
Sedikit lebih dari setahun yang lalu kami
meninjau aplikasi
Splunk Machine Learning Toolkit , yang dengannya Anda dapat menganalisis data mesin pada platform Splunk menggunakan berbagai algoritma pembelajaran mesin.
Hari ini kami ingin berbicara tentang pembaruan yang telah muncul selama setahun terakhir. Banyak versi baru telah dirilis, berbagai algoritma dan visualisasi telah ditambahkan yang akan memungkinkan mengambil analisis data di Splunk ke tingkat yang baru.
Algoritma baru
Sebelum berbicara tentang algoritma, perlu dicatat bahwa ada
API ML-SPL yang dengannya Anda dapat memuat algoritma open source apa pun yang lebih dari 300 algoritma Python. Namun, untuk ini Anda harus dapat memprogram sampai batas tertentu dalam Python.
Oleh karena itu, kami akan memperhatikan algoritma yang sebelumnya hanya tersedia setelah memanipulasi Python, tetapi sekarang tertanam dalam aplikasi dan dapat dengan mudah digunakan oleh semua orang.
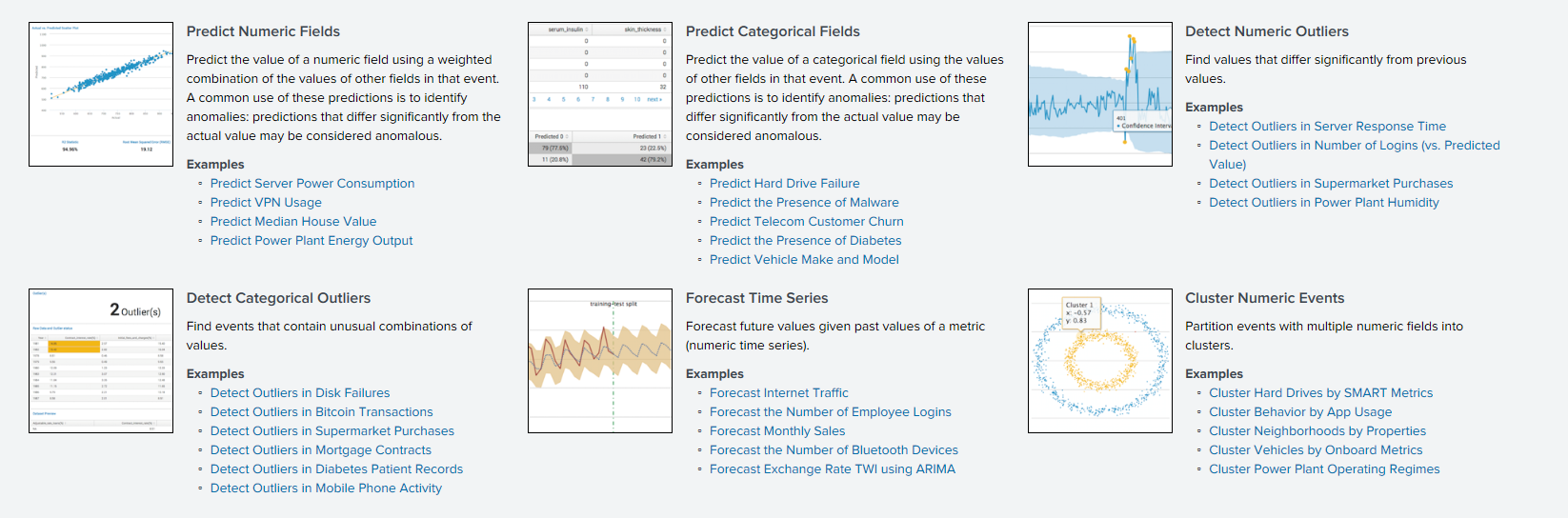 ACF (fungsi autokorelasi)
ACF (fungsi autokorelasi)Fungsi autokorelasi menunjukkan hubungan antara suatu fungsi dan salinan yang digesernya dengan jumlah pergeseran waktu. ACF membantu Anda menemukan bagian duplikat atau menentukan frekuensi sinyal, disembunyikan karena suara dan getaran yang tumpang tindih pada frekuensi lain.
PACF (fungsi autokorelasi parsial)Fungsi autokorelasi pribadi menunjukkan korelasi antara dua variabel, minus pengaruh semua nilai autokorelasi internal. Autokorelasi pribadi pada lag tertentu mirip dengan autokorelasi biasa, tetapi perhitungannya tidak termasuk pengaruh autokorelasi dengan lag yang lebih kecil. Dalam praktiknya, autokorelasi pribadi memberikan gambaran yang lebih “bersih” tentang ketergantungan berkala.
