek BachBot, pengkodean dipilih pada tingkat catatan (setiap token mewakili catatan) alih-alih tingkat akor (setiap token mewakili akor). Solusi ini mengurangi ukuran kamus dari 128
4 kemungkinan akor menjadi 128 kemungkinan nada, yang memungkinkan untuk meningkatkan efisiensi kerja.
Skema pengkodean asli untuk komposisi musik diciptakan untuk proyek BachBot. Paduan suara dibagi menjadi langkah-langkah waktu yang sesuai dengan nada keenambelas. Langkah-langkah ini disebut bingkai. Setiap bingkai berisi urutan tupel yang mewakili nilai nada catatan dalam format antarmuka alat musik digital (MIDI) dan tanda pengikat catatan ini ke catatan sebelumnya dengan tinggi yang sama (catatan, tanda pengikatan). Catatan dalam bingkai diberi nomor sesuai urutan ketinggian (sopran → alt → tenor → bass). Setiap bingkai juga dapat memiliki bingkai yang menandai akhir kalimat; Fermata diwakili oleh simbol titik (.) Di atas catatan. Simbol
MULAI dan
AKHIR ditambahkan ke awal dan akhir setiap nyanyian. Simbol-simbol ini menyebabkan inisialisasi model dan memungkinkan pengguna untuk menentukan kapan komposisi berakhir.
START
(59, True)
(56, True)
(52, True)
(47, True)
|||
(59, True)
(56, True)
(52, True)
(47, True)
|||
(.)
(57, False)
(52, False)
(48, False)
(45, False)
|||
(.)
(57, True)
(52, True)
(48, True)
(45, True)
|||
ENDContoh pengkodean dua akord. Setiap akord berlangsung dalam ketukan kedelapan dalam ukuran, akor kedua disertai oleh pertanian. Urutan "|||" menandai akhir bingkai def encode_score(score, keep_fermatas=True, parts_to_mask=[]): """ Encodes a music21 score into a List of chords, where each chord is represented with a (Fermata :: Bool, List[(Note :: Integer, Tie :: Bool)]). If `keep_fermatas` is True, all `has_fermata`s will be False. All tokens from parts in `parts_to_mask` will have output tokens `BLANK_MASK_TXT`. Time is discretized such that each crotchet occupies `FRAMES_PER_CROTCHET` frames. """ encoded_score = [] for chord in (score .quantize((FRAMES_PER_CROTCHET,)) .chordify(addPartIdAsGroup=bool(parts_to_mask)) .flat .notesAndRests):
Kode yang digunakan untuk menyandikan nada musik21 menggunakan skema penyandian khususTugas model
Pada bagian sebelumnya, penjelasan diberikan menunjukkan bahwa tugas komposisi otomatis dapat dikurangi menjadi tugas memprediksi urutan. Secara khusus, suatu model dapat memprediksi nada berikutnya yang paling mungkin berdasarkan catatan sebelumnya. Untuk mengatasi jenis masalah ini, jaringan saraf dengan memori jangka pendek (LSTM) paling cocok. Secara formal, model harus memprediksi P (x
t + 1 | x
t , h
t-1 ), distribusi probabilitas untuk catatan selanjutnya yang mungkin (x
t + 1 ) berdasarkan token saat ini (x
t ) dan keadaan tersembunyi sebelumnya (h
t-1 ) . Menariknya, operasi yang sama dilakukan oleh model bahasa berdasarkan jaringan saraf berulang.
Dalam mode komposisi, model diinisialisasi dengan token
START , setelah itu memilih token berikutnya yang paling mungkin untuk diikuti. Setelah itu, model melanjutkan untuk memilih token berikutnya yang paling mungkin menggunakan note sebelumnya dan status tersembunyi sebelumnya sampai token END dihasilkan. Sistem ini mengandung elemen suhu yang menambahkan beberapa tingkat keacakan untuk mencegah BachBot menyusun bagian yang sama berulang kali.
Fungsi kerugian
Saat melatih model untuk prediksi, biasanya ada beberapa fungsi yang perlu diminimalkan (disebut fungsi rugi). Fungsi ini menjelaskan perbedaan antara prediksi model dan properti ground truth. BachBot meminimalkan hilangnya cross-entropy antara distribusi yang diprediksi (x
t + 1 ) dan distribusi aktual dari fungsi tujuan. Menggunakan cross entropy sebagai fungsi kerugian adalah titik awal yang baik untuk berbagai tugas, tetapi dalam beberapa kasus Anda dapat menggunakan fungsi kerugian Anda sendiri. Pendekatan lain yang dapat diterima adalah mencoba menggunakan berbagai fungsi kerugian dan menerapkan model yang meminimalkan kerugian aktual selama verifikasi.
Pelatihan / pengujian
Dalam pelatihan jaringan saraf rekursif, BachBot menggunakan token koreksi dengan nilai x
t + 1 alih-alih menerapkan prediksi model. Proses ini, yang dikenal sebagai pembelajaran wajib, digunakan untuk memastikan konvergensi, karena prediksi model secara alami akan menghasilkan hasil yang buruk pada awal pelatihan. Sebaliknya, selama validasi dan komposisi, prediksi model x
t + 1 harus digunakan kembali sebagai input ke prediksi berikutnya.
Pertimbangan lainnya
Untuk meningkatkan efisiensi dalam model ini, metode praktis berikut digunakan yang umum untuk jaringan saraf LSTM: pemotongan gradien yang dinormalisasi, metode eliminasi, normalisasi paket, dan metode propagasi balik kesalahan terputus waktu (BPTT) yang terpotong.
Metode pemotongan gradien yang dinormalisasi menghilangkan masalah pertumbuhan yang tidak terkendali dari nilai gradien (kebalikan dari masalah gradien hilang, yang diselesaikan dengan menggunakan arsitektur sel memori LSTM). Dengan menggunakan teknik ini, nilai gradien yang melebihi ambang tertentu dipotong atau diskalakan.
Metode eksklusi adalah teknik di mana beberapa neuron yang
dipilih secara acak terputus (dikecualikan) selama pelatihan jaringan. Ini menghindari overfitting dan meningkatkan kualitas generalisasi. Masalah overfitting muncul ketika model menjadi dioptimalkan untuk set data pelatihan dan pada tingkat yang lebih rendah berlaku untuk sampel di luar set ini. Metode eksklusi sering memperburuk kehilangan selama pelatihan, tetapi memperbaikinya pada tahap verifikasi (lebih lanjut tentang ini di bawah).
Perhitungan gradien dalam jaringan saraf berulang untuk urutan 1000 elemen adalah setara dengan biaya untuk maju dan mundur melewati dalam jaringan saraf propagasi langsung 1000 lapisan.
Metode terputus galat balik terpotong (BPTT) dari waktu ke waktu digunakan untuk mengurangi biaya memperbarui parameter selama pelatihan. Ini berarti bahwa kesalahan hanya diperbanyak selama jumlah langkah waktu yang tetap dihitung kembali dari saat ini. Harap dicatat bahwa ketergantungan pembelajaran jangka panjang masih dimungkinkan dengan metode BPTT, karena status laten telah terungkap pada banyak langkah waktu sebelumnya.
Parameter
Berikut ini adalah daftar parameter yang relevan untuk model jaringan saraf berulang / jaringan saraf dengan memori jangka pendek:
- Jumlah lapisan . Meningkatkan parameter ini dapat meningkatkan efisiensi model, tetapi akan membutuhkan waktu lebih lama untuk melatihnya. Selain itu, terlalu banyak lapisan dapat menyebabkan overfitting.
- Dimensi keadaan laten . Meningkatkan parameter ini dapat meningkatkan kompleksitas model, namun hal ini dapat menyebabkan overfitting.
- Dimensi perbandingan vektor
- Panjang urutan / jumlah frame sebelum memotong propagasi kembali kesalahan dari waktu ke waktu.
- Kemungkinan eksklusi neuron . Probabilitas yang dengannya neuron akan dikeluarkan dari jaringan selama setiap siklus pembaruan.
Metodologi untuk memilih set parameter optimal akan dibahas nanti dalam artikel ini.
Implementasi, pelatihan dan pengujian
Pemilihan platform
Saat ini, ada banyak platform yang memungkinkan Anda untuk menerapkan model pembelajaran mesin dalam berbagai bahasa pemrograman (termasuk bahkan JavaScript!). Platform populer termasuk
scikit-learn ,
TensorFlow, dan
Torch .
Perpustakaan Torch dipilih sebagai platform untuk proyek BachBot. Pada awalnya, perpustakaan TensorFlow dicoba, tetapi pada waktu itu menggunakan jaringan saraf berulang yang luas, yang menyebabkan meluapnya RAM GPU. Torch adalah platform komputasi ilmiah yang didukung oleh bahasa pemrograman cepat LuaJIT *. Platform Torch berisi perpustakaan yang sangat baik untuk bekerja dengan jaringan saraf dan optimisasi.