ARIMA (proses terintegrasi autoregresi dan moving average)Model ARIMA adalah salah satu model paling populer untuk membangun prakiraan jangka pendek. Nilai autoregresif mengungkapkan ketergantungan dari nilai saat ini dari deret waktu pada yang sebelumnya, dan rata-rata bergerak dari model menentukan efek dari kesalahan perkiraan sebelumnya (juga disebut white noise) pada nilai saat ini.
 Gradient Boosting Classifier dan Gradient Boosting Regressor
Gradient Boosting Classifier dan Gradient Boosting RegressorGradient boosting adalah metode pembelajaran mesin yang digunakan untuk masalah regresi dan klasifikasi yang menciptakan model prediksi dalam bentuk ansambel model yang lemah, biasanya pohon keputusan. Dia membangun model secara bertahap, ketika masing-masing algoritma berikutnya berupaya untuk mengkompensasi kekurangan komposisi semua algoritma sebelumnya. Awalnya, konsep boosting muncul dalam karya sehubungan dengan pertanyaan apakah mungkin, memiliki banyak algoritma pembelajaran yang buruk (sedikit berbeda dari definisi acak), untuk mendapatkan yang baik. Selama 10 tahun terakhir, meningkatkan tetap menjadi salah satu metode pembelajaran mesin yang paling populer, bersama dengan jaringan saraf. Alasan utamanya adalah kesederhanaan, keserbagunaan, fleksibilitas (kemampuan untuk membangun berbagai modifikasi), dan, yang paling penting, kemampuan generalisasi tinggi.
X-meansAlgoritma clustering X-means adalah algoritma k-means lanjutan yang secara otomatis menentukan jumlah cluster berdasarkan kriteria informasi Bayesian (BIC). Algoritma ini nyaman digunakan ketika tidak ada informasi awal tentang jumlah cluster di mana data ini dapat dibagi.