Implementasi dan pelatihan model
Implementasinya, tentu saja, akan bervariasi tergantung pada bahasa dan platform yang Anda pilih. Untuk mempelajari bagaimana BachBot mengimplementasikan jaringan saraf dengan memori jangka panjang dan pendek menggunakan Torch, periksa skrip yang digunakan untuk melatih dan mengatur parameter BachBot. Skrip ini tersedia di situs web
Feynman Lyang GitHub.Titik awal yang baik untuk menavigasi repositori adalah
skrip 1-train.zsh .
Dengannya , Anda dapat menemukan path ke file
bachbot.py .
Lebih tepatnya, skrip utama untuk mengatur parameter model adalah file
LSTM.lua . Script untuk melatih model adalah file
train.lua .
Optimalisasi Hyperparameter
Untuk mencari nilai optimal dari hiperparameter, metode pencarian kisi digunakan menggunakan kisi parameter berikut.
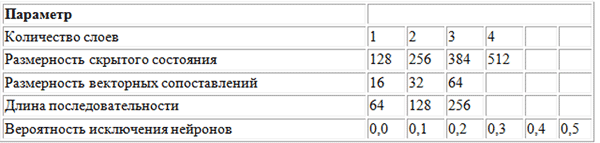 Kisi parameter yang digunakan oleh BachBot dalam pencarian kisi
Kisi parameter yang digunakan oleh BachBot dalam pencarian kisiPencarian kisi adalah pencarian lengkap dari semua kemungkinan kombinasi parameter. Metode lain yang disarankan untuk mengoptimalkan hiperparameter adalah pencarian acak dan optimasi Bayesian.
Himpunan parameter optimal yang terdeteksi sebagai hasil pencarian kisi adalah sebagai berikut: jumlah lapisan = 3, dimensi keadaan tersembunyi = 256, dimensi perbandingan vektor = 32, panjang urutan = 128, probabilitas eliminasi neuron = 0,3.
Model ini mencapai kerugian lintas-entropi 0,324 selama pelatihan dan 0,477 pada tahap verifikasi. Grafik kurva belajar menunjukkan bahwa proses belajar menyatu setelah 30 iterasi (≈28,5 menit saat menggunakan GPU tunggal).
Grafik kehilangan selama pelatihan dan selama fase verifikasi juga dapat menggambarkan efek dari masing-masing hyperparameter. Yang menarik bagi kami adalah kemungkinan menghilangkan neuron:
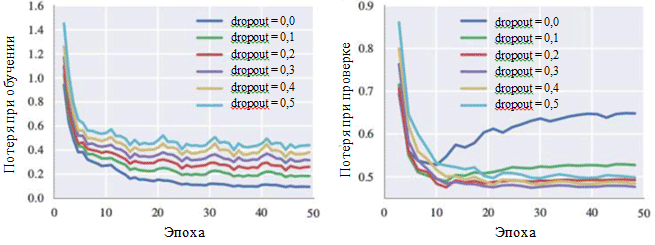 Kurva Belajar untuk Berbagai Pengaturan Metode Pengecualian
Kurva Belajar untuk Berbagai Pengaturan Metode PengecualianDapat dilihat pada gambar bahwa metode eliminasi benar-benar menghindari terjadinya overfitting. Meskipun dengan kemungkinan pengecualian 0,0, kerugian selama pelatihan minimal, pada tahap verifikasi, kerugian memiliki nilai maksimum. Nilai probabilitas yang besar menyebabkan peningkatan kerugian selama pelatihan dan penurunan kerugian pada tahap verifikasi. Nilai minimum kerugian selama fase verifikasi saat bekerja dengan BachBot diperbaiki dengan probabilitas pengecualian 0,3.
Metode penilaian alternatif (opsional)
Untuk beberapa model - terutama untuk aplikasi kreatif seperti menggubah musik - kehilangan mungkin bukan ukuran yang tepat untuk keberhasilan sistem. Sebaliknya, persepsi manusia yang subyektif mungkin menjadi kriteria terbaik.
Tujuan proyek BachBot adalah untuk secara otomatis membuat musik yang tidak dapat dibedakan dari komposisi Bach sendiri. Untuk menilai keberhasilan hasil, survei pengguna di Internet dilakukan. Survei ini diberikan dalam bentuk kompetisi di mana pengguna diminta untuk menentukan karya mana yang termasuk dalam proyek BachBot, dan mana untuk Bach.