RobustscalerIni adalah algoritma preprocessing data. Aplikasi ini mirip dengan algoritma StandardScaler, yang mentransformasikan data sehingga untuk setiap fitur rata-rata adalah 0 dan variansnya 1, sehingga semua fitur memiliki skala yang sama. Namun, penskalaan ini tidak menjamin penerimaan nilai minimum dan maksimum spesifik dari atribut. RobustScaler mirip dengan StandardScaler dalam hal itu, sebagai akibat dari penerapannya, fitur-fiturnya akan memiliki skala yang sama. Namun, RobustScaler menggunakan median dan kuartil alih-alih mean dan varians. Ini memungkinkan RobustScaler untuk mengabaikan outlier atau kesalahan pengukuran, yang bisa menjadi masalah untuk metode penskalaan lainnya.
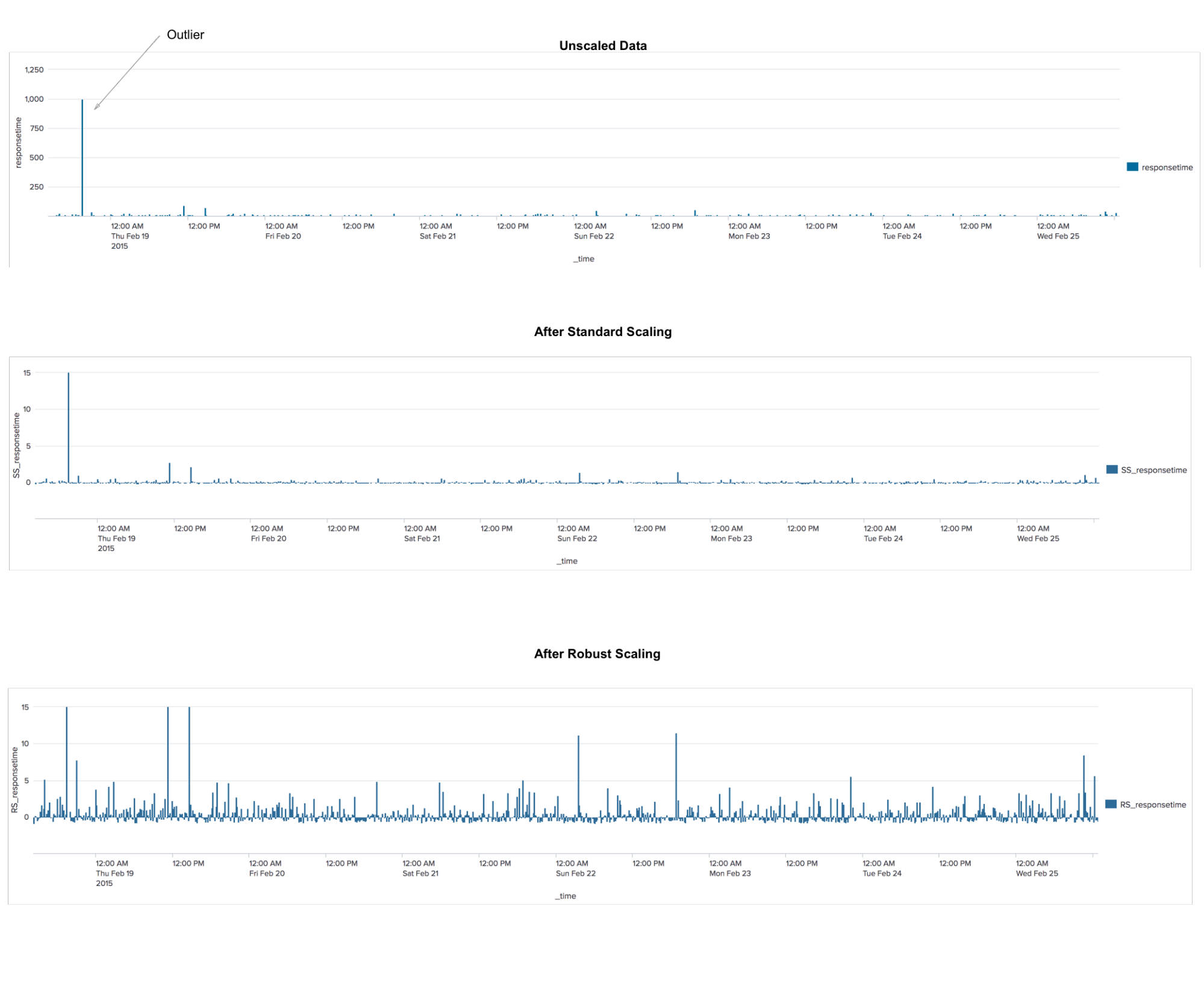 TFIDF
TFIDFUkuran statistik yang digunakan untuk menilai pentingnya kata dalam konteks dokumen yang merupakan bagian dari kumpulan dokumen. Prinsipnya adalah ini: jika sebuah kata sering ditemukan dalam dokumen, sementara jarang ditemukan di semua dokumen lain, maka kata ini sangat penting untuk dokumen itu sendiri.
MLPClassifierAlgoritma jaringan saraf pertama di Splunk. Algoritma ini dibangun berdasarkan
perceptron multilayer , yang akan menangkap hubungan nonlinear dalam data.
Administrasi
Dalam versi baru, administrasi aplikasi telah berubah secara signifikan.
Pertama,
model peran akses ke berbagai model dan percobaan telah ditambahkan.
Kedua, antarmuka baru untuk
mengelola model telah diperkenalkan. Sekarang Anda dapat dengan mudah melihat jenis model apa yang Anda miliki, periksa pengaturan masing-masing model (misalnya, variabel mana yang digunakan untuk melatihnya) dan melihat atau memperbarui pengaturan berbagi untuk masing-masing model.
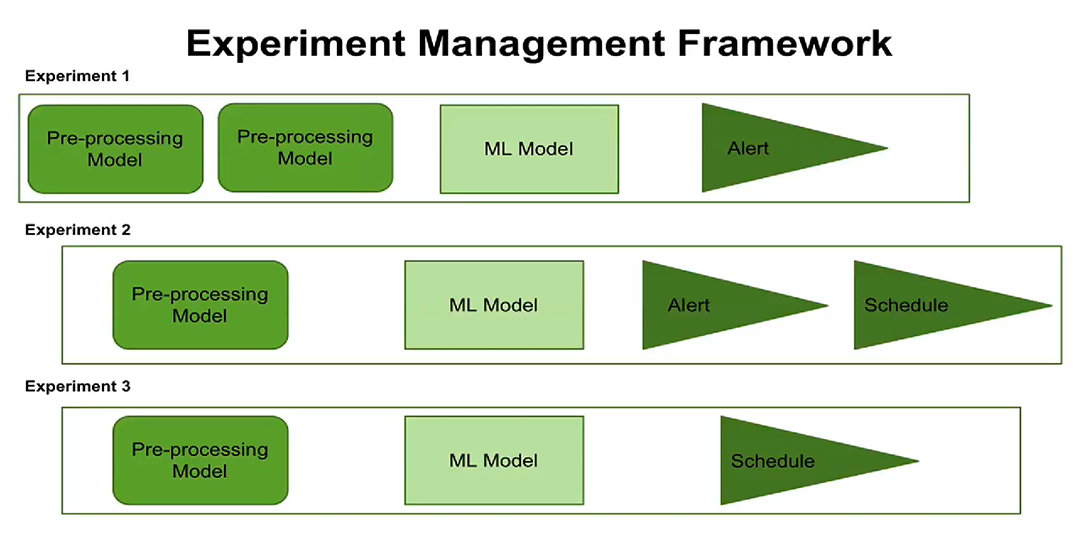
Ketiga, munculnya konsep manajemen eksperimen. Sekarang Anda dapat
mengkonfigurasi eksekusi percobaan pada jadwal, mengkonfigurasi peringatan. Pengguna dapat melihat kapan setiap percobaan dijadwalkan untuk dijalankan, langkah dan parameter pemrosesan apa yang dikonfigurasikan untuk setiap percobaan.
Konsep baru manajemen eksperimen sekarang memberi Anda kesempatan untuk membuat dan mengelola beberapa percobaan sekaligus, untuk mencatat kapan percobaan ini dilakukan dan hasil apa yang diperoleh.
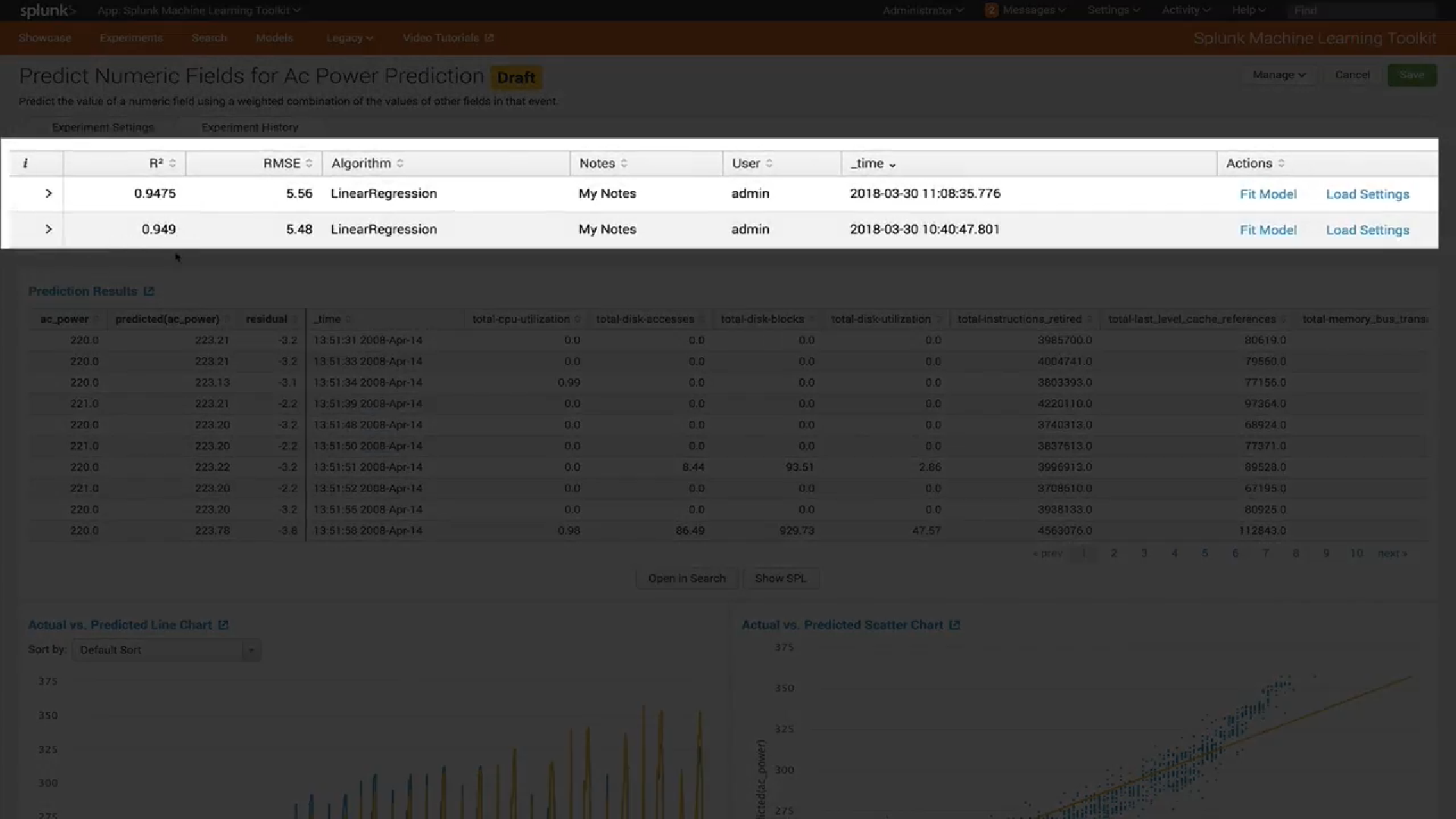
Visualisasi
Dalam versi terbaru MLTK 3.4, jenis visualisasi baru telah ditambahkan.