Hasil survei menunjukkan bahwa peserta survei (759 orang dengan berbagai tingkat pelatihan) mampu membedakan secara akurat antara dua sampel hanya dalam 59 persen kasus. Ini hanya 9 persen lebih tinggi daripada hasil tebakan acak! Coba
survei BachBot sendiri!
Menyesuaikan model dengan harmonisasi
Sekarang BachBot dapat menghitung P (x
t + 1 | x
t , h
t-1 ), distribusi probabilitas untuk catatan berikutnya yang mungkin didasarkan pada catatan saat ini dan keadaan tersembunyi sebelumnya. Model prediksi sekuensial ini selanjutnya dapat diadaptasi untuk menyelaraskan melodi. Model adaptasi seperti itu diperlukan untuk menyelaraskan melodi, yang dimodulasi dengan bantuan emosi, sebagai bagian dari proyek musikal dengan tampilan slide.
Ketika bekerja dengan harmonisasi model, melodi yang telah ditentukan disediakan (biasanya ini adalah bagian sopran), dan setelah itu model harus menyusun musik untuk sisa potongan. Untuk menyelesaikan tugas ini, pencarian "terbaik-pertama" serakah digunakan dengan batasan bahwa nada melodi diperbaiki. Algoritma serakah melibatkan keputusan yang optimal dari sudut pandang lokal. Jadi, di bawah ini adalah strategi sederhana yang digunakan untuk harmonisasi:
Asumsikan bahwa xt adalah token dalam harmonisasi yang diusulkan. Pada langkah waktu t, jika nada tersebut sesuai dengan melodi, maka xt sama dengan nada yang diberikan. Jika tidak, xt sama dengan not selanjutnya yang paling mungkin sesuai dengan prediksi model. Kode untuk adaptasi model ini dapat ditemukan di situs web Feynman Lyang GitHub: HarmModel.lua , harmonize.lua .
Berikut ini adalah contoh harmonisasi Twinkle pengantar tidur, Twinkle, Little Star dengan BachBot, menggunakan strategi di atas.
 Harmonisasi lagu pengantar tidur Twinkle, Twinkle, Little Star dengan BachBot (di bagian soprano). Bagian viola, tenor dan bass juga diisi dengan BachBot
Harmonisasi lagu pengantar tidur Twinkle, Twinkle, Little Star dengan BachBot (di bagian soprano). Bagian viola, tenor dan bass juga diisi dengan BachBotDalam contoh ini, melodi Twinkle pengantar tidur, Twinkle, Little Star diberikan di bagian soprano. Setelah itu, bagian viola, tenor dan bass diisi menggunakan BachBot menggunakan strategi harmonisasi. Dan
inilah bunyinya .
Terlepas dari kenyataan bahwa BachBot telah menunjukkan kinerja yang baik dalam melakukan tugas ini, ada beberapa batasan yang terkait dengan model ini. Lebih tepatnya, algoritma
tidak melihat ke
depan ke dalam melodi dan hanya menggunakan not saat ini dari melodi dan konteks masa lalu untuk menghasilkan not berikutnya. Ketika menyelaraskan melodi oleh orang-orang, mereka dapat mencakup keseluruhan melodi, yang menyederhanakan derivasi harmonisasi yang sesuai. Fakta bahwa model ini tidak mampu melakukan hal ini dapat menimbulkan
kejutan karena pembatasan penggunaan informasi selanjutnya yang menyebabkan kesalahan. Untuk mengatasi masalah ini, apa yang disebut
pencarian balok dapat digunakan.
Saat menggunakan pencarian balok, berbagai garis gerakan diperiksa. Misalnya, alih-alih menggunakan hanya satu, catatan yang paling mungkin, yang saat ini sedang dilakukan, empat atau lima catatan yang paling mungkin dapat dipertimbangkan, setelah itu algoritma melanjutkan pekerjaannya dengan masing-masing catatan ini. Meneliti berbagai opsi dapat membantu model
pulih dari kesalahan . Pencarian balok biasanya digunakan dalam aplikasi pemrosesan bahasa alami untuk membuat kalimat.
Melodi yang dimodulasi dengan bantuan emosi kini dapat dilewatkan melalui model harmonisasi untuk menyempurnakannya.