Box Plot yang terkenal atau, seperti kita juga menyebutnya, "Boxes with kumis."
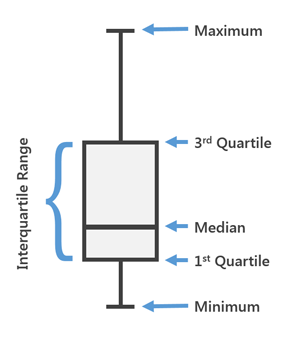
Box Plot digunakan dalam statistik deskriptif, dengan menggunakannya Anda dapat dengan mudah melihat median (atau, jika perlu, rata-rata), kuartil bawah dan atas, nilai minimum dan maksimum sampel dan pencilan. Beberapa kotak ini dapat ditarik berdampingan untuk membandingkan secara visual satu distribusi dengan yang lain. Jarak antara berbagai bagian kotak memungkinkan Anda untuk menentukan tingkat dispersi (dispersi) dan asimetri data dan mengidentifikasi outlier.
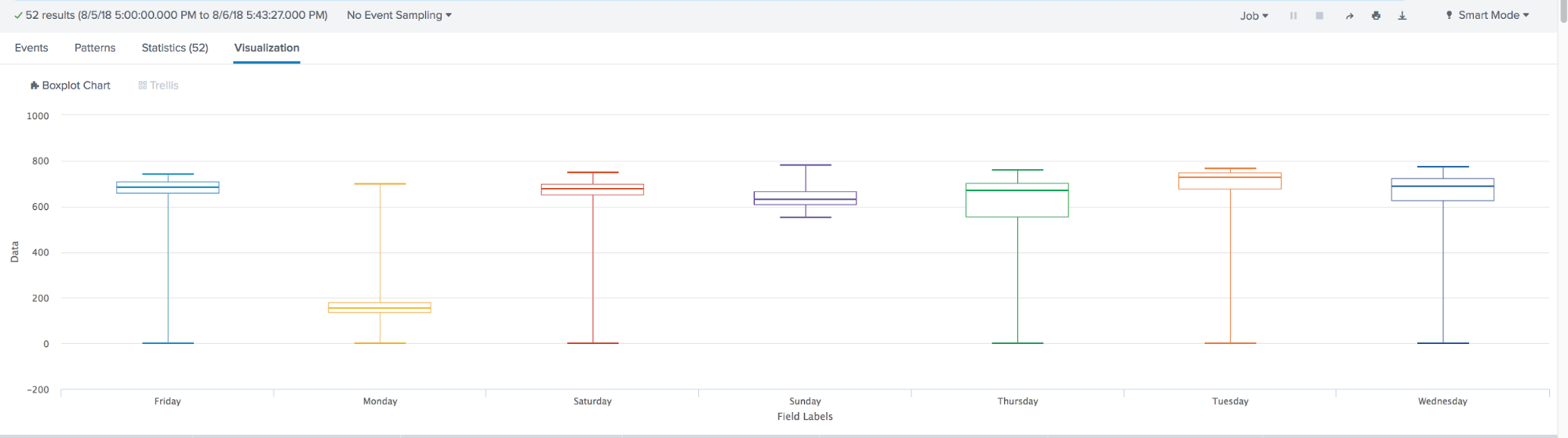
Kesimpulannya, sepanjang tahun, pembelajaran mesin di Splunk telah mengambil langkah besar ke depan. Muncul:
- Banyak algoritma built-in baru, seperti: ACF, PACF, ARIMA, Gradient BoostingClassifier, Gradient Boosting Regressor, X-means, RobustScaler, TFIDF, MLPClassifier;
- Model akses berbasis peran dan kemampuan untuk mengelola model dan eksperimen;
- Plot Kotak Visualisasi
